고성능 ML 백엔드를 위한 10가지 Python 성능 최적화 팁
Python은 배우기 쉽고, ML 관련 라이브러리를 포함한 오픈소스 생태계가 상당히 발전해있는 좋은 언어입니다. 편의성이 좋다 보니 여러 회사들이 데이터 분석과 ML 모델 학습뿐만 아니라, 백엔드 서버에서도 Python을 자주 사용합니다. (대표적으로 Instagram도 백엔드 서버로 Python을 사용합니다 [0-1]). 하이퍼커넥트의 많은 ML 백엔드 서버들도 Python으로 작성되고 있는데요, 하지만 Python은 실행 속도가 느리다는 치명적인 단점이 있습니다. Python은 분명 ML 도메인에서 사용하기 좋은 언어이긴 하지만, 응답시간이 중요한 로직에서도 Python 백엔드 서버를 운영하면서 Python의 느린 속도 때문에 많은 고통을 겪어 왔습니다.
Python의 속도가 문제가 되어도, 이미 작성된 로직들을 C++, Go, Rust, Kotlin과 같은 더 빠른 언어로 포팅하기는 쉽지 않습니다. 기본적으로 전체 비즈니스 로직을 새로운 언어로 다시 작성하는 것은 시간이 매우 많이 들며, 또 Numpy나 PyTorch와 같은 라이브러리의 이점을 포기하기도 쉽지 않기 때문이죠. 하이퍼커넥트도 Python에서 다른 언어로 포팅하기 어려운 상황들을 많이 겪어왔고, 그때마다 Python 자체를 최대한 빠르게 사용하기 위한 다양한 트릭들을 발견하며 성능 요구사항을 맞춰왔습니다.
이번 포스트에서는 하이퍼커넥트가 Python으로 작성된 다양한 ML 백엔드 서버들을 운영하며 발견한 성능 최적화 기법 10가지를 공유해 보려 합니다. 특히 다량의 데이터를 사용하는 ML 워크로드에 특화된 최적화 기법들을 다루며, ML 백엔드에서 자주 사용되는 third-party 라이브러리를 효과적으로 사용하는 방법도 같이 공유합니다. Pypy, Numba, C binding 처럼 팀의 반발을 살 수 있으며(?), 유지보수성 난이도가 높아져서 적용이 어려운 방법들은 이번 포스트에선 다루지 않습니다. 단 몇 줄의 코드 수정만으로 서버의 응답시간(latency)을 절반 이상 낮출 수 있는 팁들도 있으니, 재미있게 읽어주세요.
Note: Python을 사용한다면 일반적으로 CPython implementation [0-2]을 사용할 것이기 때문에, 글의 내용도 모두 CPython implementation을 사용하는 것을 가정하고 작성했습니다.
Table of Contents
- 상황에 따라 gc가 병목일 수 있다. 이런 경우 gc 발동 조건을 튜닝할 수 있다.
- Built-in list는 충분히 빠르지 않다. 필요시 array나 numpy를 사용하자.
- multiprocess는 커뮤니케이션 오버헤드가 높기에, low-latency 시나리오에서 조심히 사용해야한다.
- Pytorch를 multiprocess 환경에서 쓴다면 num_threads를 조정하자.
- Pydantic은 아주 느리다. 불필요한 곳에서 가급적 사용하지 말자.
- Pandas DataFrame은 생성에 많은 시간이 걸리므로, 유의해서 사용해야 한다.
- 바닐라 json 패키지는 느리다. orjson이나 ujson을 사용하자.
- Class는 충분히 빠르지 않을 수 있다. 너무 문제가 되면 dict를 사용하자.
- Python 3.11은 덜 느리다.
- (보너스) line profiler 사용법
#1 상황에 따라 gc가 병목일 수 있다. 이런 경우 gc 발동 조건을 튜닝할 수 있다.
일반적인 Python 백엔드 서버에서는 한 요청당 객체를 수 백 개씩 만드는 경우가 드뭅니다. 때문에 garbage collector에 의해 latency가 크게 발생하는 경우도 흔치 않습니다. 하지만 대규모 데이터를 다루는 ML 백엔드의 경우에는 다릅니다. 대표적으로 추천 API 서버에서는 요청이 들어올 때마다 수천~수만 개의 객체를 생성하고 처리해야 합니다. 이런 상황에는 garbage collection(GC)가 문제를 발생시킬 수도 있습니다. 하이퍼커넥트에서 운영 중인 추천 API 서버들도 GC로 인해 실행 속도가 늦어지는 현상이 자주 발견되었고, 코드 몇 줄의 수정을 통해 GC 설정을 조금만 튜닝하자 P99 Latency가 1/3 수준으로 낮아지는 경험을 하기도 했습니다.
그렇다면 GC는 왜, 그리고 어떻게 문제를 일으킬까요? 이를 설명하기 위해 간단하게 Python garbage collection의 동작에 대해 먼저 설명하겠습니다.
Python GC
Python에서 수명이 다한 객체는 기본적으로 reference counting을 통해 메모리가 회수됩니다. 모든 객체마다 자신이 참조되고 있는 개수(reference count)를 들고 있다가, 이 숫자가 0이 되면 메모리에서 삭제하는 방식이죠 [1-1, 1-2]. 하지만 reference counting 만으로는 메모리 관리에 한계가 있습니다. 바로 reference cycle이 있는 객체들에 대해서는 영원히 메모리를 회수할 수 없기 때문입니다. (ex. 순환 참조가 있는 linked list 객체) Reference counting 만으로는 reference cycle이 있는 객체들을 제거할 수 없으므로, Python에서는 cyclic garbage collection이라고 하는 작업을 추가로 수행하며, 이를 편히 garbage collection(GC)라고도 부릅니다. (참고로 JVM 계열 언어에서는 reference counting 방식의 GC가 아닌, tracing garbage collection [1-3] 이라는 방법을 사용합니다.)
Reference counting을 통한 메모리 회수는 보통 매우 빠르게 이루어집니다. 성능 문제는 보통 cyclic garbage collection 단계에서 발생합니다. 생각해봅시다. Garbage 객체를 제거하기 위해서는 먼저 garbage에 해당하는 객체를 찾는 작업이 선행되어야 합니다. 그럼 어떻게 Garbage 객체를 찾을까요? “모든” 객체에 대해서 reference를 graph를 그리며, 접근 불가능한 cycle을 찾는 방법 밖에 없습니다. 현재 메모리에 있는 모든 객체에 대해서 전수 조사를 해야하기에 느려질 수 밖에 없는 것이죠.
Python에서는 느린 GC 속도에 대응하기 위해 “Generation” 이라는 최적화 기법을 사용합니다. 이는 JVM에서의 weak generational hypothesis (young gc / old gc) 개념 [1-4]과 거의 일치합니다. 대부분의 객체는 짧은 수명을 가지며 생성 이후 빠른 시간안에 메모리에서 해제되어야 할 것들이고, 수명이 오래된 객체는 대부분 전역 변수처럼 존재하여 메모리에서 해제될 필요가 없는 객체라는 가설이죠. 실제로 위 가설을 바탕으로, GC를 수행할 때마다 항상 모든 객체에 대해 scan하는 대신, 특정 generation에 해당하는 객체들에 대해서만 scan을 수행합니다. Young generation 객체는 자주, Old generation 객체는 상대적으로 가끔씩 scan을 수행하는 것이죠.
Python Generation GC
그렇다면 Python에서 generation은 어떻게 관리되고 있으며, 또 generation마다 GC는 어떤 주기로 실행되고 있을까요?
Python에서 객체는 generation 0, generation 1, generation 2 중 하나에 포함됩니다. 기준은 해당 객체가 cyclic garbage collector로 부터 생존한 횟수입니다. 한 번도 GC 가 불리지 않은 객체는 gen0, 한 번 불렸지만 생존한 객체는 gen1, 두 번 이상 GC가 불렸지만 생존한 객체는 gen2에 속하게 됩니다. Python에서 각 generation마다 GC가 호출되는 빈도 수도 따로 조절됩니다. 이는 Python의 내장 함수인 gc.get_threshold() 을 통해 확인할 수 있습니다.
>>> import gc
>>> gc.get_threshold()
(700, 10, 10)
위 threshold만 보면 다소 헷갈릴 수 있는데요, 사실 threshold0 이 의미하는 바와 threshold1, threshold2 가 의미하는 바가 살짝 다릅니다. threshold0 의 값은 “(number of allocations) - (number of deallocations)이 threshold를 넘으면 gen0 GC가 호출된다”를 의미합니다. 기본 값은 700이니, “객체 생성 수 - 객체 해제 수” 가 700을 넘으면 gen0 GC가 호출된다고 보면 됩니다.
threshold1 는 gen1에 대한 기준인데, 이는 “gen0 GC가 몇 번 호출되면 gen1 GC를 호출할 것인지”를 의미합니다. 기본 값으로 gen0 GC가 10번 호출되면 gen1 GC가 한 번 수행됩니다. 비슷하게 threshold2 는 “gen1 GC가 몇 번 호출되면 gen2 GC를 호출할 것인지”를 의미합니다. 다만 gen2 GC의 경우에는 여기에 더해 추가로 long_lived_pending / long_lived_total 이 25%를 넘을 경우에만 수행된다는 조건도 만족했을 때만 수행됩니다. Gen 2 GC에만 특별한 조건이 붙어있는 이유는 Gen 2 GC를 수행하는데 매우 오랜 시간이 소요되기 때문입니다 [1-5].
GC 오버헤드
대규모 데이터를 다루는 ML 백엔드 서버에서는 하나의 요청에서 많은 객체가 생성될 수 있고, 이런 시나리오에선 더 자주 Cyclic GC가 발동될 수 있습니다.
