자바 Stomp Client 성능 개선기
안녕하세요, 하이퍼커넥트 Backend Dev1팀의 Fitz 입니다.
아자르에서는 프로덕트의 특성으로 인해 Message broker 서버와 Stomp client를 직접 구현하여 사용하고 있습니다. 이 글에서는 직접 구현되어있는 Stomp client를 non-blocking 방식으로 개선하여 성능과 안정성을 향상시킨 내용에 대해 공유합니다.
배경
아자르 API는 전 세계에서 오는 많은 트래픽을 받아내고 있기에 상대적으로 높은 사양의 서버를 사용하고 있습니다. 그렇기에 기존에 사용하고 있던 Stomp client의 성능에 대해 큰 문제를 느끼지 못하고 있었습니다.
하지만 매칭된 상대의 정보를 전송하는 부분을 마이크로서비스로 분리하면서 문제가 드러나기 시작했습니다. 비교적 낮은 사양의 환경에서 코드가 돌아가자 CPU의 점유율이 높아지는 등 불안정한 모습을 보이기 시작했습니다.
그래서 병목을 진단하고 성능을 개선하기로 했습니다.
non-blocking으로의 개선
기존의 Stomp client는 네티를 이용해 구현되어 있기에 이미 non-blocking하게 구현되어 있었습니다.
하지만 기존 클라이언트에서는 apache-commons-pool을 이용하여 Connection을 pool로 관리하고 있었고, 전송 성공여부를 확인하기 위해 Future.get() 메소드를 사용하기 때문에 동기적이라는 문제가 있었습니다.
