Kubernetes에 Microservice 배포하기 2편 - Pipeline 복제하기
안녕하세요, DevOps 팀의 Sammie입니다. 저번 글 - Kubernetes Microservice 배포하기 1편에서는 CI/CD pipeline의 전반적인 내용을 다루었습니다. 이번 글에서는 Hyperconnect에서 사용하는 Helm chart와 Spinnaker pipeline 생성에 대해 좀 더 자세히 공유해보려고 합니다.
아래에서 설명할 pipeline 생성 도구는 Python과 Django[1]로 만들어져 있습니다. 기본적인 기능만을 사용하지만, 둘 다 사용해본 적이 없다면 글을 읽는 데 약간의 어려움이 있을 수 있어 양해 부탁드립니다. 또한, 핵심적인 코드만 적었으므로 그대로 복사 + 붙여넣기를 하면 작동하지 않을 수 있습니다.
Helm
Kubernetes에 resource를 생성하기 위해서는 YAML manifest나 이와 유사한 데이터가 필요합니다. Helm[2]은 Kubernetes 용 package manager로 배포에 필요한 resource를 하나로 묶고 (charts), 상태를 추적하여 배포 또는 롤백을 쉽게 할 수 있도록 도와줍니다. 배포에 필요한 YAML manifest을 생성할 때, 코드의 재사용성을 높이기 위해 go template[3] + sprig template[4] 기반의 강력한 template engine을 사용 할 수 있습니다.
1편에서 언급했듯이, Hyperconnect에서는 Spinnaker를 사용하고 있습니다. Spinnaker는 Helm chart와 values.yaml 파일을 받아 (1) rendering 하여 artifact를 생성하고, (2) 이를 바로 Kubernetes에 배포하는 기능을 제공합니다. 즉, Spinnaker로 다음 command line을 수행 할 수 있습니다.
helm template <chart> --values <values-file> > artifact.yaml(artifact 생성)kubectl apply -f artifact.yaml(artifact 배포)
또한, Spinnaker는 배포된 Kubernetes resource의 상태 확인 기능을 제공하므로 Helm 자체의 배포 및 롤백 기능을 사용할 필요가 없습니다. 따라서, Hyperconect에서는 Helm을 순수한 template engine으로만 사용합니다.
Helm Charts
Hyperconnect에서는 2개의 Helm charts를 만들어 아래 resource manifest를 생성하는 데 사용하고 있습니다.
Deployment | StatefulSet | DaemonSet | CronJob | JobConfigMapHorizontalPodAutoscalerPodDisruptionBudgetServiceVirtualService (istio)DestinationRule (istio)Gateway (istio)RequestAuthentication (istio)AuthorizationPolicy (istio)
이 charts에 적용되는 몇 가지 규칙은 다음과 같습니다.
- 예외 없이 모든 microservice가 2개의 charts를 사용합니다. 왜 2개를 사용했는지는 3편 - Canary 배포에서 다루겠습니다.
- 개발자가 작성해야 하는 boilerplate를 최소화합니다. 예를 들어 Deployment의
spec.selector의 경우app: (microservice 이름)으로 통일 시켜 개발자가 신경 쓸 필요가 없게 합니다. - 작성하지 않았을 때 Pod이 정상 작동하지 않는 경우에만 필수 항목으로 만듭니다. 예를 들어,
image나containerPort가 있습니다. 나머지는 일단 기본값을 부여하고, 값을 수정 할 수 있도록 제작합니다.
Helm Chart를 만든 이유
Kubernetes Deployment나 Service manifest에는 개발자가 느끼는 boilerplate가 생각보다 많습니다. DevOps 관점에서는 당연히 지정해야 하는 spec.selector도 개발자의 관점에서는 하나의 boilerplate입니다. 또한, Hyperconnect의 microservice가 공통으로 가지고 있는 성질로 인한 boilerplate도 상당히 많습니다. 예를 들어, port의 개수나 protocol이 같다면 Istio의 많은 설정 역시 동일합니다. Logging sidecar를 사용하는 microservice 수십 개는 resources만 조금씩 다른 동일한 container spec을 공유하고 있습니다.
이런 boilerplate를 최소화하고, 개발자가 최소한의 지식으로 빠르게 배포 할 수 있도록 Helm chart를 만들게 되었습니다. 아쉽게도 chart 전체를 공개할 수는 없지만, boilerplate를 없애기 위한 노력과 여러 번의 기능 추가 및 버그 수정 요청을 통해 얻은 몇 가지 교훈을 공유하자면 다음과 같습니다.
Lessons
List vs Map
Hyperconnect에서는 Helm charts에 사용할 values.yaml 파일을 작성할 때, 재사용성을 높이기 위해 모든 stack에 적용되는 공통 values.yaml과 각 stack에만 적용되는 <stack>-values.yaml 파일을 만들어서 사용합니다. 예를 들어, dev 환경에 배포할 때에는 values.yaml 파일과 dev-values.yaml 파일을 사용하며, prod 환경에 배포할 때에는 values.yaml 파일과 prod-values.yaml 파일을 사용합니다. 이때, <stack>-values.yaml 파일의 설정이 values.yaml 파일의 설정을 덮어쓰게 했습니다. 따라서, 모든 stack에 공통적으로 적용되는 대부분의 설정을 values.yaml에 넣고, <stack>-values.yaml에는 최소한의 설정만 override하고 있습니다.
그런데, PodTemplateSpec[5]의 env, volumeMounts 등 핵심적인 많은 부분은 list 형태로 되어있습니다. Helm values에서 list 형태의 값은 map 형태의 값과 다르게 전체가 override 되므로 값의 일부분만 재사용할 수 없습니다. 예를 들어, values.yaml에 20개의 environment variable이 정의되어 있고, prod 환경에서는 딱 하나의 값만 변경하고 싶은 상황이라도, prod-values.yaml에 나머지 19개의 environment variable을 다시 적어줘야 합니다.
이를 방지하기 위해 env나 volumeMounts 등을 map 형태로 작성하도록 Helm charts를 제작하였습니다. 다만, 순서에 영향을 받는 일부 spec을 주의해야 합니다. 예를 들어, env가 다른 env를 참조할 경우에는 먼저 정의된 env만 참조 할 수 있습니다. map 형태로 바꾸면 list로 rendering 되는 순서를 보장할 수 없어 추가적인 engineering이 필요합니다.
