머신러닝 모델 서빙 비용 1/4로 줄이기
들어가며
하이퍼커넥트의 AI 조직에서는 다양한 머신러닝 모델을 서빙하고 있습니다. 보통의 서버와는 달리, 머신러닝 모델의 처리량(throughput)을 높이기 위해서는 특수 자원인 GPU가 필요합니다. 그런데 GPU를 사용하면 성능은 좋으나 비용이 만만치 않습니다.
여기에는 몇 가지 이유가 있습니다.
- 프로덕션은 실험보다 높은 가용성을 요구하기 때문에 AWS 같은 클라우드 서비스를 주로 이용합니다. 그런데 클라우드에서 GPU 노드는 CPU 노드에 비해 비용이 몇 배로 비쌉니다. 예를 들어 일반적인 서버에 사용되는 CPU 노드인 c5.12xlarge 인스턴스에서는 현재 10대 이상의 서버가 운영되고 있고 하나의 노드에 대한 월 비용이 $1,830 수준입니다. 하지만 모델 서빙 전용 GPU 노드인 g4dn.12xlarge 인스턴스에서는 많아야 4대의 서버가 운영되고 있는데 하나의 노드에 대한 월 비용이 $3,400 수준으로 더 많은 비용이 들어가고 있습니다.
- GPU는 CPU보다 자원을 낭비하기 쉽습니다. CPU는 경우에 따라 하나의 물리 코어도 더 작은 가상 코어로 나누어 사용할 수 있습니다. 하지만 GPU는 적어도 한 번에 하나의 카드를 점유해야만 합니다.
- 연산량이 적은 모델의 경우 필요한 연산 능력보다 메모리 통신 오버헤드가 더 클 수 있는데요, 이런 경우에 GPU를 사용하면 오히려 CPU에서 바로 처리하는 것보다 비효율적입니다.
하이퍼커넥트 ML Platform 팀에서는 이런 제약 조건 아래에서 어떻게 하면 머신러닝 모델을 효율적으로 서빙할 수 있을지 고민을 거듭해왔습니다. 올해 5월부터 도입한 AWS Inferentia도 그 노력들 중 하나였는데요. 간단한 작업만으로 비용이 1/4 수준으로 크게 절감되었고, 현재는 적용 범위를 확장하여 많은 모델을 AWS Inferentia를 이용하여 안정적으로 서빙하고 있습니다.
이번 포스트에서는 AWS Inferentia를 하이퍼커넥트의 인프라에 도입한 경험, 실제로 비용이 절감이 되는지 테스트 결과, 그리고 도입 과정에서 겪을 수 있는 문제와 해결 방안을 공유해보고자 합니다.
AWS Inferentia가 무엇인가요?
AWS Inferentia는 2018년 11월에 처음 발표되었고, 2019년 12월에 EC2 인스턴스(inf1)로 출시된 꽤 따끈따끈한 AI 가속기입니다. Inferentia를 이용하면 낮은 비용으로 더 빠른 머신 러닝 추론을 할 수 있어 저희의 요구 사항에 딱 맞았습니다. 우선 Inferentia가 무엇인지, 어떻게 속도와 비용이라는 두 마리 토끼를 잡을 수 있는지 잠깐 살펴보겠습니다.
AI 가속기란?
AI 가속기란 머신러닝 어플리케이션 가속에 특화된 프로세서입니다. 쉽게 말하면 CPU보다 Convolution이나 Attention과 같은 머신러닝 레이어 연산을 빠르게 수행할 수 있는 장치입니다.
대표적인 AI 가속기로는 우리 모두가 알고 있는 GPU가 있습니다. 머신러닝 워크로드는 단순한 연산을 병렬로 수행하는 경우가 많기 때문에 CPU보다 병렬 계산에 유리한 GPU가 많이 활용되고 있습니다. 하지만 GPU는 전력 소모가 극심하고 (앞에서 보셨다시피) 가격이 비싸기 때문에 항상 좋은 선택지는 아닙니다.
때문에 세계의 기업들은 앞다투어 GPU보다 효율적으로 머신러닝 연산을 수행할 수 있는 AI 가속기를 연구/개발하고 있습니다. 이 포스트에서 소개하고 있는 AWS의 Inferentia, 구글의 TPU(Tensor Processing Unit), Apple이 A11 Bionic 칩부터 탑재하기 시작한 ANE(Apple Neural Engine) 같은 칩이 그 예입니다.
ASIC이란?
ASIC(Application-Specific Integrated Circuit)은 범용 연산보다는 특정 기능만 효과적으로 수행하도록 설계 및 제작된 칩을 뜻합니다. 회로 설계를 위한 개발 비용이 높고, 제작된 이후에는 변경이 어렵다는 단점이 있기는 하지만, 꼭 필요한 기능만을 수행하기 때문에 압도적인 성능을 보여주고 대량 생산을 통해 낮은 비용으로 제작할 수 있다는 장점이 있습니다.
낯선 이름이지만 사실 ASIC은 생각보다 가까운 곳에 많이 있습니다. 네트워크 라우터에는 네트워크 패킷 프로세싱에 최적화된 ASIC이 들어가고, 녹음기에도 디지털 음성 신호 처리에 특화된 ASIC 칩이 들어갑니다.
머신러닝 연산은 종류가 한정되어 있고, 대부분 다수의 독립적인 연산을 처리하는 패턴이기 때문에 ASIC 칩을 활용하기에 적합한 분야입니다. 그래서 다양한 AI 가속기가 ASIC 기반으로 개발되고 있고, 이 포스트에서 소개하는 AWS Inferentia도 그 중 하나입니다.
AWS Inferentia란?
AWS Inferentia는 저렴한 비용 & 높은 처리량 & 낮은 지연 시간(latency)을 장점으로 하는 ASIC 기반 AI 가속기입니다. Inferentia 칩은 4개의 NeuronCore v1으로 구성되어 있습니다. 각 NeuronCore는 강력한 행렬 곱셈 엔진으로, 대용량 on-chip 캐시와 DRAM을 탑재하고 있습니다. Inferentia는 이를 이용하여 CNN이나 Transformer와 같은 딥러닝 모델 추론을 빠르게 수행할 수 있습니다.
