JVM + Container 환경에서 수상한 Memory 사용량 증가 현상 분석하기
안녕하세요, DevOps 팀의 Sammie입니다. Hyperconnect에서는 대부분의 microservice를 Kubernetes 환경에 배포하고 있습니다. 개발자는 직접 load test 등을 수행하여 microservice에 할당되는 초기 cpu나 memory 등의 resource를 정하며, 이후 지속적인 monitoring을 통해 resource를 최적화해나가고 있습니다.
얼마 전, DevOps 차원에서 모든 microservice의 resource 사용량을 확인하고, 낭비되고 있는 resource를 최적화하는 작업을 진행했습니다. 이 중 notification-preferences이라는, 아직 production에서는 사용하지 않는 microservice가 2vCPU를 할당 (resources.cpu=2) 받고 있어, 1vCPU로 줄였습니다. 작업을 끝나고 몇 분 뒤, memory 사용량이 90%를 넘는다는 alarm이 발생했습니다. Memory 할당량이나 JVM의 GC 관련 argument를 수정한 적이 없었는데, 정말 이상했습니다.
그래서 원인을 찾아보기로 했습니다. 그리고 정말 뜻밖에도, Java의 Runtime.getRuntime().availableProcessors()가 이상한 값을 전달하고 있다는 사실을 알아냈습니다. 최근에 수행한 debugging 중 가장 재미있기도 하고, 황당하기도 해서 이번 글에는 관련 내용을 공유하려고 합니다.
Deployment Spec
이번 문제와 관련 없는 다른 내용은 전부 생략했지만, Java 기반의 microservice를 배포하는 정말 평범한 Deployment spec입니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: notification-preferences-prod
spec:
replicas: 2
selector:
matchLabels:
app: notification-preferences
template:
metadata:
labels:
app: notification-preferences
spec:
containers:
- name: notification-preferences
image: harbor.hyperconnect.com/notification-preferences:v0.0.0
env:
- name: JAVA_OPTIONS
value: |
-XX:+UseContainerSupport
-XX:InitialRAMPercentage=60
-XX:MinRAMPercentage=60
-XX:MaxRAMPercentage=60
-XX:MaxGCPauseMillis=200
-XX:MaxMetaspaceSize=256m
-XX:MetaspaceSize=256m
resources:
limits:
memory: 1Gi
requests:
cpu: "2"
memory: 1Gi
여기서 JAVA_OPTIONS 및 resources에 대해서 알아보겠습니다.
+UseContainerSupport는 Java 10에 추가되어 Java 8에 backport 된 옵션입니다. JVM은 startup시 현재 시스템의 CPU core 개수나 사용 가능한 memory 등을 기반으로 GC thread의 개수나 기본적인 memory heap size를 결정합니다. 이 option을 추가하면 시스템 전체가 아닌 container에 할당된 CPU 및 memory를 인식하여 적용하게 됩니다. [1]resources.limit.cpu를 설정하지 않은 이유는, Java의 경우 startup이나 초기 요청을 받을 때 많은 CPU 자원을 소모하기 때문입니다. GraalVM 같이 ahead-of-time compile이 아닌 일반적인 JVM을 사용할 경우 class 파일을 load 해서 compile 하는 과정이 필요하기 때문에 cpu limit을 제한할 경우 startup 시간이 길어지거나 초기 요청의 latency가 튀는 문제가 있습니다.
글의 초반에 언급했듯이, 아직 이 microservice는 사용자의 요청을 받지 않아 Prometheus나 kubelet의 health check를 제외하고는 요청량이 거의 0이었습니다. 따라서, resources.requests.cpu를 1로 줄였습니다.
그리고, memory 사용량이 증가했습니다.
