Kubernetes에 Microservice 배포하기 1편 - 클릭 몇 번으로 배포 시스템 만들기
안녕하세요, DevOps 팀의 Sammie입니다. Azar와 Hakuna 서버는 microservice architecture (MSA) 구조로 개발하고 있습니다. 서버를 여러 개의 서비스로 분리하면, 개별적인 서비스 배포가 가능하므로 기능 추가나 버그 수정 속도가 빨라지게 됩니다. 하지만, 이를 위해서 배포 pipeline을 microservice 개수만큼 만들어야 합니다. DevOps 팀은 지난 1년간 많은 시행착오를 거치며 CI/CD pipeline을 구성했고, 현재 50개 이상의 microservice에서 개발한 pipeline을 사용하고 있습니다. 몇 개의 글에 걸쳐 이 pipeline과 기술적인 내용을 공유해보려고 합니다.
CI/CD를 구축하는데 사용한 도구에 대해 자세히 적기에는 글이 너무 길어지고, 인터넷에 더 좋은 자료들이 많아 설치 방법과 같은 자세한 설명은 생략하고 글을 이해하는 데 꼭 필요한 내용만 넣었습니다. 이 글, <1편 - 클릭 몇 번으로 배포 시스템 만들기>에서는 현재의 전체적인 pipeline 구조, pipeline을 만드는데 사용한 기술 스택과 선택한 이유를 설명하겠습니다.
Stack Overview
CI/CD pipeline 구축을 위해 다음 기술과 도구를 사용합니다.
-
Kubernetes [1] (Container Orchestration): Container-based deployment 지원, container scheduling, 빠른 배포와 복구 가능, 리소스 절약 등 많은 장점이 있는 Kubernetes를 안 쓸 이유가 없습니다. AWS EKS[2]와 Terraform[3], Terragrunt[4]를 사용하여 cluster를 관리하고 있습니다.
-
Jenkins [5] (CI): DevOps팀에 의해, 중앙관리되는 전사 공용 Jenkins를 사용 중입니다. 지속해서 많은 job이 queue에 쌓이게 되므로, 대량의 concurrent builds와 많은 compute 자원이 필요하게 됩니다. 이러한 이유로, ASG 기반 spot fleet slave node[6]를 구성해서 운영하고 있습니다.
-
Spinnaker [7] (CD): Spinnaker는 EC2 기반의 application과 Kubernetes 기반의 application을 모두 배포 할 수 있으며 다양한 배포전략을 구현하기 용이합니다. Kubernetes에 HA 구성으로 배포하여 사용하고 있습니다.
-
Vault [8] (Secret Management): 기본적으로 Kubernetes
Secret을 관리하며, 각 source code repository의 deploy key를 저장하는 데 사용합니다. Kubernetes와 Vault의Secret을 동기화하기 위해 아래에 있는 secret-sync을 개발했습니다. -
Helm3 [9] (YAML Template Engine): Microservice CI/CD를 구축할 당시 Spinnaker가 Helm2만을 지원하여 Helm2를 사용했습니다. 현재는 Helm3 지원이 추가되어 Helm3만을 사용하고 있습니다. Helm charts에 사용할 –values 파일 (
values.yaml)을 저장하기 위해 독립된 repository를 사용하고 있습니다. -
Harbor [10] (Image and Helm Registry): Harbor를 Kubernetes 위에 설치하여 사용하고 있습니다. 프로젝트별로 권한 관리가 가능하고, HA 구성이 가능하며, AWS load balancer를 사용하면 IP 기반의 접근 제어도 가능합니다.
Pipeline
모든 빌드와 배포는 Spinnaker pipeline을 사용하며, 대부분의 경우 Web UI로 해당하는 pipeline을 trigger 하면서 시작됩니다. HTTP나 git webhook을 사용하는 것도 가능[11]합니다. 예를 들어, 새로운 데이터를 사용하여 주기적으로 학습시키는 kubeflow 기반의 microservice의 경우 모델 검증 후 webhook을 사용하여 자동으로 pipeline을 trigger 합니다.
