CDC & CDC Sink Platform 개발 3편 - CDC Event Application Consuming 및 Event Stream Join의 구현
지난 2편 - CDC Sink Platform 개발 및 CQRS 패턴의 적용에서는 CDC Platform에서 Kafka로 전송한 CDC Event를 CDC Sink Platform을 통해 DataSource로 적재하고 나아가 CQRS Pattern을 구현한 사례에 대해 알아보았습니다. 다음으로는 CDC Sink Platform을 활용하지 않고 CDC에서 발행한 이벤트를 Application에서 직접 Consuming하여 처리한 사례에 대해 살펴보도록 하겠습니다.
배경
본 편에서는 CDC Platform에서 발행한 CDC Event를 Application에서 직접 Consuming하여 처리한 대용량 데이터 마이그레이션 사례에 대해 소개합니다. CDC Platform을 활용할 경우 데이터베이스 스냅샷부터 스냅샷 이후에 변경된 내용을 스트리밍하는 흐름을 쉽게 만들어 낼 수 있습니다. 즉, CDC Platform을 통해 Producer 측면의 고민을 해결해주어 Data Migration이 필요할 때 마다 실시간으로 변경되는 원본 데이터를 일관성을 보장하며 읽어오는 복잡한 코드를 개발할 필요가 없습니다. 즉, Data Migration을 위해 Kafka에 적재된 Event를 읽어 어떻게 처리할지 Consumer 측면에 대한 고민만 하면 됩니다.
RDB -> RDB 마이그레이션 사례
아자르 시스템 내의 회원 정보를 기존 데이터베이스에서 회원 데이터베이스로 무중단 무손실 마이그레이션이 필요하였습니다. 회원 정보는 속성에 따라 두가지의 테이블에 나누어 적재되어 있었습니다. 구체적인 요구사항은 기존 DB의 서로 다른 테이블에 적재된 데이터를 신규 DB에 단일 테이블로 합쳐서 마이그레이션 하는 것입니다. 주어진 요구사항을 기반으로 문제를 정의하면, 서로 다른 이벤트 스트림 Join 문제와 같습니다. 각각 다른 테이블에서 발생하는 이벤트 스트림이 존재하며 하나의 이벤트 스트림으로 통합하여 데이터 소스에 적재해야 하기 때문입니다.
정의한 문제를 해결하기 위해 여러 해결 방법 중 두가지 방법에 대해 고려하였습니다. Kafka Stream API를 활용하여 Application Side에서 Stream Join을 구현하는 것과 Upsert Query를 통해 DataBase Side에서 Stream Join을 구현하는 것에 대해 살펴보았습니다. 전자의 경우 특정 Time Window를 기준으로 서로 다른 Event Stream을 Application에서 Join하기 때문에 Time Window의 간격이 예상 가능한 범위 내에 존재해야 합니다. 반면, Application에서 Join을 수행하기 때문에 DB 부하가 적은 장점이 있습니다. 후자의 경우 DB에서 Join 역할을 수행하기 때문에 DB Query의 양이 많아 부하가 상대적으로 많은 특징이 있습니다. 하지만 간편하게 구현 가능한게 장점입니다.
결론적으로, 본 작업은 단발적으로 진행하는 Migration 작업이기 때문에 간단하게 구현 가능한 Upsert Query 방식을 선택하게 되었습니다. Jdbc Batch (rewriteBatchedStatements=true)와 DataBase Parameter 설정 변경(innodb_flush_log_at_trx_commit) 등을 활용하여 Migration 작업시 Write 성능을 개선하였으며 동일한 PK를 기준으로 데이터 중복시 각 쿼리는 지정한 Column을 Update 하도록 처리하여 Database Side Stream Join을 구현하였습니다. 본 방식의 단점은, 서로 다른 Thread에서 수행하는 Bulk Upsert Query 중 동일한 PK로 Upsert를 수행하는 경우 Dead Lock이 발생할 수 있는 것입니다. 이는 Retry를 통해 해소하였으며, Retry에서도 실패할 경우 Kafka Acknowledge가 실패하여 데이터 손실 없이 재처리할 수 있도록 구현하였습니다.