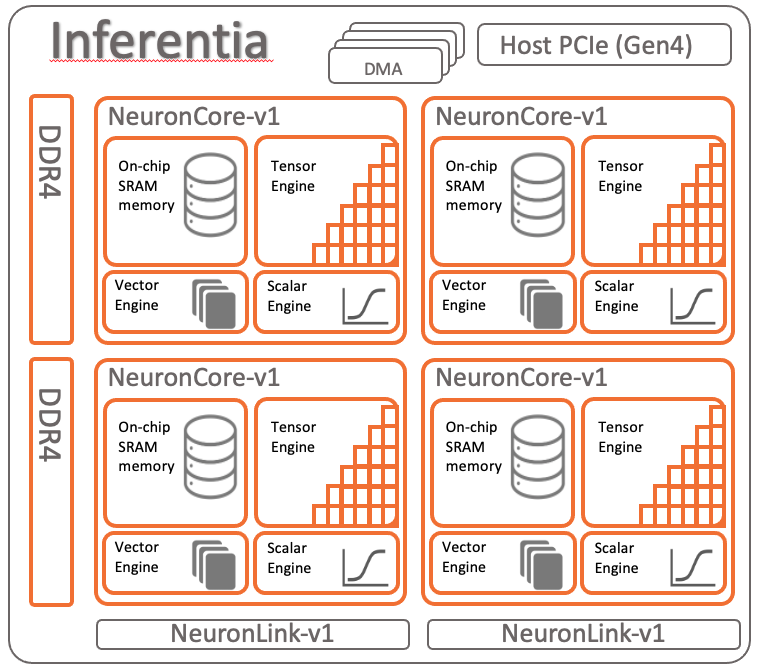
NeuronCore는 FP32, FP16, BF16 자료형 연산을 지원하며, 대표적인 딥러닝 프레임워크인 TensorFlow, PyTorch, Apache MXNet을 모두 지원합니다. 또한 ONNX 형식을 사용하는 모델도 사용할 수 있습니다.
[참고] 학습 전용 인스턴스인 AWS Trn1에 탑재된 NeuronCore v2에서는 추가로 UINT8 자료형을 지원하고 있지만, 추론 전용 인스턴스인 AWS Inf1에 탑재된 NeuronCore v1에서는 INT8을 지원하지 않습니다. 로드맵에
Neuron INT8 support on Inf1항목이 있기 때문에, 추후 지원될 가능성은 있습니다. AWS Inferentia의 아키텍처, 로드맵과 지원하는 operator에 대한 정보는 아래에서 확인하실 수 있습니다.
AWS Inferentia를 어떻게 도입하나요?
앞서 살펴본 것처럼 ASIC 칩을 이용하면 더 효율적인 연산이 가능하지만, ASIC은 특수하게 설계된 칩이기 때문에 CPU나 GPU에서 서빙하던 모델을 ASIC에서 서빙하도록 이전하려면 추가 작업이 필요합니다.
작업 방법은 프레임워크에 따라 다를 수 있는데, 이 포스트에서는 연구에 널리 이용되는 PyTorch를 기준으로 AWS Inferentia 도입 과정을 단계별로 설명드리고자 합니다.
1단계 : Neuron SDK를 이용하여 모델 컴파일하기
환경 구축하기
AWS Inferentia의 NeuronCore을 이용하려면 AWS에서 제공하는 Neuron SDK를 이용하여 기존 PyTorch모델을 전용 Neuron 모델로 컴파일해야 합니다. 필요한 SDK는 주요한 패키지 매니저를 통해 설치할 수 있습니다.
# Python 가상 환경 생성
conda create -n neuron_compile python=3.7
conda acitvate neuron_compile
# 컴파일 대상 모델이 필요로 하는 의존성 설치
pip install -r requirements.txt
# PyTorch를 위한 Neuron SDK와 torchvision 설치
pip install \
torch-neuron==1.8.1.* \
neuron-cc[tensorflow] \
torchvision==0.9.1.* \
--extra-index-url https://pip.repos.neuron.amazonaws.com
[참고] 컴파일을 위해서는 Inferentia 칩이 필요하지 않기 때문에 하이퍼커넥트에서는 온프레미스 서버에 의존성을 설치해두고 사용하고 있지만, 필요하다면 AWS에서 제공하는 전용 AMI를 이용하여 직접 EC2 인스턴스를 띄워 원격 컴파일 환경을 사용할 수도 있습니다. AWS Neuron 공식 문서에서는 (PyTorch Neuron을 포함하여) 다양한 프레임워크를 위한 Neuron SDK 튜토리얼을 지원하고 있으므로 참고 바랍니다.
모델 컴파일하기
다음은 PyTorch 모델을 Inferentia 전용 Neuron 모델로 컴파일하는 예시 코드입니다. 보시다시피 몇 줄의 코드로 간단히 변환을 수행할 수 있습니다.
