1년 동안 Workload의 절반을 ARM64로 Migration하기
안녕하세요, DevOps 팀의 Sammie입니다. Hyperconnect에서는 대부분의 service workload를 AWS 위에서 운영하고 있고, 다른 모든 회사와 동일하게 AWS 비용 절감은 중요한 주제입니다. AWS 비용을 절감할 수 있는 항목을 찾던 중, AWS Graviton Processor를 발견했습니다. Graviton2 instance는 기존 Intel 계열 (5th generation) instance와 비교하여 가격이 20% 정도 저렴하며, 최대 40% 더 빠르다고 홍보[1]하고 있었습니다. 정말로 가격대비 성능이 40% 향상되었는지는 실험 전까지는 알 수 없으나, 동일 CPU core당 가격이 저렴하기 때문에 일단 개발 환경부터 도입해 보기로 했습니다.
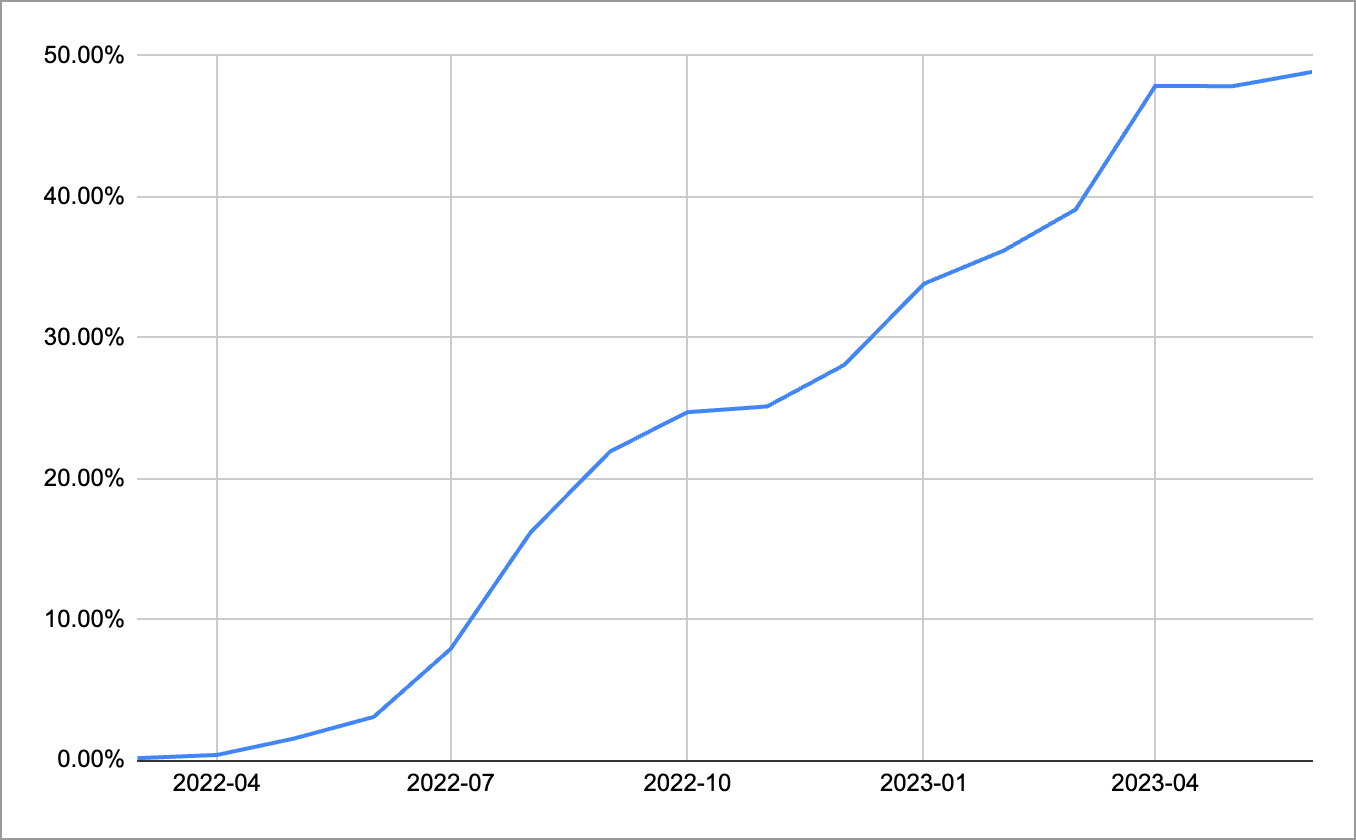
몇몇 managed service와 workload를 migration 해봤고, 적어도 성능이 더 나빠지지는 않았으므로 대부분의 production workload을 Graviton으로 migration 하기로 하고 다양한 작업을 진행했습니다. 그 결과, 2022년 5월 전까지만 해도 회사 전체에서 ARM64 사용 비중은 거의 0%였지만, 2023년 5월 기준 EC2 instance 요금의 47% 이상을 차지할 정도로 빠르게 전환하여 많은 비용을 절감할 수 있었습니다.
