초고성능 딥러닝 클러스터 구축하기 1편
Hyperconnect의 AI Lab에서는 Vision, Audio, NLP 등 다양한 분야에서 수많은 ML 모델을 연구/개발하고 있습니다. 인공지능 연구가 잘 진행되기 위해서는 딥러닝 학습을 위한 인프라가 잘 갖추어져 있어야 하며, 이를 위해 리소스를 아낌없이 투자하고 있습니다.
이번 포스트에서는 멀티노드 학습에 필요한 딥러닝 클러스터의 개요와, 왜 Hyperconnect ML Platform 팀에서 직접 딥러닝 클러스터를 구축하게 되었는 지를 설명합니다.
딥러닝 클러스터란?
딥러닝 학습 인프라의 de facto standard는 GPU 클러스터(cluster)입니다. 일반적으로 GPU 클러스터는
- 다수의 GPU가 장착된 딥러닝 서버들을
- 대역폭이 일반 1G 회선의 10배~200배인 고속 네트워크로 엮은
분산 처리(distributed processing) 시스템을 이야기합니다.
GPU 클러스터가 구성되어 있으면 딥러닝 학습에 필요한 계산을 수십~수백 개의 GPU에 나누어 동시에 처리하고, 고속 네트워크를 통해 결과를 합산할 수 있습니다. 이런 학습 방식을 멀티노드 분산 학습이라고 합니다. 이 기법을 이용하면 모델 학습의 병렬성(parallelism)을 최대한 활용함으로써 시간과 공간의 제약을 극복하고 기존에는 불가능했던 연구를 진행할 수 있습니다.
시간의 제약 극복하기 : ImageNet in 1 Hour
Data parallelism
병렬성에는 데이터(data)와 연산(task)의 두가지 측면이 있습니다. 그 중 data parallelism이란, 여러 프로세서가 같은 task를 다른 data에 대해 수행하는 것을 말합니다. Data parallelism의 쉬운 예를 살펴보죠.
for i in range(3):
a[i] += b[i]
이 루프는 같은 덧셈(task)을 스텝 i에 따라 배열의 다른 부분(data)에 수행하고 있습니다. 각 스텝 i가 서로 의존성(dependence)이 없기 때문에 어떤 순서로 실행해도 상관이 없습니다. 동시에 실행할 수도 있죠.
thread[0]: a[0] += b[0]
thread[1]: a[1] += b[1]
thread[2]: a[2] += b[2]
Data parallelism의 특징은 요구되는 계산량(data)이 증가함에 따라 병렬성도 그에 따라 증가하는 경우가 많다는 것입니다. 예를 들어 위 루프에서 다루는 데이터의 크기가 3에서 3000으로 1000배 증가한다면, 병렬성도 1000배 증가하게 됩니다. 하드웨어만 받쳐준다면 thread를 3개에서 3000개로 1000배 증가시킬 수 있죠. 때문에 data parallelism은 확장성(scalability)이 좋습니다. (이러한 방식을 weak scaling이라고 함) 또, 계산 순서에서 상대적으로 자유롭기 때문에 동기화에 따른 성능 저하도 적습니다.
계산 자원이 많이 필요한 수치해석, 시뮬레이션, 그래픽스, 그리고 딥러닝 도메인에는 data parallelism을 활용할 수 있는 여지가 굉장히 많습니다. 단순한 계산을 굉장히 많이 반복하는 패턴이기 때문이지요. 그런 data parallelism을 잘 활용하는 프로세서가 바로 GPU입니다.
GPU는 동시에 똑같은 연산을 수행하는 코어가 수천 개씩 들어있는 구조로, 각 코어에 데이터의 다른 부분(data)을 할당하여 병렬로 처리할 수 있습니다. 1대 GPU에서 활용할 수 있는 것보다 문제의 data parallelism이 더 많다면 여러 GPU에 작업을 나누어주면 됩니다. 각 GPU가 다른 샘플에 대해 같은 파라미터를 가지고 같은 방식으로 학습시키는 것이니 일종의 data parallelism으로 볼 수 있겠죠. 이렇게 하면 코드 변경이 크게 필요 없고, 배치의 크기와 GPU를 선형적으로 늘려주면 됩니다.