import torch
import torch.neuron
# 컴파일 대상 모델의 input shape에 맞는 더미 tensor를 생성
input_tensor = torch.zeros([1, 3, 224, 224], dtype=torch.float32)
# 변환할 모델 로드
model = torch.load("model.pt")
model.eval()
# 모델의 operator 지원 여부, 개수 등을 분석
torch.neuron.analyze_model(model, example_inputs=[input_tensor])
# NeuronCore 전용 모델로 컴파일하여 저장
model_neuron = torch.neuron.trace(model, example_inputs=[input_tensor])
model_neuron.save("model_neuron.pt")
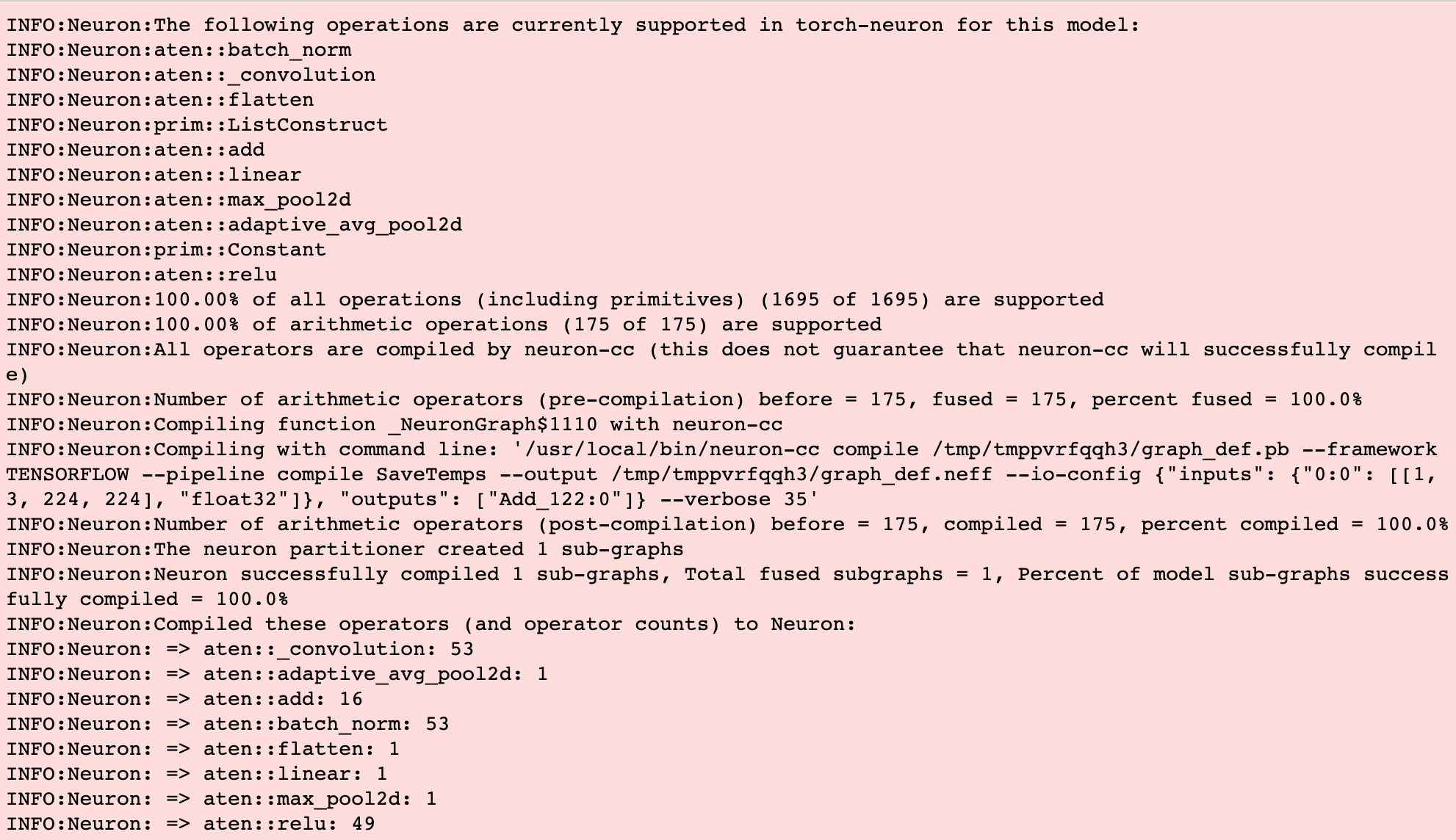
아래는 ResNet50을 Neuron SDK로 분석한 로그입니다. 모델에 어떤 operator(연산)가 얼마나 포함되어 있는지, 포함된 각 operator가 Inferentia에서 지원 되는지 여부 등을 알 수 있습니다.
로그에서 보실 수 있듯 ResNet50의 경우는 모든 operator가 지원 가능(100.00%)합니다. 임베딩(embedding)과 같이 일부 Neuron SDK로 컴파일이 불가능한 레이어는 자동으로 제외하고 컴파일을 진행하게 됩니다.
모델 추론하기
이렇게 컴파일된 Neuron 모델은 NeuronCore가 설치되어 있는 AWS Inf1에서 torch.jit.load 함수로 로드하여 사용할 수 있습니다.
import torch
import torch.neuron
# 모델 로드
model_neuron = torch.jit.load("model_neuron.pt")
# 모델 추론
input_tensor = ...
output = model_neuron(input_tensor)
2단계 : Triton Inference Server로 모델 배포하기
Triton Inference Server란 무엇인가요?
Triton inference server(이하 Triton)는 NVIDIA에서 개발한 오픈소스 추론 서버입니다.
Triton은 서로 다른 시점에 들어온 요청을 한 배치로 묶어주는 다이나믹 배칭 기능이 있어 서빙 효율을 극대화할 수 있으며, Tensorflow, PyTorch, ONNX, FasterTransformer, Python Backend 등 다양한 추론 백엔드를 사용할 수 있어 다양한 모델을 규격화하여 배포하기에 용이합니다. 특히 Triton 2.17.0 릴리즈부터는 Python Backend에서 추가로 AWS Inferentia 및 Neuron Runtime을 지원하기 때문에 Neuron 모델을 배포하기에 적합합니다.
ML Platform 팀에서는 이미 다양한 모델을 Triton으로 배포하는 서빙 플랫폼을 구축하여 활용해오고 있습니다. 덕분에 AWS Inferentia를 이용하는 Neuron 모델도 기존 시스템에 쉽게 통합할 수 있었습니다.
[참고] 하이퍼커넥트에서 어떻게 Triton으로 배포 환경을 구축하였는지는 NAVER DEVIEW 2021에서 발표한 ‘어떻게 더 많은 모델을 더 빠르게 배포할 것인가?’ 영상을 참고 부탁드립니다.
