ksqlDB를 이용하여 실시간 ML 피쳐 데이터를 계산하기
추천 시스템과 같은 머신러닝 어플리케이션에서 피쳐 데이터(feature data)는 성능에 큰 영향을 끼칩니다. 일반적으로 높은 품질의 피쳐 데이터를 많이 사용할수록, ML 모델의 성능 또한 높아지죠. 피쳐 데이터는 실시간 피쳐 (유저 행동 직후 즉각적으로 값이 업데이트되는 피쳐)와 비실시간 피쳐 (배치 등으로 업데이트에 지연시간이 존재하는 피쳐)로 구분 할 수 있습니다. 하이퍼커넥트 서비스들에서 실시간 피쳐는 비실시간 피쳐보다 더 성능에 큰 영향을 끼칩니다. 하이퍼커넥트의 서비스들은 대부분 온라인 유저만 추천할 수 있다는 제약이 존재하며, 유저-유저 추천 시스템이 대부분이기 때문입니다 [1]. 이런 경우에서 실시간 피쳐는 유저의 특성을 더 빠르고 정확하게 나타내기에, 좋은 실시간 피쳐를 많이 사용하면 성능을 더 끌어올릴 수 있습니다.
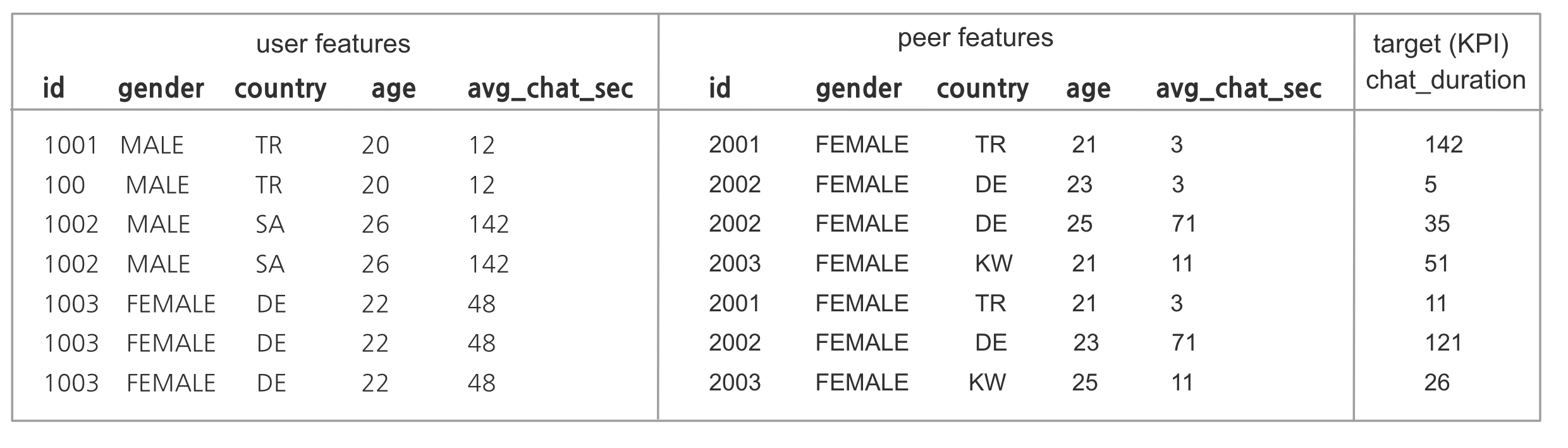
그림 1. 추천 시스템에서의 데이터셋과 피쳐 데이터. 같은 피쳐 데이터라도 실시간으로 업데이트 되면 더 높은 정확도를 보일 수 있다.
하지만 실시간으로 피쳐 데이터를 제공하는 것은 많은 비용이 듭니다. 각 유저마다 추천 요청이 왔을 때, 모델의 추론 시점에 필요한 데이터를 실시간으로 매번 계산하는 것은 거의 불가능하기 때문입니다. 더불어 일반적으로 유저와 아이템의 숫자는 매우 많기에, 백그라운드에서 모든 유저 및 아이템의 피쳐 데이터를 실시간으로 계산하는 것 또한 불가능에 가깝습니다. 대신 피쳐 데이터가 바뀔 때를 인지하고, 데이터가 바뀐 유저나 아이템에 대해서만 피쳐 데이터를 비동기적으로 갱신해 줘야 합니다. 이는 보통 정교한 백엔드 엔지니어링이나 데이터 엔지니어링 작업을 필요로 하는데, 그 비용으로 인해 실시간 피쳐 추가를 어렵게 만듭니다.