@Service
class MigrationService(
private val jdbcTemplate: JdbcTemplate
) {
companion object : KLogging() {
private const val MAX_BATCH_SIZE = 50
private const val userUpsertSql = """
INSERT INTO Nickname (userId, maskingName, currentNickname, dateCreated)
VALUES (?, ?, ?, ?)
ON DUPLICATE KEY UPDATE maskingName = VALUES(maskingName),
dateCreated = VALUES(dateCreated)
"""
private const val userExtDataUpsertSql = """
INSERT INTO Nickname (userId, maskingName, currentNickname, dateCreated)
VALUES (?, ?, ?, ?)
ON DUPLICATE KEY UPDATE currentNickname = VALUES(currentNickname)
"""
}
@KafkaListener(
topics = ["#{'\${kafka.topic.cdc.user}'.split(',')}"],
groupId = "\${cdc.migration.consumer.group-id}",
containerFactory = "cdcKafkaListenerContainerFactory",
concurrency = "1"
)
fun listenUser(records: List<ConsumerRecord<UserKey, UserEnvelope>>, acknowledgment: Acknowledgment) {
try {
/** record.value() can be null due to tombstone events, so ignore that. **/
val validRecords = records.filter { it.value() != null }
val values = validRecords.map { it.value() }
/** op command (c == create) **/
val created = values.filter { it.op == "c" }
/** op command (u == update) **/
val updated = values.filter { it.op == "u" }
/** op command (d == delete) **/
val deleted = values.filter { it.op == "d" }
/** op command (r == read (applies to only snapshots)) **/
val read = values.filter { it.op == "r" }
/** Collect event for bulk execution **/
val upsertQueue = listOf(read, created, updated).flatten()
val deleteQueue = listOf(deleted).flatten()
/** Bulk execution **/
upsertByUser(upsertQueue.map { it.after })
deleteByUser(deleteQueue.map { it.before })
/** Ack **/
acknowledgment.acknowledge()
} catch (ex: Exception) {
logger.error { "listenUser : $ex" }
throw ex
}
}
@KafkaListener(
topics = ["#{'\${kafka.topic.cdc.userext}'.split(',')}"],
groupId = "\${cdc.migration.consumer.group-id}",
containerFactory = "cdcKafkaListenerContainerFactory",
concurrency = "1"
)
fun listenUserExtData(
records: List<ConsumerRecord<UserExtDataKey, UserExtDataEnvelope>>,
acknowledgment: Acknowledgment
) {
try {
/** record.value() can be null due to tombstone events, so ignore that. **/
val validRecords = records.filter { it.value() != null }
val values = validRecords.map { it.value() }
/** op command (c == create) **/
val created = values.filter { it.op == "c" }
/** op command (u == update) **/
val updated = values.filter { it.op == "u" }
/** op command (d == delete) **/
val deleted = values.filter { it.op == "d" }
/** op command (r == read (applies to only snapshots)) **/
val read = values.filter { it.op == "r" }
/** Collect event for bulk execution **/
val upsertQueue = listOf(read, created, updated).flatten()
val deleteQueue = listOf(deleted).flatten()
/** Bulk execution **/
upsertByUserExtData(upsertQueue.map { it.after })