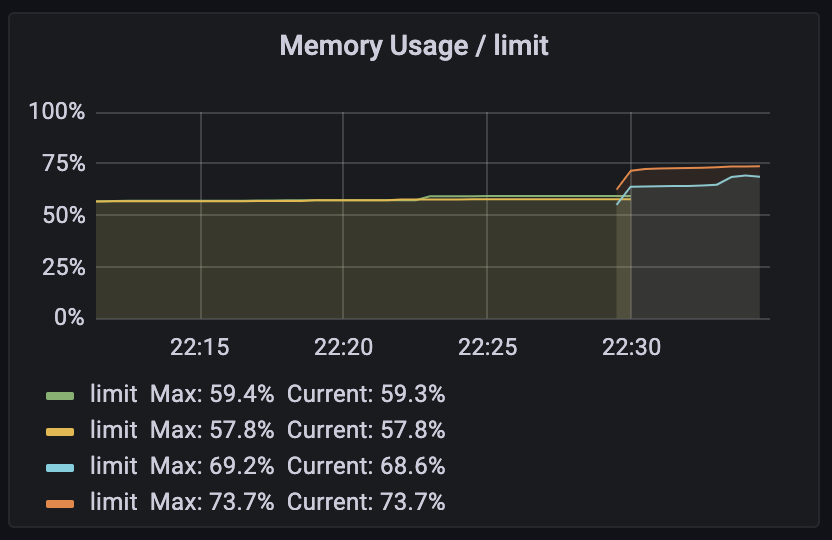
Why?
GC?
CPU 개수를 줄였더니, memory 사용량이 증가했습니다. 가장 먼저 떠오른 것은 GC입니다. CPU 개수가 줄어드니, GC thread 수가 줄어들어 GC를 덜 하는 것이 아닌가 하는 생각이 들었습니다. 이를 확인하는 방법은 간단합니다. JMX나 APM 같은 도구를 붙여서, GC 지표를 확인하면 됩니다.
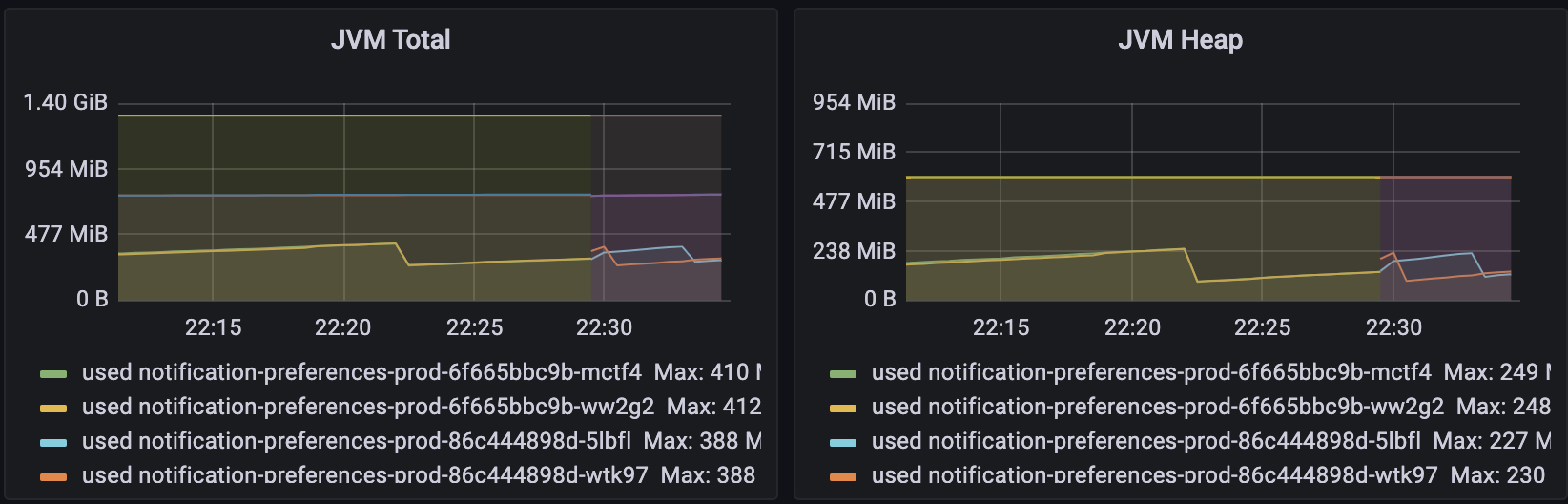
하지만, 보시는 것처럼 별 다른 변화는 없었습니다.
Thread?