이번 글에서는 Kubernetes 위에서 작동하는 100개 이상의 microservice를 ARM64로 migration 했던 작업에 초점을 맞춰 긴 여정을 소개하려고 합니다. 전반적인 process, Kubernetes의 Node와 각종 system component를 ARM64로 전환하는 과정, AMD64와 ARM64 이미지를 동시에 build 하기 위해 CI/CD pipeline을 어떻게 수정했는지, 그리고 실제 이전하면서 문제가 되었던 것을 설명해 드리겠습니다.
ARM64 and Graviton
본격적으로 migration 과정을 설명하기에 앞서, ARM64와 Graviton processor에 대한 간략한 소개와 migration을 진행한 이유를 설명하겠습니다. ARM64는 cpu archicture의 한 종류로, Intel과 AMD에서 사용하는 AMD64 archicture 대비 전력 소모면에서 강점을 가집니다. 따라서, ARM64는 주로 mobile 환경에서 사용되었으며, 지난 2018년 re:Invent에서 ARM64 기반의 Graviton processor와 2019년 12월 Graviton2 processor를 발표한 이후 서버 시장에서도 유의미한 비중을 차지하게 되었습니다.
Graviton processor의 장점은 다음과 같습니다.
- Graviton processor를 사용하는 c6g, m6g, r6g 등의 instance는 Intel 기반 c5, m5, r5보다 20% 저렴합니다.
- 일부 workload에는 40% 더 뛰어난 가격 대비 성능을 보여준다고 합니다. 물론 각 workload 특성에 따라 성능 향상의 수준은 달라지므로 stage 환경에서 load-test를 해보거나, production에 도입하기 전까지 얼마나 성능이 향상될지는 모릅니다. Hyperconnect에서 migration 한 대부분의 workload는 web server로, 서버 자체의 연산보다 database 연결 등의 I/O 연결이 많은 workload라 성능 향상이 크게 체감되지는 않았으나, 그래도 일부 시스템에서 latency가 감소하는 등 더 좋은 성능을 보여주었습니다.
물론, 장점만 있지는 않습니다.
- 제일 먼저, application을 새로 build 해야 합니다. golang 같이 native 하게 cross-compile을 지원하는 경우는 쉽지만, 그렇지 않은 경우가 있습니다. 다행히 Hyperconnect에서는 주로 JVM 기반의 programming language (Java, Kotlin) 등을 사용하기 때문에 크게 어려운 점은 없었으나, 가끔씩 JNI 등을 통해 native code를 호출하는 case나, system workload 등은 version upgrade를 하거나, custom build를 수행해야 했습니다.
- Application의 안정성을 보장할 수 없습니다. 실제로, 특정 system component가 알 수 없는 이유로 SIGSEGV 등이 발생하기도 했으며, byte order 차이로 utf8 processing이 되지 않거나, latency가 주기적으로 튀는 등 다양한 현상이 발생했습니다.
Managed Service
Elasticache, RDS 및 OpenSearch와 같이 EC2 instance 기반으로 작동하는 managed service에서도 Graviton processor를 사용할 수 있습니다. 이 서비스에서 Graviton instance로의 migration은 EC2 instance와 달리 상대적으로 쉽습니다. AWS가 직접 관리하는 software를 사용하기 때문에 새로 build 하거나, 안정성을 처음부터 검증해야 할 일은 없기 때문입니다. 물론, database 서버이므로 개발 환경, load-test를 수행하는 stage 환경을 거쳐 운영 환경을 migration 했지만, 직접 개발한 workload를 migration 하는 것보다는 상대적으로 쉬웠습니다. 지난 2020년 10월 Hyperconnect가 주로 사용하는 region에서 Graviton2 기반의 Elasticache instance가 출시[2]되었고, RDS [3], OpenSearch [4] 등 여러 managed service를 차례로 Graviton으로 migration 했습니다.
EC2 Instance
하지만, Hyperconnect에서 매우 높은 비중으로 사용하고 있는 EC2 instance에 Graviton을 도입하지 않으면 진정한 migration이라 할 수 없습니다. Hyperconnect에서는 Azar, Hakuna 및 Hyperconnect Enterprise 서비스에서 사용하는 200개 이상의 microservice가 있고, 이를 ARM64 기반으로 옮기기 위해 다양한 작업을 DevOps, SRE팀과 application 개발팀이 함께 진행했습니다. Kubernetes의 system 관련 DaemonSet migration부터, OS build, build pipeline 전반에 대한 변경과 application debugging 등 다양한 작업을 진행하여, 결과적으로 글의 도입부에서 밝힌 것과 같이 EC2 instance 요금의 47% 이상을 Graviton2 processor 위에서 실행되도록 migration 했습니다. 일부 workload는 실험적으로 다음 세대인 Graviton 3 processor [5] 기반의 c7g instance family를 사용하고 있습니다.
다음 단락에서, EC2 instance 위의 workload를 어떻게 migration 할 수 있었는지 조금 더 자세히 소개해드리겠습니다.
