CDC & CDC Sink Platform 개발 2편 - CDC Sink Platform 개발 및 CQRS 패턴의 적용
지난 1편 - CDC Platform 개발에서 DataSource로 부터 변경 이벤트를 캡쳐하여 Kafka로 전송하는 과정에 대해 알아보았습니다. 다음으로는 Kafka로 전송된 CDC Platform의 Event를 DataSource로 적재할 수 있는 CDC Sink Platform에 대해 살펴보겠습니다. 나아가 CDC Sink Platform을 활용하여 CQRS 패턴을 구현한 부분에 대해 공유하고자 합니다.
CDC Sink Platform 소개
그렇다면 오늘의 주제인 CDC Sink Platform이 하는 역할은 무엇일까요? CDC Sink Platform == Kafka -> DataSource. 즉, Kafka로부터 변경된 데이터를 읽어 DataSource로 적재하는 역할을 담당합니다. Kafka Connect를 기반으로 Kafka -> DataSource의 역할을 하는 Application을 CDC Sink Platform이라 정의하였습니다.
CDC Sink Platform 특징
CDC Sink Platform은 어떤 특징을 가지고 있을까요? CDC Platform과 동일한 특징을 가지고 있습니다.
- Kafka Connect API
- Failure Tolerance
- Scalable
- No Code
- At-least-once Delivery
CDC Sink Platform에서 활용하는 Kafka Connect
Kafka Connect의 Architecture는 지난 1편 - CDC Platform 개발과 동일한 구조를 가집니다.
CDC Sink Platform 단일 구조
Kafka로부터 변경 이벤트를 읽어 DataSource로 전송하는 Flow를 살펴보면 다음과 같습니다.
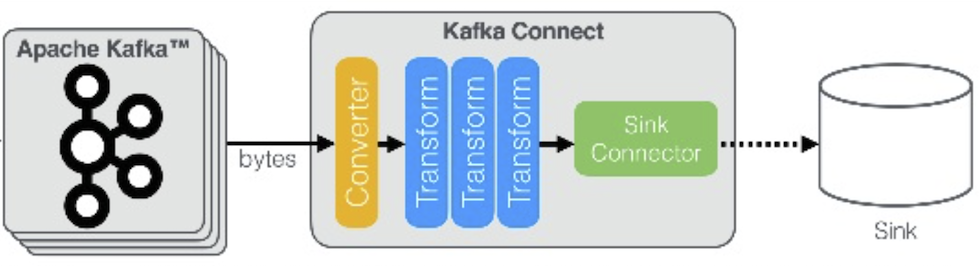
내부 구조를 살펴보면 크게 3가지의 단계로 구성됩니다.
- 첫째, Kafka로부터 변경 이벤트를 읽어 원본 형태로 변형하기 위한 Converter 단계
- Byte Array 형태의 변경 이벤트를 읽어옵니다.
- Avro, Json, ProtoBuf 등 Deserialization 역할을 함께 수행합니다.
- 둘째, 데이터를 가공할 수 있는 Transform 단계
- 특정 값을 추가/제거, 날짜의 형태를 변형 등 다양한 조건으로 데이터를 가공할 수 있습니다.
- 셋째, 가공한 데이터를 DataSource에 적재하는 단계
- 각 Sink Connector 마다 해당 DataSource에 특화된 설정을 가지고 있습니다.
CDC Sink Platform 확장 구조
Kafka로부터 변경 이벤트를 읽어 다수의 DataSource로 전송하는 Flow를 살펴보면 다음과 같습니다.
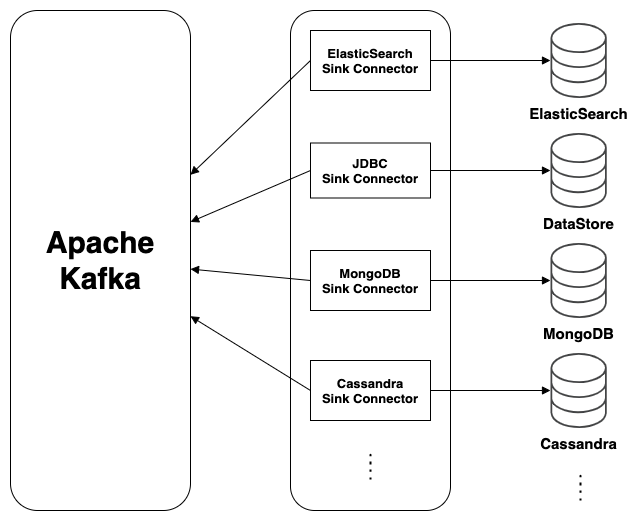
내부 구조를 살펴보면 다음과 같은 특징임을 알 수 있습니다.