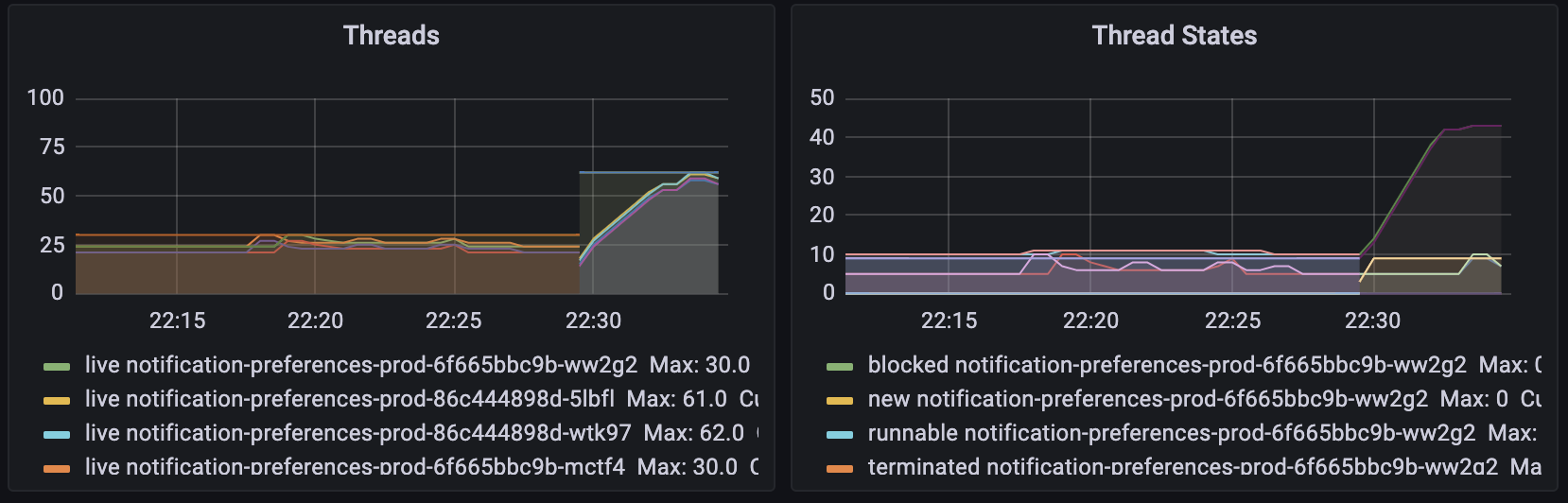
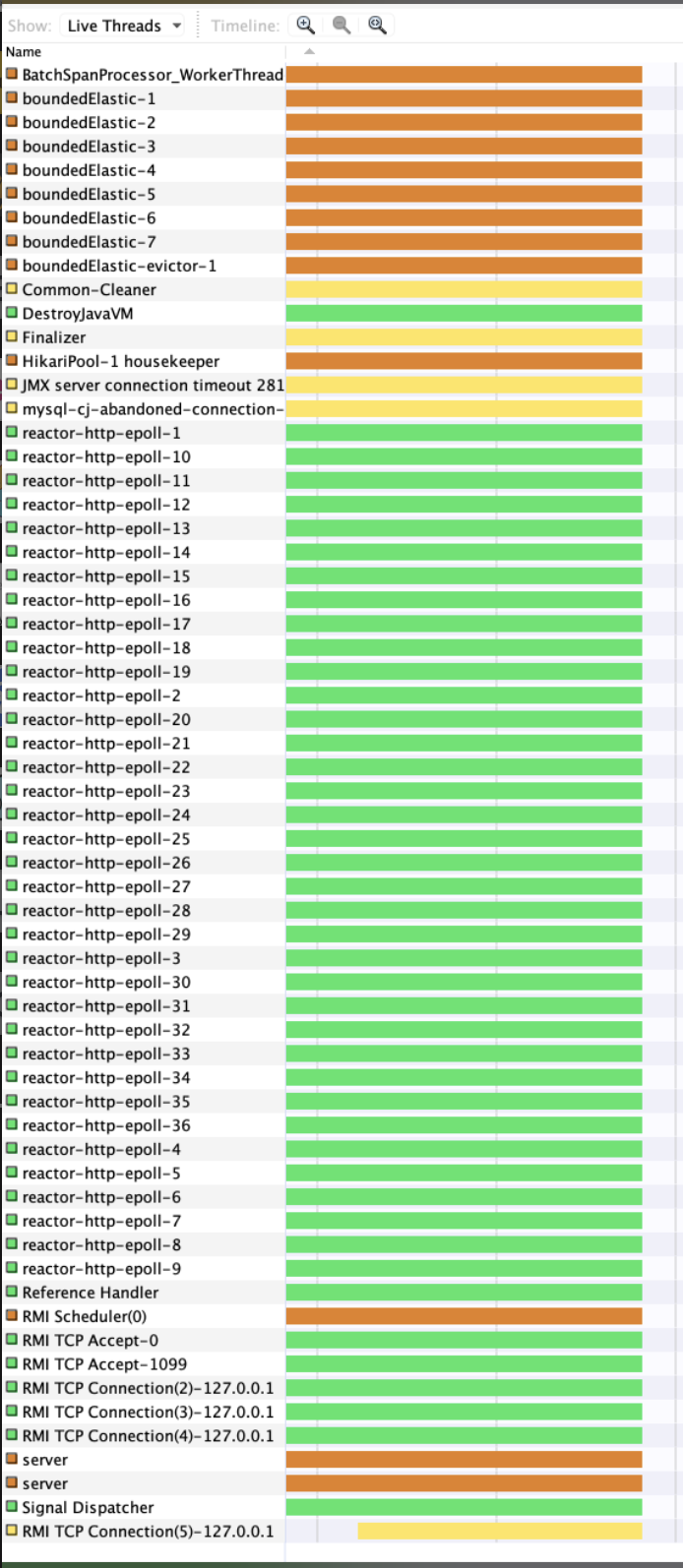
JMX 같은 도구를 붙이면 Kubernetes cAdvisor에서 제공하는 metric 외에 Java 자체의 상세한 metric을 볼 수 있었습니다. Dashboard에 다른 항목을 살펴보던 도중, 다음 그림과 같이 thread 개수가 2배 이상 증가했다는 사실을 알아냈습니다. 