Azar Mirror 서버 제작기 3편 - 개발자편
안녕하세요, Backend Dev 1팀의 Fitz입니다.
1편에서는 Mirror 서버에 대해 설명하고, 2편에서는 Devops 팀의 관점에서 트래픽을 미러링한 방법을 소개했었습니다. 이 글에서는 이전 글에 이어서 Mirror 서버를 개발하면서 read-only 서버를 개발한 경험, 마이크로서비스로 가는 중복 트래픽을 처리한 경험을 공유합니다.
read-only 아자르 서버 만들기
데이터베이스 중복 요청 문제
1편에서 동일한 요청에 대하여 동일한 처리를 한다 라는 요구사항이 있고, 이 요구사항을 만족시키기 위해서는 동일한 데이터베이스를 사용해야 한다 라는 내용이 있었습니다.
하지만 트래픽을 미러링하는 서버가 동일한 데이터베이스에 동일한 요청을 한 번 더 수행하게 되면, 해당 요청이 idempotent 하지 않은 경우 원본 데이터가 잘못될 가능성이 생기게 됩니다.
그래서 이 문제는 replication을 이용하여 해결했습니다. 원본 데이터베이스의 replica를 만들어서 mirror 서버가 이 데이터베이스를 사용하게 한다면, 동일한 데이터는 사용하면서도 원본 데이터베이스에는 영향을 끼치지 않는다는 것이 보장됩니다.
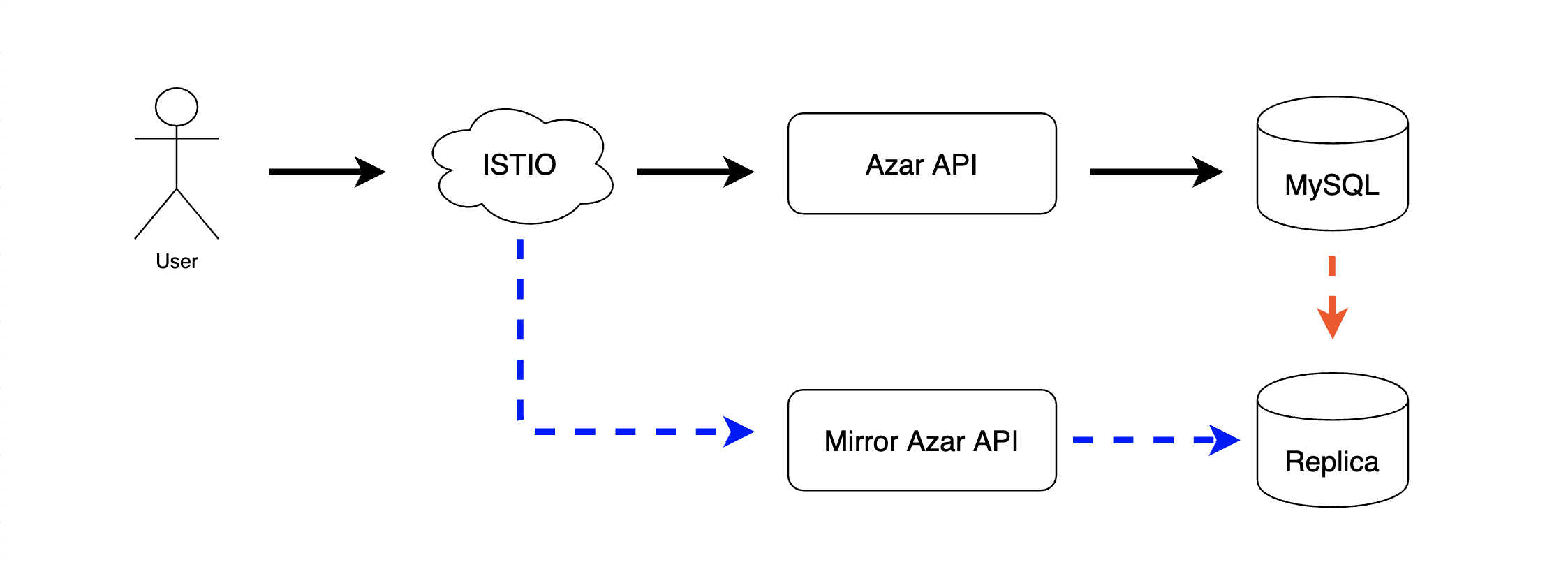
간혹 복제 지연의 문제로 데이터 불일치의 문제가 생길 수 있지만, 용인할 수 있는 수준의 빈도이고 원본 데이터에 영향을 끼치지 않는다는 것이 보장되는 것으로 인해 생기는 장점이 훨씬 크다고 판단하여 이 방식을 채택했습니다.