하이퍼커넥트에서는 일반적으로 제품 백엔드에서 발행해 주는 이벤트를 통해 실시간 피쳐를 계산하고 있습니다 [2]. 실시간 피쳐 계산 로직은 주로 Apache Flink로 구현하고 있지만, 카프카(Kafka)에서 제공하는 ksqlDB을 통해서도 구현할 수 있습니다. 이 포스트에선 ksqlDB을 이용하여 실시간 ML 피쳐 데이터를 계산하는 방법에 대해 소개합니다.
ksqlDB란
ksqlDB을 쉽게 말하면 SQL 문법을 사용하여 스트리밍 어플리케이션을 만들 수 있는 오픈소스입니다. 아래 그림처럼 어떤 메시지를 받아서 다른 종류의 메시지를 생성하는 것을 주로 스트리밍 어플리케이션이라고 하는데, 이런 어플리케이션을 SQL 만으로 정의할 수 있죠.
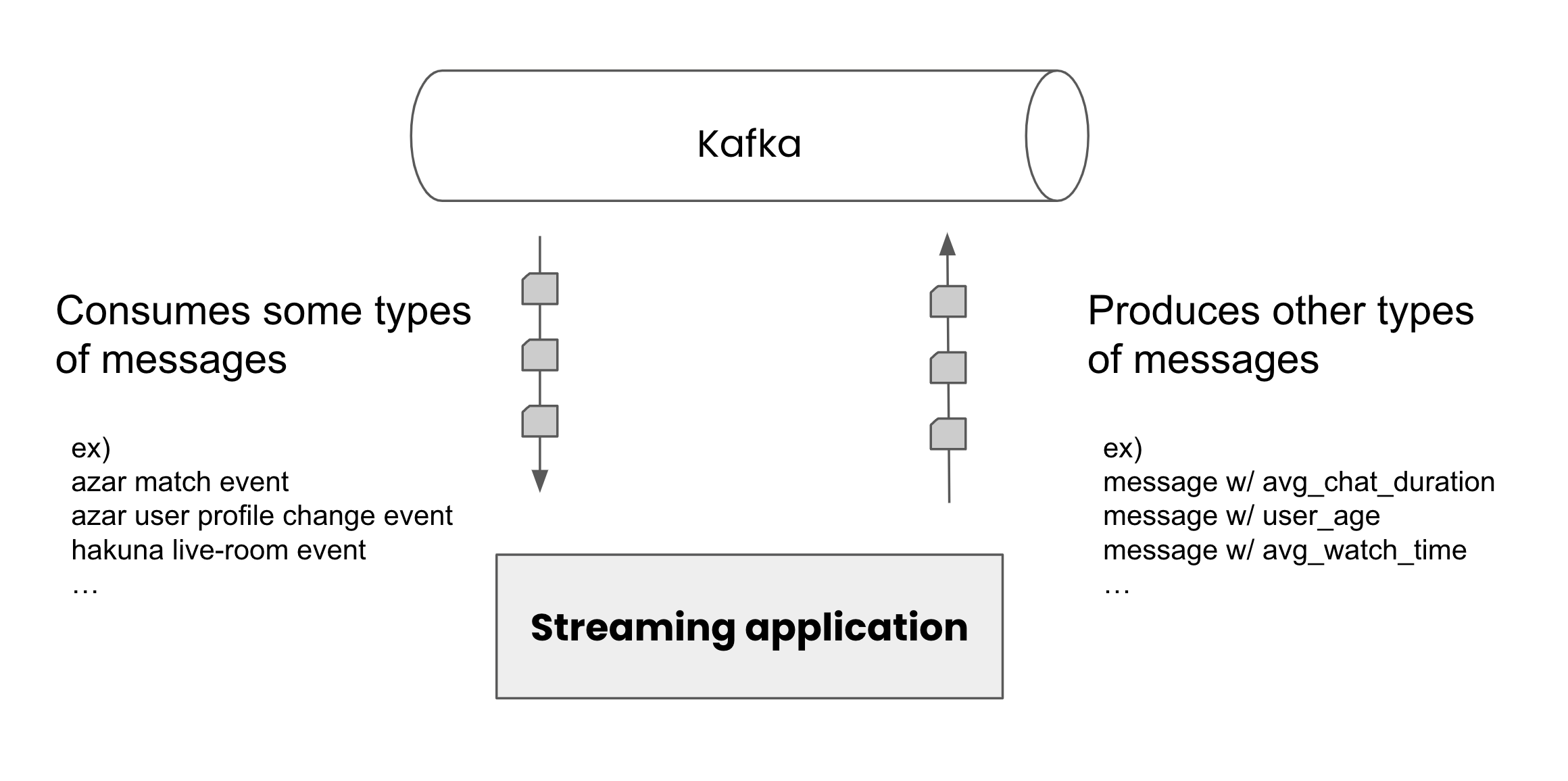
그림 2. 스트리밍 어플리케이션
예를 들어 ksqlDB에서는 아래와 같은 SQL 문법을 사용할 수 있습니다. ksqlDB에 더 자세히 알고 싶다면 Dante.R님이 쓴 다른 블로그 글 [3]도 읽어보시는 것을 추천드립니다.