Options
metadata.labels와metadata.annotations, 그리고 pod template의 labels와 annotations는 당장 사용하지 않더라도 직접 값을 추가 할 수 있게 하는 것이 좋습니다.- 큰 규모의 cluster나 production 환경에 배포하는 경우에는
nodeSelector,tolerations,affinity설정을 사용하게 되므로 처음부터 구성할 수 있게 만드는 것이 좋습니다. terminationGracePeriodSeconds와lifecycle.preStop은 Pod이 트래픽 유실 없이 종료 할 수 있도록 설정하는데 필요하므로 기본값을 잘 설정하거나 구성할 수 있게 만들어야 합니다.
Version
Deployment같이 Kubernetes API spec을 크게 변경하지 않고 옮겨놓은 같은 경우라면 설정값이나 방법이 크게 변경될 일이 없습니다. 하지만 고도로 추상화하여 chart를 작성한 경우, values.yaml 파일에 version을 명시하도록 charts를 만들면 추후 migration과 관리에 도움이 됩니다. 예를 들어, Hyperconnect에서 사용하는 Istio resource은 대부분이 boilerplate이고, 개발자가 설정하는 부분이 거의 없어 해당 부분은 고도로 추상화되어 있습니다. 이런 경우 istioConfigVersion: v1 처럼 버전을 명시적으로 작성하고, template에도 if-else로 처리하도록 만들면 검색이나 정규식을 사용하여 한 번에 migration 하거나 관리하기 쉽습니다.
물론 Helm template을 잘 설계하여 spec을 장기간 변경하지 않거나, microservice마다 사용하는 chart version을 다르게 관리하거나, 개발자에게 values.yaml 작성을 완전히 위임하는 경우에 이 방법을 사용하면 오히려 복잡도가 증가합니다. 다만 Helm chart 도입 초창기에는 이를 하기 어려우니, 임시로 사용할 만한 방법이라 생각하여 적용했습니다.
Pipeline Details
Spinnaker UI를 통해 pipeline을 구성 할 수 있습니다. Stage를 생성하고 연결하는 과정은 직관적이어서 문서를 읽지 않아도 쉽게 만들 수 있었습니다. 아래 UI screenshot에서 보이는 것처럼 “Add stage” 버튼을 눌러 새 stage를 만들고, “Type”을 선택하고, “Depends On”을 설정하여 다른 stage를 지정하면 됩니다.
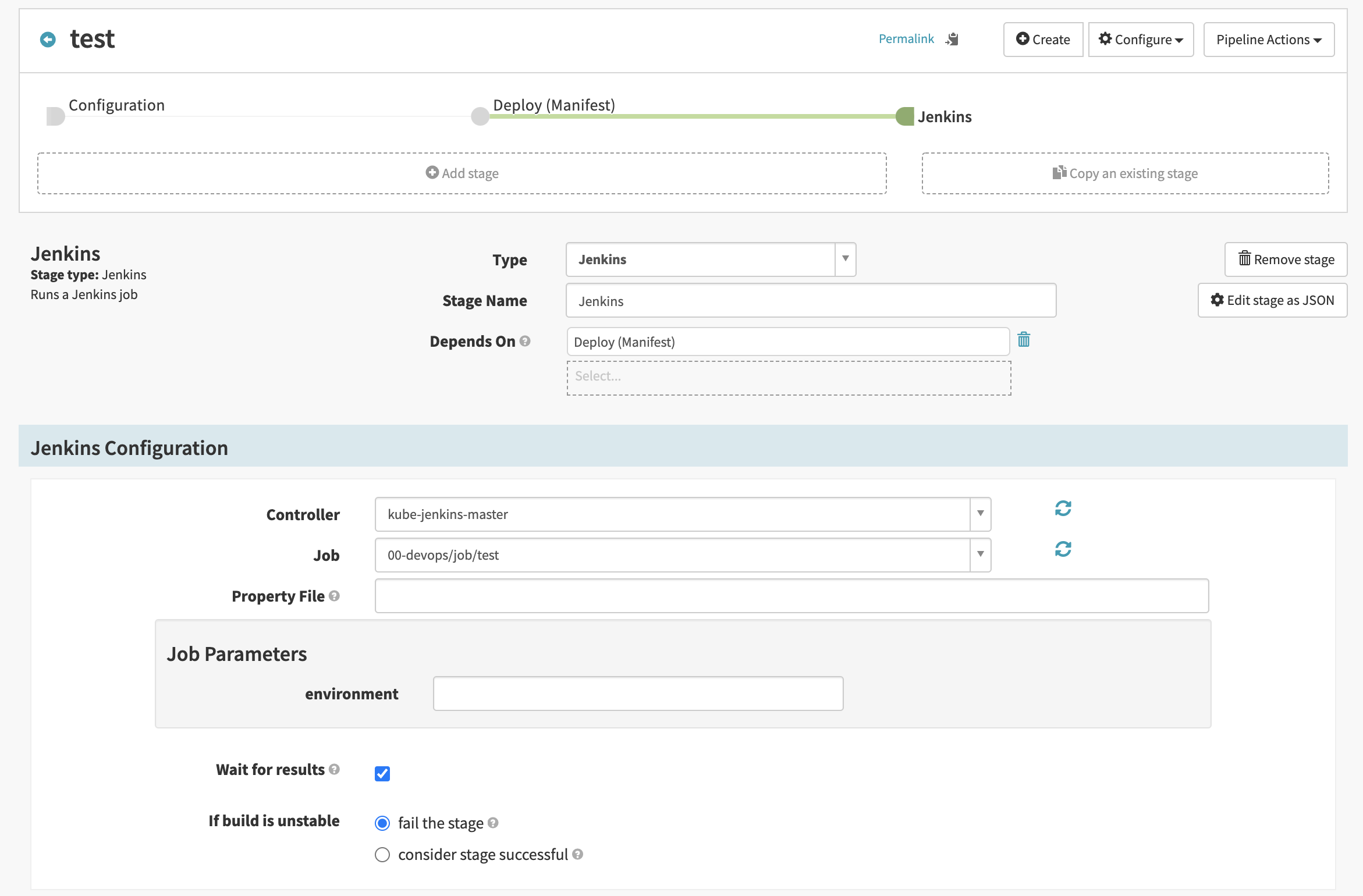
이렇게 만든 pipeline의 전체 모습을 1편에서 잠깐 소개했었는데, 이번 글에서는 stage 하나하나 자세히 설명하려고 합니다. 먼저, 가독성을 위해 pipeline 전체 모습을 다시 보여드리겠습니다.

Step 0: Configuration
각종 parameters, triggers 및 artifacts를 정의 할 수 있는 단계입니다. 일반적으로 배포에 필요한 내용입니다.
