비용 효율적인 Click-Through Rate Prediction 모델로 하쿠나 라이브 추천시스템 구축하기
안녕하세요, AI Lab에서 Machine Learning Engineer 로 근무 중인 이준영입니다. 이번 포스트에서는 하쿠나 라이브에 들어가는 추천엔진에 대해 소개드리고자 합니다. 추천은 많은 서비스들에서 유저들의 앱 내 참여도를 개선하고, 결국에는 리텐션을 개선한다고 알려져 있습니다. 많은 서비스들은 보편적으로 주요 KPI(Key Performance Index)를 올리기 위해 서비스 초기에는 인기도에 기반한 추천을 제공하고, 그 이후에 축적된 로그를 기반으로 개인화된 추천을 적용합니다. 저희 하이퍼커넥트에서 개발 중인 하쿠나 라이브가 급속도로 성장함(기사)에 따라, 하쿠나 라이브에서도 역시 여러 유저들의 취향을 반영하는 개인화된 추천을 위해 노력하고 있습니다.
Problem Formulation
처음에는 개인화 추천을 위해 EDA(Exploratory Data Analysis)를 통해 만들어진 휴리스틱한 룰을 배포했는데요. 저희가 수행했던 업무는 이 휴리스틱한 룰을 기계 학습 모델을 통해 개선하는 것이었습니다. 클릭 수, 시청 시간, 팔로우 수 등 개선해야 할 지표들이 여러 가지가 있었는데, 저희는 이 중에서 클릭 수를 높이는 데 집중하기로 했습니다. 클릭이 되지 않으면 시청 시간도 발생하지 않고, 팔로우도 발생하지 않기 때문에 일단 클릭 수를 높이는 것이 중요하다고 판단했기 때문입니다. 그래서, 클릭될 확률을 예측하는 Click-Through Rate(CTR) Prediction Task를 탐구해보기로 결정했습니다.
Model Staleness Problem in Recommender System
한편, 추천 모델에는 staleness problem이 존재한다고 알려져있습니다. staleness problem이란, 말 그대로 모델이 상한다는 뜻인데요. 모델 학습 이후에 앱 내 유저 군의 특성이 변화함에 따라 추천 모델 입력 데이터의 분포가 변하게 되고, 이에 따라 기존 추천 모델의 성능이 지속적으로 하락하는 현상을 의미합니다. 매일매일 신규로 유입되는 유저들의 성향이 달라지게 되면, 서비스 내 유저들의 행동 패턴이 달라지기 때문에 staleness problem이 발생한다고 알려져 있습니다. 추천 엔진에서 staleness problem을 해결하는 여러 가지 방식들이 있지만, 저희는 주기적으로 모델을 재학습하는 것이 가장 간단하고 안정적으로 추천 모델을 서빙할 수 있는 방법이라고 판단했습니다.
주기적으로 모델을 재학습하기 위해서는 하이퍼 파라미터에 민감하지 않은 모델을 사용하거나, 하이퍼 파라미터를 자동으로 찾는 기법들을 사용할 필요가 있었습니다. 저희가 만든 추천 엔진이 서비스 내 얼마나 큰 임팩트를 만들어낼지 아직 감이 없는 상황이었기 때문에, 많은 비용을 들여서 매일매일 하이퍼파라미터 튜닝을 진행하기 보다는 하이퍼 파라미터에 민감하지 않은 모델을 찾기로 결정했습니다.
Model Exploration
어떤 모델이 저희 서비스 데이터 셋에서 잘 동작하고, 또 하이퍼 파라미터에 민감하지 않을지는 직접 테스트 해보는 방법 밖에 없었습니다. CTR Prediction Task를 수행하는 모델들에 대한 문헌 연구를 진행했고, 구현체들을 찾아보면서 FM, FFM, DeepFM 등 수십 개의 CTR Prediction 모델들을 테스트해보았습니다. 수십 개의 모델 각각이 하이퍼파라미터에 민감한지 체크하는 것은 너무 시간이 오래 걸리는 작업이기에, 논문에서 제시한 기본 하이퍼파라미터를 기준으로 각 모델의 성능을 비교하였습니다. 여러 CTR Prediction 모델들 중에서 FFM이 그나마 좋은 성능을 보여주기는 했지만, 안타깝게도 이미 있던 휴리스틱과 비교해 만족할만한 성능 개선을 얻지 못했는데요. 그래서 다른 방향의 Model Exploration이 필요했습니다.