High-Level Overview & Migration Strategy
Hyperconnect에서 운영하는 대부분의 microservice는 Kubernetes 위에서 동작하고 있으므로, application을 migration 하기 전에 ARM64 node를 Kubernetes cluster에 도입해야 했습니다. 따라서, ARM64 기반 OS와 kubelet 및 OS package 등이 필요했고, ARM64용으로 만들어진 system component와 application을 사용해야 했습니다. 당연히, 100개 이상의 microservice를 하루아침에 AMD64 기반에서 ARM64 기반으로 migration 할 수 없으므로 migration을 하는 기간에는 AMD64와 ARM64 application이 공존해야 합니다. 따라서 node 역시 공존해야 하므로, OS, kubectl을 포함한 node의 package, DaemonSet 등으로 운영되는 system component와 application에 대한 multi-architecture image가 필요했습니다.
따라서, 다음과 같은 migration strategy를 세웠습니다.
- Hyperconnect에서 사용하는 AmazonLinux2와 Bottlerocket 기반의 node가 ARM64에서 동작하도록 수정하고, 검증합니다.
- 새 node group을 생성합니다. Hyperconnect에서 node group을 관리하기 위해 만든
node.hpcnt.com/role: service같은 convention을 그대로 지키면서, 새 node label과 taints를 추가했습니다. - 모든 DaemonSet, sidecar container 등 system component가 ARM64에서 작동하는지 검증합니다.
- Application을 ARM64용으로 build 하고, 개발 cluster부터 배포해 봅니다. ARM64 build가 성공한 application은 위에서 정한 node label을 nodeSelector로, taints에 대응되는 tolerations를 Pod spec에 넣어 배포합니다.
- 이제 production에 배포합니다. Canary 배포가 필요한 경우 deployment를 2개 만들어 하나는 기존처럼, 하나는 nodeSelector와 tolerations를 추가하여 배포한 다음, Istio를 사용해 traffic 비율을 조정하며 metric을 관찰합니다.
- 4와 5를 모든 application에 대해 반복합니다. Hyperconnect에서 운영하는 모든 Kubernetes cluster의 모든 node group은 ASG 기반으로 cluster-autoscaler를 사용하고 있기 때문에, migration이 진행될수록 AMD64 node는 줄어들고, ARM64 node는 늘어날 것입니다.
이제 다음 단락부터, 각 단계를 좀 더 자세히 설명하겠습니다.
OS & NodeGroups
앞서 언급한 것처럼, Hyperconnect에서는 AmazonLinux2와 Bottlerocket OS 기반의 node를 사용하고 있습니다. 다행히 둘 다 기본적으로 ARM64 image를 제공하고 있으므로, ARM64 kernel부터 직접 package를 하나씩 build 해야 하는 일은 없었습니다. 다만, Bottlerocket source code를 일부 수정하여 사용하고 있어 Bottlerocket의 경우 ARM64 OS를 직접 build 해야 했습니다. 다행히, Bottlerocket의 build system은 rust와 golang 기반이어서 Intel 계열의 EC2 instance에서 AMD64와 ARM64 image를 둘 다 build 할 수 있었습니다.
또한, Hyperconnect에서 사용하는 kubelet-credential-provider 역시 AMD64와 ARM64에서 동시에 호환되도록 변경했습니다. 이 블로그 작성 이후 golang 관련된 build process가 개선되어 작업하기 더 쉬워졌습니다. kubelet-credential-provider와 관련된 자세한 내용은 블로그 게시글과 PR을 참고하시기 바랍니다.
NodeGroup은 다음과 같이 label 및 taints를 설정했습니다.
- Node label은
node.hpcnt.com/arch같이 새로 추가하지 않고, Kubernetes의 well-known label인kubernetes.io/arch를 그대로 사용했습니다. - ARM64에 대응되지 않는 application이 ARM64 node에 배정되어 영원한 CrashLoopBackOff가 발생하는 상황을 피하기 위해, 모든 ARM64 node에는
kubernetes.io/arch=arm64:NoExecutetaints를 추가했습니다. - 나머지 Hyperconnect에서 node group을 관리하기 위해 만든
node.hpcnt.com/key: value같은 convention은 그대로 유지했습니다.
또한, ASG에 k8s.io/cluster-autoscaler/node-template/label/kubernetes.io/arch: arm64 tag를 명시적으로 설정했습니다. Cluster-autoscaler는 ARM64 archicture node를 자동으로 추론할 수 없어, 이 tag를 설정하지 않는다면 ARM64 node group을 띄우기 위한 ASG가 0에서 scale-out 되지 않습니다.
Docker Build
앞 단락에서, ARM64 Pod을 띄울 수 있는 Kubernetes node를 준비했으니, 이제 system component와 application을 ARM64용으로 build 해서 띄우는 일이 남았습니다. ARM64 build를 위해 한 일을 간략하게 소개해보겠습니다.
Multi-Arch Image
Docker image, 좀 더 정확히 말하면 OCI (open container inicative) image spec은 multi-architecture를 지원합니다. 즉, redis:6이라는 하나의 container image tag를 AMD64에서도, ARM64에서도 실행시킬 수 있습니다. 내부적으로 container image는 metadata 정보를 가진 manifest가 존재하고, 이 manifest에 지원하는 architecture 목록과 함께 각 architecture별로 사용할 image layer의 주소가 들어있습니다. Container runtime은 현재 architecture를 인식해서, AMD64에서 실행하면 AMD64의 layer를, ARM64에서 실행하면 ARM64의 layer를 pull 한 뒤 실행하게 됩니다.