Connection Pool을 사용하면 커넥션을 반납해야만 다른 스레드에서 이 커넥션을 사용할 수 있기 때문에 Connection 1개당 한 스레드에서밖에 사용하지 못하게 됩니다.
또한 전송 성공여부를 확인하기 위해 Future.get() 메소드를 사용하여 blocking 오퍼레이션을 수행하고 있었기 때문에 Connection Pool로 Connection을 반납하는 시간은 더 늦어지고 있었습니다.
네티를 사용하면 커넥션을 하나만 가지고도 여러 스레드가 동시에 사용할 수 있다는 장점이 있는데 이 장점을 제대로 활용하지 못하고 있던 것이죠.
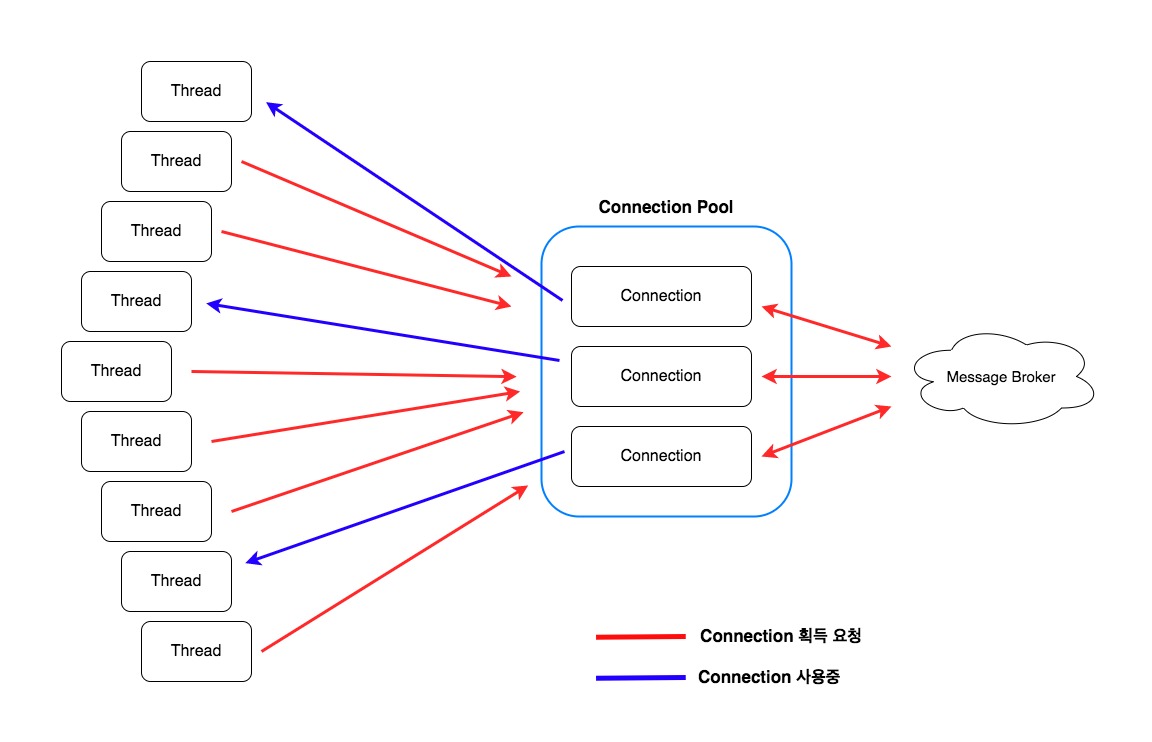
아래의 그림을 보시면 더 이해가 쉬우실 겁니다. Connection Pool을 사용하고 있기 때문에 스레드들은 Connection을 획득하기 위해 경쟁해야합니다. 그리고 Blocking operation을 수행하고 있기에 Connection의 반납속도는 더욱 늦어집니다.
그래서 동시 처리량을 높이려면 Connection의 수를 늘려 나가야 합니다.
하지만 아래 그림과 같이 개선하고자 합니다. 모든 작업이 비동기적으로 이루어지면 스레드들 간의 경쟁 없이도 작업을 진행할 수 있습니다.
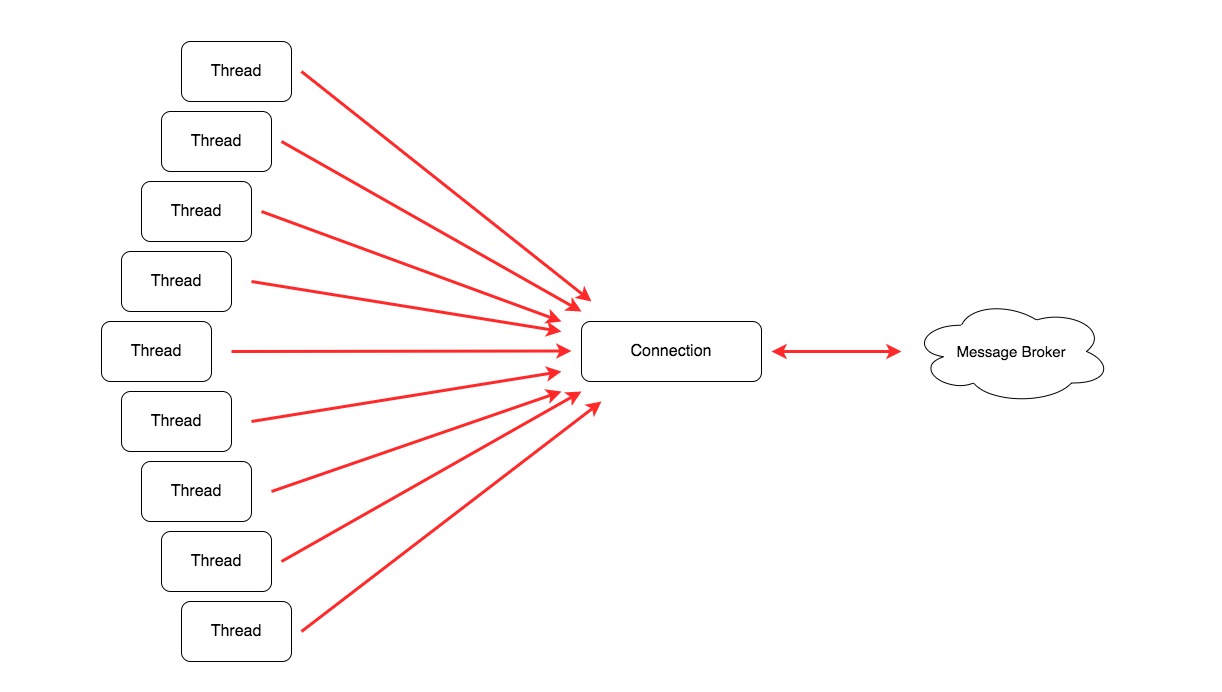
병목을 만드는 주범인 Connection Pool을 걷어내었습니다. 또한 전송 성공 여부를 기다릴 필요가 없기 때문에 로깅 등 실패에 대한 처리를 비동기 콜백으로 처리하게 하여 스레드 간 경쟁을 없앨 수 있었습니다.