deleteByUserExtData(deleteQueue.map { it.before })
/** Ack **/
acknowledgment.acknowledge()
} catch (ex: Exception) {
logger.error { "listenUserExtData : $ex" }
throw ex
}
}
private fun upsertByUser(values: List<UserValue>) {
val validValues = values.filter { it.simpleName != null }
jdbcTemplate.batchUpdate(
userUpsertSql,
validValues,
MAX_BATCH_SIZE
) { ps: PreparedStatement, value: UserValue ->
ps.setLong(1, value.id)
ps.setString(2, value.simpleName)
ps.setString(3, null)
ps.setTimestamp(4, getTimeStamp(value.dateCreated))
}
}
private fun upsertByUserExtData(values: List<UserExtDataValue>) {
jdbcTemplate.batchUpdate(
userExtDataUpsertSql,
values,
MAX_BATCH_SIZE
) { ps: PreparedStatement, value: UserExtDataValue ->
ps.setLong(1, value.id)
ps.setString(2, value.originalName)
ps.setString(3, value.originalName)
ps.setTimestamp(4, Timestamp.valueOf(LocalDateTime.now()))
}
}
private fun deleteByUser(values: List<UserValue>) {
// Do Nothing
}
private fun deleteByUserExtData(values: List<UserExtDataValue>) {
// Do Nothing
}
}
RDB -> Google BigQuery 마이그레이션 사례
일반적으로 데이터 분석을 위해 원본 데이터 소스에서 Daily Dump 혹은 특정 주기마다 Dump를 떠서 분석용 데이터베이스로 적재합니다. 이러한 일괄처리 방식은 데이터가 증가하면 Dump 생성시간이 증가하는 등 데이터 사이즈 증가에 취약한 특징을 가지고 있습니다. CDC Event를 활용할 경우 변경이 일어난 이벤트만 캡쳐하여 반영할 수 있기 때문에 비효율적인 Load를 개선할 수 있으며 나아가 실시간성을 제공받을 수 있습니다. 하이퍼커넥트에서는 CDC Event를 Application에서 Consuming하여 분석용 데이터베이스인 Google BigQuery로 적재하는 흐름을 적용하여 데이터 분석을 지원하고 있습니다.
RDB -> ScyllaDB (Apache Cassandra Compatible) 마이그레이션 사례
전세계 수 억명의 회원을 보유한 아자르 서비스에는 N^2 Scale의 대량의 데이터를 처리해야 하는 사용자간의 차단 관계 비지니스가 있습니다. 쉽게 설명하면 소셜 네트워크 서비스인 Instagram의 Follow와 비슷한 비지니스라고 이해하면 될 것 같습니다. 해당 비지니스 특성상 ACID의 중요성보다는 가용성과 일관된 성능 그리고 데이터 확장성이 더 중요한 도메인입니다. 따라서 기존 RDB에서 분산 데이터베이스 중 하나인 ScyllaDB로 데이터 마이그레이션을 진행하게 되었습니다. 서로 다른 테이블에서 발생한 이벤트를 Join하는 RDB -> RDB 마이그레이션 사례와는 다르게 RDB의 단일 테이블을 ScyllaDB 단일 테이블로 무중단 무손실 마이그레이션하는 사례입니다.
B-Tree 기반인 RDB와는 다르게 LSM Tree 기반인 ScyllaDB는 Write에 최적화된 성능을 제공합니다. 따라서, RDB에서 사용한 JDBC Batch같은 기법을 사용하지 않고 단일 Write Query를 Application에서 병렬적으로 수행하여 성능을 개선하였습니다. 이때 반드시 고려해야 할 부분은 이벤트의 적재 순서를 보장하는 것입니다. 이벤트의 적재 순서를 보장하지 못하면 최종 일관성을 보장 할 수 없기 때문입니다. 따라서, 이벤트의 적재 순서를 보장하면서 성능을 최적화하기 위해 자료구조를 만들었고 이를 활용하여 대용량 데이터 마이그레이션을 성공적으로 진행할 수 있었습니다. 해당 성능 최적화 방식은 아래에서 소개하겠습니다.
CDC Migration Producer 개발
CDC Platform은 Primary Key가 존재하는 CDC Event에 대해 Kafka Partition 단위로 적재 순서를 보장합니다. 이에 따라 각 Primary Key를 기준으로 Consuming하는 순서는 곧 데이터가 처리되고 Kafka에 적재된 순서를 의미합니다. 하지만, Consuming한 데이터를 다시 다른 DataSource에 순서를 보장하면서 적재하는 것은 또 다른 문제입니다. Consuming한 데이터를 다른 DataSource에 순서를 보장하면서 적재하는 가장 쉬운 방법은 1개씩 순차적으로 처리하는 것입니다. 하지만 이러한 방식은 비효율적인 I/O가 발생하여 많은 처리량을 얻기는 어렵습니다. 특히, Migration 대상 데이터가 많을 경우 처리량 부족으로 Kafka retension.ms을 초과하면서 데이터가 소실될 수 있습니다. 이러한 문제를 해결하기 위해 이벤트의 적재 순서를 보장하면서 뛰어난 성능을 제공할 수 있는 CDC Migration Producer를 개발하게 되었습니다. CDC Migration Producer의 핵심 아이디어는 전체 순서를 보장하지 않고, 각 Primary Key 별로 인과성을 보장하는 것입니다.