- Parameters: 배포할 버전, 빌드 및 배포할 소스 코드 git repo의 branch,
values.yaml이 들어 있는 git repo의 branch를 받습니다. 이 외에도 Slack message에 보여줄 배포 사유 같은 것도 입력받습니다. - Triggers: 일부 microservice의 배포를 자동화하기 위해 webhook 또는 git hook 기반 trigger를 설정했습니다.
- Artifacts: 위에서 생성한 Helm charts 2개와 공통
values.yaml및<stack>-values.yaml을 가져오도록 만들었습니다.
Step 1: Build Image
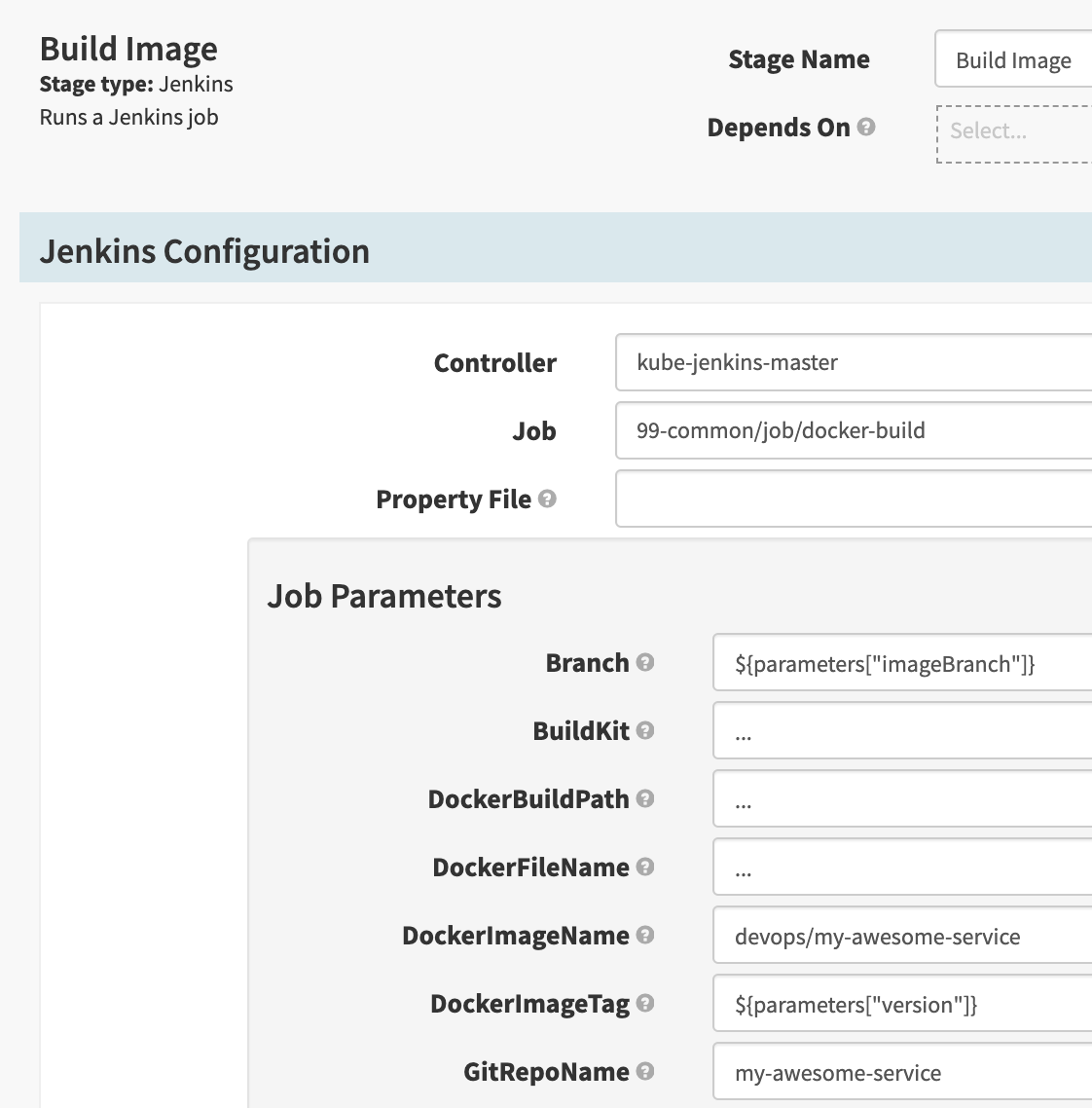
Jenkins를 사용하여 build 합니다. Spinnaker는 Jenkins 연결을 기본으로 지원[6]합니다.
- Jenkins 안에 있는 99-common 폴더의 docker-build라는 job을 실행시킵니다. 이 job은 docker image를 build하고, Harbor에 업로드 하도록 구성되어 있습니다.
- SpEL 기반의 expression[7]을 사용해서 입력받은 Spinnaker parameter를 Jenkins job parameter로 넘겨줄 수 있습니다.
- 만일 build가 실패하거나, Harbor 업로드 과정에서 오류가 발생한다면 job은 실패합니다. Job이 실패한다면 stage를 실패 처리되며 pipeline 실행이 중지됩니다.
