카프카 생태계 기반의 비즈니스 메트릭 생성하기
안녕하세요, Azar API Dev Team의 Dante.R 입니다.
이 글에서는 팀에서 Kafka Connect 와 ksqlDB 를 사용해서 Grafana 모니터링 대시보드를 구축한 경험을 공유합니다.
배경
아자르의 1:1 Video Chat은 유저가 새로운 사람을 화상으로 만나고 싶을 때 사용하는 기능입니다.
앱 내에서 유저들은 매치 필터 를 사용해 본인이 선호하는 특정 성별, 특정 국가의 유저와 Video Chat을 진행할 수 있습니다. 유저들이 언제 어떤 필터를 얼마나 사용했는지는 다양한 목적으로 사용되는 귀중한 데이터일 수 밖에 없겠죠.
기본적으로 아자르에서는 긴 기간에 대한 복잡한 다양한 조건을 사용하는 고도화된 분석과 모니터링은 Google의 Bigquery 콘솔, 그리고 별도로 구성된 Tableau 대시보드를 기반으로 진행하고 있습니다.
하지만 백엔드 서비스 운영을 위해서는 실시간으로 유저들의 기능 사용에 문제가 없는지 확인할 필요가 있고, 현재 팀에서는 Grafana 를 이용해 실시간 모니터링 대시보드 환경을 구축하고 있습니다.
이 Grafana 대시보드를 이용해 유저들의 매치 필터 사용량을 모니터링하기 위해서는 어떤 작업들이 필요할까요?
아자르 비즈니스 메트릭 생성을 위한 플로우
현재 대시보드를 만들기 위한 데이터들은 다음과 같은 플로우를 통해서 구성되고 있습니다.
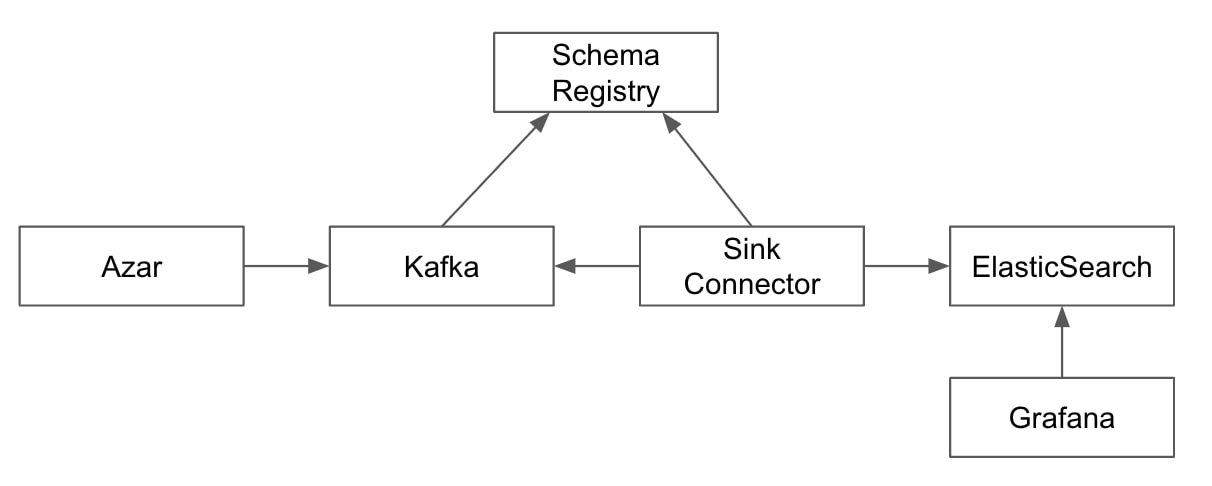
아자르 애플리케이션 이벤트
아자르에서는 CDC 플랫폼[1]을 기반으로 하는 영속성 계층 이벤트와, 서비스에서 직접 발행하는 애플리케이션 계층 이벤트의 두 형태의 이벤트를 발행하고 있습니다.
