Kubernetes 환경을 위한 자바 에이전트 개발기
안녕하세요, 하이퍼커넥트 Backend Dev1팀의 Fitz 입니다.
이 글에서는 Kubernetes 환경에 종속적인 Distributed tracing 기능을 개발하며 고민했던 내용과 자바 바이트코드 변환을 이용해 재사용성 높은 자바 에이전트를 구현한 경험을 공유합니다.
글의 전반부에서는 배경과 어떤 요구를 위해 어떤 구현을 했는지에 대해 설명하고, 뒤의 부록에서는 자바 바이트코드를 최적화한 내용에 대해 설명합니다,
배경
하이퍼커넥트에서는 Kubernetes 환경을 사용하고 있습니다. 또한 마이크로서비스 아키텍쳐를 사용하고 있는데 요청의 흐름을 파악한다던지, 각 서비스별 요청의 응답속도 등을 체크하기 위해 istio의 Distributed tracing을 구현할 필요가 생겼습니다.
이를 구현하기 위해서는 istio가 처음 요청에 주입해준 X-Request-Id 등의 헤더를 내부에서 다른 마이크로서비스를 호출하는 요청의 헤더에도 어플리케이션 레벨에서 전파하도록 해줘야 합니다.
굳이 어플리케이션 레벨에서 구현해야하는 이유는 istio 의 입장에서 보면 어플리케이션 외부에서 들어오는 http 요청이 나가는 http 요청 중 어떤 것과 관련이 있는지 알 수 없기 때문입니다.
그래서 외부에서 어플리케이션으로 들어오는 요청과, 어플리케이션에서 외부로 나가는 요청을 짝지어주기 위해서는 어플리케이션 내부에서 헤더를 전파해줘야합니다.
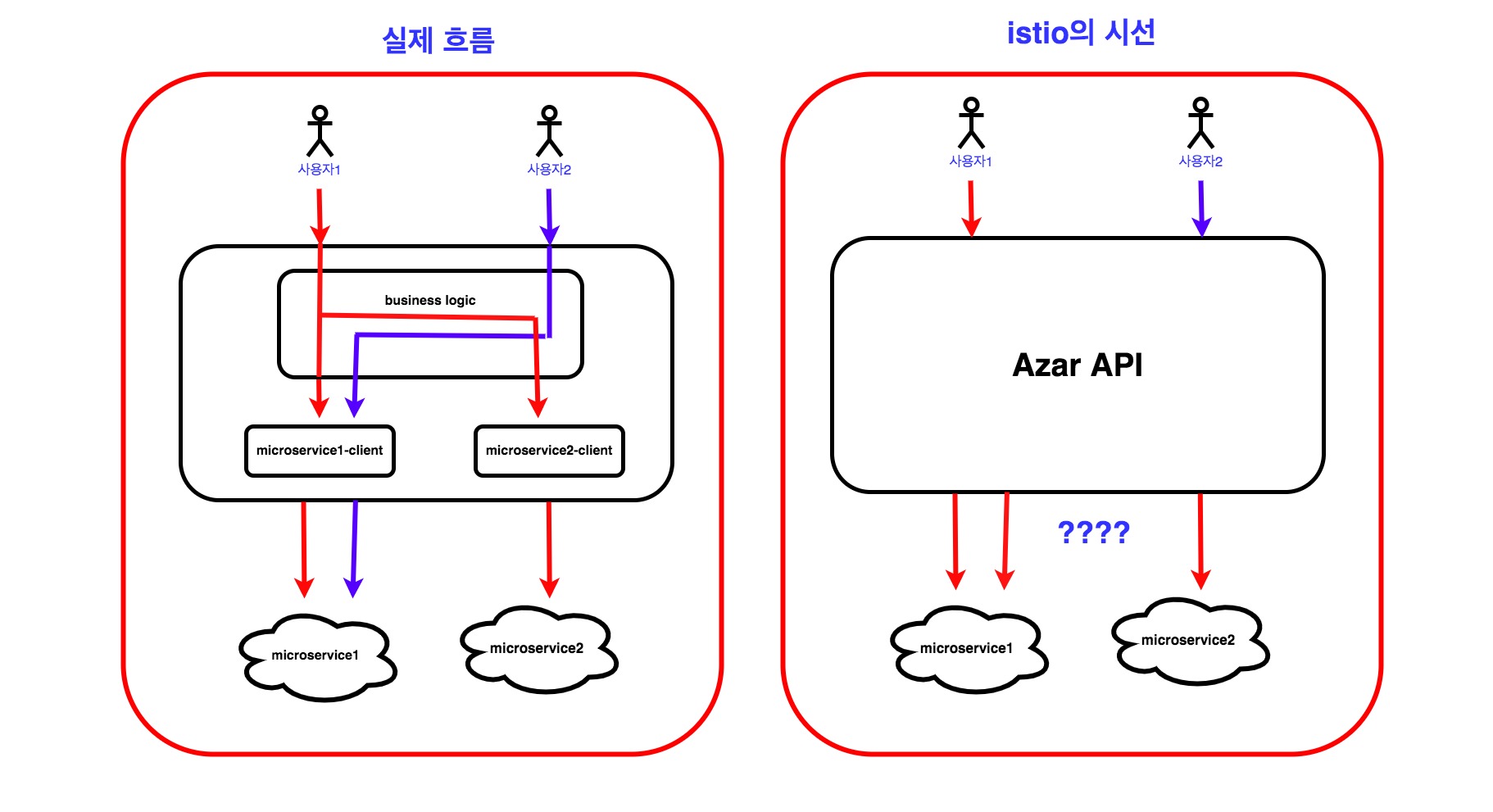
이 기능은 쿠버네티스 환경에 올라가는 모든 서비스에 적용해서 사용하게 되기 때문에, 다양한 부분에 대해 고민할 필요가 있었습니다.