Step 2: Bake
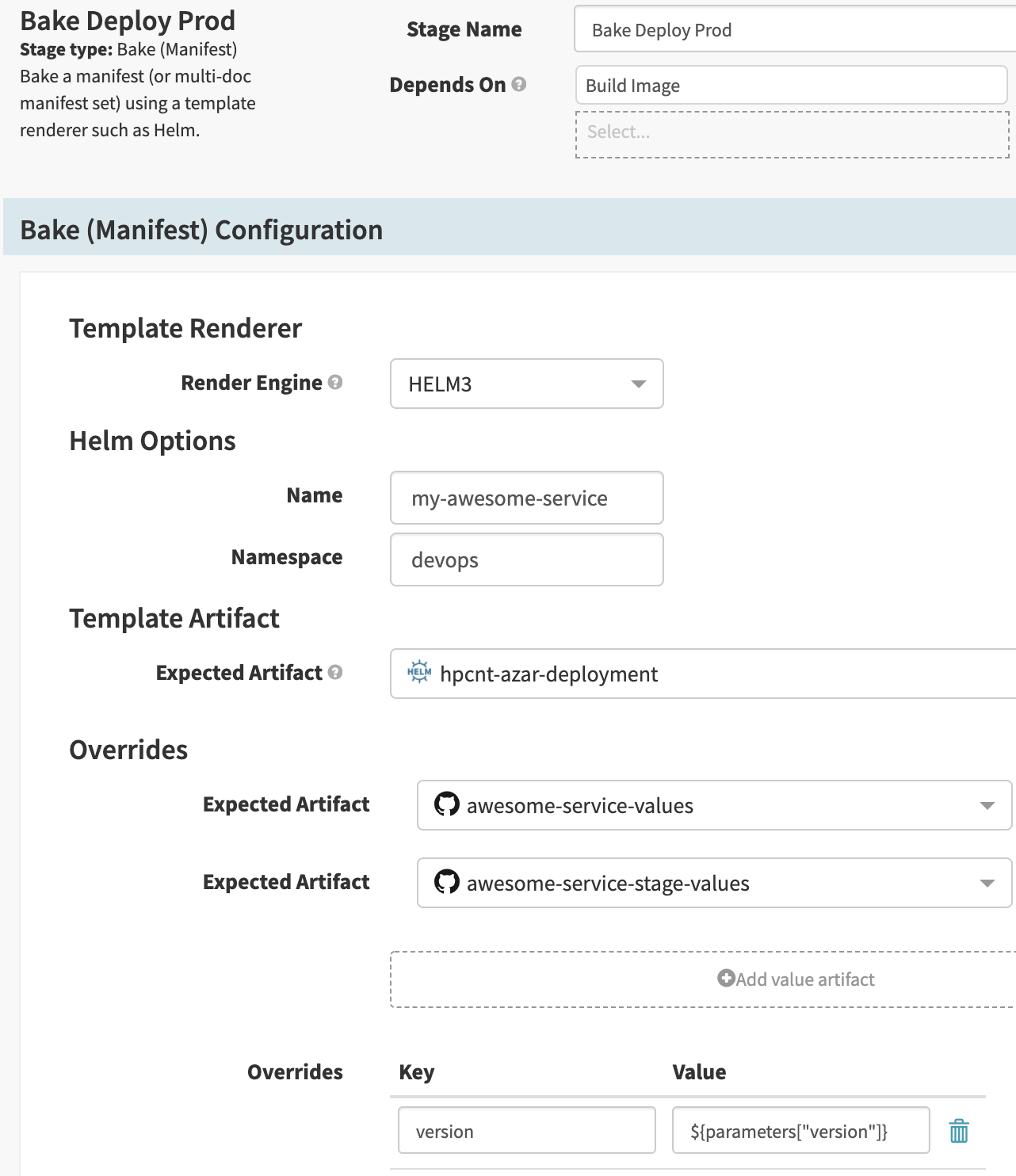
Helm을 사용해서 Kubernetes YAML manifest을 생성합니다. Stage type을 Bake (Manifest)로 선택합니다.
- 이름과 namespace를 입력 할 수 있습니다. Helm charts에서는
.Release.Name과.Release.Namespace로 받게 됩니다. - Overrides에는
values.yaml을 여러 개 지정 할 수 있습니다. 아래 지정된 파일이 가장 나중에 적용되므로, 겹치는 내용이 있다면 아래 파일의 우선순위가 높습니다. values.yaml외에 직접 key-value 쌍을 지정 할 수 있습니다. 여기에서도 Spinnaker expression을 사용 할 수 있으며 가장 나중에 적용됩니다. 이 기능을 사용해서 Deployment image version을 지정했습니다.
그리고 하단의 Produces Artifact를 지정하여 rendering 된 manifest를 artifact로 추출합니다.
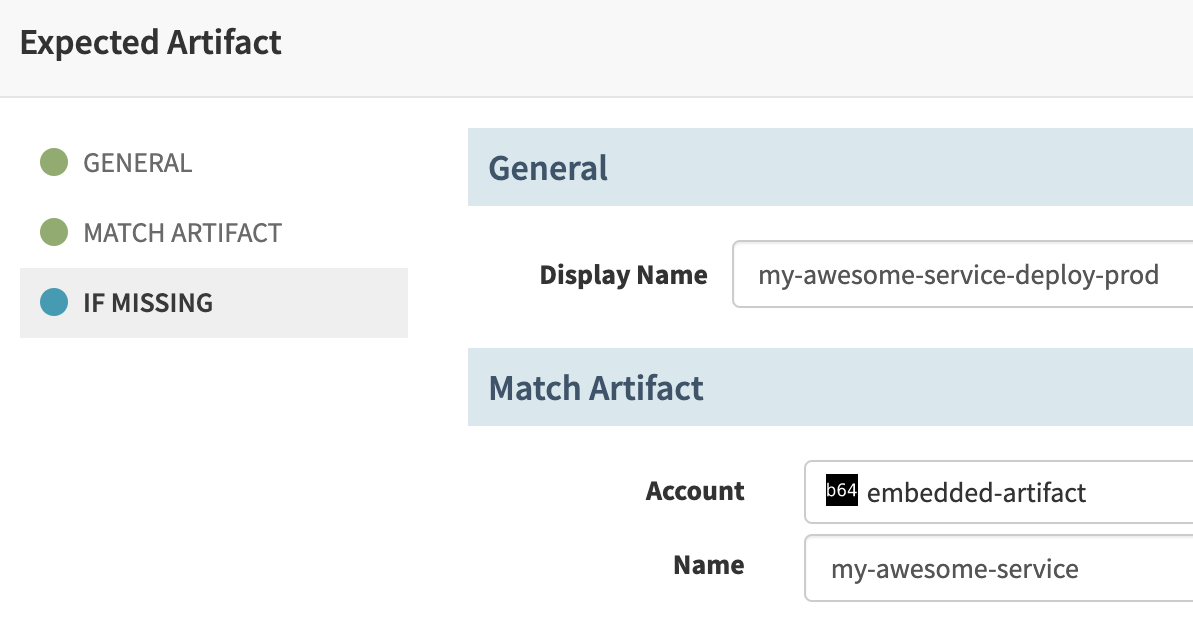
Step 3: Deploy
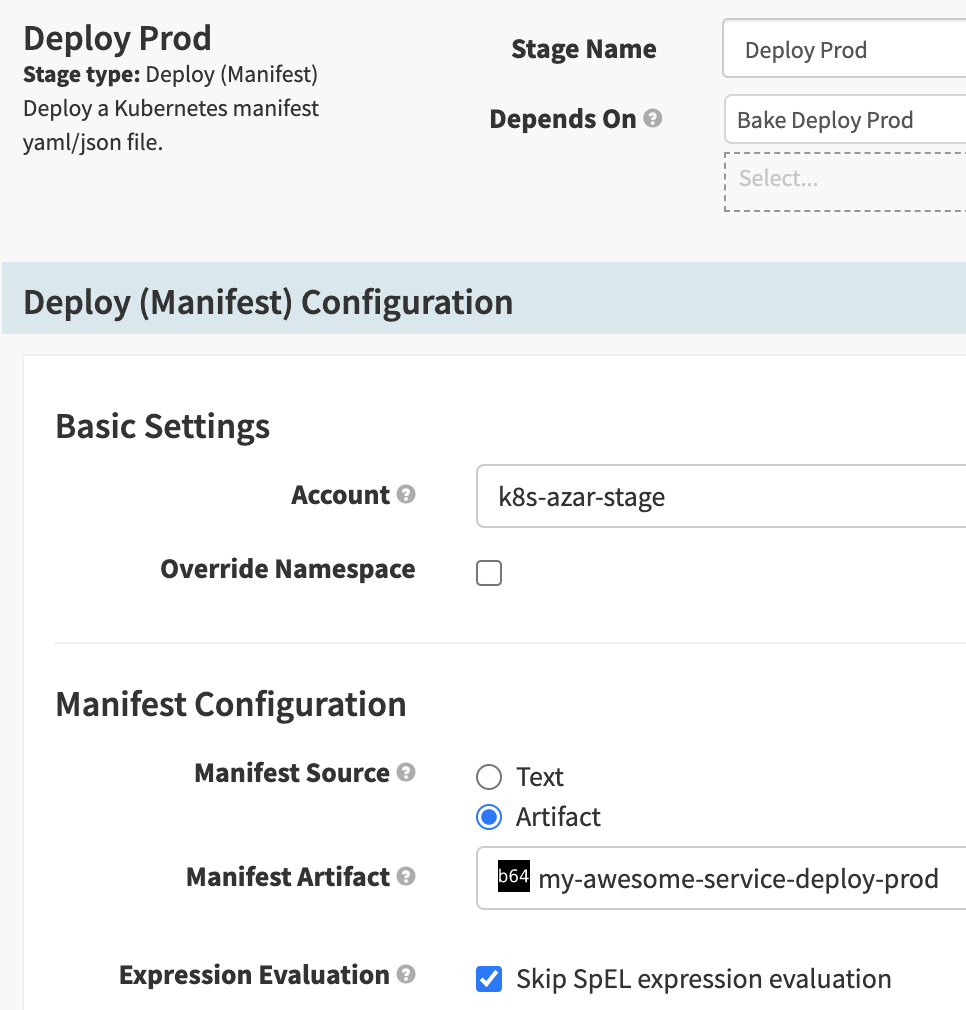
앞서 생성한 artifact를 배포합니다. Stage type을 Deploy (Manifest)로 선택합니다.
- 이 stage에서 마침내
kubectl apply ...명령이 실행됩니다. - Accounts에는 미리 설정한 Kubernetes cluster 중 하나를 선택해야 합니다. 문서[8]를 참고하여 쉽게 설정 할 수 있습니다.
- Rendering 된 YAML manifest에 string이나 ConfigMap 데이터가 있고, 우연히
${같은 SpEL 형태의 문자열이 들어가 있다면 Spinnaker가 이를 계산하려고 시도하며 오류가 발생합니다.Skip SpEL expression evaluation옵션을 켜서 계산하지 않도록 할 수 있습니다.
Step 4-5: Bake and Deploy Service
앞서 생성한 나머지 1개의 charts에 대해서 step 2와 step 3을 반복합니다.
Others
Pipeline의 뒷부분은 canary 배포 종료 시 진행되는 step으로, 3편에서 소개해드리겠습니다.
Pipeline Generation 자동화
