5일 만에 Azar Production Kubernetes cluster 이전하기
안녕하세요, DevOps 팀의 Sammie입니다. 지난 2018년 EKS가 정식 출시[1]되었지만 OIDC options을 설정할 수 없는 [2] 등 몇 가지 기능 제약으로 kops[3]를 사용하여 Azar production cluster를 구축했습니다. EKS가 점점 더 편리한 기능을 제공하게 되면서, EKS로 migration 하기로 결정했습니다.
처음으로 Azar production EKS cluster를 만들어 5일 만에 50개 이상의 모든 production workload를 새 cluster로 이전하는 데 성공했고, workload 이전 다음날부터 정상적인 배포가 진행되었습니다. 이 글을 통해 지난 5일간의 험난한 과정을 공유해드리려고 합니다. 빠른 속도로 migration을 할 수 있었던 이유 중 하나는 클릭 몇 번으로 microservice 배포 시스템을 만들 수 있었기 때문입니다. 아직 microservice 배포 시리즈 글을 읽지 않으셨다면, 한 번 읽어보시는 것을 권장합니다 :)
반복되는 용어를 줄이기 위해 old cluster는 kops로 구축된 기존 cluster를, new cluster는 EKS로 구축된 새 cluster를 가리키는 데 사용했습니다.
Why EKS?
kops에서 EKS로 이전하게 된 이유는 많지만, 다음 두 기능을 사용할 수 있다는 이유가 제일 컸습니다.
- Kubernetes ServiceAccount를 사용하여 IAM role을 사용할[4] 수 있습니다. 기존에는 kube2iam[5]을 사용하고 있었는데, 가끔씩 Pod이 crash되거나 올바른 credentials를 얻어오지 못할 때가 있었고, resource 지정 등 관리 cost가 있었습니다.
- Pod별로 security group을 부여할[6] 수 있습니다. 기존에는 별도의 대안이 없어 Kubernetes node로 사용하는 모든 EC2 instance에 대해 DB 접근을 허용하는 보안 문제가 있었습니다.
Background
본격적인 migration 설명에 앞서 Azar workload의 몇 가지 특징에 대해 공유하겠습니다.
Database
전체 서비스에서 database를 어떻게 사용하는지 확인합니다.
Azar 서버의 핵심인 API 서버는 하나의 큰 RDS를 사용하고 있습니다. 기능이 microservice로 분리되며 중앙 RDS의 의존도가 낮아지고 있지만, 여전히 요청을 처리하는데 중요한 database입니다.
Traffic Domain & ACL
어떤 domain으로부터 user traffic을 받는지 파악해야 합니다. 또한, domain별 접근제어가 어떻게 구성되어 있는지 알아야 합니다.
이미지, 실시간 media streaming을 제외한 거의 대부분의 요청은 단일 domain에서 처리됩니다. Office 등 특정 IP에서 접근 가능한 domain은 조금 더 많지만, 20개를 넘지 않으며 대부분 hard-coding 되어 있지 않습니다.
Push & Batch
중복처리가 발생하지 않도록 push 및 batch 서비스를 확인합니다.
Android, iOS device에 push notification을 보내주는 다양한 push 서버가 존재합니다. 이 서버들은 주기적으로 외부 데이터 저장소로부터 정보를 가져와 push를 전송하기 때문에, 중복되어 배포된 수만큼 중복 push를 보내게 됩니다. 따라서, push 서버는 old 또는 new cluster 중 하나에만 배포되어 있어야 합니다.
Microservice
Microservice를 전부 확인하고, 배포 pipeline을 검토합니다.
글의 제일 처음에서도 언급했지만, 모든 microservice는 DevOps팀에서 생성한 Spinnaker[7] pipeline을 통해 배포됩니다.
- Spinnaker pipeline은 DevOps팀이 개발한 시스템과 template file로부터 자동으로 생성됩니다.
- Container image는 cluster와 독립적인 Harbor[8]에 업로드됩니다.
- Secret을 제외한 모든 Kubernetes manifest는 git repository와 Helm[9] chart를 사용하여 생성됩니다.
- Secret은 cluster와 독립적인 Vault[10]에 저장되며, secret-sync라는 작은 Pod이 Vault를 읽어 Kubernetes Secret으로 저장합니다. 또한, Prometheus와 Consul을 제외하고는 persistent volume을 사용하지 않으며, 모든 데이터는 cluster와 독립적인 RDS, DynamoDB, Elasticache, S3 등에 저장됩니다.