기본적으로 thread가 사용하는 memory는 크지 않으나, 1GB 메모리를 할당한 상태에서 thread 20개가 증가하면 100MB 정도의 차이를 만들어내기에 충분해 보였습니다.
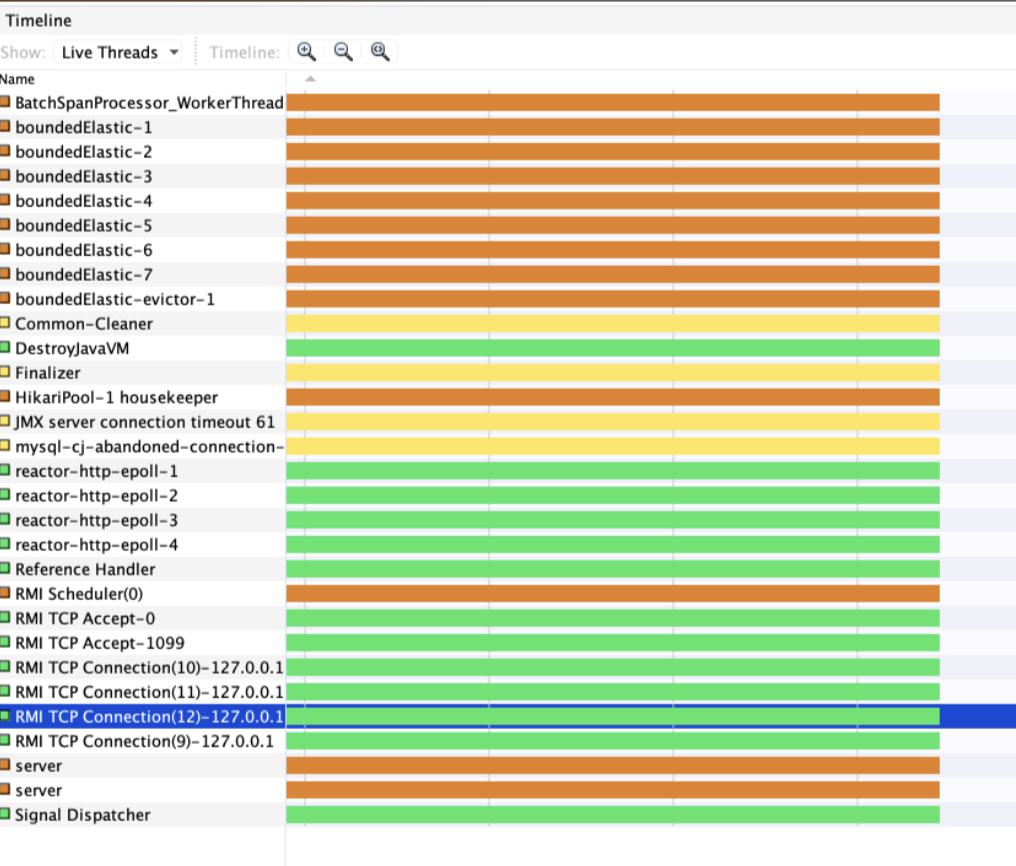
무슨 thread가 증가했는지 찾기 위해 VisualVM [2]을 사용해서 CPU 할당 변경 전후를 비교했고, reactor-http-epoll이라는 이름의 thread가 증가한 것을 알 수 있었습니다.
