클릭 한 번으로 실험 시작! 이터레이션 사이클을 단축하는 추천 실험 시스템 개발기
들어가며
아자르는 1:1 비디오 채팅을 통해 매일 전세계의 사용자들을 연결하고 있습니다. 비디오 채팅에서 즐거운 경험을 하려면 자신과 잘 맞는 사람을 만나야 하기에 추천 알고리즘의 역할이 매우 중요합니다.
지난 테크블로그에서는 하이퍼커넥트가 AI 기반 추천 시스템을 개발하여 어떻게 매치 경험을 향상시키고, 아자르의 성장을 견인하고 있는지에 대해 다루었습니다. AI Lab에서는 추천 알고리즘의 성능을 향상시키기 위해 끊임없이 더 향상된 알고리즘을 개발하고 있는데, 이런 알고리즘의 성능을 검증하려면 사용자 대상 실험을 해야 합니다.
예를 들어, 신규 가입자의 리텐션을 높이기 위해 새로운 추천 알고리즘을 개발했다고 가정해봅시다. 이 알고리즘이 기존보다 더 효과적인지를 확인하려면, 실험을 통해 실제 사용자의 반응을 비교해야 합니다. 이를 위해 신규 사용자 중 일부를 실험군으로 무작위 할당하여 새로운 알고리즘을 적용하고, 나머지 대조군에게는 기존 알고리즘을 유지한 채로 리텐션을 비롯한 주요 지표를 관찰합니다. 만약 실험군의 성과가 유의하게 더 좋다면, 새로운 알고리즘을 전체 사용자에게 적용하고, 그렇지 않으면 실험을 종료합니다.
이렇게 두 집단에 오직 ‘추천 알고리즘’만 다르게 적용하고, 그 외의 조건은 최대한 동일하게 유지한 상태에서 결과를 비교하는 실험 방식을 A/B 테스트라고 합니다. 추천 알고리즘에 대해 A/B 테스트를 하는 과정은 다음과 같이 정리할 수 있습니다.
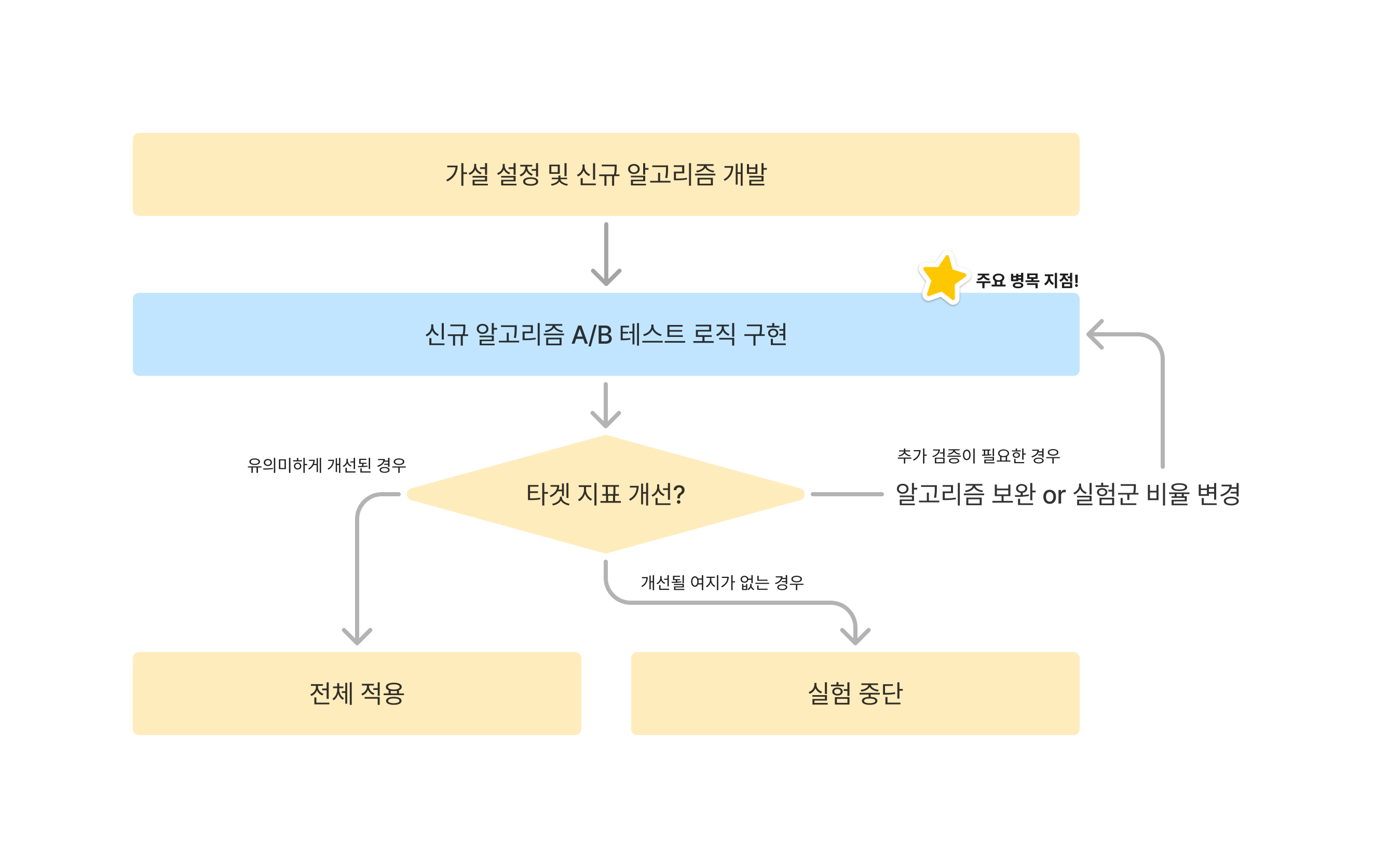
추천 시스템을 도입하던 초창기에, 저희는 신규 알고리즘 A/B 테스트 로직 구현 단계가 주요 병목 지점이라는 것을 파악했습니다. 왜냐하면, 신규 알고리즘을 적용하기까지는 여러 번의 이터레이션을 거치면서 알고리즘을 보완하고 실험군 비율을 조정해야 해서, A/B 테스트 로직의 변경이 자주 일어나기 때문입니다. 이 때마다 코드를 수정하고 테스트한 뒤 배포를 하려면 시간이 오래 걸리고, 실험 담당자가 소프트웨어 엔지니어의 스케줄에 맞춰야 해서 실험을 원하는 시점에 시작하지 못할 수도 있습니다.
빠른 추천 실험을 위한 로우 코드(Low Code) 실험 시스템
위와 같은 병목을 방지하고 빠르게 이터레이션을 돌며 추천 실험을 하기 위해, AI Lab에서는 추천 시스템 개발 초기에 코드 변경 및 배포 없이 설정 파일로 실험을 켤 수 있는 로우 코드 실험 시스템을 함께 개발했습니다. 이 시스템에서는 JSON 형식의 실험 명세를 작성하여, 런타임에 실험군을 자동으로 할당하고 신규 알고리즘을 적용할 수 있습니다.
