Behind the Paper: 하이퍼커넥트 AI 조직이 제품에 기여하면서 연구하는 법
하이퍼커넥트는 오랜 기간 제품에 기여하는 AI 기술을 연구해 왔습니다. AI를 통해 제품에 기여한다고 하면 성과지표(KPI)를 설정하고 적당한 모델을 찾은 뒤 가능한 한 빨리 시장에 제품을 출시하는 것으로 여겨지기 쉽습니다. 반대로 연구라고 하면 논문 작성과 동일시되는 경향이 있고요. 하지만 하이퍼커넥트의 AI 조직이 일하는 방식은 이러한 일반적인 인식과는 차별화되는 부분이 있습니다. 이번 블로그 포스트에서는 실제 제품에 기여하기 위한 연구 활동 과정 및 그 결과물이 ECCV 2022에 논문으로 출판됐던 사례를 통해 하이퍼커넥트 AI 조직이 일하는 방식을 소개하고자 합니다.1
하이퍼커넥트 AI의 연구 과정
하이퍼커넥트에는 이미지를 입력으로 받아서 특정 상황인지 아닌지를 판단하는 매우 중요한 작업 A가 있었습니다. 그래서 작업 A에 대해서는 많은 레이블링 된 데이터셋이 미리 확보되어 있는 상황이었고 성능이 좋은 분류기 A도 미리 만들어져 있었습니다. 한편, 작업 A와 판단해야 하는 상황은 동일하지만 입력되는 이미지의 분포가 다른 작업 B가 있었는데요, 처음에는 중요도가 높지 않았기에 분류기 A를 이용해서 작업 B를 처리하고 있었습니다. 하지만, 작업 B가 점점 더 중요해짐에 따라 분류기 A로 작업 B를 수행하는 것은 한계에 부딪혔습니다. 높아진 중요도와 달리 성능이 원하는 만큼 나오지 않았던 것인데요, 그래서 우리는 작업 B에 대해서 분류기 A를 미세조정(fine-tuning)하기로 결정했습니다. 작업 A와 B가 비슷한 작업이긴 했지만 입력 데이터의 분포가 확실히 달랐기에 작업 B에 대해서 미세조정을 하면 성능이 좋아질 것으로 기대했습니다.
하지만, 실제로 미세조정을 수행해 본 결과 작업 B에 미세조정한 분류기가 분류기 A보다 낮은 성능을 나타냈습니다. 이해할 수 없는 결과였습니다. 이유를 찾기 위해 데이터를 직접 하나하나 확인해 보았는데요, 작업 A는 당시 제품에서 매우 중요한 역할을 하고 있었기 때문에 레이블링 오류를 관리하기 위한 여러 가지 프로세스가 도입되어 있었고 그 결과로 레이블링이 오류 없이 정책에 맞게 매우 잘 관리되고 있었습니다. 반면에, 작업 B는 이제 막 중요해지기 시작했었고 과거에 중요성이 비교적 낮았기 때문에 레이블링에 오류가 많았습니다.
우리는 작업 B에 대해서도 레이블링 오류를 관리하는 프로세스 도입을 검토했지만, 작업 A의 사례를 고려했을 때 예상보다 높은 비용이 발생한다는 것을 알게 되었습니다. 특히, 데이터셋의 크기가 커질수록 비용도 비례해서 증가하기 때문에 장기적으로는 적절한 해결책이 아니라고 판단했습니다. 당시에는 노이즈가 포함된 데이터셋을 활용해 학습하는 노이즈 러닝(noise learning) 분야가 이미 활발히 연구되고 있었는데요, 이를 제품에 적용하면 큰 비용 증가 없이도 작업 B에 대해 높은 성능을 보이는 분류기를 학습할 수 있을 것이라 기대했습니다. 이에 따라 우리는 노이즈 러닝을 제품에 도입해 비용 효율적인 분류기 학습 시스템을 만드는 것을 새로운 목표로 설정하게 되었습니다.
이렇게 문제가 정의되면 우리는 문헌 조사를 시작합니다. 문헌 조사 과정에서 기존의 연구를 검토하여 문제가 과거에 어떻게 해결되었는지를 파악하고 이를 바탕으로 우리의 해결 방법을 보다 구체화합니다. 하이퍼커넥트 AI 조직은 문헌 조사를 특별히 중요하게 여기며 해결하고자 하는 문제에 대해 관련된 연구를 충분히 조사했다고 자신할 수 있을 정도로 철저히 수행합니다. 구체적인 내부 가이드라인으로 하나의 문제에 대해 최소 100편의 연구를 조사하고 이를 2~3일 내에 완료하는 기준을 가지고 있습니다. 우리는 노이즈 러닝뿐만 아니라 데이터셋 클렌징(dataset cleansing) 등 인접 분야의 논문을 포함해 수백 편의 논문들을 팀원들과 함께 조사하고 각 논문에 관해 토론했습니다.