WebFlux
notification-preferences는 Spring WebFlux를 사용합니다. WebFlux는 non-blocking하게 요청을 처리하도록 만들어진 기술입니다. 따라서, 적은 개수의 thread만으로 blocking 방법을 사용하는 서버 대비 더 많은 요청을 처리할 수 있습니다. (물론 CPU 연산만 필요한 요청이 대부분이라면 효과는 미미합니다. WebFlux에 대한 자세한 설명은 생략하겠습니다.)
WebFlux는 사용 가능한 모든 CPU core를 최대한 활용하여 가장 높은 성능을 낼 수 있도록 thread 수를 적절히 조절 [3]합니다. 정말 당연한 이야기지만, 사용 가능한 CPU 개수가 많을 수록 thread를 더 많이 spawn합니다.
int DEFAULT_IO_WORKER_COUNT = Integer.parseInt(System.getProperty(
ReactorNetty.IO_WORKER_COUNT,
"" + Math.max(Runtime.getRuntime().availableProcessors(), 4)));
여기서 의문점이 생깁니다. CPU core가 2개로 설정되어 있을 때는 위의 코드처럼 4개였는데, CPU core를 1개로 줄였더니 36개가 되었습니다.
availableProcessors()
이제 원인은 3가지로 좁혀졌습니다.
- 누군가 몰래
ReactorNetty.IO_WORKER_COUNT값을 주입했다. - 사실 WebFlux나 Netty를 사용하고 있지 않았고, 모든 것이 착각이었다.
Runtime.getRuntime().availableProcessors()가 이상한 값을 반환한다.
바로 kubectl exec -it -n <ns> <pod> -- /bin/bash 명령을 사용해 Pod에 shell로 접속한 다음, Java의 interactive shell인 jshell을 띄웠습니다. 그리고 문제의 method를 호출해보았습니다.
[hpcnt@notification-preferences-prod-xxx-yyy ~]$ jshell
[Date] java.util.prefs.FileSystemPreferences$1 run
INFO: Created user preferences directory.
| Welcome to JShell -- Version 11.0.14
| For an introduction type: /help intro
jshell> Runtime.getRuntime().availableProcessors();
$1 ==> 2
resources.requests.cpu가 2로 설정되어 있을 때는 예상했던 값을 얻을 수 있었습니다. 그러나 이 값을 1로 변경하자, 이상한 일이 일어났습니다.
[hpcnt@notification-preferences-prod-xxx-yyy ~]$ jshell
[Date] java.util.prefs.FileSystemPreferences$1 run
INFO: Created user preferences directory.
| Welcome to JShell -- Version 11.0.14
| For an introduction type: /help intro
jshell> Runtime.getRuntime().availableProcessors();
$1 ==> 36
앞서 reactor-http-epoll thread가 36개가 생겼다고 했는데, 이 것과 정확히 일치하는 이상한 숫자가 나왔습니다. 원인이 확실해 보입니다.
Meet Hotspot Code
앞에서 나온 36이라는 숫자는, 저 Pod이 떠 있는 Node 전체의 CPU 값입니다. 즉, availableProcessors() 함수는 resources.requests.cpu가 2일 때는 정상적으로 container에 할당된 CPU를 인식하여 반환하나, 1로 바꾸면 정상적으로 인식하지 못하고 Node 전체의 CPU 값을 반환합니다.
그래서 availableProcessors() 함수를 뜯어보기로 했습니다. 이 함수는 native로, C++로 정의되어 있습니다.
