⚔ Learning with Noisy Labels by Efficient Transition Matrix Estimation to Combat Label Miscorrection
Read this post in Korean
Introduction
오늘날의 ML 모델 성능은 데이터의 양과 퀄리티에 의존적입니다. 따라서 많은 ML 기반 서비스들은 고퀄리티의 데이터를 얻기 위하여 많은 비용을 지불하며 데이터를 레이블링 하고 있습니다. 하지만 언제나 그렇듯, 데이터 레이블링 과정에서 발생하는 “레이블 노이즈 (Label Noise)”를 피할 수 없으며, 이 노이즈에 의한 Noisy Labels는 ML 모델의 성능을 저하시키는 주요 원인이 됩니다.
Hello, world! 저는 AI Lab Machine Learning Research Scientist로 근무 중인 Buru (Buru Chang)입니다! 이번 포스트에서는 앞서 언급하였던 Noisy Labels 문제를 다루는 우리의 연구 내용을 소개하고자 합니다. 해당 연구는 “Learning with Noisy Labels by Efficient Transition Matrix Estimation to Combat Label Miscorrection” 라는 제목의 논문으로 세계 최고 컴퓨터 비전 학회 중 하나인 ECCV (2022)에서 발표될 예정입니다.
Learning with Noisy Labels via Label Correction
“Learning with Noisy Labels \(^{1}\)”는 Noisy Labels에 Robust한 모델을 만드는 학습방법에 대한 연구 분야입니다. 특히 최근 몇 년간, Noisy Labels 외에 저렴하게 얻을 수 있는 적은 양의 Clean Dataset을 추가 학습하였을 때, 모델의 성능을 비약적으로 끌어올릴 수 있음이 이론적 및 경험적으로 증명되고 있습니다\(^2\).
