이벤트 기반의 라이브 스트리밍 추천 시스템 운용하기
안녕하세요, 하이퍼커넥트 AI Lab에서 Machine Learning Software Engineer로 일하고 있는 이영수입니다. 하이퍼커넥트 AI Lab에서는 최고 수준의 학회에 머신러닝 논문을 출판하는 등 우수한 연구 성과를 내면서도, 다양한 머신러닝 기술을 실제로 제품에 적용하여 비즈니스 임팩트와 사용자의 만족도를 높이는 것을 가장 중요한 목표로 하고 있습니다. 머신러닝 기술을 제품에 적용하기 위해서는 다양한 엔지니어링 문제를 마주하게 되는데요. 그중 이번 포스트에서는 아자르 라이브와 하쿠나 라이브에 적용되어 있는 라이브 스트리밍 추천 시스템을 소개해드리려 합니다.
라이브 스트리밍에서의 추천 시스템
추천 시스템은 서비스가 가지고 있는 수많은 아이템 중에 사용자가 제일 좋아할 만한 아이템 들을 찾아내는 것이 목표입니다. 아이템은 도메인에 따라 결정되는데요, 예를 들어 Amazon이라면 상품, Netflix라면 영화나 비디오, Spotify라면 음악이 아이템입니다. 저희 팀에서 다루고 있는 도메인인 “라이브 스트리밍”에서 아이템은 “스트리머”, 혹은 “라이브 방송”이 됩니다. 따라서 저희의 추천 시스템은 사용자가 제일 좋아할 만한 스트리머, 혹은 라이브 방송을 추천해 주는 것이 목표가 되죠.

그림 1. 하쿠나 라이브와 아자르 라이브
허나 스트리머라는 아이템은 추천 시스템에서 꽤 까다로운 존재입니다. 다른 아이템들과 비교해 크게 아래의 2가지 특성을 가지고 있죠.
1. 현재 방송 중인 스트리머만 추천을 해야 한다
상품이나 영화, 음악의 경우에는 온라인 여부를 고려할 필요가 없습니다. 이에 반해 라이브 스트리밍에서는 어떤 스트리머가 현재 실시간 방송 중인지를 알아야 합니다 [1].
2. 컨텍스트가 자주 바뀌기 때문에 모델에서 실시간 데이터를 활용해야 한다
상품이나 영화, 음악의 경우에는 어제나 오늘이나 항상 같은 상태로 존재하며, 영화를 1주일 전에 본 사람과 어제 본 사람이 크게 다르지 않을 것입니다. 하지만 라이브 스트리밍에서는 시간대에 따라 스트리머의 방송 컨텐츠가 달라질 수도 있고 (오전 방송, 오후 방송, 새벽 방송 간의 차이), 방송 도중에도 특수한 이벤트로 인해서 특성이 바뀔 수도 있습니다 (예를 들어 평소에는 매니아들만 보는 방송이지만, 어떤 날에는 유명 게스트가 출연하여 일반적으로 인기 있는 방송이 되는 경우). 따라서 실시간 데이터를 모델에서 사용하는 것이 중요합니다.