Container registry마다 조금씩 다르나, DockerHub 같은 경우 직접 container image를 받아 manifest를 분석하지 않아도 다음 화면처럼 Web UI로 쉽게 각 container가 지원하는 architecture를 확인할 수 있습니다.
Local - macOS with Docker
macOS의 Docker Desktop에서는 BuildKit을 통한 cross-archicture build를 지원합니다. 즉, AMD64 이미지와 ARM64 image를 다음과 같은 명령어 1개로 동시에 build 할 수 있습니다.
$ docker buildx build --platform linux/arm64/v8,linux/amd64 --push -t hyperconnect/awesome-service:0.0.1 .
Build 뿐만 아니라, 다른 사람이 만들어놓은 image를 원하는 platform에서 실행할 수 있습니다. 저는 M1 mac을 사용하고 있지만, --platform=linux/amd64 option을 주어 AMD64의 redis:6 image를 실행할 수 있습니다.
% arch
arm64
% docker run --rm -it --entrypoint=arch --platform=linux/amd64 redis:6
x86_64
% docker run --rm --entrypoint=arch --platform=linux/arm64 redis:6
aarch64
Jenkins Build - docker manifest
Local에서의 build test는 docker buildx를 사용하여 간단하게 할 수 있지만, production build는 일이 조금 더 복잡해집니다. buildx는 내부적으로 QEMU라는 hypervisor를 사용하여 서로 다른 instruction set을 emulate 하기 때문에 크게 2가지 문제가 발생합니다.
- Build 속도가 느립니다. Software에 의해서 translation을 수행하므로 machine의 CPU architecture가 아닌 다른 architecture용 image를 build 속도가 매우 느립니다. Local에서 apt-get 관련된 명령어를 수행할 때 10배 이상 느려지는 경우도 있었습니다.
- QEMU는 완벽하지 않습니다. 대부분의 경우 QEMU를 사용해도 아무 문제 없이 build가 성공하지만, 특정 명령어를 수행할 때 segmentation fault 등이 발생하는 경우가 있습니다. Production 환경이므로 운에 맡겨둘 수 없었습니다.
따라서, Intel CPU를 사용하는 Jenkins node와 Graviton2 CPU를 사용하는 Jenkins node를 준비하고, 각각 AMD64와 ARM64용 image를 만든 다음 이를 하나의 image로 합치도록 했습니다.
#!/bin/bash
IMAGE_FULL_NAME="hyperconnect/awesome-service:0.0.1"
# step 1: AMD64 Jenkins node에서 AMD64 image를 build합니다.
docker build . -t "${IMAGE_FULL_NAME}-amd64"
docker push "${IMAGE_FULL_NAME}-amd64"
# step 2: ARM64 Jenkins node에서 ARM64 image를 build합니다.
docker build . -t "${IMAGE_FULL_NAME}-arm64"
docker push "${IMAGE_FULL_NAME}-arm64"
# step 3: AMD64와 ARM64 image를 하나의 image로 합칩니다.
docker manifest create "${IMAGE_FULL_NAME}" "${IMAGE_FULL_NAME}-amd64" "${IMAGE_FULL_NAME}-arm64"
docker manifest annotate --arch amd64 "${IMAGE_FULL_NAME}" "${IMAGE_FULL_NAME}-amd64"
docker manifest annotate --arch arm64 "${IMAGE_FULL_NAME}" "${IMAGE_FULL_NAME}-arm64"
docker manifest push "${IMAGE_FULL_NAME}"
docker manifest rm "${IMAGE_FULL_NAME}"
물론, migration이 불가능하거나 migration이 완료된 경우에는 AMD64와 ARM64 image를 모두 build 할 필요가 없으므로, 사용 중인 script는 좀 더 복잡하게 구성되어 있습니다.