Replica의 한계로 인한 문제
replica는 읽기만 가능하기 때문에 쓰기를 할 수 없어 비지니스 로직이 잘 동작하지 않을 수 있습니다. 하지만 Azar API는 JPA를 사용하고 있기 때문에 이 문제를 해결할 수 있었습니다.
JPA에서는 비지니스 로직에서 데이터를 변경하는 경우 데이터베이스에 바로 쓰는 것이 아니라 1차 캐시에 들어 있는 엔티티의 값을 바꾸기 때문에 이를 이용해 읽기 전용인 replica 에 데이터 변경을 시도했을 때 발생하는 대부분의 에러를 제거할 수 있었습니다.
하지만 쓰기 동작을 1차 캐시에 수행하더라도 트랜잭션이 종료될 때 flush를 하는 과정에서 write 쿼리가 수행된다거나, native query를 사용하여 1차 캐시를 통하지 않고 바로 SQL을 실행시키는 등의 문제가 아직 남아 있어 단순히 JPA를 사용하는 것만으로는 데이터베이스로 날아가는 중복 write 쿼리를 완벽히 막을 수 없었습니다.
이런 문제들은 dummy write를 수행하는 클래스를 만들어 객체 구성을 대체함으로써 해결할 수 있었습니다.
JPA는 데이터베이스에 수행하는 행위들을 추상화하여 메소드로 제공합니다. 그리고 스프링을 사용한다는 가정하에 그 위 레이어에는 Spring Data JPA로 더 추상화가 되어있습니다.
추상화가 되어있다는 것은 구현체를 바꿔서 동작시키기에 유용하다는 것이므로 해당 레이어에 속한 클래스를 상속하여 read-only로 동작할 수 있게 수정하기로 했습니다.
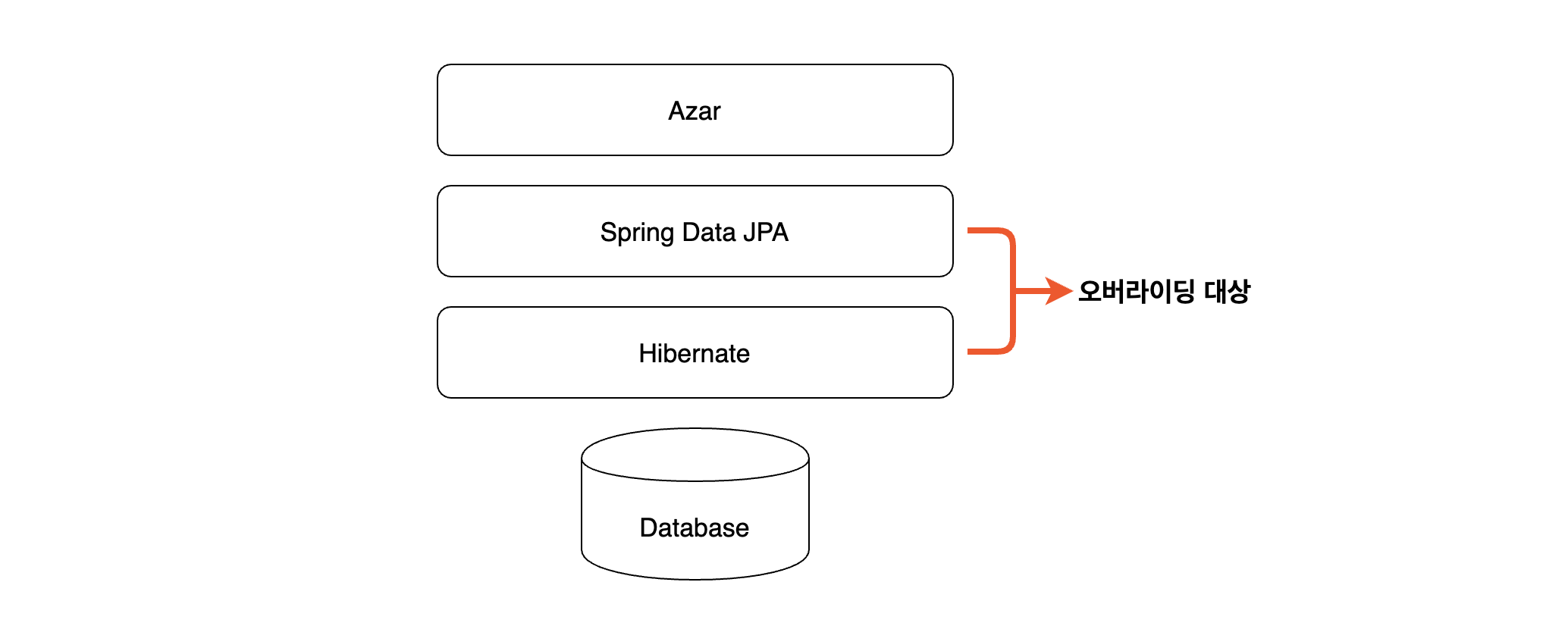
영속성 컨텍스트 flush
첫 번째 문제는 1차 캐시로 인해 미러의 비지니스 로직도 정상적으로 실제 테스트서버와 동일하게 수행되지만, 트랜잭션이 종료될 때 DB에 변경된 데이터가 flush 되면서 read-only MySQL에 실제 write 쿼리를 날리는 것입니다.
이를 해결하기 위해 미러의 각 트랜잭션을 시작할 때마다 flush 옵션을 MANUAL로 변경시켜 주어 트랜잭션이 종료되더라도 데이터베이스에 flush 하지 않도록 했습니다.
아래는 그 코드입니다. JpaTransactionManager를 override하여 begin 처리가 끝난 후에 FlushMode를 변경하도록 처리했습니다.