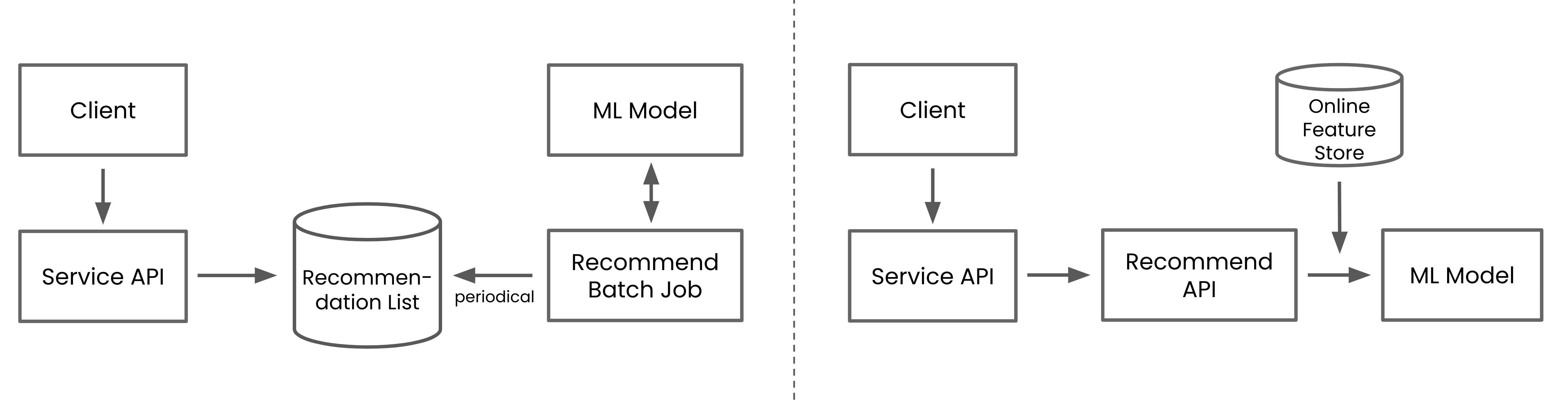
그림 2. 추천 DB를 바탕으로 비 실시간으로 동작하는 추천 시스템과(좌), 추천 API를 통해 실시간으로 동작하는 추천 시스템(우)
이처럼 라이브 스트리밍이라는 도메인에서는 실시간성이 중요하지만, 추천 시스템에서 실시간 컨텍스트를 사용하는 것은 더 많은 엔지니어링 작업을 필요로 합니다. 예를 들어 실시간성이 중요하지 않은 추천 시스템에서는 일정 주기마다 batch job으로 추천 리스트를 계산하여 데이터베이스에 저장해두고, 해당 데이터베이스만 제품 조직에 제공하는 방식으로도 추천 시스템을 구현할 수 있습니다. 하지만 실시간성이 중요한 추천 시스템에서는 사용자가 추천 목록을 요청할 때마다, 실시간으로 추천 모델을 추론하는 방식으로 동작해야 합니다. 실시간 모델 추론은 쉬운 일이 아닌 게, 모델을 추론하기 위해서 모델의 input feature를 실시간으로 가져오는 등의 부가적인 엔지니어링 작업이 요구되기 때문입니다. 이런 작업들은 추천을 위한 백엔드 시스템을 복잡하게 만들게 되죠.
높은 복잡도의 추천 시스템을 효율적으로 개발하고 운용하기 위해 하이퍼커넥트에서는 마이크로서비스 아키텍처(microservice architecture)와 이벤트 주도 아키텍처 (event-driven architecture)로 추천 백엔드 시스템을 개발하고 있습니다. 덕분에 높은 확장성(high scalability)과 낮은 결합도(loose coupling)를 바탕으로 실시간성이 특히 중요한 라이브 방송에서 보다 다양한 실시간 피쳐를 사용하고 있고, 또 개발 서비스와 독립적으로 추천 시스템의 개발과 배포를 수행하고 있습니다. 그럼 우선 하이퍼커넥트의 추천 시스템에서 적용하고 있는 두 아키텍처에 대해 설명해 드리려 합니다.
마이크로서비스 아키텍처와 이벤트 주도 아키텍처
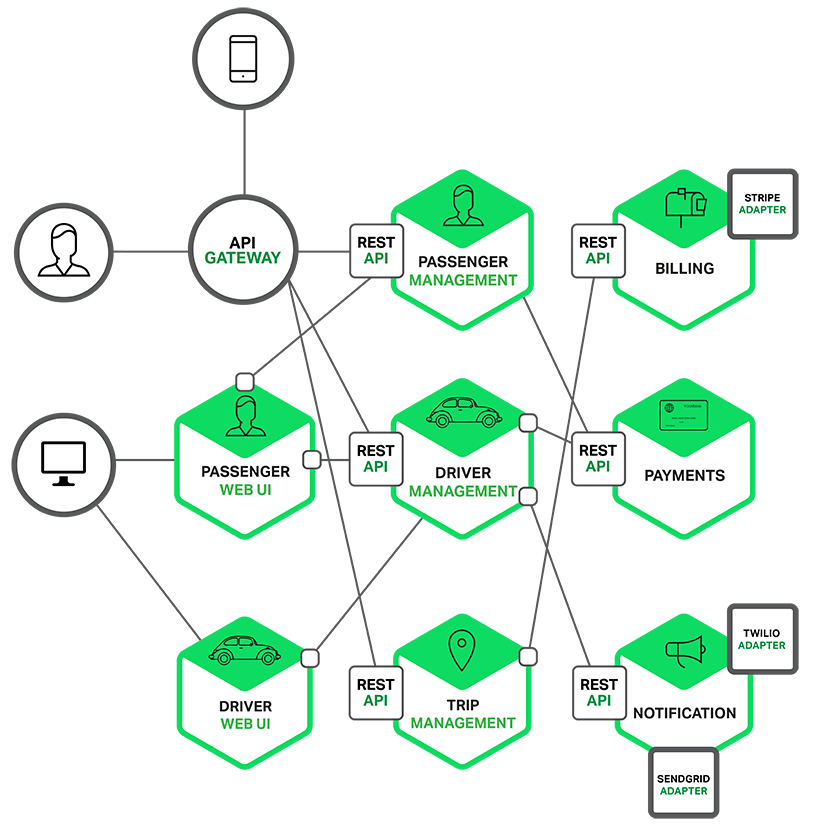
그림 3. 마이크로서비스 아키텍처 (MSA). 출처: nginx.com
