Spring WebClient에서 새어나가는 메모리 잡기
평화롭던 어느 새벽, 저희 팀에서 관리하고 있는 Spring 서버의 응답이 점점 느려지고 있다는 제보가 들어왔습니다. 타임아웃이 발생하는 빈도가 점점 늘어나더니, 몇 시간 후에는 대부분의 요청에 대해 타임아웃이 발생하고 있었습니다. 서버가 대부분의 요청에 대해 타임아웃 응답이 발생하는 것은 장애 상황이라고 볼 수 있을 것입니다.
다행히도 해당 애플리케이션은 DevOps 팀이 관리하고 있는 Kubernetes 위에서 동작하고 있었고, 주기적으로 애플리케이션의 상태가 정상인지 확인해 주는 Liveness Probe 기능이 적용되어 있었습니다. 서버가 Liveness Probe 요청에 대해 응답하지 않았기에, 문제가 되었던 파드는 개발자의 개입 없이 자동으로 재시작 되었습니다.
그렇지만 Kubernetes의 이러한 자동 재시작 기능은 애플리케이션의 근본 원인을 해결해주지 않습니다. 장애가 발생한 이후에 근본적인 문제의 원인을 찾아 해결하려고 했고, 그 과정을 설명하고자 합니다.
지표 확인
하이퍼커넥트에는 애플리케이션의 지표를 모니터링하기 위한 Prometheus와 Grafana가 구축되어 있습니다. 저희 팀에서는 Spring Boot Actuator를 이용하여 애플리케이션 지표들을 Prometheus로 전달하고 있기 때문에 Grafana로 접속하면 지표를 확인할 수 있습니다.
장애 발생 시점에 모니터링 지표 상의 특이점을 확인하기 위해 Grafana에 접속하여 CPU, Istio 및 JVM 지표를 확인했습니다.
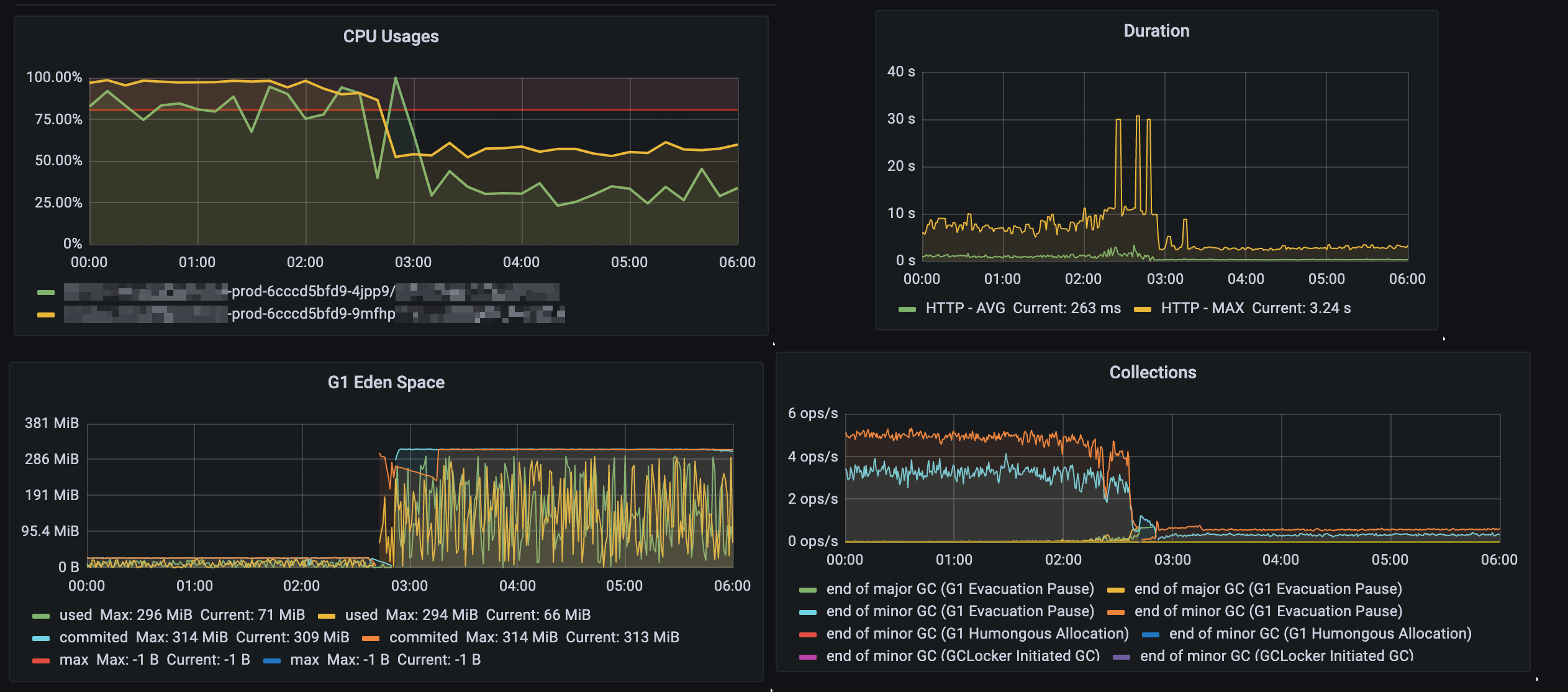
- 새로운 오브젝트를 할당하는 데 사용하는 공간인 G1 Eden Space 관련 지표가 매우 낮아졌습니다.
- 새로운 오브젝트를 할당하기 위한 메모리를 확보하기 위해 GC가 여러 번 동작했습니다.
- GC가 여러 번 동작하는 동안, CPU 사용량이 높아졌습니다.
