Flink SQL 도입기
안녕하세요. Azar Matching Dev Team 의 Zeze 입니다.
Flink 는 대다수의 백엔드 엔지니어들에게 친숙한 기술은 아니지만, 이벤트 스트리밍 처리를 위한 대표적인 기술 중 하나입니다.
대규모 실시간 데이터 스트리밍 처리를 위해 분산 환경에서 빠르고 유연하게 동작하는 오픈소스 데이터 처리 엔진이며, 팀 내에서는 Azar 의 핵심 로직인 매칭 서버를 구현하는 데에 사용되고 있고,
사내에서는 보통 Kafka 를 source 및 sink 로 사용하는 애플리케이션 코드를 직접 작성하는 방식으로 많이 사용하고 있습니다.
오늘 소개할 Flink SQL 은 애플리케이션 코드를 직접 작성하지 않고도 SQL 을 통해 이벤트 스트리밍 처리 앱을 구현할 수 있도록 해주는 기능입니다.
이번 글에서는 이벤트 스트리밍 처리를 위해 Flink SQL 을 채택한 이유와 클러스터 환경 구축 및 운영 경험을 공유하려고 합니다.
Flink SQL 도입 배경
레거시 스트리밍 앱의 위협
Azar Matching Dev Team 에서 관리하던 여러 Flink 기반 앱들 중, CPU 를 무려 96개나 사용하던 매우 무거운 레거시 앱이 있었습니다.
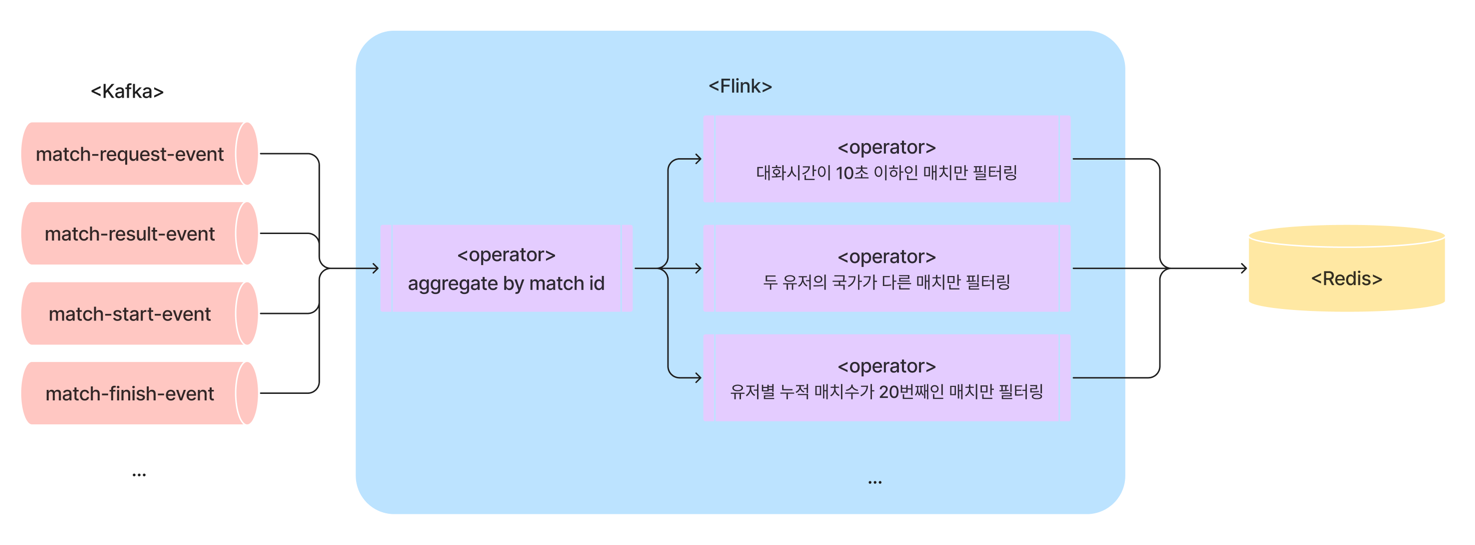
이 앱은 여러 매치 이벤트를 조인하고, 로직에 따라 조건부로 새로운 이벤트 발행하거나 Redis에 플래그를 저장하는 등 다양한 기능을 한 곳에 몰아넣은 모놀리식 구조였습니다.