Triton Inference Server에 Neuron 모델 배포하기
Triton의 Python Backend Repo에서는 AWS Inferentia를 사용하는 데 필요한 추론 서버 환경 설정 스크립트, 모델 컴파일 방법, 모델 서빙 코드 생성 스크립트를 제공하고 있어서 쉽게 모델 배포 환경을 세팅할 수 있습니다. 아래는 이를 이용하여 생성된 모델 서빙 코드의 예시입니다.
...
import torch
import torch.neuron
from triton_python_backend_utils import InferenceRequest # noqa
from triton_python_backend_utils import InferenceResponse # noqa
from loguru import logger
...
# TritonPythonModel 클래스와 각 메소드는 Triton Inference Server를 띄우기 위한 기본 구조입니다. 그 중 initialize 메소드가 Neuron 모델과 CPU/GPU 모델의 코드인 경우에 차이가 있습니다.
class TritonPythonModel:
def initialize(self, args: dict[str, str]) -> None:
# Neuron 모델의 경우에는 NeuronCore를 지정하는 코드가 필요합니다. NeuronCore는 한 번 점유가 되면 다른 프로세스가 사용할 수 없기 때문에, 하나의 inf1 인스턴스에서 여러 프로세스가 NeuronCore를 활용하기 위해서는 프로세스마다 NeuronCore를 지정하여 나누어 사용해야 합니다. 따라서 아래의 코드처럼 NeuronCore의 Index 범위를 설정해 줍니다. 해당 코드는 neuron 모델 용 코드 생성 스크립트에서도 확인하실 수 있습니다.
self.model_config = ModelConfig.parse_raw(args["model_config"])
instance_group_config = self.model_config.instance_group[0]
instance_count = instance_group_config.count
instance_idx = 0
if instance_count > 1:
instance_name_parts = args['model_instance_name'].split("_")
instance_idx = int(instance_name_parts[-1])
params = self.model_config.parameters
nc_start_idx = int(params['NEURON_CORE_START_INDEX'].string_value)
nc_end_idx = int(params['NEURON_CORE_END_INDEX'].string_value)
threads_per_core = int(params['NUM_THREADS_PER_CORE'].string_value)
num_threads = (nc_end_idx - nc_start_idx + 1) * threads_per_core
total_core_count = nc_end_idx - nc_start_idx + 1
cores_per_instance = total_core_count // instance_count
adjusted_nc_start_idx = (instance_idx * cores_per_instance) + nc_start_idx
if adjusted_nc_start_idx == (adjusted_nc_start_idx + cores_per_instance - 1):
os.environ["NEURON_RT_VISIBLE_CORES"] = f"{adjusted_nc_start_idx}"
else:
visible_core_range = f"{adjusted_nc_start_idx}-{adjusted_nc_start_idx + cores_per_instance - 1}"
os.environ["NEURON_RT_VISIBLE_CORES"] = visible_core_range
consumed_cores_list = [i for i in range(cores_per_instance)]
# CPU와 GPU 모델의 경우 `self.model.torch.load("model.pt").to_device("cuda")` 와 같이 device와 함께 한 줄의 코드로 모델을 로드할 수 있지만, neuron 모델의 경우 위와 같은 NeuronCore 세팅 과정을 거친 후 로드해주는 것이 좋습니다.
self.model = torch.neuron.DataParallel(
torch.jit.load("model.pt"),
device_ids=consumed_cores_list,