요구사항 수립
이 헤더 전파 모듈을 어떻게 개발할 것인지를 선택하기에 앞서 스스로 몇 개의 요구사항을 세웠습니다.
재사용성
모든 마이크로서비스에 이 모듈을 적용해야하고, Azar 프로덕트 내의 마이크로서비스 역시 계속 늘어나고 있습니다. 또한 회사 내의 Azar 외 다른 프로덕트들에서도 쿠버네티스 환경을 사용할 수 있기 때문에 이 모듈은 높은 재사용성을 가질 필요가 있습니다.
확장성
현재는 트레이싱을 위해 HTTP 헤더를 전파하는 기능만 개발하지만, 쿠버네티스 환경에서 필요로 하는 다른 인프라적인 요구사항이 더 생길 가능성이 있습니다. 그래서 다른 인프라적인 요구사항도 쉽게 수용할 수 있도록 확장성있게 설계해야합니다.
독립성
이 모듈은 어플리케이션 레벨에서 작동해야 하지만, 사실은 쿠버네티스 환경에 종속적인 인프라 레벨의 코드라고 볼 수 있습니다 그래서 기왕이면 비즈니스 로직을 구현하는 각 어플리케이션의 코드와는 완전히 분리될 수록 좋다고 생각했습니다.
간편성
완성된 모듈을 다른 개발자가 사용할 때 부가적인 작업을 최소화하여 매우 간편하게 적용할 수 있으면 좋겠다고 생각했습니다.
구현방식에 대한 선택
Spring AOP
제일 간편하게 접근할 수 있는 방법은 AOP를 이용해 마이크로서비스 호출을 담당하는 HTTP Client 클래스에 요청을 전송할 때마다 헤더를 복사해주는 프록시를 입혀주는 것이였습니다.
하지만 이 방법에는 아래와 같은 한계가 있어서 다른 방법을 찾게 되었습니다.
- 프록시를 입히려하는 모든 클래스의 객체를 bean으로 관리해야합니다. 그래서 개발자가 신경쓰면서 개발해야하는 부분이 늘어나게 되고, 개발자의 실수로 트레이싱이 안되는 상황이 발생할 수 있습니다.
- 스프링 환경에 종속적인 방식이기 때문에 스프링을 사용하지 않는 서비스에는 적용할 수 없습니다.
- 라이브러리로 관리하면 관리의 주체를 한 곳으로 집중시킬 순 있고 재사용성도 높아지지만, 어플리케이션의 소스코드 레벨에 부가적으로 설정 코드를 추가해야하는 것은 아쉽습니다.
- 어플리케이션 자체에 쿠버네티스에 대한 의존성이 있는 소스코드가 포함되어버립니다.
AspectJ LTW
Spring AOP의 한계를 해결해보기 위해 AspectJ의 LTW(Load time weaving)를 자바 에이전트 방식으로 사용하는 것도 고려를 해봤습니다.
자바 에이전트 방식을 사용하면 이 모듈을 기존 소스와 독립적인 jar파일로 관리할 수 있고, jvm argument로 인프라 레벨에서 주입이 가능해집니다. 그래서 위의 요구사항인 독립성과 재사용성을 확보할 수 있습니다.
하지만 이 방식은 기능의 확장이 용이하지 않는 단점이 있습니다. 인프라 레벨의 요구사항이 늘어나더라도 쉽게 확장할 수 있는 구조를 지향했었기 때문에 인프라 종속적인 로직을 Agent jar에 두고싶었는데 aspectjweaver는 이미 완성되어있는 Agent jar이므로 역할이 고정되어있기에 확장에 용이하지 않았습니다.
Agent.premain()을 직접 개발한 Agent에서 간접 호출한다고 해도 클래스로더가 맞지 않아 클래스를 찾지 못해 에러가 발생하는 경우도 잦았습니다. 그래서 확장성이 부족하였습니다.
일반적인 라이브러리를 개발하고, 그 곳에 aspectjweaver를 붙이는 방식으로 개발한다고 한다면 소스코드에 인프라 의존성이 추가되기 때문에 독립성이 사라진다는 다른 문제도 발생합니다.
Bytecode Instrument 직접 구현
결국은 위의 요구사항을 모두 만족시키기 위해 Bytecode Instrumentation 방식으로 자바 에이전트를 직접 개발하기로 했습니다.