* 실제 수백 편의 논문을 조사했던 결과
문헌 조사를 한 결과 당시 연구의 흐름은 적은 수의 클린셋이 있는 세팅과 없는 세팅으로 나누어졌습니다. 한쪽 연구는 아주 적은 수의 노이지하지 않은 클린셋을 얻을 수 있다고 가정하는 연구들이었고, 다른 한쪽은 이런 클린셋을 얻을 수 없다고 가정하는 연구들이었습니다. 여러 논문에서 제시된 벤치마크 성능을 종합적으로 검토해 보니 너무나 당연하게도 클린셋을 사용하는 연구가 월등히 좋은 성능을 보여주고 있었고, 우리 세팅의 경우에도 작은 클린셋을 당연히 얻을 수 있었기 때문에2 사용해서 성능을 높일 수 있다면 쓰지 않을 이유가 없었습니다. 그래서, 클린셋을 이용해서 성능을 높인 연구를 집중적으로 살펴보았습니다. 물론, 클린셋 없이도 클린셋을 쓴 것과 유사한 성능을 내거나 오히려 더 높은 성능을 냈다고 주장한 논문들 역시 함께 검토되었습니다.
클린셋을 쓴 연구들에는 메타 러닝(meta learning), 샘플 가중치 조정(sample reweighting), 손실 함수(loss function) 변경 등 다양한 갈래가 있었는데요, 그 중에서도 꽤 오래 전부터 연구되고 있는 전이 행렬(transition matrix)을 활용한 연구들에 집중했습니다. 몇몇 가정 아래에서 우리가 전이 행렬을 정확하게 추론할 수 있다면, 이론적으로는 노이즈가 있는 데이터셋으로부터도 마치 데이터셋이 노이즈가 없을 때처럼 분류기를 안정적으로 학습할 수 있음을 증명할 수 있었습니다3. 실제로도 전이 행렬을 활용했던 GLC(gold loss correction) 방법론(Hendrycks et al., 2018)이 많은 논문에서 인용되면서도 단순하면서도 강력한 베이스라인으로서 안정적으로 여러 벤치마크에서 좋은 성능을 내고 있었습니다. 그래서 우리는 GLC 방법론을 작업 B에 적용해 보았습니다. 하지만, 아쉽게도 분류기 A와 비교했을 때 분류기 성능이 큰 차이가 나지 않았습니다. 분류기 A와 비교했을 때 GLC 방법론이 훨씬 더 뛰어나야 분류기를 교체할 동인이 있는데 GLC 방법론에서 제안하는 여러 하이퍼 파라미터들을 바꿔보아도 우리가 도달하고 싶은 성능에 도달하는 데는 어려움을 겪었습니다.
역시 쉽게 되는 건 없습니다. 조사했던 연구를 다시 면밀히 검토해 보니 당시에 레이블 수정(label correction)과 관련된 논문들이 많이 나오고 있었고 몇몇 벤치마크에서 꽤 좋은 성능을 낸다는 것을 확인할 수 있었습니다. 여기서 레이블 수정이란 데이터셋에 노이즈가 있을 때 학습을 진행하면서 데이터셋에 있는 노이즈를 제거해 데이터셋을 점점 깨끗하게 만드는 방법을 말합니다. VC 차원(dimension) 개념으로 사고해 보면 데이터셋을 내부적으로 더 깨끗하게 만드는 것이 더 좋은 분류기를 만들기에 효과적임을 알 수 있고4, 실제로 레이블 노이즈가 증가할수록 벤치마크 성능이 확연히 떨어지는 것을 거의 모든 분류기와 데이터셋에서 당연하게도 확인할 수 있었습니다.