간단한 예시를 하나 살펴봅시다. Dummy 객체들을 다수 생성하고, 평균 생성 시간 및 최대 생성 시간을 출력하는 예시입니다. 메모리에 존재하는 객체를 더 많이 늘려주고자 Pytorch 및 Numpy 라이브러리도 사용하지는 않지만 import 해두었습니다.
import time
import numpy as np
import torch
class DummyClass:
def __init__(self):
self.foo = [[] for _ in range(4)]
def generate_objects() -> None:
bar = [DummyClass() for _ in range(1000)]
times = []
for _ in range(500):
start_time = time.time()
generate_objects()
times.append(time.time() - start_time)
avg_elapsed_time = sum(times) / len(times) * 1000
max_elapsed_time = max(times) * 1000
print(f"avg time: {avg_elapsed_time:.2f}ms, max time: {max_elapsed_time:.2f}ms")
그 결과는 아래와 같습니다.
avg time: 2.08ms, max time: 22.45ms
평균 케이스와 최악의 케이스가 차이가 많이 나는 것은 확인했습니다. 다만 아직 위 코드가 GC의 영향을 받는지는 확실하지 않습니다. 그렇다면 GC를 끈 상태에서 코드를 다시 실행해봅시다. Python에서는 gc.disable() 함수를 호출하는 것 만으로 Cyclic GC를 비활성화 할 수 있습니다.
import gc
...
gc.disable()
...
avg time: 0.73ms, max time: 0.88ms
위 결과를 보면 실행 속도에 큰 차이가 있음을 확인할 수 있습니다. 최악의 케이스(max time)의 경우 GC 여부에 따라 속도가 25배나 차이가 발생합니다. 이 현상이 프로덕션 API 서버에도 발생한다면 간헐적으로 긴 지연이 발생하므로 P99 Latency에 유의미한 영향을 줄 수 있습니다.
Generation GC별 오버헤드도 알아볼 수 있을까요? gc.disable() 대신 gc.set_threshold(700, 0, 99999999) 를 사용하면 gen0, gen1 GC는 그대로 수행하고, gen2 GC만 (사실상) 불리지 않도록 설정할 수 있습니다. Gen2 GC만 비활성화한 경우엔 avg time: 0.91ms, max time: 1.15ms의 결과가 나왔으며, GC를 완전히 끈 것보다 오래걸리긴 하지만, GC를 전혀 튜닝하지 않은 케이스와 비교시 매우 빨라짐을 확인할 수 있습니다.
또 다른 실험으로, 위 예시에서 Pytorch 및 Numpy를 import하지 않는다면, GC를 비활성화 하지 않아도 속도가 매우 빨라짐을 확인할 수 있습니다. (Gen2 GC를 비활성화 한 경우와 비슷한 속도). 이를 해석하면 Pytorch 및 Numpy가 상당한 양의 객체를 생성하고, 이들이 해제되지 않은 상태로 메모리에 상주하여 Old generation 객체 가 되어있는데, Gen2 GC가 불릴 때마다 Pytorch 및 Numpy에서 생성한 객체까지 scan을 하느라 매우 많은 시간이 걸렸다고 볼 수 있는 것이죠.
하이퍼커넥트의 사례
다수의 객체를 생성하는 ML 백엔드 어플리케이션에선 GC를 튜닝하는 방법이 때론 응답시간을 최적화할 수 있는 매우 효과적인 방법일 수 있습니다. 특히나 ML 백엔드에선 Pytorch나 Numpy와 같은 무거운 라이브러리들을 사용할 가능성이 높기 때문에 더더욱 GC 오버헤드가 클 수 있습니다. GC를 건드리는게 두렵다고요? 위와는 다른 이유기는 하지만 Instagram에서도 Python Django 서버에서 GC를 비활성화 하면서 운영하기도 했습니다 [1-6]. 생각만큼 비현실적인 방법은 아닙니다.
물론 GC를 완전히 비활성화 하는 방법은 공격적일 수 있습니다. GC를 완전히 비활성화 하는 대신, 조금 덜 공격적인 방법으로 GC를 튜닝한다면 메모리가 무한히 증가하는 상황을 막으면서도 응답시간을 크게 개선할 수 있습니다. 하이퍼커넥트에서 사용하고 있는 방법으로는 아래와 같습니다.
- Gen2 GC의 threshold를 높혀서 실행 빈도를 낮게 설정
- 어플리케이션 start-up 이후
gc.freeze()를 한 번 호출하여, 라이브러리에서 생성한 Old generation 객체들에 대해서는 Gen2 GC에서 scan하지 않도록 변경 - 지속적으로 요청이 들어오는 패턴이 아닌 주기적(ex. 100ms마다)으로 요청이 들어오는 어플리케이션에선, GC 호출 시점과 API 요청 시점이 겹치지 않도록 설정 (수동으로 GC 트리거 시점 조정)
하이퍼커넥트에선 GC 튜닝을 통해 P99 Latency를 최대 1/3 수준까지 줄이기도 했습니다. Python garbage collection에 대한 상세한 설명은 공식 dev 문서와 공식 코드에서 찾아볼 수 있습니다.
#2 Built-in list는 충분히 빠르지 않다. 필요시 array나 numpy를 사용하자.
Python의 built-in list는 매우 편리하지만, 속도가 결코 빠르지는 않습니다. 이럴 때 python의 built-in array나 numpy의 ndarray를 사용하면 도움이 될 수도 있습니다. “또 numpy야? 진부하다!” 라고 생각하실지 모르겠습니다. 하지만 numpy를 쓴다고 해서 항상 빠른 것은 아니며, 잘못 사용할 경우 오히려 성능을 더 악화시킬 수도 있습니다. 본 섹션에서는 어떤 상황에서 array나 numpy를 쓰는 것이 적절한지 다뤄보고자 합니다.
Python에서의 list, array 구현 차이
이를 이해하기 위해서 먼저 CPython에서의 list의 구현을 살펴보겠습니다.
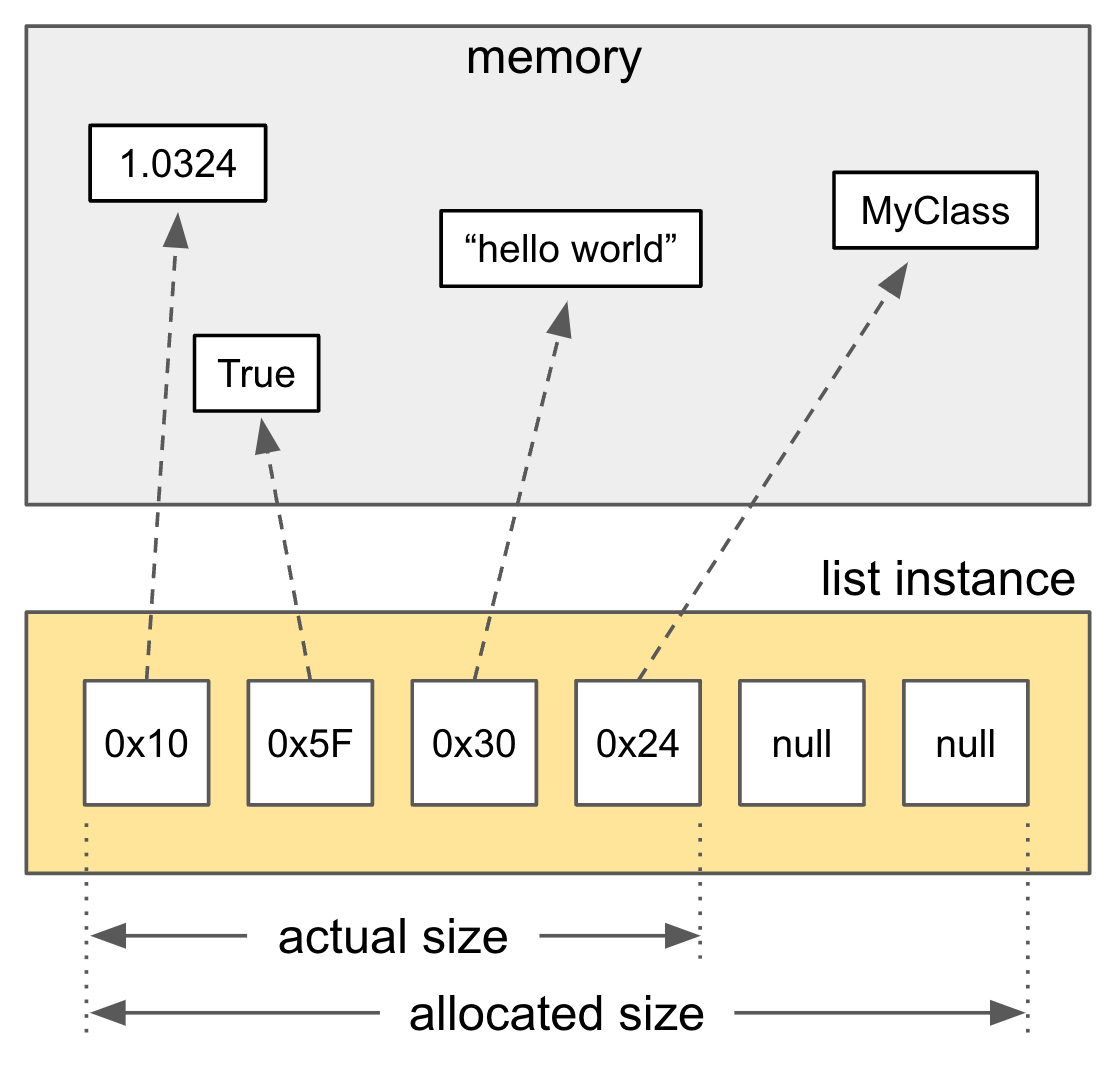
/* Python built-in list */
typedef struct {
PyObject_VAR_HEAD
/* Vector of pointers to list elements. list[0] is ob_item[0], etc. */
PyObject **ob_item;
Py_ssize_t allocated;
} PyListObject;
위 그림 및 코드처럼 list는 포인터들의 배열, 즉 더블 포인터로 구성되어 있습니다. 이는 리스트 내에서는 인접한 요소들이더라도 실제 메모리 상에서는 요소들이 제각기 다른 주소에 흩어져있을 수 있다는 뜻입니다. 따라서 cache locality가 떨어지고 cache miss가 더 자주 발생해 성능이 하락할 수 있습니다.
