CDC & CDC Sink Platform 개발 1편 - CDC Platform 개발
Application과 DataSource를 분리하는 단순한 Micro Service Architecture에서 Event Driven Architecture로 나아가기 위해서는 신뢰할 수 있는 Event Bus를 구축하는 것이 중요합니다. Kafka를 Event Bus 구현체로 활용하며 지속적인 이벤트의 흐름을 만들어내기 위해 CDC Platform을 개발한 경험을 공유합니다.
Event Driven Architecture는 이벤트를 발행하고 소비하는 패턴을 통해 느슨한 결합과 높은 확장성을 제공합니다. 이를 통해 비지니스 요구사항이 생길때마다 여러 프로젝트에 걸친 개발 작업 없이, 해당 비지니스가 필요한 도메인에서 이벤트를 소비하여 비지니스를 수행할 수 있습니다. 하지만, 이를 위해서는 Consumer에서 신뢰하고 소비할 수 있는 이벤트의 흐름을 만드는 작업이 선행되어야 합니다. CDC Platform을 활용하여 이벤트의 흐름을 만들게 된 이야기를 나누고자 합니다.
CDC ?
먼저, CDC라는 개념에 대해 처음 들어보는 분도 있을 것 같아 그 의미를 알아 보겠습니다. CDC란 무엇일까요? CDC == Change Data Capture. 즉, 변경된 데이터를 캡쳐하는 것을 의미합니다.
CDC 이론의 응용과 최종 일관성
현재 상태는 과거로부터 발생한 모든 변경 사항의 누적합과 같습니다. 최종 일관성 개념을 함께 적용해본다면 모든 변경사항을 지속적으로 누적해서 더하면 언젠가는 현재 상태에 수렴하게 될 것입니다. 이 이론을 적용하는 것으로 결합도가 낮고 확장성이 높은 시스템을 설계할 수 있습니다. 앞으로 CDC & CDC Sink Platform 개발 전 편에서 다룰 주제는 모두 CDC Pattern과 최종 일관성 이론을 기반으로 합니다.
CDC Platform 소개
그렇다면 오늘의 주제인 CDC Platform이 하는 역할은 무엇일까요? CDC Platform == DataSource -> Kafka. 즉, DataSource로부터 변경된 데이터를 캡쳐하여 Kafka로 전송하는 역할을 담당합니다. Kafka Connect를 기반으로 DataSource -> Kafka의 역할을 하는 Application을 CDC Platform이라 정의하였습니다.
CDC Platform 특징
CDC Platform은 어떤 특징을 가지고 있을까요?
- Kafka Connect API
- Failure Tolerance
- Scalable
- No Code
- At-least-once Delivery
CDC 기술을 선택한 이유 ? - Application Layer Event VS Persistence Layer Event
Application Layer를 기반으로 Event를 발행하는 방법도 있었을텐데, Persistence Layer 기반으로 이벤트를 발행하는 방식을 선택한 이유는 다음과 같습니다. Application에서 신뢰할 수 있는 Event를 발행하려면, 도메인 별 분리 및 DataSource 고립이 선행되어야 합니다. 현재, 서로 다른 프로젝트에서 Database를 공유하여 사용중이기 때문에, Application Layer 기반으로 Event를 발행할 경우 외부로 부터 발생한 변경사항에 따른 Event를 놓칠 수 있는 문제가 있었습니다. 따라서, 변경되었음을 근본적으로 신뢰할 수 있는 Persistence Layer 기반의 CDC 기술을 선택하게 되었습니다.
나아가, Application Layer 기반으로 Event를 발행하기 위해서는 Transactional Outbox Pattern 적용을 함께 고민해야 합니다. 대용량 데이터 베이스 환경에서 Transactional Outbox Pattern 구현을 위해 추가적인 Table을 설계하는 것은 부담이 있습니다. CDC 기술을 선택할 경우, 이미 저장소에 반영되었음을 저장소 차원에서 보장하기 때문에 Transactional Outbox Pattern 적용은 불필요합니다.
CDC Platform에서 활용하는 Kafka Connect
Kafka Connect는 Standalone Mode와 Distributed Mode를 제공합니다. 하지만, 운영 환경 대상이기에 Distributed Mode에 대해서만 다루도록 합니다. Kafka Connect의 Architecture는 크게 3가지의 모델로 구성됩니다.
- Connector Model
- 어떤 데이터를 어떤 형식으로 복제할지의 관심사를 가집니다.
- Worker Model
- 작업 수행에 관심사를 가지며, 확장성 및 내결함성을 제공합니다.
- 1개의 Worker는 N개의 Task를 가질 수 있습니다.
- Task는 실제 작업을 처리하는 Thread 입니다.
- Data Model
- 메세지 즉, 데이터 자체에 관심사를 가집니다.
- 메세지 내용은 직렬화에 구애받지 않는 형식으로 표현됩니다.
CDC Platform에서 활용하는 Kafka Connect - Distributed Worker
Distributed Mode는 Kafka Connect에 대한 확장성 및 내결함성을 제공합니다. Kafka를 활용하여 동일한 group.id에 대해 논리적인 Clustering을 제공하며, 내부적으로 Kafka Connect Worker는 Consumer Group을 활용하여 Coordination & Rebalancing을 하게됩니다. 나아가 Kafka를 Main Storage로 활용하며, Kafka Topic을 통해 데이터를 관리합니다. 관리 대상 Topic은 다음과 같습니다.
- 첫째, Connector 및 Task 구성을 관리하기 위해 Config Topic을 사용합니다.
- 둘째, Offset을 관리하기 위해 Offset Topic을 사용합니다.
- 셋째, Connector 상태를 관리하기 위해 Status Topic을 사용합니다.
이외에도 각각의 Connector 구현체 별로, 정보를 관리하기 위해 Kafka Topic을 추가적으로 사용합니다.
[Distributed Worker Model]
- Worker는 Instance로 보아도 무방합니다.
- 각 Worker에 여러개의 Connector를 등록할 수 있습니다.
- 각 Connector는 N개의 Task를 통해 분산처리 가능합니다.
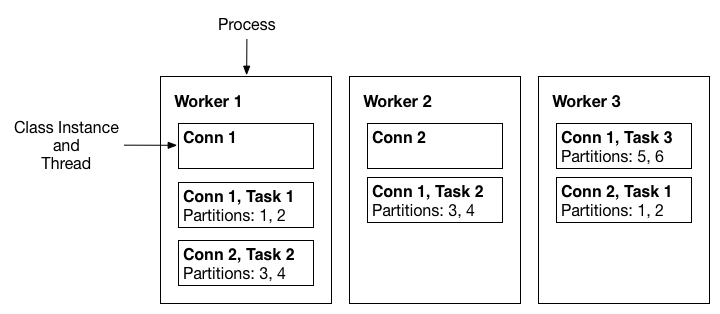
[Task Rebalancing]
- Worker는 Instance로 보아도 무방합니다.