예를 들어, 기존에 v1 알고리즘을 쓰고 있는 상태에서 한국의 신규 가입자를 대상으로 v2 알고리즘을 검증하고 싶다면 다음과 같이 JSON 설정을 작성하면 됩니다.
{
# 실험 대상 조건("AND" 형식으로 나열)
"target_condition": {
"country": "kr",
"is_newbie": true,
},
# 실험 설정
"treatments": [
{
"percent": 95, # 95%는 대조군으로 할당
"name": "신규 가입자 리텐션 향상 실험 [대조군]",
"algorithm": "v1" # 기존 알고리즘
}
},
{
"percent": 5, # 5%는 실험군으로 할당
"name": "신규 가입자 리텐션 향상 실험 [실험군]",
"algorithm": "v2" # 신규 알고리즘
}
]
}
이처럼 배포 없이 설정 파일만으로 추천 알고리즘과 실험 로직을 바꿀 수 있는 시스템을 도입한 덕분에, 저희는 AI 추천 시스템 도입 초기부터 빠른 이터레이션 사이클을 유지하며 실험 로직을 고도화할 수 있었습니다.
그러나 추천 시스템이 고도화되면서 새로운 문제가 생겨났습니다. 조직이 성장하며 더 많은 추천 실험을 진행하게 되었고, 이로 인해 설정 파일의 사이즈가 빠르게 불어났습니다. 또 단순히 알고리즘의 버전만 바꾸는 수준을 넘어, 알고리즘의 세부 동작(임계치나 가중치, 특정 기능의 on/off 여부 등)을 조절해야 하는 실험들이 등장했고, 이로 인해 설정 파일의 구조도 복잡해졌습니다. 이렇게 실험 설정이 길고 복잡해지다 보니 설정을 잘못 건드려서 잘못된 로직이 적용되는 사고가 잦아졌고, 실험 설정을 수정하거나 검토하는데 더 많은 시간이 소요되었습니다.
빠르게 성장하는 조직에서도 모멘텀을 잃지 않기 위해서는 이러한 문제들을 해결하는 것이 매우 중요했습니다. 이에 저희는 기존 시스템을 전면적으로 재설계하여, 더욱 발전된 실험 플랫폼인 Policy Engine을 개발하게 되었습니다. 지금부터 그 개발 과정을 소개합니다.
실험과 정책의 분리
새로운 실험을 할 때는 이미 적용된 기존 설정들을 고려해야 합니다. 예를 들어 국가와 플랫폼에 따라 세그먼트를 나누어, 세그먼트마다 다른 추천 알고리즘을 적용하고 있다고 가정해봅시다. 이 상태에서 매치 횟수가 10회 미만인 모든 유저를 대상으로 새로운 실험을 하려면 어떻게 해야 할까요? 이미 국가와 플랫폼에 따라 나뉘어져 있는 세그먼트를 매치 횟수에 따라 한 번 더 쪼개서 매치 횟수가 10회 미만인 유저에게는 새로운 실험 설정을, 10회 이상인 유저에게는 기존 설정을 적용해야 합니다. 이처럼 세그먼트가 세분화될수록 관리해야 하는 설정의 수가 기하급수적으로 증가하기 때문에, 새로운 실험 설정을 작성하기가 더 어려워집니다.
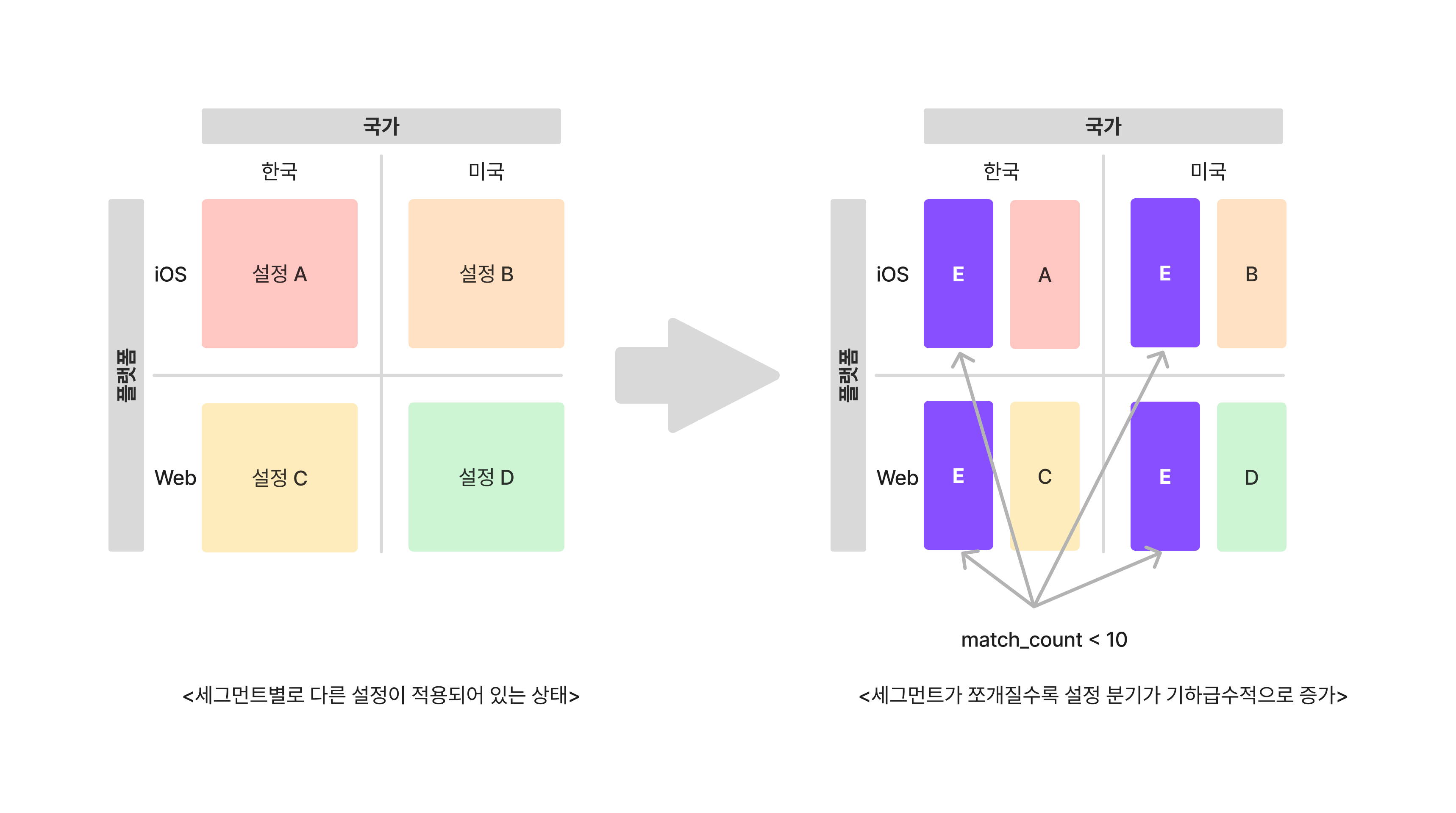
어떻게 하면 이미 전체 적용된 설정이 많은 상태에서도 새로운 실험을 빠르게 할 수 있을까요? 그동안 진행된 추천 실험 사례를 분석한 결과, 저희는 이미 전체 적용된 설정은 자주 변경되지 않는 반면, 현재 진행되고 있는 실험 설정은 자주 변경된다는 사실을 발견했습니다. 일반적으로 소프트웨어 엔지니어링에서는 이렇게 변경 주기가 서로 다른 데이터 간의 의존 관계를 끊어 디커플링(decoupling)하는 것을 권장합니다.