Clean Dataset을 활용한 연구들에는 Noisy Labels의 영향을 줄이기 위한 Loss Correction\(^3\), Sample Re-weighting\(^4\)과 같은 접근법들이 존재하지만, 이번 연구에서 우리는 잘못 레이블된 데이터들을 옳은 레이블로 교정하며 데이터셋의 Noise 정도를 직접적으로 낮추는 Label Correction에 집중합니다. 현재 MAML (Model-agnostic Meta-learning)\(^5\) 기반의 Label Correction 방법들이 좋은 성능을 보여주고 있지만, 다음과 같은 두 가지의 치명적인 단점이 존재합니다.
- 레이블 교정이 잘못되었을지라도, 한번 교정된 레이블은 무조건적으로 옳은 레이블로 취급함.
- 여러 Training Step을 거치는 MAML 기반 방법들은 학습 시간 측면에서 매우 비효율적임.
FasTEN: Fast Transition Matrix Estimation for Learning with Noisy Labels
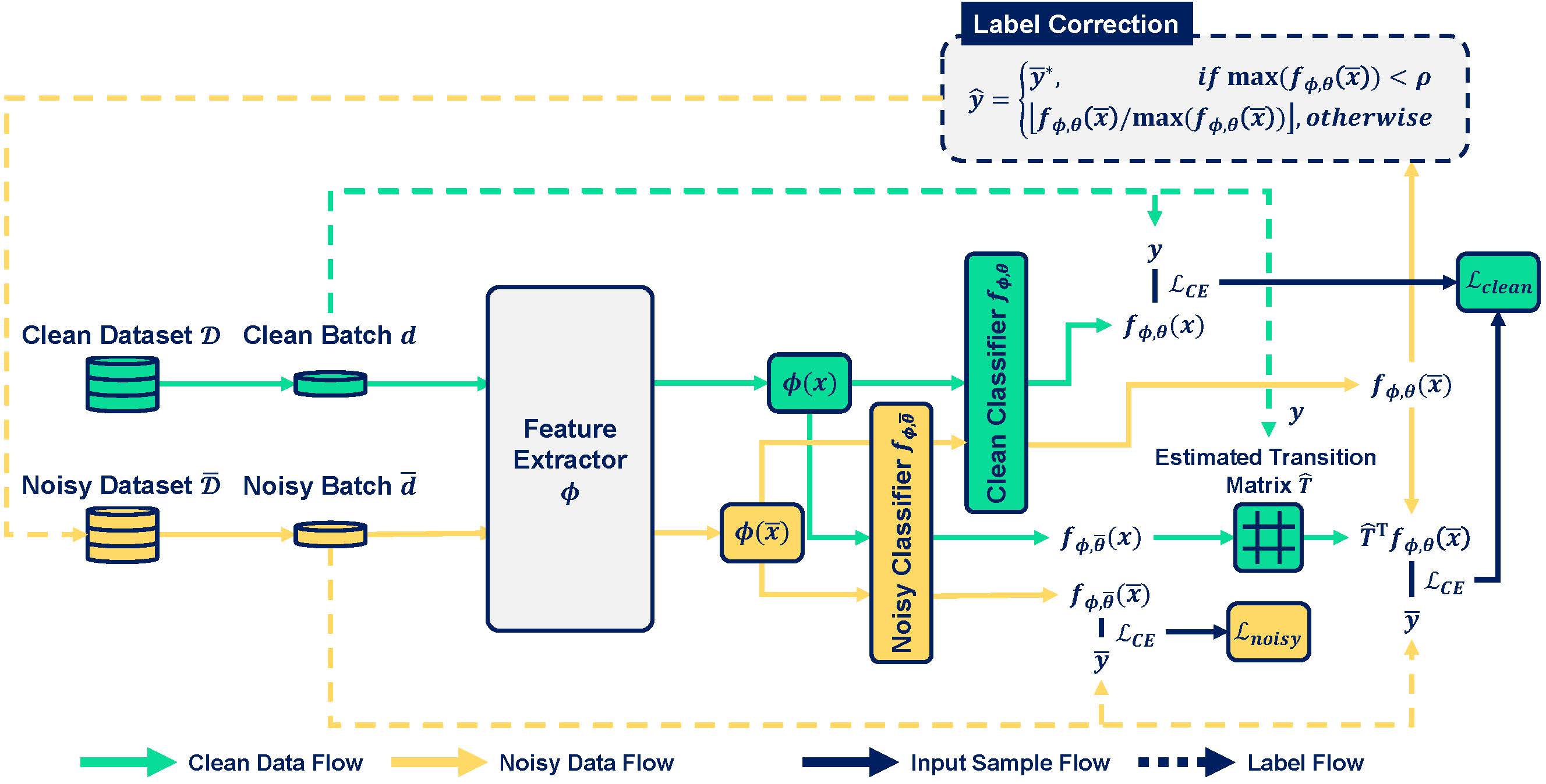
Figure 1. Model architecture of our proposed FasTEN.
앞서 언급된 두 가지 단점을 해결하기 위해 우리는 FasTEN (Fast Transition Matrix Estimation for Learning with Noisy Labels)을 제안합니다. FasTEN은 다음과 같은 장점이 있습니다.
- 레이블 교정이 잘못되었을 수 있음을 끊임없이 의심하며 지속적으로 레이블 교정을 새로 함.
- 효율적으로 Label Transition Matrix를 추정하며 학습 시간을 단축시킴.
아래에서 보다 자세하게 우리가 제안한 FasTEN이 위에서 설명한 두 가지의 장점을 가질 수 있는지 설명하도록 하겠습니다.
Transition Matrix
FasTEN은 Noisy Labels에 대처하기 위하여 Transition Matrix (\(T\))를 활용합니다. Transition Matrix는 \(N\)개의 Class 간 Label Corruption이 어떻게 일어났는지에 대한 (\(N\)x\(N\)) 확률 값을 나타내는 Matrix입니다.