Mission Critical
SPOF 또는 약간의 performance 저하에도 아주 민감하게 반응하는 workload를 확인합니다.
Azar에서는 연결을 원하는 사용자를 받아 최적의 조합을 계산하는 match 서버가 존재합니다. 사용자 match는 실시간으로 처리되어야 하며, 최적의 match를 얻기 위해서는 가능한 모든 조합을 계산하여 정렬하여야 하므로 match 서버는 정확히 1개입니다. Match 서버를 2개 배포하고, traffic을 분산한다면 같은 match 서버에 요청을 보낸 사용자끼리만 만나게 됩니다. 따라서, match 서버의 canary test는 불가능합니다. 오직 API 서버에서만 match 서버로 요청을 전송하기 때문에, 다음과 같은 모습입니다.
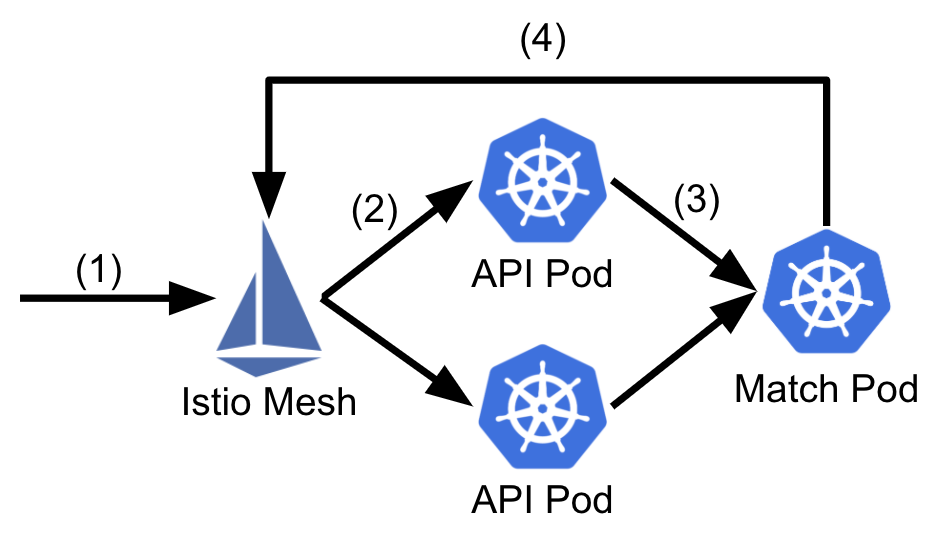
- 사용자가 match 요청을 서버로 전송합니다.
- Istio[11] mesh가 random 한 API 서버를 찾아 요청을 전달합니다.
- API 서버는 요청을 확인 한 뒤 match 서버에 데이터를 전달합니다.
- Match 서버는 match 결과를 asynchronous 하게 API 서버로 전달합니다.
Edge Proxy
Traffic control이 가능한 edge proxy의 설정과 service traffic flow를 확인합니다.
Kubernetes가 없었던 시절, canary 배포 및 EC2 기반 API 서버 배포를 위해 HAProxy를 사용하고 있었습니다. 현재도 HAProxy를 사용 중이며, API 서버 traffic은 application load balancer (ALB)를 통과하여 EC2 기반의 HAproxy[12]로 전송됩니다. 그다음 HAProxy에서 Istio ingressgateway[13]로 연결되는 internal ALB로 traffic을 전송하게 됩니다. 그림으로 표현하면 다음과 같습니다.

Planning
계획에 앞서, 배포된 microservice를 분류했습니다. 실제 traffic을 받기 전 테스트 기기로 핵심 기능을 검증하겠지만, 여전히 canary test를 수행해야 하기 때문입니다. In-memory에 state를 가지고 있는 match 서버 같은 경우 old cluster와 new cluster로 traffic이 나누어지면 안되며, push 서버 같은 경우 2개 이상으로 배포되는 것 자체가 장애를 발생시킬 수 있기 때문입니다. 따라서, microservice를 다음과 같은 4가지 타입으로 분류했습니다.
- A. Stateless 하여 몇 개가 배포되어도 상관없는 서비스 (a.k.a 평범한 microservice)
- B. Stateless 한 서비스이나, Stateful 한 서비스를 참조함 (예: API 서버)
- C. Stateful 한 서비스 (ex: match 서버)
- D. 2개 이상 배포되어서는 안 되지만, 잠시 꺼져도 상관없는 서비스 (ex: push 서버)
다행히도, B, C, D는 예시로 든 서비스를 제외하고는 해당되는 다른 microservice가 없었습니다. 따라서, 앞 단락에서 살펴본 특징을 사용해 downtime이 없도록 이전 계획을 세울 수 있었습니다.