CTR Prediction via Gradient Boosting
저희가 주목했던 점은 여러 Data Competition에서 XGBoost, LightGBM, CatBoost와 같은 Gradient Boosting 모델들이 베이스라인으로 흔하게 사용되고 CTR Prediction Task 역시 Gradient Boosting으로 해결할 수 있는 문제임에도 불구하고, 최신 state-of-the-art CTR Prediction 연구들에서는 Gradient Boosting Models이 베이스라인으로 잘 다뤄지지 않는다는 것이었습니다. 저희는 그래서 Gradient Boosting으로 CTR Prediction을 수행해보았습니다.
고전적인 Categorical Feature Encoding 방법
CTR Prediction Task는 입력 데이터에 유저의 인덱스, 유저의 성별, 나이 그룹 등 categorical feature가 다수 포함되어 있습니다. 하지만, 일반적으로 Gradient Boosting 은 numerical feature만을 처리할 수 있기 때문에, categorical feature들은 모두 numerical feature로 바꿔주어야 합니다. 일반적으로 categorical feature를 numerical feature로 바꿔야 할 때는 one-hot encoding이 흔하게 사용됩니다. 하지만, CTR Prediction에서는 유저의 인덱스와 같이 아주 높은 cardinality를 가지는 categorical feature들이 존재하는데, 이 feature들을 one-hot vector로 바꾸는 경우 입력 차원이 너무 과도하게 증가해 학습이 어려워집니다.
따라서, CTR Prediction을 Gradient Boosting 으로 수행하기 위해서는 높은 cardinality의 categorical feature를 사용하지 않거나, Label Encoding 혹은 Target Encoding을 통해 categorical feature를 numerical feature로 바꿔주는 방식을 사용해야 합니다. Label Encoding은 categorical feature를 임의의 숫자로 변경하는 방식입니다. 입력 차원을 유지하면서 Gradient Boosting 에서 사용할 수 있다는 장점이 있지만, 치환한 숫자의 크기가 어떠한 것도 의미하지 않기 때문에 치환된 numerical feature에 정보가 제대로 담기지 않는다는 단점이 있습니다. Target Encoding 은 어떤 categorical feature가 등장한 모든 데이터 인스턴스들의 출력 값의 평균으로 categorical feature를 치환하는 방법인데요. 예를 들면, 어떤 유저가 평균적으로 본 아이템 중 10%만을 클릭했다면, 그 유저의 인덱스를 0.1로 바꿔버리는 방식입니다. 해당 categorical feature가 등장하는 인스턴스들의 출력 값들의 평균이 워낙 강력한 시그널이다 보니, 오버피팅에 취약하다고 알려져 있습니다.
최신 Categorical Feature Encoding 방법
Label Encoding, Target Encoding 같은 고전적인 방법들의 문제를 해결하기 위해, 최근의 몇몇 연구들에서는 Gradient Boosting에서 사용할 수 있는 새로운 방식의 categorical feature encoding 방법들을 제시했습니다.
- LightGBM은 Gradient와 Hessian을 활용해 categorical feature의 optimal split을 찾는 방식을 제안했습니다.
- CatBoost에서는 Target Encoding의 오버피팅 현상을 막기 위해 random shuffle등을 통한 변형된 형태의 Target Encoding을 제안했고요.
- K-fold cross validation을 통해 Target Encoding의 오버피팅을 해결한 K-Fold Target Encoding과 XGBoost가 조합된 방식이 제안되기도 했습니다.
새롭게 제시된 방식들이 CTR Prediction에서의 극도로 cardinality가 높은 categorical feature를 핸들링하기 위해 제시된 방법은 아니지만, CTR Prediction의 baseline으로 사용해볼만한 가치는 있다고 판단했습니다. 그리고, 저희의 실험 결과 최신 categorical feature encoding과 Gradient Boosting을 같이 사용한 결과는 놀라웠습니다.