반면 Python의 built-in array [2-1] 나 numpy의 ndarray는 c의 array처럼 연속된 메모리 공간에 값을 할당합니다. 아래는 built-in array 객체의 구현입니다.
/* Python built-in array */
typedef struct arrayobject {
PyObject_VAR_HEAD
char *ob_item;
Py_ssize_t allocated;
const struct arraydescr *ob_descr;
PyObject *weakreflist; /* List of weak references */
Py_ssize_t ob_exports; /* Number of exported buffers */
} arrayobject;
List와 동일하게 ob_item 이라는 필드를 가지고 있지만, list의 경우 타입이 PyObject 인 반면, array의 경우 타입이 char* 인 것을 눈치채셨나요? 이처럼 built-in array는 어떤 객체에 대한 레퍼런스를 들고 있는 것이 아니라, 값 자체를 들고 있기 때문에 locality가 보장됩니다. 대신 int, byte, float 등 primitive한 값만 저장할 수 있다는 제약이 존재합니다.
Numpy의 ndarray가 C로 구현되어 있는 것은 워낙 유명합니다. ndarray 또한 built-in array와 비슷하게 연속된 메모리 공간에 값을 할당하기에, 매우 빠른 속도로 메모리 접근이 가능합니다. 다만 ndarray에서 dtype=’O’로 설정하여 객체를 저장하게 된다면, 객체에 대한 reference를 저장하기 때문에 built-in list와 동일한 방식으로 작동합니다 [2-2].
이러한 차이 때문에 list와 array, ndarray는 상황에 따라 상이한 성능을 보입니다. 여기서는 두 가지 상황에 대해 이들의 성능을 비교해보겠습니다.
list, array, numpy ndarray의 접근 성능 비교
얼핏 보면 list의 경우 인덱스 상으로는 인접한 요소들이더라도 실제 메모리에서는 제각기 다른 주소에 흩어져있기 때문에 cache locality가 떨어지고 cache miss가 더 자주 발생해 성능이 하락할 것이라고 추론할 수 있습니다. 그런데 진짜로 그럴까요? 아래 벤치마크를 통해 확인해보겠습니다.
import timeit
import array
import numpy as np
# Parameters for testing
N = 10000 # number of rows and columns in the array
M = 1000 # number of iterations
# Initialize the arrays
my_list = [i for i in range(N)]
my_array = array.array('i', my_list)
my_ndarray = np.array(my_list)
def test_list_sum():
sum(my_list)
def test_array_sum():
sum(my_array)
def test_numpy_sum():
sum(my_ndarray)
def test_numpy_npsum():
np.sum(my_ndarray)
# Perform the benchmarks
list_time = timeit.timeit(test_list_sum, number=M)
array_time = timeit.timeit(test_array_sum, number=M)
ndarray_sum_time = timeit.timeit(test_numpy_sum, number=M)
ndarray_npsum_time = timeit.timeit(test_numpy_npsum, number=M)
# Output the results
print(f'list: {list_time * 1000:.1f} ms')
print(f'array: {array_time * 1000:.1f} ms')
print(f'ndarray (sum): {ndarray_sum_time * 1000:.1f} ms')
print(f'ndarray (np.sum): {ndarray_npsum_time * 1000:.1f} ms')
list: 72.0 ms
array: 126.4 ms
ndarray (sum): 373.0 ms
ndarray (np.sum): 2.5 ms
결과를 보면 ndarray의 경우 np.sum()을 썼을 때는 압도적으로 빠른 성능을 보여주지만 그냥 sum을 했을 때는 list가 array나 ndarray보다 오히려 빠릅니다. 왜 그럴까요?
위의 코드는 모든 요소들을 한 번씩 읽고 더하는 연산을 수행합니다. Built-in list의 경우 test_list_sum() 함수를 실행할 때 memory read → arithmetic operation (+) 이 순차적으로 일어납니다.
그런데 array나 ndarray는 다릅니다. 이들은 python 객체가 아닌 primitive 값을 저장하기 때문에, python 로직(i.e. sum 함수)에서 값에 접근하기 위해서는 먼저 primitive value를 python 객체로 변환해야 합니다. 따라서 test_array_sum() 이나 test_numpy_sum() 함수를 실행할 때는 다음과 같은 연산이 수행됩니다.
memory read → conversion (int -> Python object) → arithmetic operation (+)
이 변환의 오버헤드로 인해 list보다 더 나쁜 성능을 보이는 것으로 보입니다.
그렇다면 np.sum()은 왜 빠른걸까요? 이 함수는 C로 구현되어 있어 요소를 Python 객체로 변환할 필요 없이 primitive 값에 대해 그대로 연산을 수행합니다. 이 경우 모든 값을 C 로직에서 더한 뒤, 최종 결과를 Python 객체로 한 번만 변환하면 되므로 conversion overhead가 거의 없습니다. 또한 C의 for loop이 python의 for loop보다 훨씬 오버헤드가 적고, 일부 연산의 경우 OpenMP와 같은 병렬처리 기술을 활용할 수도 있어 월등히 빠른 것이죠.
즉, numpy를 통해 성능 향상을 극대화하기 위해서는 indexing을 통해 하나씩 접근하는 것이 아니라, numpy에서 제공하는 별도의 operator를 사용하는 것이 중요합니다. 만약 numpy에서 제공하지 않는 자체 함수를 사용해야 하는 경우, apply_along_axis() [2-3] 와 같은 함수를 사용하면 그냥 for loop을 돌리는 것보다는 우수한 성능을 보일 때도 있습니다. 하지만 이 또한 pure-python 레벨에서 로직을 수행하는 것이므로 성능 향상을 최대로 가져가려면 최대한 vectorize된 operator를 활용하는 것이 좋겠죠.
list, array, numpy ndarray의 직렬화 성능 비교
또 다른 경우는 배열을 직렬화(serialization) 하는 상황입니다. 예를 들어 배열에 담긴 값을 DB에 저장하거나 페이로드에 담아 보낼때 binary 데이터로 변환이 필요할 수 있습니다. 이때 array나 ndarray의 경우 이미 연속적인 메모리 공간에 binary 형태로 값이 저장되어 있기 때문에 값을 단순히 읽거나 copy해주면 되지만, list의 경우 메모리 공간 곳곳에 흩어져있는 각각의 값을 읽은 다음 이를 binary로 변환까지 거쳐야 하기 때문에 훨씬 느립니다.
Python에서 널리 사용되는 직렬화/역직렬화 패키지 중 하나인 marshal을 이용해 marshal(직렬화), unmarshal(역직렬화) 성능을 비교해보겠습니다.
import timeit
import array
import numpy as np
import pickle
import marshal
import random
N = 10000 # number of elements in the array
M = 1000 # number of iterations
# Initialize the arrays
my_list = [random.random() for _ in range(N)]
my_list_enc = marshal.dumps(my_list)
my_array = array.array('f', my_list)
my_array_enc = marshal.dumps(my_array)
my_ndarray = np.array(my_list, dtype=np.float32)
my_ndarray_enc = marshal.dumps(my_ndarray)
def test_list_marshal():
marshal.dumps(my_list)
def test_list_unmarshal():
marshal.loads(my_list_enc)
def test_array_marshal():
marshal.dumps(my_array)
def test_array_unmarshal():
marshal.loads(my_array_enc)
def test_ndarray_marshal():
marshal.dumps(my_ndarray)
def test_ndarray_unmarshal():
marshal.loads(my_ndarray_enc)
# Perform the benchmarks
list_marshal_time = timeit.timeit(test_list_marshal, number=M)
array_marshal_time = timeit.timeit(test_array_marshal, number=M)
ndarray_marshal_time = timeit.timeit(test_ndarray_marshal, number=M)
list_unmarshal_time = timeit.timeit(test_list_unmarshal, number=M)
array_unmarshal_time = timeit.timeit(test_array_unmarshal, number=M)
ndarray_unmarshal_time = timeit.timeit(test_ndarray_unmarshal, number=M)
...
[marshal]
list: 131.2 ms
array: 0.8 ms
ndarray: 1.9 ms
[unmarshal]
list: 155.4 ms
array: 0.9 ms
ndarray: 0.9 ms
marshal과 unmarshal 결과를 보면 list와 array, ndarray 사이에 상당한 속도 차이가 있습니다. 특히 list의 경우 다른 두 방식과 직렬화/역직렬화 시간이 무려 80~160배나 차이가 납니다. (다른 직렬화 패키지인 pickle을 사용하더라도 비슷한 결과를 관찰할 수 있습니다) 이는 list의 경우 메모리공간 여기 저기에 흩어져 있는 데이터들을 취합해야 할 뿐만 아니라, 각각의 요소에 대해 data type을 확인한 뒤에 바이너리로 변환해야 해서 추가적인 overhead가 발생하기 때문으로 보입니다.
이처럼 list와 array, ndarray는 얼핏 비슷해 보이지만 자료를 저장하는 방식때문에 성능 면에서는 큰 차이를 보입니다. 만약 직렬화 오버헤드가 큰 상황이라면 array나 ndarray를 사용해서 실행 속도를 최적화하는 것도 고려해볼만 합니다.
하이퍼커넥트의 사례
하이퍼커넥트에서 운영하고 있는 추천 서버에서는 임베딩처럼 다수의 float로 이루어진 벡터를 다루는 연산을 많이 수행합니다. 이들 연산의 대부분은 numpy의 vector operator나 fancy indexing을 최대한 활용하고 있습니다. 따라서 복잡한 로직임에도 불구하고 많은 요청량을 감당해내도록 구현하고 있습니다.
이 외에도 위에서 언급한 serialization 상황에서의 성능 개선을 실제로 경험한 사례도 있습니다. 추천 서버의 특성상 데이터베이스에 벡터를 읽고 쓰는 로직이 많은데요, 벡터를 데이터베이스에서 읽을 때 marshal과 같은 빠른 바이너리 인코더를 이용하여 역직렬화를 수행했음에도 불구하고, list 객체의 역직렬화 오버헤드가 상당히 높았습니다. 이를 numpy ndarray 기반의 로직으로 바꾼 결과 역직렬화 시간이 5분의 1로 줄어들었고, 서비스의 end-to-end latency도 크게 개선되었습니다.