(해당 Pod의 runtime은 Corretto11으로, 아래의 source code 또한 Corretto11 [4]에서 가져왔습니다.)
src/java.base/share/native/libjava/Runtime.cJNIEXPORT jint JNICALL Java_java_lang_Runtime_availableProcessors(JNIEnv *env, jobject this) { return JVM_ActiveProcessorCount(); }src/hotspot/share/prims/jvm.cppJVM_ENTRY_NO_ENV(jint, JVM_ActiveProcessorCount(void)) JVMWrapper("JVM_ActiveProcessorCount"); return os::active_processor_count(); JVM_END
위의 2단계를 거쳐, src/hotspot/os/linux/ directory에 도착했습니다. 그리고 cgroupSubsystem_linux.cpp 파일을 열어보았습니다. 예상대로, cgroups에서 정보를 가져오는 것으로 추정되는 코드가 보였습니다. (주석이나 log trace는 삭제했습니다.)
int CgroupSubsystem::active_processor_count() {
cpu_count = limit_count = os::Linux::active_processor_count();
int quota = cpu_quota();
int period = cpu_period();
int share = cpu_shares();
if (quota > -1 && period > 0) {
quota_count = ceilf((float)quota / (float)period);
}
if (share > -1) {
share_count = ceilf((float)share / (float)PER_CPU_SHARES);
}
if (quota_count !=0 && share_count != 0) {
if (PreferContainerQuotaForCPUCount) {
limit_count = quota_count;
} else {
limit_count = MIN2(quota_count, share_count);
}
} else if (quota_count != 0) {
limit_count = quota_count;
} else if (share_count != 0) {
limit_count = share_count;
}
result = MIN2(cpu_count, limit_count);
return result;
}
- 가장 처음
cpu_count,limit_count는os::Linux::active_processor_count()함수의 실행 결과를 가져오게 되어있습니다. 별도의 설정이 없다면,sysconf(_SC_NPROCESSORS_CONF)를 호출하여 가져옵니다. Command line으로는getconf -a | grep _NPROCESSORS_ONLN를 사용해 확인할 수 있고 이는 Node의 CPU core 개수인 36개입니다. cpu_quota(),cpu_period(),cpu_shares()는 각각/sys/fs/cgroup/cpu/내의cpu.cfs_quota_us,cpu.cfs_period_us,cpu.shares파일을 읽는 것으로 보였습니다. Limit이 설정되지 않았으니cpu_quota는 -1이고,cpu_period는 kubelet에 의한 고정값 100000,cpu.shares는 1 core를 할당했을 때는 1024, 2 core를 할당했을 때는 2048이 됩니다.
따라서, 1 core를 할당했을 때 당연히 1이 반환된다고 생각했습니다. 코드를 더 자세히 들여다보았고, 마침내 원인을 찾을 수 있었습니다.
src/hotspot/os/linux/cgroupV1Subsystem_linux.cpp 파일에 있는 cpu_shares()는 다음과 같이 구현되어 있습니다.
int CgroupV1Subsystem::cpu_shares() {
GET_CONTAINER_INFO(int, _cpu->controller(), "/cpu.shares",
"CPU Shares is: %d", "%d", shares);
// Convert 1024 to no shares setup
if (shares == 1024) return -1;
return shares;
}
드디어, 원인을 찾았습니다. 바로 resources.requests.cpu를 1001m과 999m으로 변경하고 테스트를 진행해봤습니다.