CDC Migration Producer 개발 - Image Guide
간단한 자료구조입니다. 이해를 돕기 위해 이미지를 통해 동작 방식을 설명합니다.
CDC Migration Producer 개발 - Image Guide : Command Queue
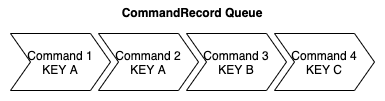
아래 CommandRecord Queue는 CDC Event가 적재된 Kafka Topic을 의미하며, 각 Command는 Create, Update, Delete로 구성된 CDC Event를 의미합니다.
CDC Migration Producer 개발 - Image Guide : Command Execution Phase
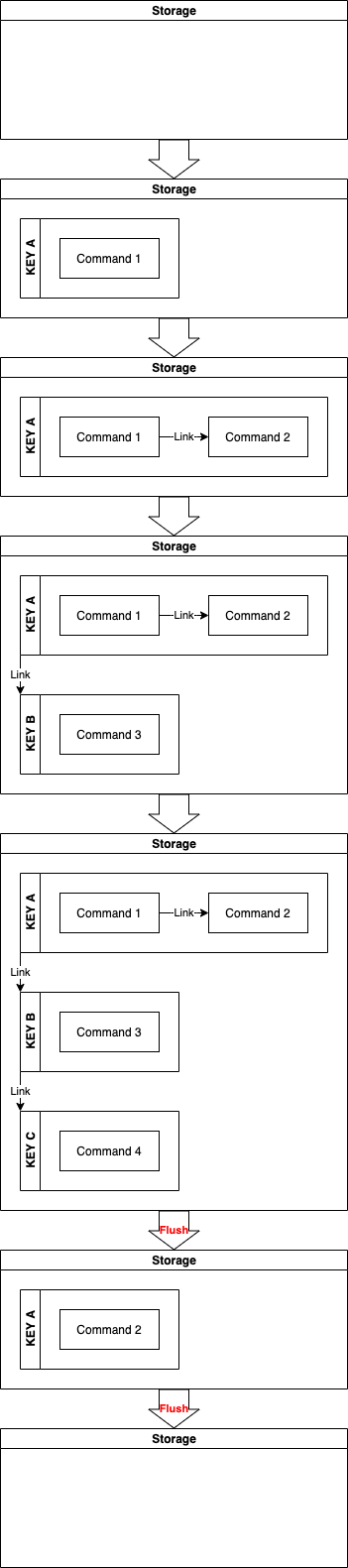
아래 이미지는 CommandRecord Queue에서 Command를 가져와서 각 Command를 CDC Migration Producer를 통해 처리하는 과정을 나타냅니다. 간략하게 설명하면 Local Storage에 각 Primary Key 별로 순서대로 이벤트를 적재합니다. 이후, flush 조건이 달성될 때 각 Primary Key 별로 요청을 모아 대량으로 처리합니다. 이를 통해 Primary Key 별 순서를 보장하고 처리 성능을 개선하게 됩니다.