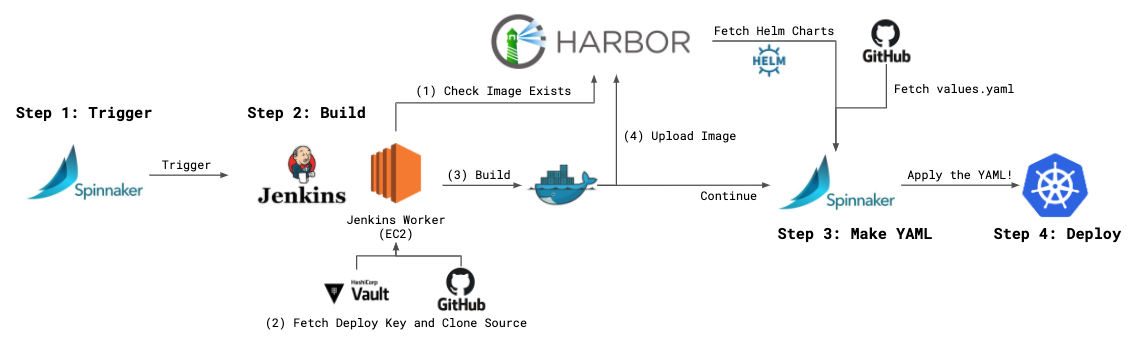
기본적인 pipeline은 다음과 같은 단계로 되어있습니다.
1. Trigger: Docker image 버전, source code repo의 branch와 values.yaml이 존재하는 repo의 branch를 입력합니다. Production의 경우 master branch 외에는 배포할 수 없도록 하여 혹시 모를 장애를 예방하고 있습니다.
2. Build: Pipeline의 첫 번째 stage입니다. Jenkins를 호출하여 build를 시작합니다.
- Harbor에 동일한 이름과 버전의 이미지가 존재하는지 확인하여 중복 build를 방지합니다.
- Vault에 로그인하여 deploy key를 가져와 git repository를 clone 합니다. 이때, Jenkins EC2 node의 instance role을 사용하여 로그인[12]합니다.
- Docker image를 build합니다. Docker BuildKit[13]을 지원하며, maven 등 자주 사용하는 build process는 속도 향상을 위한 별도 명령을 먼저 실행합니다.
- 마지막으로 생성된 Docker image를 Harbor에 push하고, 로컬에서는 삭제합니다.
3. Bake Manifest: Harbor에서 Helm chart를, git에서 values.yaml을 가져와서 Kubernetes YAML manifest를 생성합니다.
4. Deploy: 앞서 생성된 manifest를 apply하고, rolling update가 끝날 때까지 상태를 추적합니다.
이를 그림으로 요약하면 다음과 같습니다.
추가 고려 사항
물론, 실제 사용하고 있는 pipeline은 조금 더 복잡합니다.
- 장애 상황 시 빠른 배포나 테스트, canary 배포를 위해 trigger 단계에서 몇 가지 parameters를 추가로 받습니다.
- Istio[14]의 기능을 사용하여 canary deployment process를 자동화하기 위해 workload (
Deployment또는StatefulSet)와ConfigMap을 생성하는 Helm chart와 routing config (Service,VirtualService,DestinationRule,Gateway등)을 생성하는 Helm chart가 나뉘어 있습니다. (Bake와 Deploy가 2번 나타납니다) - 배포 이후 canary 배포를 종료시키기 위한 단계가 존재합니다. 평상시에는 실행되지 않으며 canary 배포 시 제일 마지막 단계에서 자동으로 실행됩니다. (Preconditions: Disable Canary 이후 step입니다)

YAML, shell script 등과 함께 2편에서 좀 더 구체적인 내용을 다룰 예정입니다. 또한, canary에 관련된 내용은 3편에서 자세히 다룰 예정이니 조금(?)만 기다려주시기 바랍니다.
Pipeline을 사용하기까지
간단해 보이는 pipeline을 사용하기 위해서는 몇 가지 작업이 먼저 수행되어야 합니다. 코드 업데이트를 제외한 대부분은 첫 배포 전 1번만 수행하고 있습니다.
-
코드 및
Dockerfile작성: 프로그래밍 언어의 제약은 없으며 대부분의 서버가 Java (or Kotlin), JavaScript (or TypeScript), Python과 Go로 작성되어 있습니다.Dockerfile은 DevOps팀에서 제공하는 base 이미지를 기반으로 만들고 있습니다. 이 base 이미지에는 기본 non-root 사용자와 home directory가 생성되어 있고, 자주 사용하는 언어의 런타임이 설치되어있습니다. -
values.yaml작성: 모든 microservice는 2개의 공통 Helm charts를 사용하여 배포합니다. Container 이미지,replicaCount,healthCheckPath,ConfigMap내용 등 Kubernetes workload에 필수적인 내용이values.yaml에 작성되어 있습니다. Stack (dev,qa,prod등)에 따라 일부 값이 달라지는 경우가 있어 공용으로 사용하는 파일 한 개와 stack 별로 하나씩 존재합니다. 특히 production stack에서는nodeSelector,affinity,resources등이 엄격하게 지정되어 있습니다. -
Secrets 작성: git repo의 deploy key와 microservice가 사용할 각종 secrets가 Vault에 작성되어 있습니다.