- EKS cluster 생성 및 인프라 설정: EKS cluster를 생성하고, ALB ingress controller 등 infra 관련 workload를 배포합니다.
- Vault 복사 및 동기화: Old cluster에 영향을 주지 않도록 Vault에 저장된 secret을 복제합니다.
- Helm values.yaml 설정 수정: Microservice manifest를 생성하는 데 사용할 설정 파일을 수정합니다.
- IAM role trusted relationships 추가: New cluster의 EC2 instance IAM role이 다른 IAM role을 사용할 수 있도록 합니다.
- Spinnaker pipeline 추가: New cluster에 배포할 수 있도록 Spinnaker pipeline를 생성합니다.
- New cluster에 평범한 microservice 배포 및 match 서버 배포: Push 서버를 제외한 모든 microservice를 배포합니다.
- 테스트 기기로 new cluster 테스트: 전 단계에서 배포한 microservice가 잘 동작하는지 확인합니다.
- 배포 금지 기간 설정: 이 시점부터 개발자의 배포가 제한됩니다.
- Vault, values.yaml, IAM roles, Spinnaker pipeline 다시 동기화: 1~7단계를 수행하는 동안 변경된 사항을 다시 적용합니다.
- New cluster에 평범한 microservice 및 match 서버 배포: 9 단계에서 동기화된 내용으로 다시 배포를 수행합니다.
- Old cluster의 match 서버로 요청을 전송하도록 API 서버 설정 변경: Match 서버로 보내는 traffic을 분산시켜서는 안 됩니다.
- 테스트 기기로 new cluster 최종 테스트 및 로그 확인: Canary test 직전 한 번 더 확인합니다.
- Old cluster 지표와 연관된 모든 alarm 중지: Slack에 notification이 쌓이지 않도록 각종 alarm을 중지시킵니다.
- HAProxy를 사용하여 canary 수행: 1%부터 조금씩 canary 비율을 늘려봅니다.
- New cluster로 100% traffic이 전송되도록 HAProxy 설정 수정: Canary test가 통과하면 100% traffic을 받도록 합니다.
- 평범한 microservice의 DNS record 변경: 외부에서 직접 접근하는 microservice의 DNS record를 업데이트합니다.
- New cluster의 API 서버가 new cluster의 match 서버로 요청을 전송하도록 설정 변경 및 blue-green 재배포
- New cluster의 지표를 보도록 alarm을 수정하고, 다시 활성화: 퇴근 후 장애가 생겼을 때 인지할 수 있도록 빠르게 alarm을 켭니다.
- Old cluster에서 push 서버 삭제 후 new cluster에 push 서버 배포: 중복 발송되어서는 안 되므로 반드시 삭제 후 생성합니다.
- Vault, values.yaml, Spinnaker pipeline을 모두 new cluster로 변경: Old cluster를 new cluster 설정으로 덮어씁니다.
- 개발자의 배포 허용: 이 시점부터 개발자가 자유롭게 배포할 수 있습니다.
- Old cluster 관련 설정 및 cluster 제거: Spinnaker나 Vault 등에서 관련 설정을 제거하고, 백업 후 cluster를 삭제합니다.
여러 가지 타입의 microservice가 섞여있고, 배포 금지 기한을 최대한 줄이기 위해 migration 과정이 상당히 길어졌습니다. 아래 단락부터 하나씩, 자세히 공유해보겠습니다.
Day 1 ~ 3
Provision EKS Cluster (Step 1)
Cluster 이전을 결정한 다음 날, 출근하자마자 new cluster를 생성하고 ALB ingress controller를 배포하는 등 infra 관련 작업을 시작했습니다.
Hyperconnect에서 EKS cluster와 nodegroup 관리는 전부 Terraform으로 구성되어있습니다. EKS Terraform module [14]을 기반으로 작성한 내부 module을 사용하고 있습니다. Instance가 종료되거나, node group spec이 변경될 때 pod이 안전하게 drain 될 수 있도록 scaling hook을 설정하는 등 많은 부분을 개조했습니다. 또한, 대부분의 infra 관련 workload를 하나의 Helm charts로 묶어 관리하고 있습니다. Terraform Helm provider[15]을 사용하여 terraform apply를 통해 Helm charts를 설치 / 업그레이드하고 있습니다. 다음 infra workload를 주로 사용합니다.