지난 2017년, Facebook에서는 대규모 분산 학습에서 배치의 크기와 learning rate 사이의 관계에 대한 연구 논문을 arxiv에 업로드하였습니다. 논문에서는 매 스텝마다 ImageNet 데이터셋에서 총 8192개의 샘플을 뽑아 256개의 Tesla P100 GPU에 각 32개씩 나누어주어 ResNet-50 모델을 단 1시간만에 학습할 수 있었다고 보고하였습니다. 이렇게 분산 학습하여 AllReduce한 결과가 1개 GPU 기준으로 32개 샘플을 가지고 학습하는 스텝을 256번 반복하여 누적시킨 결과와 거의 비슷하기 때문에 이런 방식의 확장이 가능했습니다.
당시에 NVIDIA Tesla P100 GPU와 50G Ethernet 네트워크로 이 정도의 결과를 얻었는데요, 다음 세대 라인업 하드웨어인 NVIDIA V100 GPU와 100G Ethernet 네트워크를 이용한다면 수 분만에 학습이 가능합니다.
AllReduce
딥러닝 학습은 매 스텝마다 그라디언트(gradient)를 계산해서 모델의 파라미터(parameter)를 반복적으로 업데이트하는 과정입니다. Data parallel하게 진행되는 분산 학습에서는 여러 GPU에서 동일한 모델 파라미터와 다른 입력을 가지고 서로 다른 그라디언트를 계산하고, 이를 다 더한 값을 가지고 각자의 모델 파라미터를 똑같이 업데이트하게 됩니다. 이를 AllReduce 통신 패턴이라고 합니다.
가장 간단하게 AllReduce를 구현하는 방법은 다음과 같습니다.
def AllReduce(id, data_send: List[T]) -> List[T]:
data_recv = []
# 1. 각 GPU에서 계산된 그라디언트(data_send)를 모두 한 GPU에 모은다.
Gather(from=id, to=0, src=data_send, dst=data_recv) # blocking
# 2. 한 GPU에 모인 그라디언트(data_recv)를 합산한다.
data_send = sum(data_recv) if id == 0
# 3. 합산된 그라디언트(data_send)를 모든 GPU로 보내준다.
Broadcast(from=0, to=id, src=data_send, dst=data_recv) # blocking
return data_recv
그렇지만 이 방식은 모든 GPU와 한 GPU 사이의 통신이 이루어져야 하기 때문에, 데이터가 몰리는 GPU 쪽 트래픽에서 병목이 발생합니다. 메모리 사용량도 너무 많아 OOM 에러가 발생하기 쉽습니다. 보통은 좀 더 효율적으로 통신하는 알고리즘을 이용하는데, 가장 잘 알려진 방식은 Ring-AllReduce입니다.
def RingAllReduce(id, data: List[T]) -> List[T]:
# 1. (GPU 개수 - 1)만큼 반복한다.
for n in range(N-1):
# 1.1. 합산할 데이터 일부를 다음 GPU로 보내준다.
Send(to=(id+1), src=data[id-n]) # nonblocking
# 1.2. 이전 GPU에서 보내준 데이터를 받는다.
Receive(from=(id-1), dst=data[id-n]) # blocking
# 1.3. 받은 데이터를 보낼 데이터에 합산한다.
data[id-1-n] += data[id-n]
# 2. (GPU 개수 - 1)만큼 반복한다.
for n in range(N-1):
# 2.1. 합산된 데이터 일부를 다음 GPU로 보내준다.
Send(to=(id+1), src=data[id+1-n]) # nonblocking
# 2.2 이전 GPU에서 보내준 데이터를 받는다.
Receive(from=(id-1), dst=data[id-n]) # blocking
return data
Ring-AllReduce 알고리즘을 이용하면 모든 GPU가 고르게 데이터를 주고 받기 때문에 트래픽 병목이 발생하지 않고, 하드웨어의 양방향 통신 기능을 이용하여 주고 받는 과정을 동시에 처리하도록 최적화할 수 있습니다.
공간의 제약 극복하기 : GPT-3
Task parallelism
Task parallelism은 data parallelism과 다른 방향의 병렬성으로, 여러 프로세서가 다른 task를 같은 data 또는 다른 data에 대해 수행하는 것을 말합니다. Task parallelism의 쉬운 예를 살펴보죠.
for i in range(3):
b[i] = f(a[i]) # thread-unsafe function f()
c[i] = g(b[i]) # thread-unsafe function g()
이 루프는 같은 배열(data)을 이용하여 다른 계산(task)을 차례로 수행하고 있습니다. Pipelining 패턴으로 병렬화할 수 있는 대표적인 예시입니다.
thread[0]: b[0] = f(a[0]) | b[1] = f(a[1]) | b[2] = f(b[2]) |
thread[1]: | c[0] = g(b[0]) | c[1] = g(b[1]) | c[2] = g(b[2])
Task parallelism의 특징은 계산의 양(data)이 아니라 프로그램 특성(task)에 따라 병렬성이 결정된다는 점입니다. 예를 들어 위 루프에서 다루는 데이터의 크기를 3에서 3000으로 늘리더라도 동시에 연산할 수 있는 thread의 수는 2개가 한계입니다. 각 스텝(f(), g())이 서로 의존성이 있기 때문입니다. 이와 같은 의존성에 의해 동기화 오버헤드(|)가 발생하고, 확장성 역시 프로그램 특성에 의해 제한됩니다.