앞 단락에서 작동하는 pipeline을 만들었습니다. Pipeline이 1~2개라면 앞 단락에서처럼 UI를 통해 만들고 복사해도 문제가 없지만, 50개 이상의 service가 4가지 이상의 서로 다른 stack (dev, qa, stage, production 등)의 pipeline을 제작하려면 UI만으로는 한계가 있습니다. 복사 + 붙여넣기를 하다 실수로 dev 설정을 production cluster에 배포하거나, Helm chart 버전이 업데이트되었을 때 200개 이상의 pipeline을 업데이트할 생각을 하면 아찔해집니다.
그러므로 다음 요구사항을 충족하는 도구를 만들어야 안전하게 pipeline을 관리 할 수 있습니다.
- “변수”를 지원하는 pipeline template이 존재해야 합니다. 이 template으로 application 이름이나 stack에 따라 조금씩 다른 pipeline을 만들 수 있어야 합니다.
- Helm chart 버전 등 pipeline 일부가 변경되었을 때 모든 pipeline에 쉽게 업데이트 할 수 있어야 합니다.
- DevOps끼리 협업할 때 문제가 생기지 않도록 DevOps의 컴퓨터에서 실행되는 것보다는 서버에서 실행될 수 있으면 좋습니다.
- 실수를 방지하기 위해 현재 구성과의 차이 (diff)를 볼 수 있으면 좋습니다.
- UI로 쉽게 pipeline을 생성 할 수 있으면 좋습니다. DevOps 외에 다른 개발자들이 Spinnaker pipeline을 수정 할 수 있다면 업무 속도가 빨라집니다.
Spinnaker Pipeline Template
이미 Spinnaker에는 pipeline template [9]이라는 기능이 있어 쉽게 pipeline의 일부를 parameterize 할 수 있습니다. 하지만 바로 사용하기에는 몇 가지 문제가 있었습니다.
- Spin CLI [10]를 사용해야 합니다. Hyperconnect에서는 Spinnaker에 Google OAuth login을 사용하는데 OAuth의 특성상 서버 환경에서 CLI를 사용하기 어렵습니다.
- 단순한 변수 치환 정도밖에 지원하지 않습니다.
- 공통부분의 관리를 편하게 하기 위해 어떤 microservice에는 추가적인 artifact가 필요합니다.
- 잘못된 namespace에 배포하거나 삭제하는 것을 방지하기 위해 dev stack에만 검증 step을 추가해야 합니다.
- Canary 배포를 위해 1%, 5%, 10% 등 traffic 설정 비율만 다르게 적용하는 step을 반복하여야 합니다.
- (개인적인 취향이지만) JSON입니다.
{, }, [, ]와,로 인해 눈이 아프고 편집하다,를 빼먹는 등 실수하기 쉽습니다.