- Worker 장애시 Task Rebalancing 됩니다.

CDC Platform 단일 구조
단일 Source로부터 변경 이벤트를 읽어 Kafka로 전송하는 Flow를 살펴보면 다음과 같습니다.
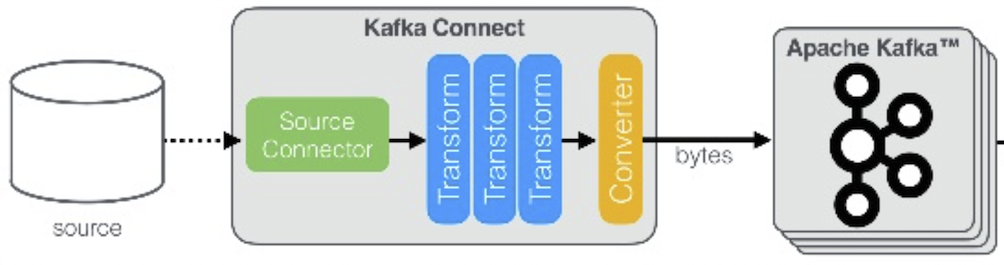
내부 구조를 살펴보면 크게 3가지의 단계로 구성됩니다.
- 첫째, DataSource로부터 변경 데이터를 읽는 단계
- 각 Source Connector 마다 해당 DataSource에 특화된 설정을 가지고 있습니다.
- 둘째, 데이터를 가공할 수 있는 Transform 단계
- 특정 값을 추가/제거, 날짜의 형태를 변형 등 다양한 조건으로 데이터를 가공할 수 있습니다.
- 셋째, 가공한 데이터를 Kafka에 전송하기위한 형태로 변형하는 Converter 단계
- Avro, Json, ProtoBuf 등 Serialization의 역할을 함께 수행합니다.
- 최종적으로 Kafka에 전송하기 위한 Byte Array 형태로 변형합니다.
CDC Platform 확장 구조
다수의 Source로부터 변경 이벤트를 읽어 Kafka로 전송하는 Flow를 살펴보면 다음과 같습니다.
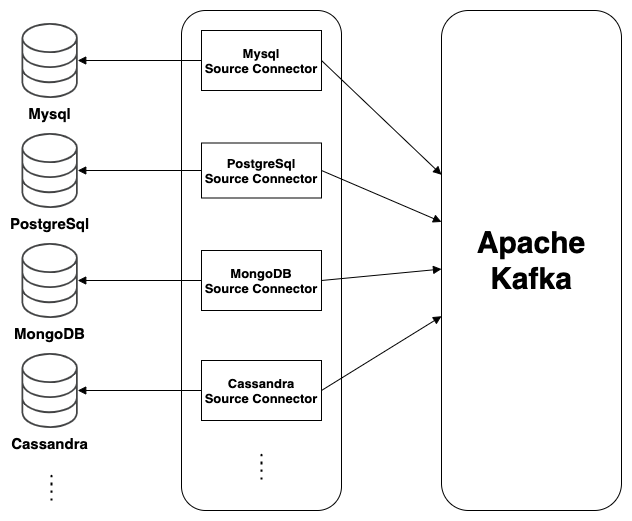
내부 구조를 살펴보면 다음과 같은 특징임을 알 수 있습니다.
- 첫째, 각 Source에 매핑되는 Connector를 사용하여 Kafka로 변경 이벤트를 전송합니다.
- 둘째, Source Connector 를 통해 다수의 Source로 확장 가능합니다. (MySQL, PostgreSQL, Oracle, HDFS, MongoDB, Ignite, ElasticSearch, Cassandra 등)
CDC Platform 설치
CDC Platform은 이식성을 높이기 위해 Docker 기반으로 패키징하여 구성합니다.
FROM confluentinc/cp-kafka-connect-base:6.1.1
ENV CONNECT_PLUGIN_PATH="/usr/share/java,/usr/share/confluent-hub-components" \
CUSTOM_SMT_PATH="/usr/share/java/custom-smt" \
CUSTOM_CONNECTOR_MYSQL_PATH="/usr/share/java/custom-connector-mysql" \
CUSTOM_CONNECTOR_SCYLLA_PATH="/usr/share/java/custom-connector-scylla"
ARG CONNECT_TRANSFORM_VERSION=1.4.0
ARG DEBEZIUM_VERSION=1.5.0
ARG SCYLLA_CDC_VERSION=1.0.0
# Download Using confluent-hub
RUN confluent-hub install --no-prompt confluentinc/connect-transforms:$CONNECT_TRANSFORM_VERSION
# Download Custom Source Connector
RUN mkdir $CUSTOM_CONNECTOR_MYSQL_PATH && cd $CUSTOM_CONNECTOR_MYSQL_PATH && \
curl -sO https://repo1.maven.org/maven2/io/debezium/debezium-connector-mysql/$DEBEZIUM_VERSION.Final/debezium-connector-mysql-$DEBEZIUM_VERSION.Final-plugin.zip && \
jar xvf debezium-connector-mysql-$DEBEZIUM_VERSION.Final-plugin.zip && \
rm debezium-connector-mysql-$DEBEZIUM_VERSION.Final-plugin.zip
RUN mkdir $CUSTOM_CONNECTOR_SCYLLA_PATH && cd $CUSTOM_CONNECTOR_SCYLLA_PATH && \
curl -sO https://repo1.maven.org/maven2/com/scylladb/scylla-cdc-source-connector/$SCYLLA_CDC_VERSION/scylla-cdc-source-connector-$SCYLLA_CDC_VERSION-jar-with-dependencies.jar
CDC Platform Connector 운영
CDC Platform은 Kafka Connect를 통해 다음과 같은 REST API를 제공합니다. CDC Platform 사용자는 이를 활용하여 작업을 요청할 수 있습니다. No Code 기반이며, 운영의 효율성을 위해 Script를 작성하여 API를 호출합니다.
- Connector 목록 조회
- Connector 등록
- Connector 삭제
- Connector 재시작
- Connector 상태 조회
- Connector에 대해 실행중인 Task 목록 조회
- Connector에 대해 실행중인 특정 Task의 상태 조회
- Connector에 대해 실행중인 특정 Task 재시작
- …
CDC Platform Connector 운영 - Connector 등록
여러 작업 중 가장 핵심이라고 볼 수 있는 Connector 등록 Script를 살펴보겠습니다. Connector에서 필요한 정보를 작성하여 API를 통해 등록합니다.