Model parallelism
모든 병렬 처리 패턴은 data parallelism과 task parallelism의 조합입니다. GPU 레이어를 쪼개고 이에 대응하는 모델 파라미터를 여러 GPU로 나누는 패턴인 model parallelism도 그 중 하나입니다.
Model parallelism이란:
- 각 디바이스에 ML 모델 학습에 필요한 연산(task)을 쪼개어 할당하고
- 그에 따라 파라미터(data)도 나누어 할당한 후
- 같은 입력(data)에 대해 연산의 다른 부분(task)을 처리하고
- 각 결과를 합산(reduction/concat)하여 출력(data)을 만드는 병렬화 방식입니다.
행렬 곱셈(@) 예제로 model parallelism과 다른 parallelism의 차이점에 대해 살펴봅시다.
y[0:3][0:3] = x[0:3][0:3] @ w[0:3][0:3]
위 식에서 x는 입력, w는 파라미터, y는 출력을 나타냅니다. 행렬 곱셈 연산(task)은 특성 상 더 작은 행렬 곱셈으로 쪼갤 수 있고, 그에 따라 입력(data_1)이나 파라미터(data_2)를 각 thread에 나누어줄 수 있습니다.
Data parallelism 관점에서 보면 행렬 곱셈에서 주된 data는 “입력”에 해당하는 x입니다. x의 row를 각 thread에 분배하면 thread는 동일한 “모델” w를 이용하여 같은 연산(task)을 진행하여 y의 각 row를 얻을 수 있습니다. (행렬이 row-major로 저장되어 있다고 가정하면) 데이터를 나누고 합치는 과정이 아주 자연스럽습니다. 하지만 w를 모든 thread에서 온전히 갖고 있어야 하기 때문에, 모델의 크기가 한 thread가 감당할 수 없을만큼 커지면 순수 data parallelism만으로는 병렬화가 불가능하게 됩니다.
# row-wise
thread[0]: y[0][0:3] = x[0][0:3] @ w[0:3][0:3]
thread[1]: y[1][0:3] = x[1][0:3] @ w[0:3][0:3]
thread[2]: y[2][0:3] = x[2][0:3] @ w[0:3][0:3]
thread[3]: y[3][0:3] = x[3][0:3] @ w[0:3][0:3]
Model parallelism 관점에서 보면 행렬 곱셈에서 주된 data는 “모델”에 해당하는 w입니다. w의 column을 각 thread에 분배하면 thread는 동일한 “입력” x를 이용하여 다른 연산(task)을 진행하여 y의 각 column을 얻을 수 있습니다. (행렬이 row-major로 저장되어 있다고 가정하면) 결과를 합치는 과정에서 메모리 이동이 많이 일어나게 됩니다. 대신 w를 모든 thread에서 온전히 갖고 있을 필요가 없습니다.
# column-wise
thread[0]: y[0:3][0] = x[0:3][0:3] @ w[0:3][0]
thread[1]: y[0:3][1] = x[0:3][0:3] @ w[0:3][1]
thread[2]: y[0:3][2] = x[0:3][0:3] @ w[0:3][2]
thread[3]: y[0:3][3] = x[0:3][0:3] @ w[0:3][2]
Model parallelism을 활용하는 병렬화 방식은 모델의 크기가 커지면 그에 따라 병렬성이 커지기 때문에 (더 많은 디바이스에 나누어줄 수 있음) data parallelism의 측면이 있고, 처리하는 데이터가 많아지더라도 병렬성이 변함없기 때문에 (모든 디바이스에 같은 입력을 전달해주어야 함) task parallelism의 측면도 있는 것이죠.
배치 데이터를 크게 하여 data parallelism을 활용할 수 있다면 굳이 확장성이 나쁜 model parallelism을 쓸 이유가 없다고 생각할 수도 있지만, 파라미터가 엄청나게 많은 모델은 model parallelism을 이용해야 파라미터를 GPU 메모리에 들어갈 정도로 나눌 수 있다는 점에서 활용처가 다르다고 할 수 있겠네요.