매치 필터 사용 현황을 모니터링 하기 위한 대시보드 구성에 사용할 데이터 소스로는 ‘요청’에 대한 이벤트를 사용하려고 합니다. 클라이언트에서 신규 Video Chat에 대한 요청이 들어오면 MatchRequestEvent 이벤트를 카프카로 발행하고 있습니다. 이 이벤트는 Production DB에 저장하는 영속성 정보가 아니기 때문에 애플리케이션 이벤트로 사용합니다.
data class MatchRequestEvent(
...
val filterSelections: List<FilterSelection>
...
) {
data class FilterSelection(
...
val filterId: String
...
)
}
Schema Registry 를 사용한 카프카 이벤트의 스키마 관리
아자르에서 발행하는 모든 카프카 이벤트는 Schema Registry 를 사용해 스키마를 관리합니다.
카프카 이벤트를 사용하는 경우, 이벤트 프로듀서와 컨슈머는 논리적으로 분리되어 상호 간의 의존성이 존재하지 않습니다. 하지만 프로듀서 혹은 컨슈머의 이벤트 스카마가 변경되는 경우, 직렬화 혹은 역직렬화에서 예외가 발생할 수 있습니다. 아키텍처 관점에서는 의존성을 갖지 않지만, 내부 구현 상에서는 상호간의 의존성을 갖게 됩니다.
이와 같은 문제를 해결하기 위해 아자르에서는 Schema Registry 를 도입했습니다. Schema Registry 를 사용하면, 스키마 버전관리 및 호환성 설정을 통해 각 이벤트의 스키마 규칙을 강제할 수 있습니다.
Schema Registry 에는 FORWARD_TRANSITIVE, BACKWARD_TRANSITIVE, FULL_TRANSITIVE, NONE 등 다양한 호환성 유형을 가지고 있습니다.[2]
- FORWARD_TRANSITIVE : 프로듀서에서 이벤트 스키마를 항상 먼저 변경하는 경우 사용하는 호환성의 한 종류입니다. 최신 버전의 이벤트 스키마를 사용하는 프로듀서에서 발행한 이벤트를 모든 이전 버전의 스키마를 사용하는 컨슈머에서 구독할 수 있습니다.
- BACKWARD_TRANSITIVE : 컨슈머에서 이벤트 스키마를 항상 먼저 변경하는 경우 사용하는 호환성의 한 종류입니다. 최신 버전의 이벤트 스키마를 사용하는 컨슈머에서 모든 이전 버전의 이벤트 스키마를 사용하는 프로듀서에서 발행하는 이벤트를 구독할 수 있습니다.
- FULL_TRANSITIVE : 퍼블리셔 혹은 컨슈머에서 모두에서 각각 스키마 변경을 하는 경우 사용하는 호환성의 한 종류입니다. 어떤 버전의 스키마를 사용하는 이벤트가 오더라도 구독할 수 있습니다.
- NONE : 이벤트 스키마 제약 조건을 사용하지 않을 때 사용하는 호환성 유형입니다.
MatchRequestEvent 와 같은 애플리케이션 이벤트는 프로듀서와 컨슈머에서 각각 스키마를 변경할 수 있기 때문에 FULL 호환성 사용을 권장하고, 그 중 모든 하위 버전에 대한 호환성을 보장하는 FULL_TRANSITIVE 유형을 사용합니다.
DevOps 팀에서 JulieOps 기반의 kafka-gitops 를 운영하고 있어 아래처럼 avsc 파일을 통해 schema 를 정의하면, CI/CD 파이프라인에서 새로 정의한 토픽이 자동으로 생성됩니다.
{
"type": "record",
"name": "MatchRequestEventMessage",
"namespace": "azar_api.match_request_event",
"fields": [
...
{
"name": "filterSelections",
"type": {
"type": "array",
"items": {
"type": "record",
"name": "FilterSelectionMessage",
"fields": [
...
{
"name": "filterId",
"type": {
"type": "string",
"avro.java.string": "String"
}
},
...
},
"java-class": "java.util.List"
}
}
...
]
}
Kafka Connect를 통해 이벤트를 ElasticSearch 에 적재
우리는 이렇게 발행된 이벤트들을 Grafana에서 데이터 소스로 사용할 ElasticSearch 로 보내려고 합니다.
일반적으로 ElasticSearch 는 전문 검색, 맞춤법 검사, 분석, 그리고 키-벨류 저장을 위해 사용됩니다.[3] 아자르에서는 전문 검색을 위한 ElasticSearch 와 메트릭 분석을 위한 ElasticSearch, 두 개의 ElasticSearch 를 운영하고 있습니다.