Offline Experiments
Performance Comparison
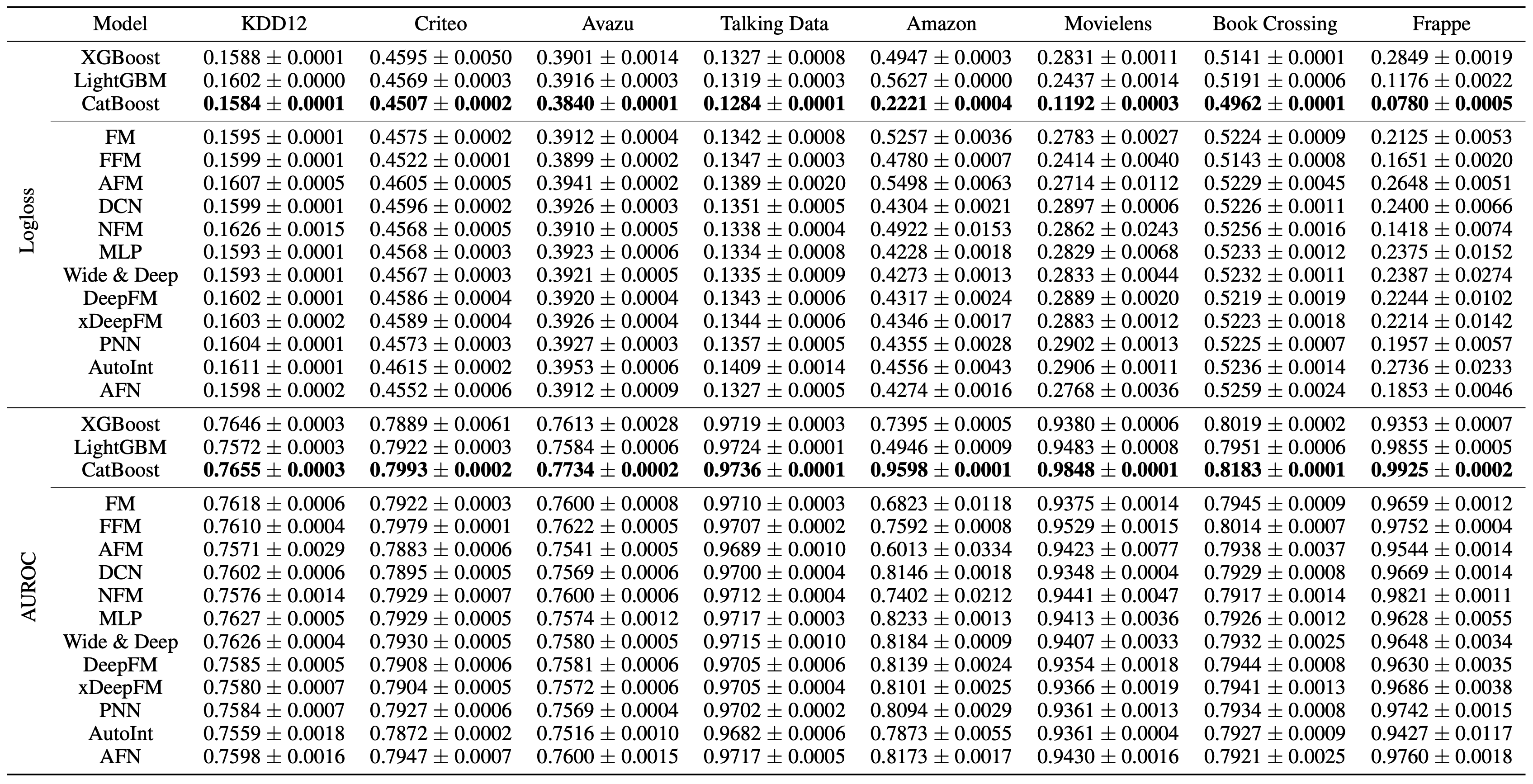
아래 Table은 8개의 public benchmark dataset에 널리 사용되는 12개의 CTR Prediction models 과 3개의 gradient boosting 모델들을 비교한 결과입니다. 보시는 것처럼 gradient boosting 모델들이 기존 CTR Prediction model들의 성능을 압도하는 것을 확인할 수 있습니다. 저희 데이터셋에서도 상당히 비슷한 경향성을 보였습니다.