DIY - YAML & Jinja2 & Django
Spinnaker의 application과 pipeline은 Front50 [11]이라는 Spinnaker의 microservice가 담당합니다. 이 정보는 영구적으로 저장되어야 하므로 S3[12], GCS[13] 같은 Cloud Storage나, RDBMS를 사용합니다. Hyperconnect에서는 S3를 backend storage로 사용하도록 설정했습니다. 즉, Spinnaker API나 Spin CLI를 사용하지 않아도 S3에 저장된 파일을 직접 편집하여 pipeline을 변경 할 수 있습니다.
또한 Spinnaker의 pipeline은 전부 JSON으로 구성되어있습니다. 따라서, 어떤 방법을 사용하더라도 최종적으로 Spinnaker가 인식 가능한 올바른 형태의 JSON을 생성하고, 이를 S3에 올리게 되면 pipeline을 만들 수 있습니다.
그래서 위의 요구 사항들을 만족하도록 직접 JSON pipeline 생성기를 만들었습니다.
- YAML:
{, }, [, ], ,를 보기가 싫어 pipeline template은 YAML로 작성하였습니다. 맨 마지막 단계에 JSON으로 변환시키면 됩니다. - Jinja [14]: Python에서 많이 사용되는 Jinja template를 사용하였습니다. Spinnaker pipeline template에서는 지원하지 않는 if-statement를 사용하여 특정 조건일 만족할 경우에만 artifact나 step을 추가 할 수 있고, for-statement를 사용해 비슷한 step을 여러 번 반복하여 만들 수 있습니다.
- Django: 빠른 프로타입을 만들 수 있는 편리한 ORM과 frontend 코딩을 하지 않아도 기본적인 CRUD가 가능한 admin 페이지 [15]를 지원하는 Django를 사용했습니다.
Django Model
먼저, 데이터를 저장할 Django Model을 생성합니다. Template를 저장할 PipelineTemplate 모델과 microservice 정보를 저장할 MicroService 모델을 만들었습니다. 대부분의 설정이 stack에 따라 다르므로, 1개의 microservice는 여러 개의 stack을 가지고, 한 개의 stack은 여러 개의 pipeline을 가지도록 했습니다.
from django.db import models
class PipelineTemplate(models.Model):
name = models.CharField(max_length=32)
content = models.TextField()
class MicroService(models.Model):
name = models.CharField(max_length=32)
product = models.ForeignKey('HpcntProduct') # Azar, Hakuna, ...
team = models.ForeignKey('HpcntTeam') # Azar Backend1팀, Azar Backend2팀, ML팀 등등
k8s_ns = models.CharField(max_length=32) # Kubernetes namespace
git_repo = models.CharField(max_length=32)
class Stack(models.Model):
name = models.CharField(max_length=15) # dev, qa, stage, prod, ...
micro_service = models.ForeignKey('MicroService')
pipelines = models.ManyToManyField('PipelineTemplate')
Django admin에서 제공하는 inline [16]을 사용하면, 다음과 같은 admin UI를 쉽게 얻을 수 있습니다.
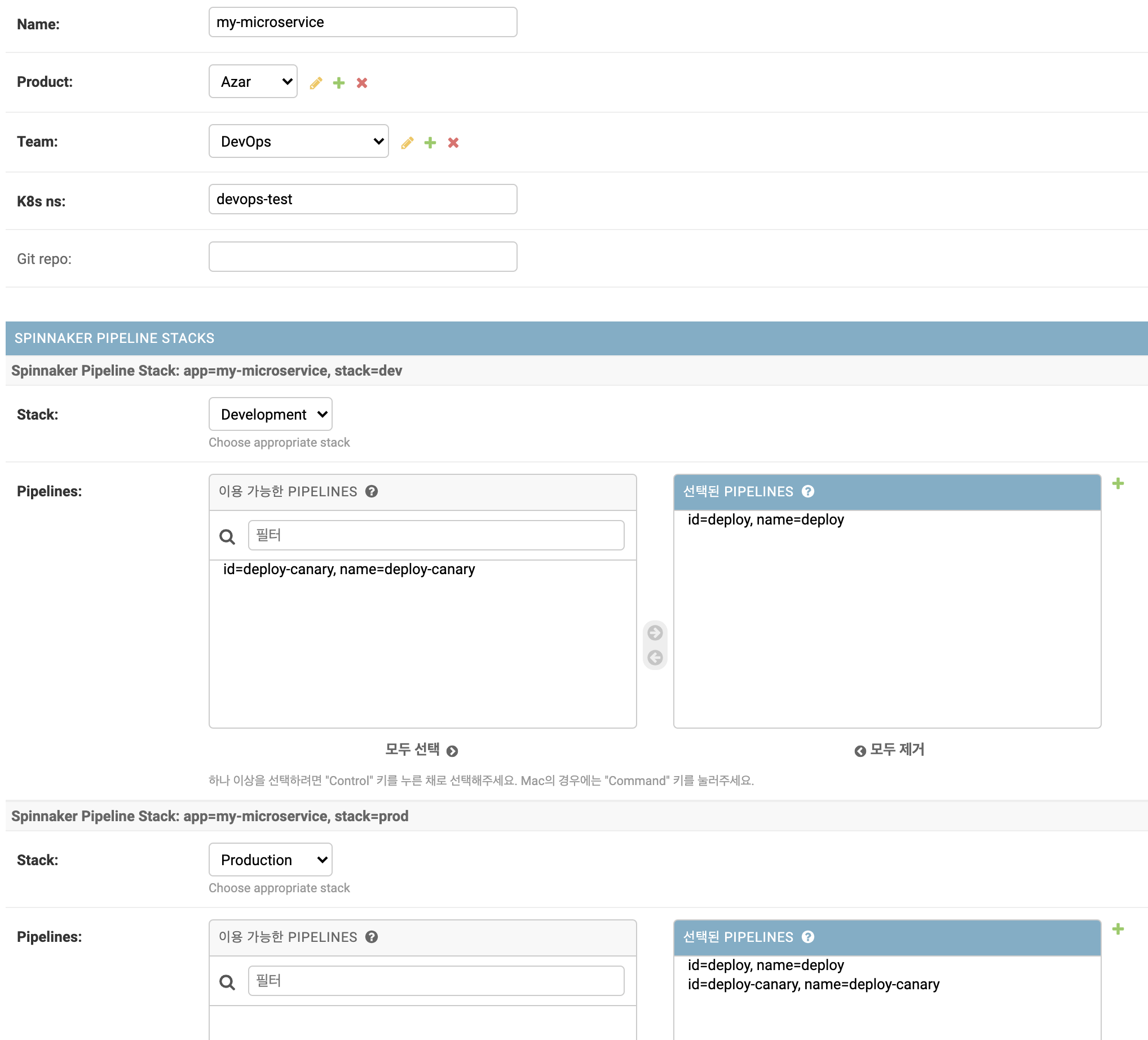
my-microservice를 생성했고, dev 환경에는 일반 배포만 하면 되므로 deploy pipeline만 선택했으며 prod 환경에는 일반 배포와 canary 배포가 모두 필요하므로 deploy와 deploy-canary pipeline을 선택했습니다.