다만 위에서도 언급했듯 단순히 numpy나 array를 사용한다고 해서 항상 속도가 빨라지는 것은 아니므로, 어떤 연산을 수행하는지 파악하고, 해당 상황에서 실제로 속도 향상이 있는지 간단한 실험을 통해 미리 테스트해보고 적용하는 것이 좋겠습니다.
#3 multiprocess는 커뮤니케이션 오버헤드가 높기에, low-latency 시나리오에서 조심히 사용해야한다.
기본적으로 CPU 연산에 많은 시간이 걸린다면 병렬성(parallelism)을 통해서 작업 속도를 빠르게 할 수 있습니다. Multi-threading이나 multi-processing이 대표적인 방법이죠. 하지만 잘 알려져있다시피 Python에서 multi-threading은 Global Interpreter Lock (GIL) [3-1] 때문에 성능을 거의 개선해주지 못합니다.
아쉬움을 달래고자 Python 커뮤니티에서는 multi-threading 대신 multi-processing을 사용하여 병렬 처리를 수행하도록 권장합니다. 그렇다면 정말 multi-processing을 쓰는 것이 답일까요? 사실 항상 그렇지만은 않습니다. Python multi-processing에서는 아래와 같은 두가지 문제가 존재하며, 상황에 따라 이 문제가 발생하지 않을 환경에서만 multi-processing을 사용하는 것이 낫습니다.
- 미리 Process pool을 만들어두지 않고, 매번 Process를 생성(spawning)하게 되면 오버헤드가 매우 높아집니다.
- 미리 Process pool을 만들어놔도, 프로세스간에 주고받는 데이터가 크다면 커뮤니케이션 오버헤드가 높아집니다.
Process 생성(spawn)에 대한 오버헤드
먼저 1번의 경우부터 예시와 함께 보겠습니다. 아래 코드는 fibonacci(25)를 총 4번 수행하는 API입니다. /multiprocess 를 호출하면 4개의 multiprocessing pool을 사용하여 병렬로 계산하고, /singleprocess 를 호출하면 하나의 스레드로 순차적으로 함수를 네 번 호출합니다.
import multiprocessing
import time
from fastapi import FastAPI
app = FastAPI()
def fibonacci(n: int) -> int:
return n if n <= 1 else fibonacci(n-1) + fibonacci(n-2)
@app.get("/multiprocess")
async def multiprocess_run() -> float:
start_time = time.time()
with multiprocessing.Pool(4) as pool:
pool.map(fibonacci, [25, 25, 25, 25])
elapsed_time = time.time() - start_time
print(f"multiprocess elapsed time: {elapsed_time * 1000:.1f}ms")
return elapsed_time
@app.get("/singleprocess")
async def singleprocess_run() -> float:
start_time = time.time()
for _ in range(4):
fibonacci(25)
elapsed_time = time.time() - start_time
print(f"singleprocess elapsed time: {elapsed_time * 1000:.1f}ms")
return elapsed_time
각각의 API endpoint를 호출하면 그 결과는 어떨까요? 무려 multiprocess를 사용한 경우가 2배 이상 느립니다. (MacOS에서의 결과)
multiprocess elapsed time: 304.2ms
singleprocess elapsed time: 129.2ms
위 예시에서 multiprocess가 singleprocess보다 느린 이유는 Process를 생성(spawning)하는데서 발생하는 오버헤드입니다. 참고로 python multiprocess를 생성하는 방법으로는 spawn과 fork가 있습니다 [3-2]. Spawn은 Python 인터프리터를 처음부터 생성하고, 라이브러리도 처음부터 import 하는 방식으로 구현됩니다. 따라서 생성 속도가 아주 느릴 수 밖에 없죠. 이에 반해 fork 방식은 os에서 제공하는 fork sysyem call을 사용합니다. Spawn보다 fork가 더 오버헤드가 적지만, fork는 thread를 사용하는 상황에서 안전하게 메모리를 복사할 수 없어서 문제를 일으킬 수 있습니다 [3-2, 3-3]. 우리가 직접 thread를 사용하지 않아도 3rd-party 라이브러리에서 thread를 사용하는 경우는 흔하기 때문에, fork 사용시 신중하게 코드를 작성해야 합니다. MacOS와 Windows에서 기본 값은 spawn, Unix에서 기본 값은 fork 방식으로 설정되어 있고, 이는 사용자가 바꿀 수 있습니다.
Spawn은 느린 것이 문제고, fork 방식은 안전하지 않은 것이 문제라면 둘 다 사용하지 말아야 한다는 것일까요? 사실 가장 좋은 방법은 HTTP 요청이 올 때마다 매번 spawn이나 fork를 통해 프로세스를 생성하는 대신, 어플리케이션 startup시에 미리 process pool을 만들어 전역변수로 할당해두고, HTTP 요청이 올 때마다 미리 만들어진 process pool을 사용하는 것입니다.
위의 예시 코드에 아래와 같이 startup_event_handler 를 만들고, 미리 정의된 process pool를 사용하도록 수정한 예시입니다.
async def startup_event_handler():
app.state.process_pool = multiprocessing.Pool(4)
app.add_event_handler("startup", startup_event_handler)
@app.get("/multiprocess")
async def multiprocess_run() -> float:
start_time = time.time()
app.state.process_pool.map(fibonacci, [25, 25, 25, 25])
elapsed_time = time.time() - start_time
print(f"multiprocess elapsed time: {elapsed_time * 1000:.1f}ms")
return elapsed_time
위처럼 바꾼 코드에서의 /multiprocess endpoint 실행 속도는 아래와 같습니다. 130ms가 걸렸던 single process 방식에 비해 훨씬 빨라진 것을 확인할 수 있습니다.
multiprocess elapsed time: 49.9ms
Process간 데이터 전송에 대한 오버헤드
그럼 이제 모든 문제가 해결되었을까요? 그렇다면 이 섹션이 등장하지 않았을 것입니다. 미리 Process pool을 만들어놔도, 프로세스간에 주고받는 데이터가 크다면 커뮤니케이션 오버헤드가 높아질 수 있습니다. 섹션 초반에서 설명했던 두 번째 문제입니다.
Python에선 process간에 통신시 pickle을 통해서 데이터를 직렬화합니다 [3-4]. 만약 process간에 주고받는 데이터의 크기가 크다면, pickle을 통해서 데이터를 직렬화하고 다시 받는 쪽에서 역직렬화 하는 오버헤드가, 병렬성으로 부터 개선되는 성능 향상 폭보다 더 커질 수 있습니다.
예시를 하나 살펴 봅시다. 아래는 길이가 512인 벡터 100개를 element-wise sum 하는 예시입니다. /multiprocess 를 호출하면 4개의 multiprocessing pool을 사용하여 데이터를 1/4씩 쪼개서 병렬로 계산하고, /singleprocess 를 호출하면 하나의 스레드로 모든 데이터에 대해 element-wise sum을 수행합니다. multiprocess에서는 process spawn 오버헤드를 줄이기 위해 미리 process pool을 만드는 방식을 적용하였습니다.
import multiprocessing
import random
import time
from typing import List
from fastapi import FastAPI
async def startup_event_handler():
app.state.process_pool = multiprocessing.Pool(4)
app = FastAPI()
app.add_event_handler("startup", startup_event_handler)
def generate_random_vector(size: int) -> List[float]:
return [random.random() for _ in range(size)]
def element_wise_sum(vectors: List[List[float]]) -> List[float]:
ret_vector = [0.0] * len(vectors[0])
for vector in vectors:
for i in range(len(vector)):
ret_vector[i] += vector[i]
return ret_vector
@app.get("/multiprocess")
async def multiprocess() -> List[float]:
vectors = [generate_random_vector(512) for _ in range(100)]
start_time = time.time()
result_vector_list = app.state.process_pool.map(element_wise_sum, [
vectors[:25], vectors[25:50], vectors[50:75], vectors[75:],
])
ret_vector = element_wise_sum(result_vector_list)
elapsed_time = time.time() - start_time
print(f"multiprocess elapsed time: {elapsed_time * 1000:.1f}ms")
return ret_vector
@app.get("/singleprocess")
async def singleprocess_run() -> List[float]:
vectors = [generate_random_vector(512) for _ in range(100)]
start_time = time.time()
ret_vector = element_wise_sum(vectors)
elapsed_time = time.time() - start_time
print(f"singleprocess elapsed time: {elapsed_time * 1000:.1f}ms")
return ret_vector
Process spawn으로 인한 오버헤드가 제거되었음에도 불구하고, 위 코드를 실행해보면 아래처럼 multiprocess가 더 느린 것을 확인할 수 있습니다. 이는 vectors 변수 자체의 크기가 매우 크기 때문에, 이를 다른 프로세스로 보내기 위한 커뮤니케이션 오버헤드가 매우 커서 발생하는 문제입니다.
multiprocess elapsed time: 12.0ms
singleprocess elapsed time: 10.4ms
하이퍼커넥트의 사례
어쩌면 위와 같은 예시가 일반적이지 않다고 생각할 수 있습니다. 하지만 대규모 데이터를 다루는 ML 백엔드에서 크기가 큰 벡터를 연산하는 것은 꽤나 빈번히 발생하는 일입니다. 하이퍼커넥트 ML 조직에서도 커뮤니케이션 오버헤드로 인해 multiprocessing을 사용해도 오히려 속도가 느려지는 경험을 했습니다 (latency 5% 이상 저하).
이처럼 Python multiprocessing는 커뮤니케이션 오버헤드가 크기 때문에, 도입하기 전에 어플리케이션 사용 패턴을 충분히 파악한 후 도입해야 합니다. 하이퍼커넥트에서도 병렬성으로 해결 가능한 로직이 보인다고 하더라도, 미리 패턴을 충분히 파악한 후 코드 작업 여부를 결정하고 있습니다.