public class MirrorJpaTransactionManager extends JpaTransactionManager {
public MirrorJpaTransactionManager(EntityManagerFactory emf) {
super(emf);
}
@Override
protected void doBegin(Object transaction, TransactionDefinition definition) {
super.doBegin(transaction, definition);
EntityManagerHolder entityManagerHolder = (EntityManagerHolder) TransactionSynchronizationManager.getResource(obtainEntityManagerFactory());
EntityManager em = entityManagerHolder.getEntityManager();
if (em instanceof Session) {
((Session) em).setHibernateFlushMode(FlushMode.MANUAL);
}
}
}
Repository 클래스 override
또한 JPA의 Repository 클래스에서 save()를 호출할 경우 자동으로 generate된 새로운 id를 리턴해줘야 하고, saveAndFlush()를 호출하면 강제로 영속성 컨텍스트가 flush 되는 등의 문제가 있기 때문에 미러의 Repository 클래스 역시 override 해줄 필요가 있었습니다.
그래서 기본적으로 적용되는 SimpleJpaRepository 클래스를 오버라이딩하여 delete 등의 데이터를 변경하는 동작에 대한 메소드는 아무런 동작을 하지 않는 메소드로 override 하였고,
새로운 id를 리턴해줘야하는 save() 메소드는 타입에 따라 랜덤 값을 리턴해주도록 구현했습니다.
public class MirrorJpaRepository<T, ID> extends SimpleJpaRepository<T, ID> {
...
