아자르에서는 어떤 추천 모델을 사용하고 있을까?
하이퍼커넥트 AI 조직은 사용자 경험을 향상시키고, 비즈니스 성과를 높이는 AI 기술을 꾸준히 개발해왔습니다. 이러한 노력의 성과는 2023년 2분기 매치 그룹 주주 서한과 어닝콜에서 발표되었습니다. 하이퍼커넥트의 대표 서비스인 아자르는 2022년 2분기 대비 24%(원화 기준 30%)의 매출 성장을 기록했습니다. 아래의 주주 서한에서 강조되었듯, 이 성과는 AI 기반 추천 시스템이 견인하였습니다. 이번 포스트에서는 아자르의 AI 추천 모델이 어떻게 설계되고 구현되었는지 자세히 살펴보겠습니다
 Match Group Earnings Letter, 2023 Q2, Page 8
Match Group Earnings Letter, 2023 Q2, Page 8
아자르는 1:1 비디오 채팅을 핵심 기능으로 하는 글로벌 커뮤니케이션 플랫폼입니다. 유저들은 스와이프 기능을 사용해 전 세계의 다른 유저들과 쉽게 연결될 수 있습니다. 아자르에서는 유저가 누구와 연결되는지가 채팅 경험에 큰 영향을 미치기 때문에, 매칭 알고리즘의 역할이 매우 중요합니다. AI 모델을 도입하기 전, 아자르는 유저의 행동 패턴을 분석하여 휴리스틱한(경험 기반) 규칙을 매칭에 활용했습니다. 아래는 이해를 돕기 위한 휴리스틱한 규칙의 예시입니다.
* 두 유저가 같은 언어를 사용하면 +10점
* 두 유저 모두 일본어를 사용하면 추가로 +15점
* 두 유저가 같은 나이대에 속하면 +25점
* 한 유저가 최근에 신고된 이력이 있으면 -10,000점
* 두 유저의 기기 언어 설정이 다르면 -∞점 (만나지 못함)
* 성별 필터를 사용하는 유저는 +1,000점
기존 아자르 추천 시스템은 유저의 행동 데이터를 기반으로 위와 같이 점수를 매긴 후, 그 점수가 높은 순서대로 유저를 매칭하는 방식이었습니다. 아자르에 AI 추천 알고리즘 도입을 처음 검토하던 당시, 기존의 휴리스틱 알고리즘을 위한 코드는 수십만 줄에 달할 정도로 매우 복잡했습니다. 하이퍼커넥트는 이 복잡한 휴리스틱 알고리즘을 AI 기반 추천 시스템으로 전환하는 작업을 진행했고, 그 결과 앞서 언급한 것과 같은 중요한 재무적 성과도 달성할 수 있었습니다.
AI 추천 알고리즘 도입의 중요성
AI 알고리즘을 추천 시스템에 도입하는 것은 비즈니스에 두 가지 중요한 이점을 제공합니다. 첫째, 휴리스틱 알고리즘은 시간이 지나면 성능이 떨어지는 지연 문제(staleness problem)를 겪습니다. 새로운 특성을 가진 유저들이 유입되면 기존 규칙이 이들에게 잘 작동하지 않아 지속적인 수정이 필요합니다. 이를 해결하려면 사람이 직접 데이터를 분석하고 새로운 규칙을 만들어야 하기 때문에 관리가 복잡하고 유지 비용이 증가합니다. 반면, AI 모델은 입력과 출력을 정의하고 지속적으로 학습하는 파이프라인(continuous training pipeline)을 구축하면 새로운 데이터에 계속 적응하며 일관된 성능을 유지할 수 있습니다. 이러한 시스템은 비록 초기 구축 비용이 들지만, 이후에는 관리가 용이해지고 유지 비용도 절감되며, 변화하는 유저 특성에 신속하게 반응해 지속적인 성능을 보장합니다.
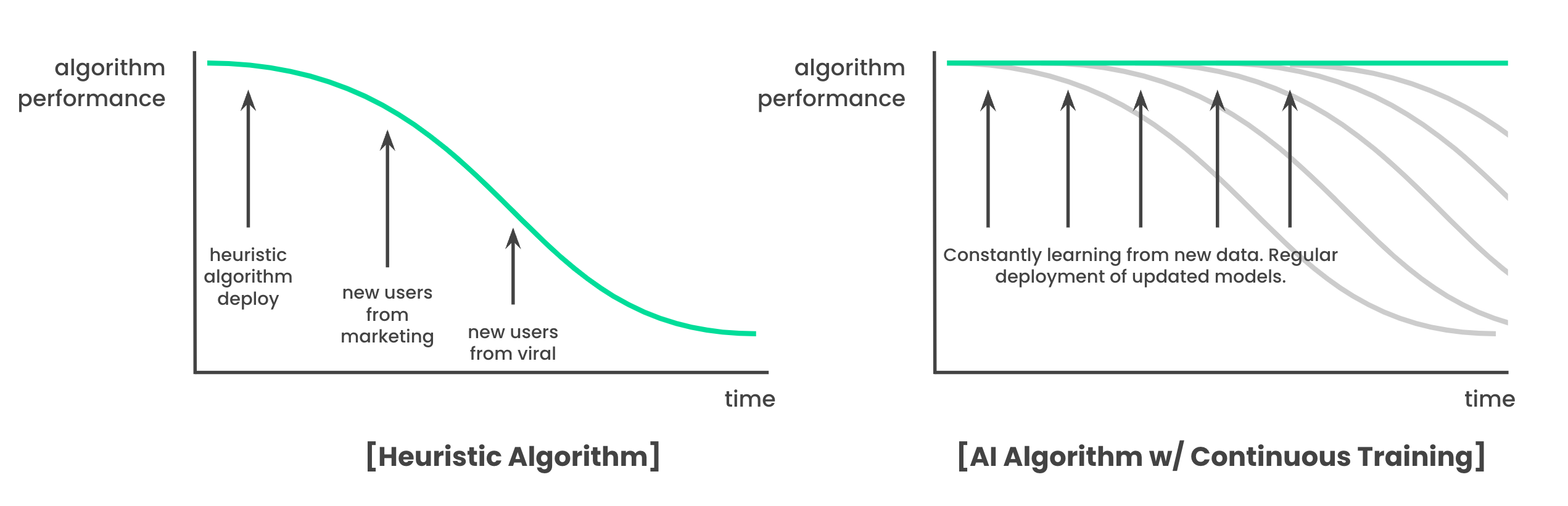
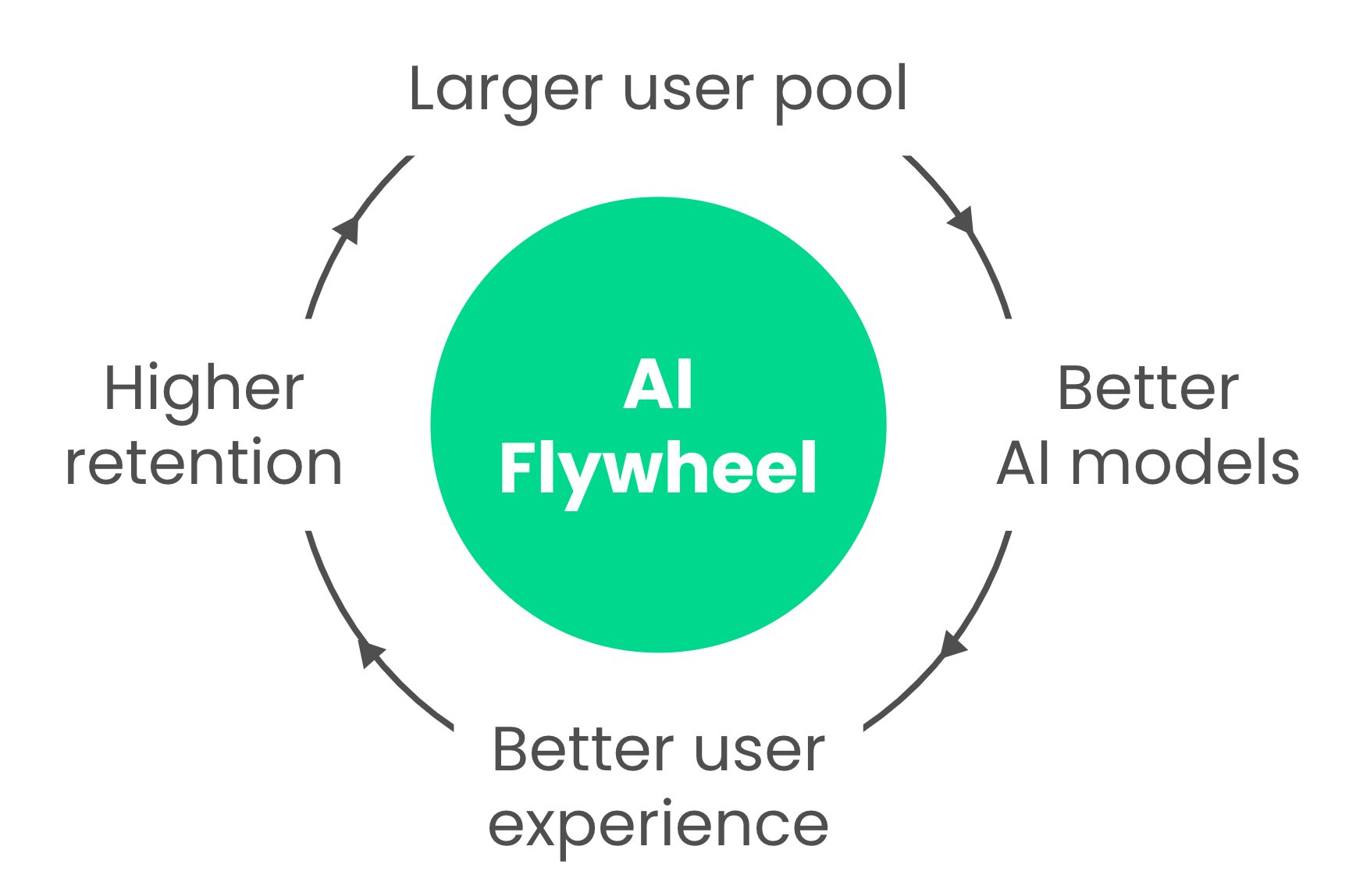
둘째, AI 추천 알고리즘은 경쟁 우위를 제공합니다. AI 기반 추천 시스템은 학습 데이터에 따라 휴리스틱보다 유저 경험을 크게 개선할 가능성이 높습니다. 유저 맞춤형 추천을 제공할 수 있기에 서비스 만족도가 높아지고, 이는 리텐션(재방문율) 증가로 이어집니다. 그 결과 전체 유저 수가 늘어나며 더 크고 다양한 유저 풀이 형성됩니다. 유저 풀이 커질수록 AI는 더 많은 데이터를 학습해 더욱 정확한 추천을 제공할 수 있고, 이는 유저 만족도와 리텐션을 다시 높이는 선순환을 만듭니다. 이러한 구조는 AI 추천 알고리즘의 경쟁 우위를 강화하며, 경쟁자가 이를 따라잡기 어렵게 만들어 비즈니스의 장기적인 성공에 기여합니다.