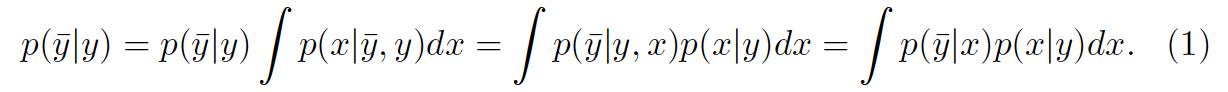
Equation 1. 이번 연구에서 우리는 Transition Matrix를 Instant-independent하다는 가정을 하고 있습니다.
많은 이전 연구들은 Small Clean Dataset을 이용하여 Noisy Labels의 Transition Matrix를 정확하게 추정하고, 추정된 Transition Matrix를 활용하여 Noisy Label에 Robust한 모델을 만들 수 있음을 보여주었습니다. 하지만, 위 Transition Matrix 추정 접근법을 Label Correction 접근법과 함께 사용할 때에는 다음과 같은 어려움이 존재합니다.
- Label Correction 이후 Transition Matrix는 변화함.
- 변화하는 Transition Matrix를 매번 정확하게 추론하기엔 매우 느린 학습 속도.
Label Correction과 Transition Matrix을 함께 활용하기 위해서는, 첫째, Label Correction 이후 Transition Matrix의 변화에 대응할 수 있어야하며, 둘째, 변화하는 Transition Matrix를 빠르게 학습할 수 있어야합니다. 따라서, FasTEN은 끊임 없이 변화하는 Transition Matrix를 효율적으로 추정하는 것을 목표로 합니다.
Efficient Transition Matrix Estimation based on Two-head Architecture
FasTEN은 Small Clean Dataset을 활용하여 Noisy Labels의 Transition Matrix를 추정하기 위해서 두 개의 Classifier, Clean Classifier \(f_{\phi,\theta}\) 와 Noisy Classifier \(f_{\bar{\phi},\bar{\theta}}\)를 활용합니다. 여기서 \(\phi\)는 Feature Extractor, \(\theta\)는 Linear Classifier를 나타냅니다. Clean Classifier는 Noisy Labels \(\tilde{D}\)외에 Small Clean Data \(D\)를 추가적으로 학습에 사용하는 Classifier이며, Noisy Classifier는 오직 Noisy Labels로만 학습하는 Classifier입니다. Transition Matrix는 다음과 같이 Clean Data로 이루어진 Mini-batch \((d \sim D)\)와 Noisy Classifier를 가지고 추정하게 됩니다 (\(\hat{T}\)). .
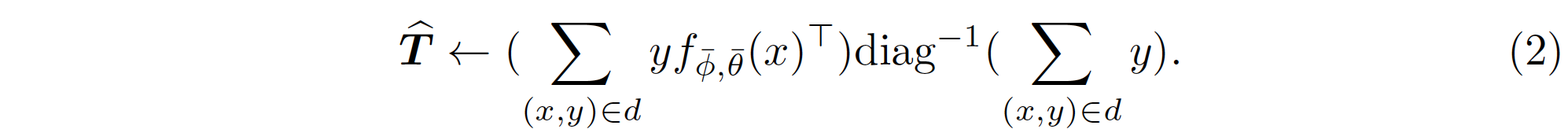
우리는 Clean Data \((x,y)\)의 실제 Label \(y\)를 알고 있기 때문에, Input \(x\)에 대한 Noisy Classifier의 예측 값인 \(f_{\bar{\phi},\bar{\theta}}(x)\)를 함께 이용하여 각 Mini-batch의 Transition Matrix를 추정할 수 있습니다 (\(\hat{T}\)). Clean Classifier는 이렇게 추정된 Transtion Matrix를 활용하여 Noisy Labels를 학습하게 됩니다. 하지만, Clean Classifier를 학습하기 위하여 Noisy Classifier가 Clean Data를 Inference 해야 하는 비효율이 발생합니다. Clean Data는 Clean Classifier를 학습하는 데 사용될 뿐, Noisy Classifier의 학습에는 활용되지 않기 때문이죠.