마이크로서비스 아키텍처
마이크로서비스 아키텍처(MSA)는 복잡한 대형 소프트웨어를 작고 독립적인 여러 모듈로 나누어 개발하는 아키텍처이자 접근 방식입니다 [2]. MSA를 적용했을 때의 가장 큰 장점은 배포 주기가 짧아진다는 것인데요, 특히 하나의 제품을 위해 개발에 참여하는 조직이 많을수록 그 효과가 더 커진다고 할 수 있습니다. 이런 장점 때문에 하이퍼커넥트의 추천 마이크로서비스 또한 제품 마이크로서비스들로부터 분리되어 있습니다. 제품 개발팀에서는 제품의 본질에만 집중하고, 추천 팀에서는 추천을 위해서만 고민하는 것이 효율이 좋기 때문이죠.
하지만 MSA를 이용한다고 하더라도 마이크로서비스 간 API 요청이 잦아지고 Shared Database가 생기기 시작하면, 본래 MSA의 장점이었던 낮은 결합도가 점차 깨지게 되며 커뮤니케이션 비용이 증가하게 되어, 결과적으로 배포 주기가 다시 느려지는 상황이 발생할 수 있습니다.
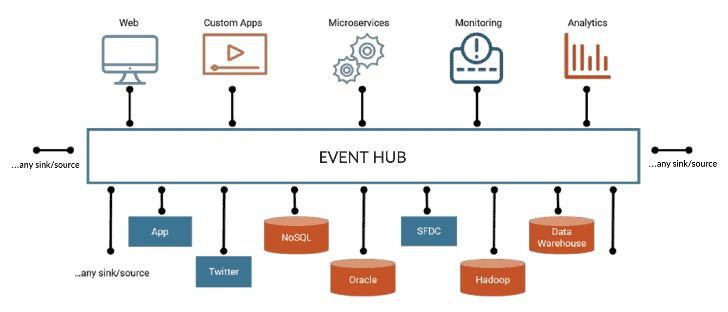
그림 4. 이벤트 주도 아키텍처. 출처 anexinet.com
이벤트 주도 아키텍처
이런 상황에 마이크로서비스간 결합도를 더 낮출 수 있는 방법 중 하나가 이벤트 주도 아키텍처(Event Driven Architecture) 입니다. 마이크로서비스와 이벤트 주도 아키텍처를 합쳐서 Event-driven Microservices라고도 부릅니다. 이벤트 주도 아키텍처에서는 API 호출이나 트랜잭션이 발생했을 때, 해당 트랜잭션을 처리하는 마이크로서비스가 이벤트를 공통 이벤트 버스(ex. Kafka)에 발행(publish) 하고, 해당 이벤트가 필요한 다른 마이크로서비스에선 이벤트를 구독(subscribe) 하는 형태로 시스템을 구성합니다 [3]. 이벤트 주도 아키텍처로 시스템을 구성하면 데이터의 흐름이 보다 명확해지며, 마이크로서비스 간 통신 시나리오가 훨씬 단순해지고, 따라서 다시 loosely coupled 시스템으로 만들 수 있습니다 [4].