아래의 코드에서는 client 객체 획득부터 전송까지 모두 콜백을 이용하기 때문에 세밀한 동시성 제어가 가능합니다. client 객체를 사용하는 콜백은 사용 가능한 client 객체를 찾았을 때 이를 주입받아 실행되며, addListener 메소드로 추가된 콜백은 전송 실패시에만 실행됩니다.
(1개의 client 객체는 1개의 Connection을 갖고있습니다. 그래서 1 클라이언트 = 1 커넥션이라고 생각하셔도 됩니다.)
stompClientManager.useAsyncClient { client ->
client.send(destination, content, params).addListener { future ->
if (!future.isSuccess && future.cause() != null) {
logger.error("메시지를 브로커 이벤트로 송신하는데 실패하였습니다", future.cause())
}
}
}
사용 가능한 client 객체를 찾는 것에 대한 내용은 아래에서 설명하겠습니다.
Connection 관리
예비 Connection Pool
위의 그림에서는 1개 Connection 만으로 여러 스레드가 동시에 사용할 수 있게 되었지만 이 구조에서도 여전히 문제가 있었습니다.
불의의 사고로 Connection이 끊어지게 되면 지속적으로 들어오는 초당 수 천개의 요청이 실패하게 되면서 오류 발생은 물론 정상적인 서비스 운영에도 영향을 끼치게 될 것이라는 점입니다. 그래서 커넥션이 깨진 경우에도 요청이 실패하지 않도록 대비책이 필요했습니다.
여러 고민을 거쳐 아래의 그림과 같이 Connection이 깨진 경우에 대한 Fallback을 설계하였습니다.
- 예비 Connection을 여러 개 만들어 놓고 커넥션이 깨진 경우는 예비 Connection을 사용하여 요청을 처리합니다.
- Broker 서버 배포 등의 이유로 모든 예비 Connection이 깨진 경우는 새로운 Connection을 비동기적으로 생성하고, 반환된
Future에 요청 처리를 트리거하여 연결이 완료된 후에 요청을 처리하도록 했습니다.
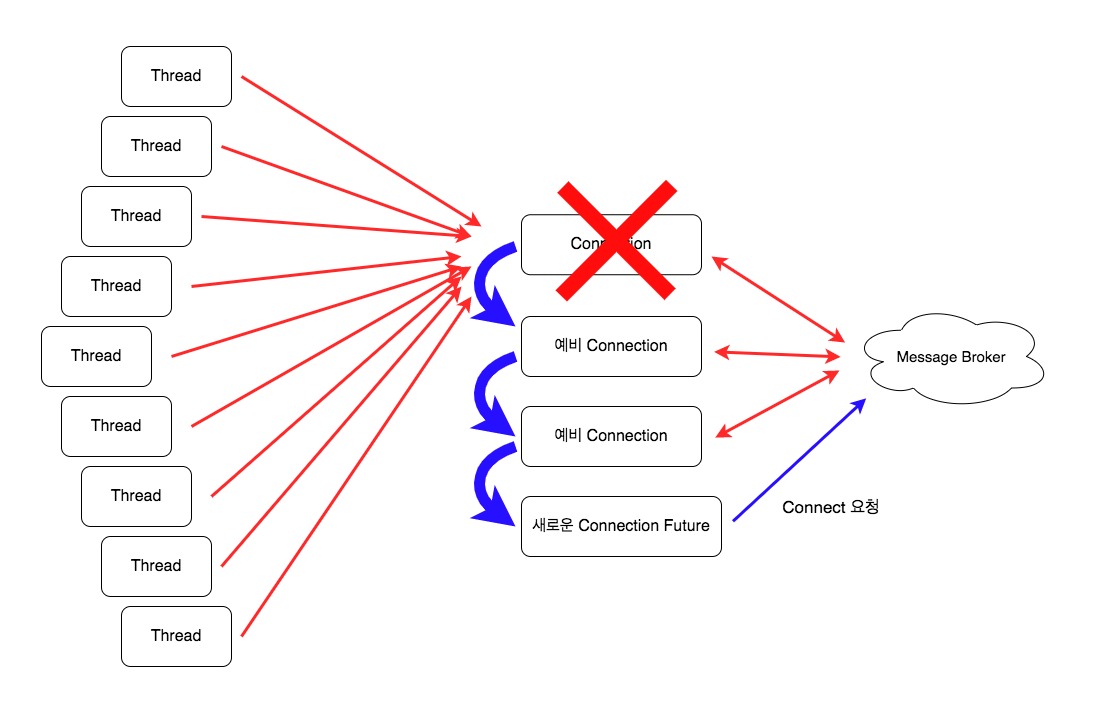
바로 새로운 Connection을 생성하는 것이 아닌 예비 Connection을 미리 만들어뒀다가 사용하는 이유는, Connection을 맺기 위해 걸리는 시간으로 인해 응답속도가 느려지는 것을 방지하기 위함입니다. 만약 예비 Connection을 사용하지 않는다면 요청은 성공하겠지만 Connection을 맺는 시간에 대한 지연이 발생하여 응답속도가 느려질 수 있기 때문입니다.