CDC Migration Producer 개발 - Code Guide
프로그래밍 언어는 Kotlin을 활용하며 I/O 작업에 대해 Kotlin Coroutine을 사용합니다. KafkaListener의 Listener Mode를 Single이 아닌 Batch를 사용하여 한번에 가져오는 데이터의 개수를 증가시킵니다. 이를 통해 Consumer는 한번에 수백 수천개의 데이터를 poll() 해서 가져오게 됩니다. CDC Platform은 Partition Rebalancing을 제외한 일반적인 상황에서 Kafka로 데이터를 전송할 때 PK를 기준으로 동일한 파티션으로 전송합니다. 따라서, 각 Kafka 파티션 내에는 동일한 PK에서 발생한 이벤트가 순차적으로 적재되어 있음을 보장받을 수 있습니다. 이제 데이터를 다른 DataSource에 적재하는 순서를 보장해야 하며 이를 위해 CommandProducer를 사용합니다. 동일한 PK를 기준으로 Queue에 넣어 처리 순서를 보장하며 flush trigger 조건을 만족할 때만 I/O가 발생하도록 Lazy하게 처리하여 성능을 개선하였습니다.
spring.kafka.bootstrap-servers=kafka-broker:9092
spring.kafka.listener.type=batch
spring.kafka.listener.concurrency=1
spring.kafka.listener.ack-mode=manual_immediate
spring.kafka.consumer.group-id=block-service-prod
spring.kafka.consumer.max-poll-records=500
spring.kafka.consumer.enable-auto-commit=false
spring.kafka.consumer.key-deserializer=io.confluent.kafka.serializers.KafkaAvroDeserializer
spring.kafka.consumer.value-deserializer=io.confluent.kafka.serializers.KafkaAvroDeserializer
spring.kafka.properties.schema.registry.url=http://schema-registry
spring.kafka.properties.specific.avro.reader=true
kafka.topic.cdc.block=cdc-data.azar.azar.UserBlocking
@Service
class MigrationService(
private val repository: BlockRepository
) {
companion object {
private const val DEBEZIUM_OP_CODE_CREATE = "c"
private const val DEBEZIUM_OP_CODE_UPDATE = "u"
private const val DEBEZIUM_OP_CODE_DELETE = "d"
private const val DEBEZIUM_OP_CODE_READ = "r"
private val LOG = LoggerFactory.getLogger(this::class.java)
private val blockTimeGenerator = BlockTimeGeneratorImpl()
fun toPrimaryKey(primaryKey: Block.PrimaryKey) = primaryKey.getUserId() + ":" + primaryKey.getBlockedUserId()
}
@KafkaListener(topics = ["#{'\${kafka.topic.cdc.block}'}"])
fun listen(records: List<ConsumerRecord<Key, Envelope>>, acknowledgment: Acknowledgment) {
try {
/** record.value() can be null due to tombstone events, so ignore that. **/
val validRecords = records.filter { it.value() != null }
val commandRecords = toCommandRecord(validRecords)
/** Produce Commands **/
val producer = ComplexCommandProducer.of()
commandRecords.forEach { producer.send(it) }
producer.flush()
/** Ack **/
acknowledgment.acknowledge()
} catch (ex: Exception) {
LOG.error("listen : $ex")
throw ex
}
}
private fun toCommandRecord(records: List<ConsumerRecord<Key, Envelope>>) = records.map { toCommandRecord(it) }
private fun toCommandRecord(record: ConsumerRecord<Key, Envelope>): CommandRecord {
val value = record.value()
val blockCommand = when (value.op) {
DEBEZIUM_OP_CODE_CREATE -> CreateBlock.of(repository, value.after.toBlock())
DEBEZIUM_OP_CODE_UPDATE -> CreateBlock.of(repository, value.after.toBlock())
DEBEZIUM_OP_CODE_DELETE -> DeleteBlock.of(repository, value.before.toBlockPrimaryKey())
DEBEZIUM_OP_CODE_READ -> CreateBlock.of(repository, value.after.toBlock())
else -> throw CommandOperationException(value.op)
}
return CommandRecord.of(toPrimaryKey(blockCommand.getPrimaryKey()), blockCommand)
}
private fun Value.toBlock() : Block {
val primaryKey = toBlockPrimaryKey()
val type = BlockType.valueOf(blockingType)
val timeUUID = blockTimeGenerator.toStartTimeUUID(dateBlocked)
return Block.of(primaryKey, type, timeUUID)
}
private fun Value.toBlockPrimaryKey() : Block.PrimaryKey = Block.PrimaryKey.of(userId.toString(),blockedUserId.toString())
}
/**
* ComplexCommandProducer
*
* When auto flush ?