이 과정에서, Connector에서 Snapshot 기능을 지원하는 경우 이미 적재된 기존 데이터들의 특정 시점 Snapshot 그리고 해당 시점 이후의 Event Stream까지 누락 없이 모든 데이터 변경을 전송하게 할 수 있습니다. 보편적으로 사용하는 MySQL의 Debezium MySQL Source Connector의 경우 snapshot.mode 설정을 통해 Snapshot 기능 사용여부를 설정할 수 있습니다. 따라서, 필요할 경우 Connector를 통해 모든 데이터를 다시 복원하는 흐름까지도 만들어 낼 수 있습니다.
#!/bin/sh
# Argument Validation
if [ "$#" -ne 8 ]; then
echo "$# is Illegal number of parameters."
echo "Usage: $0 [cdc_url] $1 [database_url] $2 [database_user] $3 [database_password] $4 [database_include_list] $5 [kafka_bootstrap_servers] $6 [snapshot_mode] $7 [replication_factor]"
exit 1
fi
# Define variables
args=("$@")
cdc_url=${args[0]}
database_url=${args[1]}
database_user=${args[2]}
database_password=${args[3]}
database_include_list=${args[4]}
kafka_bootstrap_servers=${args[5]}
snapshot_mode=${args[6]}
replication_factor=${args[7]}
curl -i -X PUT -H "Accept:application/json" -H "Content-Type:application/json" ${cdc_url}/connectors/test_db_connector/config -d '{
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "'${database_url}'",
"database.port": "3306",
"database.user": "'${database_user}'",
"database.password": "'${database_password}'",
"database.server.name": "cdc-data.azar",
"database.include.list": "'${database_include_list}'",
"database.history.kafka.bootstrap.servers": "'${kafka_bootstrap_servers}'",
"database.history.kafka.topic": "cdc-schema.test",
"snapshot.locking.mode": "none",
"max.batch.size": "20480",
"max.queue.size": "81920",
"poll.interval.ms": "100",
"snapshot.mode": "'${snapshot_mode}'",
"snapshot.new.tables": "parallel",
"producer.override.acks": "-1",
"producer.override.max.in.flight.requests.per.connection": "1",
"producer.override.compression.type": "snappy",
"producer.override.linger.ms": "50",
"producer.override.batch.size": "327680",
"errors.tolerance": "all",
"errors.log.enable": "true",
"errors.log.include.messages": "true",
"topic.creation.default.replication.factor": "'${replication_factor}'",
"topic.creation.default.partitions": "11"
}'
CDC Platform Connector 운영 - Connector 조회
등록된 Connector를 조회하고 현재 상태는 어떤지, 나아가 각 Connector에 등록된 Task들은 어떠한 상태인지 살펴보도록 하겠습니다.
#!/bin/sh
# Argument Validation
if [ "$#" -ne 1 ]; then
echo "$# is Illegal number of parameters."
echo "Usage: $0 [cdc_url]"
exit 1
fi
# Define variables
args=("$@")
cdc_url=${args[0]}
curl -f -X GET ${cdc_url}/connectors?expand=status
위 요청을 수행 후, 그 결과를 살펴보겠습니다. 2개의 RUNNING 상태인 Connector가 등록되어있고, 각각 1개의 RUNNING 상태인 Task가 동작하고 있는 것을 확인 가능합니다. 이를 통해 현재 Connector 및 Task의 상태를 알 수 있습니다. 더 나아가서, 본 API를 활용하면 특정 상태에 빠진 Task를 복구할 수 있습니다.
{
"test1_db_connector":{
"status":{
"name":"test1_db_connector",
"connector":{
"state":"RUNNING",
"worker_id":"xxx.xx.xx.xx:8083"
},
"tasks":[
{
"id":0,
"state":"RUNNING",
"worker_id":"xxx.xx.xx.xx:8083"
}
],
"type":"source"
}
},
"test2_db_connector":{
"status":{
"name":"test2_db_connector",
"connector":{
"state":"RUNNING",
"worker_id":"xxx.xx.xx.xx:8083"
},
"tasks":[
{
"id":0,
"state":"RUNNING",
"worker_id":"xxx.xx.xx.xx:8083"
}
],
"type":"source"
}
}
}
CDC Platform Connector 운영 - Mysql Source Connector
위에서는 일반적인 Connector 운영에 대해 소개하였습니다. 다음으로는 가장 많이 활용하는 Mysql Source Connector에 대해 살펴보도록 하겠습니다. Mysql Source Connector는 Binlog를 기반으로 처리할 데이터를 읽게 됩니다. 어떤 파일에서 읽을 것인지는 Binlog File Name으로 결정하며, 어떤 Position에서부터 읽을지는 Binlog Position을 기반으로 결정합니다.
따라서, Mysql Source Connector를 사용하기 위해서는 아래와 같은 Database 설정이 구성되어야 합니다. expire_logs_days 설정의 경우, 0이 아니어도 무방합니다. 또한, GTID를 지원할 경우 Enable할 것을 권장하며, 필수 사항은 아닙니다.
binlog_format = 'ROW'
log_slave_updates = 'ON'
binlog_row_image = 'FULL'
expire_logs_days = 0
Mysql Source Connector를 적용하는데 도움되는 Mysql 명령어는 다음과 같습니다.
SHOW MASTER STATUS;
SHOW SLAVE STATUS;
SHOW VARIABLES LIKE 'log_bin';
SHOW BINARY LOGS;
SHOW GLOBAL VARIABLES LIKE 'read_only';
SHOW GLOBAL VARIABLES LIKE 'binlog_row_image';
SHOW GLOBAL VARIABLES LIKE 'binlog_format';
SHOW GLOBAL VARIABLES LIKE 'expire%';
Mysql Source Connector에서 사용할 Database 계정이 필요하며, 필요한 Global Privileges는 다음과 같습니다. Snapshot 진행시 DDL Update가 발생하여 Schema가 깨지는 것을 방지하기 위해 Table Lock을 잡도록 설정할 수 있습니다. 하지만, 장애 예방을 위해 Table Lock 권한은 부여하지 않는 것을 권장하며, 필요할 경우에만 LOCK_TABLES 권한을 추가해야 합니다.