CREATE STREAM male_users WITH (KAFKA_TOPIC=...) AS
SELECT
userId,
gender,
timestamp
FROM azar_user_registered
WHERE gender = "MALE"
EMIT CHANGES;
스트리밍 어플리케이션을 개발하기 위해서는 코드 작업 뿐만 아니라 마이크로서비스 생성, 배포, 모니터링, 리소스 조정 등 해야 할 것이 적지 않습니다. 하지만 ksqlDB를 사용하면 SQL을 작성하고 시스템 상에 등록만 하면 끝이죠. 물론 ksqlDB는 아직 매우 제한적인 기능만 제공하며, 최신 기술인만큼 안정성에 대한 검증이 충분히 되지는 않았습니다. 그럼에도 불구하고 추천 도메인에서 ksqlDB는 매우 매력적인 옵션이라고 생각합니다. 매우 빠르게 피쳐 데이터를 실시간으로 사용할 수 있도록 만들어주기 때문입니다.
ksqlDB로 실시간 피쳐 데이터를 제공하는 방법
최근 추천 도메인에서 피쳐 데이터는 피쳐 스토어 (Feature Store)라고 불리는 컴포넌트에서 주로 관리되고 있습니다. 피쳐 스토어를 간단히 소개하면 피쳐 데이터를 모델 학습과 추론 시에 모두 사용 가능하도록 만들어주는 일종의 데이터베이스의 개념입니다 [4].
피쳐 스토어에 실시간으로 피쳐 데이터를 업데이트하는 방법에는 여러 가지가 있겠지만, 그 중 하나는 카프카(Kafka)를 이용하는 방법이 있습니다. 대표적인 오픈소스 피쳐 스토어인 Hopsworks [5]에서도 카프카를 이용해서 피쳐를 업데이트할 수 있도록 인터페이스를 제공하고 있으며, 하이퍼커넥트의 인하우스 피쳐스토어 또한 카프카를 통한 업데이트를 지원하고 있습니다 [1].
이처럼 피쳐 스토어에 데이터를 업데이트하기 위해 카프카 메시지를 사용한다면, ksqlDB는 실시간 피쳐를 만들기 위해 굉장히 적합한 옵션이라는 것을 눈치챌 수 있습니다. 왜냐하면 우리가 실시간 피쳐 데이터를 제공하기 위해 해야 하는 일이, 제품 조직에서 발생한 카프카 메시지를 받아서 피쳐 스토어를 위한 적합한 카프카 메시지를 발행하는 것이니까요.