유지보수가 어려운 상태에서 전사 인프라 작업으로 인해 해당 앱의 실행 노드를 변경하자, 앱이 정상적으로 동작하지 않는 문제가 발생했고, 몇 차례 단순 튜닝을 시도해 보았지만 빠르게 해결하기 어려웠습니다.
그 결과, 높은 운영 피로도를 감수하며 이 앱을 계속 유지보수 할지 아니면 다른 방법으로 대체할지를 결정해야 했습니다.
고를 수 있었던 선택지들
다행히 기존 앱의 로직 중 중요한 이벤트들을 조인하는 기능은 (아래 그림에서 aggregate by match id 에 해당하는 부분) 별도의 프로젝트를 진행해 이미 새로운 Flink 앱으로 구현해 놓은 상태였기 때문에 이를 레버리지하는게 유리한 상황이었습니다.
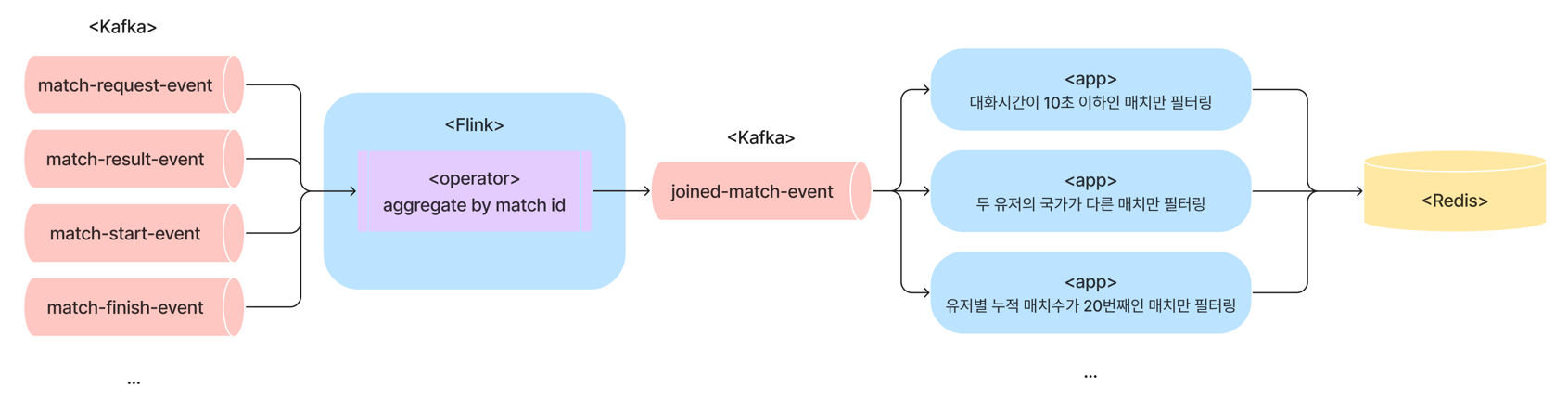
그렇다면 위 그림처럼 이벤트 조인 이후 수행하는 조건부 이벤트 발행 또는 로직 수행 부분을 어떤 방식으로 대체할지를 고민해야 했는데요, 다음과 같은 선택지 및 장단점이 있었습니다.
- 하나의 Flink App 으로 구현
- 장점 - 하나의 앱만 관리하면 되므로 운영이 간편합니다.
- 단점 - 또 다시 거대한 앱이 될 가능성이 크며, 앱의 한 부분이 실패할 경우 다른 기능도 영향받기 쉽습니다.
- 여러 Flink App 으로 구현
- 장점 - 각 앱을 독립적으로 관리할 수 있어 유연합니다.
- 단점 - 앱의 개수가 늘어나면, 클러스터/리소스/배포 관점에서 부담이 증가할 수 있습니다.
- Flink SQL 을 사용
- 장점 - 쿼리를 통해 로직을 정의하므로 빠른 개발이 가능하며, 하나의 클러스터만 관리하면 됩니다.