- 첫째, Kafka로부터 변경 이벤트를 읽어 각 Source에 매핑되는 Connector를 통해 DataSource로 적재합니다.
- 둘째, Sink Connector 를 통해 다수의 DataSource로 확장 가능합니다. (JDBC, DynamoDB, Cassandra, HDFS, HBase, Redis, Ignite, ArangoDB, ScyllaDB, Google BigQuery 등)
CDC Sink Platform 설치
CDC Sink Platform은 이식성을 높이기 위해 Docker 기반으로 패키징하여 구성합니다.
FROM confluentinc/cp-kafka-connect-base:6.1.1
ENV CONNECT_PLUGIN_PATH="/usr/share/java,/usr/share/confluent-hub-components" \
CUSTOM_SMT_PATH="/usr/share/java/custom-smt"
ARG DEBEZIUM_VERSION=1.5.0
ARG CONNECT_TRANSFORM_VERSION=1.4.0
ARG CONNECT_ELASTICSEARCH_VERSION=11.0.3
# Download Using confluent-hub
RUN confluent-hub install --no-prompt confluentinc/connect-transforms:$CONNECT_TRANSFORM_VERSION \
&& confluent-hub install --no-prompt confluentinc/kafka-connect-elasticsearch:$CONNECT_ELASTICSEARCH_VERSION
# Download Custom SMT
RUN mkdir $CUSTOM_SMT_PATH && cd $CUSTOM_SMT_PATH && \
curl -sO https://repo1.maven.org/maven2/io/debezium/debezium-core/$DEBEZIUM_VERSION.Final/debezium-core-$DEBEZIUM_VERSION.Final.jar