Kafka Connect 를 이용하면 쉽게 카프카 이벤트를 다른 데이터 소스에 적재할 수 있습니다.[4] 아자르 애플리케이션에서 카프카 이벤트를 사용하지 않고 직접 ElasticSearch 에 데이터를 적재할 수 있지만, Kafka Connect 를 통해 이벤트를 ElasticSearch 에 적재하고 있습니다.
Kafka Connect 를 통해 이벤트를 ElasticSearch 에 적재하는 이유는 아래와 같습니다.
- 높은 처리량을 요구하는 트래픽이 유입되었을 때 이를 안정적으로 ElasticSearch 에 저장할 수 있습니다. Kafka Connect 는 워커 노드에 분산 배치되어 있는 태스크들이 이벤트를 파티셔닝해 분산처리 하기 때문에 높은 처리량의 트래픽을 받을 수 있습니다. 또한, 파티셔닝 된 이벤트는 순차적으로 정렬되고 오프셋을 저장하기 때문에 Kafka Connect 에 장애가 나거나 실패가 발생하더라도 해당 지점부터 재처리할 수 있는 장점이 있습니다.
- 어떤 형태로 데이터를 저장할지에 대해 고민을 하지 않아도 됩니다. ElasticSearch Sink Connector 를 통해 ElasticSearch 에 데이터를 적재할 때, 이벤트의 토픽 명을 인덱스로 설정하고 이벤트의 필드들을 ElasticSearch 의 타입으로 저장합니다.
apiVersion: platform.confluent.io/v1beta1
kind: Connector
metadata:
name: metric-es-sink-match-request
namespace: confluent
spec:
name: metric-es-sink-match-request
connectClusterRef:
name: connect-confluenthub
class: "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector"
taskMax: 1
configs:
topics: "azar-api.api.match-request-event"
connection.url: "{elasticsearch_url}"
connection.compression: "true"
linger.ms: "50"
batch.size: "2000"
max.buffered.records: "10000"
max.retries: "20"
connection.timeout.ms: "5000"
read.timeout.ms: "30000"
flush.timeout.ms: "30000"
key.ignore: "true"
behavior.on.null.values: "IGNORE"
behavior.on.malformed.documents: "warn"
errors.tolerance: "all"
errors.log.enable: "true"
errors.log.include.messages: "true"
type.name: "_doc"
drop.invalid.message: "true"
write.method: "insert"
data.stream.type: "METRICS"
data.stream.dataset: "stream"
restartPolicy:
type: OnFailure
maxRetry: 1000
Grafana 를 통해 비즈니스 메트릭 읽어오기
현재 아자르에서는 Grafana 를 사용해 다양한 비즈니스 메트릭에 대한 대시보드를 운영하고 있습니다.
사실 ElasticSearch 를 데이터 소스로 사용하는 경우에는 같이 제공되는 Kibana 대시보드를 생성하는 경우가 일반적입니다. 그럼에도 아자르에서 Kibana 대시보드를 이용하지 않고 Grafana 를 사용하는 이유는 다음과 같습니다.
- 아자르에서는 ElasticSearch 뿐만 아니라 Prometheus, InfluxDB, CloudWatch 등 다양한 소스를 사용해 메트릭을 만들고 있습니다. 이러한 다양한 데이터 소스와의 연동을 Grafana가 더 용이하게 지원해주고 있습니다.
- Kibana 대시보드는 Xpack 이라는 유료 플랜을 사용해야 Alert 을 설정할 수 있지만 Grafana 는 이러한 연동을 기본적으로 제공한다는 비용상의 이점도 있습니다.
우리는 새로 만드는 대시보드를 이용해서 매치 필터의 사용량을 필터의 종류에 따라 그룹화하여 모니터링하고 싶습니다. 데이터 소스를 위에서 설정한 ElasticSearch 로 설정하고, 성별선택(filterId : ‘GENDER_CHOICE’) 필터의 시간에 따른 사용량 데이터를 확인해보겠습니다.