)
self.model.num_workers = num_threads
# 의사 코드입니다. 실제 실행 시에 동작할 코드를 포함합니다.
def execute(self, requests: list[InferenceRequest]) -> list[InferenceResponse]:
batched_inputs = torch.cat(get_inputs(requests)), dim = 0)
with torch.inference_mode():
batched_outputs = self.model(batched_inputs)
return make_responses(batched_outputs)
3단계 : 모델 지표 모니터링하기
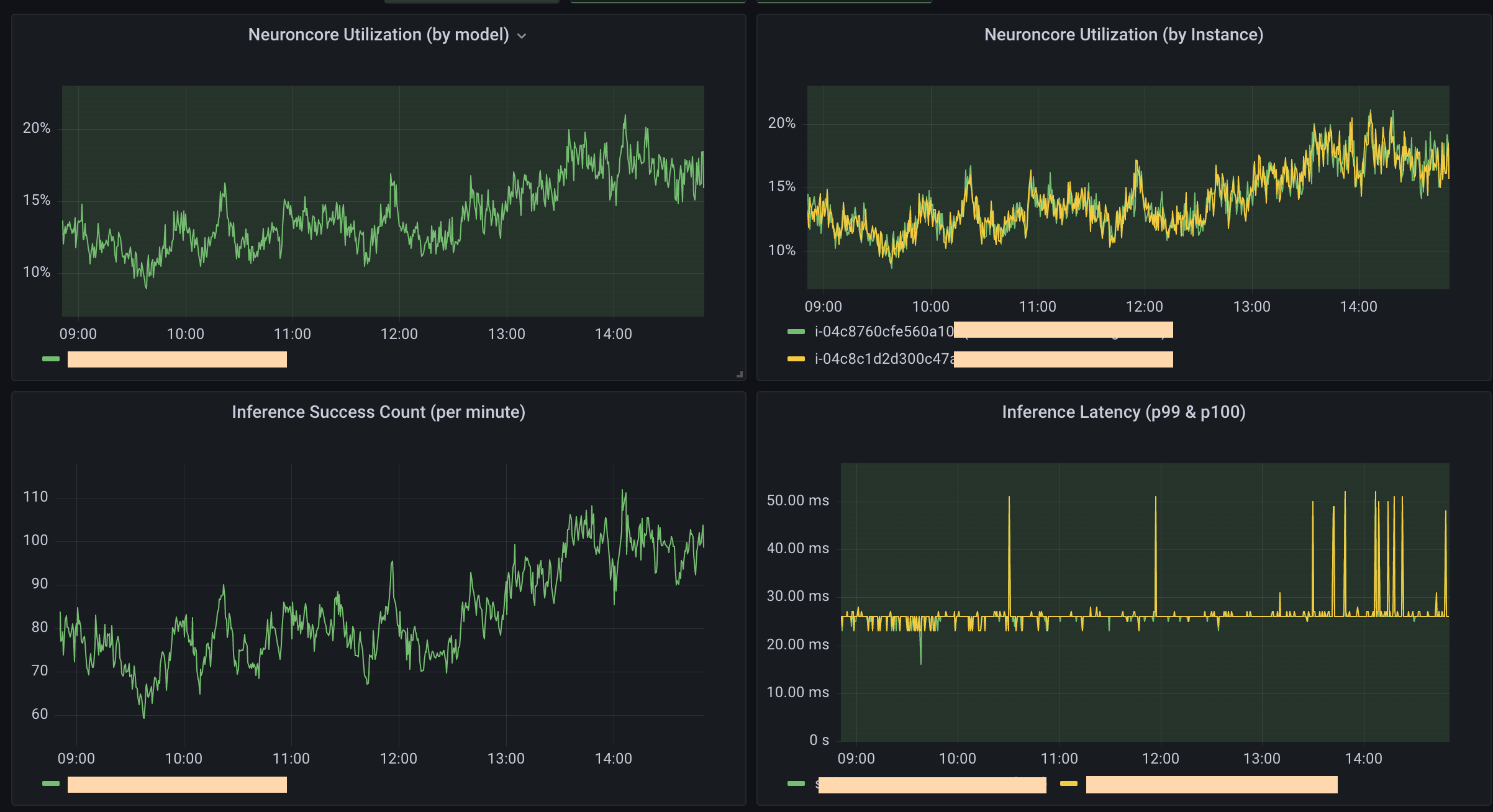
배포된 모델은 프로덕션에서 임계 경로(critical path)에 들어가기 때문에 반드시 지표 모니터링이 수반되어야 합니다. AWS에서는 이를 위해 다양한 Neuron 디버깅 & 프로파일링 도구를 제공하고 있습니다. 이 중 지속적으로 성능 지표와 통계치를 모니터링 하기 위해서는 Neuron Monitor를 활용하시면 됩니다.
Neuron Monitor는 기본적으로 JSON으로 지표를 리포트합니다. AWS에서는 기본적으로는 TensorBoard를 이용하여 시각화하도록 가이드하고 있으나, 사용 사례에 맞게 커스터마이즈할 수 있습니다. 예를 들어 하이퍼커넥트에서는 다른 서비스와 함께 통합 모니터링할 수 있도록 DevOps 팀에서 구성해주신 Grafana Dashboard를 사용하고 있습니다.
Neuron 모델이 GPU 모델보다 얼마나 효율적인가요?
학습된 모델을 다시 한 번 컴파일하고 별도로 배포하는 과정을 거치려면 인적 비용이 듭니다. 당연히 그보다 더 많은 자원을 아낄 수 있어야 도입하는 의미가 있겠지요.
실제로 하이퍼커넥트에서 AWS Inferentia를 도입하여 GPU를 사용한 것에 비해 얼마나 비용을 절감할 수 있었는지, 실험을 통해 알아보겠습니다.
실험 환경 준비하기
다음 표는 AWS의 GPU 인스턴스인 g4dn.12xlarge와 Inferentia 인스턴스인 inf1.2xlarge의 시간당 요금을 나타낸 것입니다. (us-west-1 리전, 온디맨드 플랜 기준)
| 노드 유형 | Cost (USD/hour) | #vCPU | Memory (GiB) | #GPU | #Inferentia |
|---|---|---|---|---|---|
| g4dn.12xlarge | 4.694 | 48 | 192 | 4 | - |
| inf1.2xlarge | 0.435 | 8 | 16 | - | 1 |
실험에서 g4dn.12xlarge의 경우 총 4개의 GPU를 사용할 수 있으며, 하나의 모델 추론 서버가 한 개의 GPU를 사용하도록 설정하였습니다. inf1.2xlarge의 경우에는 Inferentia 칩이 하나이고, 하나의 모델 추론 서버가 해당 칩(4개의 Neuron Core) 전체를 사용하도록 설정하였습니다.
GPU 노드와 Inferentia 노드 모두 Triton을 이용해서 컴파일 여부만 다른 동일한 모델을 배포하였습니다. 따라서 쿠버네티스 Pod 하나당 스펙을 비교하면 다음과 같습니다.
| 노드 유형 | Cost (USD/hour) | #vCPU | Memory (GiB) | #GPU | #Inferentia |
|---|---|---|---|---|---|
| g4dn.12xlarge | 1.2725 | 12 | 48 | 1 | - |
| inf1.2xlarge | 0.435 | 8 | 16 | - | 1 |
[참고] 모델 추론 서버의 수가 4의 배수가 아니면 GPU 노드 비용이 낭비되는 구성이지만, Pod의 수는 트래픽에 따라 유동적이므로 추측하기 어렵습니다. 따라서 이 실험에서는 무조건 GPU 쪽에 유리하게 계산하였습니다.
로드 테스트를 통해 모델 성능과 비용 비교하기
실제 환경에 도입하였을 때의 비용을 예측하기 위해서는 부하 테스트(load test)가 필요합니다. 하이퍼커넥트에서는 오픈소스 부하 테스트 툴인 nGrinder을 이용하고 있습니다. 본 테스트에서는 가상의 사용자 집단이 요청을 보내는 상황을 가정하고, 서버에 부하가 걸리는 동안의 평균 TPS와 Latency를 측정하였습니다.
프로덕션에서는 두 지표 요건을 모두 만족시켜야 합니다. 따라서 pod 개수를 일치시키고 GPU 노드와 Inferentia 노드에서 Latency가 동일한 상황에서의 TPS를 계산한 후, 각각 동일한 TPS가 될 때까지 pod를 늘렸을 때의 비용 차이를 비교하면 됩니다. 비용이 얼마나 절감되었는지를 뜻하는 절감율은 절감된 비용을 원래 비용으로 나누어 계산합니다.