동기화 코드
동기화 코드의 핵심적인 내용만 설명하자면 다음과 같습니다. sync() 함수를 실행하여 모든 microservice > stack > template에 대해 pipeline을 잘 생성한 뒤 S3에 올리는 코드입니다. 실제로는 각 microservice나 stack마다 parameter를 override하거나, 생성된 다른 pipeline을 참조하는 등 다양한 기능을 지원하고, cache 등 성능 향상을 위한 복잡한 코드로 구성되어 있습니다.
import json
import jinja2
import yaml
from deepdiff import DeepDiff # https://pypi.org/project/deepdiff/
def sync(dry_run=False):
jobs = []
for micro_service in MicroService.objects.all(): # 모든 microservice에 대해서...
for stack in micro_service.stack.all(): # 모든 stack에 대해서...
for pipeline_template in stack.pipelines.all(): # 모든 pipeline_template에 대해서...
pipeline_id, pipeline_json = build_pipeline(micro_service, stack, pipeline_template) # pipeline을 만든 뒤
is_updated, diff = get_diff(pipeline_id, pipeline_json) # diff를 계산하고...
if is_updated: # 변경된 목록을 만듭니다.
jobs.append({
'id': pipeline_id,
'data': pipeline_json,
'diff': diff,
})
if not dry_run:
# 그리고 s3에 업로드합니다.
for job in jobs:
s3_upload(job['id'], json.dumps(job['data']))
return jobs
def build_pipeline(micro_service, stack, pipeline_template):
template = jinja2.Template(pipeline_template.content) # Spinnaker template을 Jinja2로 로드합니다.
yaml_text = template.render({ # micro_service와 pipeline_stack 등에서 필요한 template 변수를 적용합니다.
'app_name': micro_service.name,
'product': micro_service.product.name,
'namespace': micro_service.k8s_ns,
'git_repo': micro_service.git_repo,
'stack': stack.name,
})
pipeline_as_dict = yaml.load(yaml_text) # Rendering된 YAML text를 Python dictionary로 읽습니다.
# Spinnaker에서는 artifact나 trigger 등을 UUID로 구별하는데, 이를 동적으로 만들어줘야 합니다. 핵심적인 내용이 아니라 생략합니다.
return pipeline_as_dict
def get_diff(pipeline_id, pipeline_json):
pipeline_json_old = get_current_pipeline(pipeline_id) # S3에서 현재 pipeline 상태를 가져옵니다.
patch = DeepDiff(pipeline_json_old, pipeline_json)
is_updated = bool(patch)
# 쉽게 diff를 확인 할 수 있도록 YAML format으로 만듭니다.
return is_updated, yaml.dump(json.loads(patch.to_json())) if patch else ''
Pipeline Template
분량 관계상 모든 template 내용을 보여드리지 못하는 점 양해 부탁드립니다.
application: "{{ app_name }}"
name: "deploy"
parameterConfig:
- name: version
label: Version
required: true
default: ""
- name: helmBranch # values.yaml이 포함된 repo의 branch
label: Helm Branch
required: true
default: master
- name: imageBranch # 배포할 microservice git repo의 branch
label: Image Branch
required: true
default: master
expectedArtifacts:
- displayName: hpcnt-workload-chart # Helm chart
matchArtifact:
artifactAccount: harbor
name: hpcnt-workload-chart
reference: harbor
type: helm/chart
version: 1.0.0
useDefaultArtifact: true
defaultArtifact:
artifactAccount: harbor
name: hpcnt-workload-chart
reference: harbor
type: helm/chart
version: 1.0.0
- displayName: "{{ product }}-{{ namespace }}-{{ app_name }}-values" # 공통 values.yaml
matchArtifact:
name: "deploy-values/{{ product }}/{{ namespace }}/{{ app_name }}/values.yaml"
type: "github/file"
useDefaultArtifact: true
defaultArtifact:
name: "deploy-values/{{ product }}/{{ namespace }}/{{ app_name }}/values.yaml"
reference: "<git-repo>/contents/deploy-values/{{ product }}/{{ namespace }}/{{ app_name }}/values.yaml"
type: "github/file"
version: "${parameters[\"helmBranch\"] ?: \"master\"}"
- displayName: "{{ product }}-{{ namespace }}-{{ app_name }}-{{ stack }}-values" # stack별 values.yaml
matchArtifact:
name: "deploy-values/{{ product }}/{{ namespace }}/{{ app_name }}/{{ stack }}-values.yaml"
type: "github/file"
useDefaultArtifact: true
defaultArtifact:
name: "deploy-values/{{ product }}/{{ namespace }}/{{ app_name }}/{{ stack }}-values.yaml"
reference: "<git-repo>/contents/deploy-values/{{ product }}/{{ namespace }}/{{ app_name }}/{{ stack }}-values.yaml"
type: "github/file"
version: "${parameters[\"helmBranch\"] ?: \"master\"}"
stages:
- refId: build # jenkins 호출하여 image build
name: Build Image
requisiteStageRefIds: []
type: jenkins
master: kube-jenkins-master
job: 99-common/job/docker-build
parameters:
Branch: "${parameters[\"imageBranch\"]}"
DockerImageName: "{{ namespace }}/{{ app_name }}"
DockerImageTag: "${parameters[\"version\"]}"
GitRepoName: "{{ git_repo }}"
- refId: bake-deploy # Helm chart rendering
name: "Bake Deploy"
requisiteStageRefIds:
- build
type: bakeManifest
templateRenderer: HELM3
namespace: "{{ namespace }}"
outputName: "{{ app_name }}"
expectedArtifacts: # {{ app_name }}-deploy로 rendering된 manifest 저장
- displayName: "{{ app_name }}-deploy"
matchArtifact:
kind: base64
name: "{{ app_name }}-deploy"
type: "embedded/base64"
inputArtifacts:
- account: harbor
id: hpcnt-workload-chart
- account: git-hpcnt-bot
id: "{{ product }}-{{ namespace }}-{{ app_name }}-values"
- account: git-hpcnt-bot
id: "{{ product }}-{{ namespace }}-{{ app_name }}-{{ stack }}-values"
overrides:
version: "${parameters[\"version\"]}"
- refId: deploy # manifest deployment
name: "Deploy"
requisiteStageRefIds:
- bake-deploy
type: deployManifest
account: "k8s-{{ product }}-{{ stack }}" # 배포할 Kubernetes cluster
cloudProvider: kubernetes
manifestArtifactAccount: "embedded-artifact"
manifestArtifactId: "{{ app_name }}-deploy" # 앞 stage에서 rendering된 manifest
moniker:
app: "{{ app_name }}"
source: artifact
skipExpressionEvaluation: true
Conclusion
마지막으로 Django admin을 약간 개조하면 큰 노력 없이 웹으로 pipeline diff를 보고, pipeline을 생성/수정하는 것이 가능합니다.