CDC Sink Platform Connector 운영
CDC Sink Platform은 Kafka Connect기반으로 지난 1편 - CDC Platform 개발과 동일한 API를 제공합니다. 따라서, Connector를 등록, 조회하는 과정과 CDC Sink Platform의 장애 탐지, 장애 상황에서 복구하기 위한 Failover 방법은 동일하며 본 편에서 다루지 않습니다. 1편 내용을 참조해주세요.
CDC Sink Platform 모니터링
JMX Metric을 수집하여 Grafana를 활용하여 모니터링합니다. 모니터링 지표는 크게 두 가지로 구분 됩니다.
- CDC Sink Cluster Worker Metric
- CDC Sink Cluster Task Metric
CDC Sink Platform 모니터링 - 설정
jmx_exporter를 활용하여 JMX Metric을 Prometheus로 수집하고 Grafana를 통해 모니터링합니다.
startDelaySeconds: 0
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
rules:
- pattern : "kafka.connect<type=connect-worker-metrics>([^:]+):"
name: "cdc_sink_kafka_connect_connect_worker_metrics_$1"
- pattern : "kafka.connect<type=connect-metrics, client-id=([^>]+)><>([^:]+)"
name: "cdc_sink_kafka_connect_connect_metrics_$2"
labels:
client: "$1"
- pattern : "kafka.connect<type=connector-task-metrics, connector=([^,]+), task=([^>]+)><>([^:]+)"
name: "cdc_sink_kafka_connect_connect_task_metrics_$3"