# give requests.cpu = 1001m, limits.cpu = unset
[hpcnt@notification-preferences-prod-xxx-yyy ~]$ cat /sys/fs/cgroup/cpu/cpu.shares
1025
[hpcnt@notification-preferences-prod-xxx-yyy ~]$ jshell
jshell> Runtime.getRuntime().availableProcessors();
$1 ==> 2
# give requests.cpu = 999m, limits.cpu = unset
[hpcnt@notification-preferences-prod-xxx-yyy ~]$ cat /sys/fs/cgroup/cpu/cpu.shares
1022
[hpcnt@notification-preferences-prod-xxx-yyy ~]$ jshell
jshell> Runtime.getRuntime().availableProcessors();
$1 ==> 1
그리고 thread와 memory 지표를 확인했습니다. (시간 순서대로 2, 1, 1001m, 999m 할당)
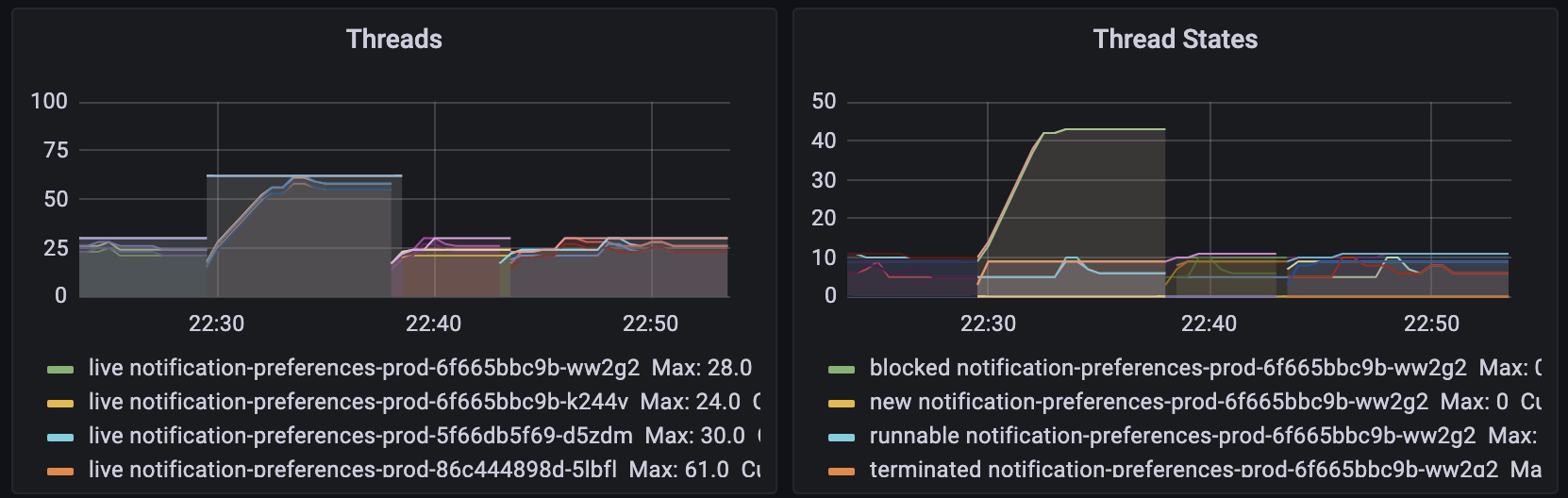
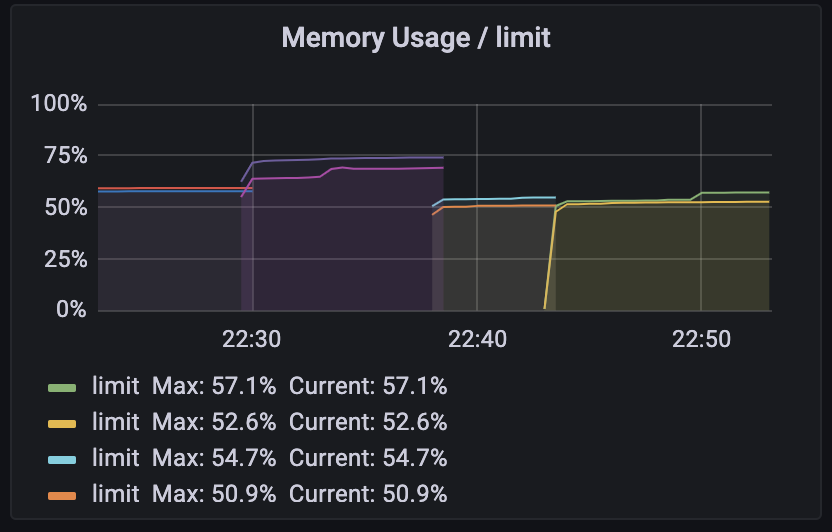
예상했던 그대로였습니다.
Solution & Related Issue
Resource를 다시 늘리거나, resources.limits.cpu를 설정하거나, resources.requets.cpu를 1001m이나 999m으로 설정하는 것은 각자 문제가 있으므로 ActiveProcessorCount를 사용하여 강제로 사용 가능한 CPU 수를 지정하여 문제를 해결했습니다.
env:
- name: JAVA_OPTIONS
value:
-XX:ActiveProcessorCount=1
문제의 원인을 알고 나니 구글링 할 수 있는 키워드를 얻었고, 관련된 여러 가지 이슈를 확인할 수 있었습니다.