1. Select
2. Replication Client
3. Replication Slave
4. Reload
5. Show Databases
CDC Platform 장애 탐지
장애 탐지는 Application Log와 System Metric을 활용합니다. 나아가 상시 모니터링을 위해 JMX 기반의 지표를 수집하여 활용합니다.
- 장애 탐지
- Log Level Detection
- Log4j -> Sentry -> Slack Notification
- System Metric Detection
- Zabbix -> Slack Notification
- Log Level Detection
CDC Platform 장애 탐지 - 설정
Kafka Connect 6.1.0 기준, log4j를 지원합니다. log4j.properties 설정을 활용하여 특정 Log Level 이상의 로그를 Sentry로 전송합니다. 이를 통해 장애를 인지하고 대응할 수 있습니다.
log4j.rootLogger=INFO, stdout, Sentry
# Send the logs to the console.
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=[%d] %p %m (%c:%L)%n
# default log levels
log4j.logger.org.reflections=ERROR
log4j.logger.org.apache.zookeeper=ERROR
log4j.logger.org.I0Itec.zkclient=ERROR
# Send the logs to sentry
log4j.appender.Sentry=io.sentry.log4j.SentryAppender
log4j.appender.Sentry.threshold=WARN
나아가, System Metric 기반으로 장애를 인지하고 대응해야 합니다. 이는, Zabbix를 통해 Metric을 수집하고 Slack을 통해 문제 상황을 알립니다.
CDC Platform 모니터링
JMX Metric을 수집하여 Grafana를 활용하여 모니터링합니다. 모니터링 지표는 크게 세 가지로 구분 됩니다.
- CDC Cluster Worker Metric
- CDC Cluster Task Metric
- CDC Cluster Connector Metric
CDC Platform 모니터링 - 설정
jmx_exporter를 활용하여 JMX Metric을 Prometheus로 수집하고 Grafana를 통해 모니터링합니다.
startDelaySeconds: 0
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
rules:
- pattern : "kafka.connect<type=connect-worker-metrics>([^:]+):"
name: "cdc_kafka_connect_connect_worker_metrics_$1"
- pattern : "kafka.connect<type=connect-metrics, client-id=([^>]+)><>([^:]+)"
name: "cdc_kafka_connect_connect_metrics_$2"
labels:
client: "$1"
- pattern : "kafka.connect<type=connector-task-metrics, connector=([^,]+), task=([^>]+)><>([^:]+)"
name: "cdc_kafka_connect_connect_task_metrics_$3"
labels:
connector: "$1"
task: "$2"
- pattern: "debezium.([^:]+)<type=connector-metrics, context=([^,]+), server=([^,]+), key=([^>]+)><>RowsScanned"
name: "cdc_debezium_metrics_RowsScanned"
labels:
plugin: "$1"
name: "$3"
context: "$2"
table: "$4"
- pattern: "debezium.([^:]+)<type=connector-metrics, context=([^,]+), server=([^>]+)>([^:]+)"
name: "cdc_debezium_metrics_$4"
labels:
plugin: "$1"
name: "$3"
context: "$2"
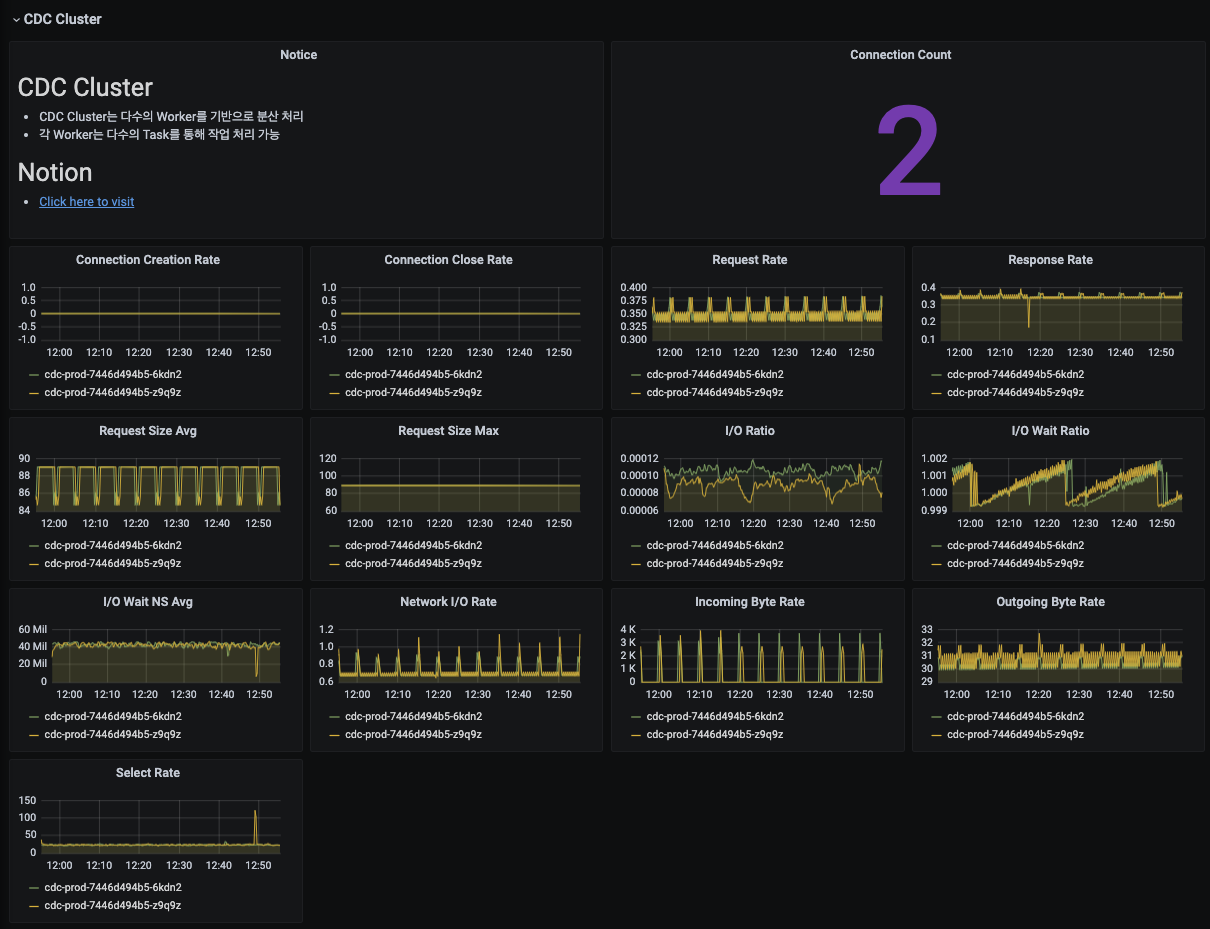
CDC Platform 모니터링 - Cluster Worker Metric
CDC Cluster의 Worker 지표를 제공합니다.