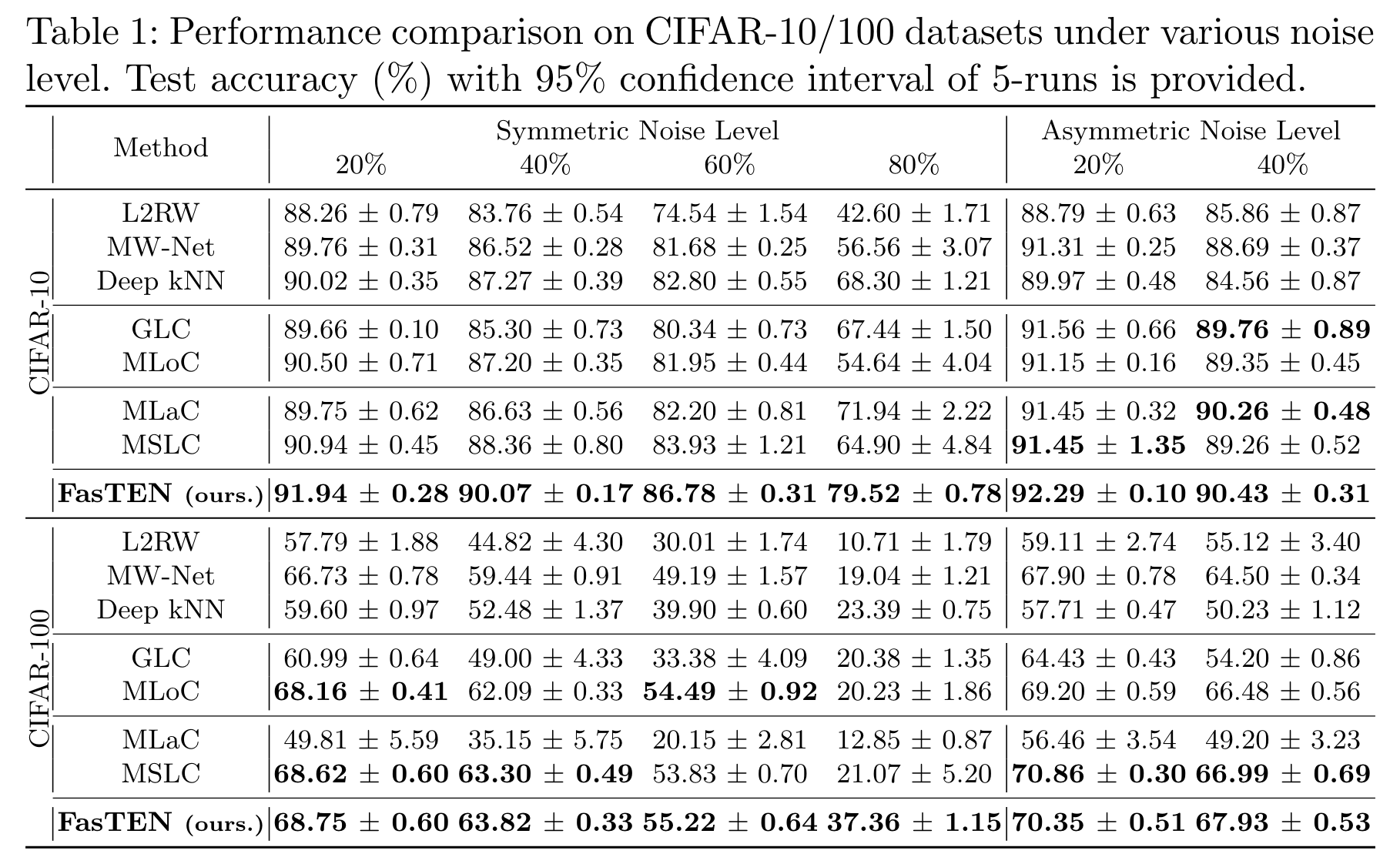
하지만, 이 레이블 수정 방법들에는 한 가지 치명적인 문제가 있었는데요. 한 번 잘못 레이블 수정하면 오류가 전파되면서 아예 학습이 망가질 수도 있다는 점이었습니다. 위 성능 비교표를 보시면 MLaC, MSLC와 같은 레이블 수정 방법론들의 성능 신뢰 구간(confidence interval)이 몇몇 실험들에서 이상하게 큰 것을 볼 수 있는데요. 이는 한번 잘못 수정된 레이블 오류가 다른 레이블까지 전파되어 학습이 아예 망가지는 경우들이 생기기 때문에 발생하는 현상입니다.
아무리 좋은 성능을 내더라도 일정 확률로 학습이 망가질 가능성이 있는 방법론은 제품에서 사용하기 어렵습니다. 보통 제품에서는 분류기가 주기적으로 재학습되는 경우가 많은데 만약 이 과정 중에 일정 확률로 학습이 망가진다면 우리는 그때마다 수동으로 신경 써서 배포할지 말지 결정하거나 다시 학습시키는 등 몇몇 귀찮은 작업을 추가로 해줘야 하기 때문입니다.