labels:
connector: "$1"
task: "$2"
CDC Sink Platform 모니터링 - Cluster Worker Metric
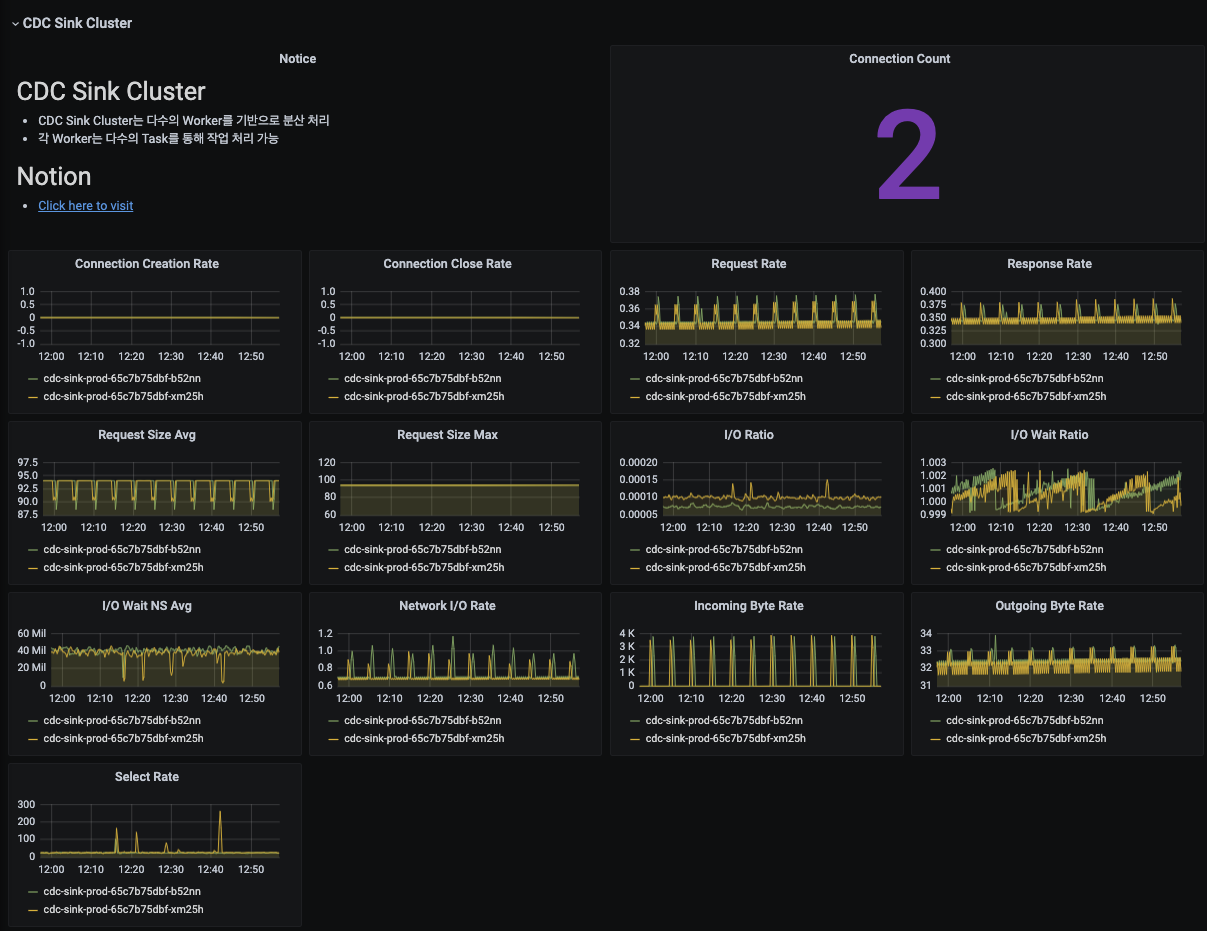
CDC Sink Cluster의 Worker 지표를 제공합니다.
- Connection 지표
- Request 지표
- Response 지표
- I/O 지표
CDC Sink Platform 모니터링 - Cluster Task Metric
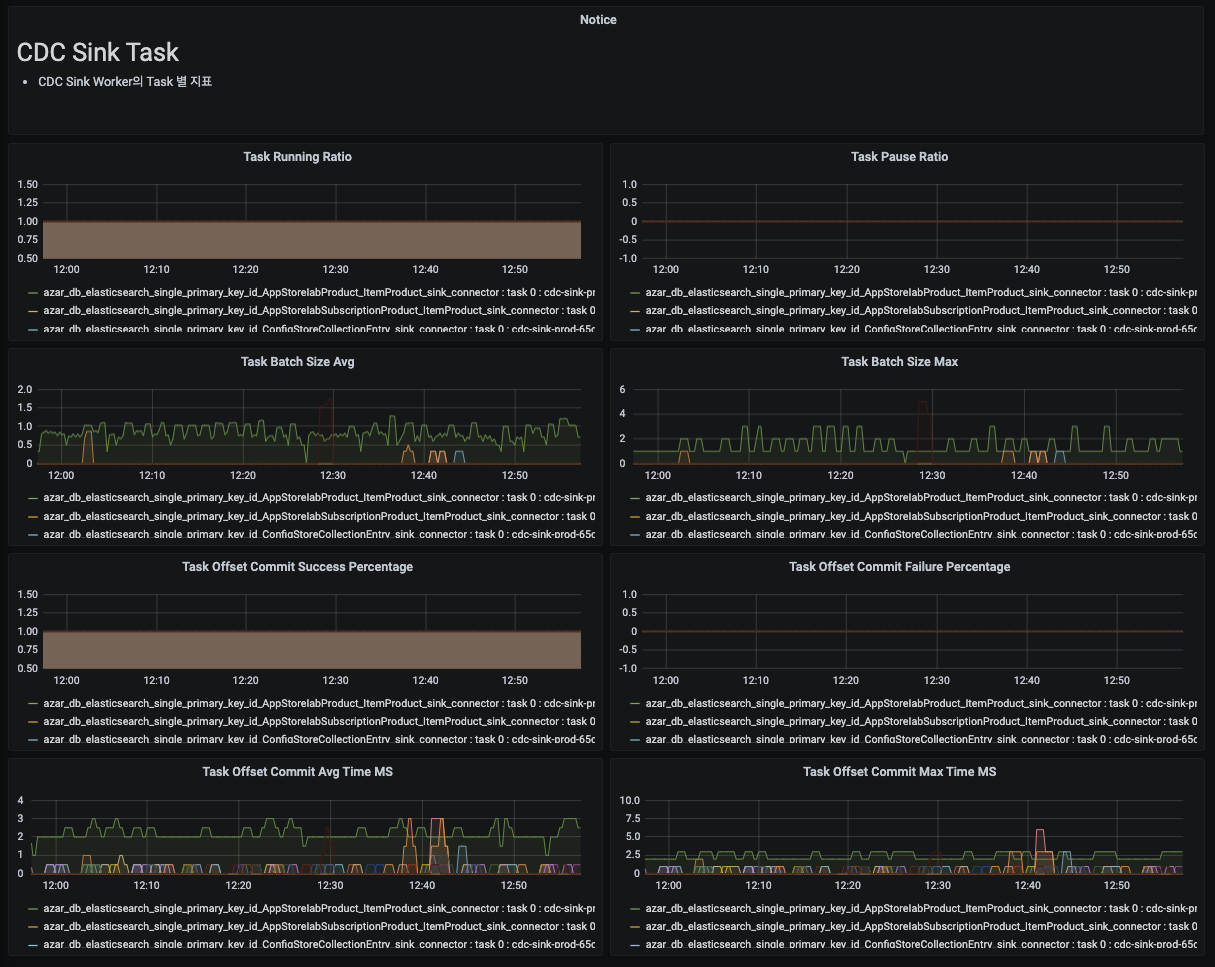
CDC Sink Cluster의 Task 별 지표를 제공합니다.
- 동작하고 있는 Task 목록
- Task Batch Size
- Task Offset Commit Success/Failure Percentage
- Task Offset Commit 소요 시간
CDC Sink Platform 활용 - 활용 사례
다음으로 위에서 구축한 CDC Sink Platform을 활용한 실제 사례에 대해 알아보도록 하겠습니다. 어떠한 요구사항이 있었고 요구사항의 기술적 어려움은 무엇인지 나아가 해당 요구사항을 해소하기 위해 어떤 설계와 구현을 선택하였는지 살펴보도록 하겠습니다.
CDC Sink Platform 활용 - CQRS Pattern의 구현
Admin에서 Full Text Search 즉, 통합 검색 기능을 지원해야 하는 요구사항이 있었습니다. 통합 검색을 지원해야 하는 데이터의 저장소는 RDB이며, RDB는 OLTP 환경에서 ACID 보장을 위해 사용하고 있습니다. 원본 저장소인 RDB에서 직접 통합 검색을 수행할 수 있겠지만 RDB에서 사용하는 B-Tree 구조상 Full Text Search는 비효율적으로 동작합니다. 따라서 RDB에서 통합 검색을 지원하는 것은 자료구조상 적절하지 않았습니다. 이러한 문제를 해결하기 위해 Full Text Search를 효율적으로 수행할 수 있는 Inverted Index 기반의 검색엔진 도입을 고려하게 되었습니다.