Data Source: ${stack}
Query : _index : metrics-stream-azar-api.api.match-request-event AND filterSelections.filterId : "GENDER_CHOICE"
Metric : Count
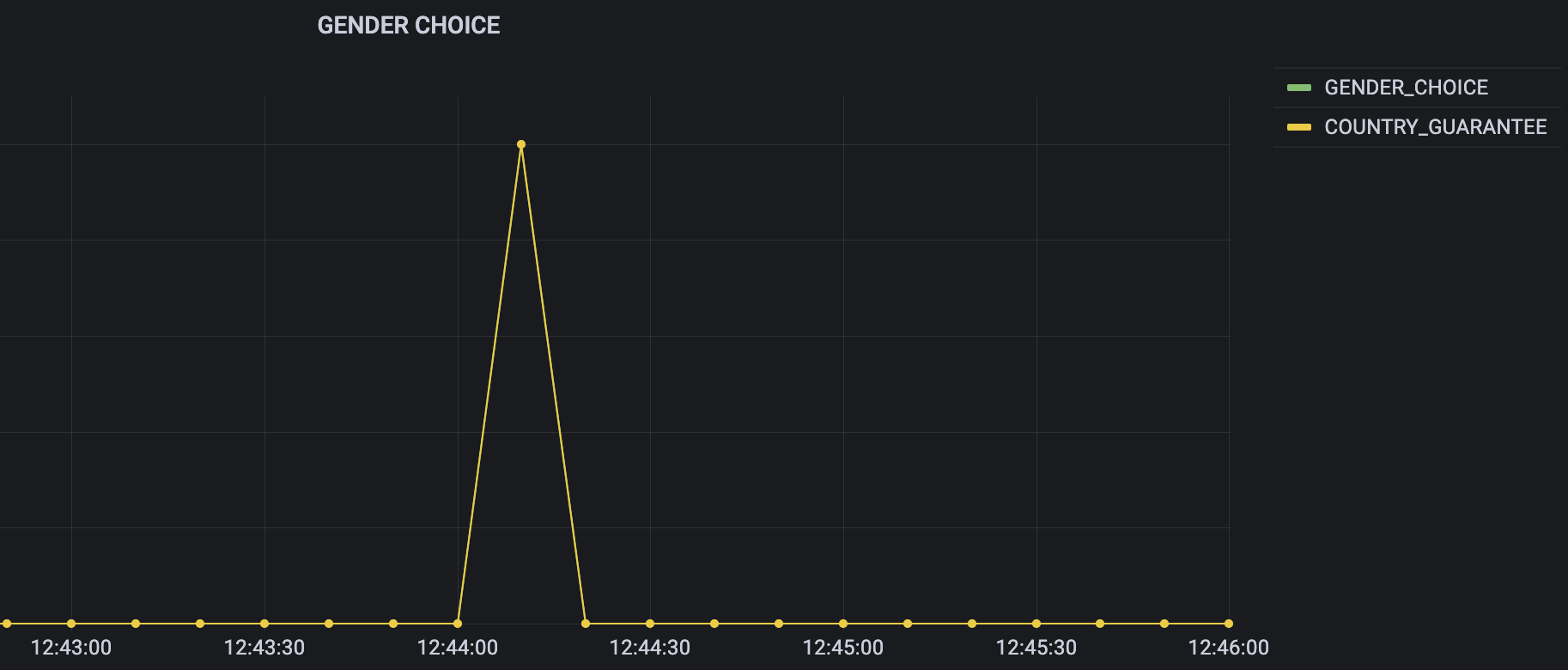
GENDER_CHOICE 타입에 대한 수치만 표시되는 것을 기대했지만 다른 필터 타입인 COUNTRY_GUARANTEE에 대한 수치도 불필요하게 같은 그래프에 기본적으로 표시되는 것을 확인할 수 있습니다.
이렇게 표시되는 원인은 데이터 소스인 ElasticSearch에서 원천 데이터를 document 단위로 가져오기 때문입니다. 동시에 여러 개의 매치 필터를 사용한 유저가 존재하는 경우 한 document에 여러 필터 정보가 존재하고, 성별 선택을 사용한 유저들 중 굳이 알고 싶지 않았던 다른 필터의 사용 수치도 그래프에 나타나게 되는 것이죠. 필요하지 않은 정보이고 분석시 혼동을 줄 수 있을 것 같습니다. 어떻게 해결할 수 있을까요?