레이블 수정 방법론은 분명 데이터셋을 더 깨끗하게 만들어주기 때문에 성능 측면에서 업사이드가 있는 방법이었습니다. 하지만, 오류가 전파될 수 있는 위험 때문에 쓰기가 어려운 게 문제였죠. 그래서 우리는 이런 생각에 도달하게 됩니다.
그럼, 오류 전파가 안되게 하면 되잖아!
GLC 방법론을 한번 재현해 본 우리는 GLC 방법론을 응용하면 오류가 전파되지 않는 새로운 레이블 수정 방법을 디자인할 수 있을 것이라 판단했습니다. GLC 방법론은 학습을 두 번 해야 하는데 레이블 수정을 할 때마다 학습을 한 번씩 더할 수는 없으니, 학습을 두 번 하지 않도록 GLC 방법론을 매 반복마다 실시간으로 계산할 수 있도록 수정하는 작업부터 먼저 했고요. 그 이후에 레이블 수정의 아이디어를 넣어서 새로운 알고리즘을 디자인했습니다(구체적인 방법론에 대한 설명은 다른 포스트에서 자세하게 확인하실 수 있습니다).
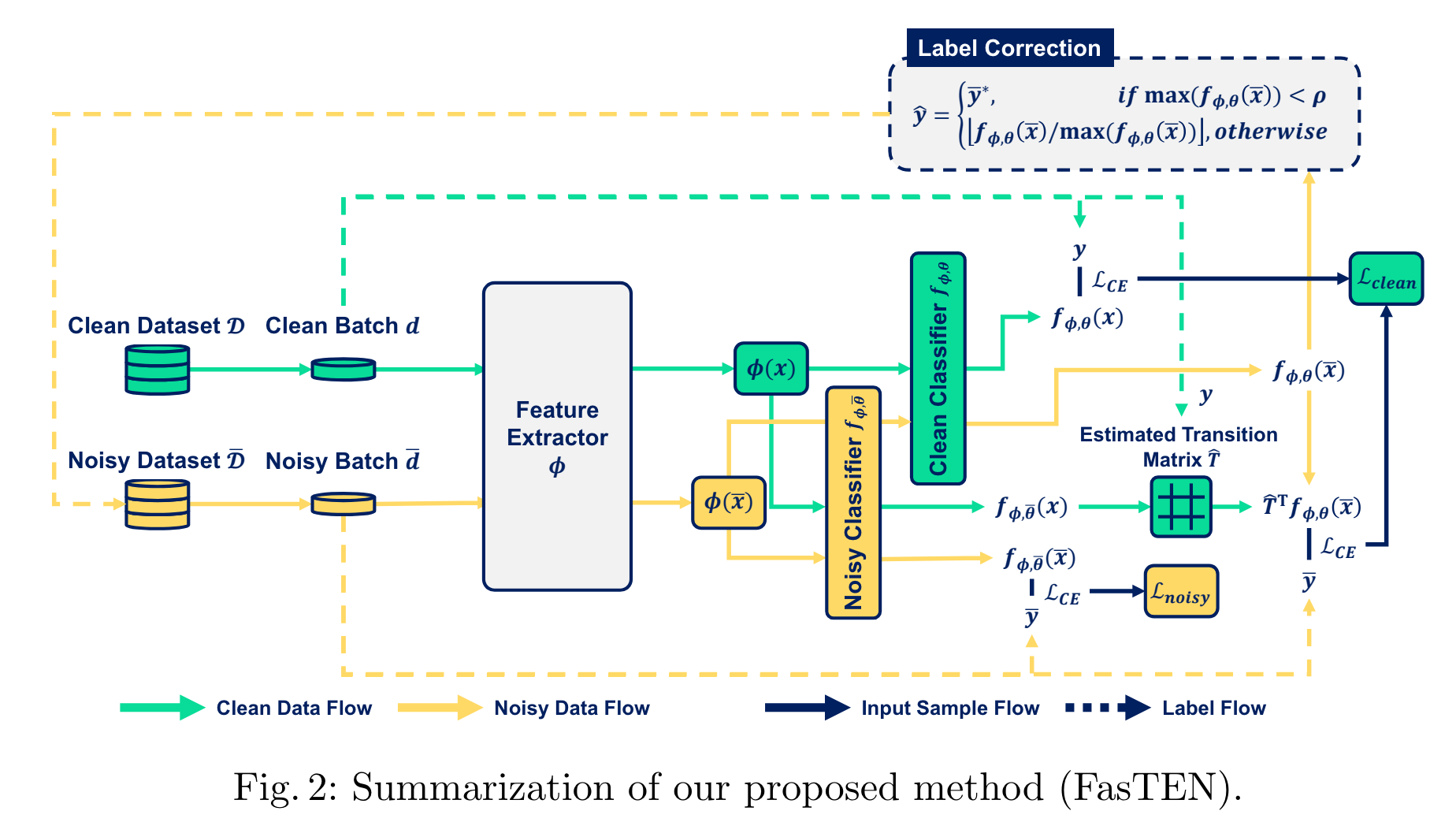
이 새로운 방법은 레이블 수정을 하더라도 바뀐 레이블을 완전히 신뢰하지 않아 오류가 다른 레이블로까지 전파되지 않도록 디자인되어 있습니다. 결과적으로 우리는 이 방법을 통해서 작업 B에서 제품에서 원하는 성능을 얻을 수 있게 되었습니다.