- 단점 - SQL 만으로는 복잡한 로직을 표현하기 어렵고, 팀이 클러스터 관리에 익숙하지 않다면 어려울 수 있습니다.
팀에서는 Flink 의 내부 구현에 대해 꽤나 이해도가 높아져 있는 상태였기 때문에, Flink SQL 을 사용하면 생산성 및 운영 효율성에서 이점이 있을 것이라고 판단하여 본격적으로 Flink SQL 도입을 검토하기 시작했습니다.
Flink SQL 을 선택한 이유 및 대안 기술과의 비교
Flink SQL 을 본격적으로 도입하기 전에, 비슷한 스트리밍 쿼리 엔진 기술들인 ksqlDB 와 Spark Structured Streaming 에 대해서도 검토해보고 비교해 보았습니다. Flink SQL 을 선택하게 된 가장 중요한 포인트는 아래 3가지 정도라고 할 수 있는데요,
-
High Availability
Flink 는 stateful 한 처리를 지원하면서, Checkpoint와 Savepoint를 통해 앱의 작업 상태를 주기적이거나 원하는 시점에 안정적으로 저장 및 복구할 수 있습니다. 또한 클러스터에서 전반적인 job 의 작업 분배 및 상태를 관리하는 구성요소인 JobManager 는 leader-standby 형태로 HA 모드로 구성할 수 있습니다. 실질적으로 job 의 연산을 수행하는 TaskManager 는 일부가 fail 할 경우 job 의 재시도 전략에 따라 fail 한 TaskManager 의 작업을 다른 TaskManager 로 재분배하여 작업을 계속할 수 있습니다.
-
윈도우, 조인, 이벤트 타임 처리, 워터마크 등 고급 스트리밍 기능을 지원
Flink SQL 은 다른 스트리밍 쿼리 엔진 기술들과 비슷하게 SQL 문법을 통해 다양한 스트리밍 처리 기능을 지원합니다. 단순하게
SELECT로 데이터의 형태를 변환하고WHERE절로 조건식에 따라 레코드를 필터링하는 기본 기능 외에도,JOIN을 통해 여러 스트림을 결합하거나,UNION을 통해 스트림들을 합칠 수 있습니다. 그리고 윈도우 기능을 사용하여 이벤트 시간 기반으로 데이터를 집계할 수 있으며, Flink SQL 은 tumbling, hopping (sliding), session window 등 다양한 타입의 윈도우 처리를 지원합니다. 각 윈도우 타입의 동작 방식에 대해서 궁금하시다면 Dante.R 께서 쓰신 ksqlDB Deep Dive 의Windowed Aggregation파트를 참고해보시면 좋을 것 같습니다. 또한 이벤트 타임 처리를 지원하며, 워터마크를 활용하여 얼마만큼의 지연 데이터까지 허용할 것인지도 설정해 줄 수 있습니다. 정말 쿼리로 단순하게 stateful streaming app 을 작성할 수 있는지 궁금해 하실 분들을 위해 Appendix 에 hopping window 를 사용하는 예제를 추가해두었습니다. -
User Defined Function & Custom Connector 를 통한 확장성
Flink SQL 은 UDF (User Defined Function) 를 통해 사용자 정의 함수를 작성할 수 있으며, Custom Connector 작성을 통해 다양한 데이터 소스와 sink 를 연결할 수 있습니다. 이 특성은 저희 팀이 Flink 의 내부 동작 방식에 꽤나 익숙했기 때문에 장점이 될 수 있었는데요, 앞서 말씀드렸듯 기존 레거시의 대부분이 Redis 의 SET 또는 INCR 커맨드를 사용하는 패턴인 상황에서 Flink 공식 Redis Connector 가 없어 Redis Connector 를 직접 작성하여 사용했습니다. 또한 당시에는 ARRAY 타입에 대해 교집합을 구하는 등의 빌트인 함수를 지원하지 않았기 때문에, 이러한 기능도 UDF 를 통해 구현하여 쿼리에 사용하였습니다.