- Istio: https://istio.io/
- Fluentd: https://www.fluentd.org/
- Pomerium: https://www.pomerium.io/
- Prometheus: https://prometheus.io/
- Cluster autoscaler: https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler
- Kubernetes dashboard: https://github.com/kubernetes/dashboard
- EBS CSI driver: https://github.com/kubernetes-sigs/aws-ebs-csi-driver
- EFS CSI driver: https://github.com/kubernetes-sigs/aws-efs-csi-driver
- kube2iam: https://github.com/jtblin/kube2iam
- ALB ingress controller: https://github.com/kubernetes-sigs/aws-alb-ingress-controller
- ExternalDNS: https://github.com/kubernetes-sigs/external-dns
- Reloader: https://github.com/stakater/Reloader
다른 product의 production cluster나 dev, stage cluster를 생성하면서 겪은 시행착오를 통해 많은 부분을 모듈화 할 수 있었습니다. 그 결과, 작업 몇 시간 만에 cluster를 생성할 수 있었습니다.
Deploy, Deploy, Deploy! (Step 2 ~ 7)
이제 old cluster에 존재하는 모든 microservice를 new cluster에 배포하고, 정상적으로 배포되었는지 확인해야 합니다. 이 기간에는 개발자가 old cluster에 자유롭게 배포할 수 있어야 하므로, 데이터나 설정을 수정할 때는 복제 후 수정했습니다.
Prepare
Vault (Step 2)
Microservice 배포에 관한 이전 글과 이 글의 앞부분에서 secret-sync를 설명드렸습니다. 모든 Kubernetes Secrets는 Vault 데이터를 사용하여 생성되므로, 기존 Vault 데이터를 다른 path에 복제한 다음 secret-sync가 복제된 path를 바라보도록 설정하면 됩니다.
Helm values.yaml (Step 3)
secret-sync에 의해 동기화되는 Secret을 제외한 모든 microservice Kubernetes manifest는 Helm charts와 몇 개의 values.yaml으로부터 생성됩니다. 모든 values.yaml 파일은 DevOps팀이 관리하는 한 개의 중앙 git repository에 저장되어 있으므로, 쉽게 수정할 수 있습니다. 같은 production 환경에서의 cluster migration이므로 거의 모든 내용은 그대로 사용하였으나, domain이 변경되면서 Istio Gateway host 설정을 조금 변경했습니다. Vault와 마찬가지로 old cluster 배포에 영향을 주지 않기 위해 별도의 branch로 작업했습니다.
IAM trust relationship (Step 4)
다른 cluster와 동일한 규칙으로 EC2 instance IAM role을 사용하기 위해, new cluster는 old cluster와 다른 IAM role을 사용합니다. 따라서, kube2iam을 사용하여 assume 하는 모든 role의 trust relationship을 수정해주어야 합니다. 이 IAM role은 Terraform으로 관리되지는 않았으나, 10개 정도밖에 되지 않아 손으로 빠르게 작업했습니다.
Spinnaker (Step 5)
먼저 Spinnaker 설정에 new cluster 인증 정보를 추가하여 new cluster를 연결시켰습니다. Old cluster는 azar-prod라는 이름으로 연동되어 있으므로, new cluster는 azar-prod2라는 이름을 사용했습니다.
그다음으로는, new cluster에 배포할 수 있는 Spinnaker pipeline을 생성해야 합니다. 다행히 모든 배포 pipeline을 자동으로 생성하는 시스템이 있어 Spinnaker pipeline을 하나씩 복사하지 않아도 됐습니다.
from models import MicroService, Stack, PipelineTemplate
template = PipelineTemplate.objects.get(name='deploy')
for microsrv in MicroService.objects.filter(product__name='azar'):
prod_stack = microsrv.stacks.filter(name='prod').first()
if not prod_stack:
continue
prod2_stack, created = Stack.objects.update_or_create(name='prod2', micro_service=microsrv)
prod2_stack.pipelines.add(template)
(1) Azar에 사용되고, (2) production pipeline이 존재하는 모든 microservice에 prod2 pipeline을 생성하는 간단한 코드입니다. 이 코드를 python manage.py shell을 통해 실행한 다음, 동기화 로직을 trigger 해서 몇 분만에 pipeline을 모두 생성했습니다. 코드 실행 시점 기준으로 70+개의 microservice의 prod2 pipeline이 생성되었습니다.