그렇다면 만약 Clean Data를 Inference하는 과정을 Clean Classifier와 Noisy Classifier가 공유할 수 있다면, Inference에 필요한 연산량을 절약할 수 있습니다. 따라서 우리는 그림 1과 같이 두 Classifier의 Feature Extractor \(\phi\)를 공유하고, 각 Classifier의 Linear Classifier만 구분하는 Two-head Architecture를 활용합니다. Two-head Architecture에서는 Noisy Labels와 Clean Data 모두 한 번씩만 Feature Extractor를 거치면 되기 때문에, 효과적으로 연산량을 절약할 수 있게 됩니다.
최종적으로 두 개의 Classifier를 학습하는 Loss Function은 각각 다음과 같이 정의됩니다.
\[\mathcal{L}_{clean} = \mathcal{L}_{CE}(f_{\phi,\theta}(x),y) + \sum_{(\bar x,\bar y)\in \bar d}(\mathcal{L}_{CE}\Big(\hat{T}^\top f_{\phi,\theta}(\bar x),\bar y\Big)\] \[\mathcal{L}_{noisy} = \sum_{(\bar x, \bar y)\in \bar d}\mathcal{L}_{CE}\Big(f_{\phi,\bar \theta}(\bar x), \bar y\Big)\]Label Correction
Two-head Architecture를 통하여 효율적으로 Transition Matrix를 추정할 수 있게 됨으로써, 우리는 매 Iteration 별로 각 Mini-batch에 대해서 On-the-Fly로 Transition Matrix를 추정할 수 있게 되었습니다. 마찬가지로 FasTEN은 Inference 과정에서 Noisy Labels에 대한 Clean Classifier의 확률 값을 값싸게 계산할 수 있고, 계산된 확률 값을 기반으로 Label을 Correction하게 됩니다. 기존 방식과 다른 점은, 한번 Label Correction이 일어났더라도, 모델이 학습됨에 따라 확률 값이 다르게 계산되고, 모델이 이전에 판단했던 Label Correction과는 다른 판단을 할 수 있기 때문에 FasTEN은 이에 대한 대비책을 마련했다는 겁니다. 따라서 FasTEN은 매 Iteration 별 예측 확률 값이 사전에 설정된 Threshold \(\rho\)를 넘지 못했을 때, 맨 처음 Data Sample에 할당되었던 Original Label (\(y^*\))로 환원합니다. 이 과정을 통해 우리는 이전 Iteration들에서 잘못 Correction된 Label을 새롭게 레이블링할 수 있는 기회를 가질 수 있게 됩니다.
\[\hat y = \begin{cases} \bar{y}^*,& \text{if } \max (f_{\phi,\theta} (\bar{x})) < \rho\\ \lfloor f_{\phi,\theta} (\bar{x}) / \max (f_{\phi,\theta} (\bar{x})) \rfloor, & \text{otherwise} \end{cases}\]Experiments
우리가 제안한 FasTEN의 효과성을 확인하기 위하여, 아래와 같은 데이터셋에서 실험을 진행하였습니다.