Integrating with CD Pipeline
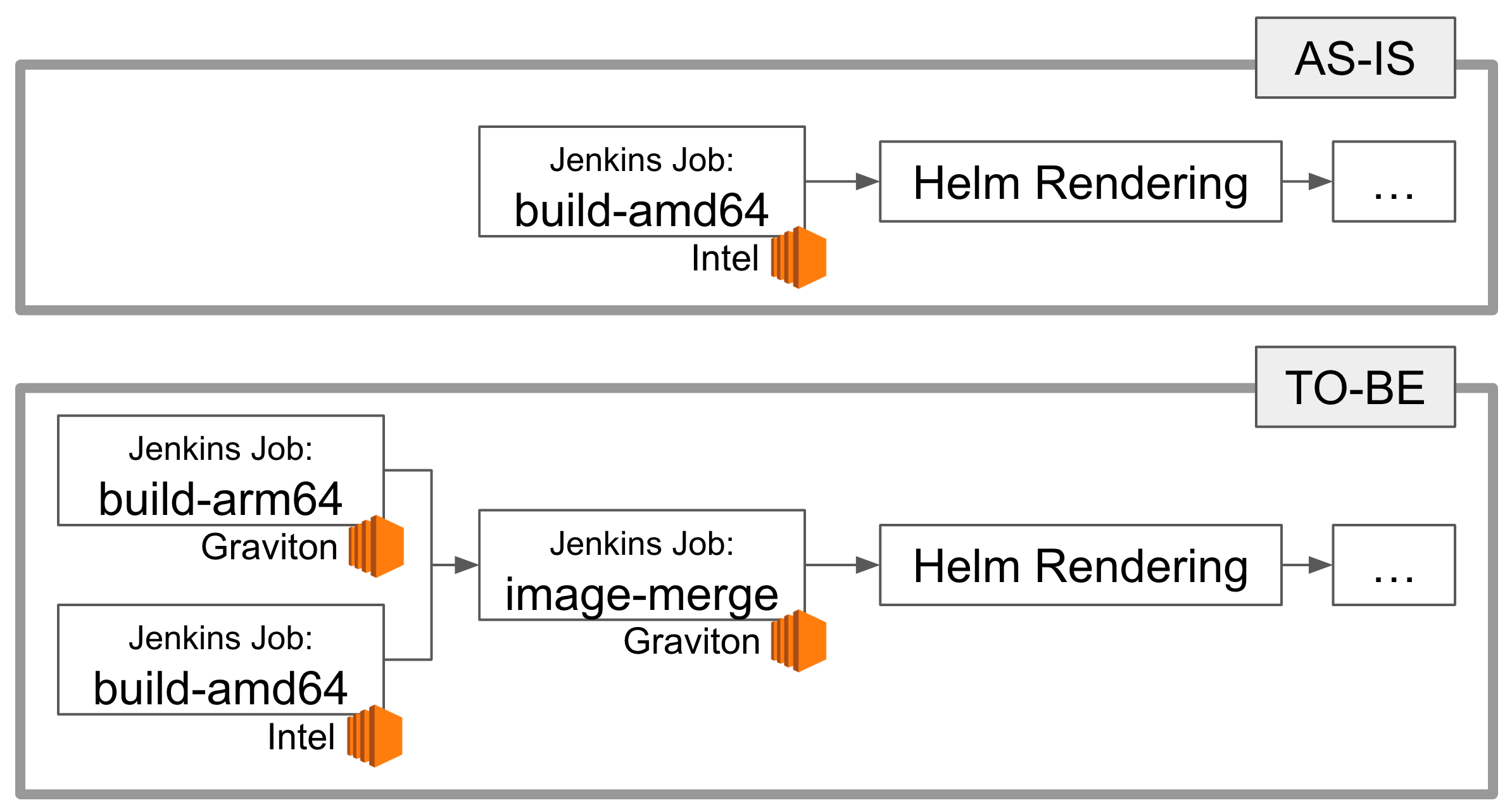
이제 배포 pipeline을 수정해야 합니다. 기존에는 AMD64 build를 수행하는 Jenkins job 1개만 실행되었다면, 이제 AMD64와 ARM64 build를 수행하는 Jenkins job 2개를 실행하고, 이를 하나의 image로 합치는 Jenkins job 1개를 실행하도록 해야 합니다.
Hyperconnect에서는 모든 CD pipeline을 하나의 repository에서 YAML 파일을 사용하여 관리하고 있습니다. 2019년에 처음 도입된 이 시스템은 몇 차례의 개선을 거쳐 현재에도 200+개 이상의 microservice를 QA부터 production까지 모든 배포 환경에서 사용하고 있습니다. 일부 outdated 된 내용이 있지만, 2020년에 기술블로그에서 소개한 내용을 보면 쉽게 이해할 수 있습니다.
이러한 중앙 관리 시스템 덕분에 build pipeline을 수정하는 과정은 매우 간단해졌습니다. 지난번 기술 블로그 소개 내용 이후로 GitHub Action처럼 module을 조합하여 pipeline을 생성하도록 개선하여, 개발자는 다음 1줄만 배포 pipeline에 추가하면 ARM64를 위한 build step을 생성할 수 있습니다.
/pipeline:
docker-build:
uses: docker-build@master
with:
repository: <repo-name>
# other parameters are omitted
mustBuildARM64: true # <- add this line!
이 작업을 한 장의 그림으로 요약하자면, 다음과 같습니다.
System Component Migration
이제 local과 CI에서 ARM64로 build 하여 test 하는 방법을 알았으니, system component를 migration 할 차례입니다. DaemonSet으로 설치되는 monitoring이나 logging 등을 위한 system components는 두 개의 archicture를 모두 지원하도록 무조건 먼저 작업해야 합니다. Migration은 방법은 간단합니다. aws-load-balancer-controller 부터 fluent-bit 까지 사용하고 있는 모든 system component image와 version을 list-up 한 다음, ARM64 image로 변경하면 되는 반복 작업입니다.
Finding the ARM64-Compatible Image
하지만 세상은 만만하지 않습니다. 안타깝게도 사용하고 있는 모든 image가 ARM64를 지원하는 것은 아닙니다. ARM64 image가 없는 application이라면, 선택이 필요합니다.
- 직접 build를 수행합니다. Multiple architecture를 기본적으로 지원하는 golang 기반의 프로젝트라면 base image정도만 수정하는 매우 쉬운 작업이 됩니다.
- 버전을 upgrade 합니다. 점점 더 많은 사람이 ARM64 기반으로 workload를 이전하고 있으므로, 이제는 대부분의 open source project에서 ARM64 버전을 지원하고 있습니다.
