ksqlDB Deep Dive
안녕하세요, Azar API Dev Team의 Dante.R 입니다.
이 글에서는 Kafka Streams 및 ksqlDB 의 동작 원리 및 ksqlDB 의 사용 예제를 공유합니다.
ksqlDB 란?
ksqlDB 는 카프카 기반의 Event Streaming 기능을 지원하는 자바 라이브러리인 Kafka Streams 를 기반으로 만들어진 Event Streaming SQL Engine 입니다.[1]
자바 코드로 Event Streaming 기능을 사용하는 Kafka Streams 와 달리 ksqlDB 는 SQL 을 기반으로 스트림을 생성하고 처리할 수 있습니다. Kafka Streams 를 활용하려면 ‘애플리케이션 개발, 배포 인프라 구축 등’ 다양한 부분을 신경써야 하지만, ksqlDB 는 다른 부분을 신경쓰지 않고 SQL 을 사용해 바로 이벤트 스트림을 활용할 수 있다는 점에서 엄청난 생산성을 제공합니다.
ksqlDB 를 사용하면 KStream, KTable, GlobalKTable 과 같은 Stream 과 현재 상태를 snapshot 으로 제공하는 Materialized View 를 생성할 수 있습니다.[2]
ksqlDB 의 필요성
카프카는 실시간으로 이벤트 처리를 할 수 있는 매우 강력한 Event Streaming Platform 입니다. 카프카의 실시간성 및 내결함성이 증가함에 따라 많은 회사들이 ‘이벤트 기반 아키텍처(Event-Driven Architecture)’ 로 애플리케이션을 구성하고 있습니다.[3]
이벤트는 각 애플리케이션에서 ‘현재 상태’ 를 전달하기 때문에 데이터를 분석하거나 특정 값을 기준으로 전체 이벤트 플로우를 추적하는데 어려움이 있습니다. 하지만 이벤트를 변환 혹은 join 함으로써 전체 플로우를 확인할 수 있습니다.
예를 들어 인터넷 쇼핑몰에서 유저가 주문을 하는 경우 애플리케이션에서 ‘주문’ 이벤트를 발행하고, 결제를 하는 경우 ‘결제’ 이벤트를 발행한다면 전체 플로우를 한 번에 확인하기 어렵습니다. 하지만 ksqlDB 를 활용하면 두 이벤트를 join 해 유저의 주문이 정상적으로 결제가 되었는지 혹은 결제가 실패했는지 등 전체 플로우를 확인할 수 있습니다.
Kafka Streams 의 동작 원리
ksqlDB 설명에 앞서, 기반 기술이 되는 Kafka Streams 의 동작원리에 대해 알아보겠습니다.
Kafka Streams 은 아래 그림처럼 Kafka Conumser 를 통해 이벤트 레코드를 consume 하고, 각 레코드를 파티션에 따라 특정 StreamTask 에 할당해 이벤트 스트림 처리를 합니다. StreamTask 는 Kafka Streams 내에서 사용하는 가장 작은 작업 단위로, 처리하는 이벤트 중 가장 큰 파티션 수만큼 할당 됩니다.[4]
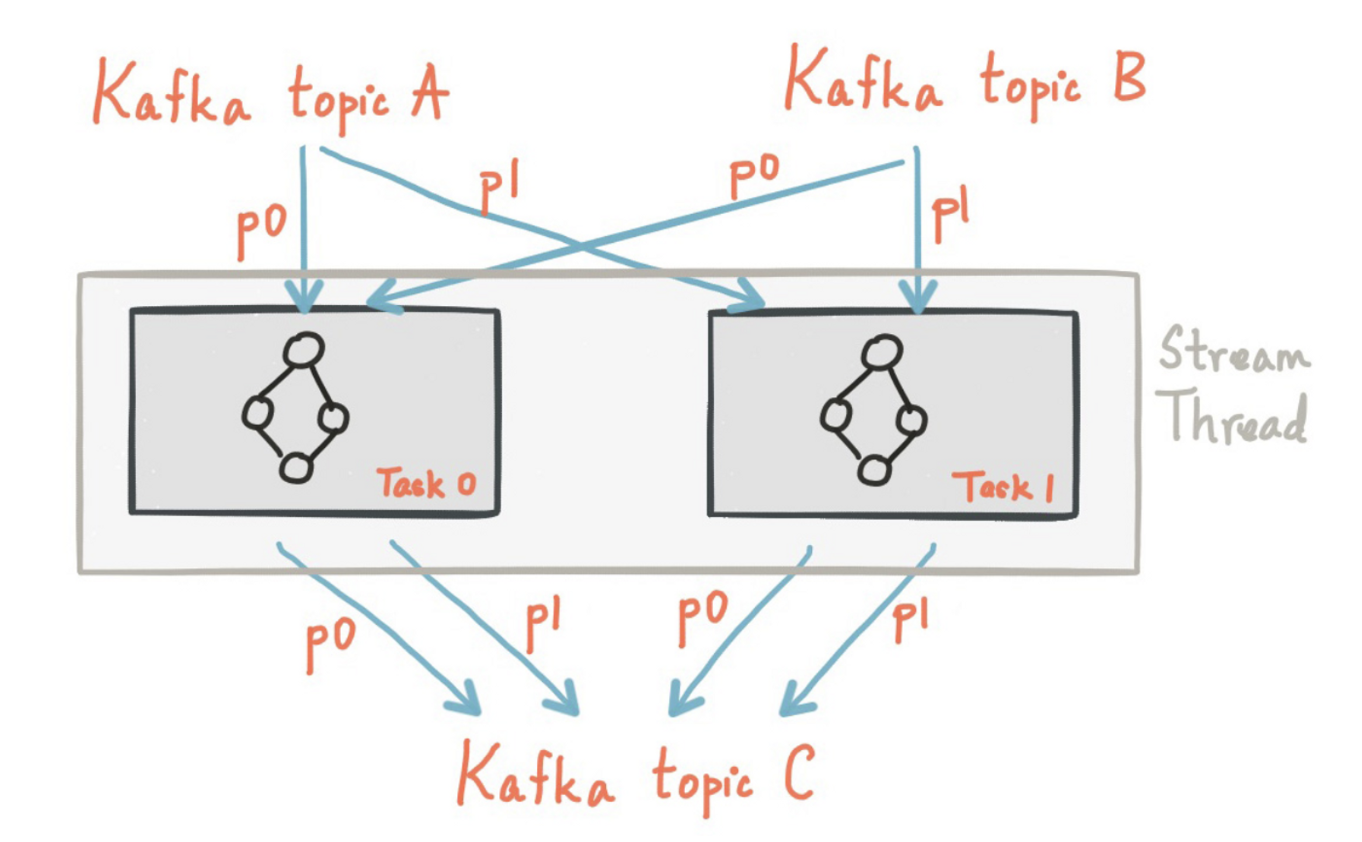
위 과정을 코드 레벨에서 보면 아래와 같습니다.[5]
- Stream Thread 가 Kafka Consumer 를 통해 레코드를 consume 합니다.