이 방식에서는 구현의 자유도가 높기 때문에 위에서 고민한 요구사항을 모두 만족하게 할 수 있습니다. Bytecode Instrumentation 라이브러리는 ASM을 사용하기로 했습니다.
ASM을 선택한 이유는 아래와 같습니다.
- 제일 low한 레벨의 라이브러리이기에 성능이 아주 좋습니다.
- 문서화가 아주 잘 되어있습니다. 이 것만으로도 이 라이브러리를 추천할만 합니다. 150장짜리 PDF에서 ASM에 대한 내용 뿐 아니라 바이트코드의 동작에 대한 설명, 메소드 프레임에 대한 설명 등 JVM의 동작에 대한 많은 정보를 얻을 수 있습니다.
- ASMifier를 사용하면 자바 코드에서 ASM코드를 자동으로 생성할 수 있습니다. 자동 생성된 코드를 필요에 맞게 수정해서 사용하면 편하게 개발이 가능합니다. 그래서 바이트코드를 사용하여 구현하기 때문에 생기는 생산성의 저하를 보완할 수 있습니다.
위의 자바 에이전트 방식이므로 위의 LTW를 사용하는 것과 마찬가지로 독립성, 재사용성을 확보하는 것과 함께 어플리케이션 코드에 부가적인 설정은 하나도 할 필요가 없기 때문에 간편성 또한 확보할 수 있습니다.
ASM을 사용하게 되면 생기는 단점도 있었습니다. 자바 바이트코드를 직접 조작하게 되므로 러닝 커브가 높아져 유지보수성이 떨어진다는 단점이 있었습니다. 이 단점은 설계를 통해 극복하기로 하고 ASM으로 개발을 시작했습니다.
코어 구현
코어 구현은 분량의 압박으로 핵심 부분을 위주로 나열했습니다.
Interceptor
기본적인 컨셉으로는 타겟 메소드의 전후에 프록시 바이트코드를 삽입하여 전처리와 후처리를 지원하는 방식으로 개발하기로 했습니다.

전후 처리를 책임지는 역할을 맡는 인터페이스를 AroundInterceptor라고 이름지었고 이 인터페이스에 있는 메소드의 내용은 아래와 같습니다.
default Object[] before(Object target, Object[] args) {
return args;
}
default void after(Object target, Object[] args) {
}
before 메소드를 보면 리턴 타입이 Object[] 입니다. before 메소드는 메소드의 인자를 바꿔치기하는 기능을 지원하기 때문입니다.
이 기능을 지원함으로써 뒤에서 나올 Hystrix의 스레드로컬 전파 관련 이슈들을 해결할 수 있었습니다.
만약 특정 메소드에 부가적인 기능을 입히고 싶다면 이 인터페이스를 구현해서 에이전트에 등록하면 됩니다.
프록시를 이렇게 추상화시켰기 때문에, 이후 HTTP 헤더 전파 외의 다른 기능을 개발할 때에도 이 인터페이스를 구현해서 기능을 추가할 수 있게 되었습니다. 이로써 위에서 언급한 요구사항중 확장성을 확보하였습니다.
유지보수성 확보
ASM을 사용한다고 했는데, 위의 AroundInterceptor를 보면 이 인터페이스와 인터페이스의 구현체는 바이트코드가 아닌 일반적인 자바 코드로 구현됩니다.
심지어 이 인터셉터를 에이전트에 등록할 때에도 ASM의 존재는 보이지 않습니다. 아래는 HTTP 헤더 전파를 위해 개발한 HTTP 플러그인 코드의 최종본입니다.
public class HttpClientPlugin implements Plugin {
@Override
public void setup(TransformerRegistry transformerRegistry) {
transformerRegistry.registerTransformer(
NameBaseTransformerDelegate.builder()
.classNamePattern("org.apache.http.client.HttpClient+") // HttpClient 인터셉터를 상속받은 모든 클래스에 적용
.methodName("execute") // execute라는 이름을 가진 모든 메소드에 적용
.addInterceptorClass(HttpClientInterceptor.class) // AroundInterceptor를 상속받은 인터셉터
.build()
);
}
}
이처럼 내부적으로 ASM을 이용한 구현 내용을 캡슐화하여 기능을 사용하는 사람은 내부의 로직을 몰라도 쉽게 사용할 수 있게 설계하였습니다. 이처럼 핵심로직을 최소화하고 캡슐화시켰기 때문에 위에서 나온 ASM을 사용했을 때의 단점인 유지보수성 하락을 극복할 수 있었습니다.
또한 이 코드를 보아 짐작했을때 무언가 부가적인 요구사항이 생겼을 때 개발자가 추가적으로 구현해야할 코드는 이 Plugin 클래스와 AroundInterceptor 인터페이스를 구현한 클래스 두 개뿐 입니다. ASM에 대해 알 필요도 없습니다.
개발자는 이처럼 쉽게 기능을 확장할 수 있습니다. 기능 개발을 위해 추가해야할 코드의 양이 적어지므로 유지보수할 포인트가 매우 줄어들어 유지보수성이 더욱 좋아집니다.