@Override
public <S extends T> S save(S entity) {
if (entityInformation.isNew(entity)) {
Arrays.stream(entity.getClass().getDeclaredFields()).forEach(field -> {
if (field.getAnnotation(Id.class) != null) {
...
Optional<ID> generatedValue = (Optional<ID>) RandomIdGenerator.generate(entityInformation.getIdType(), castedMaxValue);
if (generatedValue.isPresent()) {
ReflectionUtils.setField(x, entity, generatedValue.get());
}
}
});
}
return entity;
}
@Override
public <S extends T> S saveAndFlush(S entity) {
return save(entity);
}
}
개발한 JpaRepository 클래스는 아래와 같이 @EnableJpaRepositoies 어노테이션에 넘겨서 설정했습니다.
@EnableJpaRepositories(
repositoryBaseClass = MirrorJpaRepository.class,
repositoryFactoryBeanClass = MirrorJpaRepositoryFactoryBean.class,
basePackages = {"...", "..."}
)
@Profile("mirror")
public class MirrorJpaConfig {
...
}
위의 코드를 보면 @EnableJpaRepositories 어노테이션에 repositoryFactoryBeanClass 도 지정되어 있는 것을 보실 수 있습니다. @Query 어노테이션을 사용하는 등의 방식으로 JPQL과 Native Query를 사용해서 영속성 컨텍스트를 거치지 않고 바로 쿼리를 날리는 상황을 감지하여 쿼리를 날리는 대신, 쿼리가 성공했다는 값만 리턴하는 등의 동작을 정의하기 위함입니다.
이렇게 read-only로 만들기 위해 JPA의 여러 클래스들을 오버라이딩하여 사용하였고, 오버라이딩이 불가능한 클래스에는 팩토리 메소드를 오버라이딩하여 기존의 객체에 프록시를 입혀 요청을 가로채는 등의 여러 트릭을 사용하여 최대한 데이터베이스에 write 쿼리를 날리지 않도록 막았습니다.
모두 하나하나 소개하기에는 분량이 너무 많기에 이 정도로 소개하고 다음으로 넘어가겠습니다.
Redis, Stomp 등 read-only로 만들기
Azar API에서 사용하는 Lettuce, Redisson 같은 Redis 클라이언트들이나 자체적으로 제작한 Stomp 클라이언트 등의 클래스들도 역시 추상화가 잘 되어있었기 때문에 쉽게 오버라이딩하여 동작을 바꿔치기할 수 있었습니다.
JPA와 마찬가지로 클래스를 오버라이딩하여 Read만 하도록 만들어 write 동작을 하지 않도록 하였습니다.
예를 들면 Spring에서 자주 사용하는 클래스인 RedisTemplate의 일부인 delete 메소드는 아래와 같이 오버라이딩 했습니다.
public class ReadOnlyRedisTemplate<K, V> extends RedisTemplate<K, V> {
...
@Override
public Boolean delete(K key) {
return true;
}
@Override
public Long delete(Collection<K> keys) {
if (keys == null) {
return null;
}
return (long) keys.size();
}
}
이처럼 다른 클래스들도 API의 Document를 보고 인자와 리턴 값을 파악하여 적절한 값을 리턴하도록 오버라이딩 하여 요청을 중복으로 전송하거나, write를 하는 동작들을 막았습니다.
마이크로서비스로 가는 중복 요청 문제
위에 나왔던 방식대로 Azar API에서 사용하는 데이터베이스에 대한 write 동작들은 클래스를 오버라이딩하여 대체함으로써 해결할 수 있었습니다.
하지만 Azar는 마이크로서비스 아키텍처를 사용하고 있기 때문에 마이크로서비스 동작에 대해서도 쓰기 방지가 필요했습니다. 만약 마이크로서비스를 호출하는 메소드들을 이전의 방식과 동일하게 모두 오버라이딩 한다면 아래와 같은 문제점이 발생할 수 있습니다.
- 어떤 API에 쓰기 동작이 들어있는지 모두 구분해야 하기 때문에 고려해야 할 것들이 많아져서 유지보수성이 떨어집니다.