 |
|---|
| Evaluation results of three tabular learning models and twelve CTR prediction models on eight real-world datasets. Logloss and AUROC with 95% confidence interval of 10-runs is provided. |
Efficiency Comparison
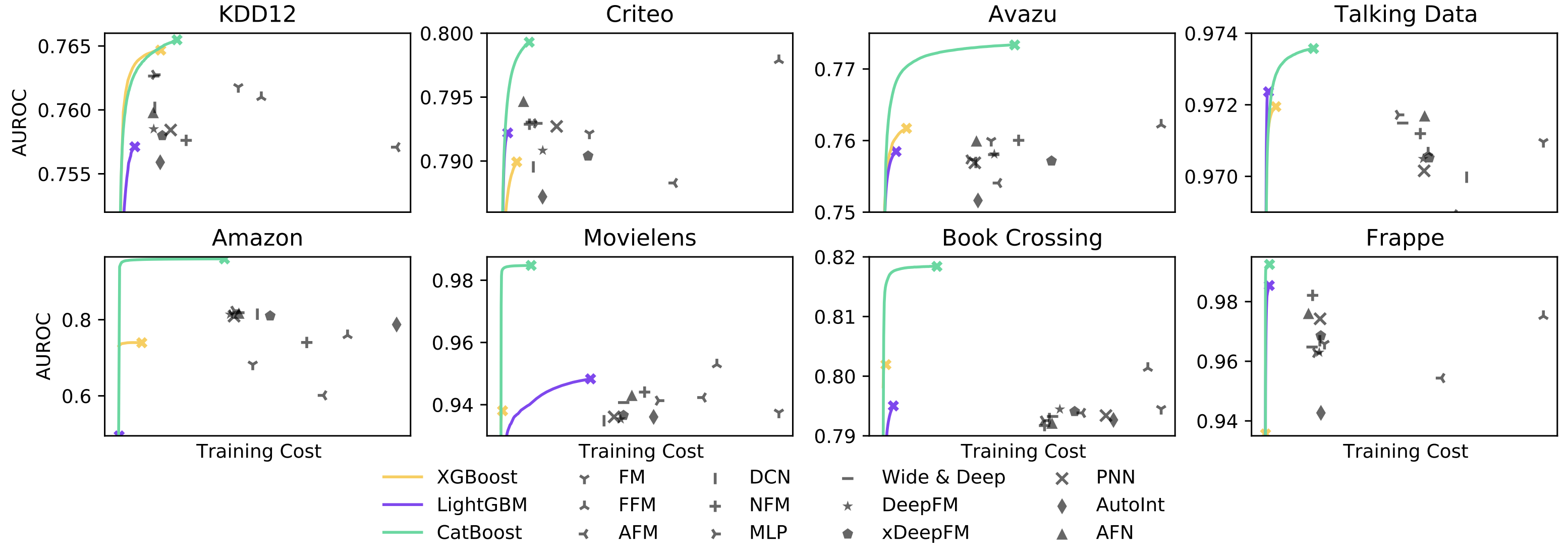
Gradient Boosting은 학습 비용 측면에서도 기존 CTR Prediction 모델들에 비해 효율적인데요. 주기적으로 재학습을 해주는 방식으로 모델을 배포하기로 결정했기 때문에, 비용 효율적인 모델을 사용하는 것이 중요했습니다. 아래 그림은 AWS instance 비용 대비 AUROC 성능을 각 모델에 대해 그린 결과입니다. Gradient Boosting 모델들이 학습에 드는 비용이 적으면서도 더 좋은 AUROC 성능을 보여주는 것을 확인할 수 있었습니다.