이 점에 기반하여, 저희는 PolicyEngine에 Policy와 Experiment라는 두 가지 개념을 도입했습니다.
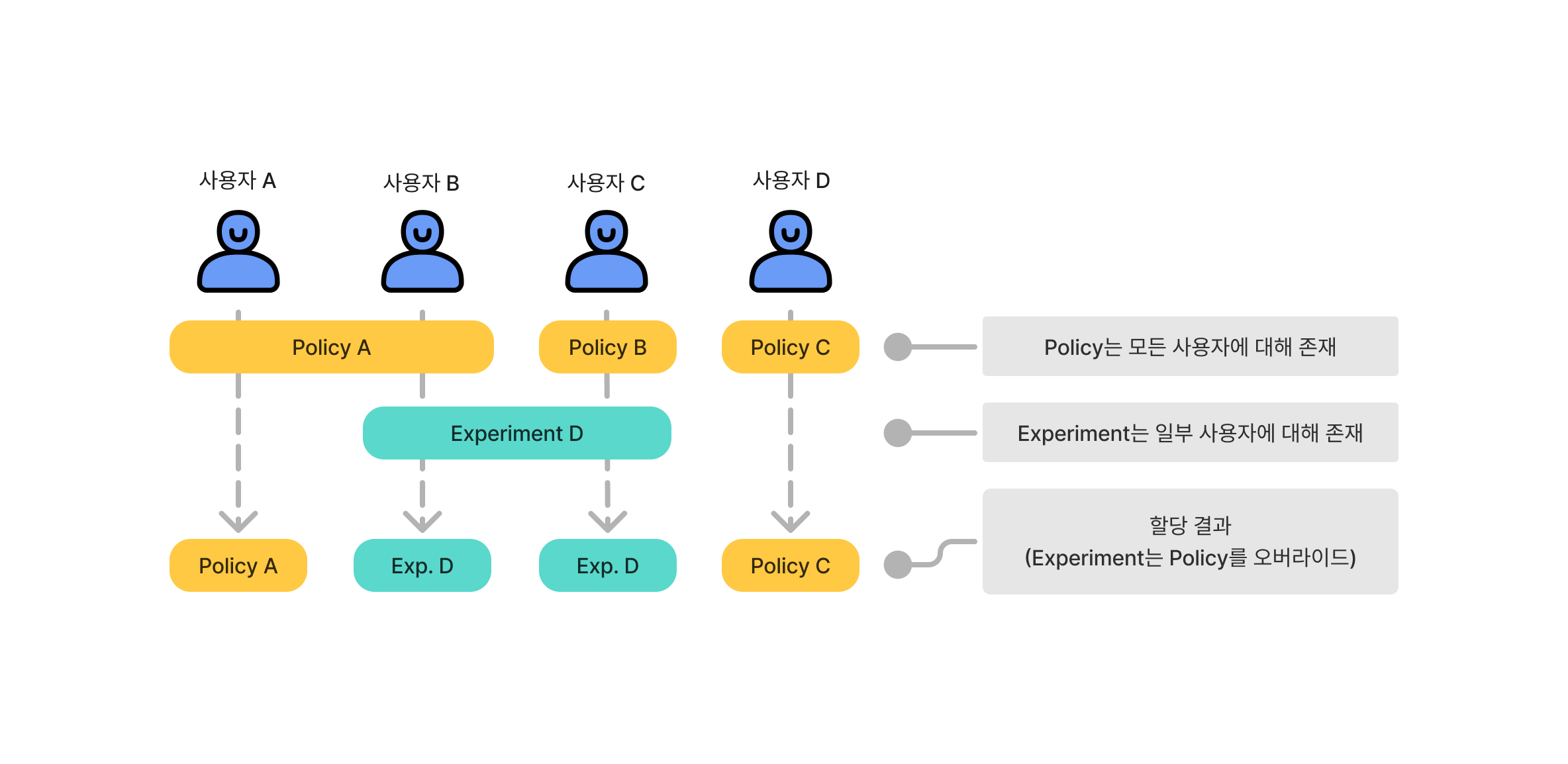
Policy는 특정 사용자에게 기본적으로 적용되는 설정으로, 전체 적용되어 자주 바뀌지 않는 설정에 해당합니다. 일종의 디폴트 값이라고 볼 수 있습니다. 반면 Experiment는 실험 집단에 속한 사용자를 위한 설정입니다. 사용자는 Policy 설정과 Experiment 설정을 동시에 가질 수도 있으며, 이 때는 Experiment가 Policy보다 우선권을 가집니다. 따라서 사용자에게 Policy 설정만 존재한다면 Policy 설정이 그대로 적용되지만, 만약 Experiment 설정이 존재한다면 Policy 설정을 오버라이드하여 Experiment 설정이 적용됩니다.
예를 들어, 사용자 A와 B에게 Policy A 설정이 적용되어 있다고 가정해봅시다. 만약 사용자 B를 대상으로 실험을 하기 위해 Experiment D 설정을 추가할 경우, 사용자 B에 대해서는 기존에 적용되던 Policy A 대신 Experiment D의 설정이 적용됩니다. 하지만 실험 대상이 아닌 사용자 A에게는 기존대로 Policy A 설정이 적용됩니다.
집단 설정에 특화된 DSL의 도입
기존 시스템에서는 JSON 키-값 쌍을 이용해 실험 대상 집단을 표현했습니다. 이 방식은 구현이 간단하면서, 국가나 성별과 같은 큰 단위의 세그먼트를 쉽게 표현할 수 있어 추천 시스템 초기 실험에 적합했습니다.
그러나 추천 시스템이 고도화되면서, 더 복잡한 조건에 따라 세그먼트를 나누는 경우가 많아졌습니다. 예를 들어, 안드로이드 또는 웹으로 접속했고 매치 횟수가 10회 이상인 사용자를 JSON으로 표현할 때는 아래와 같이 연산자를 중첩해야 합니다. 그러나 JSON은 계층 구조 표현에 최적화된 언어이기 때문에, 조건 표현에 쓸 경우 금세 장황해지고 사람이 이해하기 어렵다는 단점이 있습니다.
/* 장황한 JSON 표현식 */
{
"target": {
"AND": [
{
"OR": [
{ "platform": "ANDROID" },
{ "platform": "WEB" },
]
},
{
"GTE": {
"match_count": 10
}
}
]
}
}
실험 대상을 한 눈에 이해할 수 없다면, 실험 현황을 파악하기도 어렵고 실수로 설정을 잘못 작성할 가능성도 높아질 것입니다. 이를 방지하려면 실험 집단 표현에 특화된 DSL(도메인 특화 언어)가 필요하다고 판단했습니다. 요구사항은 다음과 같았습니다.
- 다양한 논리 연산자(
and,or,not등)와 비교연산자를 지원한다. - 러닝 커브가 낮아 실험을 담당하는 데이터 사이언티스트나 ML 엔지니어가 쉽게 익힐 수 있다.
