Survival Analysis (1/3)
Survival Analysis (생존분석)은 어떤 사건의 발생 확률을 시간이란 변수와 함께 생각하는 통계 분석 및 예측 기법입니다. 다양한 분야에 활용되는 만큼 이름도 다양한데, 기계공학에서는 Reliability Analysis, 경제학에서는 Duration Analysis, 사회학에서는 Event-History Analysis라고 부릅니다.
IT에서는 고객 이탈 분석과 예측에도 활용합니다. 다음 동영상은 애완동물 관련 사업을 하는 tails.com에서 소개한 내용입니다.
하이퍼커넥트 또한 고객 이탈을 예측하고 방지하는 데 Survival Analysis 기법을 활용하고 있습니다. 예를 들어 신규 가입 고객이 언제까지 서비스를 이용하는지, 어떤 활동이 고객의 retention에 영향을 미치는지 등을 분석하고 고객 retention을 개선하고자 노력합니다.
이번 포스트에서는 Survival Analysis를 소개하고 이를 어떻게 고객 이탈 분석에 활용할 수 있는지 소개하겠습니다.
Survival Analysis의 기본 개념
먼저 Survival Analysis에 대해 간략하게 설명하겠습니다. 위키피디아 문서를 보면 친절한(?) 예제와 설명이 있습니다.
다음은 Survival Analysis에 등장하는 주요 개념들입니다.
- Event (사건) : 생존의 반대 개념입니다. 죽음, 사고, 장애 등 생존분석으로 분석하려는 대상입니다. 고객 이탈분석에서는 이탈이 바로 사건입니다.
- Time (시간) : 말 그대로 (상대적) 시간입니다. 즉, 분석하려는 대상을 관찰하기 시작한 시점으로부터 경과한 시간입니다. 이탈분석에서는 비교적 명확한데, 각 고객의 가입 시점으로부터 경과한 시간입니다.
- Censored (중도절단) : right censored와 left censored로 나뉩니다.
- Right censored : 대상에 아직 사건이 발생하지 않았거나, 기타 다양한 이유로 관찰이 종료된 것을 의미합니다. 이탈분석에서는 아직 활동 중인 사용자나 잠시 활동이 뜸한 사용자가 해당합니다.
- Left censored : 대상을 관찰하기 전에 사건이 발생했거나 기대했던 최소 기간보다 생존 기간이 더 짧았던 경우입니다. 이탈분석에서는 앱을 설치하자마자 삭제하는 Bouncing이 해당합니다.
- Survival function (생존함수) : 고객이 특정 시간보다 더 오래 잔존할 확률을 계산하는 함수입니다.
- Hazard function (위험함수) : 특정 시간 t에 고객이 이탈할 확률입니다. 즉, 대상이 t까지 잔존한 상태에서 t 시점에 이탈할 확률이죠.
- Cumulative hazard function (누적위험함수) : 위험함수를 0부터 t까지 적분한 것입니다. 즉, t 시점 전까지 고객이 이탈 발생할 확률을 모두 더한 것이죠.
생존함수와 위험함수의 공식과 이론적인 내용은 추후 3편에서 따로 다루겠습니다. 이번 1편에서는 간단한 데이터 예제를 살펴봅시다.
데이터로 Survival Analysis를 수행하는 방법
위에서 설명한 생존함수와 위험함수는 데이터로 관측하지 않은 일종의 (unknown) truth입니다. 우리는 결국 데이터로 이 함수를 추정해야 합니다. 주로 Kaplan-Meier estimation을 활용해 추정합니다. 파이썬에서는 lifelines 패키지를 통해 Kaplan-Meier estimation와 그외 여러 Survival Analysis 도구를 사용할 수 있습니다.
간단한 예제를 통해 설명하겠습니다. 다음과 같이 가입 및 이탈 데이터를 확보했다고 가정합시다.
예제 데이터
| 회원 ID | 시간 | 상태 |
|---|---|---|
| Alice | D+1 | 이탈 |
| Bob | D+4 | 이탈 |
| Charlie | D+7 | 이탈 |
| Dan | D+12 | 활동중 |
| Eve | D+14 | 이탈 |
| Frank | D+20 | 활동중 |
| Grace | D+26 | 이탈 |
| Heidi | D+40 | 활동중 |
| Ivan | D+45 | 활동중 |
예제 데이터는 아래 코드로 간단하게 생성할 수 있습니다.