Transformer 아키텍쳐가 발표된 이후, 신경망을 이용한 language model은 transformer의 크기를 계속해서 키우는 방향으로 발전해왔습니다. 현재까지 공개된 language model 중 가장 강력한 GPT-3는 파라미터의 수가 무려 1746억개입니다. (논문에서 추산한) 학습에 필요한 총 계산량은 314000000 PFLOP이며, 이는 DGX-A100 한 대의 학습 이론 성능(5 PFLOPS)을 100% 발휘해도 2년이 걸리는 수준입니다.
미리 학습된 GPT-3 모델로 추론만 하려고 해도 350GB 이상 메모리가 필요하며. 학습을 위해서는 이것보다 몇 배 더 많은 메모리가 필요합니다. 하지만 GPU 메모리 용량은 많아야 10~40GB 정도이기 때문에 model parallelism을 활용하여 여러 GPU에 모델을 쪼개 넣게 됩니다. 또한 대량의 데이터를 학습하기 위해서 data parallelism도 함께 활용하게 됩니다.
GPT-3의 학습을 위해 Microsoft Azure에서 OpenAI에 계산용 GPU 10000대를 서버 당 400Gbps 고속 네트워크로 연결한 슈퍼 컴퓨터를 제공했다고 하는데요, 정말 어마어마하군요.
클러스터 해부학
딥러닝 클러스터는 학습 과정을 빠르게 하는 것을 최우선 목표로 삼아 설계됩니다. 그렇기에 시스템의 어느 한 부분에서 병목이 발생하지 않도록 최상단 소프트웨어부터 최하단 하드웨어까지 모든 단계를 함께 고려해야 합니다.
이 포스트에서 자세히 다루지는 않지만, 클러스터를 구축할 때는 이와 더불어 전력 공급이나 냉각까지 신경써주어야 합니다. 느려지거나 멈추거든요.
GPU 서버 성능 지표 알아보기
-
FLOPS
GPU가 1초 동안 몇 개의 부동소수점(floating-point) 연산을 할 수 있는 지를 나타내는 성능 척도입니다. FLOPS가 크면 같은 시간 동안 더 많은 계산을 처리할 수 있으니 성능이 좋다는 뜻이겠죠.
1000000 FLOPS = 1 GFLOPS,1000 GFLOPS = 1 TFLOPS,1000 TFLOPS = 1 PFLOPS입니다.GPU의 구조를 쉽게 설명하자면 단순한 부동소수점 연산을 처리하는 코어가 수천 개 있어서 동시에 많은 수의 연산을 처리하는 형태입니다. 그렇기 때문에 GPU는 코어가 기껏해야 수십 개인 CPU보다 FLOPS가 훨씬 높습니다. 그래서 GPU는 그래픽스, 시뮬레이션, 딥러닝 등 독립적인 연산이 아주 많은 애플리케이션 가속에 널리 이용됩니다.
부동 소수점 연산의 정밀도(precision)에 따라 기준이 되는 FLOPS 값이 달라질 수 있습니다. 계산용 GPU에서는 보통 FP32(=SP) 성능이 FP64(=DP) 성능의 2배 정도, FP16(=HP) 성능은 FP32(=SP) 성능의 2배 이상이 됩니다. 성능이 높아지는 대신 정밀도가 떨어지기는 하지만, 과학 분야의 애플리케이션이 아니라면 높은 정밀도를 필요로 하지는 않습니다. 특히 추론 단계에서는 FP16으로도 충분합니다. 최근에는 딥러닝 학습에서 FP16 정밀도를 사용하는 경우도 많습니다.
-
GPU Memory
FLOPS만큼 중요한 성능 척도가 있으니 바로 메모리 용량(capacity)과 대역폭(bandwidth)입니다.
메모리 용량은 GPU가 처리할 수 있는 배치의 크기나 모델의 크기와 관련이 있습니다.
- 배치의 크기: 메모리가 크면 한 GPU에서 더 많은 배치를 처리할 수 있으므로, data parallelism 활용도를 늘려 같은 데이터셋을 더 빠르게 학습할 수 있습니다.
- 모델의 크기: GPU는 연산을 위해 모델의 파라미터를 메모리에 담아두기 때문에 이를 위한 메모리 용량이 충분해야 합니다. Model parallelism으로 여러 GPU에 파라미터를 나누는 데는 제약 사항도 많고 동기화/통신 비용이 증가하기 때문에 한계가 있습니다.