- 비즈니스 로직에 쓰기 동작이 하나라도 들어있다면 그 로직 자체를 더미로 만들어야 하므로 동일한 요청에 대한 동일한 동작을 보장하기가 힘듭니다.
- 의존하고 있는 마이크로서비스 API에 대한 동작을 모두 오버라이딩 해야 하므로 새로운 API가 추가되면 그것에 대응하는 Mirror에 대한 추가적인 작업이 필요해지기 때문에 확장성이 떨어집니다.
그래서 Azar API 컴포넌트 내부적으로 해결하기는 힘들고, 컴포넌트 외부에서 마이크로서비스 API 호출에 대한 어떤 처리가 필요하다는 결론을 내렸습니다.
mirror-cache 설계
Azar의 마이크로서비스들은 Kubernetes 환경에서 운영되고 있어서 트래픽의 핸들링이 용이하다는 장점이 있습니다. 그래서 Azar의 outbound 트래픽을 가로채어 원본의 응답을 캐싱한 다음, Mirror에게는 캐싱 된 응답을 보내주자라는 생각을 하게 되었습니다.
그에 맞춰서 아래의 그림과 같은 구조를 설계했고, 응답을 캐싱하여 돌려주는 컴포넌트의 이름을 mirror-cache라고 지었습니다. 노란 화살표는 원본의 요청을 나타내고, 초록색 화살표는 Mirror의 요청을 나타냅니다.
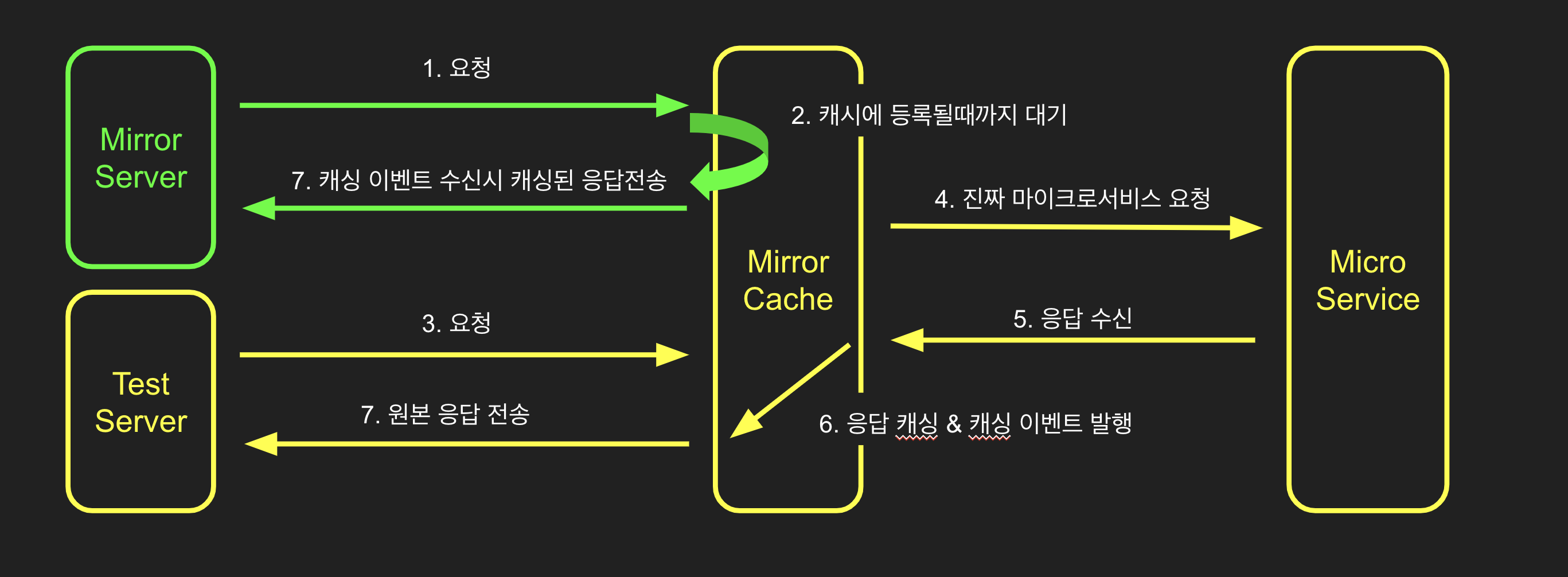
Test 환경과 Mirror 환경의 Azar에서 outbound 트래픽이 발생하면 istio가 그 트래픽을 mirror-cache로 라우팅을 해줍니다.