#4 Pytorch를 multiprocess 환경에서 쓴다면 num_threads를 조정하자.
Pre-forked worker와 PyTorch / Numpy의 충돌
백엔드 서버가 하드웨어 멀티 코어의 장점을 살리기 위해 여러개의 요청을 동시에 처리하는 일은 빈번히 발생합니다. Python 에서도 gunicorn과 같은 pre-forked worker model을 통해 멀티프로세싱을 지원하는 서버를 손쉽게 만들어낼 수 있습니다. 하이퍼커넥트의 추천 API 서버도 gunicorn [4-1]을 이용하여 하나의 pod에 pre-forked unvicorn process (Web Worker 라고도 부름) 다수를 미리 만들어둔 후, 동시에 여러 요청이 들어왔을 때 다수 process에서 동시에 요청을 처리하며 CPU 자원을 병렬적으로 사용할 수 있도록 활용하고 있습니다.
최신의 CPU는 대부분 여러 개의 코어를 가지고 있기 때문에, 일반적으로 병렬성을 이용하면 CPU의 utility를 높여 더 빠른 응답속도와 처리량을 갖는 서버를 구성할 수 있습니다. 하지만 백엔드 어플리케이션에서 PyTorch나 Numpy를 사용하고 있다면, gunicorn 처럼 병렬로 웹 요청을 처리하는 서버를 사용할 때 유의해야 합니다. 오히려 성능이 더 나빠질 수 있기 때문입니다.
PyTorch나 Numpy는 기본적으로 내부 연산을 멀티스레딩으로 수행합니다. (참고로 여기서의 멀티스레딩은 Python multithreading이 아닌, C-level에서의 멀티스레딩입니다!) 다시 말하면, 이 두 라이브러리에서는 현재 환경에서 가용한 CPU 자원을 최대한으로 사용합니다. vCPU가 4인 VM이나 Container, K8S Pod에서는 PyTorch에서 4개의 스레드를 사용해서 내부 연산을 처리한다는 말이죠. 이 점을 간과한 채 vCPU가 4인 pod에서 gunicorn을 사용해서 4개의 web worker (혹은 pre-forked process)를 띄운다면, 하나의 vCPU가 하나의 worker에서만 독립적으로 사용되지 않고, worker마다 서로 모든 CPU를 사용하려고 싸우며, interleaving 되는 시나리오가 발생할 수 있습니다. 이는 context-switching 오버헤드를 증가시키고, L1/L2 cache-miss를 발생시키며, 결과적으로 성능을 저하시키게 됩니다.
예시로 살펴보기
그럼 실제로 Numpy, PyTorch 가 기본적으로 연산을 멀티스레딩으로 수행하는지 알아봅시다. 간단한 방법으로 10,000 by 10,000 행렬곱 연산을 하는 프로그램을 작성하고, htop 과 같은 resource monitoring tool 을 통해 CPU 사용량을 체크해봅시다.
import numpy as np
import torch
numpy_a = np.empty(shape=(10000, 10000))
numpy_b = np.empty(shape=(10000, 10000))
numpy_a @ numpy_b
torch_a = torch.from_numpy(numpy_a)
torch_b = torch.from_numpy(numpy_b)
torch_a @ torch_b
위와 같은 코드를 돌려보면 행렬곱을 처리하는 부분에서 따로 멀티 스레드로 동작하도록 지시하지 않았음에도 아래와 같이 CPU 가 모두 사용 되는 것을 알 수 있습니다.

참고로 16개 중 8개의 코어만 쓰는 것은 사실 나머지 8개의 코어는 intel의 Hyper-threading 기술[4-2]로, 기존 코어의 두배만큼 뻥튀기되어 만들어진 가짜 코어들이기 때문입니다. 이러한 CPU 을 16개의 logical core, 8개의 physical core 을 가졌다고 합니다. Hyper-threading 은 행렬 곱 연산과 같이 이미 거의 완벽한 수준의 instruction level parallelism이 구현된 경우엔 별 도움이 되지 않기에 적용되지 않아 절반만 사용하는 것처럼 보이게 됩니다.
그렇다면 실제 API 서버에서 어떻게 위 문제를 해결할 수 있을까요? FastAPI와 PyTorch를 사용해서 행렬곱(matmul)을 하는 예시를 작성해보았습니다.
import os
import time
import multiprocessing as mp
import torch
def foo(i: int) -> None:
matrix_a = torch.rand(size=(1000, 1000))
matrix_b = torch.rand(size=(1000, 1000))
# warm up
for _ in range(10):
torch.matmul(matrix_a, matrix_b)
start_time = time.perf_counter()
for _ in range(100):
torch.matmul(matrix_a, matrix_b)
print(i, time.perf_counter() - start_time)
if __name__ == "__main__":
num_processes = len(os.sched_getaffinity(0))
print("num_processes: ", num_processes)
with mp.Pool(num_processes) as pool:
pool.map(foo, range(num_processes))
위 코드를 실행하여 서버를 띄우고, 요청을 보내면 아래와 같은 결과가 나옵니다.
❯❯❯ taskset 0x55 python main.py
num_processes: 4
process #[1]: 8.69 s
process #[2]: 8.76 s
process #[0]: 8.87 s
process #[3]: 8.80 s
그렇다면 각 프로세스가 사용하는 스레드의 개수를 1개로 제한해줬을때는 어떨까요? OMP_NUM_THREADS 환경변수를 이용하여 스레드 수를 설정할 수 있습니다.
아래는 각 프로세스마다 사용하는 스레드의 개수를 1개로 제한해줬을 때의 결과이며, 기본 설정과 비교했을 때 6배 가량 빠르게 실행되는 것을 확인할 수 있습니다.
❯❯❯ OMP_NUM_THREADS=1 taskset 0x55 python main.py
num_processes: 4
process #[3]: 1.43 s
process #[2]: 1.43 s
process #[1]: 1.43 s
process #[0]: 1.43 s
참고로 위 예시에서는 OMP_NUM_THREADS 를 통해 worker당 스레드 수를 제한했지만, PyTorch만 사용하는 경우 torch.set_num_threads(1) 함수를 호출하여 스레드 수를 제한할 수도 있습니다.
그렇다면 왜 PyTorch와 Numpy는 최대한의 CPU를 사용하는 것이 기본 설정일까요? 왜냐하면 이들 라이브러리는 데이터 분석과 모델 학습이 주된 사용처이기 때문입니다. 데이터 분석과 모델 학습시에는 백엔드 서버처럼 동시에 여러 작업을 수행할 일이 드물고, 그렇다면 가용한 CPU를 모두 사용하는 것이 더 빠른 속도를 보여주기 때문입니다 [4-3].
하이퍼커넥트의 사례
하이퍼커넥트에서는 위와 같은 문제를 발견한 후, PyTorch를 사용하는 FastAPI 서버, Nvidia Triton 기반의 모델 서버 등에서 PyTorch 스레드를 1로 제한하는 설정을 추가하였습니다. 그 결과, 서버에 따라 Latency와 Throughput이 각각 최대 3배 이상까지 개선되는 경험을 했습니다. 만약 multi-worker를 사용하는 서버에서 PyTorch를 사용하고 있다면, 단 한 줄짜리 코드 수정으로 성능을 3배까지도 올릴 수 있으니 시도해보시길 추천드립니다.
#5 Pydantic은 아주 느리다. 불필요한 곳에서 가급적 사용하지 말자.
Pydantic 이란
최근 많은 곳에서 백엔드 프레임워크로 FastAPI [5-1]를 사용하고 있습니다. FastAPI는 사실상 Flask의 상위 호환 프로젝트라고 봐도 무방할 정도로 좋은 오픈소스라고 생각합니다. 문제는 FastAPI에서 API endpoint를 정의할 때 사용하는 Pydantic입니다. Pydantic [5-2]은 data validation(type check)과 parsing까지 해주는 라이브러리입니다. 아래처럼 사용할 수 있습니다.
from datetime import date
from pydantic import BaseModel
class User(BaseModel):
user_id: int
birthday: date
User.parse_raw('{"user_id": "100", "birthday": "2000-01-01"}')
# User(user_id=100, datetime.date(2000, 1, 1))
FastAPI는 내부적으로 Pydantic을 아예 포함하고 있고, API request 변수와 response type을 Pydantic 객체로 넣어주면 Swagger UI 까지 자동으로 만들어주고 있습니다. 그만큼 FastAPI를 사용한다면 Pydantic은 필수로 사용할 수 밖에 없죠.
Pydantic은 정말 편리합니다. 하지만 편리함에 너무 익숙해져서 data validation이 필요 없는 환경에서도 Pydantic을 남발해서는 안됩니다. 왜냐하면 정말 느리거든요.
예시로 보는 Pydantic의 속도
아래는 길이가 50인 float list를 가지고 있는 Pydantic 인스턴스 400개를 생성하는 간단한 예시입니다.
import timeit
from typing import List
from pydantic import BaseModel
class FeatureSet(BaseModel):
user_id: int
features: List[float]
def create_pydantic_instances() -> None:
for i in range(400):
obj = FeatureSet(
user_id=i,
features=[1.0 * i + j for j in range(50)],
)
elapsed_time = timeit.timeit(create_pydantic_instances, number=1)
print(f"pydantic: {elapsed_time * 1000:.2f}ms")
pydantic: 12.29ms
결과를 보면, 위 코드는 단순히 객체만 수백개 생성했을 뿐인데 12ms라는 생각보다 굉장히 많은 시간이 소요되는 것을 확인할 수 있습니다.
그렇다면 Pydantic이 아닌 바닐라 class로 객체를 생성하면 어떨까요?
import timeit
from typing import List
class FeatureSet:
def __init__(self, user_id: int, features: List[float]) -> None:
self.user_id = user_id
self.features = features
def create_class_instances() -> None:
for i in range(400):
obj = FeatureSet(
user_id=i,
features=[1.0 * i + j for j in range(50)],
)
elapsed_time = timeit.timeit(create_class_instances, number=1)
print(f"class: {elapsed_time * 1000:.2f}ms")
class: 1.54ms
같은 숫자와 property를 가진 위 코드의 실행 결과는 1.5ms로, Pydantic을 사용했을 때보다 8배 가량 빠른 것을 확인할 수 있습니다.