사용자의 요청을 처리하기 위해서는 오브젝트를 할당하기 위한 일정 수준의 메모리가 필요합니다. 사용자의 요청을 처리하기 위한 메모리가 확보되지 않아 JVM은 GC를 통해 메모리를 확보하기 위한 시도를 하였지만, 메모리가 여전히 확보되지 않아 사용자의 요청을 처리할 수 없었을 것이라고 생각하였습니다.
GC는 더 이상 참조되지 않는 가비지 오브젝트를 메모리에서 삭제해 사용 가능한 메모리를 확보합니다. GC가 진행되었음에도 메모리가 확보되지 않았다는 사실은, 메모리 누수가 존재할 가능성을 시사합니다. 메모리 누수를 확인하기 위해서는 힙 덤프를 확인한 후 메모리에 지나치게 많이 존재하는 오브젝트를 확인할 수 있습니다.
힙 덤프 확인
힙 덤프를 확인하기 위해서는 jmap 명령을 이용하여 힙 덤프를 만든 후, 로컬로 힙 덤프를 가져와야 합니다.
힙 덤프를 만드는 명령을 소개하기 위해 사내 DevOps 운영 가이드의 일부를 가져왔습니다.
서비스 장애가 발생하지 않도록 조심해서 오퍼레이션을 진행하는 것이 중요합니다.
# 주의사항: traffic이 많거나 heap이 큰 경우 아래 jmap 명령을 바로 수행하면 서비스 장애가 발생합니다.
# 0. pod 하나를 제외했을 때 다른 pod이 traffic을 모두 감당할 수 있는지 확인합니다. 아니라면 kubectl scale 명령을 통해 replica count를 1 늘리고 작업하세요.
# 1. "kubectl label po -n <ns> <pod-name> app-" 을 수행하여 service에서 pod을 제외시킵니다.
# 2. 아래 jmap 명령을 수행합니다.
# 3. "kubectl label po -n <ns> <pod-name> app=<app-name>" 을 수행하여 service에 pod을 다시 포함시킵니다.
(local) $ kubectl exec -it -n <ns> -c <container-name> <pod-name> -- /bin/bash # 또는 sh
(pod) $ # file 경로나 pid는 다를 수 있으나, 일반적으로 /opt/hpcnt 내의 directory를 사용하면 되고, pid는 1입니다.