- 시간 칼럼은 경과 일수를 숫자로 입력했습니다.
- 상태 칼럼에는 이탈을
True, 활동중을False로 입력했습니다.True는 사건이 발생했다는 의미입니다.
import pandas as pd
data = pd.DataFrame(
{
'time': [1, 4, 7, 12, 14, 20, 26, 40, 45],
'event': [True, True, True, False, True, False, True, False, False]
},
index = ['Alice', 'Bob', 'Charlie', 'Dan', 'Eve', 'Frank', 'Grace', 'Heidi', 'Ivan']
)
Survival function 추정
먼저 생존함수를 추정해 봅시다. 다음 코드로 간단하게 할 수 있습니다.
from lifelines import KaplanMeierFitter
kmf = KaplanMeierFitter()
kmf.fit(data["time"], data["event"])
plot = kmf.plot_survival_function()
plot.set_xlabel('time (days)')
plot.set_ylabel('survival function, $\hat{S}(t)$')
plot
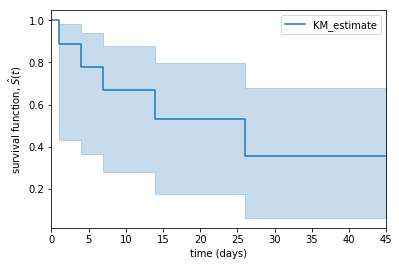
파란선은 생존함숫값입니다.
시간이 지날수록 이탈자가 발생하며 낮아지는 것을 볼 수 있습니다.
하늘색 영역은 신뢰구간입니다.
KaplanMeierFitter에 alpha 값을 지정해 조절할 수 있습니다.
기본값은 0.05 (95%)입니다.
Cumulative hazard function 추정
이번에는 누적위험함수를 추정해 봅시다. Nelson-Aalen estimator로 추정할 수 있습니다.
from lifelines import NelsonAalenFitter
naf = NelsonAalenFitter()
naf.fit(data["time"], data["event"])
plot = naf.plot_cumulative_hazard()
plot.set_xlabel('time (days)')
plot.set_ylabel('cumulative hazard function, $\hat{Λ}(t)$')
plot
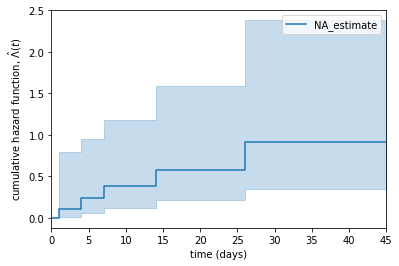
누적위험함수는 생존함수와 반대로 시간이 갈수록 증가합니다. 물론 시간이 갈수록 이탈위험이 늘어나는 것은 아닙니다. 이탈자가 누적되기 때문입니다.
lifeline 패키지는 이 밖에도 다양한 estimator를 제공합니다. 자세한 내용은 공식 문서를 참고하세요.
이탈방지 평가
우리가 서비스 이탈에 관심을 가지는 이유는 결국 이탈을 방지해야 하기 때문이겠죠. 서비스에 신규 가입한 고객에게 특별한 프로모션을 진행했다고 가정해 봅시다. 다음과 같이 A/B 테스트 결과를 얻었습니다. (편의상 똑같은 데이터를 두 번 사용합시다)
예제 데이터
실험군 (A군)
| 회원 ID | 시간 | 상태 |
|---|---|---|
| Alice_A | D+2 | 이탈 |
| Bob_A | D+4 | 이탈 |
| Charlie_A | D+9 | 활동중 |
| Dan_A | D+12 | 활동중 |
| Eve_A | D+19 | 활동중 |
| Frank_A | D+23 | 이탈 |
| Grace_A | D+26 | 이탈 |
| Heidi_A | D+41 | 활동중 |
| Ivan_A | D+48 | 활동중 |
대조군 (B군)
| 회원 ID | 시간 | 상태 |
|---|---|---|
| Alice_B | D+1 | 이탈 |
| Bob_B | D+4 | 이탈 |
| Charlie_B | D+7 | 이탈 |
| Dan_B | D+12 | 활동중 |
| Eve_B | D+14 | 이탈 |
| Frank_B | D+20 | 활동중 |
| Grace_B | D+26 | 이탈 |
| Heidi_B | D+40 | 활동중 |
| Ivan_B | D+45 | 활동중 |
data_A = pd.DataFrame(
{
'time': [2, 4, 9, 12, 19, 23, 26, 41, 48],
'event': [True, True, False, False, False, True, True, False, False]
},
index = ['Alice_A', 'Bob_A', 'Charlie_A', 'Dan_A', 'Eve_A', 'Frank_A', 'Grace_A', 'Heidi_A', 'Ivan_A']
)
data_B = pd.DataFrame(
{
'time': [1, 4, 7, 12, 14, 20, 26, 40, 45],
'event': [True, True, True, False, True, False, True, False, False]
},
index = ['Alice_B', 'Bob_B', 'Charlie_B', 'Dan_B', 'Eve_B', 'Frank_B', 'Grace_B', 'Heidi_B', 'Ivan_B']
)
효과 분석
두 그룹의 생존함수와 누적위험함수를 각각 추정해 봅시다.