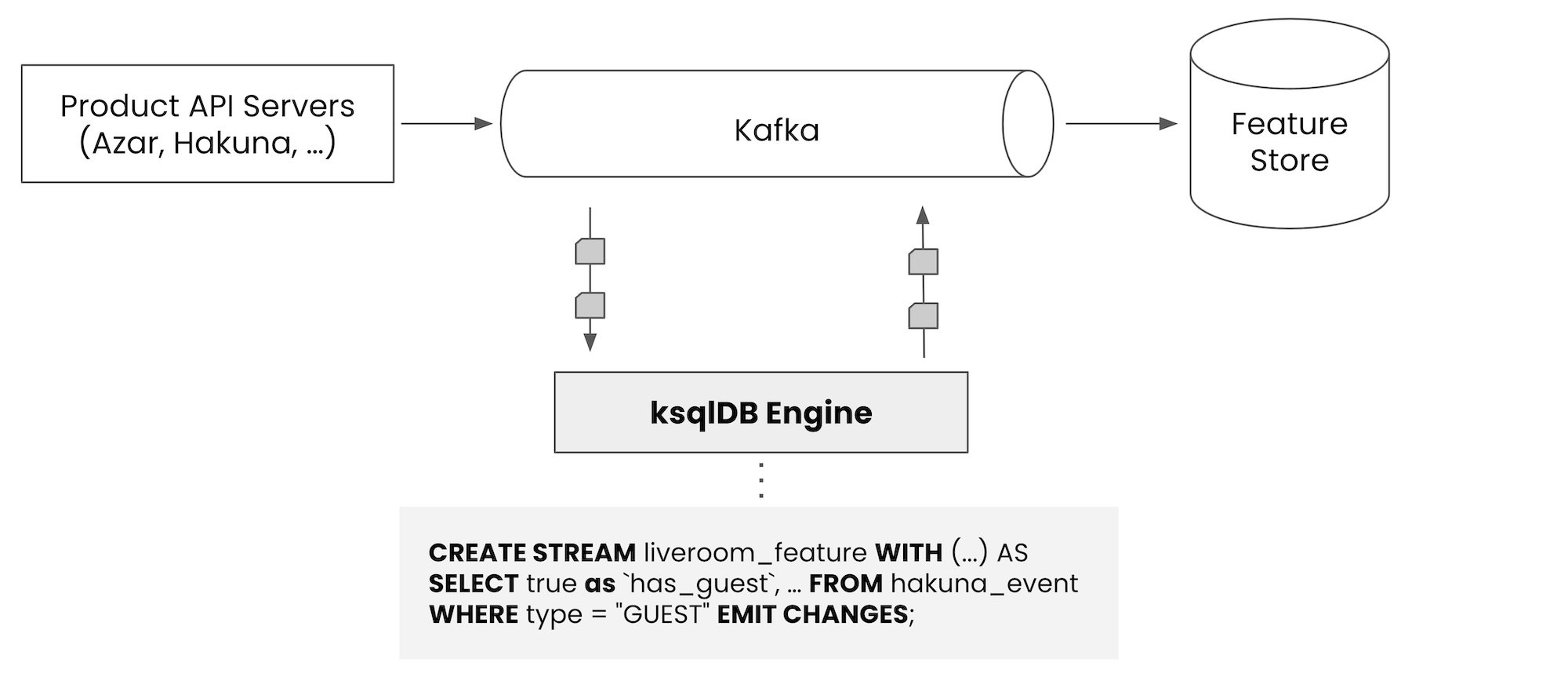
그림 3. ksqlDB와 스트리밍 어플리케이션
위 그림처럼 제품 조직에서 카프카로 발행하고 있는 메시지(이벤트)가 있다면, ksqlDB에 적당한 SQL만 작성해서 등록하는 방식으로 실시간 피쳐 데이터를 피쳐 스토어에 저장할 수 있습니다. 코드 한 줄 작성하지 않고 SQL 작성만으로 가능하다는 것이 참 편리한 부분이죠.
실시간 피쳐 데이터를 계산하는 KSQL 예시
이번 섹션에서는 실제 ksqlDB에서 사용하는 SQL 예시를 들어보겠습니다.
예시 1 - 단순한 스키마 변환 (Transform)
먼저 기존에 존재하는 메시지(이벤트)를 피쳐 스토어를 위한 포맷으로 스키마를 변환하는 예시입니다. 매우 단순하다고 생각할 수 있지만, 사실 생각보다 매우 자주 필요한 패턴입니다. 왜냐하면 제품 백엔드에서는 도메인 이벤트만을 발행하고 싶어 하지, 피쳐 스토어만을 위한 전용 메시지를 발행하고 싶지 않을 것이기 때문입니다. ksqlDB를 통해 피쳐 스토어에서 필요한 메시지로 변환하는 작업이 매우 쉽기 때문에, 제품 백엔드 조직에서는 피쳐 스토어를 위해서 별도로 개발 작업을 해주지 않아도 됩니다. 도메인도 깔끔하게 분리할 수 있고요.
또한 잘 설계된 시스템이라면 이미 제품 백엔드에서 주요한 도메인 이벤트를 카프카에 발행하고 있을 가능성이 높습니다. 그렇다면 ML 조직 입장에서는 개발 코스트 없이 SQL 작성만으로 실시간 피쳐를 적재할 수 있습니다.