정리하자면, 이 방식에서는 Connection을 획득할 때 스레드끼리 경쟁하지 않으며, Pool 내부의 Connection들에는 Connection의 가용성을 높이는 역할이 아닌 앞의 Connection이 깨졌을 경우의 Fallback 용도로 사용되게 됩니다.
Connection Refresh
만약 예비 Connection Pool 내부의 Connection이 깨진 경우에는 깨진 Connection을 없애고, 그 위치에 새로운 Connection으로 갈아끼우도록 했습니다.
그리고 여러 요청이 동시에 들어왔을 때 Connection이 깨져있다면, 중복으로 Refresh가 발생할 가능성이 있습니다. 그러면 동시에 엄청난 수의 Connect 요청이 발생하여 서버에 무리를 줄 수 있습니다.
그래서 중복으로 Refresh를 하지 않도록 CAS (Compare And Set) 연산을 사용하여 중복요청 트리거를 막았습니다. 이 연산은 CPU 레벨에서 Atomic 연산을 지원하므로 동기화 오버헤드에 대한 부담없이 동시성 이슈를 처리할 수 있었습니다.
val refreshJobFlag = AtomicReferenceArray<Boolean>(Array(connectionSize) {
false
})
...
fun triggerRefreshConnection(idx: Int) {
if (refreshJobFlag.compareAndSet(idx, false, true)) {
eventExecutor.submit {
try {
val conn = connections.get(idx)
connections.set(idx, stompClientFactory.getClient())
conn.close()
} finally {
refreshJobFlag.set(idx, false)
}
}
}
}
새로운 Connection Future 처리
만약 모든 예비 Connection이 깨졌다면, 새롭게 Connection을 생성하고 그 Connection의 연결이 완료되면 요청을 처리하도록 트리거해야합니다.
이 작업도 마찬가지로 동시에 여러 요청이 들어온다면 중복으로 Connection을 생성하는 요청이 많이 생길 수 있습니다. 이 경우는 Future를 리턴하기에 ConcurrentHashMap을 이용하여 1초 TTL의 간단한 캐싱을 구현해서 Connection이 최대 1초에 1개만 생성되도록 구현했습니다.
Best practice는 Guava나 Caffeine 같은 캐시 구현체를 이용하는 것이지만 필요로 하는 기능이 매우 간단한 기능이기도 하고, 여러 서비스에서 사용하는 라이브러리이기에 최대한 외부 의존성을 줄이고 싶었습니다.