values.yaml은 모든 개발자가 볼 수 있는 공개적인 repository에 저장하기 때문에 database password 등 적을 수 없는 값만 stack 별로 하나씩 작성합니다. 앞에서 언급했듯이 secret-sync라는 작은 Pod이 Vaults에 저장된 secrets를 읽어 대응되는 KubernetesSecrets를 생성해줍니다. -
Spinnaker Pipeline 생성: Pipeline의 전체 구조는 모든 microservice에 동일하게 적용할 수 있지만, microservice와 stack에 따라 대상 cluster나 namespace, 알림이 전송되는 Slack channel 등 조금씩 다른 부분이 있습니다. 복사 + 붙여넣기를 하다 오타가 나거나, pipeline을 변경해야 할 때 하나씩 바꾸느라 야근을 하지 않도록 pipeline을 자동으로 생성하고 수정 할 수 있는 특별한 “도구”를 개발해서 관리하고 있습니다. 이는 2편에서 자세히 다루도록 하겠습니다.
개발자가 1~3단계를 끝내고, DevOps 팀에서 4단계를 마치면 마침내 Spinnaker pipeline을 사용할 수 있는 상태가 됩니다.
Dockerfile과 values.yaml 리뷰가 통과되고 첫 배포가 성공하게 되면 DevOps팀의 주요 업무는 끝납니다. 업데이트된 코드나 values.yaml이 있으면 개발자가 독립적으로 pipeline을 실행 시켜 배포하고 있습니다. 다만 안정성을 확보하기 위해 production의 values.yaml이 수정된 경우 DevOps팀의 리뷰를 받아 배포합니다.
Secret Sync - Secret Management for Kubernetes
Vault는 기본적으로 key-value 값을 저장할 뿐, 이를 Kubernetes Pod이 사용할 수 있는 형태로 만들어주지는 않습니다. 지금은 Vault sidecar[15]를 사용하여 쉽게 설정이 가능하지만, pipeline 구축 당시에는 없었습니다. 따라서 아래 4가지 방법 정도를 선택 할 수 있었습니다.
Choice 1. Microservice에서 직접 사용
Microservice에서 직접 Vault API를 호출하여 secrets를 가져옵니다.
- 장점: 거의 무한대의 자유도가 있으며, 개발만 한다면 secrets hot reloading이 가능합니다. 권한을 분리하면 해당 microservice만 secrets를 읽을 수 있습니다.
- 단점: 서비스에 Vault API에 의존적인 코드가 포함되며, microservice마다 authentication이 필요합니다.
Choice 2. Sidecar 개발
Vault의 내용을 읽어 파일로 전달하는 image를 개발하여 microservice와 같이 배포합니다. (위에서 소개한 Vault sidecar와 같은 형식입니다)
- 장점: 개발자는 Vault API에 대해 알지 못해도 됩니다. 표준적인 파일 입력을 사용하여 데이터를 받을 수 있습니다. 1과 마찬가지로 권한을 분리하면 해당 microservice만 secrets를 읽을 수 있습니다.
- 단점: Vault에 저장할 때 지정된 format을 따라야 합니다. 모든 Pod에 sidecar가 붙어야 하므로 추가적인 리소스를 사용합니다. 1과 마찬가지로 microservice마다 authentication이 필요합니다.
Choice 3. Kubernetes Secret으로 동기화
중앙화된 1개의 Pod이 주기적으로 cluster의 모든 Vault secrets를 읽은 다음, 각 Namespace에 Kubernetes Secret을 생성합니다.
- 장점: Sidecar 개발 방식의 장점을 포함합니다. Sidecar가 필요 없어 리소스가 절약됩니다. Authentication은 Pod 1개에 대해서 전체 권한을 부여하면 되므로 간단해집니다.
- 단점: 해당 namespace에 접근 권한이 있는 모든 개발자가 다른 microservice의 secret을 볼 수 있습니다. 중앙화된 Pod에 Vault뿐만 아니라 Kubernetes에 대해서도 많은 권한이 필요합니다.
Choice 4. Do It as You Want
개발자가 3가지 방식 중 하나를 고르게 합니다.
- 장점: 가장 자유도가 높습니다. 장점을 선택할 수 있습니다.
- 단점: 추적이 매우 어렵고, 올바르게 권한을 설정하기 상당히 복잡해집니다.