 |
|---|
| AUROC by training cost estimated on AWS EC2 instances. |
Ablation Study
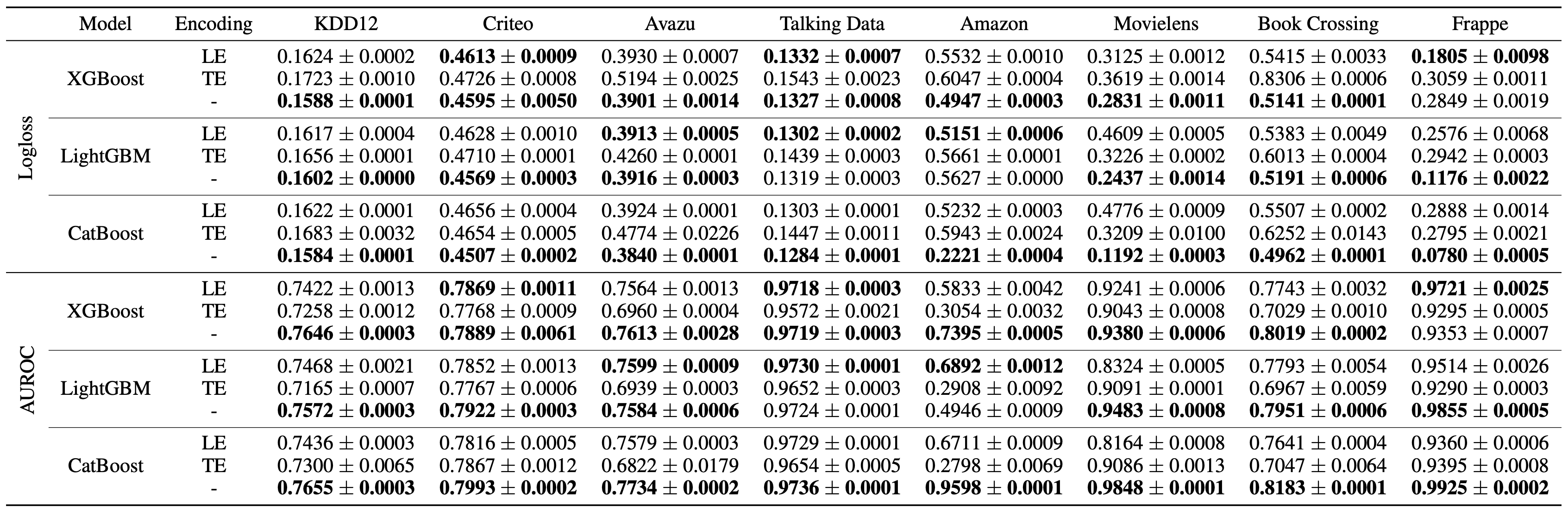
최근의 categorical feature encoding 방법들이 성능에 어느 정도 기여했는지를 체크해보기 위해 ablation study도 진행했는데요. 최신 categorical feature encoding 방법을 사용하지 않고 Label encoding이나 Target encoding과 같은 고전적인 방식을 사용하면 성능이 어떻게 변화하는 지 확인해보았습니다. 아래 Table에서 보실 수 있는 것처럼, 대부분의 경우에서 최신 categorical feature encoding을 사용하는 것이 중요했고, 특히 가장 성능이 좋았던 CatBoost에서는 모든 경우에서 최신 categorical feature encoding 기법을 사용하는 것이 중요했습니다.
 |
|---|
| Ablation study results of three tabular learning models regarding to encoding methods of categorical features. Logloss and AUROC with 95% confidence interval of 10-runs is provided. |
Online Deployment
오프라인 실험 결과들을 토대로 최종 모델로 CatBoost가 선택되었습니다. 그리고, 이 모델을 실제 배포해 유저들에게 추천을 제공했습니다. 기존 휴리스틱한 룰과 된 마나 성능이 차이나는 지 알아보기 위해 A/B Testing 을 진행한 결과, 하쿠나 라이브의 두 개의 주요 지역에서 각각 59.47% 와 84.96% 의 높은 CTR gain을 얻을 수 있었습니다.