- Connection 지표
- Request 지표
- Response 지표
- I/O 지표
CDC Platform 모니터링 - Cluster Task Metric
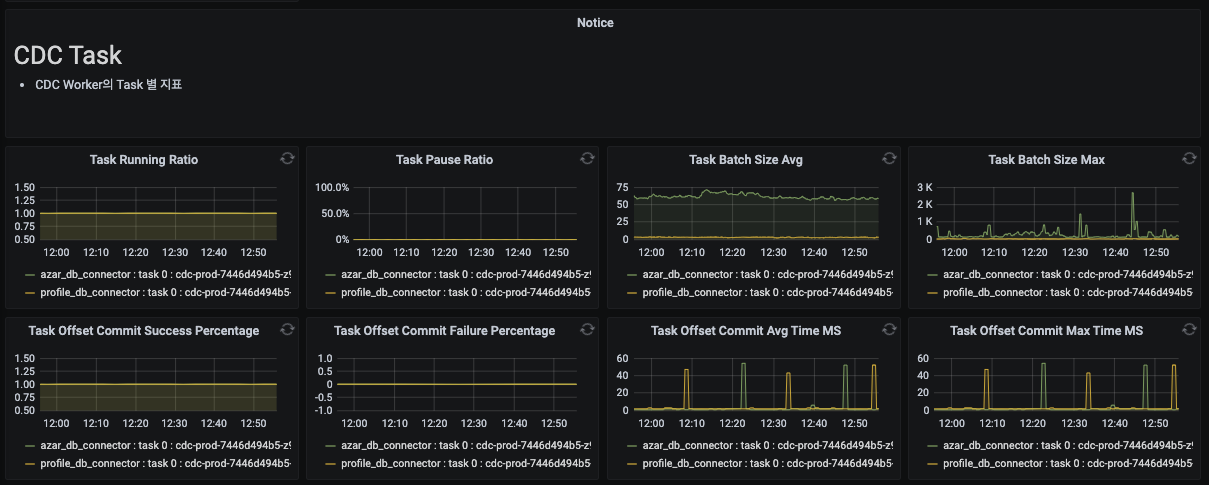
CDC Cluster의 Task 별 지표를 제공합니다.
- 동작하고 있는 Task 목록
- Task Batch Size
- Task Offset Commit Success/Failure Percentage
- Task Offset Commit 소요 시간
CDC Platform 모니터링 - Cluster Connector Metric
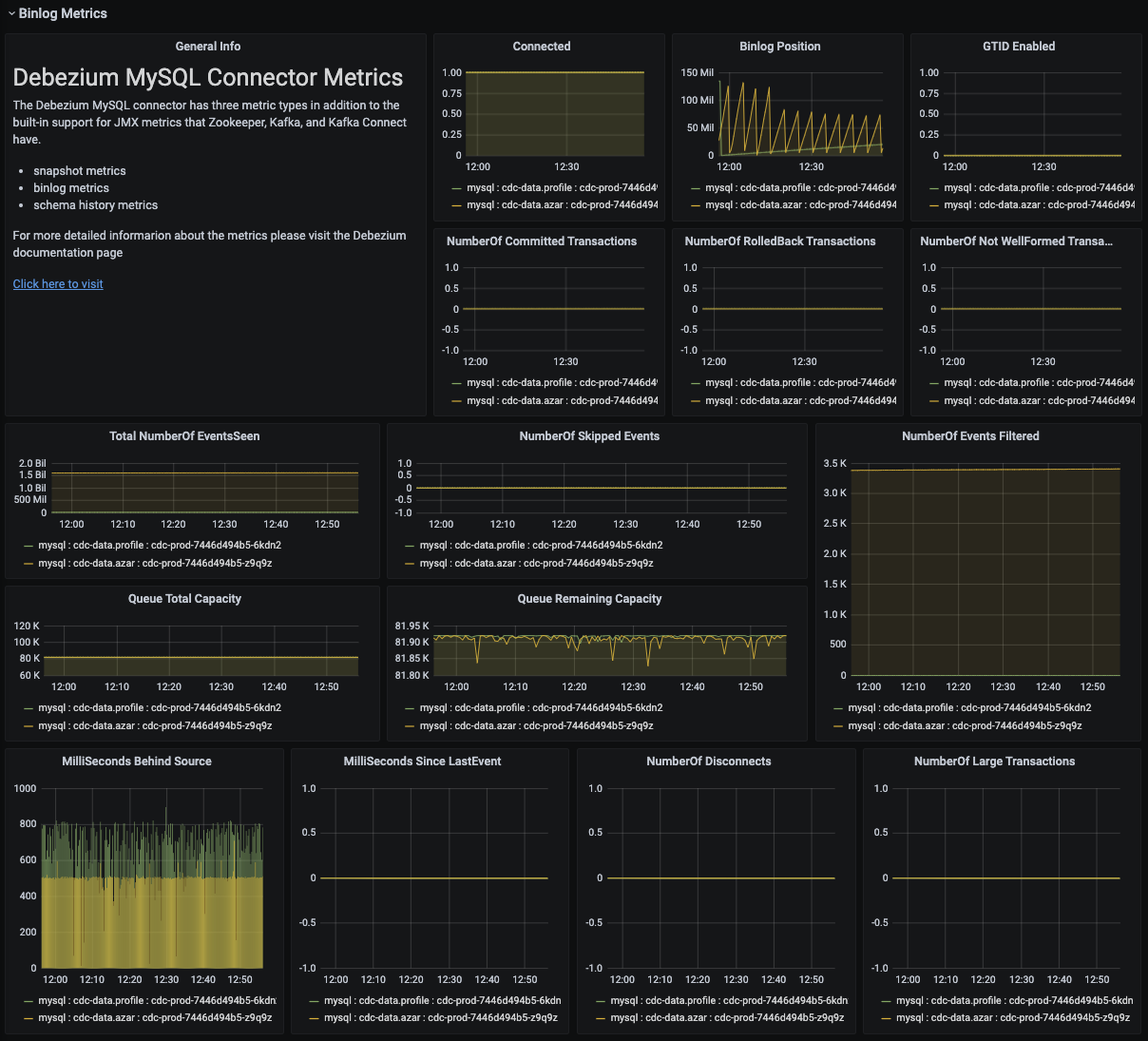
CDC Cluster에 등록된 Connector 중 Mysql Connector의 Metric 입니다. 대표적으로 아래와 같은 지표들을 확인 가능합니다.