Product 별로 Kubernetes cluster가 나누어져 있으며, DevOps팀을 제외하고는 cluster admin 권한이 없었고, 팀별로 Namespace가 분리되어 있으므로 microservice마다 권한을 분리할 필요성을 느끼지 못했습니다. 또한 위의 방법을 혼합하여 사용하게 된다면 DevOps팀의 관리 능력을 벗어날 것 같아, 결론적으로 3번 방식을 선택하기로 했습니다.
먼저, 모든 Vault secrets는 k8s-secret/<cluster-name>/<namespace>/ 하위 경로에 작성하도록 규칙을 정했습니다. 그리고 1분마다 k8s-secret/<cluster-name>/ 하위의 모든 secrets를 읽어 지정된 Kubernetes Namespace에 Secret으로 만들어주는 작은 프로그램인 secret-sync를 만들었습니다. 마지막으로 모든 Namespace Secret에 read/write 권한을 가지는 ClusterRole을 생성하고, DevOps만 접근 권한이 있는 devops Namespace에 배포했습니다. 현재에도 10개 이상의 cluster에 하나씩 설치되어 열심히 secret을 동기화하고 있습니다.
언젠가 Secret Sync 코드와 Vault 연동 설정, Secret 동기화 설정 등을 별도의 게시글과 Github으로 공개할 예정입니다 :)
Behind the Development
이 단락에서는 CI/CD pipeline 개발 배경에 대해 간략하게 설명합니다. 읽지 않으셔도 다음 글을 이해하는 데 아무 문제도 없습니다.
Pipeline 개발은 2019년 5월에 시작되었습니다. 당시 Azar Backend팀에는 monolithic한 API 서버와 최근에 분리한 1~2개의 microservice가 있었고, EC2 AMI를 만들어 Spinnaker로 배포하고 있었습니다. 하지만 다른 팀에서 개발한 microservice는 여전히 ssh 접속 후 script 실행이라는 고전적인 방법으로 배포했습니다. Container 기술은 production에서 거의 사용되고 있지 않았으며, 당연히 production Kubernetes cluster도 없었습니다. 테스트 서버를 띄우기 위해 Kubernetes를 사용하고는 있었지만 구버전이었고, 단순히 문자열을 치환하는 shell script를 template engine으로 사용했습니다.
그러던 어느 날, Azar에 새 기능이 추가되면서 microservice 몇 개를 배포해야 하는 일이 생겼습니다. 요구사항은 다음과 같았습니다.
- Kubernetes로 쉽게 이전 할 수 없는 API 서버에서 microservice를 호출합니다.
- 사용자가 microservice를 직접 호출하는 경우는 없습니다.
- 트래픽은 전부 1개의 port로만 들어오며, protocol은 HTTP/1.1입니다.
- RDS, DyanmoDB, AWS ElastiSearch Service 등에 데이터를 저장합니다.
회사의 인프라 상황과 위의 요구사항을 종합하여 몇 가지 초기 목표를 설정했습니다.
- 빠른 구축: 안타깝게도 production 배포까지 1달 정도의 짧은 시간이 남아있었습니다. 빠르게 PoC를 진행하고, 최소한의 안정성을 가진 pipeline을 구축해야 했습니다.
- Infrastructure-as-a-code: Terraform code와 Terraform state와 실제 infrastructure가 전부 다른 경우가 종종 있었고, 손으로 구축된 경우도 있었습니다. 기존 Terraform state 및 존재하는 AWS resource와의 의존성을 줄이고 모든 설정을 코드로 다루고 싶었습니다.
- 많은 자동화: DevOps 일이 공통으로 가지는 당연한 목표입니다. 게다가 Azar backend팀에서 microservice 구조로 개편하기로 하여 microservice가 빠른 속도로 많아질 수도 있었습니다. 실제로 당시에는 Azar 서비스만 10개 정도의 microservice를 사용했지만, 지금은 여러 product가 50개 이상의 microservice를 사용하고 있습니다.
- 익숙한 도구: Google과 같은 대기업에 비하면 개발자가 적은 신생(?) 회사였지만, 모든 것을 쉽게 뜯어고칠 수 있을 만큼 작은 기업은 아니었습니다. 이미 Jenkins, Spinnaker, Nexus3 등 많은 도구를 개발자들이 사용하고 있었습니다.
Azar Backend팀과의 논의, 수많은 Googling과 PoC(=삽질)을 거쳐 글의 제일 처음에 있던 기술 스택을 사용하게 되었습니다.
- Kubernetes: 이미 kops를 사용하여 테스트 서버용 cluster가 배포되어 있어, 설정을 복사하고 몇몇 부분을 수정해 첫 번째 production cluster를 쉽게 띄웠습니다.