해결 방안
가장 쉽게 해결하는 방법은 각 타입의 filter 에 대해서 이벤트 발행처에서 처음부터 분리해서 별도의 이벤트들을 발행하는 것입니다. 하지만 이런 해결책을 사용하는 것은 최대한 지양하고 싶습니다. 단순히 데이터 분석 편의성만을 위해 이벤트 구현을 바꾸는 것은 사용처의 방식을 고려하지 않고 발행하는 이벤트의 특성에 맞는 해법이 될수 없겠죠. 매치 필터의 종류가 늘어날 때마다 발행하는 이벤트의 개수가 선형적으로 증가하는 문제 또한 우려됩니다.
이러한 부분들을 고려해서 발행하는 서비스 어플리케이션의 코드를 수정하지 않고, 별도의 가공 파이프라인을 통해서 한 이벤트 안의 list를 분리해서 사용하기로 했습니다.
Kafka Streams vs ksqlDB
카프카 이벤트 스트림을 가공해서 새로운 이벤트 스트림(들)을 생성하는 방법은 여러 방식이 있겠지만, 여기서는 일반적으로 사용되는 Kafka Streams 와 ksqlDB 라는 두 가지의 기술을 고려했습니다. 실시간성이 중요한 비즈니스 메트릭의 특성에 알맞기 때문입니다.
이 기술들을 사용하면 필드 변경, 조인, 윈도우 등의 방식을 사용해서 주어진 이벤트 스트림을 실시간으로 가공하고 필요하다면 다른 데이터와 조인해서, 원하는 새로운 형태의 이벤트 스트림을 발행할 수 있게 됩니다.
팀 내부적으로는 ksqlDB를 사용하기로 했고, 두 기술에 대한 간단한 소개와 함께 선택한 이유에 대해서 설명드리겠습니다.
Kafka Streams
먼저 Kafka Streams 이란, 카프카 이벤트를 통해 KStream, KTable 그리고 GlobalKTable 이라는 세 가지 형태의 이벤트 스트림을 생성할 수 있는 자바 라이브러리 입니다.[5]
KStream 은 연속해서 들어오는 이벤트들을 가공하고, 새로 발급하는 이벤트의 스트림을 생성합니다.
KTable 은 이벤트의 현재 상태를 보여주는 스트림입니다. RDBMS 의 엔티티에 계속해서 upsert 를 하는 형태라고 생각하시면 됩니다.
GlobalKTable 은 KTable 과 유사하지만 모든 Kafka Streams 인스턴스에서 동일하게 replication 이 되는 KTable 입니다. KStream 과 KTable 을 조인하려면 co-partitioning 되어 있어야 한다는 제약이 있는 반면 GlobalKTable은 데이터가 모든 인스턴스에 replication 되기 때문에 co-partitioning 되지 않은 KStream 과 조인할 수 있다는 장점이 있습니다.
Kafka Streams 는 이러한 여러 형태의 이벤트 스트림들에 대한 생성, 가공, 새 토픽 발행, 그리고 Serialization을 직접 자바 코드 구현을 통해 지원하고 있습니다.
ksqlDB
ksqlDB 는 Kafka Streams 를 기반으로 만들어진 기술로, 자바 라이브러리가 아닌 SQL 문법을 기반으로 새로운 이벤트 스트림을 생성할 수 있게 도와줍니다.[6]
이러한 특성은 Kafka Streams 와 비교했을 때 다음과 같은 장점들을 가집니다.[7][8]
- 쿼리를 사용하기 때문에 이벤트 스트림에 대한 생성, 가공, 새 토픽 발행, 그리고 Serialization 을 각각 구현하지 않고 한 번에 해결할 수 있습니다.
- 단일 시스템에서 바로 카프카 커넥터를 붙여 사용할 수 있습니다.
- pull 쿼리를 사용해서 materialized view 를 생성할 수 있습니다.