* 1. flushTriggerKeySize <= Stored command key size
*
* Guaranteed Features
* 1. Sequential processing for the same primary key.
* 2. Bulk processing
*
* Not guaranteed Features
* 1. Not safe for concurrency issues.
*
* @author Min.K
*/
class ComplexCommandProducer private constructor(
private val flushTriggerKeySize : Int
) : CommandProducer {
companion object {
fun of(flushTriggerKeySize: Int = DEFAULT_FLUSH_TRIGGER_KEY_SIZE) : ComplexCommandProducer {
if (MAX_FLUSH_TRIGGER_KEY_SIZE < flushTriggerKeySize) {
throw CommandArgumentException(flushTriggerKeySize.toString())
}
if (MIN_FLUSH_TRIGGER_KEY_SIZE > flushTriggerKeySize) {
throw CommandArgumentException(flushTriggerKeySize.toString())
}
return ComplexCommandProducer(flushTriggerKeySize)
}
private val LOG = LoggerFactory.getLogger(this::class.java)
private const val MAX_FLUSH_TRIGGER_KEY_SIZE = 1000
private const val DEFAULT_FLUSH_TRIGGER_KEY_SIZE = 100
private const val MIN_FLUSH_TRIGGER_KEY_SIZE = 1
}
private val storage = LinkedHashMap<String, Queue<Command>>()
override fun send(record: CommandRecord) {
if (!isAddable(record)) {
flushAll()
}
add(record)
if (mustFlush()) {
flushLine()
}
}
override fun flush() {
flushAll()
}
private fun doSend(commands: List<Command>) = runBlocking {
if (commands.isEmpty()) return@runBlocking
val splitCommands = commands.chunked(flushTriggerKeySize)
splitCommands.forEach { suspendDoSend(it) }
}
private suspend fun suspendDoSend(commands: List<Command>) = withContext(Dispatchers.IO) {
if (commands.isEmpty()) return@withContext
val deferredResponse = commands.map { async { it.execute() } }
deferredResponse.awaitAll()
}
private fun flushLine() {
doSend(getCommands())
}
private fun flushAll() {
do {
val commands = getCommands()
doSend(commands)
} while (commands.isNotEmpty())
}
private fun getCommands(): List<Command> {
if (storage.isEmpty()) return emptyList()
val flushableEntities = storage.entries.take(flushTriggerKeySize)
return flushableEntities.map {
val key = it.key
val queue = it.value
val command = queue.remove()
if (queue.isEmpty()) {
storage.remove(key)
}
command
}
}
private fun isAddable(record: CommandRecord): Boolean {
val storedRecordValue = storage.getOrDefault(record.getKey(), emptyList<Command>())
if (Int.MAX_VALUE <= storedRecordValue.size) {
return false
}
if (Int.MAX_VALUE <= storage.size) {
return false
}
return true
}
private fun mustFlush(): Boolean {
if (flushTriggerKeySize > storage.size) {
return false
}
return true
}
private fun add(record: CommandRecord) {
if (!isAddable(record)) {
LOG.error("Add Record Exception : $record")
throw CommandStorageException(record.toString())
}
val commandQueue = storage.getOrPut(record.getKey(), { LinkedList() })
commandQueue.add(record.getCommand())
}
}
interface CommandProducer {
/**
* Send commandRecord lazily.
*
* After all of send() calls are done, you must need to call flush().