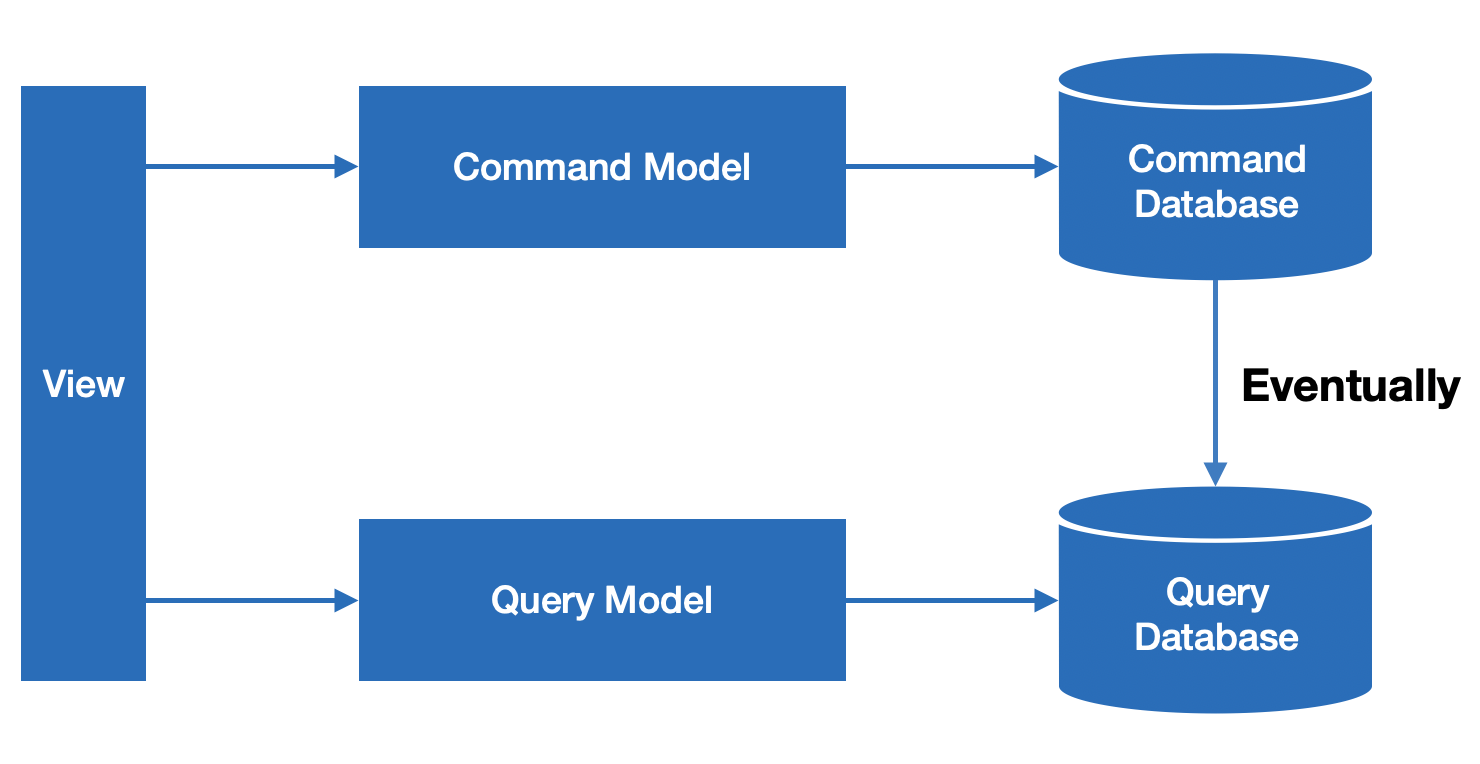
- CQRS Pattern ?
- Command and Query Responsibility Segregation
- 즉, 명령과 조회의 책임을 분리하는 것을 의미합니다.
- CQRS Pattern의 구현
- Full Text Search 요구사항에 대해 Inverted Index 기반의 검색 엔진을 활용하여 검색 기능을 제공
- Full Text Search Time Complexity
- 기존 - B-Tree
- O(N)
- 개선 - Inverted Index
- O(1)
- 기존 - B-Tree
CDC Sink Platform 활용 - CQRS Pattern의 구현 : Sink Connector 등록
CQRS 패턴을 구현하기 위해 먼저 검색에 적합한 자료구조에 지속적으로 데이터를 적재하는 흐름을 만들어내야 합니다. 이를 위해 위에서 구축한 CDC Sink Platform에 Sink Connector를 등록해야합니다. Sink Connector 등록 Script를 살펴보겠습니다.