어떤 모델을 만들까?
아자르의 아하 모멘트를 찾는 지난 포스트에서 우리는 리텐션을 높이기 위해 어떤 경험을 제공해야 하는지 분석했습니다. 대화 시간, 신고 여부, 친구 신청 여부, 스와이프 여부 등 다양한 1차 지표를 종합하여, 결국 어떤 지표를 최적화해야 리텐션이 증가하는지 파악했습니다. 이렇게 도출된 1차 지표를 예측하는 모델을 만들고, 해당 지표를 최대화하는 방식으로 유저를 연결하면 됩니다. 이번 테크 블로그에서는 설명의 편의를 위해 대화 시간을 리텐션을 향상시키는 핵심 지표로 가정하겠습니다. 대화 시간을 예측하는 모델을 만들고, 그 시간을 최대화하는 방식으로 매칭을 진행하는 것이죠. 구체적으로는 유저를 노드(node)로 구성한 그래프를 만들고, 예측된 대화 시간을 엣지(edge) 가중치로 설정한 후, 이 가중치가 최대가 되도록 노드 쌍을 선택하면 됩니다.
이전 포스트에서 우리는 하이퍼커넥트의 추천 모델링의 방식과 그 이유를 설명한 바 있습니다. 해당 포스트에서는 유저에게 아이템을 추천하는 방식을 다뤘지만, 아자르의 경우는 아이템 대신 다른 유저, 즉 피어(peer)를 추천한다는 점만 다를 뿐, 기본적인 접근 방식은 동일합니다.
비용 효율적인 추천 알고리즘에 대해 다룬 이전 포스트에서 설명했듯이, \(f\)에 CatBoost를 사용하는 것은 일반적으로 좋은 선택입니다. CatBoost는 하이퍼파라미터에 민감하지 않으며, 다른 모델들보다 성능이 우수한 경우가 많기 때문입니다. 그러나 아자르 1:1 추천 시스템에서는 응답 속도, 즉 레이턴시 제약으로 인해 CatBoost를 사용할 수 없습니다. 1:1 비디오 채팅에서 짧은 응답 시간(레이턴시)은 매우 중요한데, 대기 시간이 길어지면 유저가 플랫폼에 다른 사용자가 없다고 느껴 이탈률이 증가할 수 있습니다. 안타깝게도 CatBoost는 모든 유저-피어 간 연산을 수행하기에는 매우 느립니다. CatBoost는 유저가 \(N\)명일 때 가능한 유저-피어 간 연산을 모두 수행해야 하므로 \(O(N^2)\)번의 추론이 필요합니다. 예를 들어 \(N\)이 1만 명일 경우 5천만 쌍에 대해 비용이 큰 CatBoost 추론을 수행해야 하는데요, 이처럼 많은 연산은 짧은 응답 시간을 요구하는 상황에서 적합하지 않습니다. 물론, 이런 많은 연산도 병렬로 처리하면 레이턴시 제약 조건을 만족시킬 수도 있지만 연산량 자체가 \(O(N^2)\)로 늘어나기에 유저가 늘어남에 따라 자원을 제곱배로 늘려주어야 하기에 확장성있는 설계가 아닙니다.
짧은 레이턴시 제약 조건에서의 모델링
대규모 데이터에서 빠른 연산을 처리하기 위한 다양한 기법들 중, 저희 시나리오에 가장 적합한 방법은 뉴럴 네트워크 기반의 투 타워 아키텍처(two-tower architecture)였습니다. 이 모델의 접근 방법을 도식화하면 아래와 같습니다.
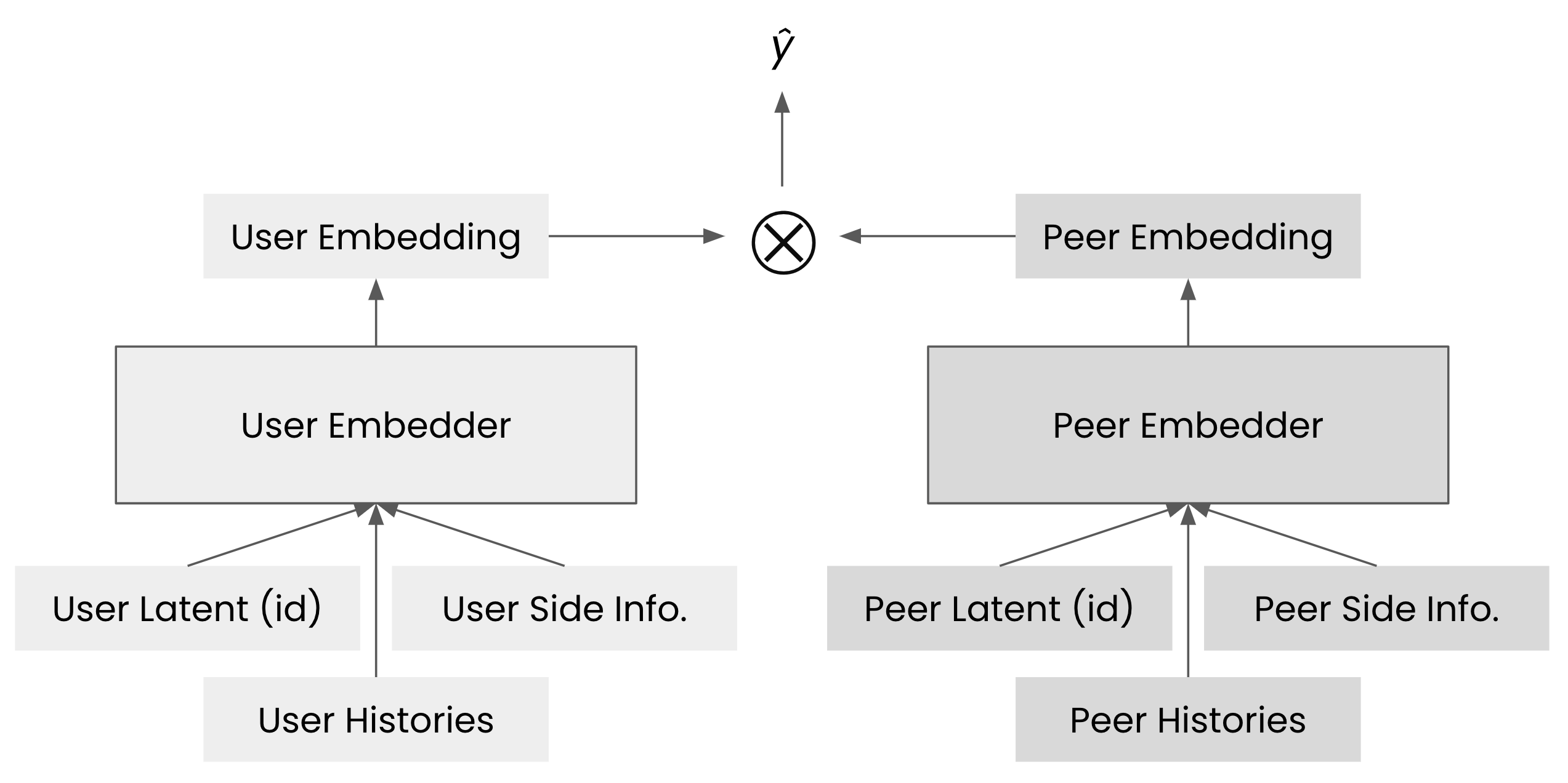 two tower architecture 개요
two tower architecture 개요
이 구조를 간단히 설명하면, 유저 임베딩 벡터와 피어 임베딩 벡터를 각각 생성한 뒤, 두 벡터를 내적하여 최종 결과물인 \(\hat{y}\)를 계산합니다. 이러한 방식으로 두 개의 타워처럼 독립적인 경로를 통해 결과를 도출하기 때문에 ‘투 타워 아키텍처’라 불립니다.
이 방법이 빠른 이유는 다음과 같습니다. 기존 방식에서는 값비싼 전체 연산을 \(O(N^2)\)번 수행해야 했지만, 이렇게 투 타워 아키텍처를 사용하면 임베더와 같은 비싼 연산은 \(O(N)\)번만 하면 되고 내적과 같은 간단한 연산만 \(O(N^2)\)번 수행하면 됩니다. 예를 들어, 유저 \(i\)에 대한 임베딩 벡터 \(e_i\)를 \(i\)번째 열로 하는 행렬 \(E\)를 만들면 \(E^TE\in \mathbb{R}^{N \times N}\) 연산으로 모든 유저 쌍의 예측 대화 시간 행렬을 얻을 수 있습니다. 행렬 곱셈은 여러 상용 라이브러리 등을 통해 빠르게 계산할 수 있으므로 투 타워 아키텍처는 전체 연산을 빠르게 수행할 수 있습니다.
실제 구현에서는 속도와 비용 효율성을 모두 고려해 최적화를 추가로 적용합니다. 예를 들어, 단순한 행렬 곱셈은 BLAS 라이브러리 등을 사용하여 CPU에서 처리하고, 유저 임베딩을 생성하는 고비용 연산은 NPU나 GPU를 활용하여 처리합니다. 또한, 여러 요청을 한 번에 처리하는 배칭(batching)을 통해 처리량을 높이고 비용을 절감할 수 있습니다.