ClassLoader
에이전트를 구현하면서 ClassLoader와 관련된 것들도 많이 신경을 써야 했습니다.
첫 번째로 Interceptor는 타겟 클래스와 같은 클래스로더에서 로딩되어야 합니다. 그렇지 않으면 인터셉터 내부에서 사용하는 타겟 클래스와 관련된 클래스들을 클래스로더에서 찾지 못해 NoClassDefFoundError가 발생할 수 있습니다.
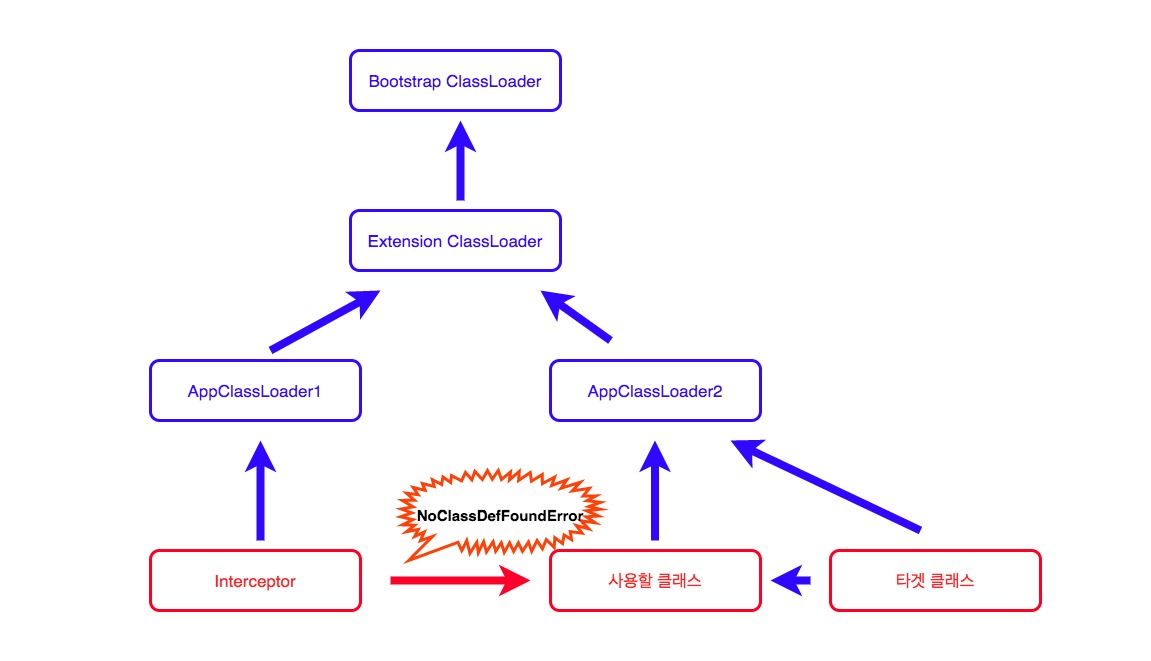
그래서 인터셉터를 타겟 클래스의 클래스로더로 reload하였습니다. 만약 Bootstrap ClassLoader에 의해 로딩되는 클래스일 경우는 인터셉터에서 사용할 수 있는 클래스의 선택지를 넓혀주기 위해 Thread.currentThread().getContextClassLoader() 를 사용해 어플리케이션 클래스로더에서 로딩하도록 하였습니다.
ClassLoader parent = loader == null ? Thread.currentThread().getContextClassLoader() : loader;
AroundInterceptor inst = (AroundInterceptor) AgentClassLoader.of(parent)
.define(interceptor.getName(), protectionDomain).newInstance();
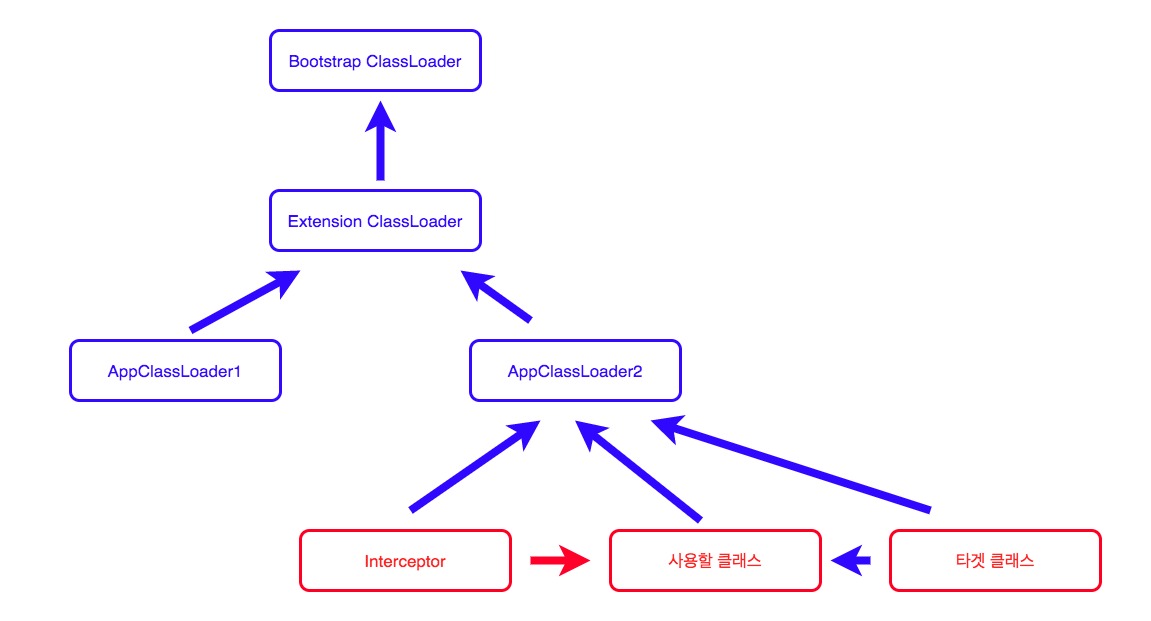
두 번째로는 이 에이전트는 Bootstrap ClassLoader에 의해 로딩되어야합니다. 참고링크
그 이유로는 프록시를 입혀야할 클래스 중에 최상위 클래스로더인 Bootstrap ClassLoader에 의해 로딩되는 클래스들도 있기 때문입니다.