지금 우리가 만든 모든 구성 요소가 정말 다 필요할까?
필요하지 않은 구성 요소가 있다면 운영의 편의를 위해 과감하게 빼는 것이 미래를 위해 더 나은 선택일 가능성이 높습니다. 그래서 우리는 보통 방법론이 일차적으로 완성되면 제거 실험(ablation study)을 진행하는데요. 이 연구에서도 마찬가지로 제거 실험을 진행했습니다. 이 모델은 크게 두 개 구성 요소로 이루어져 있습니다. (1) 레이블 수정을 하는 부분과 (2) GLC 방법론을 매 반복마다 실시간으로 계산하는 부분입니다. 레이블 수정 부분을 제거해 봤을 때 만약 성능이 많이 하락하지 않는다면, 우리는 방법론의 간결함을 유지하도록 레이블 수정 부분을 제거하는 선택을 할 수도 있습니다. GLC 방법론을 실시간으로 계산하는 부분만은 제거할 수 없기에 (1) 부분에 대해서만 제거해보는 실험을 진행해 보았습니다.
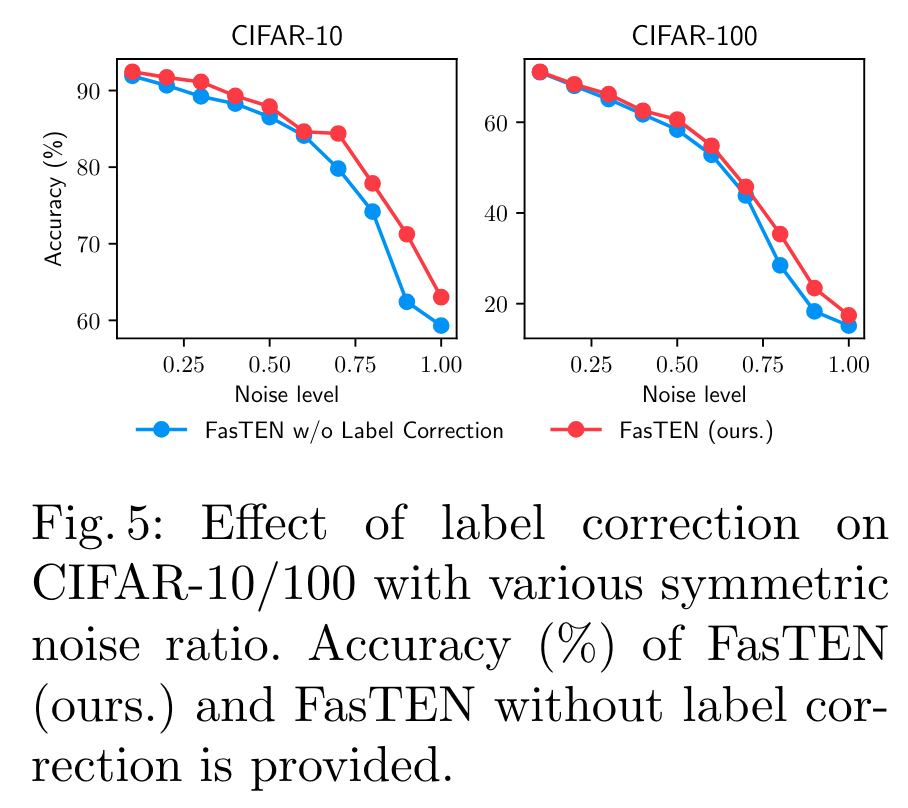
레이블 수정을 하는 부분을 제거했을 때 작업 B에서 유의미한 수준의 성능 하락이 있어서 어떤 구성 요소도 제거하지 않기로 결정했습니다(위에 첨부해 드린 실험 결과는 CIFAR 벤치마크 데이터셋에 대한 실험 결과이지만 내부 데이터를 활용한 제거 실험에서 더 큰 차이를 보여주었습니다).