- Polling 한 레코드를 StreamPartitionAssignor 가 metadata 를 활용해 activeTask 를 생성하고, TaskManager 는 이를 활용해 StreamTask 를 생성합니다.
@Override public void onAssignment(final Assignment assignment, final ConsumerGroupMetadata metadata) { final List<TopicPartition> partitions = new ArrayList<>(assignment.partitions()); partitions.sort(PARTITION_COMPARATOR); // Get activeTasks, standByTasks, activeAndStandbyHostPartitions information through userData by version final AssignmentInfo info = AssignmentInfo.decode(assignment.userData()); if (info.errCode() != AssignorError.NONE.code()) { // set flag to shutdown streams app assignmentErrorCode.set(info.errCode()); return; } ... switch (receivedAssignmentMetadataVersion) { // The internal implementation is slightly different depending on receivedAssignemtMetadataVersion , but the overall sequence is the same. ... // Validate whether the number of activeTasks and partitions obtained from info are the same validateActiveTaskEncoding(partitions, info, logPrefix); // create StreamTask activeTasks = getActiveTasks(partitions, info); partitionsByHost = info.partitionsByHost(); standbyPartitionsByHost = info.standbyPartitionByHost(); topicToPartitionInfo = getTopicPartitionInfo(partitionsByHost); encodedNextScheduledRebalanceMs = info.nextRebalanceMs(); break; } // If rebalance is needed for reasons such as version change, new host, etc., schedule it in advance maybeScheduleFollowupRebalance( encodedNextScheduledRebalanceMs, receivedAssignmentMetadataVersion, latestCommonlySupportedVersion, partitionsByHost.keySet() ); final Cluster fakeCluster = Cluster.empty().withPartitions(topicToPartitionInfo); streamsMetadataState.onChange(partitionsByHost, standbyPartitionsByHost, fakeCluster); // we do not capture any exceptions but just let the exception thrown from consumer.poll directly // since when stream thread captures it, either we close all tasks as dirty or we close thread taskManager.handleAssignment(activeTasks, info.standbyTasks()); } - StreamTask 를 Stream Thread 에 할당
static Map<String, List<TaskId>> assignTasksToThreads(final Collection<TaskId> tasksToAssign, final boolean isStateful, final SortedSet<String> consumers, final ClientState state, final Map<String, Integer> threadLoad) { final Map<String, List<TaskId>> assignment = new HashMap<>(); for (final String consumer : consumers) { assignment.put(consumer, new ArrayList<>()); } final int totalTasks = threadLoad.values().stream().reduce(tasksToAssign.size(), Integer::sum); // Calculate the minimum tasks to be assigned per thread // more than one StreamTask can be assigned to one Stream Thread final int minTasksPerThread = (int) Math.floor(((double) totalTasks) / consumers.size()); final PriorityQueue<TaskId> unassignedTasks = new PriorityQueue<>(tasksToAssign); // First assign tasks to previous owner, up to the min expected tasks/thread if these are stateful // Next interleave remaining unassigned tasks amongst unfilled consumers // assign unassigned tasks yet if (!unassignedTasks.isEmpty()) { ... } // Update threadLoad for (final Map.Entry<String, List<TaskId>> taskEntry : assignment.entrySet()) { final String consumer = taskEntry.getKey(); final int totalCount = threadLoad.getOrDefault(consumer, 0) + taskEntry.getValue().size(); threadLoad.put(consumer, totalCount); } return assignment; }
Kafka Streams 의 stateful 동작
Kafka Streams 는 ‘stateless’ 와 ‘stateful’ 두 가지 유형의 Stream 이 존재합니다.
stateless 란, 현재 상태에만 의존적인 Stream 을 의미합니다. 예를 들어, Stream 을 특정 필드 조건을 기준으로 필터링을 하거나 특정 필드를 조작하는 것과 같이 현재 값을 기준으로 Stream 을 처리할 수 있는 형태입니다. stateful 이란, 이전 상태에 의존적인 Stream 을 의미합니다. 예를 들어, 특정 윈도우 내의 Stream 들을 join 하거나 집계를 하는 것과 같이 이전 값을 알아야 처리할 수 있는 형태입니다.