이번에 HTTP 헤더 전파 기능을 개발하면서는 java.net.HttpURLConnection 클래스가 이에 해당했었습니다.
예외 핸들링
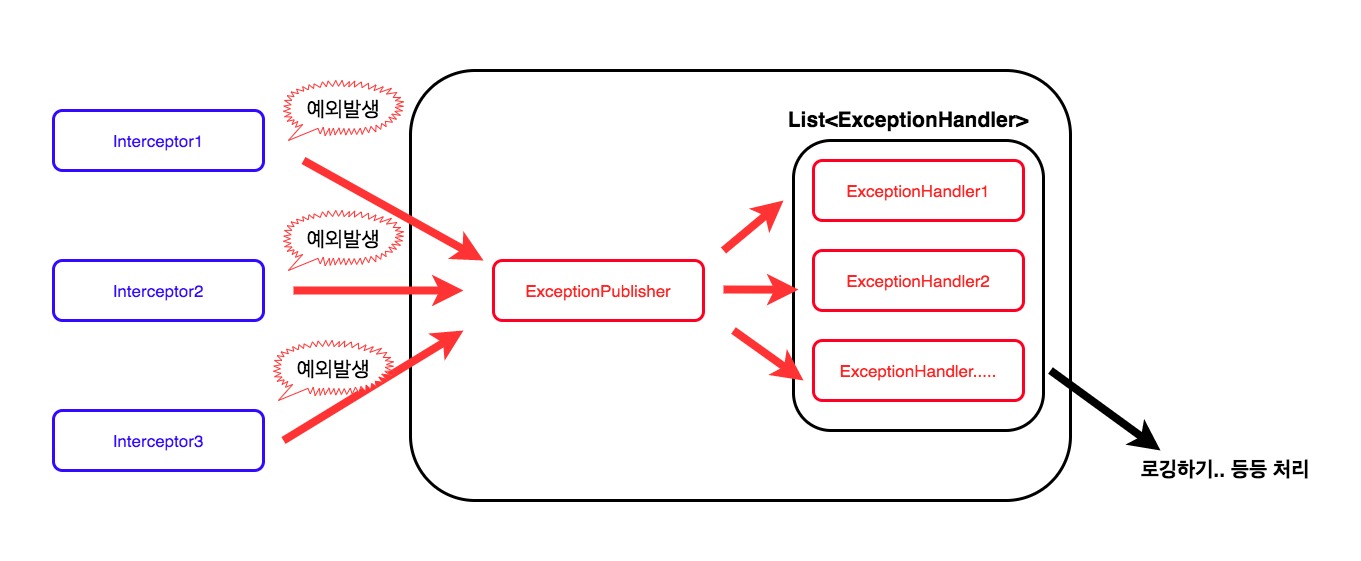
Interceptor를 호출하는 코드는 메소드의 전후에 삽입됩니다. 그러면 인터셉터에서 예외가 발생한다면 그 예외가 원본 메소드에까지 전파될 가능성이 있어 어플리케이션에 영향을 끼칠 가능성이 있습니다.
그래서 이것을 해결하기 위해 인터셉터를 호출하는 코드를 try-catch로 감싸서 예외가 발생시 ExceptionPublisher에 예외를 전달하여 이를 처리할 수 있도록 하였습니다.
void targetMethod(String arg1, Integer arg2) {
try {
Object[] changedArgs = interceptor.before(this, arg1, arg2);
arg1 = (String) changedArgs[0];
arg2 = (Integer) changedArgs[1];
} catch (Exception ex) {
ExceptionPublisher.publish(this, new Object[]{ arg1, arg2 }, ex);
}
// Original method...
}
ExceptionPublisher는 사용자가 등록한 ExceptionHandler들에게 예외를 전파합니다. 사용자는 이 ExceptionHandler를 직접 등록할 수 있으며 예외상황의 처리 방식을 정의할 수 있습니다.