kmf = KaplanMeierFitter()
kmf.fit(data_A["time"], data_A["event"], label="experiment")
ax_kmf = kmf.plot()
kmf.fit(data_B["time"], data_B["event"], label="control")
ax_kmf = kmf.plot(ax=ax_kmf)
ax_kmf.set_xlabel('time (days)')
ax_kmf.set_ylabel('survival function, $\hat{S}(t)$')
ax_kmf
naf = NelsonAalenFitter()
naf.fit(data_A["time"], data_A["event"], label="experiment")
ax_naf = naf.plot()
naf.fit(data_B["time"], data_B["event"], label="control")
ax_naf = naf.plot(ax=ax_naf)
ax_naf.set_xlabel('time (days)')
ax_naf.set_ylabel('cumulative hazard function, $\hat{Λ}(t)$')
ax_naf
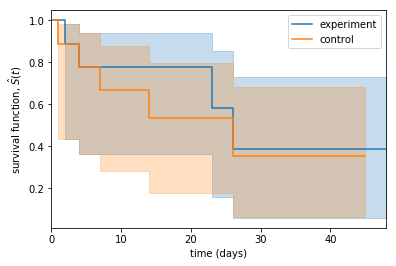
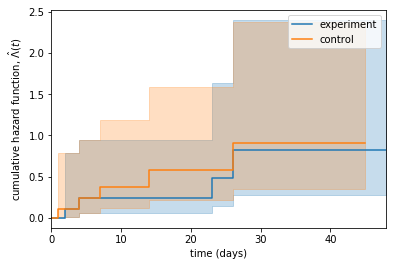
육안으로 봤을 땐 실험군 대상으로 진행한 프로모션이 효과가 있는듯 보입니다. 생존함숫값이 상승했고, 위험함숫값이 감소했죠. 하지만 95% 신뢰구간이 상당히 겹치므로 프로모션이 정말 고객이탈을 유의미하게 줄였는지 알아봐야 합니다. 생존분석에서는 Logrank test를 사용해 유의성을 검증합니다.
유의성 검증
Logrank test는 생존함수 분포를 비교하고 유의한 차이가 있는지 알아보는 가설 검정 기법입니다. Mantel-Cox test라고도 합니다. 파이썬에서는 다음과 같이 Logrank test를 실행할 수 있습니다.
from lifelines.statistics import logrank_test
logrank_test(data_A["time"], data_B["time"], data_A["event"], data_B["event"]).p_value
앞서 얻은 A/B 테스트 결과를 Logrank test로 검증해 보면 p-value가 0.6792로 계산됩니다.
즉, 프로모션은 유의한 성과를 얻지 못했습니다.
마무리
이번 포스트에서는 Survival Analysis를 소개하고, 파이썬에서 Survival Analysis를 수행하는 방법을 간단하게 알아봤습니다. Survival Analysis로 고객이탈과 잔존 비율을 살펴볼 수 있고, 고객이탈을 방지하는 A/B 테스트의 효과를 검증할 수 있습니다. 하지만 고객이탈을 사후에 분석하는 것보다 고객이탈을 예측하고 사전에 방지하는 것이 훨씬 더 중요할 겁니다.
다음 2편에서는 Survival Analysis를 활용해 고객이탈을 예측하는 여러 Predictive Analysis 기법을 다룹니다.
Read more
-
Survival Analysis (3/3)
Survival Analysis의 이론적 내용을 소개합니다. -
Survival Analysis (2/3)
Survival Analysis를 활용한 고객 이탈 예측 방법을 소개합니다.