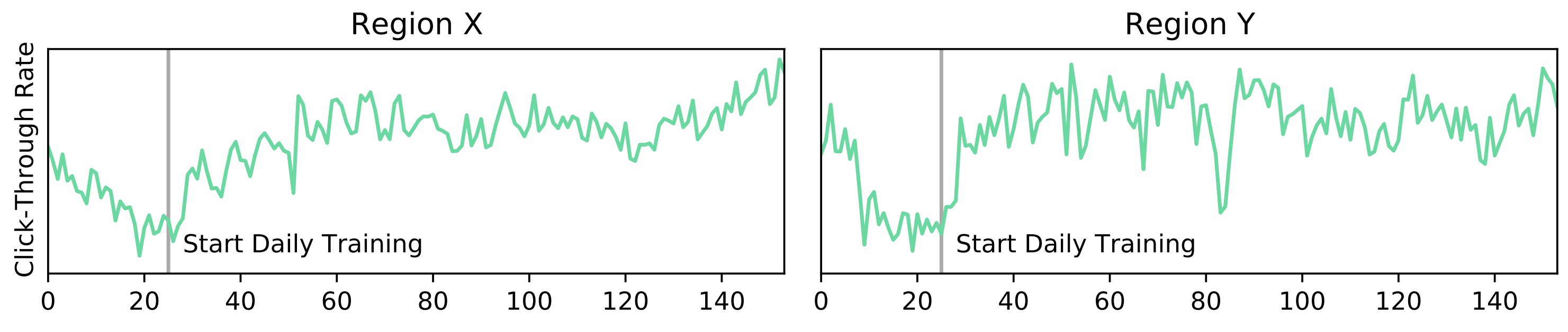 |
|---|
| Alleviating staleness problem by daily training with CatBoost. CTR over time after first model deployment on two main regions X and Y of our application is plotted. |
마지막으로, 위 그림은 하쿠나 라이브의 두 개의 주요 지역에서 날짜에 따른 CTR 성과를 그린 그래프입니다. 첫 모델 배포 이후 주기적으로 재학습하는 파이프라인이 갖춰지지 않아 지속적으로 성능이 감소하는 staleness problem이 나타난 것을 확인할 수 있었습니다. 그리고, 주기적인 재학습을 시작하니 다시 성능이 높은 수준으로 지속적으로 유지되는 것을 확인할 수 있었습니다. 다시 말해, 저희는 CatBoost를 이용해 추천 모델 학습 및 배포 파이프라인을 구축함으로써 지속적으로 높은 성능을 나타내는 추천 엔진을 비용 효율적으로 구축할 수 있었습니다.
마치며
본 포스트에서 저희가 어떤 과정을 통해 하쿠나 라이브 내 추천 엔진을 개발하고, 배포했는지에 대해 소개드렸는데요. 이번 포스트에서 소개해드린 연구 이후에도 더 좋은 성능을 내는 모델을 만들기 위해 추가적인 연구를 진행하고 있습니다. 더하여, 본 포스트에서 소개드린 내용은 ICLR 2021 Workshop 부문에서 발표될 예정입니다(링크). 저희 AI Lab에서는 서비스 내 문제를 기계 학습 모델을 통해 해결하고, 실제 논문까지 쓰는 경험을 원하는 분들을 상시적으로 채용하고 있으니 많은 지원 부탁드립니다.
Read more
-
비즈니스 문제를 AI 문제로 정렬하는 방법
최적화 이론의 완화(relaxation) 개념을 비즈니스 문제에 적용하여, 비즈니스 문제를 AI 문제로 정렬하는 방법을 소개합니다. -
아자르에서는 어떤 추천 모델을 사용하고 있을까?
아자르의 1:1 비디오 채팅에 사용되는 추천 모델 CUPID를 소개합니다. -
협업 필터링을 넘어서: 하이퍼커넥트 AI의 추천 모델링
하이퍼커넥트 AI 조직이 추천 시스템에 협업 필터링(collaborative filtering)을 넘어 어떤 모델링을 적용하고 있는지 소개합니다. -
Behind the Paper: 하이퍼커넥트 AI 조직이 제품에 기여하면서 연구하는 법
하이퍼커넥트 AI 조직이 어떻게 연구를 통해 제품에 기여하고 논문까지 출판하는지 소개합니다.