vs ksqlDB
ksqlDB 의 경우 현재 사내에서 Kafka 를 위해 사용하는 Confluent 플랫폼에 해당 기능이 포함되어 있고, 이미 전사적으로 사용하는 사례가 꽤 있었습니다. 그러나 stateful 스트리밍 처리에서 HA 동작이 다소 비효율적인 면이 있다고 판단했습니다. stateful operation 의 failover 시 state 가 어떻게 변화했는지 기록한 changelog 를 모두 replay 해야하기 때문에 failover 시간이 오래 걸릴 수 있습니다. 또한 ksqlDB 가 HA 를 달성하는 방법은 처리 스트림의 복제본을 두어 changelog 를 내부 state 에 지속적으로 업데이트하는 것인데, 이는 복제본에서도 동일한 연산을 수행하는 것이기 때문에 리소스가 두 배로 소모될 수 있습니다. 자세한 내용은 Configuring ksqlDB for High Availability | Confluent Developer 에서 확인해보실 수 있습니다.
vs Spark Structured Streaming
Spark Structured Streaming 은 Spark SQL 엔진을 기반으로 구현된 스트리밍 처리 엔진으로, 사내에서 이미 사용 중인 사례가 있으며 UDF 나 Custom Sink 작성도 가능하고, Flink 보다 규모가 크고 잘 구축된 에코시스템을 갖추고 있다는 장점이 있습니다. 다만, Spark 는 마이크로 배치 단위로 동작하기 때문에 레코드 단위의 지연이 발생할 수 있고, 실시간 처리가 중요한 상황에서는 Flink 보다 불리할 수 있습니다. 하지만 이러한 단점보다는 아쉽게도 팀 내에서 Spark 에 대한 경험이 거의 없었다는 점 때문에 Custom Sink 작성이 필요한 상황에서 Spark 를 선뜻 선택하기가 어려웠습니다.
클러스터 환경 구축 및 쿼리 배포 방식
Flink SQL 쿼리를 제출해서 실제 Flink Job 을 수행시키려면 Flink Cluster 를 먼저 구축해주어야 하는데요, 지금부터 그 과정에 대해서 간단히 소개해보겠습니다.
로컬에서 간단하게 테스트하기
다음과 같은 과정으로 로컬에서 Flink Cluster 를 띄우고, Flink SQL 쿼리를 제출해 볼 수 있습니다.
- flink 공식 웹페이지에서 binary 를 다운로드 받습니다.
- 로컬에서
{FLINK_HOME}/bin/start-cluster.sh를 실행하여 로컬 클러스터를 띄웁니다. - 클러스터가 시작되었다는 문구를 확인한 후
{FLINK_HOME}/bin/sql-client.sh을 실행하면 Flink SQL CLI 가 실행됩니다. 테스트 삼아SELECT 1;을 입력해보면 쿼리가 제출되면서 1을 담은 Row 가 출력되는 것을 확인하실 수 있습니다. - 쿼리 제출 후 웹 브라우저로 http://localhost:8081 을 접속하면 Flink Web UI 를 확인하실 수 있으며, 제출한 쿼리가 job 으로 변환되어 실행되었음을 확인하실 수 있습니다.
여기까지 진행해 보셨을 때 Shell 에서 쿼리를 제출하는 방식이 불편하게 느껴지셨을 수 있는데요, 다행히도 2022 년 말에 Flink SQL Gateway 기능이 릴리즈되면서 HTTP 기반으로 쿼리를 제출하는 것이 가능해졌습니다.
운영 환경에서의 클러스터 아키텍쳐
사내의 대부분의 서비스들이 Kubernetes 위에서 동작하고 있기 때문에, Flink SQL Cluster 또한 Kubernetes 위에서 동작하도록 구성하였습니다. 참고로 아래 그림에서 파란색 네모는 pod 를, 보라색 원형은 sidecar container 를 나타냅니다.