Kafka Streams 는 아래 그림처럼 로컬 저장소인 ‘State Store’ 를 사용해 stateful 한 Stream 을 처리합니다. 원격 저장소가 아닌 로컬 저장소를 사용하는 이유는 수백만 ~ 수십억개의 Stream 을 다뤄야 할 수 있는 Kafka Streams 의 특성상 네트워크 통신에 의한 지연도 성능적으로 크리티컬할 수 있기 때문입니다.
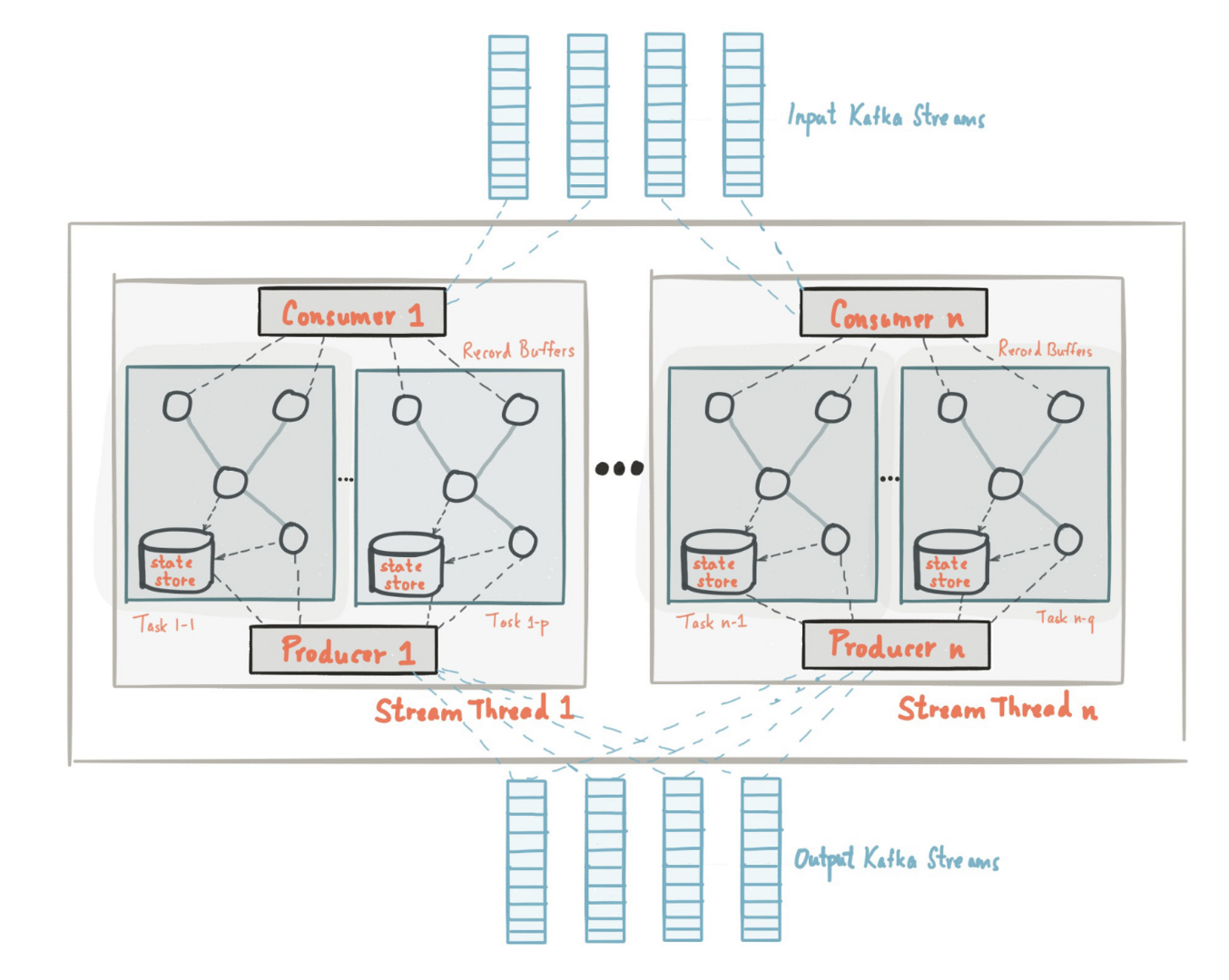
State Store 로 사용하는 저장소는 RocksDB 인데, 이를 사용하는 이유는 다음과 같습니다.
- 가용성이 낮지만, 매우 빠르다는 장점을 가집니다.
- big data 를 처리하기 위해 만들어져, Kafka Streams 와 같이 엄청난 수의 데이터를 저장하는데 적합합니다.
- 분산 스토리지가 아니라는 단점을 가지고 있지만, 고성능의 I/O 를 필요로 하고 big data 를 저장해야 하며 로컬 저장소의 역할만 하면 되는 Kafka Streams 에 적합합니다.
Kafka Streams 의 리밸런싱
Kafka Streams 의 Consumer group 은 애플리케이션의 scale 혹은 fault 시나리오 발생 시 리밸런싱이 일어날 수 있습니다. 로컬 저장소를 사용하는 Stream 은 리밸런싱이 발생하면 문제가 발생할 수 있습니다. 이를 해결하기 위해 각각의 로컬 저장소는 WAL(Write-Ahead Log) 방식으로 변경 로그 파일로 저장하고 해당 파일을 Checked Point File 이라 합니다.