HTTP 플러그인 구현
HTTP 헤더 전파 기능 구현
HTTP 헤더를 전파하는 기능은 쉽게 구현할 수 있었습니다. 일단 대부분의 서비스에서 직간접적으로 이용하는 클래스인 Apache HttpClient와 java.net.HttpURLConnection 클래스에 프록시를 입혔습니다.
적용하려는 마이크로서비스는 모두 spring-boot와 tomcat을 사용하고 있었고, 현재 요청은 스프링의 RequestContextHolder.getRequestAttributes() 메소드를 이용해 가져올 수 있었습니다.
또한 타겟 JVM의 클래스들을 이용할 것이므로 의존성은 모두 provided scope로 주었습니다. 에이전트 내부의 코드에서는 클래스를 직접 참조하지 않으므로 해당 의존성이 타겟 JVM에 없어도 에러가 발생하지 않습니다.
Hystrix 스레드간 상태 전파
Hystrix를 사용하게 되면 요청을 별도의 스레드에서 수행하게 됩니다. [참고링크]
하지만 현재 요청을 가져오는데에 사용한 RequestContextHolder.getRequestAttributes()는 스레드 로컬 기반이기 때문에 Hystrix 스레드에서 요청을 수행하게 된다면 값을 받아오지 못하게 됩니다.
Hystrix에서는 이를 위해 스레드간 상태전파를 할 수 있는 void wrapCallable(Callable c) 메소드를 제공하고 있습니다. 이를 오버라이딩하여 사용하면 스레드간의 상태 전파가 가능합니다.
그래서 Hystrix를 위한 상태전파 인터셉터를 개발하였고 그 내용은 아래와 같습니다. wrapCallable 메소드의 Callable은 메소드의 인자로 넘어오기 때문에 인터셉터의 before 메소드에서 지원하는 메소드 인자 바꿔치기 기능을 통해 해당 작업을 수행했습니다.
@Override
public Object[] before(Object target, Object[] args) {
return Arrays.stream(args).map(arg -> {
if (arg instanceof Callable) {
RequestAttributes attributes = RequestContextHolder.getRequestAttributes();
return (Callable) () -> {
RequestAttributes preAttributes = RequestContextHolder.getRequestAttributes();
RequestContextHolder.setRequestAttributes(attributes);
try {
return ((Callable) arg).call();
} finally {
RequestContextHolder.setRequestAttributes(preAttributes);
}
};
}
return arg;
}).toArray();
}
정리
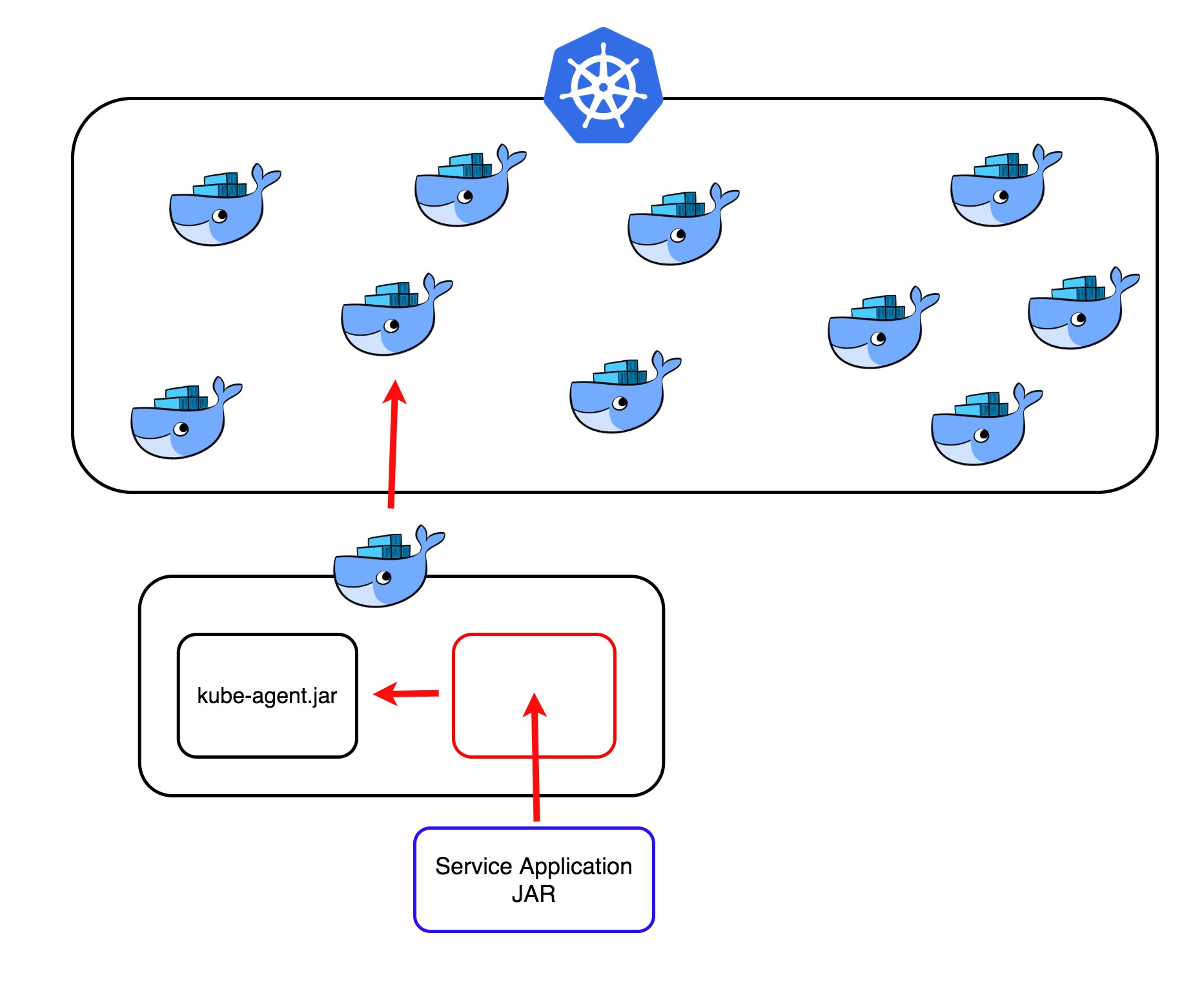
개발이 완료되고 최종적으로는 아래와 같은 그림이 되었습니다.