이러한 압도적인 장점들 때문에 카프카 를 개발하는 Confluent 에서는 ksqlDB 에서 지원하지 않는 데이터 포맷이나 매우 복잡한 애플리케이션을 사용하는 경우를 제외하고는 ksqlDB 사용을 권장하고 있습니다. 하이퍼커넥트의 인프라실에서는 이미 ksqlDB 서버를 운영하고 있고, 현재 요구사항에서 필요한 로직이 비즈니스적으로 복잡한 연산이 아니라 단순한 원소의 flatten이였기 때문에 자연스럽게 ksqlDB 를 선택했습니다.
ksqlDB 를 적용한 1:1 Video Chat 메트릭 생성 플로우
이 내용을 반영한 새로운 메트릭 생성 플로우는 아래와 같습니다.
ksqlDB 은 기존에 발행하고 있는 이벤트 스트림을 중간에서 컨슘하고, 원하는 형태로 데이터를 가공한 새로운 이벤트 스트림을 다시 카프카로 발행해주는 역할을 수행합니다.
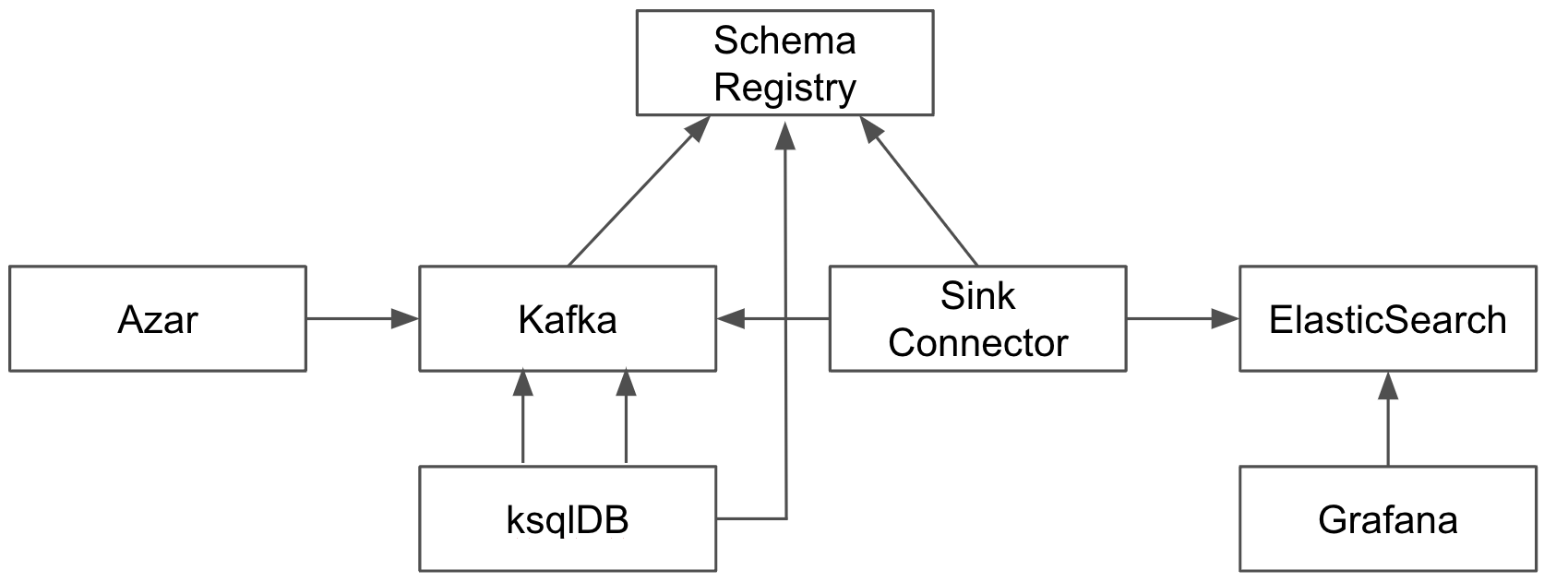
ksqlDB를 이용한 데이터 가공
ksqlDB를 이용하여 애플리케이션 이벤트 안에 있던 filterSelections 를 flatten 하고 각각의 필터 타입에 대해 이벤트를 재발행하는 것으로 필터별로 대시보드를 만들 수 있게 됩니다.
이를 위해 우리는 2개의 이벤트 스트림을 생성합니다.
- 애플리케이션 이벤트가 발행될 때마다 이 값을 ksql 로 사용하기 위한 input Stream
- 우리가 원하는 형태로 가공해서 flatten 한 event 를 다시 생성해서 내보내기 위한 output Stream
ksqlDB 는 데이터 스트림을 편리하게 조작할 수 있는 다양한 빌트인 함수들을 제공합니다.