GPU의 메모리 용량 뿐만 아니라 시스템 메모리 용량도 어느 정도 확보해야 합니다. 결국 배치나 모델이 시스템 메모리에서 각 GPU로 전송되는 것이기 때문에, 시스템 메모리가 모든 GPU의 메모리를 합한 것보다는 커야 병목이 되지 않습니다.
메모리 대역폭은 GPU가 메모리를 읽고 쓰는 속도와 관련이 있습니다. 대역폭이 크다고 해서 메모리 접근 속도가 반드시 빨라지는 것은 아니지만, GPU는 넓은 메모리 영역을 동시에 읽고 쓰기 때문에 대역폭이 클수록 메모리 접근에 소요되는 총 시간이 감소하는 것이 보통입니다.
FLOPS와 메모리 대역폭은 프로그램 성능의 상한을 결정합니다.
- Activation, Pooling, Normalization 같이 메모리 접근 횟수 대비 연산 비중이 거의 없는 레이어는 보통 memory-bound라고 합니다. memory-bound는 대역폭에 의해 성능 상한이 결정됩니다.
- Convolution, Dense 같이 메모리 접근 횟수 대비 연산 비중이 큰 레이어는 보통 compute-bound라고 합니다. compute-bound는 FLOPS에 의해 성능 상한이 결정됩니다.
주어진 시스템에서 memory-bound와 compute-bound를 나누는 기준은 FLOPS에 의한 이론 성능 상한과 대역폭에 의한 이론 성능 상한이 맞물리는 지점입니다. 그보다 메모리 접근 대비 연산 수가 많으면 compute-bound, 연산 수가 적으면 memory-bound가 되는 것이죠. CPU에서 실행할 때는 compute-bound였던 프로그램이 GPU에서는 memory-bound가 될 수도 있습니다.
-
Interconnect
CPU가 관리하는 시스템 메모리와 GPU에 장착된 메모리는 물리적으로 분리되어 있습니다. 파일로 저장된 데이터셋을 GPU에서 학습하기 위해서는 시스템 메모리에 있는 배치를 GPU 메모리로 전송하는 과정을 거쳐야 합니다. 학습된 모델 파라미터를 저장하기 위해서는 거꾸로 GPU 메모리에서 시스템 메모리로 전송하는 과정이 필요합니다.
다른 GPU에 할당된 배치에서 계산된 그라디언트를 합치는 경우, Model parallelism을 활용하여 모델을 쪼갠 경우 등 서로 다른 GPU 간에 데이터를 주고받아야 할 때도 서로의 메모리로 데이터를 전송하게 됩니다.
이렇게 데이터를 주고 받을 때 사용되는 대표적인 인터페이스로 PCI Express(PCIe)가 있습니다. PCIe는 여러 개의 lane으로 구성되어 있는데, 현재 표준으로 사용되는 PCIe 3.0 버전은 lane 당 (x1) 약 1GB/s의 대역폭으로, 최신 CPU/마더보드에서 지원하는 PCIe 4.0 버전은 그 두 배인 lane 당 (x1) 약 2GB/s의 대역폭으로 양방향 통신이 가능합니다.
보통 GPU는 16 lane 너비(x16)를 지원하므로 PCIe 3.0 기준 약 15.75GB/s의 대역폭으로 양방향 통신이 가능합니다. 하지만 CPU에서 지원하는 PCIe lane 수가 부족하면 일부 GPU는 x16으로 동작하지 못하고 x8로 동작하는 경우가 생깁니다.
서버급 Intel CPU에서는 소켓 당 48 lane를 지원합니다. 이는 일반적인 2소켓 구성 상 48 * 2 = 96 lane을 사용할 수 있어 GPU와 고속 네트워크 카드(HCA)를 합쳐 최대 6개까지만 제 성능으로 지원할 수 있습니다. 반면 서버급 최신 AMD CPU에서는 소켓 당 96 lane까지도 지원하므로, 훨씬 큰 대역폭을 운용할 수 있습니다. NVIDIA의 고성능 서버 라인업인 DGX가 Intel에서 AMD로 변경된 이유이기도 하죠.
NVIDIA에서는 PCIe와 별도로 NVIDIA GPU 간 고속 통신를 위해 NVLink 기술을 제공합니다. 예를 들어 NVLink 2세대(e.g. V100)에서는 150GB/s의 대역폭, NVLink 3세대(e.g. A100)에서는 300GB/s의 대역폭으로 각각 PCIe 3.0, PCIe 4.0보다 9배 가량 넓은 대역폭으로 통신할 수 있습니다. PCIe로는 병목이 걸리는 규모의 데이터 전송도 NVLink를 이용하게 되면 문제가 없습니다. 하지만 범용 인터페이스인 PCIe와는 달리 지원을 해주는 일부 메인보드에서만 사용이 가능하며, GPU에 따라서는 별매품 NVLink 브릿지를 설치해야하는 경우도 있습니다.