하이퍼커넥트에서는 이미 다양한 프로덕트와 피쳐들을 이벤트 주도 아키텍처로 개발하고 있고, AI Lab에서 개발하고 있는 다양한 머신러닝 기반의 서비스도 예외는 아닙니다. 이벤트 기반으로 시스템을 구성하면 엔지니어링 비용이 조금 더 증가하는 단점이 있지만, 커뮤니케이션 비용을 최소화하면서 매우 높은 자유도로 개발을 할 수 있다는 장점이 있습니다.
이벤트 기반의 라이브 스트리밍 추천 시스템
추천 시스템을 제품 서비스로부터 분리된 별도의 마이크로서비스로 개발하게 되면 개발의 독립성을 통해 빠른 배포와 실험이 가능해진다는 사실은 명백합니다. 그렇다면 이벤트 주도 아키텍처는 추천 시스템에서 구체적으로 어떤 도움이 될까요? 추천 모델 추론에 필요한 input feature를 가져오는 로직을 예시로 들어보겠습니다.
추천 모델에서 방송별 현재 시청자들의 수나 평균 시청 시간 와 같은 input feature를 사용해 본다고 가정해 봅시다. 이때 이벤트 기반의 MSA가 아닌 통상적인 MSA에서 방송별 현재 시청자들의 수나 평균 시청 시간 을 실시간으로 가져오기 위해서는 아래 2가지 방법 중 하나를 이용해야 합니다.
- 제품 백엔드 팀에 해당 데이터를 반환해 주는 API를 개발해달라고 요청
- 여러 마이크로서비스에서 공유해서 사용하는 데이터베이스 생성
초기에는 위의 방법이 괜찮을 수 있습니다. 하지만 시간이 지나면 두 방법 모두 생산성을 악화시키고, 결과적으로 추천 성능까지 저하시킬 수 있습니다. 아래와 같은 문제를 갖고 있기 때문이죠.
제품 마이크로서비스에 API 요청하는 방식의 문제
이 방법은 추천 서비스에서 원하는 데이터를 바로 쓰고 싶어도, 제품 팀에서 해당 데이터를 반환해 주는 API를 개발할 때까지 기다려야 합니다. 그 과정 중에 여러 번의 미팅과 함께 커뮤니케이션 오버헤드가 발생할 수도 있죠. 결과적으로 이는 생산성을 떨어뜨리고, 추천 모델을 온라인에서 더 자주 실험할 수 있는 기회를 줄이게 됩니다.
여러 마이크로서비스에서 데이터베이스를 공유하는 방식의 문제