임베더(embedder)로는 어떤 모델을 사용할까?
우리는 임베더를 위한 다양한 모델 구조를 검토했습니다. Wide&Deep(Cheng et al., 2016), FM(Rendle 2010), FFM(Juan et al., 2016), DeepFM(Guo et al., 2017), NCF(He et al., 2017) 등 수십 개의 모델을 재현(reproduce)하여 아자르 데이터셋으로 오프라인 테스트를 진행한 결과, Wide&Deep 모델이 가장 뛰어난 성능을 보였습니다. 하지만 이 모델은 기존 유저의 대화 시간 예측에는 우수했지만, 신규 유저에 대해서는 상대적으로 낮은 예측력을 보여주었습니다. 이는 신규 유저의 데이터가 부족하기 때문에 다른 모델에서도 공통적으로 나타나는 자연스러운 현상입니다. 그러나 기존 유저는 이미 플랫폼에 익숙하고 일정 수준의 만족도를 유지하는 경우가 많아 리텐션을 크게 높일 여지가 적은 반면, 신규 유저는 처음 접속했을 때의 경험에 따라 리텐션이 크게 달라질 수 있기 때문에 신규 유저에 대한 더 높은 예측력을 만들어내기 위한 다른 방법이 필요했습니다.
우리는 문헌 조사를 통해 다양한 접근 방식을 탐구했습니다. 그래프 신경망(graph neural networks)기반 추천 방법들과 세션 기반 추천(session-based recommendation) 방법들을 포함해 다양한 방법론들을 검토한 결과, 세션 기반 추천이 현재 업계에서 사실상의 표준으로 자리 잡았다는 점을 확인했습니다. 우리는 세션 기반 추천 방법을 사용해 신규 유저에게 더 나은 경험을 제공하기로 결정했습니다.
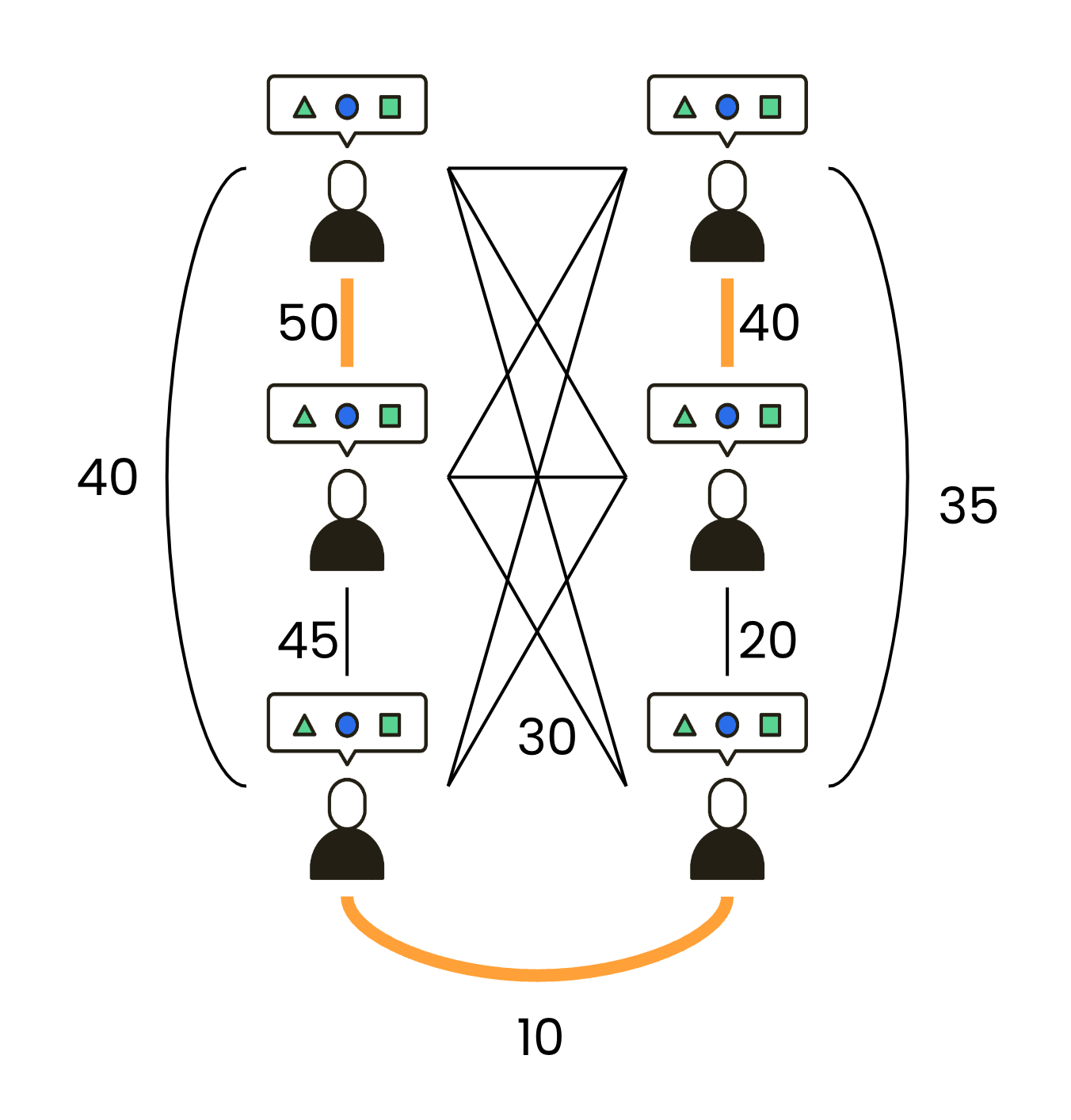
세션은 유저가 플랫폼에 접속한 후부터 종료할 때까지의 일련의 행동을 의미하며, 세션 기반 추천 시스템은 이 세션 내 정보를 바탕으로 맞춤형 추천을 제공하는 방식입니다. 이 방식은 유저의 행동이나 선호도를 즉각적으로 반영하기 때문에, 데이터가 부족한 신규 유저에게도 빠르게 맞춤형 추천을 할 수 있습니다. 예를 들어, 아래 그림에서 Alice가 반지에 관심을 보인 후 털모자에 관심을 보였다면, 세션 기반 추천은 그녀가 이후에 어떤 아이템에 가장 관심을 가질지를 예측합니다. Alice가 털모자 이후 귀마개에 관심을 보였다면, 그 새로운 정보를 바탕으로 다음 관심사를 추론하는 것이 세션 기반 추천의 핵심입니다.