서버를 연결하는 기술 알아보기
GPU가 다른 GPU에 있는 메모리에 접근해야 하는 경우가 있습니다. 한 서버에 장착된 GPU라면 PCIe 또는 NVLink를 통해 통신할 수 있죠. 하지만 딥러닝 클러스터에서는 다른 서버에 장착된 GPU 간에 데이터 통신이 필요합니다. 그래서 모든 서버를 연결하는 고속 인터커넥트 네트워크가 필요합니다.
고속 인터커넥트 네트워크를 구성하려면 우선 각 서버에 고속 네트워크 카드인 HCA(Host Channel Adapter)가 설치되어 있어야 합니다. HCA는 서버의 메모리 서브시스템과는 PCIe로, 다른 서버의 HCA와는 고속 네트워크 스위치와 특수 케이블을 통해 연결되어 있습니다. 그리고 스위치는 또 다른 스위치들과 연결되어 클러스터의 내부망을 구성합니다.
-
RDMA
수많은 서버들이 데이터를 교환할 때마다 CPU, 캐시, OS 페이지를 거치게 되면 엄청난 병목이 발생합니다. GPU 사이에 발생하는 모든 I/O마다 OS와 메모리 서브시스템이 동기화되어야 하기 때문에 그 과정에서 많은 비효율이 발생할 수밖에 없는 것이죠.
이를 방지하기 위해 데이터를 주고받을 디바이스와 메모리 서브시스템만 관여해서 CPU 자원을 낭비하는 일 없이 데이터를 주고받는 기술을 DMA(Direct Memory Access)라고 합니다. 디스크에 저장된 파일을 시스템 메모리로 올리는 동안 CPU는 다른 작업을 수행할 수 있도록 하는 기술, 시스템 메모리를 거치지 않고 GPU와 GPU가 PCIe를 통해 직접 통신하는 기술 등이 DMA에 포함됩니다.
디바이스의 데이터를 OS 간섭 없이 곧바로 HCA를 통해 다른 서버로 보내거나 반대로 HCA를 통해 받은 데이터를 곧바로 디바이스로 보내는 것을 RDMA(Remote Direct Memory Access)라고 합니다. DMA가 한 서버 내의 디바이스 간의 메모리 접근에 관한 기술이라면, RDMA는 서로 다른 서버에 있는 디바이스 간의 메모리 접근에 관한 기술이라고 볼 수 있습니다.
RDMA를 실현하는 대표적인 기술로는 Mellanox의 Infiniband가 있고, 범용으로 사용되는 Ethernet 프로토콜을 이용한 RoCE(RDMA over Converged Ethernet)도 있습니다.
-
Nonblocking Minimal Spanning Switch
네트워크를 구성하는 각 스위치에 연결된 uplink의 수와 downlink의 수가 1:1로 동일하여 항상 두 디바이스 사이에 통신이 일어날 수 있으면서, 네트워크를 구성하는 스위치의 개수가 최소일 때를 nonblocking minimal spanning switch 구조라고 합니다.
만일 nonblocking 구성이 아니게 되면 모든 디바이스가 다른 디바이스와 통신하는 collective communication 패턴에서 항상 병목이 걸리게 됩니다. 분산 학습에서 일어나는 대부분의 통신 패턴인
AllReduce또는AllGather연산이 모두 collective communication이기 때문에 여기서 병목이 걸린다면 매 스텝마다 성능 저하가 일어나니, 결국 전체 성능에 크게 영향을 주겠죠.스위치 연결 토폴로지는 장단점이 다른 여러 가지 방식이 있고 모니터링 장비 등도 연결되어야 하기 때문에 꼭 최소의 스위치를 사용해야 하는 것은 아니지만, 서버의 HCA들이 all-to-all로 1:1 nonblocking 통신을 할 수 있도록 구성하는 것이 중요합니다.