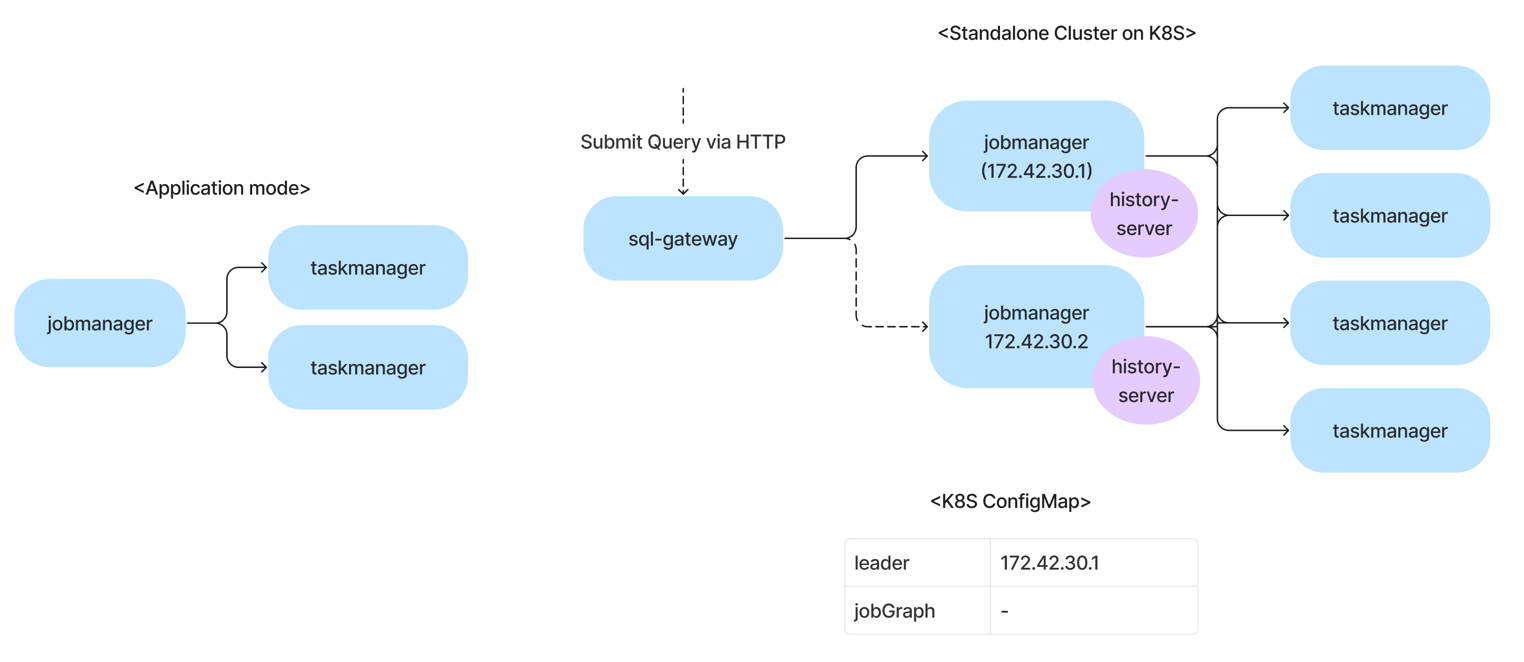
기존의 Flink App들은 모두 Application mode로 배포 및 운영되고 있었습니다.
이 모드는 각 애플리케이션마다 별도의 클러스터를 띄우는 방식으로 Kubernetes 상에서는 앱마다 JobManager Pod와 TaskManager Pod를 각각 띄워 동작시키게 되는데요,
사내에서는 여러 조직 또는 작업자들이 각자 Flink App을 만들어 개별적으로 관리하는 패턴이 대부분이었기 때문에 앱 간 독립성과 격리의 중요성, 작업별로 별도의 설정 및 종속성 관리 차원에서 Application mode 를 사용하는 것도 유리한 점이 있었습니다.
반면, Flink SQL 의 경우 이미 떠있는 Cluster 에 job 을 제출하는 방식으로 동작하므로 이러한 Cluster 를 구성하기 위해서는 JobManager 와 TaskManager 들을 Session mode 로 띄워야 하는데요,
저는 Flink 공식 가이드 중 Stand Alone Cluster on Kubernetes 가이드를 기반으로 클러스터를 구성하였습니다.
가이드 내용 중에서도 특히 HA 환경을 구성하기 위해 High-Availability with Standalone Kubernetes 항목의 설정들을 참고하였고, high-availability.storageDir 로는 자주 사용하는 인프라인 s3 를 이용하였습니다.
참고로 해당 가이드 외에도 Native Kubernetes 에서도 Session mode 로 앱을 띄우는 방법을 소개하고 있는데요, 해당 페이지의 방식은 제공되는 shell script 를 동작시켜 클러스터를 띄우는 방식이라 deployment 설정의 많은 부분을 직접 정의해서 배포하는 사내 인프라 환경에서 사용하기는 적합하지 않다고 생각했습니다.