이 방법 또한 쉽게 택할 수 있는 선택지가 아닙니다. 쿼리를 잘못 작성하게 된다면 다른 API들의 성능에 영향을 끼칠 수도 있고, 쿼리와 함께 write operation을 사용하고 싶어도 개발에 돌입하기 전에 해당 write operation 다른 마이크로서비스에 끼칠 수 있는 side-effect에 대해서도 고려해야 합니다. 그 과정 동안 커뮤니케이션 비용은 다시 커질 수밖에 없죠.
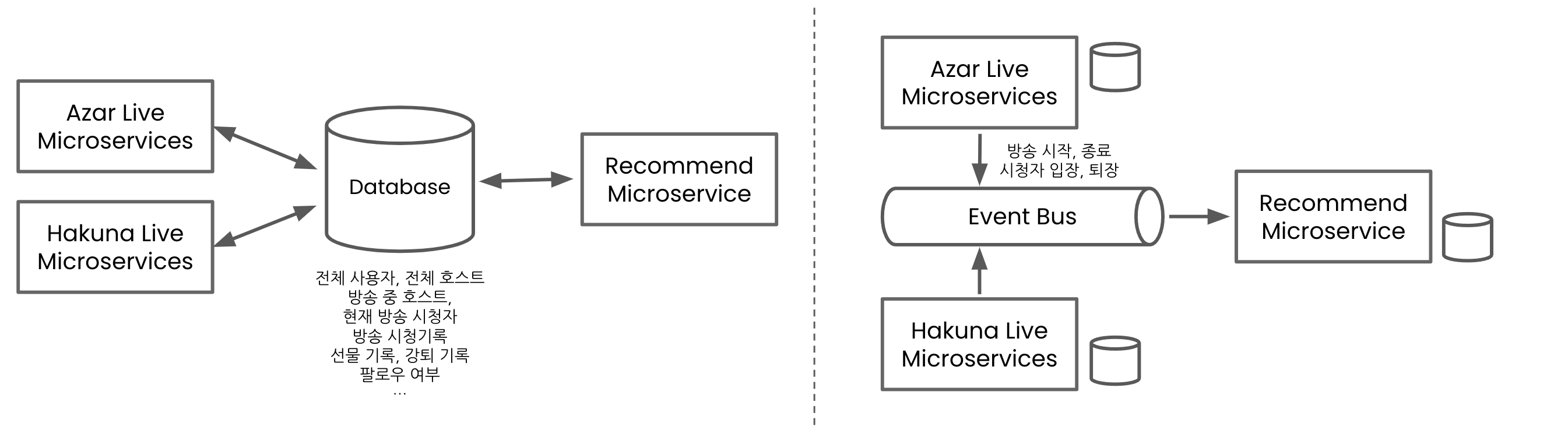
그림 5. Shared database 기반의 MSA와 (좌), Event 기반의 MSA (우)
이벤트 주도 아키텍처
이런 상황 속에서 이벤트 주도 아키텍처는 많은 문제를 해결해 줍니다. 아자르 라이브나 하쿠나 라이브와 같은 제품 백엔드 서비스에서는 방송 시청과 관련된 이벤트를 이벤트 버스에 발행하고, 추천 서비스 쪽에서는 해당 이벤트를 구독하여 방송별 현재 시청자들의 수나 평균 시청 시간과 같은 데이터를 쉽게 계산할 수 있게 됩니다.
이벤트는 한 번 스펙이 정해지면 잘 바뀌지도 않고, 따라서 커뮤니케이션도 크게 필요하지 않습니다. 또 Scalable 한 시스템을 자연스럽게 구축할 수 있고, single point of failure[5]가 줄어들기 때문에 더 안정적인 서비스 운영도 가능해집니다. 무엇보다도 이벤트 기반으로 추천 시스템을 구성한다면 훨씬 자유도가 높아지고 새로운 피쳐의 추가 속도가 빨라지게 됩니다. 필요한 피쳐를 그냥 저희가 이벤트에서 당겨와서 만들면 되니까요!
하이퍼커넥트의 라이브 스트리밍 추천 백엔드 시스템
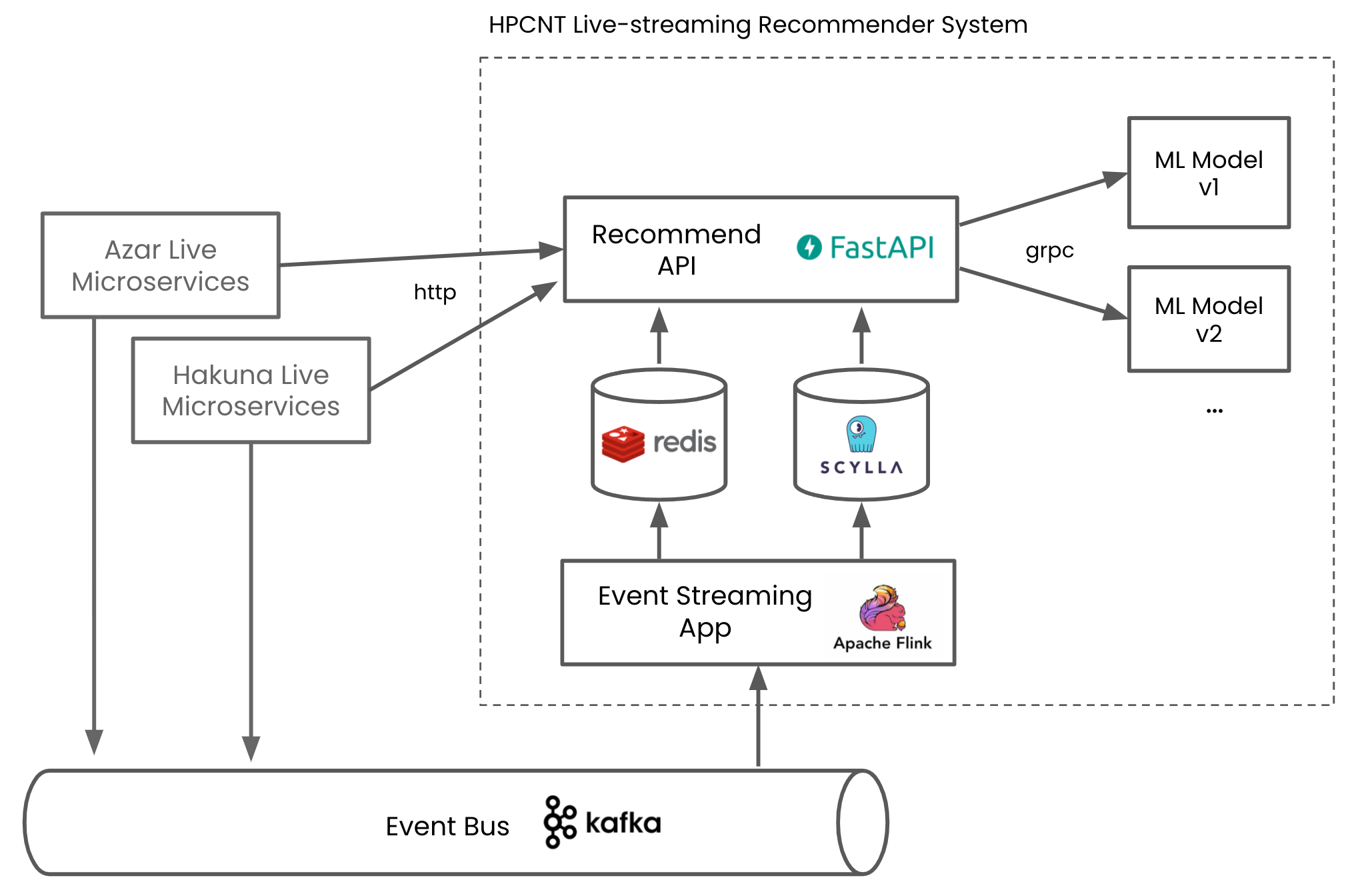
그림 6. 하이퍼커넥트의 라이브 스트리밍 추천 백엔드 시스템
하이퍼커넥트의 라이브 추천 백엔드 시스템은 이벤트 주도 아키텍처로 개발되어 있습니다. 다른 마이크로서비스에 의존성이 없고, Kafka를 통해 받아오는 event 만으로 데이터를 관리 중이죠. 덕분에 새로운 모델을 배포하면서 새로운 데이터를 사용하고 싶을 때, 다른 조직과 별도의 커뮤니케이션 없이 자체적으로 이벤트를 consume 하고 가공하여 빠르게 새로운 피쳐를 사용하고 있습니다.