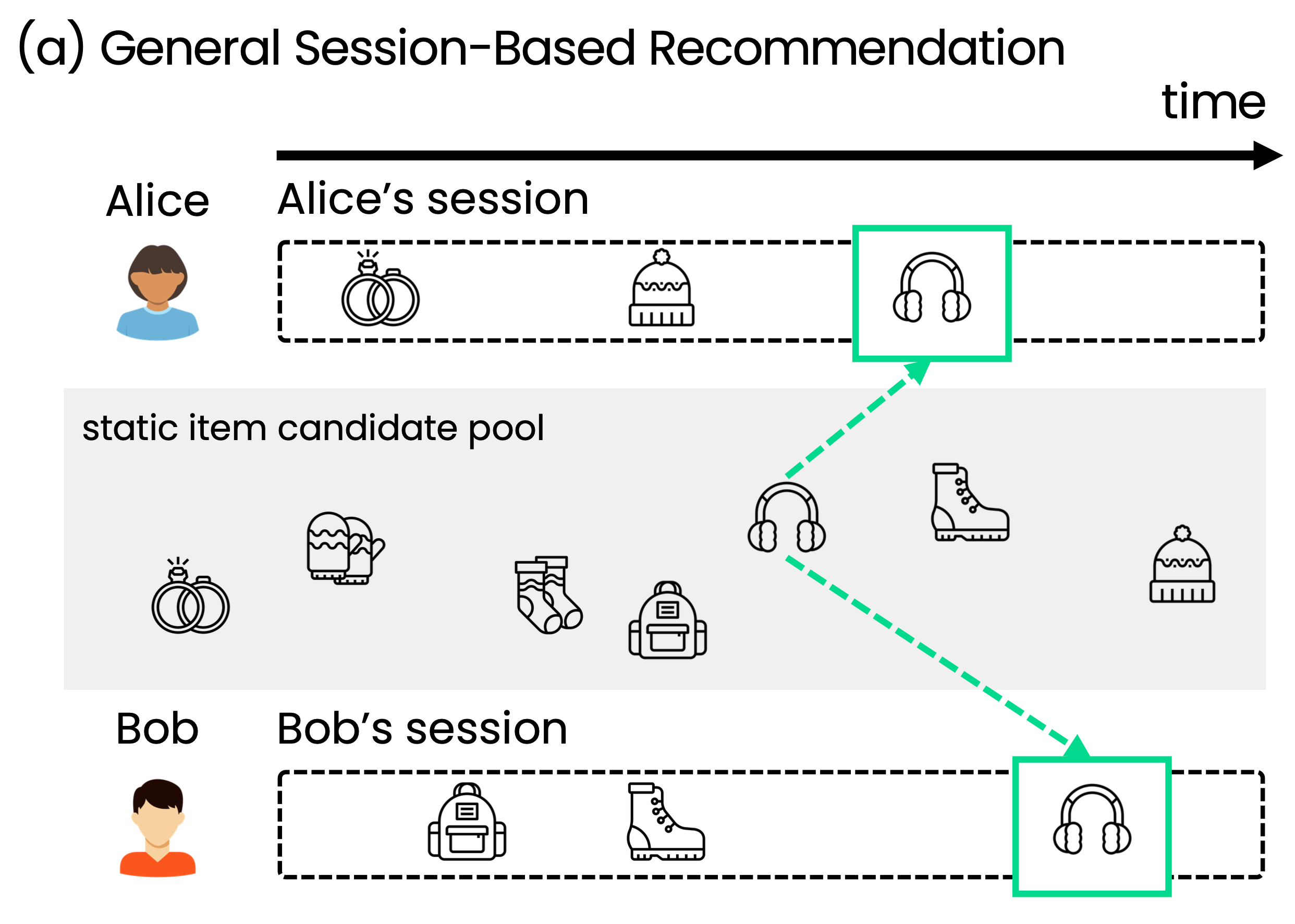 session 기반 추천의 예시
session 기반 추천의 예시
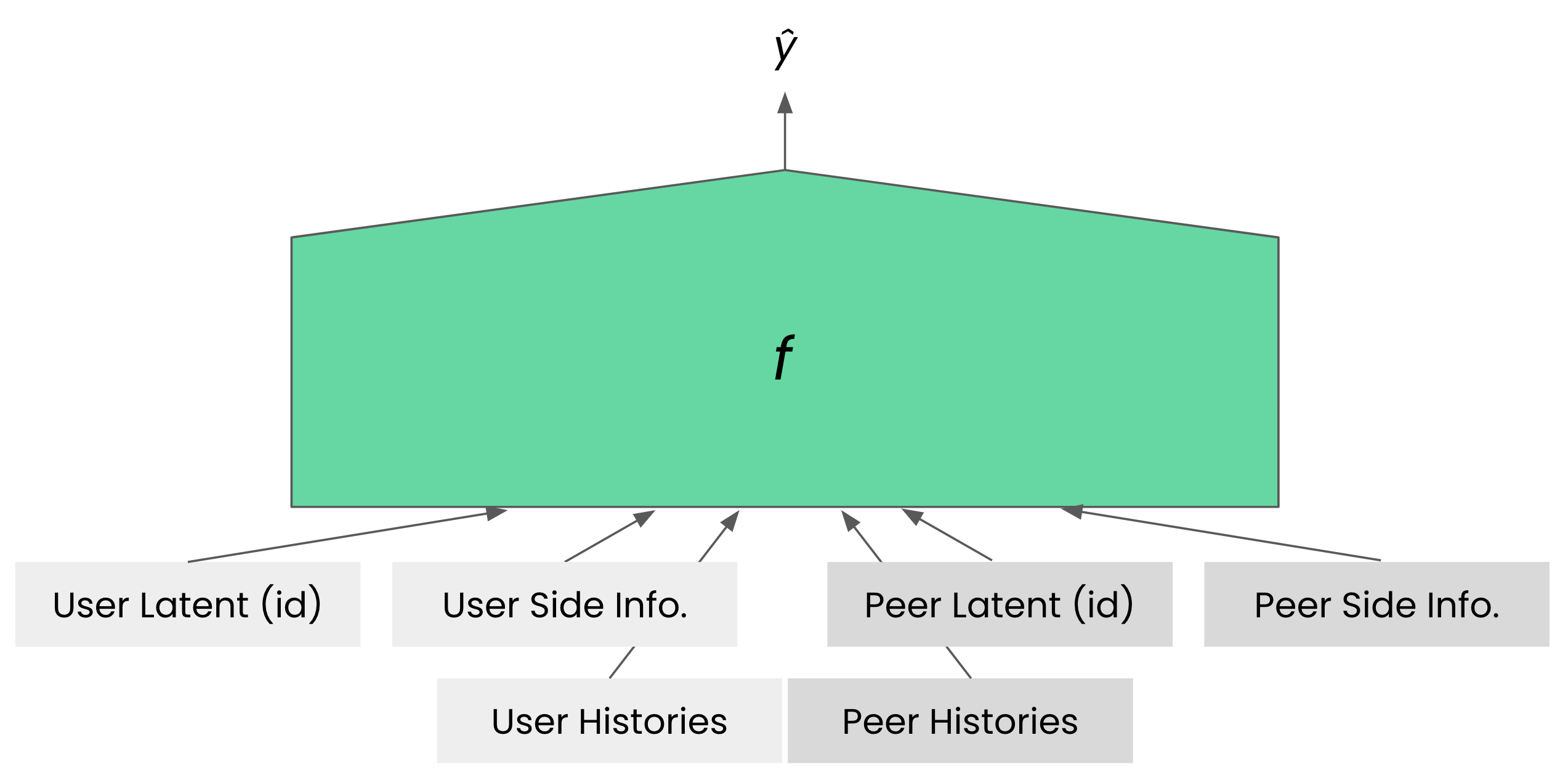
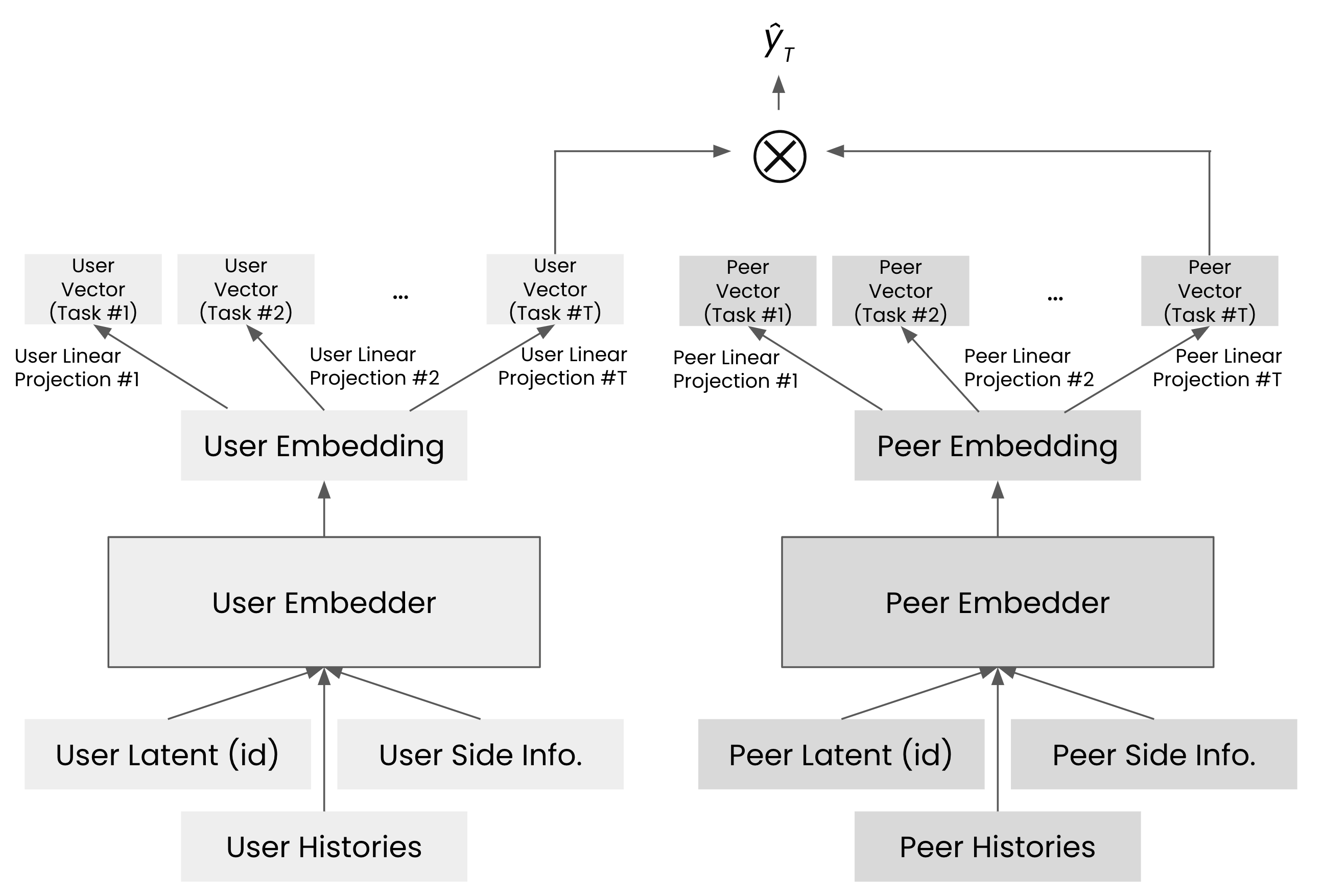
과거에는 LSTM과 같은 RNN이 세션 기반 추천에 주로 사용되었지만, 최근에는 트랜스포머(transformers) 모델, 특히 인과 트랜스포머(causal transformers)가 널리 사용되고 있습니다. 세션 기반 추천은 다음 아이템을 순차적으로 예측하는 방식이기 때문에, 이전 정보가 후속 정보에 영향을 미치는 인과 관계를 잘 반영하는 인과 트랜스포머(causal transformers)를 적용하는 것이 적합합니다. 우리 시스템에서도 다음과 같이 인과 트랜스포머를 활용하여 유저 임베더(user embedder)를 효과적으로 구성할 수 있습니다.
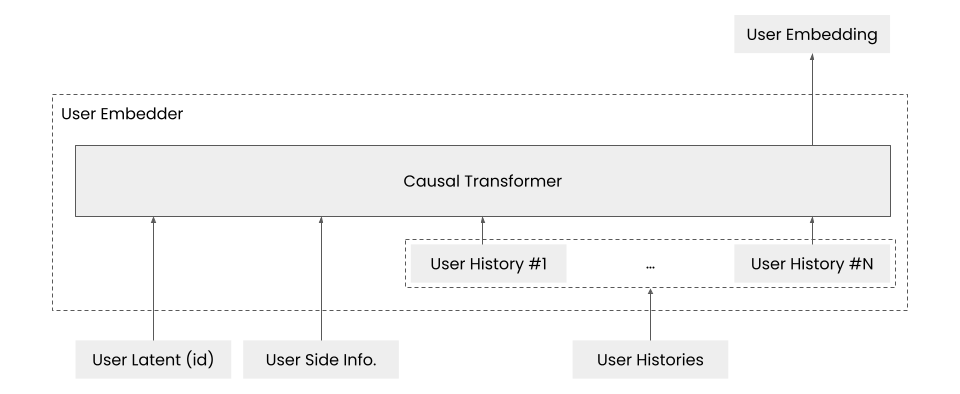
앞서 설계된 것처럼, 유저 임베더는 유저 아이디(user id), 보조 정보(side information), 히스토리를 입력으로 받아 유저를 벡터화한 임베딩(user embedding)을 출력합니다. 이 과정에서 유저 아이디, 보조 정보, 히스토리가 차례로 인과 트랜스포머에 입력되며, 마지막 출력 토큰이 유저 임베딩으로 사용됩니다. 피어 임베더도 동일한 방식으로 설계되며, 두 임베더에서 출력된 유저 임베딩과 피어 임베딩 벡터를 내적해 대화 시간을 예측합니다. 이러한 구조는 유저와 피어의 히스토리가 대화 시간 예측에 즉각적으로 반영되므로, 신규 유저에 대해서도 Wide&Deep 모델만 단순히 사용할 때보다 대화 시간을 더 정확하게 예측할 수 있습니다.