아래 스크립트와 같이 ElasticSearch Sink Connector에 필요한 정보를 작성하여 API를 통해 CDC Sink Platform에 등록해야합니다. 또한, 필요 시 ElasticSearch Schema를 함께 초기화하여 색인 전략을 ElasticSearch에 등록해야 합니다. Full Text Search를 위해서는 ElasticSearch에 검색 요구사항에 적절한 Inverted Index가 구성되어야 하기 때문입니다. 따라서, 요구사항에 적합한 Inverted Index를 구성하기 위해 Tokenizer는 Whitespace를 사용하였으며, Token Filter는 NGram을 사용하여 색인하였습니다.
지난 CDC Platform에서 발행한 이벤트 중, Full Text Search가 필요한 특정 Kafka Topic을 대상으로 작성하였습니다. ElasticSearch Document의 Document Id는 ES에서 자동 생성하는 Key가 아닌 해당 Database Table의 PrimaryKey인 id를 기준으로 추출하여 사용하였습니다. 위 검색 요구사항의 경우 Event Sourcing Pattern에는 적합하지 않았습니다. 따라서, 특정 Primary Key를 기준으로 중복 제거 및 최신 데이터로 업데이트 되어야 하기에 “write.method”: “upsert”를 통해 Upsert로 동작하도록 구성하였습니다.
#!/bin/sh
## Argument Validation
if [ "$#" -ne 4 ]; then
echo "$# is Illegal number of parameters."
echo "Usage: $0 [cdc_sink_url] $1 [elasticsearch_url] $2 [database_name] $3 [second_database_name]"
exit 1
fi
# Define variables
args=("$@")
cdc_sink_url=${args[0]}
elasticsearch_url=${args[1]}
database_name=${args[2]}
second_database_name=${args[3]}
target_topics=(
cdc-data.azar.${database_name}.StringLocalizationV2
)
# Check elasticsearch schema initialization enabled
if [ -z "$ELASTICSEARCH_SCHEMA_INITIALIZATION_ENABLED" ]; then
ELASTICSEARCH_SCHEMA_INITIALIZATION_ENABLED="true"
fi
# Check cdc sink connector initialization enabled
if [ -z "$CDC_SINK_CONNECTOR_INITIALIZATION_ENABLED" ]; then
CDC_SINK_CONNECTOR_INITIALIZATION_ENABLED="true"
fi
# Create elasticsearch analyzer for using NGRAM
if [ "x$ELASTICSEARCH_SCHEMA_INITIALIZATION_ENABLED" = "xtrue" ]; then
for target_topic in ${target_topics[@]}; do
response=$(curl -X PUT -H "Accept:application/json" -H "Content-Type:application/json" --silent --write-out "HTTPSTATUS:%{http_code}" $elasticsearch_url/$(echo $target_topic | awk '{print tolower($0)}') -d '{
"settings": {
"index.number_of_replicas": 3,
"index.max_ngram_diff": 8,
"analysis": {
"analyzer": {
"fulltext": {
"tokenizer": "whitespace",
"filter": ["ngram_filter", "unique"]
}
},
"filter": {
"ngram_filter": {
"type": "ngram",
"min_gram": 2,
"max_gram": 10
}
}
}
},
"mappings": {
"dynamic_templates": [
{
"token_regex": {
"match_mapping_type": "string",
"match_pattern": "regex",
"match": "(?i).*token.*",
"mapping": {
"type": "keyword",
"ignore_above": 256
}
}
},
{
"json_regex": {
"match_mapping_type": "string",
"match_pattern": "regex",
"match": "(?i).*json.*",
"mapping": {
"type": "keyword",
"ignore_above": 256
}
}
},
{
"base64_regex": {
"match_mapping_type": "string",
"match_pattern": "regex",
"match": "(?i).*base64.*",
"mapping": {
"type": "keyword",
"ignore_above": 256
}
}
},
{
"hash_regex": {
"match_mapping_type": "string",
"match_pattern": "regex",
"match": "(?i).*hash.*",
"mapping": {
"type": "keyword",
"ignore_above": 256
}
}
},
{
"other_strings": {
"match_mapping_type": "string",
"mapping": {
"type": "text",
"analyzer": "fulltext",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
]
}
}')
body=$(echo $response | sed -e 's/HTTPSTATUS\:.*//g')
status=$(echo $response | tr -d '\n' | sed -e 's/.*HTTPSTATUS://')
echo "\nElasticSearch Response Code : $status\n"
echo "\nElasticSearch Response Body : $body\n"
if [ $status -ge 500 ]; then
echo "ElsticSearch Server Error"
exit 1
fi
done
fi