일반적으로 Machine Learning의 성능이라고 하면 모델의 성능이 가장 중요하다고 생각하기 쉽습니다. 물론 실제로도 모델은 매우 중요합니다. 하지만 라이브 스트리밍과 같이 실시간으로 데이터를 주고받을 일이 많은 추천 시스템에서는 어떤 시스템 아키텍처를 가져가는지도 추천 성능에 영향을 끼칠 수 있습니다. 연구 단계에서 높은 성능의 추천 모델을 만들었다고 하더라도, 해당 모델을 서빙하기 위해 필요한 실시간 피쳐를 시스템에서 가져올 수 없다면 해당 모델은 프로덕션에서 사용할 수가 없습니다. 또는 서빙 사이드의 개발 속도가 모델 연구 속도를 따라오지 못한다면 iteration이 느려질 수밖에 없고, 더 높은 성능 향상을 이룰 기회를 날려버릴 수 있죠. Machine Learning에서 가장 중요한 가설 → 오프라인 실험 → 온라인 실험 → 개선 → 가설 의 Cycle을 더 빠르게 굴리기 위해서는 충분히 높은 생산성을 ML 백엔드 시스템에서도 보여주어야 합니다.
이벤트 주도 아키텍처를 사용하면 개발의 독립성이 보장되고, 시스템이 커져도 조직 간 커뮤니케이션 비용으로 인한 생산성 저하 문제가 줄어들게 됩니다. 덕분에 시스템이 성숙해지며 코드가 복잡해져도 계속 빠른 개발과 배포가 가능하며, 모델 실험 및 개선 cycle도 여전히 자주 돌릴 수 있게 되죠.
구현 레벨에서의 challenge 들과 해결 방법
지금까지 이벤트 주도 아키텍처를 통해 추천 시스템에서 생산성을 챙길 수 있음을 보였지만, 사실 이벤트 주도 아키텍처도 만능은 아닙니다. 실시간 추천 시스템은 여전히 구현 과정에서 많은 엔지니어링 challenge를 가지고 있고, 이 섹션에서는 저희가 겪었던 대표적인 엔지니어링 challenge들과 각각에 대한 해결 방법들을 간단히 소개해 드리려 합니다.