- 선언적(declarative) 문법을 지원하여 쉽게 이해할 수 있다.
- 파서(parser)의 구현 비용이 낮다.
이 조건들을 만족하는 언어에는 Python이나 JavaScript 같은 스크립팅 언어 또는 Google의 CEL(Common Expression Language) 등이 있었으며, 저희는 그 중에서 Python을 채택했습니다. Python은 데이터 사이언티스트와 ML 엔지니어들에게 익숙한 언어이기 때문에 진입 장벽이 낮고, and, or, not, in 등 자연어에 가까운 선언적인 연산자 문법을 제공해 사람이 이해하기 쉬우며, ast 패키지나 eval() 함수를 이용해 쉽게 파싱하고 실행할 수 있기 때문입니다.
엄밀히 말하면, Python을 그대로 쓰지 않고 제한된 문맥 안에서 활용할 수 있도록 부분 집합 언어(subset language)를 정의했습니다. 이렇게 하면 Python 언어의 낮은 학습 곡선을 활용하면서, 실험 설정에 필요한 표현력을 갖출 수 있습니다.
다음은 앞서 살펴본 예시인 안드로이드 또는 웹으로 접속했고 매치 횟수가 10회 이상인 사용자를 DSL 구문으로 나타낸 것입니다. 이 때, user 변수는 platform, match_count, country 등 사용자의 문맥 정보를 담고 있습니다. JSON에 비해 훨씬 간결하고, 이해하기도 쉬운 것을 확인할 수 있습니다.
lambda user: user.platform in ['ANDROID', 'WEB'] and user.match_count >= 10
저희는 여기서 더 나아가, “실험 집단 뿐만 아니라 전체 설정을 DSL 문법으로 표현하면 어떨까?”라는 질문을 던졌습니다. Python의 문법을 사용하면 비슷한 패턴의 설정을 공통 함수로 만들 수 있어, 복잡한 설정도 쉽게 작성할 수 있기 때문입니다.
예를 들어, “10회 이상 매치를 한 사용자에게 가산점을 적용하는 알고리즘”이 있다고 가정합시다. 저희가 정의한 DSL에서는 사용자에게 적용하는 모든 조치를 Treatment로 표현합니다. 이 중 ConditionalTreatment를 사용하면, Condition에 정의한 조건에 따라 다른 treatment를 반환하도록 분기 로직을 만들 수 있습니다.(일종의 if 문을 객체로 표현한 셈입니다.) 여기에 DSL의 함수 기능을 응용하면, 앞서 언급한 알고리즘, 즉 “10회 이상 매치시 가산점을 부여”에 해당하는 ConditionalTreatment 구문을 동적으로 생성하는 함수를 만들 수 있습니다.
def add_bonus(bonus):
return ConditionalTreatment(
conditions = [
Condition(
target=lambda user: user.match_count < 10,
treatment=EmptyTreatment() # 아무 조치도 하지 않음
),
Condition(
target=lambda user: user.match_count >= 10,
treatment=BonusScoreTreatment(bonus)
),
]
)
이제 서로 다른 타이밍에 서로 다른 가산점을 적용하는 A/B 테스트를 작성해봅시다. 먼저 ABGroup 구문을 정의하고, 위에서 만든 add_bonus() 함수를 호출해 각 ABGroup에 해당하는 ConditionalTreatment를 동적으로 생성하여 주입하면 됩니다. 이렇게 하면 ABGroup마다 Treatment와 Condition을 중복 정의할 필요가 없어 코드의 양이 줄어들고, 함수 이름을 보고 로직의 의도를 쉽게 파악할 수 있어 가독성도 높아집니다.
Experiment(
target=lambda user: user.platform in ['ANDROID', 'WEB'],
ab_groups=[
ABGroup(ratio=0.90, treatment=add_bonus(0)),
ABGroup(ratio=0.05, treatment=add_bonus(10)),
ABGroup(ratio=0.05, treatment=add_bonus(20)),
]
)
이처럼 실험 설정 전체를 DSL 구문으로 작성할 수 있게 하자 즉시 효과가 나타났습니다. 한 사례에서는, 국가별 알고리즘 세부 설정에서 공통된 패턴을 찾아 함수로 묶었더니, 설정 코드 라인이 7천 줄 → 50줄로 무려 99% 감소했습니다.
또 다른 사례에서는, 수십 개의 설정 조합을 동시에 테스트해야 해서 설정을 바꾸고 리뷰할 때마다 많은 시간이 소요되었습니다. 그런데 설정 조합을 렌더링하는 공통 함수를 만들어, 함수 인자만 바꾸면 자동으로 다른 설정 조합이 만들어지게 하자 설정 변경과 리뷰에 소요되는 시간이 4일에서 반나절로 87% 단축되었습니다.
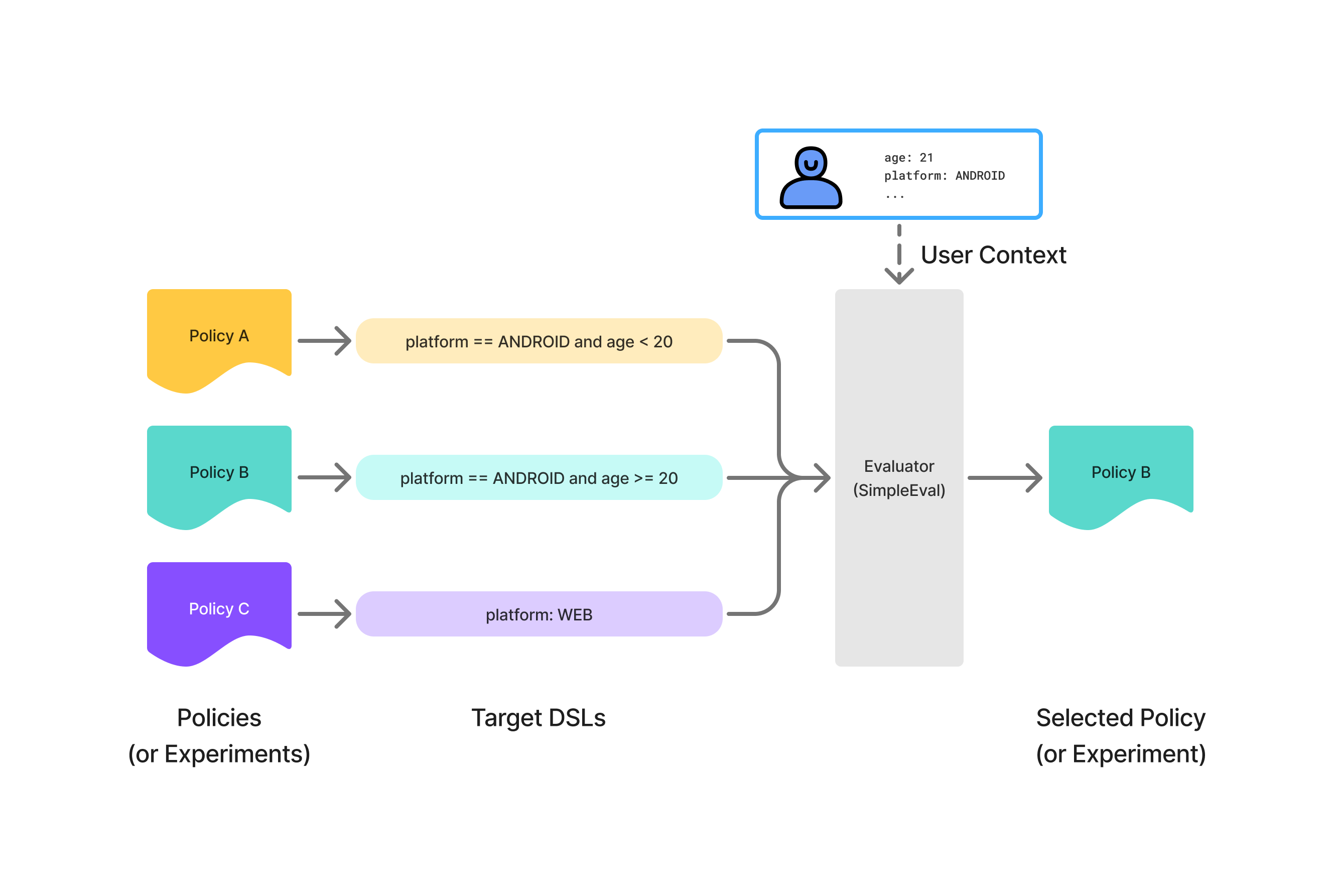
이제 DSL로 작성한 설정이 어떻게 사용자에게 적용되는지 살펴보겠습니다. 실험 시스템에 등록된 모든 Policy와 Experiment 설정은 Evaluator라는 컴포넌트에 주입됩니다. Evaluator는 ast 패키지를 이용해 DSL 구문을 파싱한 다음, simpleeval 패키지를 이용해 target 구문을 실행하여 사용자에게 해당되는 설정인지 여부를 판별하는 컴포넌트입니다. 사용자로부터 매치 요청이 들어올 때마다, Evaluator는 각 Policy 및 Experiment을 순회하며 DSL 구문을 실행해서 해당 사용자에게 적용할 설정을 찾아냅니다.