Synthetic Noisy Dataset
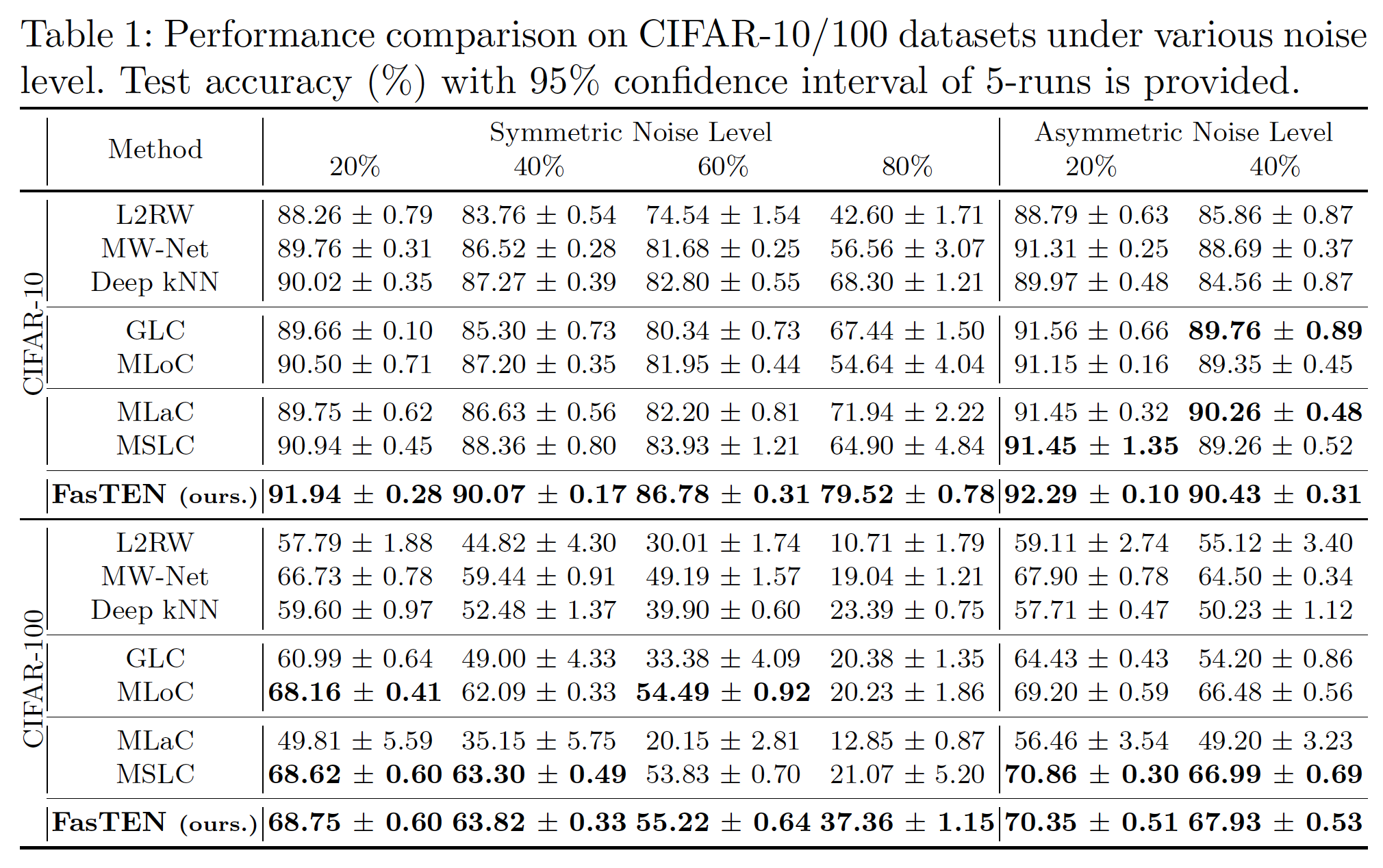
첫 번째 실험은, CIFAR-10/100 Dataset을 인위적으로 Noisy Labels로 만든 Synthetic Noisy Dataset에서의 실험입니다. Clean Dataset을 Noisy Labels로 만들기 위하여 Label Corruption이 Symmetric하게 일어나는 경우와 Asymmetric하게 일어나는 두가지 경우를 가정하여 실험을 진행하였습니다. 두 가지 모든 경우에 대해서 저희가 제안한 FasTEN이 Baseline들보다 좋은 성능을 보였습니다.
Real-world Noisy Dataset

위 실험과 더불어, 우리는 실제 Real-world 상황을 가정하여, Real-world에서 발생한 Label Noise를 포함하고 있는 데이터셋인 Clothing1M\(^6\)에서도 실험을 진행하였습니다. Synthetic Noisy Dataset에서와 마찬가지로 FasTEN은 State-of-the-art의 성능을 거두었습니다.