하이퍼커넥트의 사례
하이퍼커넥트에서는 불필요한 Pydantic객체를 사용하던 로직을 모두 바닐라 class 혹은 내장 dataclass로 변경 후, 추천 API 서버의 Latency를 2배 이상 개선시킨 경험이 있습니다. 어떤 서버에서는 Pydantic 객체 생성에 걸리는 시간만 200ms 이상 소요되던 케이스도 있었습니다 (p99 기준).
Pydantic의 느린 속도를 알고 있는지, 내부 로직을 rust로 작성한 Pydantic V2가 개발 중이기도 합니다 [5-3]. 언제 나올지 기대를 하고 있는데요, 아무리 빨라져도 바닐라 Python class 보다 빨라질 수는 없기 때문에 validation이 필요없는 상황에서는 Pydantic을 사용하지 않도록 늘 조심하고 있습니다.
#6 Pandas DataFrame은 생성에 많은 시간이 걸리므로, 유의해서 사용해야 한다.
데이터를 분석하거나 전처리할 때, 많은 ML 엔지니어들은 Pandas [6-1]를 애용합니다. Pandas는 내부적으로 NumPy를 사용하지만 [6-2], 잘못 사용한다면 기대만큼 빠르게 동작하지 않을 수 있습니다. 특히 Pandas를 사용한다면 가장 많이 사용하게 되는 DataFrame의 경우, 데이터의 재가공 프로세스로 인해 생각보다 느린 성능을 보이기에 주의해서 사용해야 합니다.
예시로 보는 pandas 성능
그렇다면 pandas.DataFrame은 얼마나 느릴까요? 아래는 속성이 50개인 dict 객체 1000개에 대해 null 값을 0.0으로 imputation 해보는 예시입니다. pandas.DataFrame에서 제공하는 fillna 메소드를 사용하는 방법과, 순수 Python iteration으로 구현하는 방법을 각각 측정해보았습니다.
import random
import timeit
from typing import Dict, Optional
import pandas as pd
def create_sample_dict() -> Dict[str, Optional[float]]:
d = {}
for i in range(50):
d[f"feature{i}"] = random.random() if random.random() < 0.9 else None
return d
data_list = [create_sample_dict() for _ in range(1000)]
def null_imputation_using_df():
df = pd.DataFrame(data_list)
return df.fillna(0.0)
def null_imputation_in_pure_python():
ret = []
for data in data_list:
new_data = data.copy()
for key, val in new_data.items():
if val is None:
new_data[key] = 0.0
ret.append(new_data)
return ret
elapsed_time = timeit.timeit(null_imputation_using_df, number=1)
print(f"pandas.DataFrame: {elapsed_time * 1000:.2f}ms")
elapsed_time = timeit.timeit(null_imputation_in_pure_python, number=1)
print(f"pure python: {elapsed_time * 1000:.2f}ms")
pandas.DataFrame: 6.91ms
pure python: 1.78ms
결과를 보면 pandas Dataframe을 쓰는 것 보다, 순수 Python 구현이 3배 이상 빠른 것을 확인할 수 있습니다. Pandas의 내부 구현이 NumPy로 되어있음에도 불구하고, Python for loop이 더 빠른 것은 꽤 의아한 결과입니다. df.fillna 명령어가 문제일까요? 사실 대부분의 시간은 pd.DataFrame(data_list) 에서 소요됩니다. DataFrame을 만드는 것 자체가 꽤나 많은 시간을 필요로 하기 때문이죠. 그렇다면 왜 DataFrame을 만드는 것이 오래 걸릴까요?
pandas.DataFrame의 구조와 특징
Pandas DataFrame은 컬럼 지향 (column-oriented) 자료구조를 사용합니다 [6-3, 6-4]. 내부적으로 컬럼마다 numpy ndarray가 하나씩 있는 구조이며, 다시 말하면 컬럼의 수만큼 ndarray가 만들어지게 됩니다.
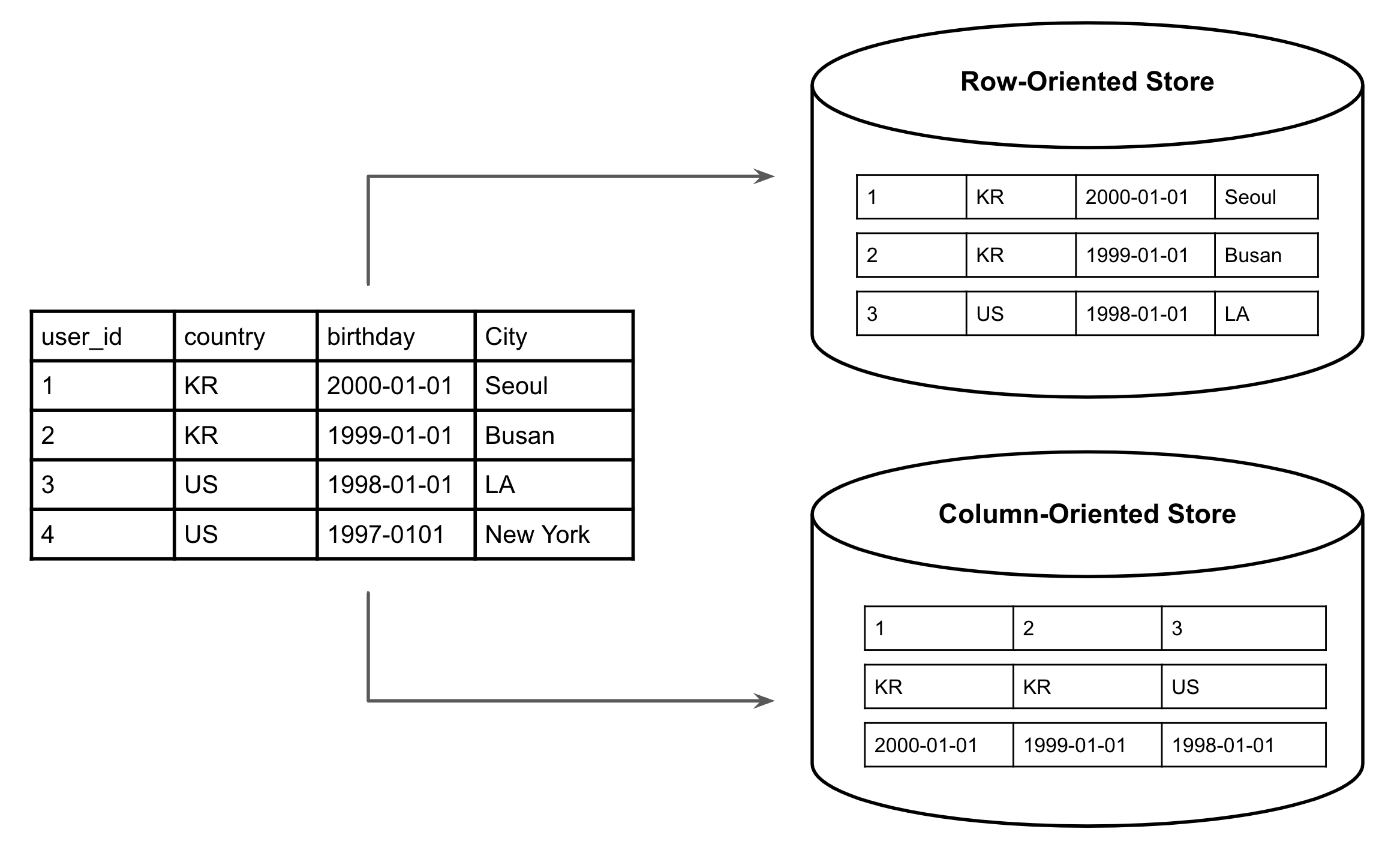
예를들면 아래처럼 세개의 컬럼을 가진 DataFrame은 3개의 ndarray를 가지고 있는 형태입니다.
df = pd.DataFrame([
{"id": 111, "rating": 5.0, "category": "TRAIN"},
{"id": 222, "rating": 4.5, "category": "BUS"},
{"id": 333, "rating": 4.0, "category": "METRO"},
{"id": 444, "rating": 3.5, "category": "METRO"},
])
"""
id -> ndarray([111, 222, 333, 444], dtype=np.int32)
rating -> ndarray([5.0, 4.5, 4.0, 3.5], dtype=np.float32)
category -> ndarray(["TRAIN", "BUS", "METRO", "METRO"], dtype='O')
"""
위와 같은 컬럼 지향 형태로 데이터를 표현한다면, 열 단위로 데이터를 가공하는 연산은 매우 빠르게 수행될 수 있습니다. 예를들면 아래처럼 모든 rating 데이터에 2를 곱하는 연산은 하나의 ndarray만 수정하면 되기 때문에, 로우 지향 자료구조보다 훨씬 빠르게 동작합니다.
df["rating"] = df["rating"] * 2
한 번 생성된 DataFrame은 잘만 사용하면 빠르게 데이터를 가공하는데 사용할 수 있습니다. 문제는 DataFrame을 처음 생성(construct)하는데의 오버헤드에 있습니다.
처음 등장했던 예시처럼 list of dict 데이터를 pandas.DataFrame으로 바꾸려면 1) 컬럼 지향 형태로 데이터를 재가공 후 numpy ndarray를 생성하는 작업과, 2) 컬럼마다 dtype을 추론하는 작업이 수행되어야 합니다. 이는 필연적으로 입력으로 들어온 데이터의 반복적인 읽기 작업과 전처리 작업을 필요로 하며, 오버헤드가 될 수 있습니다.
pandas.DataFrame을 잘 사용하기
만약 열단위 데이터 조작이 많이 필요하지 않은 상황이라면, DataFrame을 아예 사용하지 않는 편이 좋습니다. 만약 열단위 데이터 조작이 많이 필요한 상황이라면, DataFrame의 입력 값으로 list of dict가 아닌 numpy ndarray를 넣어주는 것 만으로 성능을 개선할 수 있습니다. Pandas에서 내부적으로 데이터를 전처리 하는 시간괴, dtype을 추론하는 시간을 줄여줄 수 있기 때문입니다.