Deploy & Test (Step 6 ~ 7)
가장 오랫동안 수행한 작업이지만 가장 공유할 내용이 없는 작업이기도 합니다. 앞서 생성한 pipeline을 하나씩 실행하여 정상적으로 배포되었는지 확인했습니다. 빼먹거나 오타가 발생한 작업을 다시 수행하면서 livenessProbe와 readinessProbe를 모두 통과하도록 만들었습니다. 그다음에는 테스트 장비를 가져와서 Azar의 핵심 기능이 정상적으로 수행되는지 확인했습니다.
화요일 오후, 처음으로 API 서버의 health check OK를 확인하고, 수요일 오전에 핵심 기능이 모두 정상 작동한다는 사실을 확인했습니다. 이제 실제 traffic을 받는 일만 남았습니다.
Day 4
Canary Test (Step 8 ~ 14)
이제 실제 traffic을 받아 볼 차례입니다. old cluster와 new cluster에 배포된 버전이 다르면 장애가 생겼을 때 문제를 정확히 확인하기 힘들어, 이 단계부터는 개발자의 배포를 금지시켰습니다.
Re-deploy (Step 9 ~ 10)
DevOps팀이 new cluster를 테스트하는 중에도 개발자는 열심히 설정을 변경하고, old cluster에 새 버전을 배포했습니다. 그동안 변경된 모든 설정을 new cluster에 다시 한번 적용했습니다.
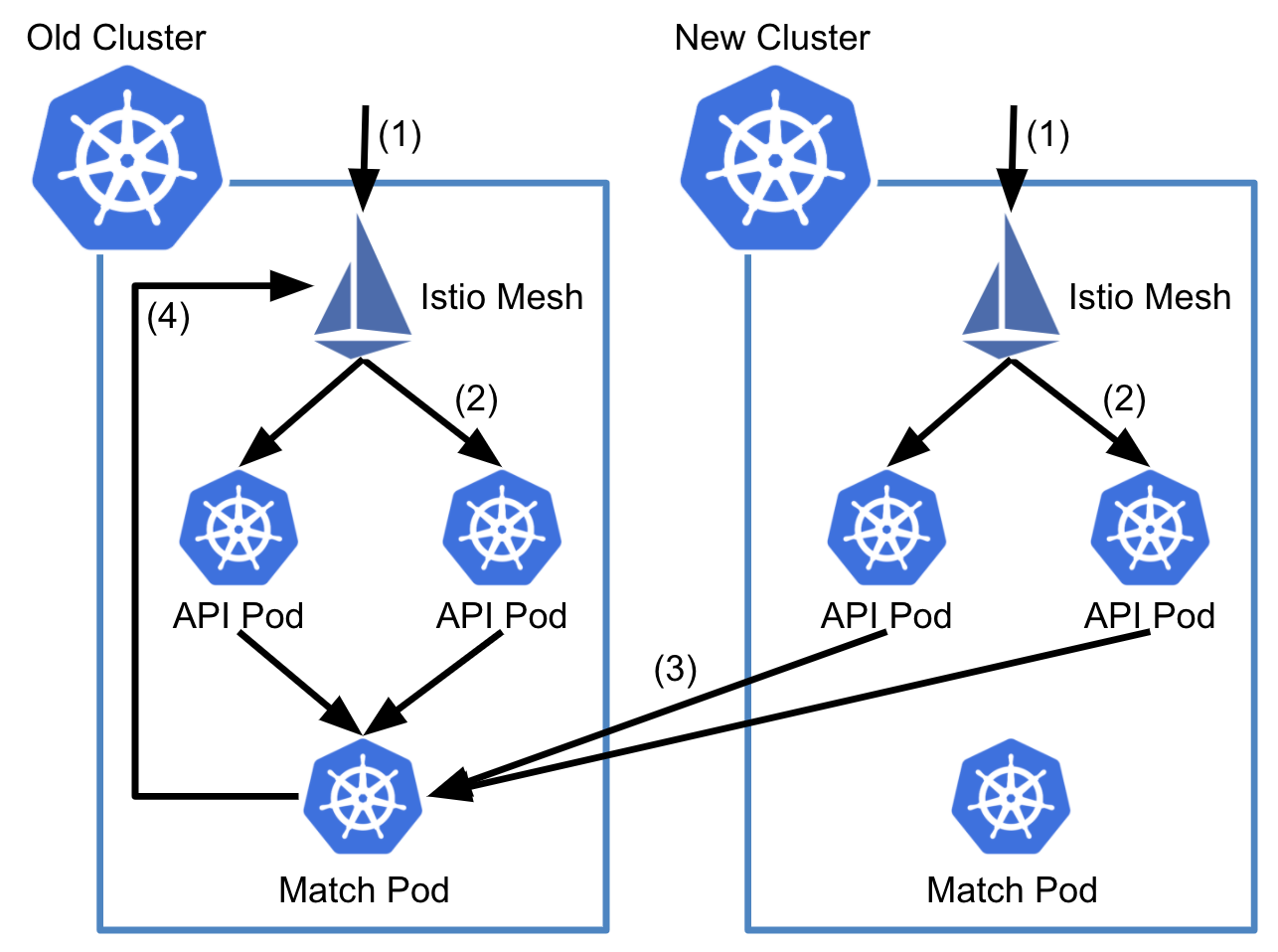
API -> Match (Step 11)