MECE 검증으로 실험 간 충돌 막기
여러 실험을 동시에 진행하면 의도치 않게 실험 집단이 서로 겹쳐 설정 충돌이 발생할 수 있습니다. 추천 시스템 도입 초기에는 실험 개수가 많지 않았기 때문에 사람이 직접 충돌 여부를 확인할 수 있었습니다. 그러나 실험의 개수가 많아지고, DSL을 도입하여 더 복잡한 조건에 따라 세그먼트를 나눌 수 있게 되면서, 실험 간 충돌을 사람이 직접 검증하는 것이 사실상 불가능해졌습니다.
이를 해결하기 위해, 저희는 정적 분석(static check)으로 실험 간 충돌을 자동 감지하는 MECE 검증 기능을 도입했습니다.
MECE(Mutually Exclusive & Collectively Exhaustive)란 ‘서로 중복되지 않고, 전체적으로 누락되지 않는다’는 원칙입니다. 예를 들어 match_count >= 10 과 match_count < 11이라는 두 조건이 있다고 해 봅시다. 먼저 두 조건을 합치면 match_count의 모든 가능한 값을 포함하므로 collectively exhaustive(전체적으로 누락되지 않음) 조건을 만족합니다. 하지만, match_count의 값이 10일 때는 두 조건에 모두 해당되므로 mutually exclusive(서로 중복되지 않음) 조건은 만족하지 않습니다. 이처럼 MECE 조건을 검증하면 실험 간에 서로 집단이 겹치거나, 특정 집단을 누락하는 일이 없게 사전에 막을 수 있습니다.
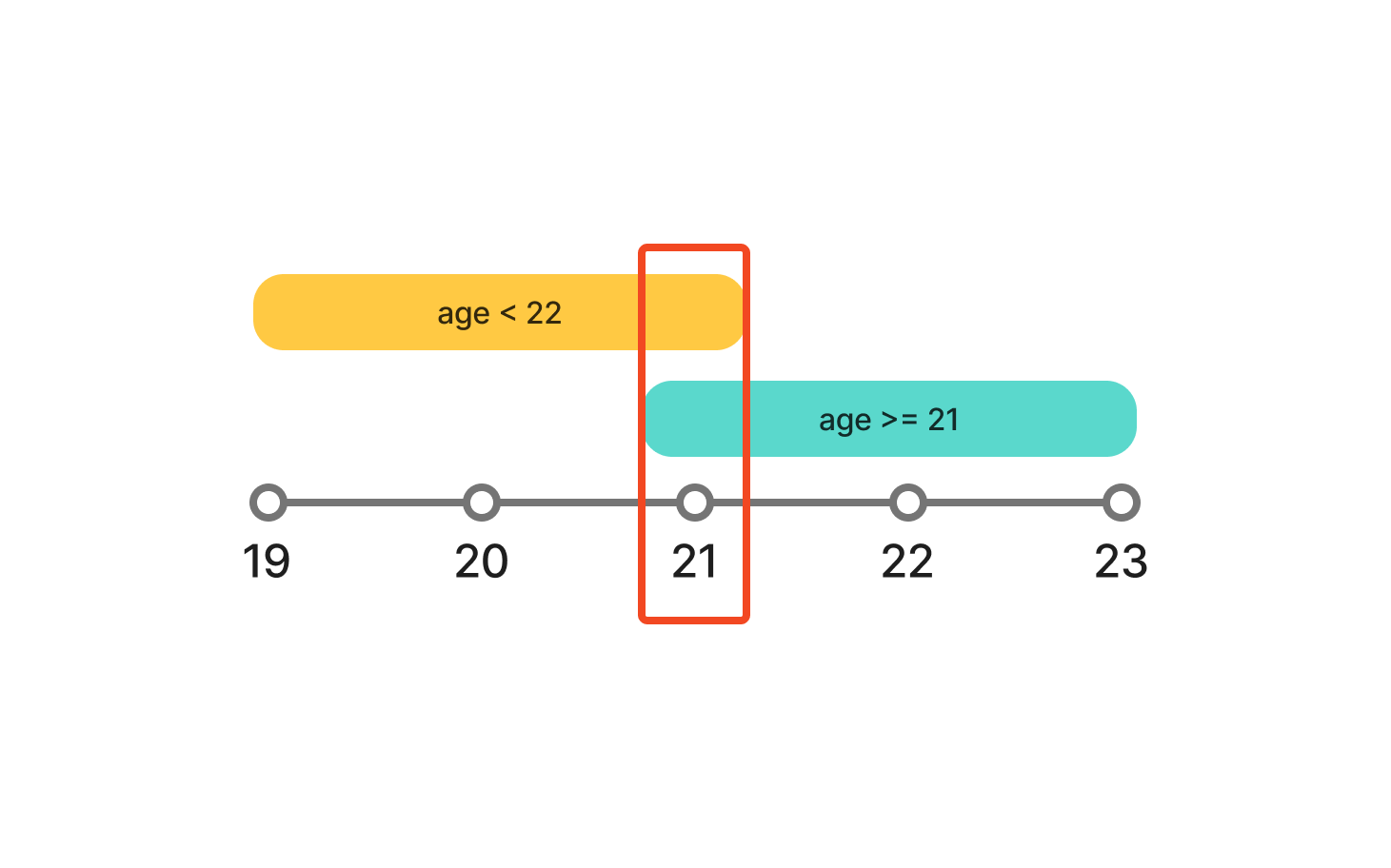
MECE를 프로그래밍적으로 구현하려면 집단 간 교집합을 구하는 수학적인 검증 알고리즘이 필요합니다. 이 문제를 해결하기 위해 여러 기술을 조사한 결과, 복잡한 논리 연산이나 방정식을 풀어주는 데 특화된 Theorem Prover라는 기술을 발견했습니다. Theorem Prover란 수학적 정리(theorem)의 증명이나 해를 자동으로 찾아주는 알고리즘 또는 소프트웨어를 말합니다. 데이터 분석 도구인 R이나 시뮬레이션에 사용되는 Matlab도 일종의 theorem prover라고 할 수 있습니다. 저희는 다양한 옵션들을 조사한 끝에, 프로덕션 환경에서 안정적으로 사용할 수 있고 지속적으로 관리되는 Microsoft의 Z3를 채택해 MECE 검증 기능을 구현했습니다.