- Binlog Metrics
- Binlog Position
- Binlog가 Master로부터 지연되고 있는 시간
- Snapshot Metrics
- Snapshot 대상 Table 수
- Snapshot 소요 시간
- Snapshot 진행 중 여부
- Schema History Metrics
- Schema Change 개수
- Schema가 마지막으로 변경된 이후 경과 시간
실전 및 운영 - Failover
Failover에 필요한 배경 지식을 살펴보도록 하겠습니다. 먼저, Connector는 N개의 Task를 가지며, Task는 실제 작업을 수행하는 Thread에 할당되는 작업 단위입니다. 나아가, 각 Task는 status를 가지고 있으며, Task Restart API를 통해 문제 상황 발생시 재 구동이 가능합니다. 따라서, 아래와 같은 흐름으로 Failover가 이루어 집니다.
- 첫째, CDC Cluster에 등록된 Connector 목록과 각 Connector에 등록된 Task 목록을 함께 조회
- 둘째, 조회한 목록 중 상태가 FAILED인 Task에 대해 Restart API를 호출
실전 및 운영 - Failover 설정
먼저, 위에서 확인한 Failover 로직을 반복적으로 수행하기 위해 Script를 작성합니다.
#!/bin/sh
# Author : pkgonan
# Check kafka connect url
if [ -z "$KAFKA_CONNECT_URL" ]; then
echo "KAFKA_CONNECT_URL is missing."
exit 1
fi
# Check kafka connect failover log enabled
if [ -z "$KAFKA_CONNECT_FAILOVER_LOG_ENABLED" ]; then
KAFKA_CONNECT_FAILOVER_LOG_ENABLED="false"
fi
# Logging started
if [ "x$KAFKA_CONNECT_FAILOVER_LOG_ENABLED" = "xtrue" ]; then
echo "$(date +%Y-%m-%d-T%H:%M:%S%z) - Failover started"
fi
# List current connectors and status
if [ "x$KAFKA_CONNECT_FAILOVER_LOG_ENABLED" = "xtrue" ]; then
curl -s "$KAFKA_CONNECT_URL/connectors?expand=info&expand=status" | \
jq '. | to_entries[] | [ .value.info.type, .key, .value.status.connector.state,.value.status.tasks[].state,.value.info.config."connector.class"]|join(":|:")' | \
column -s : -t| sed 's/\"//g'| sort
fi
# Restart any connector tasks that are FAILED
curl -s "$KAFKA_CONNECT_URL/connectors?expand=status" | \
jq -c -M 'map({name: .status.name } + {tasks: .status.tasks}) | .[] | {task: ((.tasks[]) + {name: .name})} | select(.task.state=="FAILED") | {name: .task.name, task_id: .task.id|tostring} | ("/connectors/"+ .name + "/tasks/" + .task_id + "/restart")' | \
xargs -I {connector_and_task} sh -c 'curl -v -X POST "$KAFKA_CONNECT_URL"{connector_and_task}'
# Logging finished
if [ "x$KAFKA_CONNECT_FAILOVER_LOG_ENABLED" = "xtrue" ]; then
echo "$(date +%Y-%m-%d-T%H:%M:%S%z) - Failover finished"
fi
이후, Failover Script의 이식성을 높이기 위해 Docker 기반으로 패키징하여 구성합니다.
FROM alpine
RUN apk add --no-cache util-linux \
&& apk add --no-cache curl \
&& apk add --no-cache jq
COPY ./script/failover.sh /opt/hpcnt/failover.sh
ENTRYPOINT sh failover.sh
현재, Kubernetes 기반의 환경을 이용하고 있습니다. 따라서, Kubernetes Cronjob을 사용하여 위 Script를 1분마다 반복적으로 구동합니다. 이를 통해, CDC Connector의 Task에서 장애가 발생했을 때 자동으로 복구 할 수 있습니다. 참조하는 DataSource, Kafka 등 시스템 장애 발생 시, 장애가 복구 될 때까지 지속적으로 재시도를 하면서 Failover를 수행합니다.
실전 및 운영 - DB Failover 안전성 검증
Event Driven Architecture에서 CDC 이벤트를 기반으로 주요 비지니스를 수행하려면 데이터가 손실되지 않는다는 보장이 필요합니다. 따라서, DB 장애시 CDC에서 처리하는 데이터가 손실되지 않는지 검증하고자 합니다.
Mysql과 같이 Binlog 기반의 Database를 예로 들어 설명하겠습니다. 기본적으로, Debezium Mysql Source Connector를 사용하여 Mysql DB에서 데이터를 읽어 Kafka로 전송하는 흐름을 가집니다. 이때, Mysql Connector는 binlog의 FileName과 Position을 기반으로 어디에서부터 읽어서 처리해야 할지를 결정하게 됩니다. 따라서, binlog의 FileName과 Position 정보가 소실되지 않는 것이 중요하며, 기존에 참조하던 binlog가 없을 경우 장애가 발생할 수 있습니다.
Mysql 기준, Failover 상황에서 Binlog가 소실되지 않는지 확인해보고 CDC 입장에서 장애가 발생하지 않는지 검증이 필요합니다. AWS 환경 위에서 시스템을 운영하고 있으며, 검증 케이스는 아래와 같습니다.
- 첫째, AWS RDS Mysql (MySQL Community Engine) - Multi-AZ Disable
- 둘째, AWS RDS Mysql (MySQL Community Engine) - Multi-AZ Enable
- 셋째, AWS RDS Aurora Mysql - Multi-AZ Enable
실전 및 운영 - DB Failover 안전성 검증 결과
- 첫째, AWS RDS Mysql (MySQL Community Engine) - Multi-AZ Disable
- Multi-AZ가 구성되어 있지 않기에, 물리 장비 장애시 Slave를 Promote하는 방법을 사용해야 합니다.
- Promote != Failover로, Promote 진행시 CDC에서 바라보고 있는 Binlog File은 소실 됩니다.
- 따라서, RDS Multi-AZ Disable 환경에서 1개의 AZ에 위치한 DB 장애시 CDC는 장애에 영향을 받습니다.
- 둘째, AWS RDS Mysql (MySQL Community Engine) - Multi-AZ Enable
- Multi-AZ가 구성되어 있으며, 물리 장비 장애시 Failover가 가능합니다.
- Failover With Restart를 진행시, 기존에 CDC에서 바라보고 있는 Binlog File이 소실되지 않고 유지됩니다.