아래는 클러스터 환경 구축을 위해 사용한 실제 config.yaml (구 flink-conf.yaml) 파일 내용 중 HA 및 S3 연동을 위해 설정한 부분들입니다.
# config.yaml 일부
high-availability.type: kubernetes
high-availability.storageDir: s3://{s3-path-for-flinksql-recovery}
kubernetes.cluster-id: {cluster-id}
kubernetes.namespace: {k8s-namespace}
# namespace 내의 service account 를 통해 Kubernetes cluster 에 접근할 수 있도록 권한을 부여하는 작업이 필요할 수 있습니다.
kubernetes.service-account: {k8s-service-account-for-flinksql}
그 외에 설정시 주의해야 할 점 중 하나로, HA 환경 설정시 JobManager pod 를 두 개 띄우게 되는데 이 때 서로의 주소가 달라야 리더 선출 로직 등이 정상적으로 동작하므로 JobManager 컨테이너 실행 인자를 다음과 같이 설정해 주었습니다.
args: ["start-foreground", "-D", "jobmanager.rpc.address=$(POD_IP)"]
이렇게 설정을 해두면 아키텍쳐 그림에 표시된 것처럼 Kubernetes ConfigMap 에 현재 리더로 선출된 JobManager pod 의 정보 및 현재 실행중인 Job ID 등이 저장되어 HA 에 활용됩니다.
GitOps 방식을 이용한 쿼리 배포
보통 쿼리를 작성하고 실행할 때 이를 위한 web UI 또는 전용 툴이 제공되는 경우가 많은데요, 현재 Flink 에서 직접 제공하고 있는 툴은 아직 없습니다.
비슷한 web UI 연동 사례로 Hue 가 있어 PoC 를 진행해 보았으나, 당시 Flink SQL Gateway 버전 호환성 이슈로 추가 개발이 필요했고, 개발 환경 구성에 시간이 너무 많이 소요되어 다른 방법을 모색했습니다.
사내에서는 GitOps 패턴을 많이 사용하고 있어서 쿼리를 배포하거나 Job 을 중단시키는 GitHub Actions 를 구현해 사용하고 있는데요, 간단하게는 다음과 같은 과정으로 동작합니다.
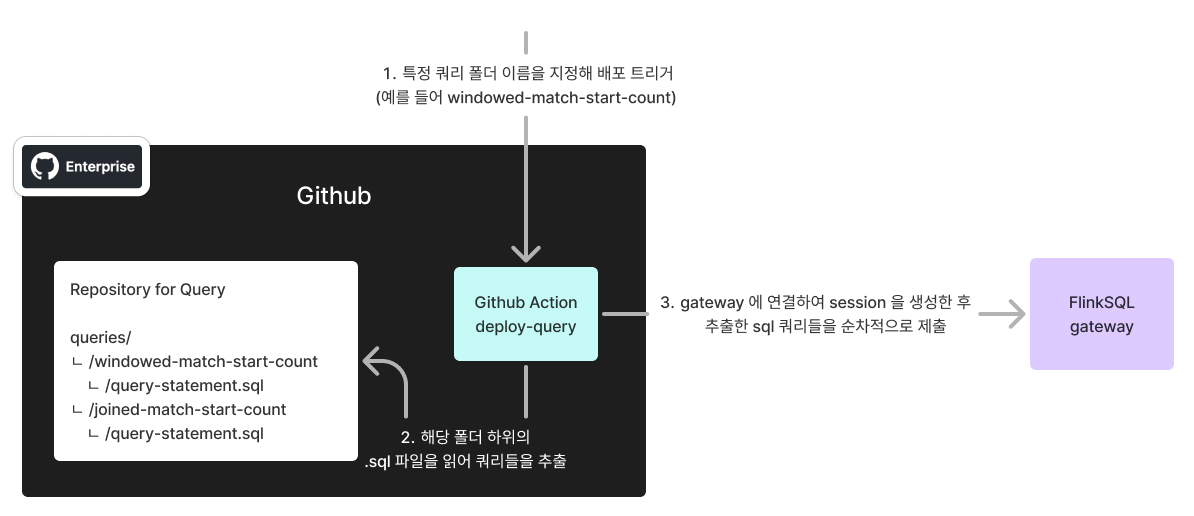
해당 구조를 위해 Repository 내에 각 job 별로 폴더를 생성하고 실행할 쿼리들을 SQL 파일로 모아두었으며, Github Actions 구현 시 폴더 이름을 받아 쿼리를 추출할 SQL 파일을 특정할 수 있도록 했습니다.