# Primary Key Name == id를 Key로 추출, Key : Value로 ElasticSearch 저장
if [ "x$CDC_SINK_CONNECTOR_INITIALIZATION_ENABLED" = "xtrue" ]; then
curl -f -i -X PUT -H "Accept:application/json" -H "Content-Type:application/json" ${cdc_sink_url}/connectors/azar_db_elasticsearch_single_primary_key_id_StringLocalizationV2_sink_connector/config -d '{
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "'$(IFS=, ; echo "${target_topics[*]}")'",
"connection.url": "'${elasticsearch_url}'",
"transforms": "unwrap,extract",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false",
"transforms.extract.type": "org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.extract.field": "id",
"connection.compression": "true",
"linger.ms": "50",
"batch.size": "2000",
"max.buffered.records": "10000",
"max.retries": "20",
"connection.timeout.ms": "5000",
"read.timeout.ms": "30000",
"flush.timeout.ms": "30000",
"key.ignore": "false",
"behavior.on.null.values": "delete",
"behavior.on.malformed.documents": "warn",
"errors.tolerance": "all",
"errors.log.enable": "true",
"errors.log.include.messages": "true",
"type.name": "_doc",
"drop.invalid.message": "true",
"write.method": "upsert"
}'
fi
CDC Sink Platform 활용 - CQRS Pattern의 구현 : 검색 기능 개발
현재 사내 Backend API 시스템은 JVM 기반의 Kotlin 그리고 Spring Framework를 공통 기술 스택으로 사용하고 있습니다. 이러한 환경에서 ElasticSearch 검색 기능을 쉽게 통합하기 위해 spring-boot-starter-data-elasticsearch를 사용하였습니다. 이를 통해서 사용자는 ElasticSearch Sink Connector를 통해 ElasticSearch로 적재된 데이터를 검색할 수 있습니다. 데이터를 검색하는 Repository 구현을 살펴보면 아래와 같습니다.
Scroll 기반이 아닌 단순 페이징 기능을 제공하며, ElasticSearch를 기반으로하는 검색 기능을 제공합니다. Bool Query를 사용하며 Score 계산 없이 효율적으로 Inverted Index를 검색합니다. 이를 통해 사용자는 찾고자 하는 텍스트에 대해 빠르게 검색 가능합니다.
import org.springframework.data.domain.Page
import org.springframework.data.domain.Pageable
import org.springframework.data.elasticsearch.annotations.Query
import org.springframework.data.repository.PagingAndSortingRepository
interface LocalizationSearchRepository : PagingAndSortingRepository<Localization, Long> {
@Query("""
{
"bool": {
"filter": [
{
"multi_match": {
"query": "?0",
"type": "cross_fields",
"analyzer": "whitespace"
}
}
]
}
}
""")
fun findBy(query: String, pageable: Pageable): Page<Localization>
}
Serialization & Deserialization
앞서 CDC Platform에서 Event의 Schema 정보를 Kafka에 전송하는 Data에 넣지 않고 Schema Registry를 통해 관리하도록 설정했다면 이벤트를 소비하는 CDC Sink Platform도 Deserialization을 위해 Schema Registry를 사용해야 합니다. CDC Platform에서 Apache Avro를 기반으로하는 io.confluent.connect.avro.AvroConverter를 사용하기 때문에 CDC Sink Platform에서도 이를 사용합니다.
Throughput
Sink Connector는 tasks.max 설정을 통해 N개의 task를 가질 수 있습니다. Sink Connector의 task는 Kafka Topic의 Partition과 매핑됩니다. 따라서, 처리량을 줄이고 싶으면 task 개수를 줄이고 처리량을 늘리고 싶으면 task 개수를 늘려 처리량을 조절할 수 있습니다. 이는 Producer의 발행량보다 Consumer의 소비량이 부족한 상황에서 반드시 고려되어야 합니다. Consumer Lag이 지속 발생하여 Kafka Topic의 retention.ms을 지나게 될 경우 이벤트가 소실될 수 있어 유의해야합니다.
만약, 근본적으로 Partition 개수가 적어서 처리량이 부족한 것이라면 Kafka Topic의 Partition 개수를 늘리는 방향을 고민해야 합니다.
At-least-once Delivery
CDC Platform의 Producer는 At-least-once Delivery를 지원합니다. 따라서, 동일한 이벤트가 중복되어 Kafka로 전송이 가능합니다. 이에 따라 Consumer는 이벤트의 중복 발행 가능성을 인지하고, 중복 제거가 필요하면 Consumer에서 이를 처리해야 합니다. 중복 제거 기법은 각 비지니스에 따라 달라지며 일반적으로 유일성을 보장하는 식별자를 기준으로 중복을 제거할 수 있습니다. 간단한 예시로는 Auto Increment Primary Key, UUID Primary Key, Composite Primary Key, Transaction Id 등 다양한 유형의 식별자가 있습니다.