CREATE STREAM feature_store_command1 WITH (...) AS
SELECT STRUCT(
`feature_name` := 'user-profile',
`method` := 'UPDATE',
`keys` := STRUCT(
`user_id` := userId
),
`values` := STRUCT(
`level` := userLevel,
`_last_updated_at_ms` := timestampMillis
)
)
FROM azar_user_cdc
EMIT CHANGES;
위는 제품 백엔드에서 발행한 도메인 이벤트로부터 피쳐 스토어에 필요한 메시지로 바꾸는 단순한 예시입니다. 예시를 보면 필드 이름에 ` 가 붙어있는 부분을 특이하게 생각할 수도 있습니다. ksqlDB에서는 기본적으로 필드 이름에 대해 case insensitive 한 정책을 따르며, ksqlDB Stream을 카프카 메시지로 다시 내보낼 때에는 이런 필드들에 대해 upper case로 변환해서 보내줍니다. 필드들에 대해 Lower case로 변환된 상태로 메시지를 발행하고 싶다면 필드 이름 앞뒤로 `를 붙여주어야 합니다 (confluent kafka 기준) [6].
예시 2 - 필터링 (where 문으로 필요한 메시지 필터링)
앞의 예시와 비슷하지만 WHERE 문을 이용해서 필터링하는 예시도 자주 사용되는 패턴입니다. 하나의 카프카 토픽에는 여러 메시지가 발행될 수 있습니다. 대표적으로 라이브 방송의 입장/퇴장 이벤트는 서로 다르지만, 하나의 토픽에 발행될 수 있죠. 이런 경우에 우리는 한 종류의 메시지만 필터링 하고 싶을 수 있습니다.
아래는 대표적인 예시로, participantType = 'GUEST' 이면서 eventType = 'ENTRANCE' 인 메시지만 필터링하고, 이 경우에는 ``has_guest := true 의 피쳐스토어 메시지를 발행하는 예시입니다.
CREATE STREAM feature_store_command2_1 WITH (...) AS
SELECT STRUCT(
`feature_name` := 'live-room-context',
`method` := 'UPDATE',
`keys` := STRUCT(
`live_room_id` := liveRoomId
),
`values` := STRUCT(
`has_guest` := true,
`_last_updated_at_ms` := timestampMillis
)
)
FROM live_room_event
WHERE participantType = 'GUEST' AND eventType = 'ENTRANCE'
EMIT CHANGES;
아래 SQL은 반대로 ‘게스트 퇴장’ 메시지만 필터링합니다. 위 SQL와 아래 SQL을 모두 ksqlDB에 등록하면 실시간 ‘게스트 여부 피쳐’를 사용할 수 있게 됩니다.
CREATE STREAM feature_store_command2_2 WITH (...) AS
SELECT STRUCT(
`feature_name` := 'live-room-context',
`method` := 'UPDATE',
`keys` := STRUCT(
`live_room_id` := liveRoomId
),
`values` := STRUCT(
`has_guest` := false,
`_last_updated_at_ms` := timestampMillis
)
)
FROM live_room_event
WHERE participantType = 'GUEST' AND eventType = 'LEAVE'
EMIT CHANGES;
예시 3 - 짧은 기간의 Windowing
우리가 주로 사용하는 피쳐 데이터에는 합, 평균과 같은 최근 N분간의 aggregation 피쳐가 많습니다 (ex. 최근 1시간 동안의 평균 대화시간, 최근 10분간 클릭 수 등). 이런 데이터를 계산하기 위해서 스트리밍 어플리케이션에선 보통 Windowing 이라는 기능을 많이 사용합니다. 예를 들어 최근 10분간의 메시지들을 모두 입력으로 받은 다음, Count(), Sum() 과 같은 aggregation function을 호출하여 피쳐를 계산하곤 하죠.
ksqlDB은 Windowing 방식으로 Tumbling Window, Hopping Window, Session Window 의 3가지 방식을 제공합니다 [7]. 참고로 스트리밍 어플리케이션에서 가장 보편적으로 사용되는 Sliding window (메시지가 들어온 시점으로부터 최근 N분간을 windowing)는 ksqlDB에서 지원하지 않습니다. 세 가지 windowing 방법 중에서 어떤 것을 사용해야 할까요?
우선 Session Window는 시간 기반의 windowing 방식이 아닌, 유저의 세션이 지속되는 동안 윈도우가 계속 늘어나도록 동작합니다. 애초에 고정된 시간 기반의 윈도우가 아니라 가변 길이로 동작하므로, 우리가 의도하는 “최근 10분간의 피쳐”를 계산하려는 우리의 목적과 맞지 않습니다. 따라서 Session Window는 적합하지 않습니다.