그러나 임베더를 인과 트랜스포머로만 구성하는 것은 현실적으로 어렵습니다. 트랜스포머의 연산량 부담으로 유저 임베딩을 생성하는 데 시간이 오래 걸리기 때문입니다. 히스토리의 수가 \(M\)개일 때 트랜스포머의 연산 복잡도는 \(O(M^2)\)으로 증가하며, 매칭 풀에서 가장 히스토리가 긴 유저의 임베딩 생성 시간이 전체 계산 시간을 좌우합니다. 유저들은 하루에도 수많은 피어를 만나 히스토리가 길어질 수 있기 때문에, 인과 트랜스포머로만 임베더를 구성하는 것은 확장성이 부족한 설계입니다. 이러한 이유로, 아자르와 같은 대규모 트래픽의 실제 서비스에서는 현실적으로 적용하기 어렵습니다.
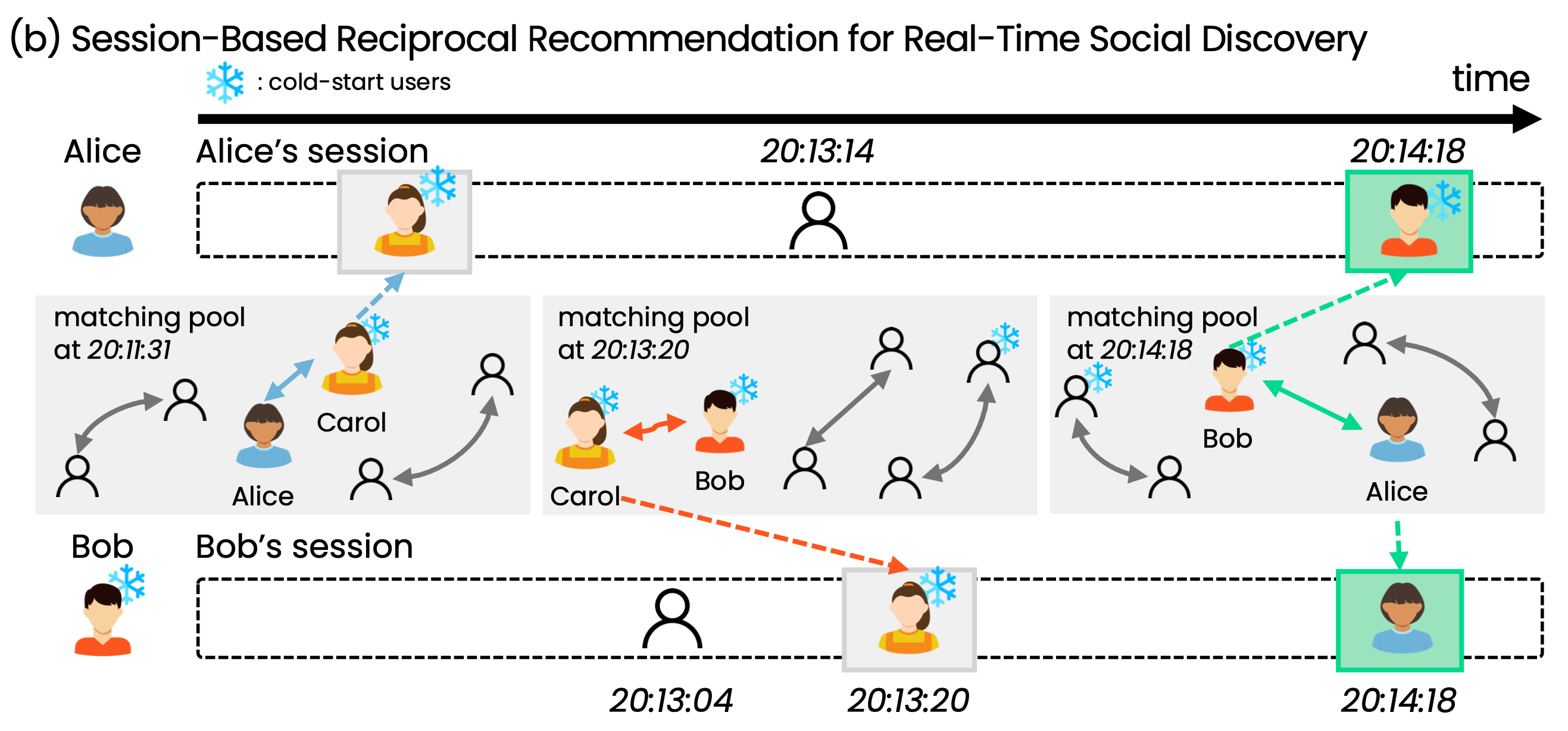
아자르에서는 매칭 풀에 매치를 원하는 유저들을 모아 예상 대화 시간이 높을 것 같은 유저-피어 쌍을 매칭시키는데, 모든 유저 간의 대화 시간을 예측하려면 각 유저에 대해 임베딩을 생성하고 내적연산을 수행해야 합니다. 이 과정에서 인과 트랜스포머를 사용하는 임베더 연산이 가장 큰 병목이 되며, 전체 계산 시간이 매칭 풀에서 가장 히스토리가 긴 유저의 임베딩 생성 시간에 비례해 늘어나기에 확장성이 부족한 설계입니다.
이런 상황에서 고려할 수 있는 방법 중 하나는 유저 임베딩을 비동기적으로 미리 계산하여 캐싱하는 것입니다. 매 매치 요청마다 유저 임베딩을 다시 계산하여 대화 시간을 예측하는 대신, 이미 계산된 유저 임베딩을 재사용해 필요한 연산량을 줄일 수 있습니다. 그러나 이 방법에는 한계가 있습니다. 아자르에서는 유저가 만나고 싶은 조건을 설정하는 필터가 존재하며, 유저는 매칭 풀에 들어갈 때마다 필터 조건을 변경할 수 있습니다. 이 조건은 보조 정보에 포함되어 유저 임베딩에 반영됩니다. 만약 유저가 필터 조건을 변경했는데 그 정보가 즉시 반영되지 않으면, 유저 경험에 부정적인 영향을 줄 수 있습니다. 따라서 단순히 유저 임베딩 캐싱만으로는 이 문제를 해결하기에 충분하지 않았고, 우리는 새로운 유저 임베더 모델링 방안을 고안하게 되었습니다.
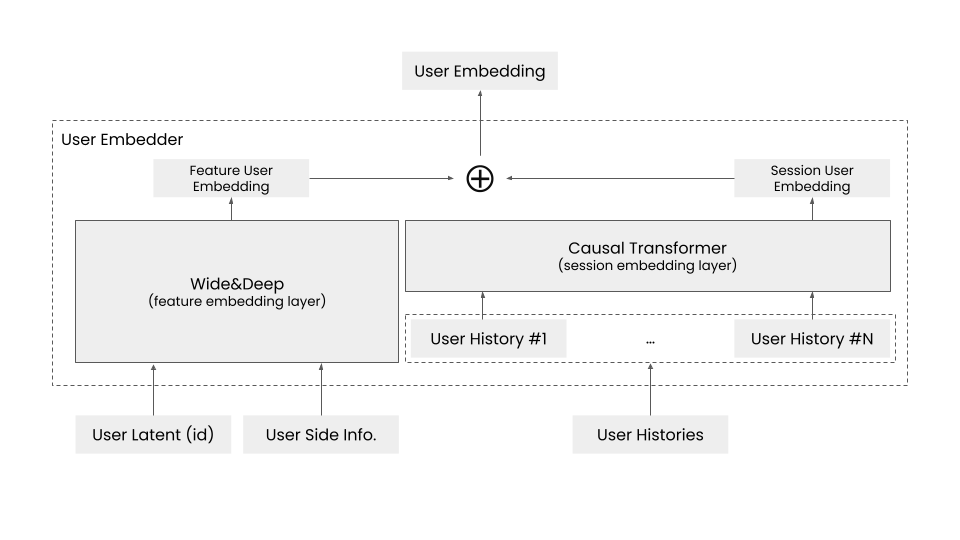
이 새로운 모델링은 매 매치 요청마다 변경되면 반드시 반영해야 하는 정보와 캐싱해도 되는 정보를 분리하여 처리합니다. 변경되면 반드시 반영해야 하는 정보는 피쳐 임베딩(feature representation)에 담고, 캐싱할 수 있는 정보는 세션 임베딩(session representation)에 저장하고 이 둘을 더해 유저 임베딩을 만듭니다. 초기 실험 결과에 따라, 피쳐 임베딩을 생성하는 레이어에는 Wide&Deep 구조를 사용했습니다. 이렇게 세션 임베딩을 비동기 방식으로 분리해 처리하면, 히스토리 개수 \(M\)의 제곱에 비례해 증가하던 연산량이 히스토리 개수와 무관하게 처리됩니다. 세션 임베딩을 사용함으로써 유저의 선호도를 빠르게 반영하면서도 비동기 방식으로 처리되어 응답 시간을 크게 단축할 수 있습니다. 우리는 이 모델을 ‘잘 맞는 사람들을 이어주는 모델’이라는 의미로 CUPID라고 명명했습니다.
어떻게 배포할까?