Training Efficiency
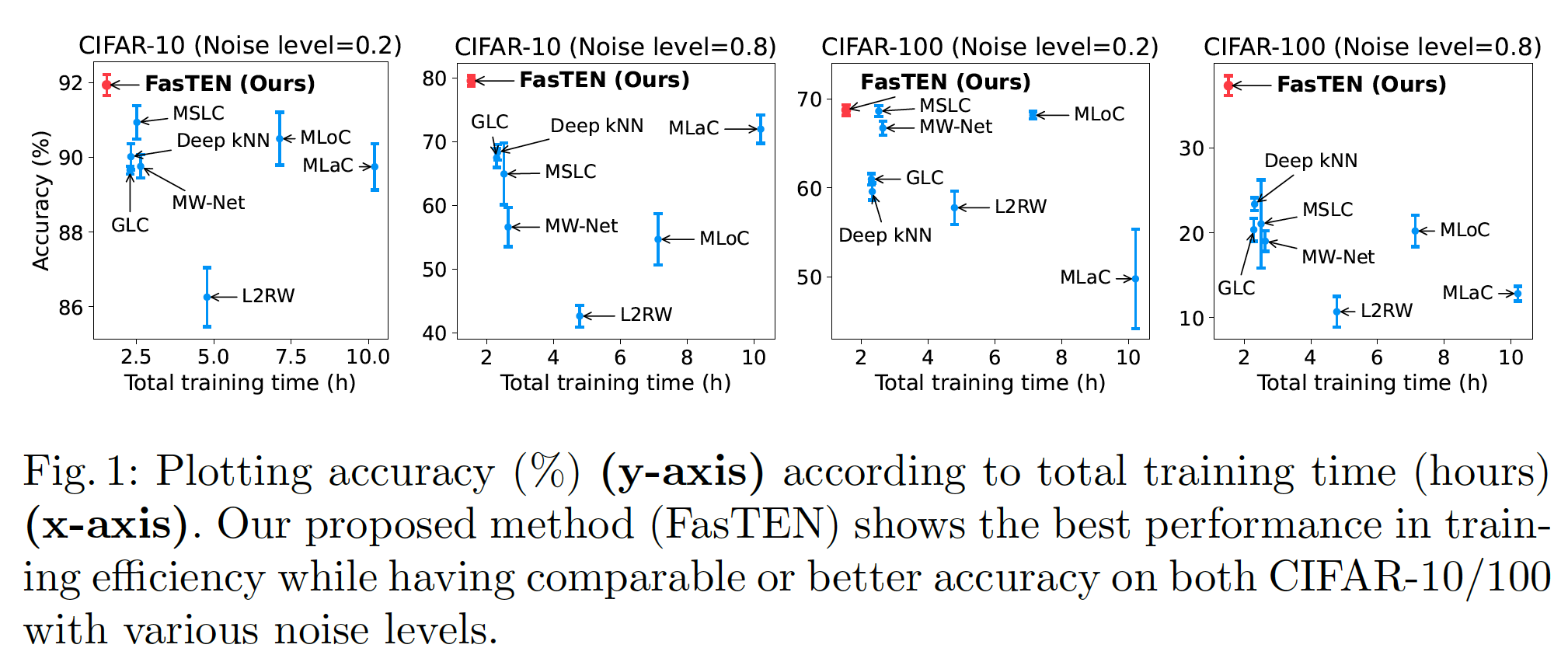
FasTEN이 위 두 실험에서 가장 좋은 성능을 보였는데, FasTEN의 장점은 여기서 끝이 아닙니다. FasTEN은 모델이 최고 성능에 도달하기까지 필요한 학습시간을 Baseline 대비 최대 6.64배 줄일 수 있는 것으로 분석되었습니다. FasTEN은 모델의 학습, 배포의 Iteration을 빠르게 가져가야 하는 Real-world Application에서 큰 기여를 할 수 있을 것으로 기대됩니다.