다음으로 Tumbling Window를 사용하는 것을 고려할 수 있습니다. Tumbling Window는 고정된 시간으로 윈도우를 만드는 방식입니다. 예를 들어 10분짜리 Tumbing Window를 만들면, (17:00 ~ 17:10), (17:10 ~ 17:20), (17:20 ~ 17:30), ... 와 같은 윈도우들이 만들어집니다. 아래 그림을 참고하시면 Tumbling Window가 어떻게 동작하는지를 대략적으로 알 수 있습니다.

그림 4. ksqlDB의 Tumbling Window
얼핏 보았을 땐 Tumbling Window를 사용하면 “최근 10분간의 aggregation 피쳐”를 만들 수 있을 것처럼 보이지만, 사실 어려운 문제가 존재합니다. 아래 시나리오를 생각해 봅시다.
message arrived | window | count(*) in window | what we want |
17:00 | 17:00 ~ 17:10 | 1 | 1 |
17:02 | 17:00 ~ 17:10 | 2 | 2 |
17:04 | 17:00 ~ 17:10 | 3 | 3 |
17:06 | 17:00 ~ 17:10 | 4 | 4 |
17:08 | 17:00 ~ 17:10 | 5 | 5 |
17:10 | 17:10 ~ 17:20 | 1 | 5 |
17:12 | 17:10 ~ 17:20 | 2 | 5 |
위와 같은 시나리오를 보면, 현재 시간이 17:12인 경우에, 할당되는 Window의 구간이 (17:00 ~ 17:20) 이 되고, 해당 Window에서 COUNT(*)를 실행하면 결과가 2가 나오게 됩니다. 우리는 사실 현재 시점 기준으로부터 “최근 10분간의 COUNT”를 구하고 싶은 것이고, 그렇다면 위와 같은 시나리오에서는 5라는 값이 출력되길 바랄 것입니다. 하지만 Tumbling Window는 현재 시점 대비 상대적인 Window가 만들어지지 않고, 절대적인 시간을 기준으로 윈도우가 생성됩니다. 따라서 우리가 원하는 “현재 시각 기준 최근 10분” 이라는 조건의 윈도우를 만들 수 없고, 따라서 윈도우의 aggregation function 결과 또한 우리가 의도하지 않은 결과가 나오게 되죠. Tumbling Window 또한 최근 N분간의 aggregation 피쳐를 만들기엔 적합하지 않은 것을 확인할 수 있습니다.
마지막 후보는 Hopping Window 입니다. Hopping Window는 Tumbling Window와 비슷하게 고정된 윈도우 크기를 가지지만, hop interval 기준으로 다수의 윈도우를 생성합니다. 예를 들어 Window size = 10분, Hop size = 2분으로 설정하면 구간이 겹치는 윈도우들이 여러 개 만들어집니다. 구체적으로는 위와 같은 설정에서 (window_size=10min, hop_size=2min) 하나의 메시지가 입력으로 들어오면, 한 시점에 총 5개의 Window가 존재하게 됩니다. 다시 말하면 어떤 하나의 해당 메시지는, 총 5개의 Window에 동시에 포함될 수 있죠. 예시를 들어볼까요? 아래 그림을 보면 Tumbling Window와는 다르게, 하나의 메시지가 여러 윈도우에 포함되는 것을 확인할 수 있습니다.