맨 처음 등장했던 예시에서, null_imputation_using_df 함수를 아래처럼 바꾸는 것 만으로 속도를 2배 정도 개선할 수 있습니다.
import numpy as np
(...)
def null_imputation_using_df():
arr = np.array([list(d.values()) for d in data_list], dtype=np.float32)
df = pd.DataFrame(arr, columns=list(data_list[0].keys()))
return df.fillna(0.0)
pandas.DataFrame: 2.35ms
하이퍼커넥트의 사례
pandas DataFrame은 DataFrame 인스턴스를 생성하는데 필요한 오버헤드보다, 열 단위 조작으로 인한 수행 시간이 더 클때 효율적입니다. 하이퍼커넥트에서는 백엔드 서버 및 모델 서버 대부분에서는 열 단위 조작 시간보다 DataFrame 인스턴스 생성 시간이 더 큰 병목이었으며, 이런 경우에 로직을 Python primitive와 NumPy 만을 사용하도록 바꿨습니다. 그 결과, P99 latency를 절반 이상으로 낮추고, throughput 또한 2배 이상 개선하는 경험을 하기도 했습니다.
#7 바닐라 json 패키지는 느리다. orjson이나 ujson을 사용하자.
ML과 관련된 작업을 하다 보면 json을 쓸 일이 아주 많습니다. 추론에 필요한 feature들도 json의 형태로 표현하면 편리하고, 만약 웹서버를 만들 경우 다양한 속성들을 표현하기 위해서 위해서 json으로 데이터를 주고 받는 경우가 많죠. 일반적으로 python에서 json을 다룰 때는 내장 json 패키지를 많이 사용합니다. 이 패키지는 Json문자열을 python dict와 list로 seamless하게 바꿔주기 때문에 아주 편리하죠.
그런데 이 json도 상당한 병목이 될 수 있습니다. Python의 내장 json 패키지는 pure python으로 구현되어 있고, 크고 깊은 json 데이터를 다룰 때 예상보다 오랜 시간이 소요될 수 있습니다.
그렇다면 어떻게 해야 할까요? 다행히 내장 패키지보다 더 빠른 orjson[7-1]이나 ujson[7-2]과 같은 서드파티 패키지들이 있습니다. 이런 라이브러리들은 핵심 로직이 Rust나 C로 구현되어 있고, 큰 사이즈의 데이터를 다루는데 적합하도록 최적화되어 있어 내장 패키지보다 처리 속도가 훨씬 빠릅니다.
아래 코드는 서로 다른 json 라이브러리에서 1000개의 property를 가지는 json string을 100번 파싱하는 예시입니다.
import json
import random
import timeit
import ujson
import orjson
sample_dict = {}
for i in range(1000):
sample_dict[f"feature{i}"] = random.random()
json_string = json.dumps(sample_dict)
def test_json():
return json.loads(json_string)
def test_ujson():
return ujson.loads(json_string)
def test_orjson():
return orjson.loads(json_string)
num_runs = 100
json_time = timeit.timeit(test_json, number=num_runs)
ujson_time = timeit.timeit(test_ujson, number=num_runs)
orjson_time = timeit.timeit(test_orjson, number=num_runs)
print(f'json: {json_time * 1000:.1f} ms')
print(f'ujson: {ujson_time * 1000:.1f} ms')
print(f'orjson: {orjson_time * 1000:.1f} ms')
결과는 다음과 같습니다.
json: 36.5 ms
ujson: 14.4 ms
orjson: 8.6 ms
내장 json 패키지와 비교했을 때, ujson의 경우 2배 이상, orjson의 경우 4배 이상 속도가 차이나는 것을 알 수 있습니다. 만약 json 파싱을 heavy하게 해야 하는 상황이라면, 라이브러리를 바꾸는 것만으로도 유의미한 성능 향상을 이룰 수 있을 것입니다.
하이퍼커넥트의 사례
하이퍼커넥트의 ML 모델 서빙 서버 중에는, 다량의 feature 데이터를 json 형태로 입력받는 것들이 있었습니다. 서버에서 입력받는 json 데이터는 대부분 다량의 피쳐가 포함된, 큰 사이즈가 많았습니다. 해당 서버들에서 바닐라 json 패키지에서 orjson으로 바꾼 후, p99 latency가 5~10% 정도 개선되는 경험을 했습니다.
#8 Class는 충분히 빠르지 않을 수 있다. 너무 문제가 되면 dict를 사용하자.
수 십개 이내의 클래스 인스턴스를 만드는 것은 보통 큰 문제가 되지 않습니다. 문제는 수 천개 이상의 클래스를 사용할 때입니다. 너무 많은 클래스 인스턴스를 생성하는 상황에서는, 클래스의 속도조차 문제가 될 수 있습니다.
아래는 property가 30개 있는 class와 dict를 각각 2000개 생성하는 예시입니다.
import timeit
NUM_INSTANCES = 2000
class FeatureSet:
def __init__(
self, user_id: int,
feature1: float, feature2: float, (...) feature30: float,
):
self.user_id = user_id
self.feature1 = feature1
self.feature2 = feature2
(...)
self.feature30 = feature30
def create_class_instances() -> None:
for i in range(NUM_INSTANCES):
obj = FeatureSet(
user_id=i,
feature1=1.0 * i,
feature2=2.0 * i,
(...)
feature30=30.0 * i,
)
def create_dicts() -> None:
for i in range(NUM_INSTANCES):
obj = {
"user_id": i,
"feature1": 1.0 * i,
"feature2": 2.0 * i,
(...)
"feature30": 30.0 * i,
}
class_time = timeit.timeit(create_class_instance, number=1)
print(f"class: {class_time * 1000:.1f}ms")
dict_time = timeit.timeit(create_dict, number=1)
print(f"dict: {dict_time * 1000:.1f}ms")
위 코드에 대한 실행 결과는 아래와 같습니다 (Python 3.8 환경):
class: 8.0ms
dict: 2.9ms
class와 dict의 생성 속도가 2.5배 이상 나는 것을 확인할 수 있습니다. 물론 5ms 정도의 차이라면 크지 않다고 생각할 수도 있겠지만, property의 숫자가 늘어날 수록, 생성하는 인스턴스가 많아질수록 격차는 더 커지게 됩니다.
__slot__ [8-1] 를 사용하는 것은 도움이 될 수도 있지만, 이는 주로 메모리를 절약 해주는 효과가 크지, 속도를 빠르게 해주지는 않습니다. class 대신 dataclass를 사용하는 것도 속도에 큰 차이가 나지 않았습니다.
더불어 클래스에 property가 많으면서 동시에 많은 클래스 인스턴스를 생성하는 상황에서는 kwargs와 setattr 함수를 사용 또한 조심해야합니다. 보통 property가 많으면 타이핑하기 귀찮기에 kwargs와 setattr 함수를 사용하는 경우가 빈번할 수 있습니다. 하지만 이는 함수를 더 많이 호출하게 되어 속도가 기존보다도 2배 이상 더 느려질 수 있습니다.
물론 class를 포기하고 모든 객체를 dict로 관리하는 것은 기술 부채 측면에서 끔찍한 결정이 될 수 있습니다. 하지만 코드의 아주 일부분 중에서 연산량이 너무 많아 class의 생성 속도 조차 문제가 되는 상황이라면, class를 사용하지 않는 것도 고려해볼 수 있습니다.
참고로 Python 3.11 부터는 class의 속도가 개선되어 dict와의 격차가 줄어듭니다. 자세한 내용은 다음 섹션에서 다시 다룹니다.
하이퍼커넥트의 사례
하이퍼커넥트 서비스의 경우 수천 개 이상의 오브젝트를 생성해야 하는 극히 일부 로직에서, class의 속도 조차 병목이 되어 제한적으로 dict를 사용하고 있는 부분이 존재합니다. 다만 dict 사용시 mypy와 같은 정적 type checking tool의 효과를 볼 수 없기에, 매우 제한적으로만 이용하고 있습니다.
#9 Python 3.11은 덜 느리다.
2022년 10월에 릴리즈된 Python 3.11에서는 많은 성능 향상이 있었습니다 [9-1]. 이번 섹션에서는 여러가지 개선점들 중, 앞선 섹션에서 다루었던 클래스의 생성(construction) 속도에 대해 간단히 다뤄보겠습니다. Python 3.11에서는 기존에 클래스를 초기화 할 때 일어났던 비효율적인 연산들을 최적화해 클래스 생성 속도가 훨씬 빨라졌습니다. 아래의 코드를 통해 동일한 속성값(attribute)을 가지는 dict와 class, dataclass를 만드는데 걸리는 시간을 측정해보겠습니다.
import timeit
from dataclasses import dataclass
ITERATIONS = 100000
class MyClass:
def __init__(self, key1, key2, key3):
self.key1 = key1
self.key2 = key2
self.key3 = key3
@dataclass
class MyDataclass:
key1: int
key2: int
key3: int
def create_dict():
my_dict = {"key1": 1, "key2": 2, "key3": 3}
def create_class():
MyClass(1, 2, 3)
def create_dataclass():
MyDataclass(1, 2, 3)
dict_time = timeit.timeit(create_dict, number=ITERATIONS)
class_time = timeit.timeit(create_class, number=ITERATIONS)
dataclass_time = timeit.timeit(create_dataclass, number=ITERATIONS)
print(f"dictionary creation time: {dict_time * 1000:.2f} ms")
print(f"class creation time: {class_time * 1000:.2f} ms")
print(f"dataclass creation time: {dataclass_time * 1000:.2f} ms")
# Python 3.10
dictionary creation time: 9.30 ms
class creation time: 23.05 ms
dataclass creation time: 22.30 ms
# Python 3.11
dictionary creation time: 9.45 ms
class creation time: 13.45 ms
dataclass creation time: 12.90 ms
3.10에 비해 3.11에서 class와 dataclass 생성 속도가 각각 1.7배 정도 빨라진 것을 알 수 있습니다. 그럼에도 여전히 dict의 생성 속도보다는 1.4배 정도 느린데요, class가 내부적으로 dict를 이용하기 때문에 dict 생성 시간에 class와 관련된 추가적인 오버헤드가 붙어 불가피합니다. 하지만 클래스의 생성 속도때문에 성능 문제를 겪고 있는 상황이라면 Python 3.11로 업그레이드하는 것도 고려해볼만 합니다. 현 시점(2023.05)에서는 아직 Python 3.11을 지원하지않는 라이브러리가 종종 있고, 경우에 따라 라이브러리 버전을 올려야 할 수도 있기 때문에 미리 의존하는 라이브러리들이 Python 3.11을 지원하는지 꼭 체크하는것, 잊지 마세요.