이 라우팅 작업은 devops 팀에서 도와주셨으며 자세한 내용을 보고 싶으시다면 Sammie 님이 작성하신 Azar Mirror 서버 제작기 2편 - Istio와 함께하는 Traffic Mirroring 글을 참조해보시길 바랍니다.
만약 Mirror의 요청이 mirror-cache에 먼저 도착한다면 원본의 요청이 처리될 때까지 대기하다가, 마이크로서비스에서 원본의 요청에 대한 응답을 돌려준다면 이 응답을 복제하여 Mirror 환경의 Azar API로 돌려줍니다.
요청 중계
mirror-cache는 트래픽 중계 컴포넌트이기 때문에 원본 요청과 응답의 HTTP 메시지 형식을 그대로 전송해줘야 합니다.
이것은 Spring의 추상화를 이용해서 해결했습니다. Spring은 요청과 응답의 형식을 RequestEntity와 ResponseEntity 클래스로 추상화해 두었고, 여러 방면에서 재사용하고 있습니다.
Controller에서 요청을 수신할 때 RequestEntity 클래스로 요청을 수신할 수 있고, RestTemplate은 RequestEntity를 이용하여 요청을 발송할 수 있습니다.
즉, 트래픽을 수신하는 형식과 전송하는 형식이 동일하기 때문에 수신한 요청을 그대로 전송하는 것이 가능해집니다. 그래서 이 클래스를 이용하는 것만으로 트래픽 중계 기능을 쉽게 구현할 수 있었습니다.
응답 캐싱
Mirror의 요청에는 캐싱된 응답을 전송하여야 하기 때문에 원본의 응답인 ResponseEntity에 대한 캐싱을 해줘야 합니다.
이 경우는 mirror-cache의 scalability를 위해 redis에 캐싱을 했습니다.
하지만 ResponseEntity 클래스는 immutable 클래스이기 때문에 역 직렬화 과정에서 문제가 발생하였고, 내부에 정의되어 있는 Map의 구조 때문에 기존의 역 직렬화 옵션으로는 해결이 불가능한 것을 확인했습니다.
그래서 이 부분은 클래스의 내용을 파악한 다음 Jackson의 MapDeserializer를 오버라이딩하여 사용하는 것으로 해결했습니다
동일한 요청의 구분
처음의 설계를 보면 mirror-cache는 동일한 요청에 대해 발생한 마이크로서비스 호출을 캐싱한다는 요구사항이 있는데 동일한 요청의 기준을 잡는 것도 문제였습니다.
비지니스 로직에 따라 동일한 요청을 보내더라도 응답의 내용은 달라질 수 있기 때문에 요청에 들어있는 값만 가지고는 구분에 한계가 있을 수밖에 없었습니다.
하지만 이 또한 istio의 기능으로 해결할 수 있었습니다. Istio는 모든 요청마다 고유한 값을 부여하여 x-request-id라는 HTTP 헤더로 삽입해 주기 때문에 해당 값을 이용하여 동일한 요청을 인식할 수 있었습니다.
하지만 이 헤더의 값은 Azar API 내부에서만 유효하고, 이후에 Azar API에서 RestTemplate이나 WebClient 클래스를 이용하여 마이크로서비스에 요청을 전송할 때에는 이 값을 함께 전송하지 않기 때문에 x-request-id 헤더의 값이 유실된다는 문제가 있었습니다.