글의 제일 처음에 소개해드렸던 것과 같이, match 서버는 반드시 하나만 존재해야 합니다. 두 개의 match 서버에 traffic이 분산될 경우 서로 다른 match 서버에 할당된 사용자끼리는 만날 수 없기 때문입니다. 따라서, 아래 그림처럼 new cluster의 API 서버는 old cluster의 match 서버로 요청을 전송하도록 설정하였습니다.
Canary Test (Step 14)
본격적인 설명에 앞서, Kubernetes가 없던 시절 canary 배포 등을 위해 EC2 기반의 HAProxy를 사용하고 있다고 소개해드렸습니다. 모든 사용자 요청은 제일 먼저 이 HAProxy로 routing 되므로, HAProxy 설정을 조금 고쳐 쉽게 canary를 만들 수 있었습니다.

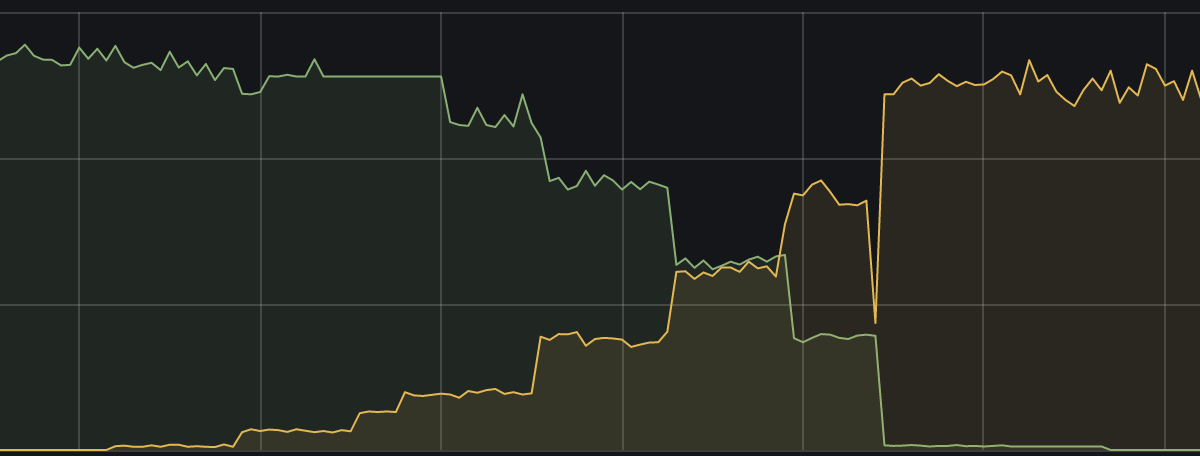
이제 traffic을 조금씩 넣어보았습니다. 설정한 canary rate에 정확히 비례하여 HAProxy session rate이 늘어나는 것을 확인할 수 있습니다. 다행히도 오류 없이 100% 전환에 성공했습니다.
Migrate All (Step 15 ~ 19)
이제 match 서버와 push 서버를 제외하고는 100% 전환되었으므로, 후속 작업을 할 차례입니다.
DNS Records (Step 16)
Cluster를 이전하면서 새 subdomain을 생성했으므로, 대부분의 경우 별도 작업 없이 새로 생긴 도메인을 사용하면 되었습니다.