- 포기합니다. 세상에는 비슷한 역할을 하는 많은 application이 존재합니다. ARM64를 지원하는 다른 application으로 migration 합니다.
Kubernetes는 golang으로 개발되어 있고, component 역시 golang 생태계가 가장 잘 조성이 되어 있어 대부분의 controller는 multi-architecture image를 제공했습니다. 따라서, 기존 Deployment나 DaemonSet에 nodeSelector 등의 옵션만 수정하면 ARM64 node에 배포되었으며, 정상작동했습니다. 다만, 몇몇 골치를 썩였던 component도 있었는데 그중에서 Istio와 fluent-bit을 소개하겠습니다.
Istio
Istio의 경우 1.6+ 이상부터 크게 2가지 container image로 구성되어 있습니다. 하나는 traffic을 실제로 처리하는 envoy 기반의 istio-proxy이고, 나머지 하나는 각종 Istio의 CRD로부터 envoy 설정을 생성하여 istio-proxy에 배포하는 pilot입니다.
이 블로그를 작성하는 시점에서 Istio는 1.15 버전이 출시되었고, ARM64 이미지를 공식적으로 지원하지만 migration 계획을 처음 세웠던 2022년 6월에는 그렇지 않았습니다. 당시 Hyperconnect에서는 Istio 1.11 버전을 사용하고 있었고, 그 당시 최신 버전인 Istio 1.13 버전에서도 ARM64 image를 지원하지 않고 있었습니다. Istio 때문에 migration을 더 연기해야 하나 고민하던 도중, unofficial Istio image를 찾을 수 있었습니다.
해당 프로젝트의 Dockerfile을 분석한 결과 별 문제가 발생하지 않을 것이라 예상했습니다. istio-proxy의 기반인 envoy는 한참 전부터 ARM64 build를 지원하고 있었고, pilot은 golang으로 개발되었기 때문에 build 설정만 조금 수정하면 ARM64 image를 생성할 수 있어 보였고, 실제로 해당 프로젝트도 build 설정을 조금 수정한 것이 전부였습니다. 물론 이론과 실제는 다를 수 있어 걱정이 되었지만, 어차피 Istio 1.11에서 Istio 1.13으로 upgrade 해야 하는 상황이라 해당 project의 image를 사용해 보기로 했습니다.
Istio 1.4부터 Istio를 upgrade 하고, 다양한 문제 상황을 debugging 한 경험이 있어 더 쉽게 도전적인 결정을 할 수 있었습니다. 결과적으로 unofficial Istio는 30+개의 cluster에서 어떤 문제도 일으키지 않고 잘 작동하였고 블로그를 작성하는 지금 시점에서는 Istio 1.15 버전에서 지원하는 공식 이미지를 사용하고 있습니다.
fluent-bit
Hyperconnect의 일부 legacy component에서는 application이 직접 Kafka로 message를 publish 하는 것이 아닌, publish 할 message를 file에 저장하고 이를 fluent-bit이 sidecar 형태로 붙어서 Kafka로 publish 하도록 되어 있었습니다. Legacy component가 다 그렇듯이, DevOps팀에서는 이를 쉽게 수정할 수 없어 기존 방법을 그대로 유지해야 했습니다. 여기서 fluent-bit이 걸림돌이 되었습니다.
네트워크 순단 등 Kafka에 순간적으로 장애가 발생했다 복구된 경우에도 fluent-bit은 자신이 가지고 있는 buffer를 잘 flush 해야 하는데, 최초 fluent-bit 도입 당시 테스트 당시 최신 버전 (1.8.x)에서는 문제가 있어 오래된 버전(1.7.x)을 사용하고 있었습니다. 이 기회에 version을 높여보자고 생각하고, 최신 버전 (1.9.x)으로 올려 ARM64 node에 넣어봤습니다.
배포 직후에는 예상대로 잘 돌아가서 안심했으나, 1시간 ~ 2일 정도 지난 후에 fluent-bit이 SIGTRAP과 SIGTERM 등 다양한 오류를 발생시키며 죽는 현상을 목격했습니다. fluent-bit은 C로 개발되었기 때문에 기본적으로 trace가 불친절하며, debug를 위해서는 core를 dump 하고, gdb 등의 low-level debugging tool을 사용해야 하는데, 너무 큰 작업이었습니다. 따라서, 최신 버전 upgrade는 포기하고 기존 version을 계속 사용하기로 하고 기존 버전인 (1.7.x)를 그대로 사용했습니다.
하지만 작업은 쉽게 마무리되지 않았습니다. 배포 몇 분만에 encoding error를 발생시키기 시작했습니다. 한글 처리에 문제가 있었고, 검색을 통해 AMD64와 ARM64의 architecture 차이로 인한 문제가 발생했고, 1.8.x 버전에서 해결되었다는 것이었습니다. 결국 해당 patch를 upstream에서 가져와서 직접 build 할 수밖에 없었습니다.
다행히, 이렇게 build 한 image는 예상대로 잘 작동해서 더 이상 fluent-bit이 ARM64 mgiration 작업에 영향을 주는 일은 없었습니다. 참고로, 블로그 작성 시점에서는 최신 버전인 v2.0.x으로 upgrade 하여 custom build 없이 사용하고 있습니다.