그래서 Azar API에서 요청으로 받은 x-request-id 헤더를 보관해두었다가 이후에 마이크로서비스를 호출할 때 헤더에 동일하게 x-request-id 값을 넣어줄 필요가 생겼습니다.
처음에는 임시적으로 헤더를 ThreadLocal에 저장하는 모듈을 개발하여 RestTemplate과 WebClient bean의 설정에 헤더를 전파하는 기능을 추가해 해결했습니다.
하지만 Azar API의 코드 내부에 코드가 돌아가는 환경에 대한 의존성이 생기기 때문에 이때부터 자바 에이전트를 이용하여 외부에서 로직을 주입하는 것에 대한 필요성을 느끼게 되었고, 추후 istio distributed tracing에 대응하는 기능을 개발하면서 헤더 전파에 대한 로직을 자바 에이전트로 개발하여 대체하였습니다.
자세한 내용은 Kubernetes 환경을 위한 자바 에이전트 개발기 글을 참조해주시기 바랍니다.
헤더 전파까지 가능해졌기 때문에 요청마다 고유한 ID를 사용할 수 있게 되었고, 다른 값들과 조합하여 동일한 요청에 대한 구분을 할 수 있게 되었습니다.
원본과 Mirror에 대한 동시성 처리
mirror-cache는 원본 캐싱 후에 Mirror에 캐싱된 응답을 리턴한다 라는 컨셉이기 때문에 무조건 원본의 요청이 먼저 처리되어야 합니다.
그렇기 때문에 Mirror의 요청이 원본보다 먼저 mirror-cache에 도착했을 때를 대비한 순차적인 처리가 필요해집니다.
이 작업은 CountDownLatch를 이용하여 처리하였습니다. Mirror의 요청의 경우는 CountDownLatch의 await() 기능을 이용하여 우선 대기를 시켰고, 원본의 요청이 처리되고 나면 countDown() 메소드로 대기를 해제시키고 캐시에서 응답을 꺼내 전송하도록 했습니다.
그리고 컴포넌트의 Scalability를 위해 Redisson의 CountdownLatch를 사용하였습니다.
이로 인해 Mirror의 요청이 먼저 도착하더라도 원본의 요청이 처리될 때까지 대기하기 때문에 요청의 순차적 처리를 보장할 수 있게 되었습니다.
이렇게 해서 read-only 처리를 완료하였고, 정상적으로 요청들이 처리되는 것을 확인했습니다.
마무리
이렇게 만들어진 Mirror 서버는 인프라 개선 등 여러 방면으로 테스트를 하는 데에 유용하게 사용되고 있습니다.
Mirror 서버를 도입함으로 인해 QA가 진행되고 있는 테스트 서버에 배포하기 전에 코드의 변경으로 인한 영향도를 미리 테스트해볼 수 있게 됨으로써 QA 일정의 지연을 막을 수 있어서 더 빠른 제품 출시에 기여할 수 있었습니다.
비슷한 고민을 하고 있으신 분들께 도움이 되었으면 좋겠습니다. 감사합니다.
Read more
-
Azar Mirror 서버 제작기 1편 - 인프라 개선을 두렵지 않게 하는 테스트 환경 만들기
서버로 유입되는 트래픽을 미러링하여 인프라 개선 사항을 편하게 테스트할 수 있는 Mirror Server를 개발한 경험을 공유합니다. -
Kubernetes 환경을 위한 자바 에이전트 개발기
쿠버네티스 환경에서 Distributed tracing 기능을 개발하며 한 고민들과 자바 바이트코드 변환을 이용해 재사용성 높은 자바 에이전트를 개발한 경험을 공유합니다. -
자바 Stomp Client 성능 개선기
자바로 작성된 Stomp client를 non-blocking으로 동작하도록 개선해 성능을 향상시킨 경험을 공유합니다. -
레디스와 분산 락(1/2) - 레디스를 활용한 분산 락과 안전하고 빠른 락의 구현
레디스를 활용한 분산 락에 대해 알아봅니다. 그리고 성능을 높이고 일관성을 보장하는 방법에 대해 알아봅니다.