- 대부분의 microservice끼리의 통신은 Kubernetes 내부 주소 (
<service>.<namespace>.svc.cluster.local)를 사용합니다. - Backoffice 등 내부 주소는 적절한 방법으로 공지하여 이전할 필요 없이 새 도메인을 사용하면 됩니다.
다만, 극소수의 microservice는 API 서버를 통과하지 않고 직접 client나 다른 외부 server에서 접근하므로, 이 DNS record만 업데이트하면 되었습니다. 10개도 되지 않아 금방 업데이트할 수 있었습니다.
Match Server (Step 17)
New cluster의 API 서버는 여전히 match 요청을 old cluster의 match 서버로 전송하고 있습니다. 이제 new cluster의 match 서버로 전송하게 변경해줘야 합니다. 이때, 설정을 변경하고 API 서버 Deployment를 rolling-update 할 경우, 업데이트가 진행되는 동안 match 요청이 old cluster와 new cluster로 나뉘어 들어가게 됩니다. 따라서, red-black (blue-green) 배포를 수행해야 했습니다.
- 현재 존재하는 모든 API 서버 Pod에
match: oldlabel을 붙입니다. - API 서버 Service의 labelSelector에
match: oldlabel을 추가합니다. - Match 서버의 주소는 Kubernetes Secret에 저장하고 있습니다. Secret을 복제하고 데이터를 수정합니다.
- API 서버의 Deployment를 복제합니다. 3에서 복제한 Secret을 참조하도록 volumes spec을 변경하고, pod의 label에
match: new를 추가하여 배포합니다.
이 과정이 끝나면, 정확하게 아래와 같은 상태가 됩니다. 파란색 Deployment가 match: old label을 가지고 있고, 빨간색 Deployment가 match: new label을 가지고 있습니다. 빨간색 Deployment를 배포하기 전 2단계에서 Service의 labelSelector를 match: old로 설정했으므로, 빨간색 Deployment로는 traffic이 들어가지 않습니다.

이제 API 서버의 labelSelector를 match: new 로 변경합니다. 그 즉시 모든 traffic은 빨간색 Deployment로만 유입되며, new cluster의 match 서버를 사용하게 됩니다. 안정된 지표를 확인 한 뒤, 다시 다음 순서로 Deployment를 삭제하면 됩니다.
- 기존 Deployment (파란색)이 참조하는 설정을 변경하여 new cluster의 match 서버를 사용하게 한 후 rollout 합니다.
- API 서버 Service의 labelSelector에서
match: newlabel을 삭제합니다. - 임시로 띄운 Deployment (빨간색)을 삭제합니다.
이렇게 red-black 배포를 수행하여 사용자 경험의 저하 없이 match 서버를 이전했습니다.
Push Server (Step 19)
20개 정도의 microservice가 push 서버와 연관되었습니다. 몇 분간 수행되지 않아도 문제가 없는 batch 작업이라 단순하게 이전했습니다.
- Old cluster에서 먼저 replica를 0으로 만듭니다.
- 모든 Pod을 종료된 것을 확인 한 뒤, new cluster로 배포합니다.
- LivenessProbe, ReadinessProbe를 통과했는지 확인하고, 다음 microservice에 대해서 작업을 수행합니다.
Push 서버를 전부 이전하고 나니, 어느덧 퇴근 시간이 다가왔습니다. 밤 사이 장애 발생을 대비하여 각종 alarm을 켜고 퇴근했습니다.
Day 5
Cleanup (Step 20 ~ 22)
개발자가 직접 배포를 할 수 없는 시간이 길어지면 당연히 좋지 못하므로, 출근 후 즉시 설정 변경 작업을 진행했습니다.
Settings (Step 20)
개발자가 정상적으로 배포할 수 있게 하기 위해서, old cluster에 영향을 주지 않도록 복제한 모든 데이터를 다시 돌려놓아야 했습니다.
- Spinnaker:
azar-prod와azar-prod2의 cluster 정보를 서로 바꾸고 재시작했습니다. - Vault: 복제한 Vault secret을 old cluster가 사용하는 path에 덮어썼습니다. secret-sync는 old cluster가 사용하는 path를 보도록 설정했습니다.
- Helm values.yaml: 간단하게, 작업용 branch를 master에 merge 했습니다.
그 후 배포가 잘 되는지, 올바른 secret을 사용하는지 확인하고, 내부 도구에 대한 몇 가지 작업을 추가로 수행했습니다. 어느덧 정오가 되었고, 이제부터 정상적으로 배포할 수 있다는 공지를 올렸습니다.