빌트인 함수 중 하나인 EXPLODE 함수를 사용해 MatchRequestEvent 애플리케이션 이벤트의 filterSeleections 를 flatten 해서 각각의 필터 타입에 대한 이벤트를 재발행하고자 합니다. Java Stream API 에 익숙하신 분들은 flatMap 과 비슷한 기능이라고 생각하시면 이해가 쉽습니다.
CREATE STREAM AZAR_MATCH_REQUEST (
...
`FILTERSELECTIONS` ARRAY<STRUCT<
...
`filterId` STRING,
...
>
>>
) WITH (KAFKA_TOPIC='azar-api.api.match-request-event', KEY_FORMAT='AVRO', VALUE_FORMAT='AVRO');
CREATE STREAM AZAR_MATCH_FILTER_SELECTION WITH (KEY_FORMAT='AVRO', VALUE_FORMAT='AVRO') AS
SELECT
ROWKEY,
...,
EXPLODE(filterSelections) AS `filterSelection`
FROM AZAR_MATCH_REQUEST
EMIT CHANGES;
아래는 아자르 앱을 통해 1:1 Video Chat을 시도했을 때 발행하는 MatchRequestEvent 이벤트의 샘플 데이터입니다. filterSelections 는 유저가 사용한 매치 필터 정보를 list 형태로 담고 있습니다.
{
...,
"filterSelections": [
{
"filterId": "COUNTRY_GUARANTEE",
...
},
{
"filterId": "GENDER_CHOICE",
...
}
],
...
}
ksqlDB 를 적용했을 때, filterSelections 의 원소를 flatten 해서 각각의 필터 타입에 대해 새로운 이벤트들을 발행합니다.
{
...,
"filterSelection": {
"io.confluent.ksql.avro_schemas.KsqlDataSourceSchema_filterSelection": {
"filterId": {
"string": "GENDER_CHOICE"
},
...
}
},
...
}
{
...,
"filterSelection": {
"io.confluent.ksql.avro_schemas.KsqlDataSourceSchema_filterSelection": {
"filterId": {
"string": "COUNTRY_GUARANTEE"
},
...
}
},
...
}
위에서 봤던 Kafka Connect의 yaml 파일에서 컨슘 이벤트를 아래처럼 수정한다면, ElasticSearch Sink Connector 는 flatten 하게 발행되는 이벤트를 ElasticSearch 에 저장하게 됩니다.