이론적으로도 말이 되는 방법일까?
위에서 언급했던 것처럼 전이 행렬을 사용하는 방법들에는 좋은 이론적인 배경이 있는데요, 우리가 전이 행렬을 정확하게 추론할 수 있다면 노이즈가 있는 데이터셋에서도 분류기를 안정적으로 학습할 수 있다는 것입니다. 기존에 알려져 있던 증명을 살짝 고쳐서 확인해 보니 새로이 만든 이 방법도 전이 행렬을 꽤 정확하게 추론할 수 있는 방법이었습니다.

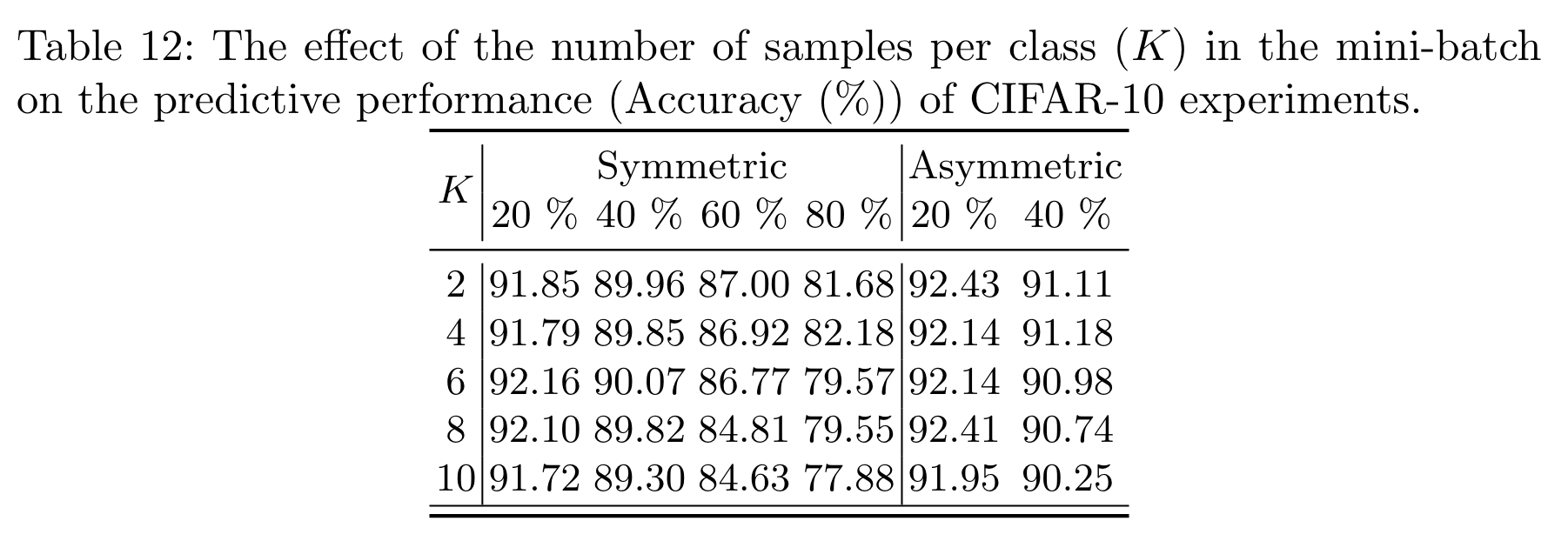
다만, 위 theorem에서 확인할 수 있는 것처럼 배치 사이즈 \(K\)가 커지면 커질수록 전이 행렬을 더 정확하게 추정할 수 있게 되는데요. 그래서 이론만 보자면 우리는 배치 사이즈를 가능한 한 크게 썼어야 했습니다. 하지만, 실제로 다양한 배치 사이즈에 대해 실험해 보니 \(K\)가 작더라도 우리의 분류기는 안정적으로 학습된다는 것을 실험적으로 확인할 수 있었습니다.