Application Migration
이제 application을 migration 할 차례입니다. 그전에, 먼저 base-image를 multi-architecture로 만들어야 합니다.
Support Base Image
Hyperconnect에서는 기본적인 directory 및 non-root 사용자, 내부적으로 사용하는 JVM 특화 설정 및 root CA 등이 포함된 base image를 사용합니다. 이 image는 거의 대부분의 application Dockerfile에서 사용하기 때문에 이 역시 migration이 필요했습니다. Hyperconnect에서는 application에서 사용하는 모든 base-image를 Packer를 사용하여 build 하고 있습니다.
Graviton migration을 처음 시작한 2021년 말에는 Docker plugin에 platform argument를 설정하거나, multi-architecture image를 push 할 수 있는 기능이 없어서 다음과 같이 run_command를 수동으로 override 하고 tag 뒤에 -amd64, -arm64 등 postfix를 붙인 다음, 위에서 설명했던 docker manifest 기능을 사용하여 1개의 multi-architecture tag를 새로 생성했습니다.
variable "arch" {
type = string
default = "amd64"
}
source "docker" "base_image_alpine3.15" {
image = "docker.hyperconnect.com/proxy/library/alpine:3.15"
run_command = ["-d", "-i", "-t", "--entrypoint=/bin/sh", "--platform=linux/${var.arch}", "--", "docker.hyperconnect.com/proxy/library/alpine:3.15"]
}
build {
name = "Base Image - Alpine3.15"
sources = ["source.base_image_alpine3.15"]
provisioner "shell" {
script = "scripts/magic.sh"
}
post-processors {
post-processor "docker-tag" {
repository = "docker.hyperconnect.com/base/alpine"
tags = ["{{isotime \"20060102\"}}-000-${replace(var.arch, "/", "")}", "latest-${replace(var.arch, "/", "")}"]
}
post-processor "docker-push" {}
}
}
Notice to Developers
이제 진짜로 모든 준비가 끝났습니다. Hyperconnect에서는 대부분의 microservice를 JVM 기반의 Java/Kotlin을 사용하여 개발하기 때문에, application에서 사용하는 Dockerfile의 base-image version을 ARM64 지원 버전으로 바꾸고, nodeSelector와 tolerations를 수정하기만 하면 쉽게 AMD64에서 ARM64로 migration 할 수 있습니다! 그렇게 2022년 7월 역사적인 ARM64 공지를 개발자에게 공지하고, migration을 시작했습니다.

서비스에 핵심적인 application은 canary 배포를 수행하여 1시간 ~ 3일 이상 비율을 조절하며 metric을 개발팀과 함께 monitoring 했고, 상대적으로 중요도가 떨어지며 Java/Kotlin만을 사용하여 코드 변경 없이 migration 가능한 application은 개발팀의 도움 없이 DevOps/SRE가 직접 테스트하여 migration 했습니다. 기술 블로그에 소개했던, Istio를 이용한 canary 배포 방법을 사용하여 두려움 없이 안전하게 배포할 수 있었고, DevOps/SRE가 모든 service의 repository 접근이 가능하며 core system metric 및 business metric을 이해하고, monitoring 할 수 있다는 점이 개발자의 직접적인 support 없이 빠르게 migration 하는데 큰 도움이 되었습니다.
물론 system component를 migration 할 때 겪었던 것처럼 세상은 아름답지 않아 몇몇 application이 골치 아프게 했는데요, 몇 가지 예시를 소개해드리겠습니다.
Native Code
Java/Kotlin application이라고 native code로부터 자유로운 것은 아닙니다. Hyperconnect에서 가장 많이 발생한 오류는 netty 관련 dependency에서 발생하는 다음 오류였습니다.
java.lang.UnsatisfiedLinkError: could not load a native library: netty_transport_native_epoll_aarch_64
Netty에서 ARM64를 support 하기 시작한 것은 꽤 오래되었지만, 간접적인 dependency로 netty를 사용하는 경우가 대부분이라 오래된 application 위주로 발생했습니다. 간단히 netty를 dependency로 사용하는 library의 version을 올리는 방법으로 해결했습니다.
Flink
Azar를 구성하는 가장 중요한 서버 중 하나인 match 서버를 포함하여, 내부적으로 10+개 이상의 microservice가 Flink를 사용하여 실시간 streaming data 처리를 하고 있습니다. Flink JVM 위에서 실행되지만, performance 항상을 위해 native memory를 할당받아 직접 관리하는 등 다양한 방법으로 native code를 사용합니다. 따라서, Flink의 경우 프로젝트에서 ARM64를 공식적으로 지원하기 전까지는, 단순히 ARM64를 지원하는 JVM base image 위에서 실행한다는 선택을 할 수 없었습니다.