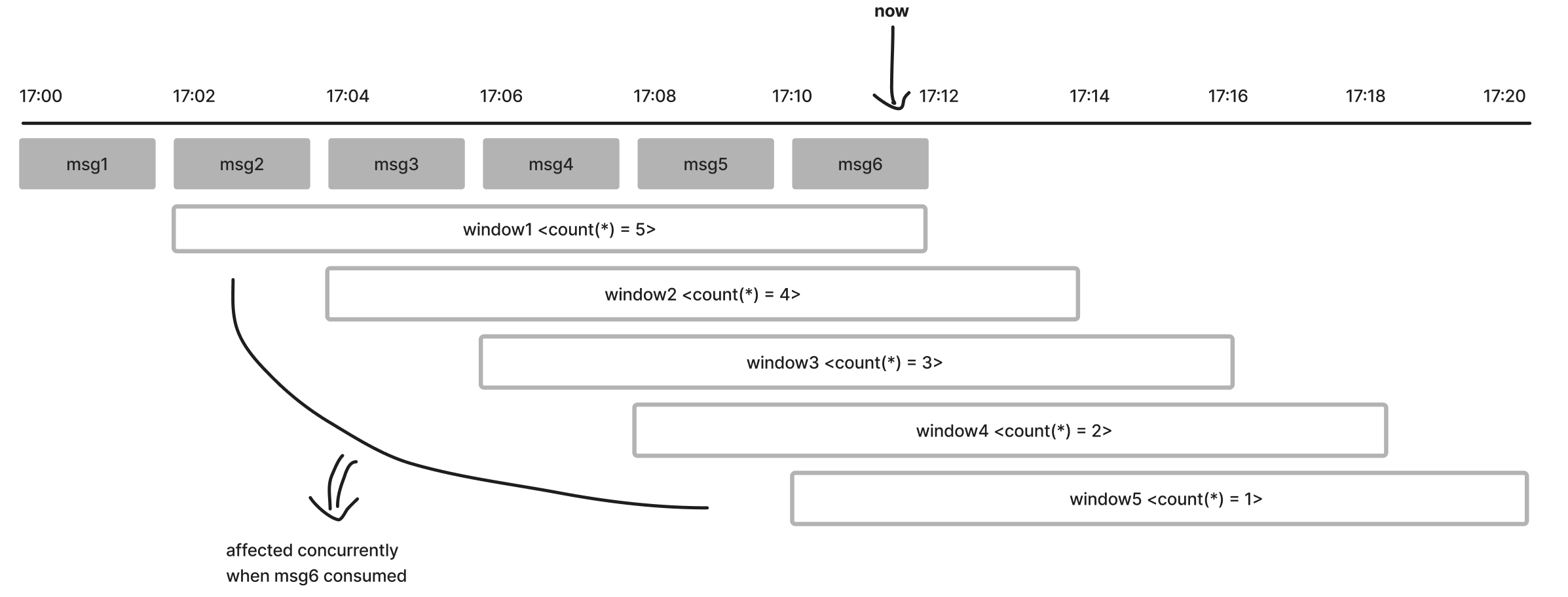
그림 5. ksqlDB의 Hopping Window
다시 우리의 목적을 생각해 봅시다. 우리는 “현재 시각 기준 최근 10분간의 메시지 개수”를 구하고 싶습니다. 위 그림처럼 현재 시간이 17:12이라면, 우리는 17:02 ~ 17:12 구간 동안 발행된 메시지의 개수인 5를 얻어내고 싶을 것입니다. 그림을 다시 보면 우리가 필요한 값과 가장 가까운 것은 window1의 count(*) 입니다. window2~5는 현재 시점으로부터 과거 10분이 아닌, 미래 시점까지 포함하는 윈도우 이기에 해당 윈도우에서 계산한 aggregation function(ex. count(*))의 값은 무시해야 하죠.
ksqlDB에서는 다행히도 EMIT FINAL 키워드를 통해 윈도우가 종료되었을 때만 출력 메시지를 보내도록 설정할 수 있습니다. 그렇다면 17:12가 되는 시점에 window1은 종료될 것이고, 그럼 이때 윈도우에 포함된 모든 메시지들에 대해 aggregation function이 실행되며, 최근 10분 (17:02 ~ 17:12) 동안의 메시지 수를 정상적으로 계산할 수 있게 됩니다. 비슷하게 2분이 지난 17:14 시점에선 window2가 emit 되며 17:04 ~ 17:14 구간의 메시지들을 계산해서 최근 10분 동안의 메시지 수를 출력할 수 있죠. 요약하자면 Hopping Window를 사용하면 우리가 의도한 대로 “최근 10분간의 COUNT”와 유사한 데이터를 얻을 수 있게 됩니다.
아래는 Hopping Window 와 EMIT FINAL을 사용한 예시로, 10분짜리 aggregation feature (COUNT, AVG)를 계산하고 있습니다.