1. 방송 시작 및 종료, 시청자 입장 및 퇴장과 같은 이벤트를 실시간으로 처리해야 함
먼저 이벤트를 실시간으로 처리해야 하는 문제를 풀기 위해 저희는 Apache Flink를 이용하여 이벤트를 비동기로 처리하고 있습니다. Flink는 Kafka와 같은 event bus에서부터 event를 subscribe 하여 실시간으로 데이터를 처리할 수 있도록 해주는 프레임워크입니다. Flink App을 통해 이벤트를 받아 유저 프로필 DB, 온라인 상태 DB 등 API 서버 구현 시 필요한 데이터베이스로 만들어내기도 하고, 모델 추론에 필요한 피쳐를 계산하여 in-memory store에 미리 저장해두기도 합니다. 덕분에 추천 API 서버에서는 타 마이크로서비스의 API 요청 필요 없이, 팀에서 관리 중인 데이터베이스에만 접근하여도 모든 비즈니스 로직을 수행할 수 있습니다.
2. 모델 추론에 필요한 input feature를 준 실시간으로 계산할 수 있어야 함
다음으로 모델 input feature의 계산 시간이 문제가 될 수 있습니다. 만약 추천 API 서버에 요청이 왔을 때 adhoc 하게 모델 추론을 위한 input feature를 계산한다면, 데이터 로드 및 처리에 상당히 오랜 시간이 걸려 응답 시간이 매우 느려질 수 있습니다. 대신에 저희는 계산하는 데 오래 걸리는 피쳐들에 대해 Flink App을 이용하여 비동기로 계산하는 방식을 사용하고 있습니다. API 요청이 왔을 때가 아닌, 이벤트가 발행되었을 때 미리 피쳐를 계산하는 것이죠. 덕분에 저희의 추천 모델들이 수십 개 이상의 피쳐를 사용함에도 불구하고, 동시에 수 백 개 이상의 item이 담긴 추천 리스트에 대한 요청도 수십~수백 밀리 초안에 처리하고 있습니다.
3. 여러 머신러닝 모델을 실시간으로 추론할 수 있어야 함
여러 머신러닝 모델을 실시간으로 추론할 수 있어야 하는 문제는 사내 ML Serving Platform을 통해 해결하고 있습니다. 하이퍼커넥트에서는 수년간 Machine Learning 모델을 실제 서비스에서 운영해가며 쌓은 노하우를 바탕으로 사내 ML Serving Platform를 운영 중이며, 정말 빠르게 새로운 머신러닝 모델들을 배포할 수 있습니다. 모델들은 kubernetes pod으로 배포되어 auto-scale 되도록 설정이 되어있으며, Nvidia Triton과 같은 기술을 통해 throughput과 latency 모두를 챙기고 있기도 하죠. 더 자세한 내용은 ML Platform 팀에서 Machine Learning Software Engineer로 일하고 계신 이승우 님이 Deview 2021에서 발표하신 어떻게 더 많은 모델을 더 빠르게 배포할 것인가?를 참고해 주시면 좋을 것 같습니다.
4. Scalability를 보장해야 함
추천 API 서버와 Flink App은 stateless 하게 작성되어 scalability를 보장하고 있습니다. 또 이들은 kubernetes pod으로 배포되어 auto-scaling 되도록 설정이 되어있습니다. 데이터베이스 또한 Key-value store인 Redis와, 분산 데이터베이스로 설계된 ScyllaDB를 사용하여 충분히 scalable 한 시스템을 가지고 있습니다. 머신러닝 모델 또한 stateless 하면서 auto-scaling이 설정된 컴포넌트로, 모든 구성 요소가 확장 가능한 구조를 가지고 있습니다.

그림 7. Grafana를 통해 모니터링 되고 있는 하이퍼커넥트의 실시간 추천 시스템. 모든 요청에 대해 실시간으로 모델 추론을 하고 있음에도 대부분의 요청을 수십~수백 ms 안에 처리하고 있으며, auto-scaling 을 통해 트래픽 변화에 유연하게 확장 가능한 구조를 갖고 있음.