또한 위 방식에서 GitHub Actions 는 단순히 Flink SQL Gateway 의 API 만을 호출하므로 구현이 간단하고 테스트가 쉬운 python 으로 작성하였습니다.
주요 operation 사례 및 트러블슈팅 경험
Flink SQL 을 도입하고 운영하면서 겪은 주요 operation 사례 및 트러블슈팅 경험을 공유하려고 합니다.
JobManager 또는 TaskManager 가 Fail 하는 경우
JobManager 의 경우 Fail 했던 경험은 없었지만, Flink 의 HA 설정을 통해 JobManager 가 Fail 하는 경우에도 다른 JobManager 가 리더로 선출되어 작업을 계속할 수 있습니다. TaskManager 의 경우는 가끔씩 fail 하는 경우가 있었는데, 대부분 Kubernetes QoS 정책으로 인해 Pod 가 재시작하는 케이스였습니다. 일부 TaskManager 가 Fail 한 경우에도 다른 TaskManager 로 작업이 재분배되어 작업이 계속되는 것을 확인할 수 있었습니다.
쿼리가 Fail 하는 경우
쿼리가 비정상적으로 실패하는 경우는 대부분 비정상 데이터 인입 시나 컴퓨팅 자원 부족시에 발생하였습니다.
비정상 데이터 인입 관련해서는 JSON 포맷의 데이터를 읽어오는 경우가 많은데, 잘못된 JSON 포맷일 경우 json.ignore-parse-errors 옵션을 통해 에러가 발생하는 데이터를 무시하도록 설정할 수 있었습니다.
간혹 JSON_VALUE 와 같은 함수를 사용해 특정 path 의 데이터를 추출 할 때 값이 없거나 타입이 달라 에러가 발생할 수 있는데, 이런 경우에는 DEFAULT {VALUE} ON ERROR 와 같이 에러 발생 시 기본값을 설정해줄 수 있습니다.
컴퓨팅 자원 부족의 경우는 대부분 TaskManager 의 CPU 가 100% 가 넘어가거나, 메모리가 부족한 경우에 발생하였는데, 이 경우에는 TaskManager 의 리소스를 늘리거나, 쿼리의 parallelism 을 늘린 후 재배포하는 등의 방법으로 대응할 수 있었습니다.
클러스터 재시작시 일부 Job 이 Fail 하는 경우
클러스터 설정 변경이나 UDF 추가 등의 이유로 클러스터를 재시작시킬 때 현재 Kubernetes 의 Deployment 를 수정하여 Pod 가 다시 생성되도록 하는 방법을 사용하고 있는데요, 이때 클러스터 재시작 후 일부 Job 이 Fail 하는 경우가 있었는데, 이는 Job 의 timeout 이나 retry 설정이 적절하지 않아서 발생한 경우가 많았습니다. 이 경우 Job 이 너무 빨리 재시도를 종료하지 않고 클러스터 재시작 후 안정될 때 까지 재시도 할 수 있도록 timeout 이나 retry 설정을 수정해주었습니다.
쿼리의 조건을 하나 수정해서 다시 배포하고 싶은 경우
쿼리의 조건을 하나 수정해서 다시 배포할 때 savepoint 를 이용해서 state 를 복원할 수 있는 경우는 조건식의 값이 바뀌는 등의 아주 간단한 수정일 때만 가능합니다. 만약 window 조건이 수정되는 경우에는 state 가 변경되어 호환성 유지가 어려워서 savepoint 를 이용한 복원이 어려울 수 있으므로, state 를 유지할 필요가 있는데 요구사항이 자주 변경된다면 직접 앱을 작성하는 것이 더 나을 수 있습니다.