만약 해당 파일이 존재하지 않으면 카프카 토픽을 earliest 부터 재생하여 기존 State Store 를 복구할 수 있습니다.[6] 해당 파일이 존재한다면 Checked Point Offset 이후의 카프카 토픽을 재생해 기존 State Store 를 복구합니다. 또한 Log compaction 과정을 통해 오래된 로그를 안전하게 저장할 수 있습니다.[7]
카프카 토픽을 재실행하여 장애 전 상태로 복구할 때까지 리밸런싱 상태가 유지되기 때문에 장애 상황이 오랜 시간 유지될 수 있습니다. 이를 최소화하기 위해 Kafka Streams 의 StreamsPartitionAssignor 는 Sticky 방식을 사용해 re-assign 이 필요한 파티션에 대해서만 해당 동작을 실행하게 합니다.
standby replica 인스턴스를 생성하는 경우, 로그 재실행을 하지 않아 장애 시간을 최소화할 수 있습니다. standby replica 는 완전한 복사본을 가지고 있기 때문에 장애가 발생한 task 를 추가 비용 없이 standby replica 로 re-assign 할 수 있습니다. standby replica 는 num.standby.replicas 파라미터를 통해 설정할 수 있습니다.
ksqlDB 아키텍처
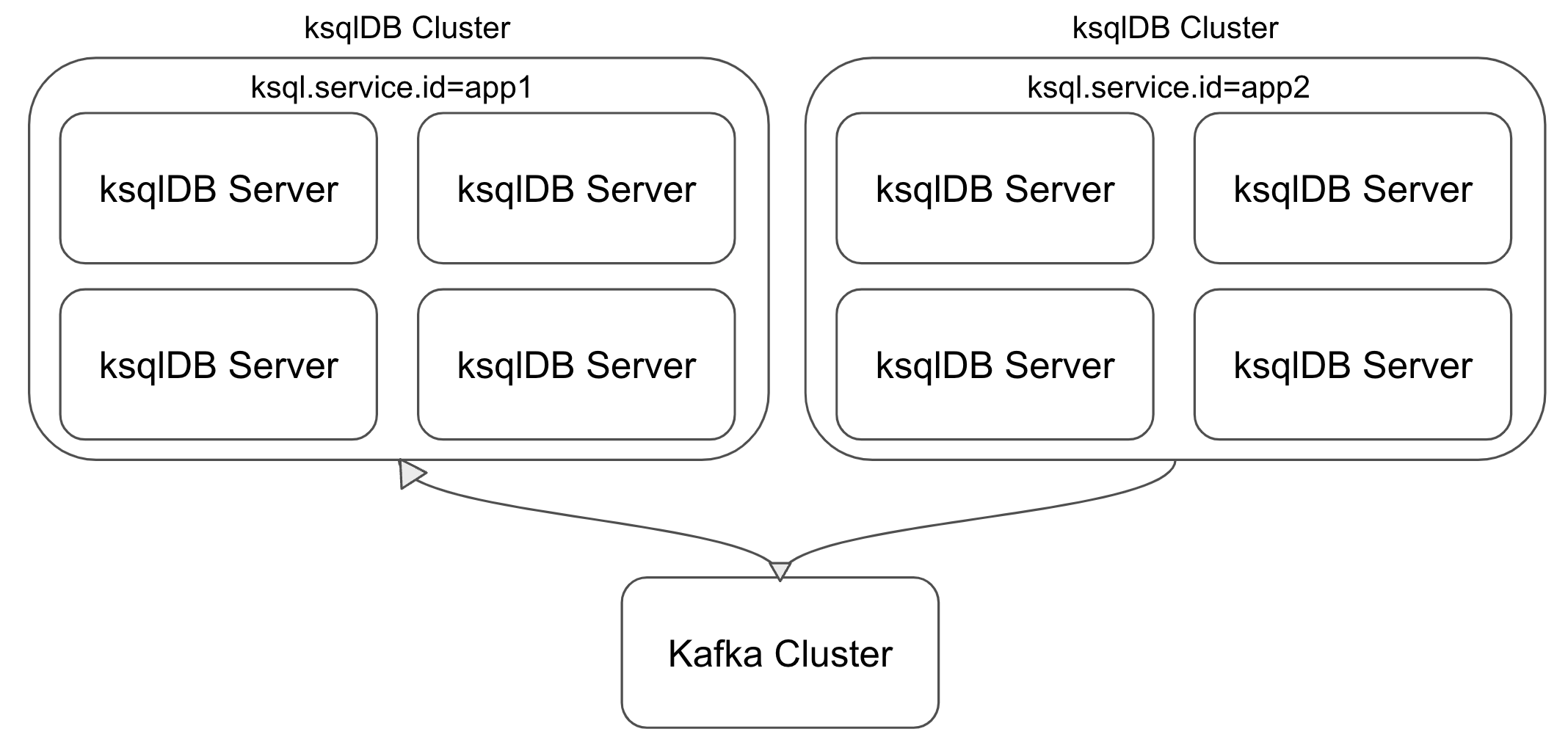
ksqlDB 는 여러 개의 서버로 구성되고, 이들은 ksql.service.id 를 기준으로 하나의 ‘클러스터’ 를 형성합니다. 클러스터 내부의 각 서버는 Kafka Streams Application 의 단일 인스턴스와 대응되고, workload (= querySet) 은 서버에 분산되는 형태로 구성됩니다.
Confluent 에서 추천하는 ksqlDB 의 구성방식은 workload 마다 ‘독립된’ 클러스터를 구축하는 것입니다. 독립된 클러스터를 추천하는 이유는 아래와 같습니다.