다음 그림은 MECE 검증 과정을 도식화한 것입니다.
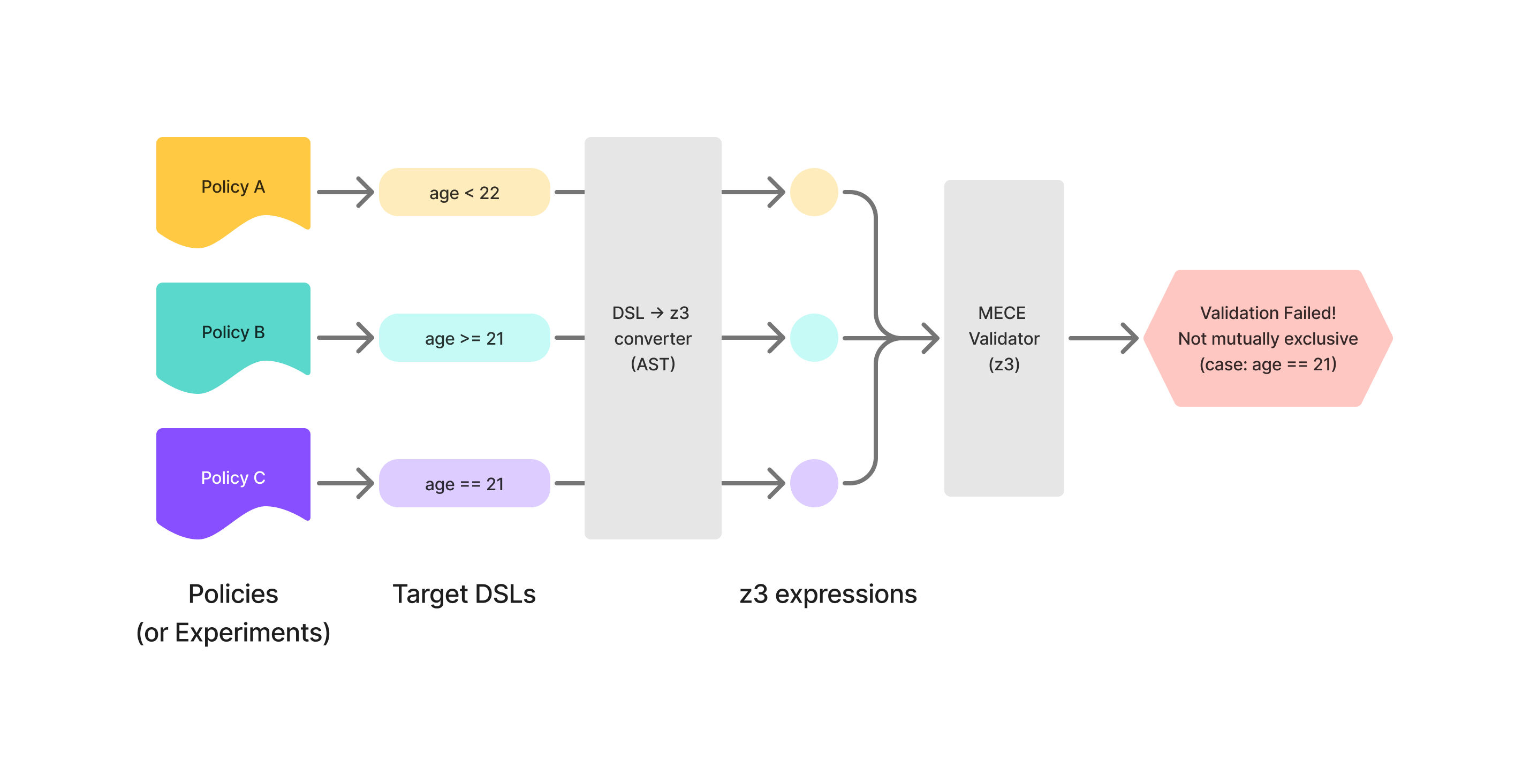
Z3를 이용해 MECE 검증을 하려면, Python으로 작성된 DSL을 Z3에서 바로 사용할 수 없기 때문에 별도의 변환 과정이 필요합니다. 이를 위해 우선 ast 패키지를 이용해 DSL을 AST(Abstract Syntax Tree) 형태로 파싱하고, 이를 Z3 표현식으로 변환하여 MECE 여부를 검증합니다.
PolicyEngine에서는 실험 설정 PR을 올리면 자동으로 MECE 검증이 수행됩니다. 따라서 실험 설정이 많고 복잡하더라도 충돌 여부를 정확하게 알 수 있게 되었습니다. 실제로 여러 건의 실험에 대해 MECE 검증 로직이 충돌을 감지해 사고를 예방할 수 있었고, 설정을 리뷰하는 사람의 심리적 부담도 크게 줄어들었습니다.
Bonus: 실시간 실험 모니터링 대시보드
추천 알고리즘 실험은 UI 실험과 달리 변경 사항이 가시적으로 보이지 않아 제대로 적용되었는지 확인하기가 어렵습니다. 기존에는 실험이 제대로 설정되었는지 확인하기 위해 추천 로직의 시스템 로그를 쿼리로 확인했습니다. 그러나 쿼리를 작성하는데 적지 않은 시간이 소요되었고, 작성 과정에서 실수를 하거나 일부 지표를 놓치는 경우가 많았습니다.