(비용 절감율은 상댓값이므로 동일 개수의 pod에서 1 TPS당 비용을 비교하는 것으로 계산 가능)
[참고] 이 실험에서는 하이퍼커넥트 서비스의 특성을 고려하여, 요청이 밀리지 않는 수준에서 오랜 기간 동안 균일하게 들어온다고 가정하였습니다. 또한 AI 가속기의 효과만을 비교하기 위하여 네트워크나 IO가 병목이 되지 않는 수준의 트래픽으로 실험을 수행했습니다.
가벼운 모델
다음은 가벼운 추천 모델에서 1개의 pod에 요청하는 가상 사용자 수를 바꾸어가며 테스트해본 결과입니다.
[Table 1. g4dn.12xlarge]
| TPS (1/s) | Latency (ms) | Cost / TPS (USD) |
|---|---|---|
| 102 | 29 | 44.91 |
| 155 | 38 | 29.55 |
[Table 2. inf1.2xlarge]
| TPS (1/s) | Latency (ms) | Cost / TPS (USD) | Cost Reduction Rate |
|---|---|---|---|
| 191 | 31 | 8.20 | 81.7% |
| 307 | 38 | 5.10 | 82.7% |
요청을 평균 30 ms 선에서 처리해야 하는 경우, 비용 절감율은 81.7%입니다. 마찬가지로 요청을 평균 40 ms 수준으로 처리해도 되는 경우에도 비용 절감율은 82.7%로 높습니다.
이는 요청이 많고 가벼운 모델에 AWS Inferentia를 도입한 것만으로도 20%의 비용만으로 같은 트래픽에 같은 품질로 서빙이 가능함을 보여줍니다.
무거운 모델
다음은 무거운 ViT 모델에서 4개의 pod에 요청하는 가상 사용자 수를 바꾸어가며 테스트해본 결과입니다.
[Table 3. g4dn.12xlarge]
| TPS (1/s) | Latency (ms) | Cost / TPS (USD) |
|---|---|---|
| 18 | 670 | 254.5 |
| 28.8 | 833 | 159.06 |
[Table 4. inf1.2xlarge]
| TPS (1/s) | Latency (ms) | Cost / TPS (USD) | Cost Reduction Rate |
|---|---|---|---|
| 72.6 | 659 | 21.57 | 91.5% |
| 73.8 | 811 | 21.22 | 86.6% |
앞선 실험과 마찬가지로 비슷한 Latency 요건을 만족시킬 때, 같은 TPS를 달성하기 위해 필요한 비용을 계산하고 이로부터 비용 절감율을 구하였습니다. 이처럼 무거운 모델에서도 80~90% 대의 높은 절감율을 얻을 수 있었습니다.
실제로 ML Platform 팀에서는 가장 많은 트래픽을 받는 주요 모델들을 AWS Inferentia로 전환하여 75% 전후의 비용 절감 효과를 보고 있습니다. AWS Inferentia는 별도 프레임워크가 아니라 학습된 모델을 컴파일하는 방식이기 때문에, 실제로 이미 서빙하고 있던 모델을 쉽게 이전할 수 있었습니다.
마치며
지금까지 ML Platform 팀에서 머신러닝 모델 서빙 비용을 줄이기 위해 어떻게 AWS Inferentia를 도입하고, 이를 통해 실제로 머신러닝 모델 서빙 비용이 얼마나 낮아지는지 살펴보았습니다.
AWS Inferentia를 도입하는 과정을 요약해보면 다음과 같습니다.
- 학습된 머신러닝 모델을 전용 Neuron 모델로 컴파일하여 저장합니다.
- 저장된 Neuron 모델을 Triton에 배포하여 서빙합니다.
- Neuron Monitor를 통해 지표를 추출하고, 니즈에 맞게 시각화하여 모니터링합니다.
이렇게 변환된 Neuron 모델을 가지고 부하 테스트를 수행하여 GPU 모델과 비교하였습니다. 실험 결과 80%대의 높은 비용 절감율을 얻을 수 있었습니다. 현재 실제로 프로덕션에 AWS Inferentia를 활용하는 모델을 점차 늘려가고 있으며, 그에 따른 비용 절감 효과를 크게 보고 있습니다.
이번 포스트가 AWS Inferentia 도입을 고민하고 있는 분들께 많은 도움이 되었으면 좋겠습니다. 회사 계정을 이용하시는 경우에는, AWS의 TEST and GO 프로그램 을 활용하시면 기술 및 비용적인 면에서 지원을 받을 수 있으니 활용해보시기를 추천드립니다.
긴 글 읽어주셔서 감사합니다!
부록 1 : Throughput과 Latency 개선 방법 공유
Neuron 컴파일러는 AWS Inferentia를 모델에 맞게 튜닝하기위한 Neuron Batching 기능과 NeuronCore Pipeline 기능을 추가로 제공하고 있습니다. 하나하나 어떤 방식인지 살펴보도록 하겠습니다.