그리고 마침 기존 코드에서 일정 주기마다 Connection을 validation하는데에 ScheduledExecutor를 사용하고 있었기 때문에, 필요로 하는 캐시 부분 구현에 같이 사용할 수 있었습니다.
fun createAsyncClient() =
clientFutureCache.computeIfAbsent(CLIENT_CACHE_KEY) {
scheduledExecutor.schedule({
clientFutureCache.remove(CLIENT_CACHE_KEY)
}, 1000, TimeUnit.MILLISECONDS)
stompClientFactory.getClientAsync()
}
...
// Connection을 맺는데에 성공하면 processRequest 콜백을 실행시킵니다.
createAsyncClient().whenComplete { client, throwable ->
if (throwable == null) {
processRequest(client)
}
}
정리
결과적으로 수행한 작업은 아래와 같습니다.
Connection Pool을 걷어내어 Connection을 획득하기 위해 스레드끼리 경쟁하지 않도록 개선.Future.get()메소드를 이용해 동기적으로 수행하던 작업을 Callback 방식으로 바꿔서 비동기적으로 개선.- Connection이 깨졌을 때의 Fallback 설계로 안정성 향상
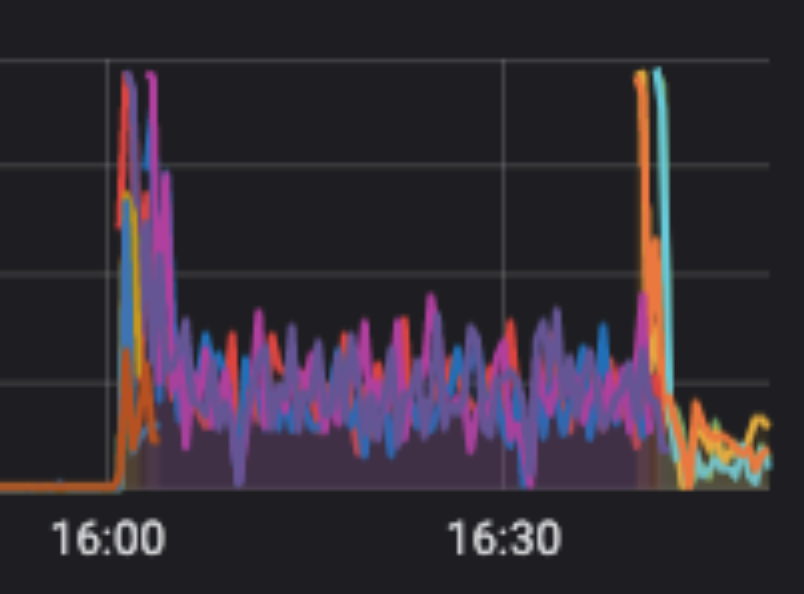
이렇게 개선한 결과 CPU 사용량 그래프가 아래와 같이 개선되었습니다. (그래프를 캡쳐한지 오래되어서 남아있는 이미지가 이것밖에…😭)
튀는 부분은 배포시점이기에 배제하고, 대략 보라색과 제일 오른쪽의 주황색 부분을 비교해보면 CPU 사용량이 대략 30% 정도로 대폭 떨어진 것을 볼 수 있습니다.
읽어주셔서 감사합니다.
Read more
-
Azar Mirror 서버 제작기 3편 - 개발자편
Mirror 서버로 traffic을 복제하고, microservice를 사용하는 요청을 routing하기 위해 Istio를 사용한 경험을 공유합니다. (개발자편) -
Azar Mirror 서버 제작기 1편 - 인프라 개선을 두렵지 않게 하는 테스트 환경 만들기
서버로 유입되는 트래픽을 미러링하여 인프라 개선 사항을 편하게 테스트할 수 있는 Mirror Server를 개발한 경험을 공유합니다. -
Kubernetes 환경을 위한 자바 에이전트 개발기
쿠버네티스 환경에서 Distributed tracing 기능을 개발하며 한 고민들과 자바 바이트코드 변환을 이용해 재사용성 높은 자바 에이전트를 개발한 경험을 공유합니다. -
레디스와 분산 락(1/2) - 레디스를 활용한 분산 락과 안전하고 빠른 락의 구현
레디스를 활용한 분산 락에 대해 알아봅니다. 그리고 성능을 높이고 일관성을 보장하는 방법에 대해 알아봅니다.