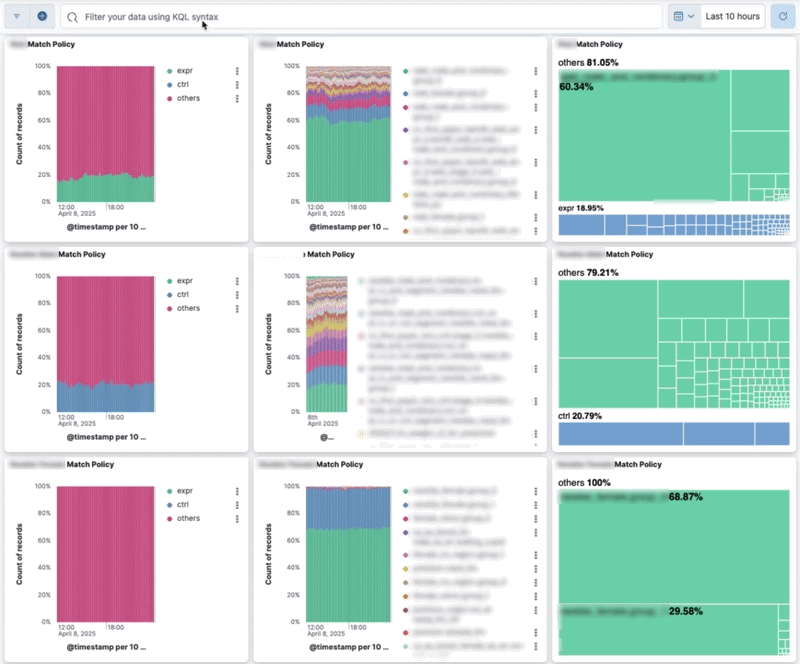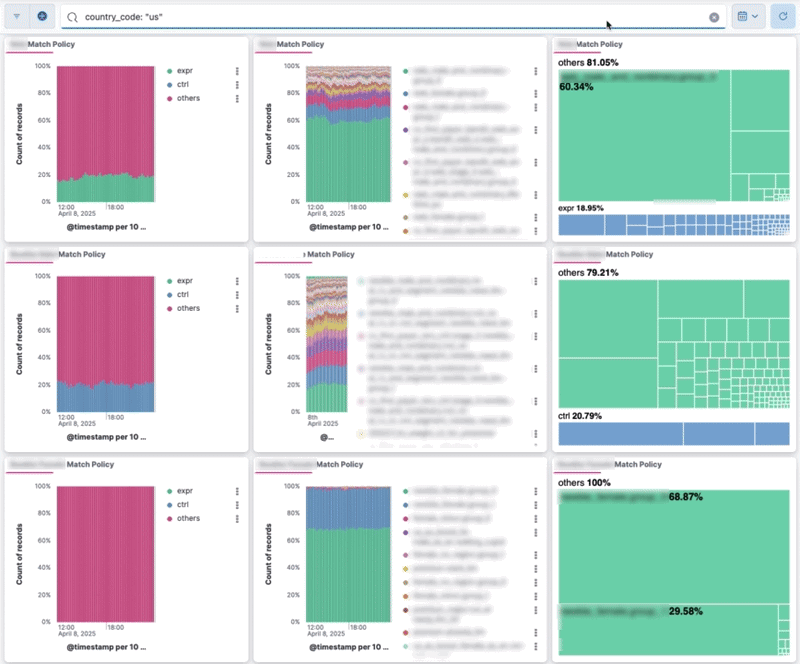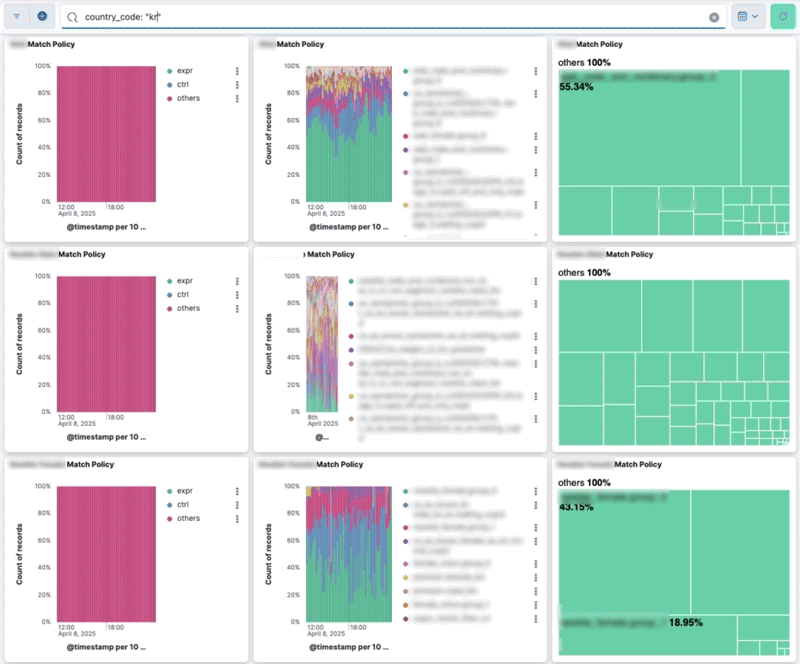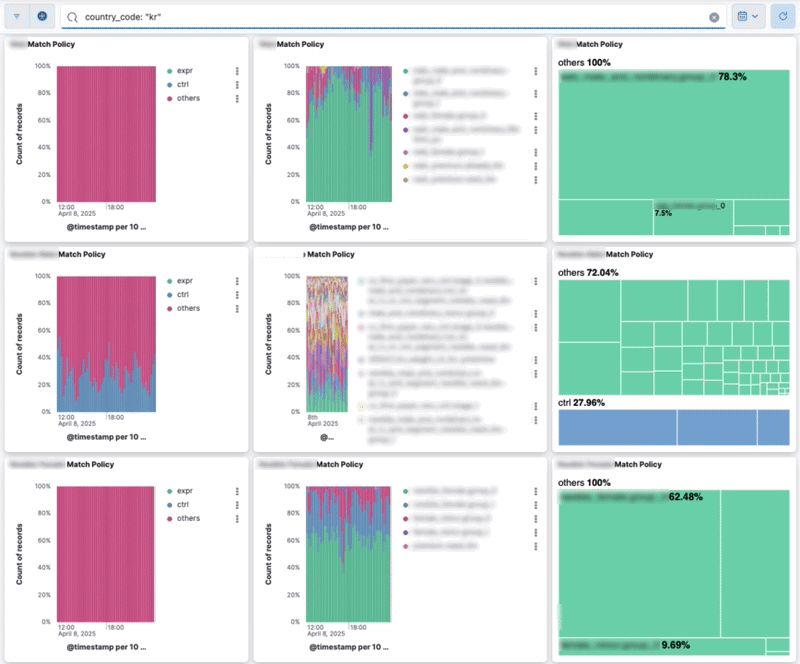
반복적인 검증 프로세스를 자동화하고 신뢰도를 높이기 위해, 실험 설정의 할당 현황을 시각적으로 확인할 수 있는 대시보드를 구축했습니다. 이 대시보드의 가장 큰 장점은 Lucene query를 지원해 특정 집단만 필터링해서 볼 수 있다는 점입니다. 특히 실험 집단의 모수가 적으면 지표가 희석되어 확인이 어려운데, 이 때 해당 국가의 사용자만 표시하도록 필터링할 수 있습니다. 예를 들어 쿼리 창에 country_code: "us" 를 입력하면 미국 사용자의 데이터만 포함하도록 대시보드가 업데이트됩니다.