- 하나의 클러스터 내부에서 여러 개의 workload 가 동작한다면 이들은 resource 를 공유하게 됩니다. 이로 인해 특정 workload 가 greedy 하다면 다른 workload 가 충분한 resource 를 받지 못하는 문제가 발생할 수 있습니다.
- failover 혹은 replication 전략을 독립적으로 가져갈 수 있습니다.
- 특정 클러스터의 capacity 를 늘리고 싶다면 ksql.service.id 인스턴스 수를 늘려주면 되기 때문에 scale 전략을 독립적으로 가져갈 수 있습니다.
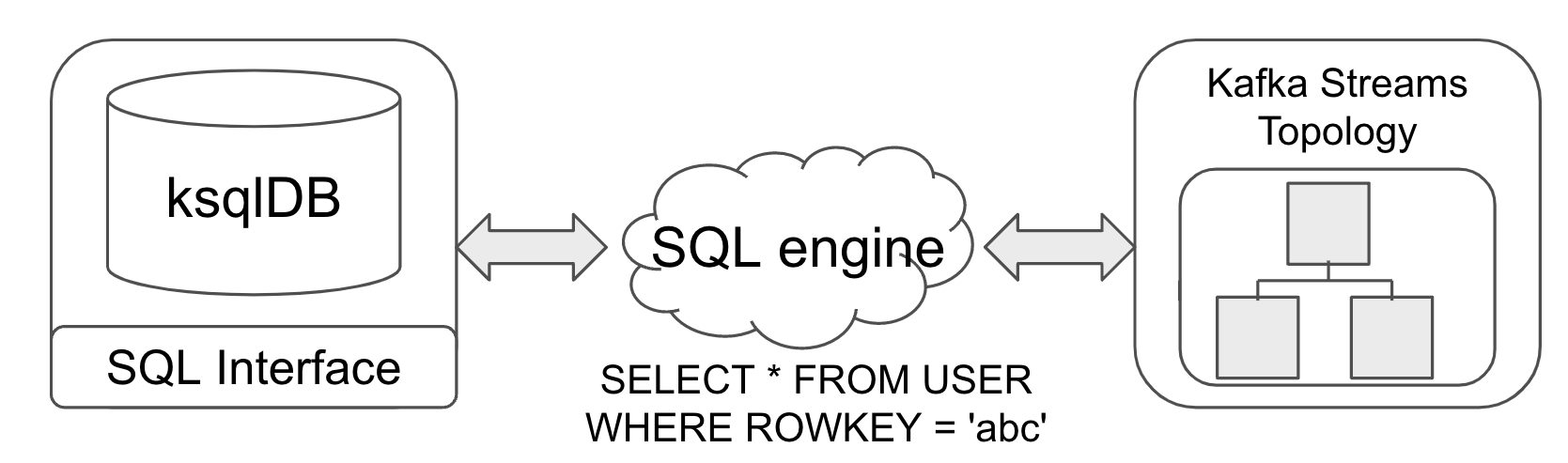
SQL Engine 은 CLI, Web UI 와 같은 클라이언트를 통해 입력된 SQL 구문을 사용해 Kafka Streams Topology 를 생성하고, 동작을 자바 코드로 변환합니다.
예를 들어 아래 그림과 같은 SQL 구문을 실행하면, Kafka Streams Topology 를 생성하고 WHERE 절을 Filter 절로 변환합니다.
ksqlDB 쿼리 타입
ksqlDB 는 Push Query 와 Pull Query 두 가지 타입의 쿼리가 존재합니다. 이처럼 두 가지 타입의 쿼리가 존재하는 이유는 ksqlDB 는 일반적인 RDBMS 와는 달리 ‘무한히 생성될 수 있는 연속된 스트림’ 을 반환하는 쿼리도 지원해야 하고, 일반적인 RDBMS 처럼 현재 상태를 기준으로 결과를 반환하는 쿼리도 지원해야 하기 때문입니다.
Push Query
전자처럼 연속된 Stream 을 반환하는 쿼리를 Push Query 라 합니다. SELECT 구문을 통해 Stream 을 쿼리했을 때 결과는 카프카 토픽으로 저장되는 것이 아니라 단순히 console 에 print 하는 것입니다.
그렇다면 Push Query 는 어떻게 연속된 Stream 결과를 반환할 수 있을까요? ksqlDB 내부 구현을 확인하면 WebSocket 을 통해 연속적으로 쿼리 결과를 받고 있는 것을 확인할 수 있습니다.
@Override
public synchronized void subscribe(final Flow.Subscriber<Collection<StreamedRow>> subscriber) {
final PushQuerySubscription subscription =
new PushQuerySubscription(exec, subscriber, queryMetadata);
log.info("Running query {}", queryMetadata.getQueryId().toString());
queryMetadata.start();
final WebSocketSubscriber<StreamedRow> webSocketSubscriber =
(WebSocketSubscriber<StreamedRow>) subscriber;
webSocketSubscriber.onSubscribe(subscription, metricsCallbackHolder, startTimeNanos);
}
예를 들어 STREAM_ORDER 라는 Stream 을 Push Query 를 사용해 쿼리하고 싶으면 아래처럼 SQL 구문을 작성하면 됩니다.
SELECT * FROM STREAM_ORDER EMIT CHAGES;
Push Query 는 EMIT CHAGES 혹은 EMIT FINAL 구문을 쿼리의 마지막에 붙여줘야 합니다. EMIT CHANGES 를 사용하면 Stream 의 변경 사항들을 연속적으로 반환하는 것이고, EMIT FINAL 은 아래에서 설명할 ‘windowed aggregation’ 에서만 사용할 수 있습니다. 이를 사용하면 ‘마지막’ 윈도우의 결과를 반환해줍니다.