- 따라서, RDS Multi-AZ Enable 환경에서 1개의 AZ에 위치한 DB 장애시 CDC는 장애 영향을 받지 않습니다.
- 셋째, AWS RDS Aurora Mysql - Multi-AZ Enable
- Aurora는 Primary Instance와 Zone에 Replica를 추가하는 것으로 Multi-AZ를 Enable 할 수 있습니다.
- Binlog 정보는 Aurora Cluster Endpoint를 통해 접근가능합니다.
- Failover 진행시, 기존에 CDC를 바라보고 있는 Binlog File이 소실되지 않고 유지됩니다.
- 따라서, RDS Aurora Mysql의 Multi-AZ Enable 환경에서 1개의 AZ에 위치한 DB 장애시 CDC는 장애 영향을 받지 않습니다.
실전 및 운영 - DB Failover 안전성 검증 결과 분석
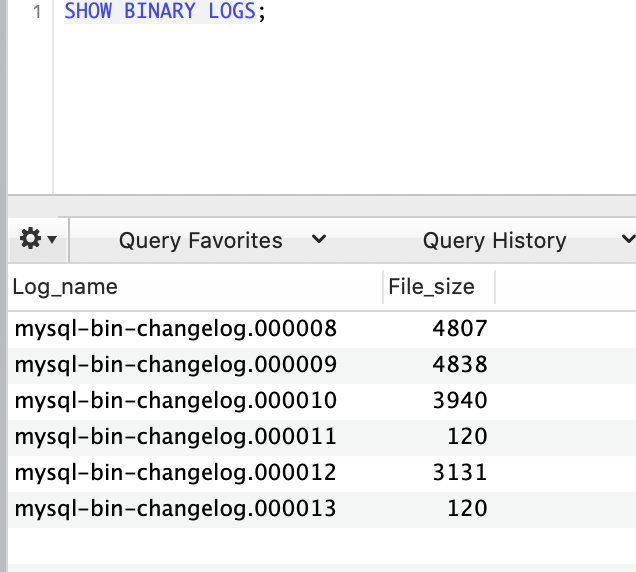
위에서 언급한 테스트 중, AWS RDS Aurora Mysql - Multi-AZ Enable 테스트에 대해 상세하게 다루어 보겠습니다. 먼저, Binlog가 Enable된 Aurora Mysql Writer/Reader 환경에서 mysql-bin-changelog.000008을 시작으로 Failover를 5회 진행 하였습니다. 이후, Show Binary Logs; 명령을 통해 Binlog File 목록을 조회하였습니다. 그 결과, 5회의 Aurora Mysql Failover에서도 기존 Master의 Binlog가 소실되지 않고 신규 Master를 통해서도 정상적으로 조회 가능한 것을 확인할 수 있었습니다.
1. 1차 Failover 이전, Last Binlog File : mysql-bin-changelog.000008
2. 1차 Failover 이후, Last Binlog File : mysql-bin-changelog.000009
3. 2차 Failover 이후, Last Binlog File : mysql-bin-changelog.000010
4. 3차 Failover 이후, Last Binlog File : mysql-bin-changelog.000011
5. 4차 Failover 이후, Last Binlog File : mysql-bin-changelog.000012
6. 5차 Failover 이후, Last Binlog File : mysql-bin-changelog.000013
실전 및 운영 - At-least-once Delivery 보장 검증
Confluent Kafka Connect 공식 문서에서는, At-least-once Delivery를 지원한다고 되어있습니다. 하지만, 신뢰할 수 없기 때문에 구체적으로 어떻게 지원하는지 직접 소스 코드를 분석하여 살펴보았습니다.
class WorkerSourceTask extends WorkerTask {
...
// Use IdentityHashMap to ensure correctness with duplicate records. This is a HashMap because
// there is no IdentityHashSet.
private IdentityHashMap<ProducerRecord<byte[], byte[]>, ProducerRecord<byte[], byte[]>> outstandingMessages;
// A second buffer is used while an offset flush is running
private IdentityHashMap<ProducerRecord<byte[], byte[]>, ProducerRecord<byte[], byte[]>> outstandingMessagesBacklog;
private boolean sendRecords() {
int processed = 0;
recordBatch(toSend.size());
final SourceRecordWriteCounter counter =
toSend.size() > 0 ? new SourceRecordWriteCounter(toSend.size(), sourceTaskMetricsGroup) : null;
for (final SourceRecord preTransformRecord : toSend) {
maybeThrowProducerSendException();
retryWithToleranceOperator.sourceRecord(preTransformRecord);
final SourceRecord record = transformationChain.apply(preTransformRecord);
final ProducerRecord<byte[], byte[]> producerRecord = convertTransformedRecord(record);
if (producerRecord == null || retryWithToleranceOperator.failed()) {
counter.skipRecord();
commitTaskRecord(preTransformRecord, null);
continue;
}
synchronized (this) {
if (!lastSendFailed) {
if (!flushing) {
outstandingMessages.put(producerRecord, producerRecord);
} else {
outstandingMessagesBacklog.put(producerRecord, producerRecord);
}
offsetWriter.offset(record.sourcePartition(), record.sourceOffset());
}
}
try {
final String topic = producerRecord.topic();
producer.send(
producerRecord,
new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null) {
producerSendException.compareAndSet(null, e);
} else {
recordSent(producerRecord);
counter.completeRecord();
commitTaskRecord(preTransformRecord, recordMetadata);
if (isTopicTrackingEnabled) {
recordActiveTopic(producerRecord.topic());
}
}
}
});
lastSendFailed = false;
} catch (org.apache.kafka.common.errors.RetriableException e) {
...
return false;
} catch (KafkaException e) {
throw new ConnectException("Unrecoverable exception trying to send", e);
}
processed++;
}
toSend = null;
return true;
}
public boolean commitOffsets() {
long commitTimeoutMs = workerConfig.getLong(WorkerConfig.OFFSET_COMMIT_TIMEOUT_MS_CONFIG);
long started = time.milliseconds();
long timeout = started + commitTimeoutMs;
synchronized (this) {
flushing = true;
boolean flushStarted = offsetWriter.beginFlush();
while (!outstandingMessages.isEmpty()) {
try {
long timeoutMs = timeout - time.milliseconds();
if (timeoutMs <= 0) {
finishFailedFlush();
recordCommitFailure(time.milliseconds() - started, null);
return false;
}
this.wait(timeoutMs);
} catch (InterruptedException e) {
finishFailedFlush();
recordCommitFailure(time.milliseconds() - started, null);
return false;
}
}
...