*/
fun send(record: CommandRecord)
/**
* Flush remain commandRecord immediately
*/
fun flush()
}
class CommandRecord private constructor(
private val key : String,
private val command: Command
) {
companion object {
fun of(key: String, command: Command) = CommandRecord(key, command)
}
fun getKey() = key
fun getCommand() = command
}
interface Command {
/**
* Execute command
*/
suspend fun execute()
}
abstract class BlockCommand internal constructor(
private val repository: BlockRepository,
private val primaryKey: Block.PrimaryKey
) : Command {
fun getRepository() = repository
fun getPrimaryKey() = primaryKey
}
class CreateBlock private constructor(
repository: BlockRepository,
private val entity: Block
) : BlockCommand(repository, entity.getId()) {
companion object {
fun of(repository: BlockRepository, entity: Block) = CreateBlock(repository, entity)
}
override suspend fun execute() {
getRepository().insert(entity)
}
}
class DeleteBlock private constructor(
repository: BlockRepository,
primaryKey: Block.PrimaryKey
) : BlockCommand(repository, primaryKey) {
companion object {
fun of(repository: BlockRepository, primaryKey: Block.PrimaryKey) = DeleteBlock(repository, primaryKey)
}
override suspend fun execute() {
getRepository().deleteById(getPrimaryKey())
}
}
CDC Migration Producer 개발 - 성능 테스트 케이스
- 외부 I/O는 1건당 10ms 소요하는 것으로 가정합니다.
- 2가지의 테스트를 진행하며 테스트는 각각 1,000개, 10,000개의 Kafka Record를 처리합니다.
- PK 기준, 일정 구간마다 중복 데이터를 Salt로 넣습니다. 실제 환경에서 충분히 가능한 상황으로 테스트 데이터를 생성합니다.