Pull Query
후자처럼 현재 상태를 기준으로 결과를 반환하는 쿼리를 Pull Query 라고 합니다. Pull Query 는 KStream 이나 KTable 과 같은 Stream 에서는 사용할 수 없고, Materialized View 에서만 사용할 수 있습니다.
Pull Query 는 ‘JOIN’, ‘PARTITION BY’, ‘GROUP BY’, ‘WINDOW’ 와 같은 현재 테이블 상태를 변경하는 쿼리를 지원하지 않습니다. 하지만 Materialized View 를 생성할 때 위 기능들을 지원합니다. 한 번 생성한 Materialized View 에서 해당 기능을 사용해 Pull Query 를 사용할 수 없기 때문에 ‘반드시’ 쿼리 패턴에 맞게 Materialzied View 를 생성해야 합니다.
예를 들어 VIEW_ORDER 라는 Materialized View 를 Pull Query 를 사용해 쿼리하고 싶으면 아래처럼 SQL 구문을 작성하면 됩니다. Pull Query 는 반드시 파티셔닝의 기준이 되는 ‘KEY’ 를 기준으로 쿼리를 해야 합니다. 아래에서는 id 가 KEY 라고 가정을 하고 쿼리한 것입니다.
SELECT * FROM VIEW_ORDER WHERE id = 1;
ksqlDB 를 사용해 Stream, Table 생성
카프카에서 하나의 토픽을 정의할 수 있는 중요한 3가지 요소가 있습니다. 토픽명, 파티션 수, 그리고 레플리카 수 입니다. KStream 혹은 KTable 과 같은 Stream 에서도 해당 요소를 설정할 수 있습니다.
- 토픽명의 기본 값은 Stream 의 이름과 동일합니다.
- 파티션 수의 기본 값은 Stream 을 생성하는데 사용된 카프카 토픽 혹은 Stream 의 파티션 수와 동일합니다. 만약 변경하고 싶다면
WITH(PARTITIONS=3)구문을 사용해 설정하면 됩니다. - 레플리카 수의 기본 값은 1 입니다. 만약 변경하고 싶다면
WITH(REPLICA=3)구문을 사용해 설정하면 됩니다.
ksqlDB 를 사용해 KStream, KTable 을 생성하는 예제를 만들어보겠습니다. Stream 을 생성하기 위한 카프카 이벤트 ‘Order’ 는 아래처럼 생겼다고 가정하겠습니다.
data class Order(
val orderId: String,
val createdAt: Long,
val itemProducts: List<ItemProduct>
) {
data class ItemProduct(
val itemId: Long,
val itemName: String,
val count: Long
)
}
만약 Order 이벤트를 사용해 파티션 수가 3이고, 레플리카 수가 3인 KStream 혹은 KTable 을 생성하고 싶다면 아래처럼 SQL 을 작성하면 됩니다. ksqlDB 는 Array, Map 등 다양한 Collection 타입을 지원하고, typed structured data 를 사용자가 자유롭게 정의할 수 있습니다.
CREATE STREAM[TABLE] STREAM_ORDER (
`orderId` STRING,
`createdAt` BIGINT,
`itemProducts` ARRAY<STRUCT<
`itemId` BIGINT,
`itemName` STRING,
`count` BIGINT
>>
) WITH (KAFKA_TOPIC='order', KEY_FORMAT='AVRO', VALUE_FORMAT='AVRO', PARTITIONS=3, REPLICA=3);
ksqlDB 를 사용해 join / aggregate
co-partition 과 internal re-partition
Kafka Streams 의 동작원리를 봤을 때, join 혹은 aggregate 과 같은 stateful 한 Stream 처리를 하려면 연관된 모든 Stream 이 ‘반드시’ 동일한 파티션 정책을 가져가야 함을 알 수 있습니다. 동일한 파티션 정책을 가져가려면 ‘파티션 수’ 와 ‘KEY’ 가 반드시 동일해야 합니다.
하지만 아자르에서 ksqlDB 를 활용해 join 을 했을 때, 동일한 파티션 정책을 가져가지 않았음에도 불구하고 Stream 의 join 이 잘 되는 것을 확인할 수 있엇습니다. 우연히 join 이 잘 되는 것이라고 생각하기에는 모든 Stream 데이터가 정상적으로 join 이 되고 있어 이유를 알기 위해 ksqlDB 코드를 확인했습니다.
ksqlDB 코드를 확인한 결과 Stream join 을 하기 전 각 Stream 들의 파티션 정책이 다른 경우, 내부적으로 re-partition 을 함으로써 정상적으로 join 을 할 수 있었던 것이었습니다.
public SchemaKStream<K> selectKey(
final FormatInfo valueFormat,
final List<Expression> keyExpression,
final Optional<KeyFormat> forceInternalKeyFormat,
final Stacker contextStacker,
final boolean forceRepartition
) {
final boolean keyFormatChange = forceInternalKeyFormat.isPresent()
&& !forceInternalKeyFormat.get().equals(keyFormat);
final boolean repartitionNeeded = repartitionNeeded(keyExpression);
if (!keyFormatChange && !forceRepartition && !repartitionNeeded) {
return this;
}
if ((repartitionNeeded || !forceRepartition) && keyFormat.isWindowed()) {
throw new KsqlException(
"Implicit repartitioning of windowed sources is not supported. "
+ "See https://github.com/confluentinc/ksql/issues/4385."