맺으며
이 포스트에선 라이브 스트리밍 추천 시스템에서 이벤트 주도 아키텍처의 효과에 대해서 소개해 드렸습니다. 또 라이브 스트리밍 추천 시스템을 개발하며 겪었던 다양한 엔지니어링 challenge와 해결 방안들도 함께 보여드렸죠. 하지만, 위와 같은 문제 말고도 이벤트 기반의 추천 시스템을 운영하면 겪게 되는 어려움에는 더 많은 것들이 있습니다. 대표적으로 이벤트 기반의 어플리케이션은 이벤트의 발생 순서와 처리되는 순서가 다를 수 있기 때문에 트랜잭션 처리를 더 잘 해줘야 하고, 또 서비스에 장애가 생겨도 fault tolerant 하게 동작할 수 있게끔 꼼꼼하게 예외 처리를 해주어야 합니다. 또 피쳐 계산 로직의 구현 차이로 인해 실시간으로 계산되는 피쳐와 학습용으로 생성되는 오프라인 피쳐가 달라지는 문제가 발생할 수도 있습니다 [6]. 이런 문제를 해결하기 위해 feature distribution analyzer나 shared feature encoder, 혹은 feature store와 같은 컴포넌트 등을 고려해야 하는 순간도 오게 됩니다. 그리고 이런 컴포넌트를 도입하는 과정에서도 새로운 challenge를 맞이하게 되죠.
또한 이 포스트에선 엔지니어링 관점에서 하이퍼커넥트의 실시간 추천 시스템에 대해 소개해 드렸지만, 모델링 관점에서도 다양한 challenge가 존재합니다. 예를 들어 모델의 배포 주기를 어떻게 더 단축시킬 것인지, 또 오프라인 정확도를 넘어서 온라인 환경에서의 정확도를 어떻게 높일 수 있을지 같은 고민들이 포함됩니다. 더 좋은 모델을 만들기 위한 고민들은 말할 것도 없죠. 하이퍼커넥트에서는 이런 문제들을 풀기 위해 Kubeflow 및 사내 ML Serving Platform을 통해 데이터 수집 - 학습 - 테스트 - 배포로 이어지는 파이프라인을 더 쉽게 구성할 수 있게 하고 있으며, 머신러닝 모델을 사용하는 많은 서비스에서 A/B 테스팅을 적극적으로 이용하여 모델에 대한 온라인 환경에서의 성능 테스트도 수행하고 있습니다. 비전 모델과 같은 다양한 기술을 사용하여 성능을 더 높이기 위한 시도도 하고 있구요.
머신러닝을 프로덕션에 적용하다 보면 정말 다양한 문제들을 마주하게 됩니다. 저희는 다양한 문제들을 각 상황에 맞는 efficient한 방법으로 풀어나가고 있습니다. 저희는 빠르게 문제를 정의하고 해결책을 제안할 수 있는 엔지니어가 머신러닝을 통해 비즈니스에 임팩트를 낼 수 있다고 믿으며, 하이퍼커넥트 AI Lab에서는 이런 문제들을 함께 풀어나갈 ML Engineer와 ML Software Engineer를 꾸준히 채용하고 있으니 많은 지원 부탁드립니다.
References
[2] https://www.redhat.com/ko/topics/microservices
[3] https://medium.com/dtevangelist/event-driven-microservice-란-54b4eaf7cc4a
[4] https://medium.com/trendyol-tech/event-driven-microservice-architecture-91f80ceaa21e
Read more
-
ksqlDB를 이용하여 실시간 ML 피쳐 데이터를 계산하기
카프카에서 제공하는 ksqlDB를 사용하여 실시간 피쳐 데이터를 계산하고 사용하는 방법을 공유합니다. -
고성능 ML 백엔드를 위한 10가지 Python 성능 최적화 팁
다량의 데이터를 사용하는 ML 워크로드에 특화된 최적화 기법들과, ML 백엔드에서 자주 사용되는 third-party 라이브러리를 효과적으로 사용하는 방법들을 실제 하이퍼커넥트의 사례와 함께 공유합니다. -
머신러닝 어플리케이션을 위한 데이터 저장소 기술
머신러닝 어플리케이션의 데이터 사용 패턴을 분석하고, 데이터 사용 패턴에 적합한 데이터 저장소엔 어떠한 것들이 있는지에 대해서 소개합니다.