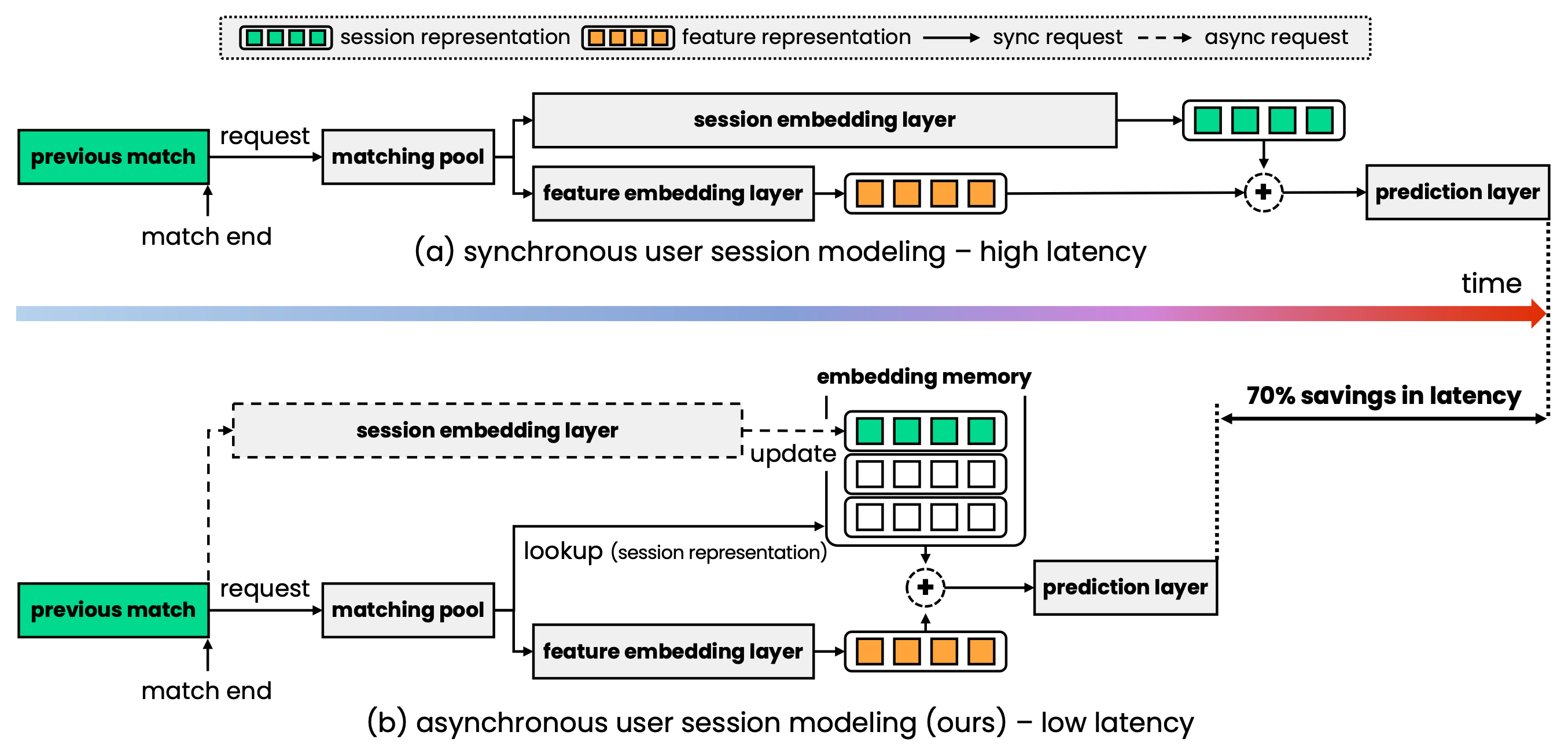
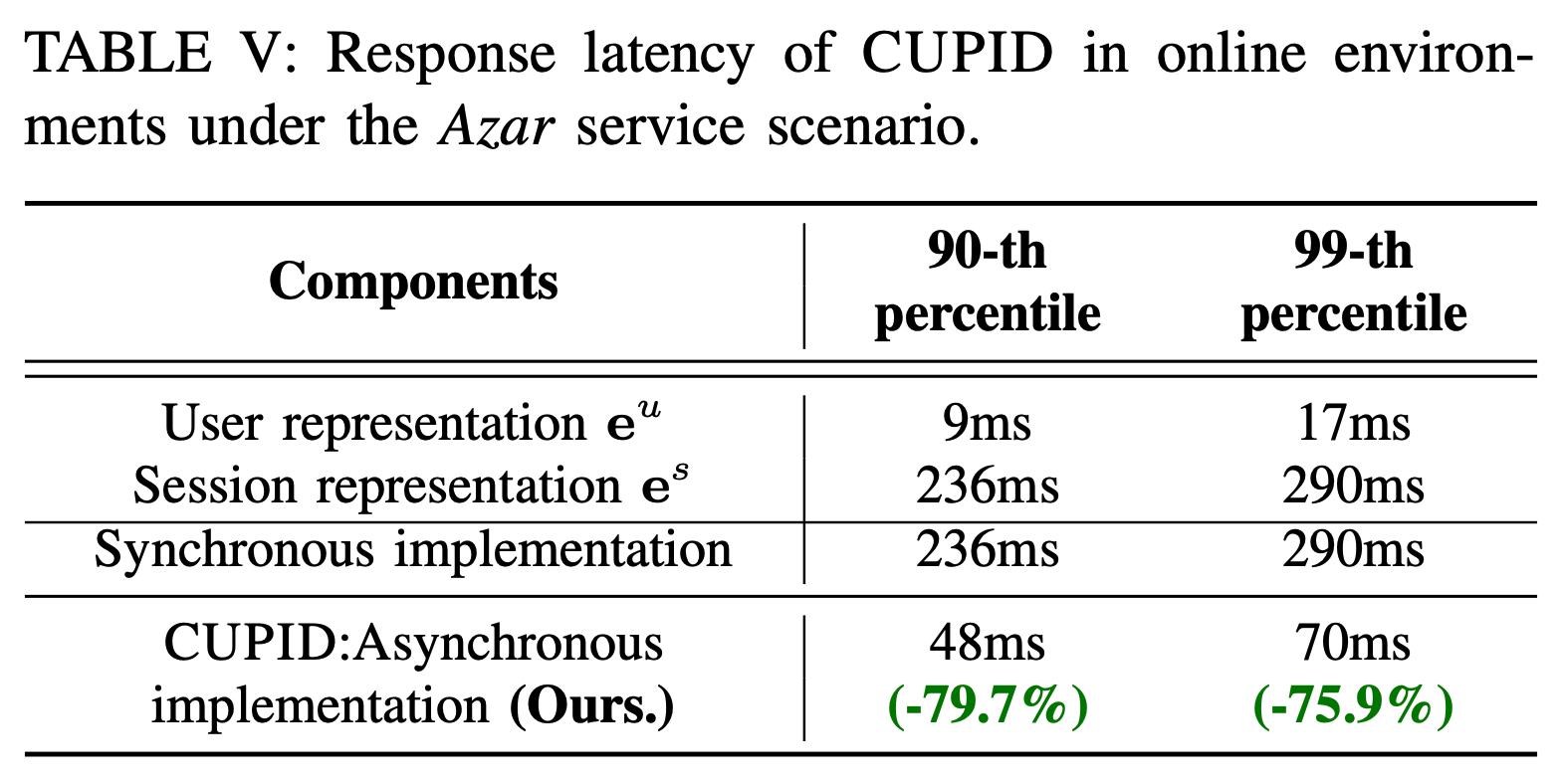
이해를 돕기 위해 배포 시나리오를 고려한 흐름을 그려보면 (b)와 같습니다. 이전 매치가 끝나면 유저는 매치 요청을 하고 매칭 풀에 들어갑니다. 매칭 풀에 들어간 후, 매치 요청마다 변경될 수 있는 보조 정보를 이용해 피처 임베딩(feature representation)을 계산하고, 동시에 임베딩 메모리(embedding memory)에서 이미 계산된 유저의 세션 임베딩을 조회(lookup)하여 사용합니다. 세션 임베딩은 비동기적으로 계산되며, 최악의 경우 이전 매치를 반영하지 못하더라도, 임베딩 메모리에 저장된 이전 임베딩을 조회해 사용할 수 있습니다. 이렇게 세션 임베딩 레이어를 비동기적으로 구성하면, 레이턴시를 90번째 백분위수에서 236ms에서 48ms로(79.7%) 줄일 수 있고 99번째 백분위수에서는 290ms에서 70ms로(75.9%) 감소시킬 수 있습니다.
어떻게 학습할까?
일반적으로 추천 모델을 학습할 때 한 데이터 포인트는 (유저, 피어, 선호도)로 구성됩니다. 유저의 매칭 히스토리가 \(M_\text{user}\) 만큼 있고, 피어의 히스토리가 \(M_\text{peer}\) 만큼 있다면, 한 데이터 포인트를 학습하는 데 \(O(M_\text{user}^2 + M_\text{peer}^2)\) 만큼의 포워드 패스(forward pass)가 필요합니다.
여기에 백워드 패스(backward pass)까지 고려하면 연산량이 상당해집니다. 우리는 학습 효율을 높이기 위해 2단계 학습 방법을 도입했고, 이를 통해 학습 효율을 213배 개선했습니다.
자세한 학습 방법은 ICDM 2024 워크숍에 출판된 논문(Kim et al., 2024)에서 확인하실 수 있습니다.