- PK 기준 Event Salt : 1,2,3,4,5,5,6,7,8,9,10,10,11,12,13,14,15,15,16,17,18…..
CDC Migration Producer 개발 - 성능 테스트 결과
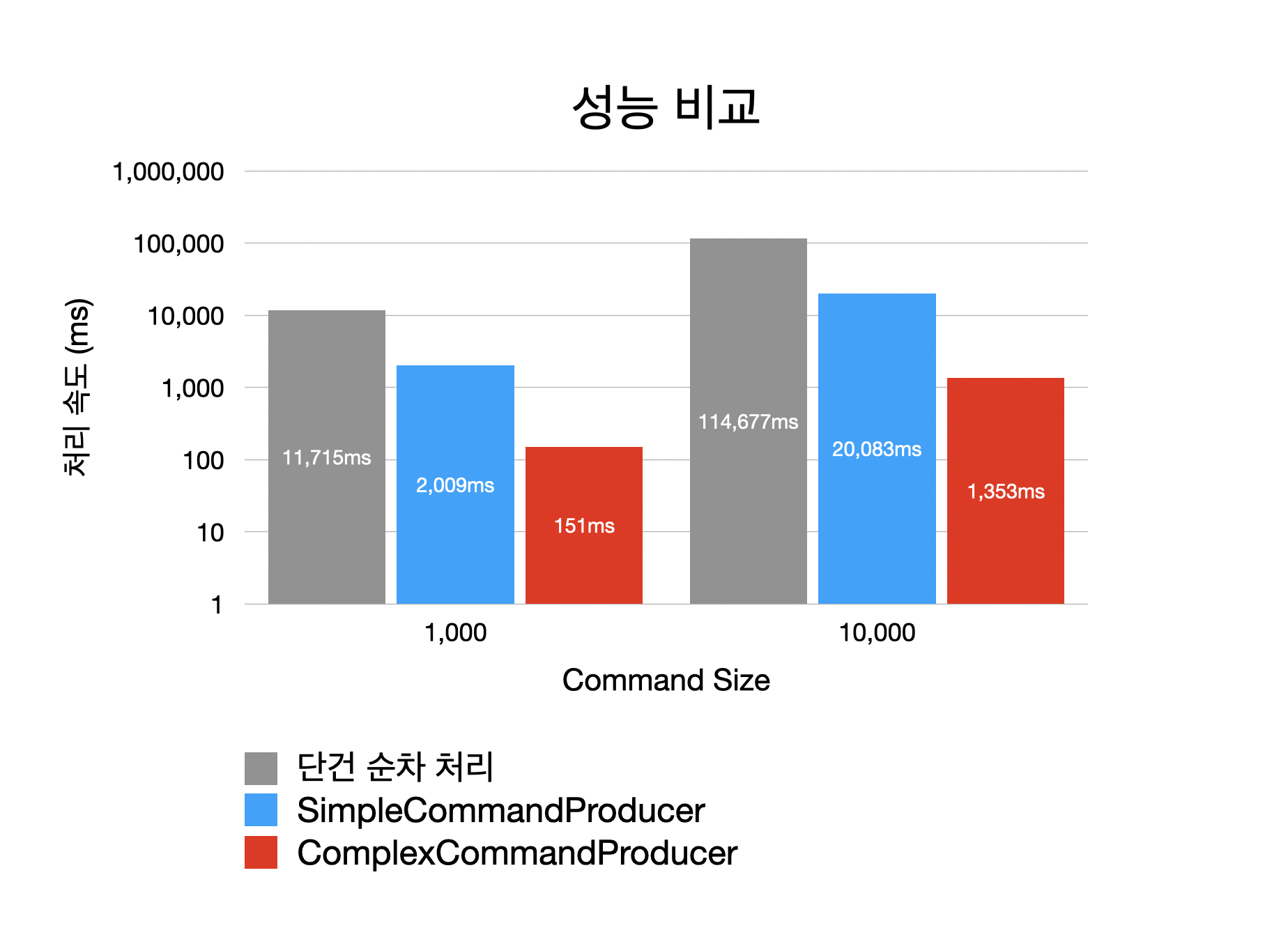
위에서 1개의 I/O는 10ms를 소요하는 것으로 가정하였습니다. 2가지의 테스트는 각각 1,000개 및 10,000개의 Kafka Record를 처리하므로 순차 처리시 이론상 10,000ms 그리고 100,000ms가 소요될 것입니다. 예상대로 단건 순차 처리 테스트는 실제로 비슷한 시간이 소요 되었습니다. 간단한 초기 버전의 구현인 SimpleCommandProducer의 경우 2,009ms 그리고 20,083ms로 성능이 대폭 개선되었습니다. 동일한 Primary Key의 Event가 빈번하게 발생할때 flush 빈도를 줄여 성능을 개선한 ComplexCommandProducer의 경우 151ms 그리고 1,353ms로 더욱 개선된 성능을 제공할 수 있었습니다. 나아가 Production ScyllaDB Write Latency는 평균 3ms 수준으로 실제 대용량 데이터 Migration 상황에서 매우 빠르게 Migration을 마칠 수 있었습니다.
결론
글로벌 서비스에서 발생하는 대용량 데이터의 무중단 무손실 마이그레이션 문제를 CDC Platform을 활용하여 해결할 수 있었습니다. 특히, 서로 다른 Event Stream Join과 같은 복잡한 문제에 대해 CDC Sink Platform을 활용하지 않고 Application에서 CDC 이벤트를 직접 Consuming 후 처리하는 방식을 사용하여 좀 더 손쉽게 문제를 해결할 수 있었습니다.
3편을 마지막으로 CDC Platform 구축 및 활용에 대한 소개를 마치도록 하겠습니다. CDC Pattern 구현 및 활용을 고려하시는 분들께 본 게시물이 도움이 되기를 바랍니다. 감사합니다.
CDC & CDC Platform 이야기
[1] 1편 - CDC Platform 개발
[2] 2편 - CDC Sink Platform 개발 : CQRS 패턴의 적용
[3] 3편 - CDC Event Application Consuming : Event Stream Join의 구현
Reference
[1] Apache Kafka Streams
[2] Log-structured merge-tree
[3] ScyllaDB
[4] Kafka Connect Concept
[5] Debezium
Read more
-
Global Media Management System 개발
전세계에 위치한 사용자에게 Media Management System을 제공한 사례에 대해 소개합니다 -
CDC & CDC Sink Platform 개발 2편 - CDC Sink Platform 개발 및 CQRS 패턴의 적용
CDC Sink Platform을 개발하고 CQRS 패턴을 적용한 사례에 대해 소개합니다. -
CDC & CDC Sink Platform 개발 1편 - CDC Platform 개발
CDC Platform을 개발하고 활용한 사례에 대해 소개합니다.