인프라에 종속적인 코드는 인프라에 들어있는게 좋다고 생각합니다. 그래서 쿠버네티스 환경에 종속적인 코드가 담긴 에이전트 jar 파일은 쿠버네티스에 배포되는 도커 베이스 이미지에 포함시켜놨습니다. 그리고 이 에이전트를 사용하는 것은 helm chart에서 명령어로 주입해주면 됩니다.
그 결과 어플리케이션은 쿠버네티스 환경에 대한 의존성을 갖지 않게 되었습니다. 또한 핵심로직을 최대한 캡슐화시키고 추상화시켜서 부가적인 요구사항이 생기더라도 최소한의 변경만으로 기능을 확장시킬 수 있게 되었습니다.
그리고 서비스들이 아무리 많이 늘어나더라도 단 한 줄만 고치면 되기 때문에 적용이 매우 간편해져서 생산성이 향상되었습니다.
감사합니다. (아래에는 바이트코드 관련한 작업을 하면서 생겼던 이슈 중 몇 개를 부록으로 정리해놓았습니다.)
[부록] 바이트코드 작업 이슈
로컬변수 슬롯 아끼기
인터셉터의 before 메소드는 타겟 메소드의 인자 값 바꿔치기를 지원합니다. 아래와 유사한 로직이라고 볼 수 있습니다.
void targetMethod(String arg1, Integer arg2) {
Object[] changedArgs = interceptor.before(this, arg1, arg2);
arg1 = (String) changedArgs[0];
arg2 = (Integer) changedArgs[1];
// Original method...
}
JVM에서는 최적화를 위해 메소드를 실행하기 위한 스택의 크기와 로컬변수 슬롯의 크기를 컴파일 타임에 미리 계산하여 바이트코드상에 저장합니다.
또한 몇 번째 로컬변수 슬롯 인덱스에 어떤 변수가 저장되는지도 바이트코드상에 저장됩니다.
위의 코드처럼 Object[] args = interceptor.before(this, arg1, arg2); 이런 코드를 사용하게 된다면 원래 메소드가 사용하는 로컬변수보다 1개를 더 사용하게 됩니다.
또한 메소드의 초반부에 추가되는 것이기 때문에 슬롯의 개수에만 영향을 주는게 아니라 각 변수의 슬롯 인덱스에도 영향을 주게 됩니다.
그래서 로컬변수에 저장하지 않기 위해 바이트코드상에서 트릭을 사용했습니다.
DUP 명령어를 사용하면 스택의 최상단의 있는 값을 복사하여 스택에 Push 합니다. 그래서 before 메소드의 리턴값을 로컬변수 슬롯에 저장하는 대신, DUP 명령어를 사용하여 before 메소드의 리턴값을 지속적으로 스택의 상단에 유지시켜 연산에 사용했습니다.
아래의 코드를 보면 INVOKESPECIAL로 before 메소드를 호출했고, 스택의 최상단에는 before 메소드의 리턴값이 들어있습니다. 그리고 for문을 이용해 인자의 개수만큼 반복하며 아래의 단계를 반복합니다.
DUP명령어를 이용해 스택 최상단에 있는before의 리턴값을 복사하여 스택에 push (스택에는 똑같은 값 2개가 있게 됩니다.)- 배열의
i인덱스에 있는 값을 가져와서 스택에 push - 인자의 타입에 맞게 타입 캐스팅
- 인자가 primitive 타입이라면 언박싱
- 해당 인자의 로컬변수 슬롯에 값 덮어씌우기
제일 마지막에는 POP 명령어로 스택에 남아있는 값을 없애버립니다. 그래서 before 호출 이후에 있는 코드들에게 영향을 끼치지 않도록 구현했습니다.