- Jenkins: 이미 사용하고 있던 EC2 기반 Jenkins를 사용했습니다. 낮은 버전, 알 수 없는 credentials 등의 이유로 Kubernetes로 migration 했습니다.
- Spinnaker: 이미 사용하고 있던 EC2 기반 Spinnaker를 사용했습니다. 낮은 버전, HA 미지원 등의 이유로 Kubernetes로 migration 했습니다.
- Vault: AWS SSM parameters, Spinnaker 배포 시 EC2 user data 설정, 공유된 EFS volume을 사용하거나 해당 EC2 instance에 직접
.env파일을 넣어 사용하는 등 전사적으로 secret이 젼혀 관리되지 않았습니다. Vault를 구축해놓는다면 장기적으로 Vault에 있는 많은 기능을 다양한 분야에 사용할 수 있으리라 생각하여 신규 구축했습니다. 현재는 팀 간 secret 공유, ssh 접속, 내부 인증서 관리 등에 사용하고 있습니다. - Nexus[16]: AWS ECR[17]을 사용하는 service가 있었습니다. 하지만 당시에는 AWS SSO[18]가 적용되어 있지 않아 multi-account 권한 관리의 어려움이 있어 임시로 Nexus3에 Docker registry를 설치해서 사용했습니다. Java package repository부터 Andriod, iOS build artifact 저장용으로 이미 Nexus3을 사용하고 있어 repository 추가 작업만 진행했습니다. 지금은 전부 Harbor로 migration 된 상태로 Nexus3는 사용하지 않습니다.
Wrap Up
- Hyperconnect에서는 10개 이상의 Kubernetes cluster에 50개 이상의 microservice를 배포하기 위해 다음 기술을 사용합니다.
Kubernetes, Jenkins, Spinnaker, Vault, Helm3, Harbor
- 모든 microservice는 2개의 Helm charts를 공용으로 사용합니다. Microservice나 stack에 따라 다른 설정을 주기 위해
values.yaml을 작성해서 공용 repository에 저장합니다. - 코드를 수정하거나,
values.yaml을 수정한 다음 Spinnaker pipeline을 실행시키면 build부터 배포까지 한 번에 수행됩니다. - DevOps팀은 “도구”를 사용해서 Spinnaker pipeline을 찍어내고 있습니다
- Vault에 secrets를 저장하면, secret-sync라는 도구가 Kubernetes
Secret으로 변환해줍니다.
다음 글에서는 DevOps팀이 사용하는 “도구”와 Helm chart, Spinnaker pipeline에 대해서 좀 더 자세히 설명하겠습니다.
Microservice 배포 자동화에 조금이나마 도움이 되었으면 좋겠습니다.
읽어주셔서 감사합니다 :)
언제나 글 마지막은 채용공고입니다. 이렇게 재미있는(?) 일을 같이할 DevOps와 Backend 개발자분들의 많은 지원 부탁드립니다. 채용공고 바로가기
References
[2] https://aws.amazon.com/eks/
[4] https://terragrunt.gruntwork.io
[8] https://www.vaultproject.io/
[9] https://helm.sh/
[10] https://goharbor.io/
[11] https://www.spinnaker.io/guides/user/pipeline/triggers/webhooks/
[12] https://www.vaultproject.io/docs/auth/aws#iam-auth-method
[13] https://github.com/moby/buildkit
[14] https://istio.io/
[15] https://www.hashicorp.com/blog/injecting-vault-secrets-into-kubernetes-pods-via-a-sidecar/
[16] https://www.sonatype.com/product-nexus-repository
Read more
-
1년 동안 Workload의 절반을 ARM64로 Migration하기
AWS에서는 ARM64 기반의 Graviton processor를 지원합니다. 가격도 저렴하고 성능도 좋은 Graviton을 production Kubernetes cluster에 도입하여, 1년 동안 50%의 workload를 전환한 경험을 공유합니다. -
JVM + Container 환경에서 수상한 Memory 사용량 증가 현상 분석하기
Resource 최적화를 진행하면서 Java container에 할당된 CPU를 줄이자, memory 사용량이 증가했습니다. 신기한(?) 현상을 분석해보았습니다. -
개발자의 AWS 권한을 GitOps로 우아하게 관리하는 방법
많은 개발자가 가지는 많은 권한을 쉽게 관리하고, 개발자가 필요한 권한을 직접 얻을 수 있게 권한 시스템을 설계하고 GitOps 기반 도구를 개발한 과정을 소개합니다. -
ImagePullSecrets 없이 안전하게 Private Registry 사용하기!
ImagePullSecrets 없이 편리하고 안전하게 private registry를 사용 할 수 있도록 Kubelet Credential Provider 기능을 실험해보았습니다.