CREATE STREAM feature_store_command3 WITH (...) AS
SELECT STRUCT(
`feature_name` := 'match-feature',
`method` := 'UPDATE',
`keys` := STRUCT(
`user_id` := userId
),
`values` := STRUCT(
`recent_10min_match_count` := COUNT(*),
`recent_10min_avg_chat_duration` := AVG(chat_duration),
`_last_updated_at_ms` := MAX(ROWTIME)
)
)
FROM azar_match_event
WINDOW HOPPING (SIZE 10 MINUTES, ADVANCE BY 1 MINUTES)
GROUP BY userId
EMIT FINAL;
위 예시처럼 SQL을 작성하면 피쳐의 업데이트 주기는 1분이 됩니다 (=hop interval). 다시 말해 메시지가 들어온다고 하더라도 피쳐 데이터가 바로 갱신되는 것이 아니라, 윈도우가 종료되는 매 1분마다 피쳐 데이터가 갱신된다는 것을 의미합니다. 만약 피쳐의 갱신 주기를 더 짧게 가져가려면 hop interval을 줄이면 되지만, 그만큼 윈도우의 숫자가 늘어나므로 ksqlDB의 부하가 증가하게 됩니다. 이처럼 ksqlDB에서 aggregation feature를 사용하려면 데이터의 갱신 주기와 ksqlDB의 부하 사이에서 적당한 값을 설정하는 것이 중요합니다. 너무 긴 시간의 윈도우를 잡으면서 (ex. 6시간 윈도우) hop interval은 짧게 가져가면 (ex. 1초), ksqlDB에 큰 부하를 줄 수 있습니다. 이런 경우에는 충분한 로드테스트와 함께 윈도우 기능을 먼저 테스트하기를 권장합니다.
어려운 예시들
위에서 설명한 예시 이외에 다른 시나리오에서도 사용하고 싶은 요구가 있을 수 있습니다. 하지만 ksqlDB 기능이 아직 미약하기도 하고, 안정성까지 고려했을 때 하이퍼커넥트에서는 아래 시나리오에 대해서는 아직까지 ksqlDB를 사용하고 있지 않습니다.
- Long windowing (ex. 최근 30일간 평균)
- 위에서 설명했듯 Hopping Window의 기간을 길게 가져가면서 hop interval은 짧게 가져가면 ksqlDB의 부하가 증가합니다.
- 더불어 카프카에 다운타임이 발생시 상태가 누락되어 데이터 정합성이 맞지 않을 가능성도 존재합니다.
- Lifetime accumulated (ex. 누적 로그인 수)
- ksqlDB에 materialized view가 있기는 하지만, 기본적으로 스트림 처리에 특화되었기에 누적 데이터를 처리하는 것은 적합하지 않습니다. (관련한 기능 제공도 X)
- Join (여러 event join)
- 가능하긴 하지만, 사용하기 까다롭고 여러 제약사항이 많습니다. (ex. Windowed stream은 join 불가)
- 트릭을 이용하여 사용할 수 있지만, ksqlDB에 부하를 줄 가능성이 높아서 아직까지 사용하고 않고 있습니다.
맺으며
추천 시스템을 비롯한 머신러닝 어플리케이션에서 실시간 피쳐 데이터는 중요하지만, 엔지니어링 비용이 상당히 발생합니다. 이런 경우에 카프카에서 제공하는 ksqlDB를 사용하면, 실시간 피쳐 데이터를 비교적 저렴하게 사용할 수 있습니다. 더불어 제품 도메인과 ML 도메인을 분리할 수 있기에 좋은 시스템 디자인을 가질 수 있게도 해줍니다. 카프카를 사용하는 조직에서 실시간 피쳐 데이터를 사용하는 데 어려움을 겪고 있다면, ksqlDB도 괜찮은 선택지가 될 수 있습니다.
References
[1] https://deview.kr/2023/sessions/536
[2] https://hyperconnect.github.io/2022/01/24/event-driven-recsys.html
[3] https://hyperconnect.github.io/2023/03/20/ksqldb-deepdive.html
[4] https://hyperconnect.github.io/2022/07/11/data-stores-for-ml-apps.html
[5] https://docs.hopsworks.ai/3.0/
[6] https://github.com/confluentinc/ksql/pull/3477
[7] https://docs.ksqldb.io/en/latest/concepts/time-and-windows-in-ksqldb-queries/
[8] https://docs.ksqldb.io/en/latest/developer-guide/ksqldb-reference/select-push-query/#final
Read more
-
고성능 ML 백엔드를 위한 10가지 Python 성능 최적화 팁
다량의 데이터를 사용하는 ML 워크로드에 특화된 최적화 기법들과, ML 백엔드에서 자주 사용되는 third-party 라이브러리를 효과적으로 사용하는 방법들을 실제 하이퍼커넥트의 사례와 함께 공유합니다. -
머신러닝 어플리케이션을 위한 데이터 저장소 기술
머신러닝 어플리케이션의 데이터 사용 패턴을 분석하고, 데이터 사용 패턴에 적합한 데이터 저장소엔 어떠한 것들이 있는지에 대해서 소개합니다. -
이벤트 기반의 라이브 스트리밍 추천 시스템 운용하기
마이크로서비스 아키텍처와 이벤트 주도 아키텍처로 구현된 라이브 스트리밍 추천 시스템을 소개합니다.