CUPID의 성능
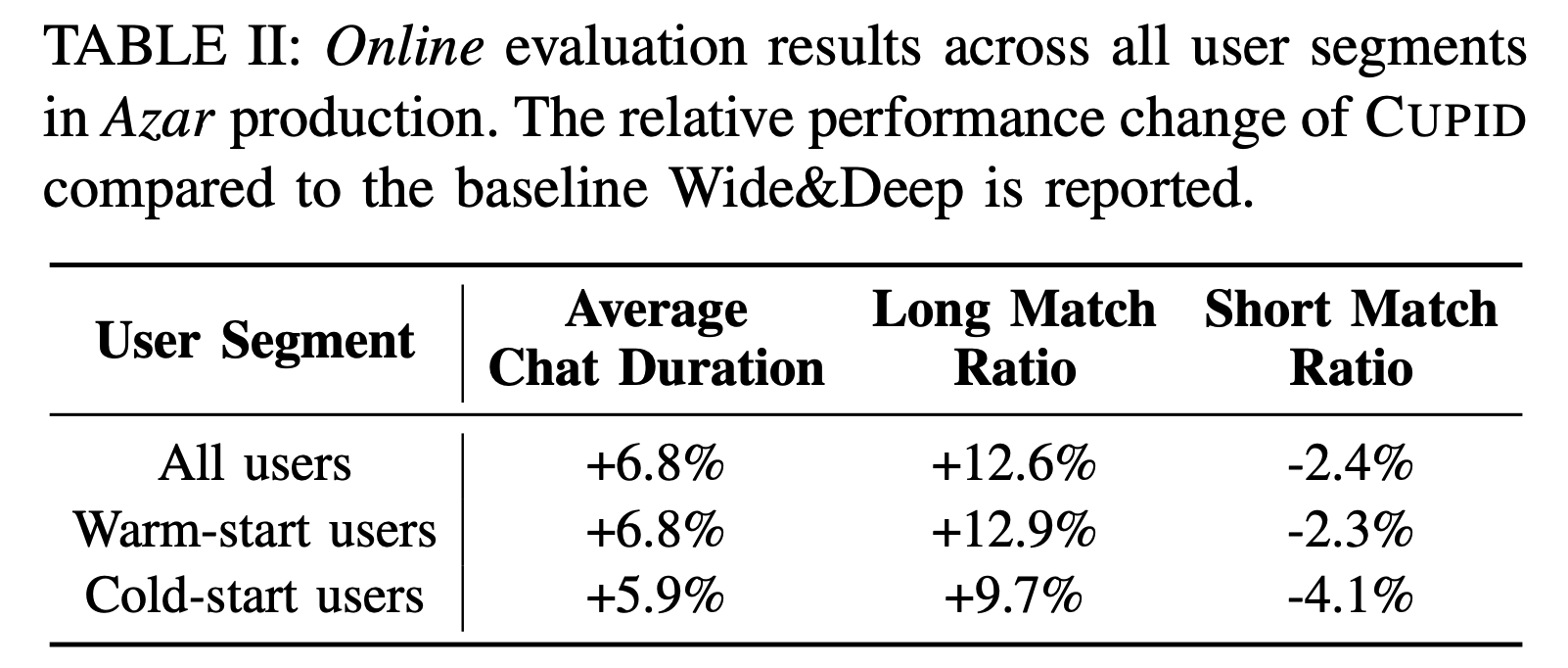
CUPID의 성능은 대규모 아자르 데이터셋을 사용해 먼저 오프라인에서 검증되었습니다. 전체 매치에서의 대화 시간 예측 성능(entire), 기존 유저 간 예측 성능(warm-warm), 기존 유저와 신규 유저 간 예측 성능(warm-cold), 그리고 신규 유저 간 예측 성능(cold-cold)을 각각 확인했습니다. Wide&Deep 모델 단독 사용 시보다 세션 임베딩 레이어와 피처 임베딩 레이어를 함께 사용하는 CUPID 모델이 AUROC과 MSE 모두에서 더 우수한 결과를 보였습니다.
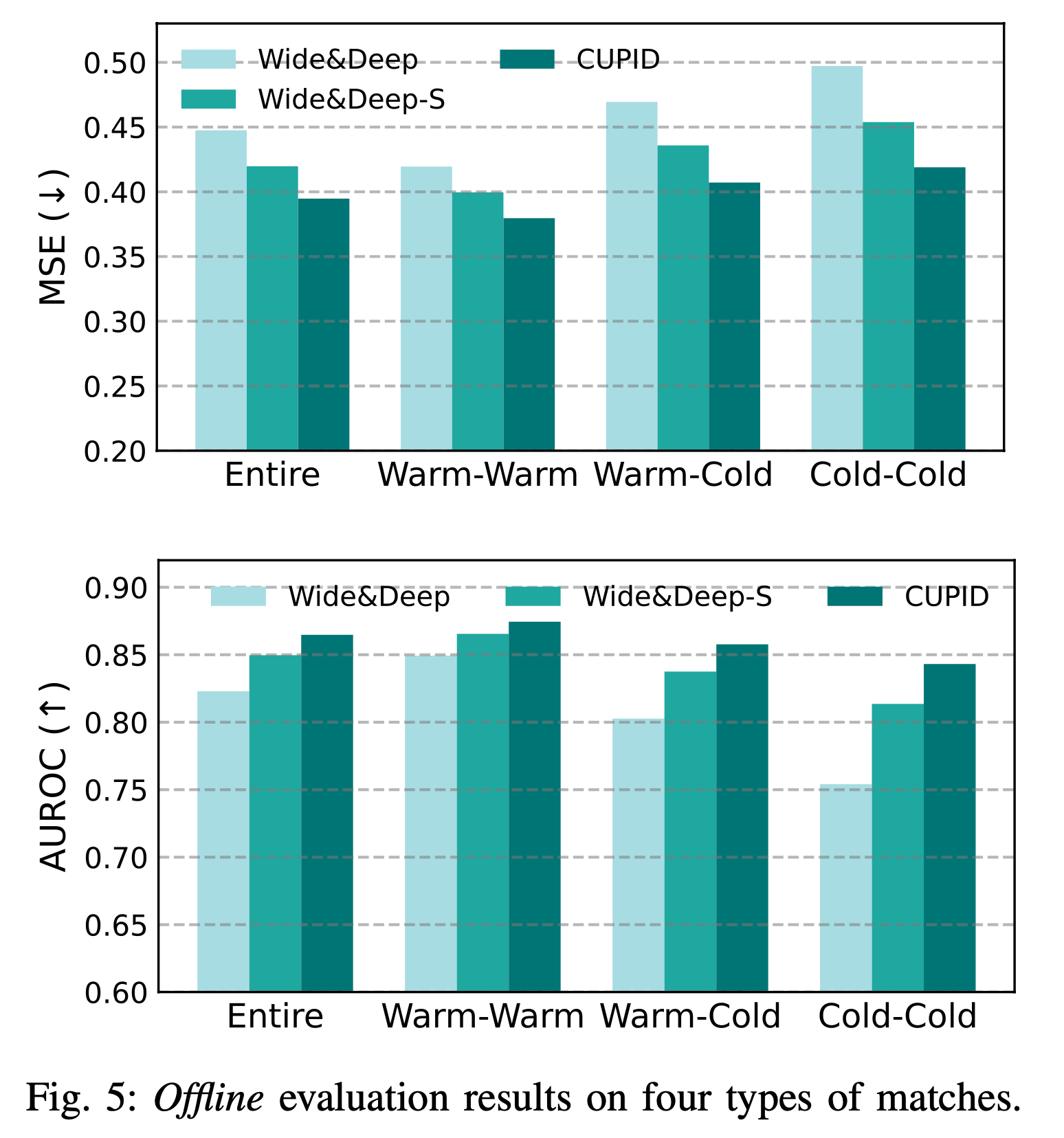
실제 아자르 서비스에 적용하여 확인해본 온라인 성능에서도, Wide&Deep 모델만 사용한 것보다 CUPID가 훨씬 더 좋은 성능을 보였습니다. 원래 의도했던 신규 유저의 경험이 크게 향상되었을 뿐만 아니라, 기존 유저의 경험도 꽤 큰 폭으로 개선되었습니다.
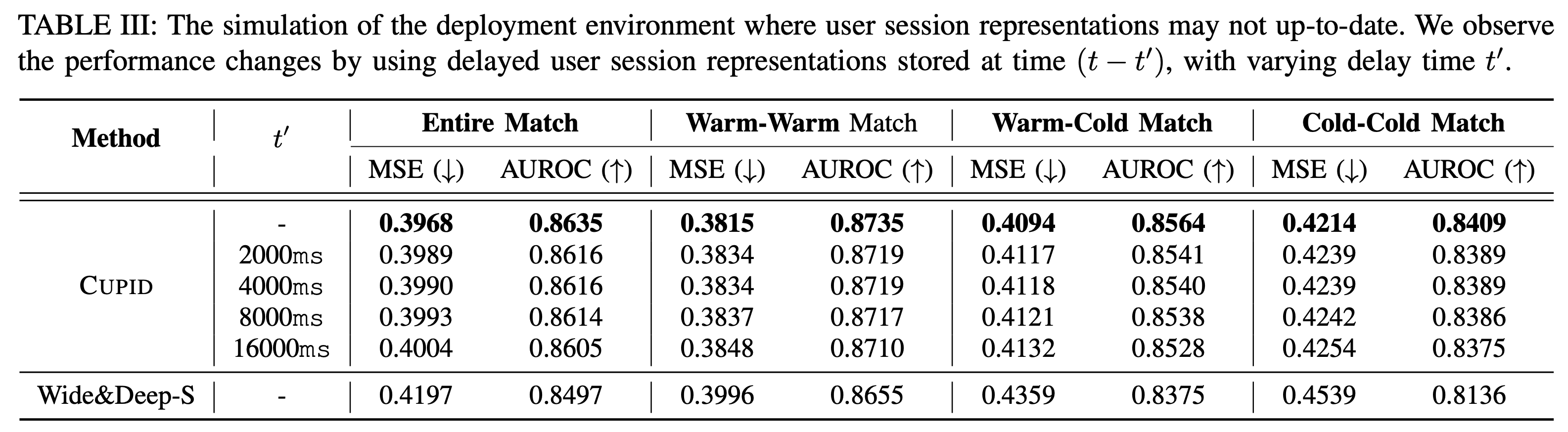
한편, CUPID는 비동기적으로 설계되어 이전 매치 결과를 즉시 반영하지 않고 과거의 세션 임베딩을 사용할 수도 있습니다. 그러나 이 경우 성능 저하가 발생할 수 있으며, 세션 임베딩이 오래될수록 성능 저하가 커질 수 있습니다. 이에 따라 비동기적인 설계에서 과거 세션 임베딩을 사용할 때 실제 성능 저하가 얼마나 큰지 확인해보았습니다. 예상대로 최신 세션 임베딩을 사용하는 것이 가장 좋았지만, 4초 정도 세션 임베딩 입수가 지연되어도 예측 성능에 큰 저하가 없었고, 16초 지연되었을 때도 Wide&Deep보다 훨씬 높은 성능을 보여 감수할 만한 수준임을 확인했습니다.