추가적으로 알게된 사실들. 이 과정에서 의도치 않게 얻어진 것이 하나 있었습니다. 본 연구의 목적은 본래 레이블 수정은 분류기의 성능을 높이기 위한 것이었으나 어떤 레이블러가 레이블링을 잘못했는지도 추정할 수 있게 되었습니다. 특정 레이블러의 레이블이 많이 수정되고 있다면 그 레이블러의 샘플들을 더 집중적으로 조사하는 등 레이블링 품질을 높이기 위한 몇몇 작업을 수행하는 데 도움을 줄 수 있는 데이터들이 이 연구의 결과물로 얻어졌습니다.
테크 스펙(tech spec)
지금까지 실제로 제품에 들어가는 기술을 만들기 위한 사례를 소개했습니다. 이런 연구 과정에서 하이퍼커넥트 AI 조직에서는 꼭 테크 스펙이라는 문서를 써야 합니다. 일종의 연구 노트라고도 볼 수 있고 연구의 결과물로서 연구가 끝났을 때 꼭 함께 나와야 하는 문서입니다. 테크 스펙 문서 템플릿을 소개해 드리면 다음과 같습니다.
- 소개(introduction): 우리가 어떤 문제를 풀 건지, 왜 이 문제를 풀어야만 하는지를 서술합니다. 문제의 중요성에 대해 여러 데이터를 통해 강조해서 서술되어야 합니다.
- 관련 연구(related works): 이전에 하이퍼커넥트에서 했던 기존 연구나 시도들이 있으면 모아둡니다. 또, 문헌 조사를 통해 학계에서 기존에 어떤 연구들이 있었는지를 조사해서 정리합니다. 문헌 조사는 최소 100편 하는 것을 원칙으로 합니다.
- 목적(objectives)
- 목표(goals): 목표가 무엇인지 명확히 합니다. 성공을 어떻게 측정할 것인지도 명확히 해야 합니다.
- 달성하지 않을 목표(non-goals): 프로젝트와 관련이 있을 수 있지만 의도적으로 해결하지 않는 것을 의미합니다. 달성하지 않을 목표를 정의하는 것은 프로젝트의 범위를 제한하고 기능의 무분별한 확장을 방지하는 데 도움이 됩니다. 본 프로젝트에서는 레이블러의 레이블 오류를 판단하는 작업이 달성하지 않을 목표 중 하나였습니다.
- 방법(methods): 어떤 방법론을 통해 문제를 해결할 것인지를 서술합니다.
- 결과(results): 제안한 방법론을 실제로 제품에 적용해서 어떤 임팩트가 났는지 결과를 작성합니다.
- 논의(discussion): 연구의 한계나 다음에 어떤 연구를 할 것인지 등에 대해서 작성합니다.
연구를 시작할 때 꼭 소개와 목적 부분을 작성하고 시작해야 하며 혹시 중간에 연구의 방향이 바뀔 때마다 본 문서는 최신 상태로 유지되도록 업데이트해야 합니다. 하이퍼커넥트 AI 조직은 본 테크 스펙 문서를 업데이트하는 것을 매우 중요시하고 있으며 지금도 많은 문서들이 계속해서 업데이트되고 있습니다.
연구가 끝나고 동시에 테크 스펙 문서가 완성되면 우리는 이 연구를 특허화할지 혹은 논문화할지 결정하게 됩니다. 본 의사 결정에는 다양한 요소들이 고려되고 있습니다. 저희가 하는 많은 연구 중에 공개하지 않기로 결정되는 연구들이 훨씬 많기에 아주 일부분만 논문이나 특허 형태로 공개되어 오고 있습니다.
논문화
우리는 본 연구를 논문화하기로 결정했습니다. 이 연구를 논문화하는 데는 그리 오랜 시간이 걸리지는 않았는데요. 이미 눈치채셨을 수도 있겠지만 저희가 작성해야 하는 테크 스펙 문서 형식은 논문의 형식과 굉장히 유사합니다. 따라서 대부분의 글이 논문에 준하는 형식으로 이미 작성되어 있고 논문 제출을 위한 벤치마크 데이터셋 실험 정도만 더 돌리고 논문 작성만 하면 됩니다. 논문 작성의 경우에도 대부분 이미 한국어로 작성이 되어있기 때문에 영어로 고치는 작업만 수행하면 할 일이 많지는 않습니다.