);
}
final ExecutionStep<KStreamHolder<K>> step = ExecutionStepFactory
.streamSelectKey(contextStacker, sourceStep, keyExpression);
final KeyFormat newKeyFormat = forceInternalKeyFormat.orElse(keyFormat);
return new SchemaKStream<>(
step,
resolveSchema(step),
SerdeFeaturesFactory.sanitizeKeyFormat(
newKeyFormat,
toSqlTypes(keyExpression),
true),
ksqlConfig,
functionRegistry
);
}
사용자의 부주의로 파티션 정책을 설정하지 않아도 ksqlDB 가 내부적으로 re-partition 을 해줌으로써 정상적으로 join 할 수 있지만 의도와는 다르게 내부적으로 불필요한 re-partition 이 발생할 수 있으므로 항상 파티션 정책을 신경써서 join 을 하는 것이 좋습니다.[8]
또한 ksqlDB 가 항상 내부적으로 re-partition 을 해줄 수 있는 것이 아니기 때문에 파티션 정책을 직접 설정하는 것이 좋습니다. 예를 들어 아래와 같은 경우, re-partition 이 불가능합니다.
- KStream 과 KTable join 에서 Stream 은 re-partition 이 가능하지만, Table 은 re-partition 이 불가능합니다.
- KStream 과 KStream 혹은 KStream 과 KTable join 에서 Stream 의 Source 가 window 기반으로 생성되는 스트림이면 안 됩니다.
- KTable 의 join key column 이 2개 이상이면 안 됩니다.
Windowed Join
ksqlDB 는 특정 window 내에 속한 이벤트 Stream 을 join 할 수 있습니다. 각 이벤트를 기준으로 ‘n분 이전’ 부터 ‘m분 이후’ 까지와 같은 설정을 할 수 있습니다.
ksqlDB 를 사용해 STREAM_ORDER 와 STREAM_PAYMENT 를 join 하고 싶다면 아래처럼 SQL 구문을 작성하면 됩니다.
SELECT o.orderId, o.itemProducts, p.paymentId, p.isSucess
FROM STREAM_ORDER o
LEFT JOIN STREAM_PAYMENT p
WITHIN 1 HOURS [WITHIN 20 MINUTES, 40 MINUTES]
ON o.orderId = p.orderId
EMIT CHANGES;
WITHIN 구문을 사용해 join 에서 사용할 윈도우의 크기를 설정할 수 있습니다. 윈도우는 ‘n {timeUnit} 이전’ 부터 ‘m {timeUnit} 이후’ 형태로 생성이 됩니다.
n 과 m 값을 별도로 설정하지 않은 WITHIN 절을 사용한다면 ksqlDB 내부에서는 ‘n {timeUnit} 이전’ 부터 ‘n {timeUnit} 이후’ 까지 윈도우를 생성합니다. 만약 n 과 m 값을 다르게 설정하고 싶다면 위의 SQL 구문의 대괄호 부분처럼 다른 값을 직접 설정해야 합니다.
ksqlDB 코드를 확인한 결과 WITHIN 절을 생성할 때 사용한 파라미터에 따라 윈도우 설정을 한다는 것을 확인할 수 있었습니다.
public WithinExpression(final long size, final TimeUnit timeUnit) {
this(Optional.empty(), size, size, timeUnit, timeUnit, Optional.empty());
}
public WithinExpression(
final Optional<NodeLocation> location,
final long before,
final long after,
final TimeUnit beforeTimeUnit,
final TimeUnit afterTimeUnit,
final Optional<WindowTimeClause> gracePeriod
) {
super(location);
this.before = before;
this.after = after;
this.beforeTimeUnit = requireNonNull(beforeTimeUnit, "beforeTimeUnit");
this.afterTimeUnit = requireNonNull(afterTimeUnit, "afterTimeUnit");
this.gracePeriod = requireNonNull(gracePeriod, "gracePeriod");
this.joinWindows = createJoinWindows();
}
Windowed Aggregation
aggregation 을 했을 때 사용할 수 있는 Window 는 Tumbling Window, Hopping Window, Session Window 3가지가 존재합니다.
Tumbling Window 는 매 n {timeUnit} 마다 ‘고정된’ 윈도우를 생성해서 윈도우 내부에 존재하는 이벤트들을 aggregation 합니다.
Hopping Window 는 n {timeUnit} 의 고정된 윈도우 크기를 가지지만, ‘hop’ interval 기준으로 윈도우를 생성합니다. hop interval 의 설정에 따라 윈도우 간 겹치는 이벤트가 발생할 수 있어 주의해서 설정해야 합니다.
Session Window 는 n {timeUnit} 의 고정된 윈도우 크기를 가지지만, ‘inactivity gap’ interval 기준으로 윈도우가 존재하지 않는 구간을 추가해 윈도우를 생성합니다.