실제로는…
앞서 설명의 편의를 위해 최적화해야 하는 1차 지표를 채팅 시간이라고 가정했지만, 아하 모멘트를 설명하는 이전 테크 블로그에서 밝힌 것처럼 실제로는 여러 1차 지표의 조합이 필요합니다. 리텐션을 최적화하기 위해서는 대화 시간 외에도 신고 여부, 친구 신청 여부, 스와이프 여부 등 여러 지표를 동시에 고려해야 합니다. 따라서 실제 모델은 여러 1차 지표를 동시에 예측하고 최적화할 수 있도록 유저 임베딩과 피어 임베딩을 직접 내적하는 것이 아닌, 작업(task)에 따라 선형 투영(linear projection)한 벡터들끼리 내적하는 방식으로 설계되었습니다.
또 대화 시간과 같이 롱테일 분포를 따르는 1차 지표의 경우 단순히 유저 벡터 \(\bar{\mathbf{e}}_\text{user}\)와 피어 벡터 \(\bar{\mathbf{e}}_\text{peer}\) 를 내적하는 것만으로는 충분하지 않습니다. 모델이 단순한 내적만으로 예측을 수행할 경우, 예측된 대화 시간은 정규분포에 가깝게 나타납니다. 그러나 실제 유저들의 대화 시간은 비대칭적이고 긴 꼬리를 가진 분포를 보이므로, 정규분포와 실제 데이터 분포 사이에 큰 차이가 발생하여 예측력이 떨어지게 됩니다.
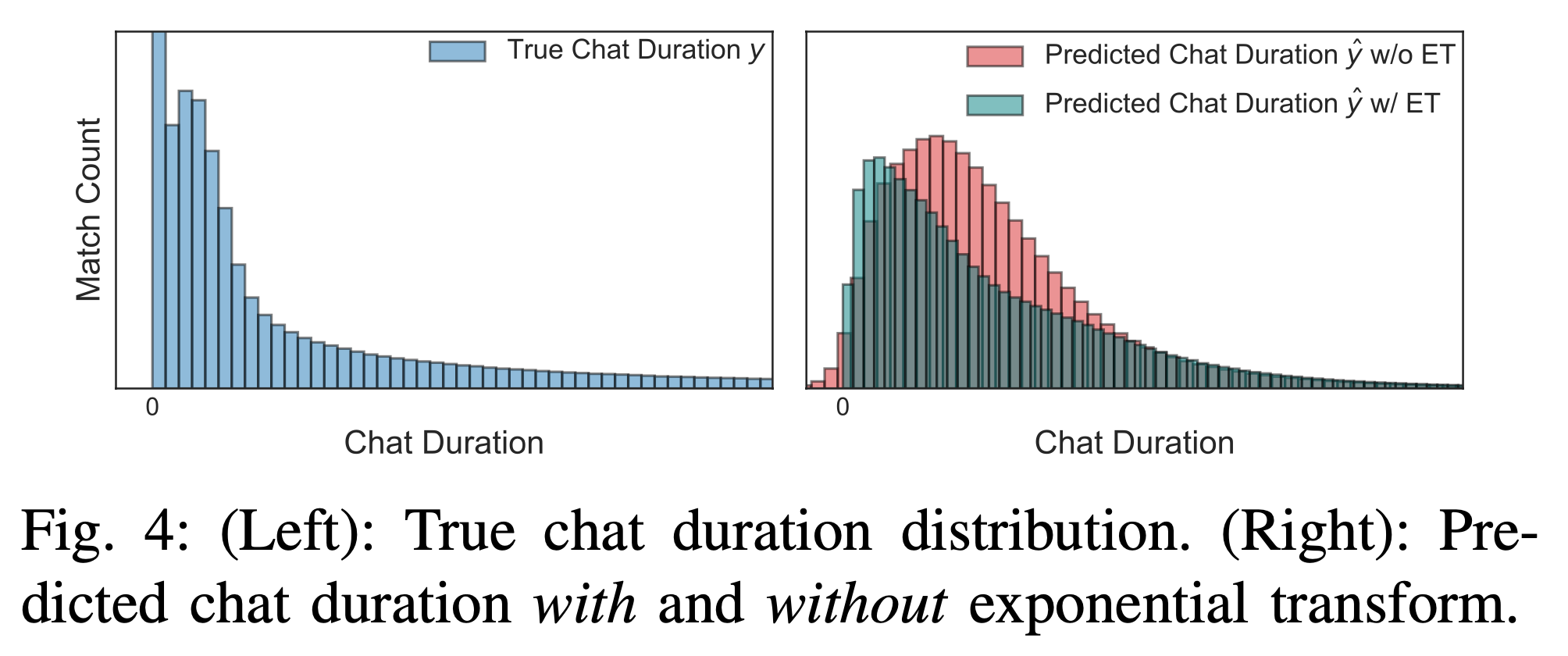
지수 변환(exponential transform; ET)은 이러한 문제를 해결하기 위해 사용됩니다. 지수 변환을 적용하면, 예측된 대화 시간이 실제 대화 시간 분포(롱테일 분포)에 더 가깝게 만들어지며, 모델이 긴 대화 시간을 더욱 효과적으로 예측할 수 있게 됩니다. 학습 가능한 \(w\)와 \(b\) 파라미터와 함께 지수 변환을 적용하여, 실제 대화 시간 분포와 유사한 예측 대화 시간 분포를 생성하고 대화 시간 예측 성능도 함께 향상시켰습니다2.
\[\hat{y}_T = \exp (w(\bar{\mathbf{e}}_\text{user} \cdot \bar{\mathbf{e}}_\text{peer}) + b)\]마치며…
이번 포스트에서는 하이퍼커넥트의 대표 서비스인 아자르의 AI 추천 모델 설계와 구현 과정을 설명했습니다. 아자르의 1:1 비디오 채팅 환경에 맞춰, 양쪽 유저의 만족도를 고려한 모델링을 통해 유저 경험을 최적화하고 리텐션을 향상시켰습니다. CatBoost 대신 투 타워 아키텍처를 사용해 짧은 레이턴시 요구를 충족시켰으며, 단순한 Wide&Deep 모델을 넘어서 세션 기반 추천을 도입해 신규 유저뿐만 아니라 기존 유저에게도 더 나은 경험을 제공할 수 있었습니다. 특히, 트랜스포머 기반 세션 추천을 통해 실시간으로 변경되는 피처 임베딩과 비동기적으로 처리되는 세션 임베딩을 분리하여 레이턴시 문제를 해결했습니다. 하이퍼커넥트 AI는 문제를 우리 상황에 맞게 정의하고 그 문제를 제대로 푸는 솔루션을 만드는 것을 원칙으로 삼고 있습니다. 이러한 접근법에 함께할 분들을 계속해서 모시고 있으니 많은 지원 부탁드립니다.
1 유저 아이디라는 범주형 변수(categorical feature)를 원핫 벡터로 변환한 후, 그 행렬이 지나치게 희소(sparse)해지지 않도록 선형 매핑을 추가한 방식으로도 이해할 수 있습니다.
2 (Kim et al., 2024)의 Table 4의 ablation 테스트 결과에서 자세한 결과를 확인하실 수 있습니다.
Reference
-
(Weinberger et al., 2009) Weinberger, K., Dasgupta, A., Langford, J., Smola, A., & Attenberg, J. (2009, June). Feature hashing for large scale multitask learning. In Proceedings of the 26th annual international conference on machine learning (pp. 1113-1120).
-
(Rendle 2010) Rendle, S. (2010, December). Factorization machines. In 2010 IEEE International conference on data mining (pp. 995-1000). IEEE.
-
(Cheng et al., 2016) Cheng, H. T., Koc, L., Harmsen, J., Shaked, T., Chandra, T., Aradhye, H., … & Shah, H. (2016, September). Wide & deep learning for recommender systems. In Proceedings of the 1st workshop on deep learning for recommender systems (pp. 7-10).
-
(Juan et al., 2016) Juan, Y., Zhuang, Y., Chin, W. S., & Lin, C. J. (2016, September). Field-aware factorization machines for CTR prediction. In Proceedings of the 10th ACM conference on recommender systems (pp. 43-50).
-
(Guo et al., 2017) Guo, H., Tang, R., Ye, Y., Li, Z., & He, X. (2017). DeepFM: a factorization-machine based neural network for CTR prediction. arXiv preprint arXiv:1703.04247.
-
(He et al., 2017) He, X., Liao, L., Zhang, H., Nie, L., Hu, X., & Chua, T. S. (2017, April). Neural collaborative filtering. In Proceedings of the 26th international conference on world wide web (pp. 173-182).
-
(Zhang et al., 2020) Zhang, C., Liu, Y., Xie, Y., Ktena, S. I., Tejani, A., Gupta, A., … & Shi, W. (2020, September). Model size reduction using frequency based double hashing for recommender systems. In Proceedings of the 14th ACM Conference on Recommender Systems (pp. 521-526).
-
(Kim et al., 2024) Kim, B., Kim, S., Kim, M., Yi, J., Ha, S., Lee, S., Lee, Y., Yeom, G., Chang, B., & Lee, G. (2024). CUPID: A Real-Time Session-Based Reciprocal Recommendation System for a One-on-One Social Discovery Platform. In Proceedings of the the 2nd international workshop on user understanding from big data workshop (DMU2 2024).
Read more
-
비즈니스 문제를 AI 문제로 정렬하는 방법
최적화 이론의 완화(relaxation) 개념을 비즈니스 문제에 적용하여, 비즈니스 문제를 AI 문제로 정렬하는 방법을 소개합니다. -
협업 필터링을 넘어서: 하이퍼커넥트 AI의 추천 모델링
하이퍼커넥트 AI 조직이 추천 시스템에 협업 필터링(collaborative filtering)을 넘어 어떤 모델링을 적용하고 있는지 소개합니다. -
Behind the Paper: 하이퍼커넥트 AI 조직이 제품에 기여하면서 연구하는 법
하이퍼커넥트 AI 조직이 어떻게 연구를 통해 제품에 기여하고 논문까지 출판하는지 소개합니다. -
아자르에서 AI 기반 추천 모델의 타겟 지표를 설정하는 방법 (feat. 아하 모멘트)
리텐션을 올리기 위해서는 어떤 AI 모델을 학습시켜야 할까요? 아자르에서 아하 모멘트 프레임워크로 AI 추천 모델의 타겟 지표를 설정한 방법을 소개합니다.