주요 모니터링 포인트
Flink 는 기본적으로 제공하는 metric 들이 많기 때문에 사내에 모니터링 인프라가 구축되어 있고, 적절한 Metric Reporter 를 이용해 지표를 수집할 수 있다면 모니터링 환경을 쉽게 구성할 수 있을 것입니다.
다양한 metric 중 알아두면 유용한 것들을 몇 가지 소개하자면,
먼저 일부 쿼리의 실패를 빠르게 감지하기 위해 numRunningJobs 을 확인하면 좋습니다. 해당 지표는 클러스터에서 현재 실행중인 job 의 개수를 나타내며, 값이 갑자기 감소한채로 유지되면 fail 한 job 이 있다고 판단할 수 있습니다.
또한 클러스터의 부하 수준을 확인하기 위해 taskmanager.cpu.load 나 taskmanager.memory.used 와 같은 지표를 확인하여 리소스 사용량을 파악할 수 있습니다.
busyTimeMsPerSecond 를 통해서도 TaskManager 가 얼마나 바쁜지 Job 별로 확인할 수 있으며 특히 Kafka 를 source 로 사용하는 경우에는 records-lag-max 와 같은 지표를 통해 데이터 지연 상태를 가장 빠르게 확인할 수 있습니다.
마치며
이번 글에서는 Flink SQL 을 도입한 이유와 클러스터 환경 구축 및 운영 경험을 간단히 소개해드렸습니다. 저희 팀에서는 Flink 에 대한 경험을 레버리지 하여 전보다 쉽고 빠르게 여러 가지 기능을 추가할 수 있었기에 생산성이나 운영 효율성 측면에서 만족스러운 결과를 얻었다고 생각합니다. 안정성 역시 뛰어나, 도입 이후 1년 정도 운영해 보았을 때 별다른 운영 작업 없이도 매우 안정적으로 동작하여 점차 확대 운영을 해 나가고 있습니다. 하지만 아직 쿼리 재배포, 클러스터 설정 변경 등 불편한 점들이 있어서, GitOps Controller 패턴 구현을 통한 쿼리 배포 환경 개선 등의 고도화 작업들을 진행할 계획입니다. 이번 글이 Flink SQL 기능에 관심 있으신 분들께 도움이 되었으면 좋겠습니다. 감사합니다.
Appendix
Kafka 로부터 이벤트를 받아 10초마다 지난 1분동안의 로그인 이벤트 수를 Kafka 로 발행하는 예제
- input format 은 json 이고, 예제 데이터는 다음과 같습니다.
{
"event_time": 1739656100463,
"event_type": "Login",
"data": {
"user_id": "12345678"
}
}
- 제출해야 하는 쿼리는 다음과 같습니다.
SET 'pipeline.name' = 'windowed_login_count';
SET 'parallelism.default' = '2';
SET 'table.exec.state.ttl' = '120000';
CREATE TABLE login_event (
data STRING,
event_time BIGINT,
row_time AS TO_TIMESTAMP(FROM_UNIXTIME(event_time / 1000, 'yyyy-MM-dd HH:mm:ss')),
-- 현재까지 관측된 이벤트 타임 기준 최대 5초까지 늦게 도착하는 이벤트를 정상적으로 처리하겠다는 의미
WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'login-event-topic',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'consumer-group-id',
'format' = 'json',
'json.ignore-parse-errors' = 'true'
);
CREATE TABLE windowed_login_count (
-- 해당 윈도우 시작 시간
window_start TIMESTAMP(3),
record_count BIGINT,
-- 이벤트 시간이 아닌 현재 레코드 발행시 처리시간을 값으로 갖는 필드
proc_time AS PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'windowed-login-count-topic',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json'
);
INSERT INTO windowed_login_count
SELECT
-- 10초 간격으로 생성되는 1분동안의 hopping window 의 시작 시간
HOP_START(row_time, INTERVAL '10' SECOND, INTERVAL '1' MINUTE) AS window_start,
-- hopping window 내의 총 record 수
COUNT(*) AS record_count
FROM login_event
-- 10초 간격으로 생성되는 1분동안의 hopping window 를 기준으로 group by 집계
GROUP BY HOP(row_time, INTERVAL '10' SECOND, INTERVAL '1' MINUTE);