Neuron Batching
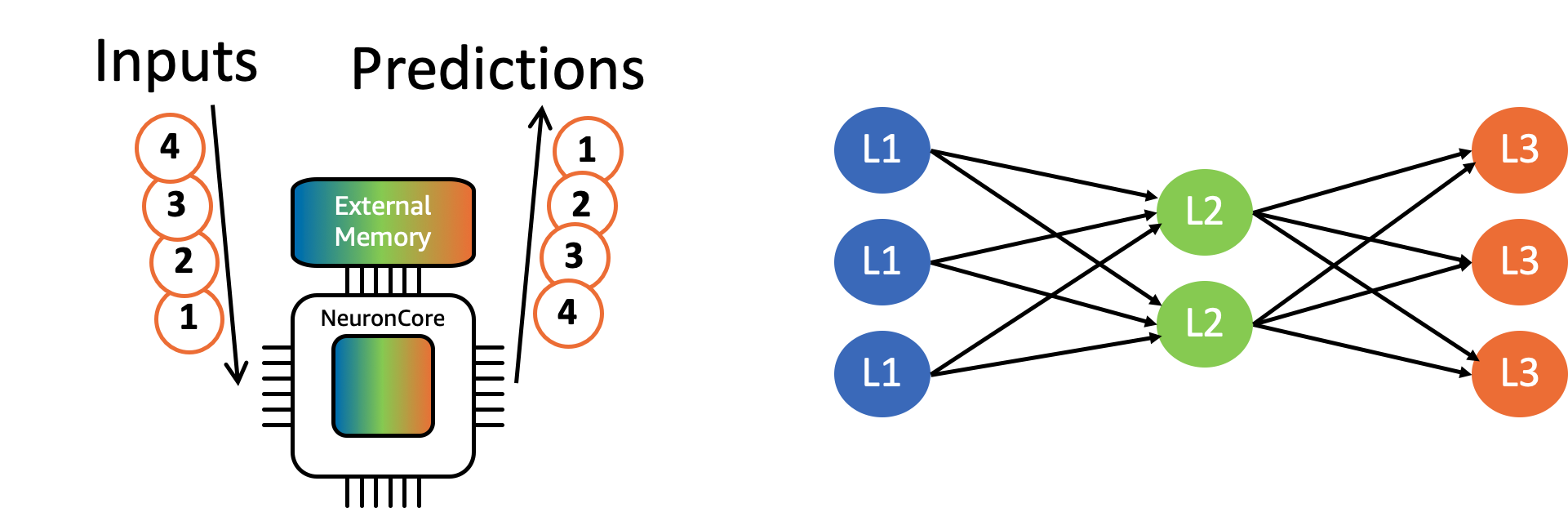
Neuron Batching은 다수의 추론 요청을 묶어서 처리하는 방법입니다. 특정 레이어의 가중치가 메모리에 한 번 로드되었을 때, 여러 개의 입력을 동시에 처리하면 메모리 접근 횟수를 줄일 수 있습니다. 이렇게 하면 여러 입력을 처리해야 하므로 Latency는 나빠지지만, Throughput이 좋아집니다.
다음 그림은 레이어가 3개인 신경망 모델에서 배치의 크기가 4일 때의 동작을 나타낸 것입니다. 현재 레이어를 계산해야 할 때 외부 메모리에 저장된 가중치를 NeuronCore의 on-chip 캐시로 로드하고, 해당 가중치로 4개의 입력을 모두 처리한 후에, 다음 레이어의 가중치를 로드합니다. Batching함으로써 가중치를 로드하는 횟수를 12번에서 3번으로 줄이는 것입니다.
Neuron은 AOT(ahead-of-time) 컴파일러를 사용하기 때문에 배치의 크기를 미리 지정해두어야 하며, 런타임에 변경할 수는 없습니다. 대신 컴파일 시에 dynamic_batch_size=True
옵션을 설정해두면 Neuron 런타임이 주어진 요청의 배치를 자동으로 컴파일 시의 배치 크기로 나누어 계산을 수행합니다.
NeuronCore Pipeline
NeuronCore Pipeline은 모델에 포함된 레이어의 가중치를 여러 NeuronCore에 분산시켜두고 파이프라이닝하며 병렬로 처리하는 방법입니다.
다음 그림과 같이 신경망 모델의 레이어 3개가 각각 다른 NeuronCore의 on-chip 캐시에 로드되면, 개별 NeuronCore는 현재 가중치를 버리고 다음 가중치를 로드할 필요가 없어집니다. 이렇게 되면 메모리 접근에 소요되는 시간이 감소하므로 Latency와 Throughput을 모두 향상시킬 수 있습니다.
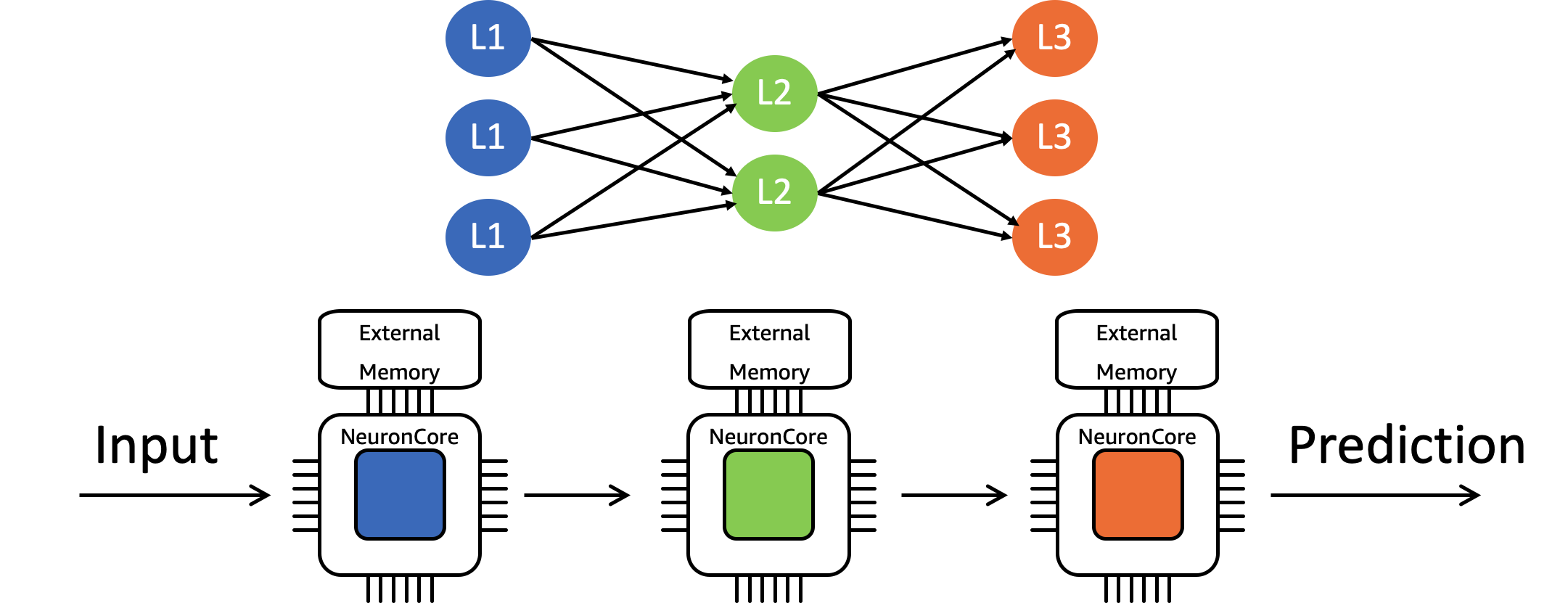
Pipeline과 Batching은 함께 사용할 수도 있습니다. 적절한 배치 크기와 파이프라인 단계 수를 함께 튜닝하면 하드웨어의 성능을 최대한 끌어올릴 수 있습니다. 다양한 조합을 테스트해보면서 최적의 값을 얻으시고 모델의 성능을 개선하는 데 도움이 되기 바랍니다.