이렇게 5일간의 cluster migration이 성공적으로 끝났습니다.
Destroy (Step 22)
혹시 모를 장애를 대비하여 주말 동안 old cluster를 유지했고, 다음 월요일에 몇 가지 작업을 수행했습니다.
prod2stack을 삭제하고, Spinnaker pipeline도 삭제했습니다.- 더 이상 사용하지 않는, 복제된 Vault secret를 삭제했습니다.
- Infra workload를 위한 Helm chart를 적용하기 전, 수동으로 apply 했던 YAML manifest를 전부 삭제했습니다.
그리고 무엇보다 신나는 명령어를 입력했습니다.
$ kops delete cluster
TYPE NAME ID
load-balancer kubernetes.azarlive.com api-azar-prod
volume a-1.etcd-events.kubernetes.azarlive.com vol-xxx
volume a-1.etcd-main.kubernetes.azarlive.com vol-xxx
volume a-2.etcd-events.kubernetes.azarlive.com vol-xxx
volume a-2.etcd-main.kubernetes.azarlive.com vol-xxx
volume b-1.etcd-events.kubernetes.azarlive.com vol-xxx
volume b-1.etcd-main.kubernetes.azarlive.com vol-xxx
...
Must specify --yes to delete cluster
그렇게 old cluster는 파괴되었고, JIRA ticket이 완료 처리되었습니다.
Wrap Up
이번 cluster migration에서 핵심적인 내용을 적어보자면 다음과 같습니다.
- 50+개의 microservice로 구성된 Azar production cluster를 kops에서 EKS로 이전했습니다.
- 자동화된 cluster provisioning 도구 및 배포 pipeline를 이용해서 5일 만에 이전할 수 있었습니다.
- Kubernetes와 무관한 EC2 based HAProxy를 사용해서 canary test를 쉽게 할 수 있었습니다.
- Stateful 한 microservice를 이전하기 위해 red-black 배포를 사용했습니다.
- Batch job들은 몇 분 정도의 downtime이 발생했습니다.
분량 문제와 보안 문제로 더 자세히 설명하지 못해 아쉽지만, production cluster를 downtime 없이 이전해야 하는 상황에서 도움이 되었으면 좋겠습니다.
긴 글 읽어주셔서 감사합니다 :)
언제나 글 마지막은 채용공고입니다. 이렇게 재미있는(?) 일을 같이할 DevOps와 Backend 개발자분들의 많은 지원 부탁드립니다. 채용공고 바로가기
References
[1] https://aws.amazon.com/blogs/aws/amazon-eks-now-generally-available/
[2] https://github.com/aws/containers-roadmap/issues/166
[3] https://github.com/kubernetes/kops
[4] https://docs.aws.amazon.com/eks/latest/userguide/iam-roles-for-service-accounts.html
[5] https://github.com/jtblin/kube2iam
[6] https://docs.aws.amazon.com/eks/latest/userguide/security-groups-for-pods.html
[9] https://helm.sh/
[10] https://www.vaultproject.io/
[11] https://istio.io/
[13] https://istio.io/latest/docs/tasks/traffic-management/ingress/ingress-control/
[14] https://registry.terraform.io/modules/terraform-aws-modules/eks/aws/
[15] https://registry.terraform.io/providers/hashicorp/helm/latest
Read more
-
1년 동안 Workload의 절반을 ARM64로 Migration하기
AWS에서는 ARM64 기반의 Graviton processor를 지원합니다. 가격도 저렴하고 성능도 좋은 Graviton을 production Kubernetes cluster에 도입하여, 1년 동안 50%의 workload를 전환한 경험을 공유합니다. -
JVM + Container 환경에서 수상한 Memory 사용량 증가 현상 분석하기
Resource 최적화를 진행하면서 Java container에 할당된 CPU를 줄이자, memory 사용량이 증가했습니다. 신기한(?) 현상을 분석해보았습니다. -
개발자의 AWS 권한을 GitOps로 우아하게 관리하는 방법
많은 개발자가 가지는 많은 권한을 쉽게 관리하고, 개발자가 필요한 권한을 직접 얻을 수 있게 권한 시스템을 설계하고 GitOps 기반 도구를 개발한 과정을 소개합니다. -
ImagePullSecrets 없이 안전하게 Private Registry 사용하기!
ImagePullSecrets 없이 편리하고 안전하게 private registry를 사용 할 수 있도록 Kubelet Credential Provider 기능을 실험해보았습니다.