Conclusion
이번 포스트에서는 ECCV (2022)에서 발표될 Learning with Noisy Labels 방법론인 FasTEN을 소개하였습니다. 하이퍼커넥트는 실제로 Human-in-the-loop 구조의 데이터 레이블링 파이프라인을 구축하여 방대한 양의 데이터를 수집하고 있고, Machine Learning 기술을 통하여 회사의 많은 문제를 풀기 위하여 노력하고 있습니다. 앞으로도 공개될 많은 논문과 테크 블로그를 통하여 다시 찾아뵙도록 하겠습니다. 읽어주셔서 감사합니다.
Introduction
The performance of current machine learning models highly depends on the quantity and quality of the training dataset. Therefore, many machine learning service providers have spent a considerable amount of money constructing datasets through human labor. However, we cannot avoid the issue of “label noise,” which often causes a decline in the performance of machine learning models, when labeling data.
Hello, world! I’m Buru, a machine learning research scientist at the AI Lab. In this blog post, we introduce our research addressing the issue of noisy labels. This research was published at ECCV 2022, one of the top-tier computer vision conferences, in a research paper titled “Learning with Noisy Labels by Efficient Transition Matrix Estimation to Combat Label Miscorrection.”
Learning with Noisy Labels via Label Correction
“Learning with Noisy Labels\(^1\)” is a research topic that aims to build models that are robust to noisy labels. In recent years, it has been shown that models cab be made more robust to noisy labels when a small clean dataset is used in addition to the original dataset\(^2\).
Although there are several ways to reduce the influence of noisy labels by using clean datasets, such as Loss Correction\(^3\) and Sample Re-weighting\(^4\), in this research, we focus on Label Correction, which directly lowers the noise level of the dataset by correcting the noisy labels. MAML\(^5\) (Model-agnostic Meta-learning)-based label correction methods show state-of-the-art performance, but they have the following two shortcomings:
- If noisy labels are mis-corrected, models blindly trust the mis-corrected labels.
- MAML-based methods require multiple steps to train models, leading to time inefficiency.
FasTEN: Fast Transition Matrix Estimation for Learning with Noisy Labels
Figure 1. Model architecture of our proposed FasTEN.
To address the above shortcomings, we propose FasTEN (Fast Transition Matrix Estimation for Learning with Noisy Labels) having the following advantages:
- It remains skeptical of all corrected labels while correcting noisy labels on the fly.
- It efficiently estimates the transition matrix, saving training time.
We describe our proposed FasTEN in detail below.
Transition Matrix
FasTEN leverages the transition matrix (\(T\)) to cope with noisy labels. The transition matrix is an (\(N\)x\(N\)) matrix representing the probabilities of label corruption between \(N\) classes.
(Equation 1. In this study, we assume that the transition matrix is instance-independent)
Many previous studies utilize a small clean dataset to accurately estimate the transition matrix, making models more robust to noisy labels. However, there are some hurdles to applying the estimated transition matrix to label correction approaches.
- The transition matrix changes after label correction.
- The training is too slow to adapt to the transition matrix change.
To apply the estimated transition matrix to label correction, first, methods should adapt to the transition matrix change by label correction. Second, they should train the changing transition matrix efficiently. Thus, FasTEN targets estimating the changing transition matrix efficiently.
Efficient Transition Matrix Estimation based on Two-head Architecture
FasTEN employs two classifiers, Clean Classifier \(f_{\phi,\theta}\) and Noisy Classifier \(f_{\bar{\phi},\bar{\theta}}\), to estimate the transition matrix using the small clean dataset. Here, indicate the feature extractor \(\phi\) and linear classifier \(\theta\), respectively. Clean classifier learns not only noisy labels \(\tilde{D}\) but also small clean data \(D\) further. Noisy classifier learns the noisy labels only. The transition matrix \(\hat{T}\) is estimated with a mini-batch of clean data \((d \sim D)\) and the noisy classifier, as follows:
\(\hat{T}\) denotes the estimated transition matrix.