부록 2 : AWS Inferentia Neuron 컴파일 경험 공유
우선 Troubleshooting Guide for Torch-Neuron 공식 문서 를 참고하시면 많은 도움을 얻을 수 있습니다.
PyTorch Neuron Import (import torch.neuron or import torch_neuron)
공식 문서에서 나온 에러 메시지 외에도, 변환된 neuron 모델을 이용한 추론 코드를 작성할 때 torch.neuron import를 잊어버리면 정체모를 에러 메시지를 마주치는 경우가 종종 있습니다.
잊지 말고 항상 import 해 주세요!
PyTorch 사용 시의 Python 버전 문제
Torchvision은 Python 3.5 버전에 대한 지원을 중단했습니다. 따라서 이에 해당하는 경우에는 Python 3.6 버전 이상을 쓰는 것이 좋습니다.
Torch-neuron은 컴파일 중간 단계에서 Tensorflow Graph로의 변환을 거치는데, 이 때 사용되는 Tensorflow 버전이 1.15.x입니다. 저희가 AWS Neuron SDK를 이용하여 PyTorch 모델을 컴파일할 때에는 Python 3.8 이상의 버전을 사용할 수 없었으나, Tensorflow 1.15.x 버전이 Python 3.8에서 지원되기 시작하면서 해당 버전에서 torch-neuron을 이용할 수 있게 되었습니다.
Protobuf의 2GB 용량 제한
저희는 다음과 같은 에러로 Neuron 모델로의 컴파일에 실패하는 경우가 있었습니다.
google.protobuf.message.DecodeError: Error parsing message with type 'tensorflow.GraphDef'
확인해본 결과, 2GB를 넘어가는 모델(.pt)의 경우, 컴파일 과정에서 Protobuf의 2GB 제한 때문에 에러가 발생한다는 것을 알게 되었습니다. 즉, 지금의 Neuron SDK는 단일 모델이 너무 큰
경우에는 아직 컴파일을 제대로 지원하지 않습니다.
현재는 AWS Neuron 로드맵의No Status상태이며, 따라서 이 이슈가 해결되기 전까지는 모델을
여러 개의 작은 모델로 분리하여 사용해야 합니다.
TensorFlow 2.x(tensorflow-neuron)에서는 이 이슈가 해결되었습니다.
GPU에서는 동작하고 CPU에서 동작하지 않는 모델의 컴파일
torch.conv1d
torch.conv2d
torch.conv3d
torch.conv_transpose1d
torch.conv_transpose2d
torch.conv_transpose3d
FP16 입력을 받았을 때, CPU에서는 돌아가지 않고 GPU에서만 돌아가는 operator가 있습니다. (위의 예시 참고) FP16을 입력으로 하고 위와 같은 operator를 포함한 모델을 변환할 때는 CPU에서 연산을 수행할 수 없어서 Neuron 컴파일을 진행할 수 없는 문제가 생깁니다.
이러한 경우에는 모델이 FP16 입력에 대해 해당 연산을 수행하지 않도록 수정하여 문제를 우회합니다.
일부 operator의 정밀도 문제
torch-neuron에는argmin,argmax,min,maxoperator의 정밀도에
관한 이슈
가 있습니다. 해당 operator들은 정밀도에 민감하기 때문에 이 경우에는 컴파일러의 최적화 옵션을 잘 사용하면 좋습니다.
Softmax에서의 정밀도 문제
Softmax는 출력값의 합이 항상 1이라는 특성을 가지고 있습니다. 그런데 막상 softmax를 포함한 모델을 Neuron 모델로 컴파일해보면 softmax 출력값의 합이 정확히 1이 되지 않는 문제가 발생할 수 있습니다.
Neuron 모델로의 컴파일 시 대부분 BF16이나 FP16으로 변환이 일어나기 때문에, 정밀도에 관한 문제가 발생할 수 있습니다. 그렇기 때문에, 출력 값들의 합이 1인지 뿐만 아니라, 같은 입력값에 대해 기존 모델과 변환된 모델 각각의 출력값들도 비교해보고 문제가 없는지 꼭 확인해야 합니다.
저희는 앞에서 소개한 것처럼 컴파일러의 최적화 옵션을 끄고 컴파일을 시도했지만, 문제가 완전히 해결되지는 않았습니다. 따라서 문제를 확실히 해결하고 싶다면, softmax operator 부분만 postprocessor로 분리하고 나머지 부분만 컴파일하는 방법 등을 사용합니다.
Torch & torchvision version compatibility
torch와 torchvision의 version compatibility가 맞지 않으면 segfault가 일어나는데, 이는 Inferentia와는 관계는 없지만 실수하기 쉽고 알아차리기 어려우므로 주의해야 합니다.
References
- Amazon Elastic Inference
- Google TPU
- Apple Neural Engine
- Hardware for Deep Learning (ASIC)
- AWS Inferentia
- NVIDIA Triton Inference Server