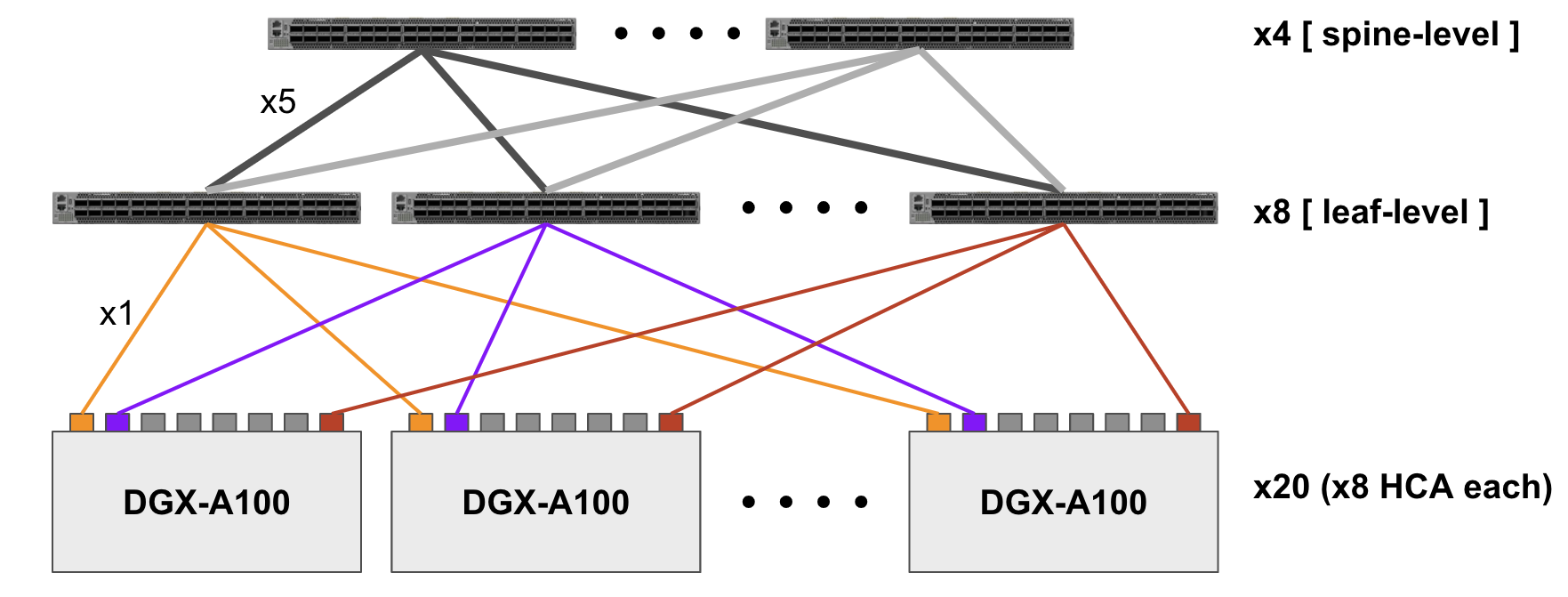
클러스터 구성
딥러닝 연구는 점점 더 많은 데이터, 더 많은 계산 자원을 요구하고 있습니다. 그리고 이를 위한 고성능 컴퓨팅 기술도 점점 고도화되어가고 있죠. 접근하기가 어렵습니다. 그래서 보통 ML 연구 팀은 클라우드 상에서 딥러닝 학습을 진행합니다. AWS나 GCP 등 클라우드 서비스에서 멀티노드 학습이 가능한 GPU 인스턴스를 제공해주는 덕분이죠. 게다가 클라우드를 이용하면 (이미 클라우드에 저장해두었던) 데이터를 사용하기 편리하고, 인프라 구축과 운영이 필요 없고, 수요에 따라 스케일링하기가 굉장히 쉽습니다.
하지만 장점이 있으면 단점도 있는 법이죠. 유동적으로 자원을 할당해주는 클라우드 인프라의 특성 상, 서버와 서버를 연결하는 고속 인터커넥트 네트워크를 최고성능으로 제공하기는 어렵습니다. 더 큰 language model을 더 많이 연구하기 위해서는 클라우드에서 제공해주는 인프라보다 최적화된 환경이 필요했습니다.
비용도 큰 문제입니다. 클라우드는 편리하지만 저렴하진 않습니다. 딥러닝 연구는 머니게임이 되어가고 있고, 이에 따라 클라우드 사용량이 늘면 지출하는 비용도 그에 비례하여 증가합니다. Hyperconnect AI Lab의 사용 패턴에 따르면 2021년에는 매월 지불하는 비용이 수억 원에 육박하는 것으로 추산되었습니다. 매달 최고사양 GPU 서버를 한 대씩 태우는 꼴이죠.