Since the actual label \(y\) of clean data \((x,y)\) is already known, we could the transition matrix (\(\hat{T}\)) of the mini-batch with the probabilities of the input \(x\) predicted by the noisy classifier \(f_{\bar{\phi},\bar{\theta}}(x)\). The clean classifier learns noisy labels with the estimated transition matrix. But, it is inefficient that the noisy classifier inferences the clean data for the clean classifier since the noisy classifier does not utilize clean data to train itself.
If the procedure of inference on clean data could be shared by the clean classifier and noisy classier, we could save the computation of the inference on the clean data for the noisy classifier. To this end, as shown in Figure 1, we employ the two-head architecture that share the feature extractor \(\phi\) and have two linear classifier heads \(\theta\). Based on the two-head architecture, both clean data and noisy labels are passed to feature extractor only once, and this saves the computation efficiently.
The final objective of training the classifier is defined as follows:
\[\mathcal{L}_{clean} = \mathcal{L}_{CE}(f_{\phi,\theta}(x),y) + \sum_{(\bar x,\bar y)\in \bar d}(\mathcal{L}_{CE}\Big(\hat{T}^\top f_{\phi,\theta}(\bar x),\bar y\Big)\] \[\mathcal{L}_{noisy} = \sum_{(\bar x, \bar y)\in \bar d}\mathcal{L}_{CE}\Big(f_{\phi,\bar \theta}(\bar x), \bar y\Big)\]Label Correction
Through its two-head architecture, FasTEN estimates the transition matrix of a mini-batch every iteration on the fly. Likewise, FasTEN produces the probabilities of noisy labels using the clean classifier, and corrects the noisy labels based on these probabilities. The major difference of our label correction is that FasTEN includes a safeguard against mis-corrected labels. If the predicted probabilities are lower than a pre-defined threshold \(\rho\), FasTEN restores the corrected labels with their original labels (\(y^*\)). This label correction procedure allows us to re-label data that were mis-corrected in previous iterations.
\[\hat y = \begin{cases} \bar{y}^*,& \text{if } \max (f_{\phi,\theta} (\bar{x})) < \rho\\ \lfloor f_{\phi,\theta} (\bar{x}) / \max (f_{\phi,\theta} (\bar{x})) \rfloor, & \text{otherwise} \end{cases}\]Experiments
To verify the effectiveness of our proposed FasTEN, we conducted experiments on the following datasets.
Synthetic Noisy Dataset
The first experiment was conducted on the synthetic noisy dataset artificially constructed from CIFAR-10/100. To turn clean datasets into noisy datasets, we used two label corruption strategies: symmetric and asymmetric. In both cases, our proposed FasTEN outperforms all the baseline methods.
Real-world Noisy Dataset
Additionally, we also conducted experiments on the real-world noisy label datasets, Clothing1M\(^6\), assuming real-world scenarios. FasTEN also show state-of-the-art performance on the real-world dataset.
Training Efficiency
FasTEN performs best in the above two experiments, but its advantages do not end there. We found that FasTEN can save up to 6.64 times the training time required for the model to reach the best performance compared to the baseline methods. FasTEN is expected to make a significant contribution to real-world applications that require fast iteration of model training and deployment.
Conclusion
In this post, we introduced FasTEN, a Learning with Noisy Labels methodology presented at ECCV (2022). Hyperconnect is also building a human-in-the-loop structured data labeling pipeline to continuously improve the models and is heavily leveraging machine learning technology to solve many practical problems that arise in the pursuit of our vision. As part of this process, we will strive for publishing more papers and technical blogs, contributing to the machine learning community with our innovations.
References
[1] https://proceedings.neurips.cc/paper/2013/hash/3871bd64012152bfb53fdf04b401193f-Abstract.html
[2] https://proceedings.neurips.cc/paper/2018/hash/ad554d8c3b06d6b97ee76a2448bd7913-Abstract.html
[4] http://proceedings.mlr.press/v80/ren18a.html