- https://bugs.openjdk.org/browse/JDK-8281571: JVM 19에서 이 문제를 수정하고, 하위 호환성을 위해
UseContainerCpuShares옵션을 넣는다는 내용 - https://bugs.openjdk.org/browse/JDK-8281181: 동일한 문제를 제기하는 이슈
- https://github.com/openjdk/jdk18u/commit/a5411119c383225e9be27311c6cb7fe5d1700b68: OpenJDK 18에 merge 된 코드
안타깝게도 현재 수정된 구현대로라면 resources.requests.cpu가 더 이상 availableProcessors()의 반환 값에 관여하지 않게 되며, resources.limits.cpu 또는 ActiveProcessorCount를 명시적으로 지정해야 이 문제를 해결할 수 있습니다. 깔끔한 해결책을 찾지는 못했지만, 문제의 원인을 완전히 밝혀냈고 어느 정도 사용 가능한 해결책을 찾아 여기서 험난한(?) debugging 여정은 마치고, 사내 공지를 작성했습니다.
Wrap Up
Resource 최적화를 위해 Kubernetes 환경에 배포되어 있는 JVM의 CPU requests 수를 2에서 1로 줄이자, memory 사용량이 증가했습니다.
- JMX 등을 사용하여 GC 지표를 확인했으나, 원인이 아니었습니다. 대신 thread 개수가 증가한 것을 확인했습니다.
- VisualVM 도구를 사용해서 어떤 thread 개수가 증가했는지 찾아봤습니다. WebFlux에서 사용하는 reactor 관련 thread가 증가한 것을 확인했습니다.
- WebFlux의 thread 개수를 계산하는 코드를 찾았고, CPU requests가 1일 때
availableProcessors()가 Node의 cpu 개수를 반환한다는 사실을 발견했습니다. - JVM Hotspot 코드를 뜯어 왜 이런 현상이 발생하는지 근본 원인을 확인했고, 안타깝게도 현재 이를 수정할 방법이 없어 명시적으로
ActiveProcessorCount를 사용하는 것으로 끝냈습니다.
Hyperconnect에서 production에 배포되는 JVM application에 대해서는 CPU requests를 2 이상 주고 있었으나, microservice가 많아지면서 resource 절약의 필요성이 커졌습니다. 따라서 CPU requests를 줄이는 과정에서 이 문제를 밟게 되었습니다. Debugging을 시작하기 전까지는 전혀 예상하지 못한 원인이어서 앞으로도 기억에 남을 것 같습니다.
JVM을 사용하며 resources.requests.cpu=1, resources.limits.cpu=null을 설정한 분들에게 도움이 되기를 바랍니다.
긴 글 읽어주셔서 감사합니다 :)
언제나 글 마지막은 채용공고입니다. 이렇게 재미있는(?) 일을 같이할 DevOps의 많은 지원 부탁드립니다. 채용공고 바로가기
References
[1] https://bugs.openjdk.org/browse/JDK-8146115
Read more
-
1년 동안 Workload의 절반을 ARM64로 Migration하기
AWS에서는 ARM64 기반의 Graviton processor를 지원합니다. 가격도 저렴하고 성능도 좋은 Graviton을 production Kubernetes cluster에 도입하여, 1년 동안 50%의 workload를 전환한 경험을 공유합니다. -
개발자의 AWS 권한을 GitOps로 우아하게 관리하는 방법
많은 개발자가 가지는 많은 권한을 쉽게 관리하고, 개발자가 필요한 권한을 직접 얻을 수 있게 권한 시스템을 설계하고 GitOps 기반 도구를 개발한 과정을 소개합니다. -
ImagePullSecrets 없이 안전하게 Private Registry 사용하기!
ImagePullSecrets 없이 편리하고 안전하게 private registry를 사용 할 수 있도록 Kubelet Credential Provider 기능을 실험해보았습니다. -
Shell 없는 Container, Live 환경에서 Debugging해보기!
Live Pod을 debugging 하기 위해 사용한 kubectl-debug라는 open-source 도구에 대해 소개하고, 이 도구를 Bottlerocket에서 쓰기 위해 패치한 과정을 공유합니다.