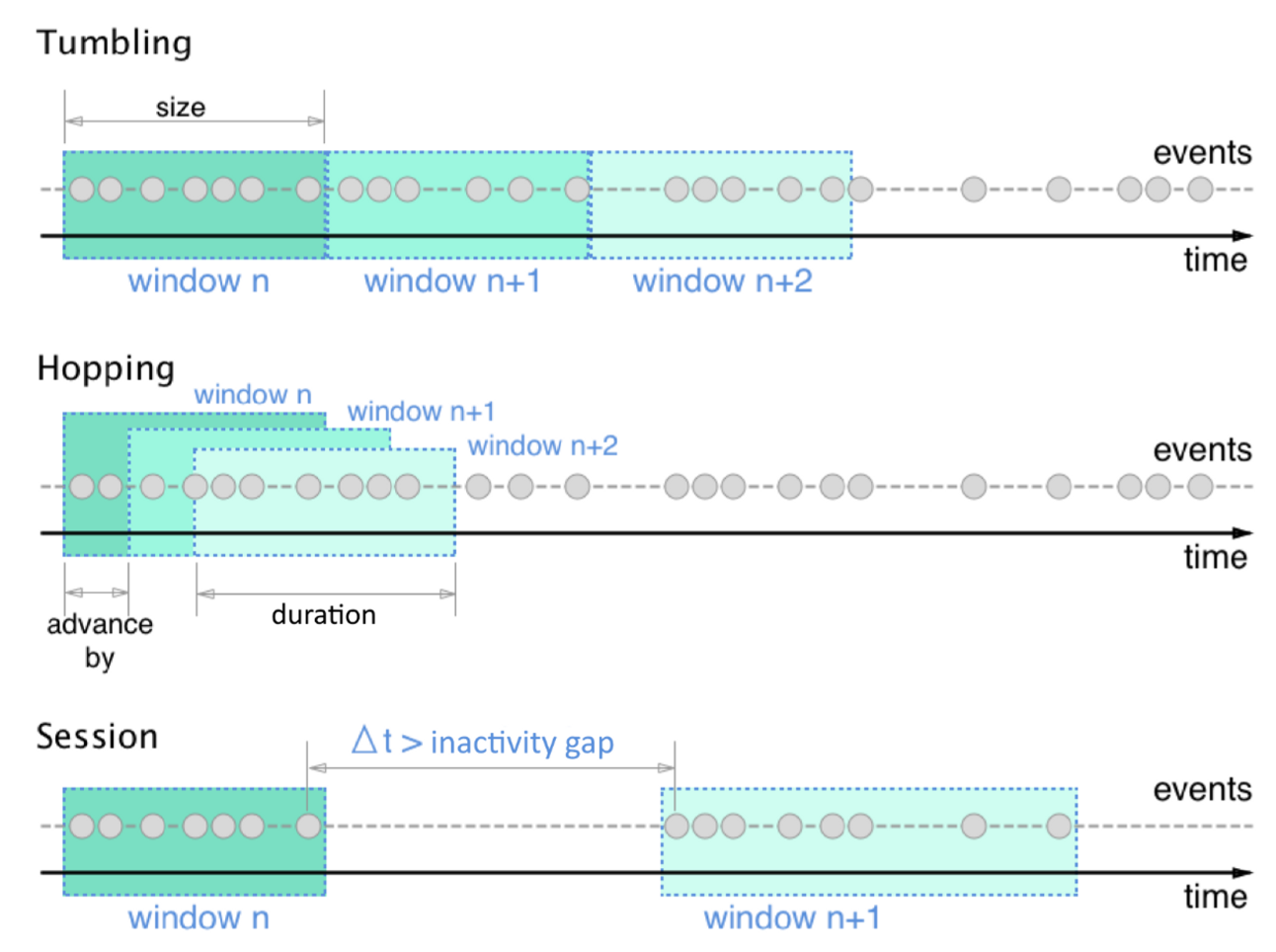
ksqlDB 를 사용해 STREAM_ORDER 를 window aggregation 하고 싶다면 아래처럼 SQL 구문을 작성하면 됩니다.
CREATE TABLE VIEW_ORDER AS
SELECT o.userId, COUNT(*) FROM STREAM_ORDER o
WINDOW TUMBLING (
SIZE 1 HOUR,
RETENTION 1 DAYS,
GRACE PERIOD 10 MINUTES
)
GROUP BY o.userId
WINDOW 구문을 사용해 윈도우를 생성할 수 있습니다. 윈도우를 설정할 때는 윈도우의 종류에 따라 약간 차이가 나지만 위 3개의 필드는 공통으로 들어갑니다.
SIZE 는 윈도우의 크기 및 timeUnit 을 설정합니다. RENTENTION 은 윈도우를 ‘남겨둘 시간’ 을 의미합니다. aggregate 된 결과를 남겨두는 시간으로 토픽의 리텐션 기간과는 완전 별개입니다. GRACE PERIOD 는 네트워크 상의 delay 에 의해 늦게 들어온 Stream 을 얼마나 기다려서 join 을 해줄지 결정합니다. ROWTIME 이 1시간 이내인 이벤트를 10분까지 더 기다려 aggregate 해줍니다.
윈도우 종류 및 3개의 필드를 적절히 사용함으로써, 원하는 형태로 window Aggregation 을 수행할 수 있습니다.
정리
오늘은 Kafka Streams 및 ksqlDB 의 동작 원리와 예제를 살펴보았습니다.
이처럼 ksqlDB 를 사용하면 별다른 설정 없이 간단하게 Stream Processing Application 을 작성할 수 있습니다.
카프카 기반의 Event Streaming Application 을 생성하고자 하는 분들께 도움이 되었으면 합니다.
Reference
[1] ksqlDB and Kafka Stremas
[2] 카프카 생태계 기반의 비즈니스 메트릭 생성하기
[3] Kafka usage
[4] StreamTask
[5] Kafka Streams Source Code
[6] State Store Checked Point Offset
[7] Kafka Streams fault tolerance
[8] ksqlDB inner re-partition
Read more
-
Spring Session + Custom Session Repository 기반 세션 저장소의 메모리 누수 해결
Spring Session + Custom Session Repository 를 사용할 때 발생한 메모리 누수 현상을 해결한 경험을 공유합니다. -
카프카 생태계 기반의 비즈니스 메트릭 생성하기
카프카 생태계를 기반으로 아자르에서 비즈니스 메트릭 생성한 경험을 공유합니다.