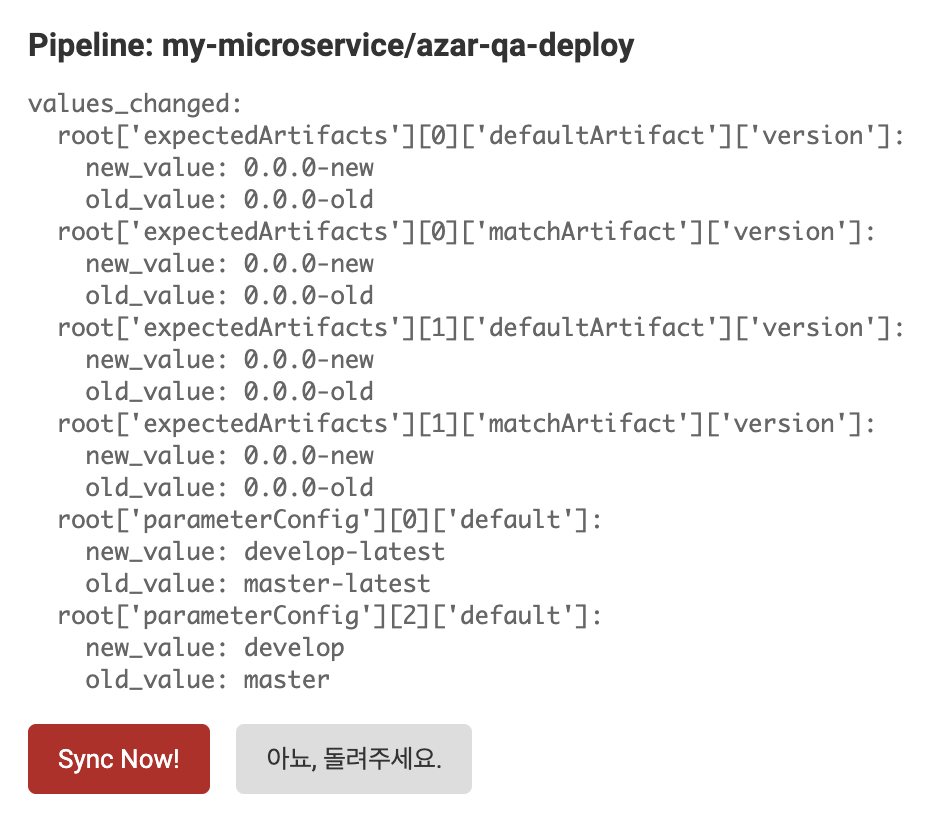
Wrap Up
- DevOps팀은 Jinja template을 사용해서 Spinnaker pipeline을 찍어내는 도구를 개발했습니다.
- 이 도구를 사용해서 Microservice / stack에 따라 조금씩 다른 pipeline을 생성 할 수 있습니다.
- Microservice metadata와 pipeline template을 Django admin web UI로 관리합니다.
다음 글에서는 Spinnaker와 Istio를 사용한 canary 배포 pipeline에 대해 공유하겠습니다.
Microservice 배포 자동화에 조금이나마 도움이 되었으면 좋겠습니다.
읽어주셔서 감사합니다 :)
언제나 글 마지막은 채용공고입니다. 이렇게 재미있는(?) 일을 같이할 DevOps와 Backend 개발자분들의 많은 지원 부탁드립니다. 채용공고 바로가기
References
[1] https://www.djangoproject.com/
[2] https://helm.sh/
[3] https://golang.org/pkg/text/template/
[4] http://masterminds.github.io/sprig/
[5] https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.18/#podtemplatespec-v1-core
[6] https://spinnaker.io/setup/ci/jenkins/
[7] https://spinnaker.io/guides/user/pipeline/expressions/
[8] https://spinnaker.io/setup/install/providers/kubernetes-v2/
[9] https://spinnaker.io/guides/user/pipeline/pipeline-templates/create/
[10] https://spinnaker.io/setup/spin/
[11] https://github.com/spinnaker/front50
[12] https://aws.amazon.com/s3/
[13] https://cloud.google.com/storage
[14] https://jinja.palletsprojects.com/en/2.11.x/
[15] https://docs.djangoproject.com/en/3.0/ref/contrib/admin/
[16] https://docs.djangoproject.com/en/3.0/ref/contrib/admin/#using-generic-relations-as-an-inline
Read more
-
1년 동안 Workload의 절반을 ARM64로 Migration하기
AWS에서는 ARM64 기반의 Graviton processor를 지원합니다. 가격도 저렴하고 성능도 좋은 Graviton을 production Kubernetes cluster에 도입하여, 1년 동안 50%의 workload를 전환한 경험을 공유합니다. -
JVM + Container 환경에서 수상한 Memory 사용량 증가 현상 분석하기
Resource 최적화를 진행하면서 Java container에 할당된 CPU를 줄이자, memory 사용량이 증가했습니다. 신기한(?) 현상을 분석해보았습니다. -
개발자의 AWS 권한을 GitOps로 우아하게 관리하는 방법
많은 개발자가 가지는 많은 권한을 쉽게 관리하고, 개발자가 필요한 권한을 직접 얻을 수 있게 권한 시스템을 설계하고 GitOps 기반 도구를 개발한 과정을 소개합니다. -
ImagePullSecrets 없이 안전하게 Private Registry 사용하기!
ImagePullSecrets 없이 편리하고 안전하게 private registry를 사용 할 수 있도록 Kubelet Credential Provider 기능을 실험해보았습니다.