Flink는 1.14부터 공식적으로 ARM64 container image를 배포하므로 ARM64 migration을 위해서는 Flink version을 1.14 이상으로 업그레이드하는 작업이 선행되어야 했습니다. Framework의 version upgrade는 대부분 code 변경이 같이 진행되어야 하므로 DevOps/SRE팀뿐만 아니라 해당 서비스를 담당하는 개발자의 support가 필요했습니다. 또한, Hyperconnect에서는 대부분의 Flink cluster가 특정 Kafka topic을 consume 하여 데이터를 처리한 후, 다시 Kafka 등으로 producing 하고 있어 infra-level의 설정을 blue/green이나 canary 등의 다양한 배포 방법을 적용하기 어려웠습니다.
다행히 Flink resource 최적화 작업 등 Flink 개선 작업이 전사적으로 진행되었고, Flink 1.14 upgrade 작업과 함께 ARM64 migration이 진행되고 있습니다. DevOps/SRE팀과 개발팀은 가까운 시일 내에 모든 Flink cluster를 ARM64로 전환할 예정입니다.
Python
Python을 단순한 script로 사용하는 것이 아닌, microservice를 개발하기 위해 사용하기 위해 library를 설치하는 순간 많은 native code를 사용하게 됩니다. Wheel을 사용하여 설치하는 많은 library는 속도 향상을 위해 native C extension을 포함하고 있고, 이 native code가 호환성 문제를 발생시킵니다. 많은 project가 ARM64를 지원하기 때문에 단순히 package version을 upgrade 하는 것으로 대부분의 문제를 해결할 수 있지만, dependency chain을 따라 설치되는 library에 문제가 생길 경우 version upgrade가 쉽지 않습니다.
또한, 인기가 많은 library는 ARM64에서 C-extension을 build 한 결과물을 같이 배포하지만, 그렇지 않은 경우 wheel에 의해 직접 build를 수행하게 되고 이는 container image의 build 시간과 사이즈를 키우게 됩니다. 물론 multi-stage build나 image layer cache 등 정석적인 방법으로 문제를 해결할 수 있지만 engineer의 시간을 많이 잡아먹는다는 사실은 변하지 않습니다.
Wrap Up & Future Plan
1년 이상의 기간 동안 정말 다양한 부분에서 많은 시간과 노력을 쏟았고, 지금도 작업은 계속 진행 중입니다. 지금까지 작성했던 어떤 blog post보다 요약이 힘들지만, 정리하자면 다음과 같습니다.
- Kubernetes workload migration을 위해, OS, kubelet 등 package, system component, base-image 등 많은 component가 multi-architecture 환경을 지원하도록 했습니다.
docker manifest등을 사용해서, 한 개의 tag로 AMD64와 ARM64 환경에서 image를 사용할 수 있도록 했습니다. 전사 CD pipeline 관리 도구를 통해 개발자가 yaml 파일에 한 줄을 추가하여 쉽게 ARM64 build를 할 수 있도록 했습니다.- Taints를 가지는 node group을 생성해서 application을 무중단으로 하나씩 migration 할 수 있도록 support 했습니다. 매우 중요한 application은 배포 과정을 같이 monitoring 했고, 상대적으로 중요도가 떨어지는 application은 DevOps/SRE가 직접 테스트하여 migration 했습니다.
제일 처음 그래프에서 소개했듯이 ARM64를 향한 여정은 아직 많이 남아있습니다. 여전히 다양한 이유로 AMD64 node 위에서 실행하는 Kubernetes workload도 존재합니다. ARM64에서 실행했을 때가 AMD64에서 실행했을 때보다 더 느려서 migration이 불가능하거나, 테스트에 시간이 더 필요하거나, library version upgrade가 많이 필요한 legacy component, 아직 ARM64를 지원하지 않는 third-party 도구 등등 아직 많은 관문이 남았습니다. 그리고 이 문제를 함께 해결해 나갔으면 좋겠습니다. 채용공고 바로가기
긴 글 읽어주셔서 감사합니다 :)
References
[1] https://aws.amazon.com/blogs/aws/new-graviton2-instance-types-c6g-r6g-and-their-d-variant/
[3] https://aws.amazon.com/blogs/aws/new-amazon-rds-on-graviton2-processors/
[5] https://aws.amazon.com/blogs/aws/new-amazon-ec2-c7g-instances-powered-by-aws-graviton3-processors/
Read more
-
JVM + Container 환경에서 수상한 Memory 사용량 증가 현상 분석하기
Resource 최적화를 진행하면서 Java container에 할당된 CPU를 줄이자, memory 사용량이 증가했습니다. 신기한(?) 현상을 분석해보았습니다. -
개발자의 AWS 권한을 GitOps로 우아하게 관리하는 방법
많은 개발자가 가지는 많은 권한을 쉽게 관리하고, 개발자가 필요한 권한을 직접 얻을 수 있게 권한 시스템을 설계하고 GitOps 기반 도구를 개발한 과정을 소개합니다. -
ImagePullSecrets 없이 안전하게 Private Registry 사용하기!
ImagePullSecrets 없이 편리하고 안전하게 private registry를 사용 할 수 있도록 Kubelet Credential Provider 기능을 실험해보았습니다. -
Shell 없는 Container, Live 환경에서 Debugging해보기!
Live Pod을 debugging 하기 위해 사용한 kubectl-debug라는 open-source 도구에 대해 소개하고, 이 도구를 Bottlerocket에서 쓰기 위해 패치한 과정을 공유합니다.