저희가 논문화할 때 가장 많은 시간을 쓰게 되는 부분은 아무래도 벤치마크 데이터셋에 실험을 돌리는 부분입니다. 논문에는 벤치마크 데이터셋에 대한 실험 결과가 필요한데 저희 데이터셋에 연구를 진행하다 보니 벤치마크 데이터셋에 실험을 집중적으로 하지 않아서 이 부분에 대한 작업은 따로 필요합니다. 다행히 저희는 대용량의 계산 자원을 보유하고 있고 공개된 것만 A100 160대를 보유하고 있습니다. 본 연구의 논문화 당시에는 쉬고 있는 몇몇 계산 자원이 있어 해당 계산 자원을 이용해 금방 벤치마크 실험을 끝낼 수 있었습니다. 이렇게 완성된 논문은 몇 번의 개정 끝에 2022 ECCV에 최종 출판되었습니다.

지금까지 하이퍼커넥트 AI 조직이 어떻게 제품에 기여하는 연구를 하는지 소개해 드렸습니다. 하이퍼커넥트 AI는 문제 하나를 풀 때 깊이 있게 고민하고 한 문제를 풀 때 최소 100편의 논문을 읽도록 강조합니다. 돌아가는 솔루션 아무거나 하나 찾아서 어떻게든 돌아가게 만드는 것보다는 여기서 최선의 선택이 무엇인지 고민하고 각 과정에서 학습해 나가면서 지식을 쌓아나가고 있습니다. 시중에 나와 있는 연구들로 우리의 문제를 해결할 수 있다면 정말 좋겠지만 나와 있는 해결책이 부족하다면 우리가 스스로 해결책을 고안해 나가는 것도 주저하지 않습니다. 그리고 이렇게 만들어낸 기술을 실제 제품에 적용해 비즈니스 임팩트를 내는 것을 최우선 과제로 여깁니다. 우리는 논문 작성만이 아니라 문제를 발견하고 AI/ML로 문제를 해결하는 모든 과정을 연구라고 정의합니다. ML Engineer는 AI/ML이란 도구를 활용해 문제를 해결하는 사람들이라고 보고 있습니다. 저희와 같이 AI/ML로 문제를 해결해 가실 분들을 찾고 있는데 많은 지원 부탁드립니다!
1 이번 포스트에서 소개하는 내용은 3년 전인 2021년에 연구되었고 2022년에 출판된 내용입니다. 따라서 현재는 더 발전된 연구들이 있을 수 있고 현재 하이퍼커넥트가 사용하고 있는 방법과는 소개된 내용이 상이할 수 있음을 미리 밝힙니다.
2 연구자인 ML Engineer가 데이터셋을 샘플링해서 적은 수를 레이블링하면 클린셋을 얻을 수 있습니다.
3 논문(Kye et al., 2022)의 Appendix A.2에서 관련 문헌 조사 내용들이 정리되어있습니다.
4 논문(Kye et al., 2022)의 Appendix A.1에서 관련 증명을 확인해보실 수 있습니다.
Reference
-
(Hendrycks et al., 2018) Hendrycks, D., Mazeika, M., Wilson, D., & Gimpel, K. (2018). Using trusted data to train deep networks on labels corrupted by severe noise. Advances in neural information processing systems, 31.
-
(Kye et al., 2022) Kye, S. M., Choi, K., Yi, J., & Chang, B. (2022, October). Learning with noisy labels by efficient 전이 행렬 estimation to combat label miscorrection. In European Conference on Computer Vision (pp. 717-738). Cham: Springer Nature Switzerland.
Read more
-
비즈니스 문제를 AI 문제로 정렬하는 방법
최적화 이론의 완화(relaxation) 개념을 비즈니스 문제에 적용하여, 비즈니스 문제를 AI 문제로 정렬하는 방법을 소개합니다. -
아자르에서는 어떤 추천 모델을 사용하고 있을까?
아자르의 1:1 비디오 채팅에 사용되는 추천 모델 CUPID를 소개합니다. -
협업 필터링을 넘어서: 하이퍼커넥트 AI의 추천 모델링
하이퍼커넥트 AI 조직이 추천 시스템에 협업 필터링(collaborative filtering)을 넘어 어떤 모델링을 적용하고 있는지 소개합니다. -
아자르에서 AI 기반 추천 모델의 타겟 지표를 설정하는 방법 (feat. 아하 모멘트)
리텐션을 올리기 위해서는 어떤 AI 모델을 학습시켜야 할까요? 아자르에서 아하 모멘트 프레임워크로 AI 추천 모델의 타겟 지표를 설정한 방법을 소개합니다.