Python 3.11의 클래스 생성 방식 변화가 궁금하시다면 이 글을 참고하세요. 이 외에도 Python 3.11의 성능 향상에 대해 더 자세히 알고 싶다면 이 글을 참고하세요.
하이퍼커넥트의 사례
Python 3.8로 운영되던 추천 API 서버를 Python 3.11로 올린 이후, 평균 latency가 5~10% 정도 줄어드는 경험을 했습니다.
#10 (보너스) line profiler 사용법
지금까지 하이퍼커넥트에서 Python으로 ML 백엔드 서버들을 운영하며 발견한 여러 성능 개선 노하우들을 공유드렸습니다. 하지만 상황에 따라 성능에 병목이 생기는 구간은 늘 바뀔 수 있습니다. 고성능 ML 백엔드를 구현하기 위해서 사실 가장 필요한 것은 Python 성능 트릭에 대해서 많이 아는 것이 아니라, 성능 문제가 발생했을 때 해결할 수 있는 능력입니다. 그리고 성능 문제를 해결하기 위해서 가장 먼저 해야할 것은 어떤 부분이 병목인지를 발견하는 것입니다.
line profiler
Python 코드에서 어느 부분이 병목인지 확인하고 싶을 때, 간단하게 진단할 수 있는 툴 중 하나가 line_profiler 입니다. line_profiler는 이름 그대로 Python 의 함수를 line by line 으로 실행속도를 측정해주는 프로그램입니다. 더 좋은 프로파일링 툴도 많지만 (ex. cProfile), line_profiler는 훨씬 쉽고 직관적으로 직관적으로 어느 부분이 병목인지 알려줍니다.
아래는 line profiler 에 대한 간단 사용 가이드입니다.
$ pip install line_profiler
위 명령어를 통해 line profiler 를 설치해줍니다.
그리고 profile 하고 싶은 함수에 @profile decorator 를 달아줍니다.
@profile
def slow_function(a, b, c):
...
그 후
$ kernprof -lv main.py
위 명령어로 파이썬 스크립트를 실행해주면 아래와 같이 profiling 결과가 나오는 것을 확인할 수 있습니다.
Wrote profile results to line_p.py.lprof
Timer unit: 1e-06 s
Total time: 2.86632s
from fastapi import FastAPI
import numpy as np
from line_profiler import LineProfiler
app = FastAPI()
def heavy_func(n):
a = np.random.random((n, n))
b = np.random.random((n, n))
return np.sum(a + b)
profiler = LineProfiler()
wrapped_heavy_func = profiler(heavy_func)
@app.get("/api")
async def api():
result = wrapped_heavy_func(100)
profiler.print_stats()
return result
File: line_p.py
Function: func at line 3
Line # Hits Time Per Hit % Time Line Contents
==============================================================
3 @profile
4 def func():
5 10 85541.0 8554.1 3.0 a = np.random.random((1000, 1000))
6 10 76209.0 7620.9 2.7 b = np.random.random((1000, 1000))
7 110 473.0 4.3 0.0 for _ in range(10):
8 100 2704098.0 27041.0 94.3 a @ b
클라우드 환경에서 프로파일링 하기
클라우드에 직접 모델 서버를 띄워야 하는 상황에선, kernprof 명령어를 사용하기 힘든 경우가 있습니다. 특히 스테이징 환경에서 실제와 비슷한 입력을 받아보며 성능을 측정해보고 싶을 때에도 kernprof은 사용하기 어렵습니다.
이런 경우를 위해 line_profiler는 Python 로직 내부에서 프로파일링 실행 및 결과를 출력할 수 있는 API를 제공합니다. 아래는 로직 내부에서 프로파일링을 하는 예시입니다.
from fastapi import FastAPI
import numpy as np
from line_profiler import LineProfiler
app = FastAPI()
def heavy_func(n):
a = np.random.random((n, n))
b = np.random.random((n, n))
return np.sum(a + b)
profiler = LineProfiler()
wrapped_heavy_func = profiler(heavy_func)
@app.get("/api")
async def api():
result = wrapped_heavy_func(100)
profiler.print_stats()
return result
위 코드를 실행시키고 /api로 요청을 보내면 profiler.print_stats() 호출에 의해 method 의 프로파일링 결과가 출력되는 것을 확인할 수 있습니다.
Function: heavy_func at line 7
Line # Hits Time Per Hit % Time Line Contents
==============================================================
7 def heavy_func(n):
8 1 361000.0 361000.0 43.1 a = np.random.random((n, n))
9 1 139000.0 139000.0 16.6 b = np.random.random((n, n))
10 1 337000.0 337000.0 40.3 return np.sum(a + b)
하이퍼커넥트에서는 많은 병목 지점을 line profiler 툴을 활용하여 진단해왔습니다. 이 블로그에서 작성된 상당수의 트릭들도 프로파일링을 통해서 발견한 것들이 많습니다. 우리가 작성하는 코드엔 다양한 병목 구간들이 존재할 수 있습니다. 더불어 눈으로 보기에 병목이라고 생각했던 것들도, 프로파일링을 실제로 돌려보니 병목이 아니었던 경우도 많았습니다. 프로파일링이 처음엔 귀찮게 느껴질 수 있어도, 정말 문제가 되는 부분을 찾고 고치기 위한 가장 효율적인 방법은 결국 프로파일링을 먼저해보는 것입니다. 프로그램의 속도가 느리다는 생각이 들 떈, 가장 먼저 병목 지점이 어디인지 또 얼마나 느린지 프로파일링을 통해서 진단해보세요. 병목 지점을 찾게되면 성능 개선은 자연스럽게 따라옵니다.
맺으며
이 글에서는 Python의 느린 성능 때문에 고충 받고 있는 분들께 도움이 되고자, 하이퍼커넥트의 Python 성능 개선 팁들을 공유해 보았습니다. 성능 개선 트릭 이외에도, Python에 대해서 충분히 고민하고, 내부 로직에 대해서 이해하려고 노력하며, 또 프로파일링까지 수행하며 성능을 개선하고자 하면, 비즈니스에서 요구하는 수준의 성능은 충분히 만들어낼 수 있다는 메시지도 전달되었기를 바랍니다. 그럼 긴 글 읽어주셔서 감사합니다.
References
[0-1] https://instagram-engineering.com/web-service-efficiency-at-instagram-with-python-4976d078e366
[0-2] https://en.wikipedia.org/wiki/CPython
[1-1] https://devguide.python.org/internals/garbage-collector/
[1-2] https://en.wikipedia.org/wiki/Reference_counting
[1-3] https://en.wikipedia.org/wiki/Tracing_garbage_collection
[1-4] https://d2.naver.com/helloworld/1329
[1-5] https://devguide.python.org/internals/garbage-collector/#collecting-the-oldest-generation
[1-6] https://instagram-engineering.com/dismissing-python-garbage-collection-at-instagram-4dca40b29172
[2-1] https://docs.python.org/3/library/array.html
[2-2] https://numpy.org/doc/stable/reference/arrays.scalars.html#numpy.object_
[2-3] https://numpy.org/doc/stable/reference/generated/numpy.apply_along_axis.html
[3-1] https://wiki.python.org/moin/GlobalInterpreterLock
[3-2] https://docs.python.org/3/library/multiprocessing.html#contexts-and-start-methods
[3-3] https://pythonspeed.com/articles/faster-multiprocessing-pickle/
[3-4] https://docs.python.org/3/library/multiprocessing.html#pipes-and-queues
[4-1] https://gunicorn.org/
[4-2] https://www.intel.com/content/www/us/en/gaming/resources/hyper-threading.html
[5-1] https://fastapi.tiangolo.com/
[5-2] https://docs.pydantic.dev/
[5-3] https://docs.pydantic.dev/blog/pydantic-v2/
[6-1] https://pandas.pydata.org/
[6-2] https://en.wikipedia.org/wiki/Pandas_(software)
[6-3] https://dkharazi.github.io/blog/blockmanager
[6-4] https://uwekorn.com/2020/05/24/the-one-pandas-internal.html
[7-1] https://github.com/ijl/orjson
[7-2] https://github.com/ultrajson/ultrajson
[8-1] https://wiki.python.org/moin/UsingSlots
[9-1] https://medium.com/aiguys/how-python-3-11-is-becoming-faster-b2455c1bc555
Read more
-
ksqlDB를 이용하여 실시간 ML 피쳐 데이터를 계산하기
카프카에서 제공하는 ksqlDB를 사용하여 실시간 피쳐 데이터를 계산하고 사용하는 방법을 공유합니다. -
머신러닝 어플리케이션을 위한 데이터 저장소 기술
머신러닝 어플리케이션의 데이터 사용 패턴을 분석하고, 데이터 사용 패턴에 적합한 데이터 저장소엔 어떠한 것들이 있는지에 대해서 소개합니다. -
이벤트 기반의 라이브 스트리밍 추천 시스템 운용하기
마이크로서비스 아키텍처와 이벤트 주도 아키텍처로 구현된 라이브 스트리밍 추천 시스템을 소개합니다.