PolicyEngine 도입의 결과
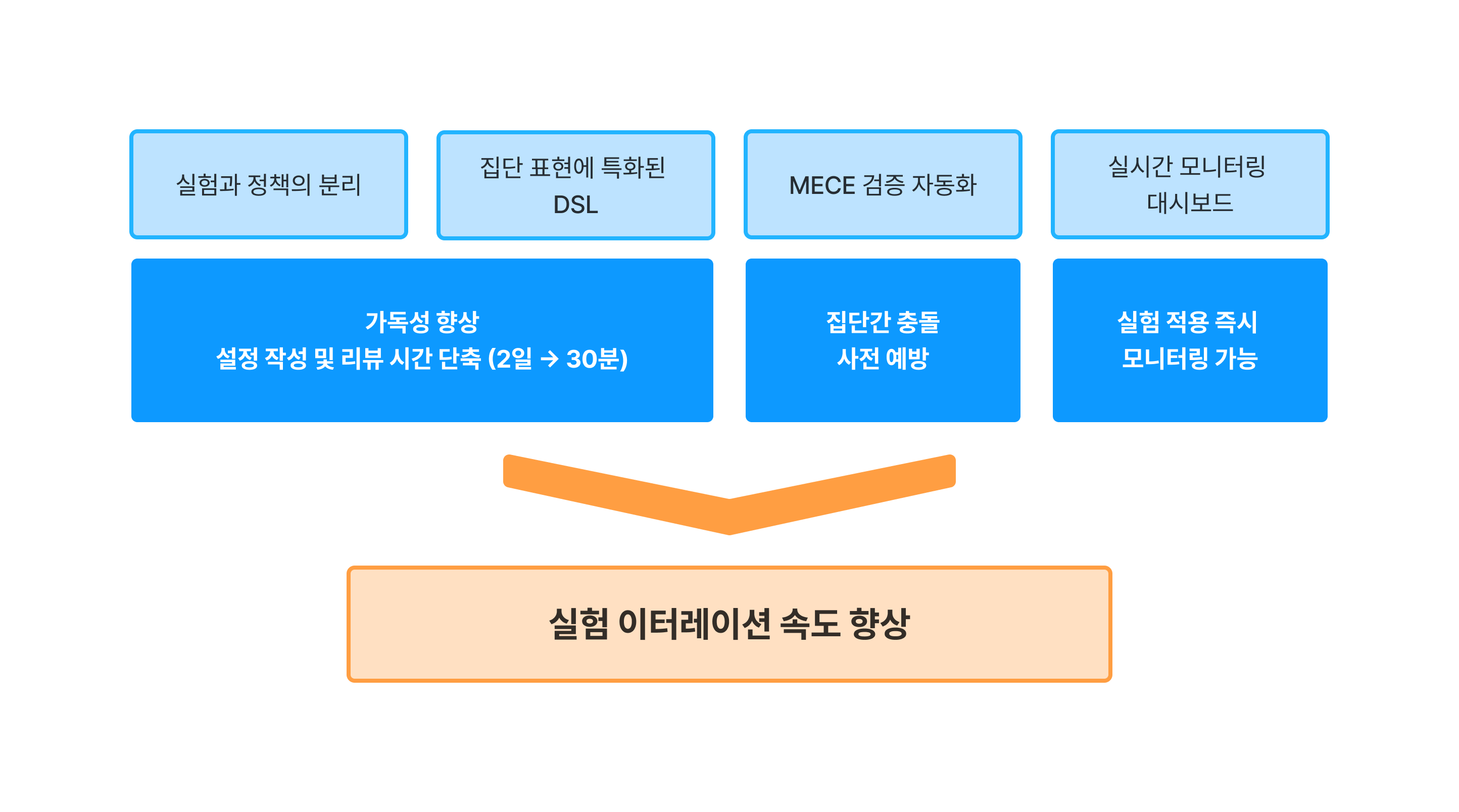
새로운 실험 시스템 Policy Engine의 도입은 매우 효과적이었습니다. 실험과 정책을 분리하고 집단 설정에 특화된 DSL을 도입하니 실험 설정을 이해하기가 쉬워졌고, 그 결과 실험 설정 작성과 리뷰에 소요되는 평균 시간이 2일 → 30분으로 무려 97% 단축되었습니다. 또 MECE 검증을 자동화하여 실험끼리 집단이 겹치는 문제를 사전에 예방할 수 있게 되었고, 실시간 모니터링 대시보드를 구축하여 실험 적용 즉시 제대로 적용되었는지 모니터링할 수 있게 되었습니다. 한 동료 분께서는 새로 바뀐 시스템이 너무 편하다며 감탄을 하시기도 했답니다.
그 중에서도 가장 큰 변화는 실험 담당자가 소프트웨어 엔지니어의 도움 없이도 직접 실험 설정을 할 수 있게 되었다는 점입니다. 기존 시스템에서도 원칙적으로는 JSON을 수정하여 실험을 켤 수 있었지만, 설정이 매우 많고 복잡하여 추천 시스템을 관리하는 엔지니어가 아니면 구조를 이해하기 어려웠습니다. 그러나 실험 설정을 쉽게 읽을 수 있게 되고, 안전 장치와 모니터링 시스템을 도입하여 심리적인 부담감이 크게 줄어들자, 실험 담당자들이 자발적으로 설정 작성 방법을 배워 직접 설정을 작성하기 시작했습니다. 현재는 대부분의 추천 실험들이 소프트웨어 엔지니어의 개입 없이 설정 변경만으로 진행되고 있습니다.
앞으로의 과제
Policy Engine은 Python 기반의 설정 스키마와 DSL을 사용해 기존 시스템보다 더 직관적인 설정을 제공하지만, 개발 경험이 없는 구성원들에게는 여전히 사용하기 어렵다는 한계가 있습니다. 이에 따라, 최근 발전하고 있는 생성형 AI 기술을 활용하여 자연어 기반의 관리자 인터페이스를 제공하려고 합니다. 이를 통해 개발 경험이 없는 구성원도 실험 현황을 쉽게 이해할 수 있고, 실험 담당자도 에이전트의 자동완성 기능을 통해 더 쉽고 빠르게 실험을 설정할 수 있는 환경을 만들 예정입니다.
맺으며
“조직의 의사결정 구조가 시스템의 구조를 닮는다.” – 콘웨이의 법칙 “원하는 시스템 구조에 맞추어 조직의 의사결정 구조를 재편한다.” – 역 콘웨이 전략
미국의 컴퓨터 과학자 맬빈 콘웨이는 “시스템의 구조는 조직의 의사결정 구조를 닮는다”라는 콘웨이 법칙(Conway’s Law)을 제시했습니다. 이 법칙을 역으로 적용한 접근이 바로 역 콘웨이 전략(Reverse Conway’s Maneuver)입니다. 즉, 이상적인 시스템 구조를 먼저 정의하고, 그에 맞게 조직의 의사결정 구조를 정렬하는 방식입니다.
AI Lab에서는 역 콘웨이 전략처럼 PolicyEngine을 도입해, 실험 담당자가 소프트웨어 엔지니어를 거치지 않고 주도적으로 실험을 할 수 있도록 의사결정 구조를 개선했습니다. 그 결과 점점 복잡해지는 요구사항 속에서도 안전하면서도 빠르게 실험을 지속할 수 있는 기반을 마련할 수 있었습니다.
AI Lab에서는 더 빠르게 비즈니스 임팩트를 내고, 아자르의 사용자 경험을 향상시킬 수 있는 방법을 끊임없이 고민하고 있습니다. 저희의 도전을 계속 지켜봐 주세요!