Data Structure 재설계 관점
먼저, 흔히 범할 수 있는 좋지 않은 데이터베이스 사용 예시를 알아보고 CDC Pattern을 활용함으로써 얻을 수 있는 장점을 살펴보겠습니다.
A 조직은 자신의 비지니스에 적합한 형태로 자료구조 즉, 데이터베이스가 설계되어 있으며 자기 자신의 비지니스에 적합한 조회 패턴으로 인덱스가 설계되어있습니다. B 조직에서는 A 조직에서 다루는 데이터가 필요하며 A 조직의 조회 패턴과는 다른 형태의 조회 요구사항이 발생합니다. 따라서 B 조직은 A 조직에게 자신의 비지니스에 적합한 인덱스 추가를 요청하게 되며, A 조직은 타 조직의 요구사항임에도 불구하고 자신의 데이터베이스에 인덱스를 추가하게 됩니다. 이후, C, D 조직이 동일한 A 조직의 데이터를 조회해야 하는 추가 요구사항이 발생합니다. C, D 조직의 조회 패턴은 서로 다르며 A 조직은 자신의 데이터베이스에 타 조직에 필요한 인덱스를 또 다시 추가하게 됩니다. 이러한 부분은 좋지 않은 설계 방식으로 불필요한 인덱스의 추가로 인해 Write Performance를 저하시키고 타 조직의 비지니스에 의존성이 생겨 확장성이 떨어지게 됩니다.
이러한 조직간 강결합이 생기는 상황 속에서 CDC Pattern을 활용한다면 각 조직은 필요시 CDC Event를 Consuming하여 자신의 비지니스와 자신의 조회 패턴에 적합한 자료구조를 구축하여 더 나은 성능과 확장성을 제공받을 수 있습니다.
그래서 CDC Sink Platform은 언제 사용해야 적합한가요?
지속적으로 Data를 Migration 하는 작업에 적합합니다.
여기서 Migration이란 CDC Event를 활용하여 최종 일관성을 기반으로 DataSource간의 동기화를 하는 모든 행위를 의미합니다. 이러한 개념을 확장해보면 위에서 예시로 사용한 Full Text Search 기능을 위해 CQRS Pattern을 적용한 부분 역시 Migration이라고 볼 수 있습니다. 나아가 Data Lake를 구축하기 위해 Google BigQuery에 모든 변경사항을 적재하는 것과 같이 여러 방면으로 확장성 높게 활용할 수 있습니다.
또한, Monolitic Architecture에서 MicroService Architecture로 전환하기 위해 DataSource를 분리하는 작업에도 이를 활용하면 Migration을 위한 복잡한 Application Code를 작성하지 않고 간단하게 Migration 작업이 가능합니다.
결론
CDC Sink Platform을 활용하면 소스 코드 개발 없이 임의의 DataSource로 데이터를 지속적으로 적재하는 흐름을 쉽게 만들어 낼 수 있습니다. 만약, 복잡한 수준의 데이터 핸들링이 필요할 경우 CDC Sink Platform을 활용하지 않고 Application에서 Kafka Event를 직접 Consuming하여 비지니스를 처리하는게 자유도 측면에서 더 적절합니다.
CDC & CDC Platform 이야기
[1] 1편 - CDC Platform 개발
[2] 2편 - CDC Sink Platform 개발 : CQRS 패턴의 적용
[3] 3편 - CDC Event Application Consuming : Event Stream Join의 구현
Reference
[1] Confluent Hub
[2] Kafka Connect REST API
[3] Grafana Dashboard For Monitoring Debezium MySQL Connector
Read more
-
Global Media Management System 개발
전세계에 위치한 사용자에게 Media Management System을 제공한 사례에 대해 소개합니다 -
CDC & CDC Sink Platform 개발 3편 - CDC Event Application Consuming 및 Event Stream Join의 구현
CDC Platform에서 발행한 CDC Event를 Application에서 직접 Consuming하여 처리한 사례에 대해 소개합니다. -
CDC & CDC Sink Platform 개발 1편 - CDC Platform 개발
CDC Platform을 개발하고 활용한 사례에 대해 소개합니다.