}
}
}
코드에서 At-least-once Delivery 보장과 관련된 코드만 살펴본다면 다음과 같습니다. 변경 데이터를 Kafka로 전송하는 행위는 sendRecords()에서 수행되며, 어디까지 처리했는지 Offset 정보를 전송하는 행위는 commitOffsets()에서 수행됩니다. 이들은 outstandingMessages 자료구조를 공유하며, outstandingMessages가 비워지지 않으면 Offset은 Commit 될 수 없습니다.
분석 결과 요약
- Kafka Connect의 WorkerSourceTask.java는 크게 두 가지의 작업을 수행한다
- Data를 Kafka로 전송
- 어디까지 처리했는지 Offset을 Kafka로 전송
- Data를 Kafka로 전송하는 행위는 다음과 같다
- 첫째, While문으로 무한 루프로 구성
- 둘째, Source Connect로부터 Data를 읽어서 지속적으로 Kafka로 전송
- 셋째, 전송 실패한 데이터는 전송 실패 데이터를 담는 Map에 적재
- 어디까지 처리했는지 Offset을 Kafka로 전송하는 행위는 다음과 같다
- 첫째, Scheduler로 구성 특정 기간마다 주기적으로 수행
- 둘째, 전송 실패한 데이터를 담는 Map에 데이터가 있다면, 비워질때까지 재 전송을 시도
- 셋째, 전송 실패한 데이터를 담는 Map이 비워지면, Offset을 Kafka로 전송
- Data를 Kafka로 전송하는 로직과 어디까지 처리했는지 Offset을 Kafka로 전송하는 로직은 동일한 Map을 공유한다
- Data를 Kafka로 전송 실패시 실패 데이터를 담는 Map을 함께 공유
분석 결론
- 전송 실패한 데이터를 담는 Map이 비워지지 않으면, Offset은 절대로 Commit 되지 않는다
- 따라서, At-least-once Delivery 보장이 가능하다
실전 및 운영 - Serialization & Deserialization
CDC에서 발행하는 Event는 신뢰하고 사용할 수 있어야 하며, 대용량 트래픽 처리를 위해 높은 처리량이 제공되어야 합니다. Kafka Connect에서 Serialization & Deserialization을 위해 다양한 Converter를 사용할 수 있습니다.
io.confluent.connect.avro.AvroConverter
io.confluent.connect.protobuf.ProtobufConverter
org.apache.kafka.connect.storage.StringConverter
org.apache.kafka.connect.json.JsonConverter
io.confluent.connect.json.JsonSchemaConverter
org.apache.kafka.connect.converters.ByteArrayConverter
Schema 정보를 Kafka로 전송하는 Data에 포함할 수 있으며, 포함하지 않고 사용할 수도 있습니다. 하지만, Kafka Sink Connector를 활용하는 등 확장성을 고려하여 Schema를 포함하는 것을 권장합니다.
이때, Schema 정보를 매번 Data와 함께 매번 전송하는 것은 성능 관점에서 좋지 않습니다. 하지만, Schema Registry를 적용하면 Schema의 정보는 Version만 전송하여 성능과 Schema 관리의 이점을 모두 누릴 수 있습니다. Confluent Schema Registry의 경우 Avro, Protobuf, Json 기반의 Schema를 지원합니다. 그리고 CDC Platform에서는 Confluent에서 권장하는 Avro를 적용하였습니다.
실전 및 운영 - CDC Event의 순서 보장
보편적으로 사용하는 MySQL Source Connector 기준으로 살펴보겠습니다. MySQL은 Binlog를 기반으로하기 때문에 기본적으로 데이터베이스에서 처리된 순서를 보장합니다. 하지만 이는 데이터베이스에서 처리된 순서를 보장하는 것이지, Kafka에 적재된 순서가 이와 일치한다는 것을 보장하지는 않습니다. MySQL Connector가 Binlog를 읽어 Kafka로 전송할 때, Primary Key가 존재하는 Table일 경우 동일한 Primary Key에 대해, 동일한 Kafka Partition으로 전송하는 것으로 이벤트의 순서를 보장합니다. Primary Key가 Composite Primary Key일 경우에도, 동일한 Kafka Partition으로 전송됩니다. 반면 Primary Key가 없는 Table의 경우, Partition Key는 null이 되기 때문에 Kafka Random Partition으로 전송되고, 이벤트의 적재 순서를 보장하지 않습니다.
구체적인 방식을 살펴본다면 Primary Key를 가리키는 Text 문자열 자체를 Key로 사용하며 본 Key를 기준으로 Hashing & Modulo를 통해 전송할 Kafka Partition을 결정합니다.
{
"id": 933
}
결론
CDC Platform을 개발하여 다음과 같은 효과를 얻을 수 있었습니다.
- 이미 저장소에 반영 되었음을 보장할 수 있는 Event 흐름 구축
- 필요 시 흘러가고 있는 Event에 빨대만 꼽아, 비지니스를 빠르게 수평 확장 가능
- 신규 Feature 개발 시, 기존 Legacy에 대한 Dependency 최소화
- Kafka 기반으로 Consumer 장애시 데이터가 소실되지 않고 재처리 가능
- Event Schema 관리는 Schema Registry를 사용하여, Producer가 Schema 임의 변경시 발생 가능한 Consumer 장애 예방
CDC & CDC Platform 이야기
[1] 1편 - CDC Platform 개발
[2] 2편 - CDC Sink Platform 개발 : CQRS 패턴의 적용
[3] 3편 - CDC Event Application Consuming : Event Stream Join의 구현
Reference
[1] Confluent Hub
[2] Kafka Connect Concept
[3] Kafka Connect REST API
[4] Amazon RDS Multi-AZ
[5] Schema Registry
[6] Kafka Connect Deep Dive – Converters and Serialization Explained
[7] Debezium
[8] Grafana Dashboard For Monitoring Debezium MySQL Connector
[9] Dump Thread Enhancement On MysSQL 5.7.2
Read more
-
Global Media Management System 개발
전세계에 위치한 사용자에게 Media Management System을 제공한 사례에 대해 소개합니다 -
CDC & CDC Sink Platform 개발 3편 - CDC Event Application Consuming 및 Event Stream Join의 구현
CDC Platform에서 발행한 CDC Event를 Application에서 직접 Consuming하여 처리한 사례에 대해 소개합니다. -
CDC & CDC Sink Platform 개발 2편 - CDC Sink Platform 개발 및 CQRS 패턴의 적용
CDC Sink Platform을 개발하고 CQRS 패턴을 적용한 사례에 대해 소개합니다.