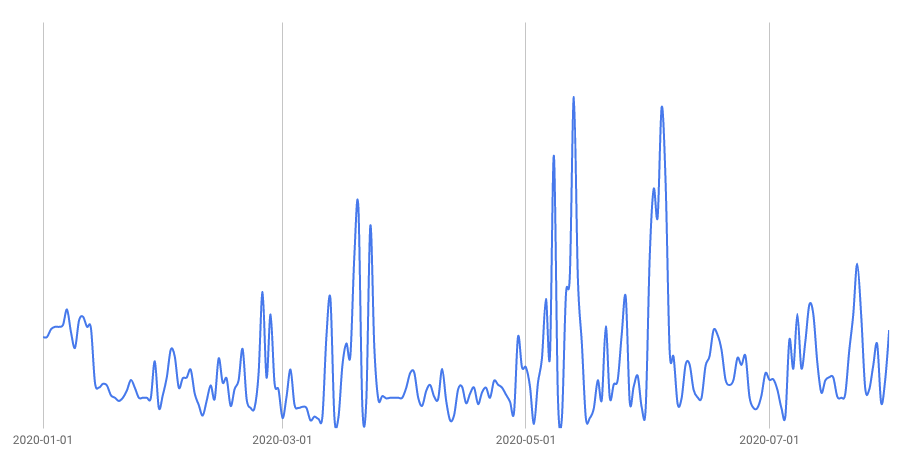
만일 여기서 새로운 프로젝트가 더해지거나, AI Lab의 규모가 두 배로 증가한다면 어떤 일이 일어날 지는 불보듯 뻔한 일이었습니다. 이에 초기 비용이 다소 크더라도 직접 클러스터를 구축하여 운영하는 것이 성능과 비용 모든 면에서 효율적이라고 판단, ML Platform 팀에서 나서서 직접 딥러닝 클러스터 구축을 진행하게 되었습니다.
NVIDIA에서는 앞서 살펴본 요구 사항을 모두 만족하는 GPU 클러스터 아키텍처인 SuperPod을 공개하였는데요, AI Lab에서는 이에 기반하여 DGX 시리즈의 최신 버전인 DGX-A100을 20대 묶어 연구용 클러스터를 구성하였습니다.
탑재된 A100 GPU는 총 160개로 새로 추가된 모드인 TF32 정밀도 기준 이론 성능은 25 PFLOPS입니다. 대략적으로 비교해보면 이는 국가슈퍼컴퓨팅센터(KISTI)의 최대 규모 CPU 클러스터 시스템인 슈퍼컴퓨터 5호기 ‘누리온’의 이론 성능 25.7 PFLOPS에 육박하며, 함께 운용하는 163개 GPU 클러스터 시스템인 ‘뉴론’의 성능 1.24PF의 20배에 달하는 수치입니다.
서버를 연결하기 위한 고속 인터커넥트 네트워크는 Mellanox Infiniband HDR로 케이블 당 200Gbps의 대역폭이며, DGX-A100 한 대에 8개의 HCA가 장착되어 있으니 서버마다 총 1.6Tbps의 대역폭으로 양방향 데이터 교환이 가능합니다. Infiniband 스위치는 14개를 리프-스파인의 2레벨로 구성하였습니다. 리프 레벨에서 스위치 i의 downlink 20개는 각 서버의 i번째 HCA와 연결, uplink 20개는 스파인 레벨의 모든 스위치에 고르게 연결되어 1:1 nonblocking로 통신하도록 했습니다.
그 외에 사용자가 접속하여 사용하는 로그인 서버, 관리용 서버, 성능 모니터링 시스템, 공유 스토리지 클러스터 등도 마찬가지로 Infiniband 네트워크로 묶어 관리합니다. 이를 바탕으로 환경 꼬임이나 연구자 간 충돌 없이, 분산 학습에서 계산 자원을 효율적으로 활용할 수 있도록 노력하고 있습니다.
마무리
이번 포스트는 여기까지입니다. 긴 글 읽어주셔서 고맙습니다.
다음 포스트에서는 딥러닝 클러스터를 완성하는 소프트웨어 스택과, AI Lab에서 직접 딥러닝 클러스터를 사용하면서 배운 경험을 공유해보고자 합니다.
References
- Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
- Big Basin
- Stanford DOWNBench: ImageNet Training
- Scaling Laws for Neural Language Models
- Megatron-LM
- Language Models are Few-Shot Learners
- DGX-A100
- NVIDIA Data Center Benchmark
- Roofline Performance Model
- PCI Express
- NVLink
- RDMA
- Nonblocking Minimal Spanning Switch
- NVIDIA SuperPod
- TF32 Precision
- KiSTi Gen5 Supercomputer System (NURION)