apiVersion: platform.confluent.io/v1beta1
kind: Connector
metadata:
name: metric-es-sink-azar-match-filter-selection
namespace: confluent
spec:
name: metric-es-sink-azar-match-filter-selection
connectClusterRef:
name: connect-confluenthub
class: "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector"
taskMax: 1
configs:
topics: "AZAR_API_API_MATCH_FILTER_SELECTION"
...
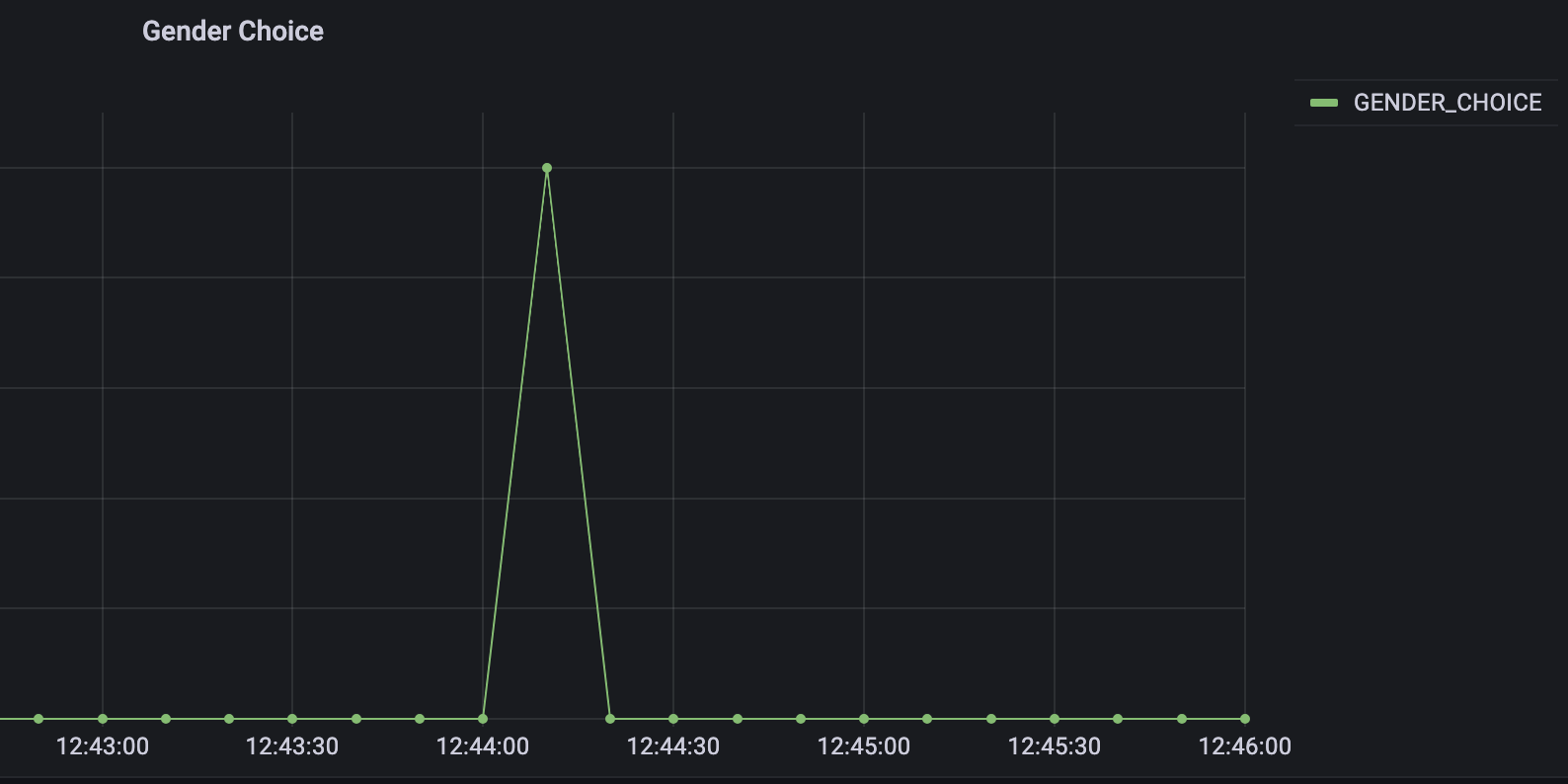
ksqlDB 를 통해 이벤트를 flatten 함으로써, 유저가 다양한 필터를 사용해 1:1 Video Chat을 진행하더라도 각각의 필터 사용에 대한 내용을 모니터링 할 수 있음을 확인할 수 있습니다.
마무리
오늘은 카프카 생태계를 기반으로 비즈니스 메트릭을 생성하는 방법과 적용, 문제해결 방안까지 살펴보았습니다.
이처럼 ksqlDB과 Kafka Connect를 사용하면 애플리케이션 수정 없이 이벤트를 메트릭에 적합한 형태로 가공하고, 기존에 구축되어 있는 메트릭 시스템에 쉽게 통합할 수 있습니다.
카프카를 사용하고, 메트릭을 생성하시려는 분들께 도움이 되었으면 합니다.
마지막으로 저희가 채용 중이라는 소식을 전하면서 글을 마칩니다.
🚀 Azar Matching Dev 채용공고 바로가기 🚀
Reference
[1] CDC & CDC Sink Platform 개발
[2] Schema Registry
[3] Uses of ElasticSearch
[4] Kafka Connect
[5] Kafka Streams
[6] ksqlDB
[7] Mastering Kafka Streams and ksqlDB, Mitch Seymour, O’reilly
[8] Kafka Streams vs ksqlDB
Read more
-
ksqlDB Deep Dive
ksqlDB 의 동작원리 및 예제를 공유합니다. -
Spring Session + Custom Session Repository 기반 세션 저장소의 메모리 누수 해결
Spring Session + Custom Session Repository 를 사용할 때 발생한 메모리 누수 현상을 해결한 경험을 공유합니다.