...
mv.visitMethodInsn(INVOKESPECIAL, classInfo.getInternalName(), delegateBefore, "([Ljava/lang/Object;)[Ljava/lang/Object;", false);
for (int i=0; i<argCount; i++) {
String argDesc = instrumentMethod.getArgTypeDescriptors()[i];
mv.visitInsn(DUP);
mv.visitIntInsn(BIPUSH, i);
mv.visitInsn(AALOAD);
ByteCodeUtils.checkCast(mv, argDesc);
if (ClassUtils.isPrimitiveType(argDesc)) {
ByteCodeUtils.unBoxingPrimitiveType(mv, argDesc);
}
ByteCodeUtils.saveStackToLocalVariable(mv, i+1, argDesc);
}
mv.visitInsn(POP);
박싱/언박싱
인터셉터 메소드들의 인자는 Object[] 입니다. 즉 reference type만 받을 수 있습니다. 하지만 타겟 메소드의 인자는 primitive type일 수도 있습니다. 그래서 이 primitive type은 reference type으로 박싱을 해줘야합니다.
일반적인 자바 코드를 작성할 때에는 컴파일러가 알아서 박싱/언박싱을 해주지만 바이트코드상에서는 직접 해야합니다. 그래서 타입이 맞지 않으면 예외가 발생할 수 있습니다.
그래서 모든 타입을 고려하여 박싱을 수행해줘기 때문에 타입별로 다른 바이트코드를 생성하는 유틸클래스를 만들었습니다.
타입 구분은 각 메소드의 인자들의 Type Descriptor를 파싱해서 가져와 이용했습니다.
void boxingPrimitiveType(MethodVisitor mv, String descriptor) {
switch (descriptor) {
// int
case "I" :
mv.visitMethodInsn(INVOKESTATIC, "java/lang/Integer", "valueOf", "(I)Ljava/lang/Integer;", false);
break;
// boolean
case "Z" :
mv.visitMethodInsn(INVOKESTATIC, "java/lang/Boolean", "valueOf", "(Z)Ljava/lang/Boolean;", false);
break;
...
}
}
언박싱도 마찬가지입니다. 인자 바꿔치기를 위해 인터셉터의 before 메소드의 결과 값을 인자에 덮어씌우는 기능에서는 만약 인자가 primitive type이면 언박싱을 해주어야합니다.
void unBoxingPrimitiveType(MethodVisitor mv, String descriptor) {
switch (descriptor) {
// int
case "I" :
mv.visitMethodInsn(INVOKEVIRTUAL, "java/lang/Integer", "intValue", "()I", false);
break;
// boolean
case "Z" :
mv.visitMethodInsn(INVOKEVIRTUAL, "java/lang/Boolean", "booleanValue", "()Z", false);
break;
...
}
}
ClassNotFoundException 처리
위의 본문에서 각 부분마다 어떤 클래스는 어떤 클래스로더가 로딩한다를 세밀하게 설정해주었었습니다.
하지만 실행할 때 ClassNotFoundException이 발생하는 문제가 있었습니다. 뭔가 클래스로더 설정을 잘못했나 싶었는데 확인해보니 프레임을 쉽게 계산하려고 주었던 COMPUTE_FRAMES 옵션이 문제였습니다.
바이트코드가 실행될 때마다 프레임의 상태는 계속 달라집니다.
JVM은 JUMP나 예외처리 같은 명령어 직후의 프레임의 상태를 바이트코드상에 명시해놓고, 이를 이용하여 바이트코드 실행마다 달라지는 프레임 상태를 빠르게 유추합니다.
ASM에서는 변환한 클래스를 다시 바이트 배열로 변환할 때 이 프레임을 자동으로 계산해서 명시해주는 COMPUTE_FRAMES 옵션을 제공하고 있습니다.
이 옵션을 사용하면 내부적으로 변환하고자 하는 클래스에서 참조하는 클래스들을 로딩해서 계산에 사용하는데 클래스로더가 맞지 않아서 발생하는 예외였습니다.
그래서 만약 세밀한 클래스로더 설정을 사용한다면 번거롭더라도 직접 계산해서 명시해주는게 좋습니다.
감사합니다.
Read more
-
Azar Mirror 서버 제작기 3편 - 개발자편
Mirror 서버로 traffic을 복제하고, microservice를 사용하는 요청을 routing하기 위해 Istio를 사용한 경험을 공유합니다. (개발자편) -
Azar Mirror 서버 제작기 1편 - 인프라 개선을 두렵지 않게 하는 테스트 환경 만들기
서버로 유입되는 트래픽을 미러링하여 인프라 개선 사항을 편하게 테스트할 수 있는 Mirror Server를 개발한 경험을 공유합니다. -
자바 Stomp Client 성능 개선기
자바로 작성된 Stomp client를 non-blocking으로 동작하도록 개선해 성능을 향상시킨 경험을 공유합니다. -
레디스와 분산 락(1/2) - 레디스를 활용한 분산 락과 안전하고 빠른 락의 구현
레디스를 활용한 분산 락에 대해 알아봅니다. 그리고 성능을 높이고 일관성을 보장하는 방법에 대해 알아봅니다.