(pod) $ jmap -dump:live,format=b,file=/opt/hpcnt/dump.bin 1
(pod) $ Ctrl+D
(local) $ kubectl cp -n <ns> -c <container-name> <pod-name>:/opt/hpcnt/dump.bin dump.bin
# 비고: 파일 사이즈가 너무 커서 kubectl cp가 실패할 경우 devspace 와 같은 툴을 사용합니다. (예: devspace sync --pod=<pod-name> --container=<container-name> --container-path /opt/hpcnt --download-only)
시작한지 어느 정도 시간이 지나 메모리 누수가 두드러지는 파드로 접속하여 힙 덤프를 만들어 받아왔습니다. IntelliJ IDEA에 .hprof 덤프 파일을 끌어 놓으면 아래와 같은 Profiler 창이 나오게 됩니다.
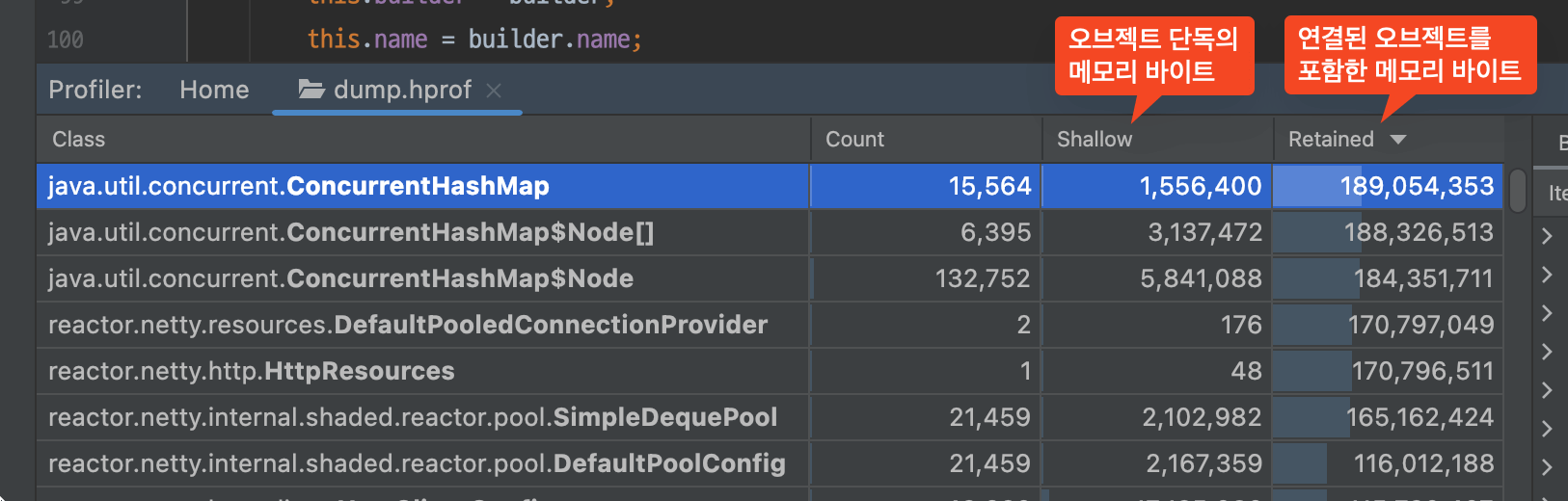
- Shallow 탭의 값은 오브젝트 자체를 저장하기 위해 할당된 메모리의 바이트 수입니다. 이 오브젝트에서 참조하는 다른 오브젝트의 크기는 포함되지 않습니다.
- Retained 탭의 값은 오브젝트 자체뿐 아니라 이 오브젝트에서만 참조하는 다른 오브젝트의 바이트 수를 합친 것입니다. 즉, 이 오브젝트를 GC 했을 때 회수할 수 있는 메모리의 바이트 수입니다.
위의 스크린샷을 예시로 설명해 보겠습니다. ConcurrentHashMap 오브젝트 자체는 많은 메모리가 필요하지 않기 때문에 Shallow 값이 1.4MB입니다. 그렇지만 이 오브젝트가 가지고 있는 수많은 키 및 값 오브젝트를 포함한 Retained 값은 180MB입니다. 힙 메모리를 분석할 때는 보통 Retained Heap을 기준으로 파악하면 문제의 오브젝트를 쉽게 찾아낼 수 있습니다.
이제 ConcurrentHashMap 오브젝트를 상세히 살펴보기 위해 더블 클릭합니다.
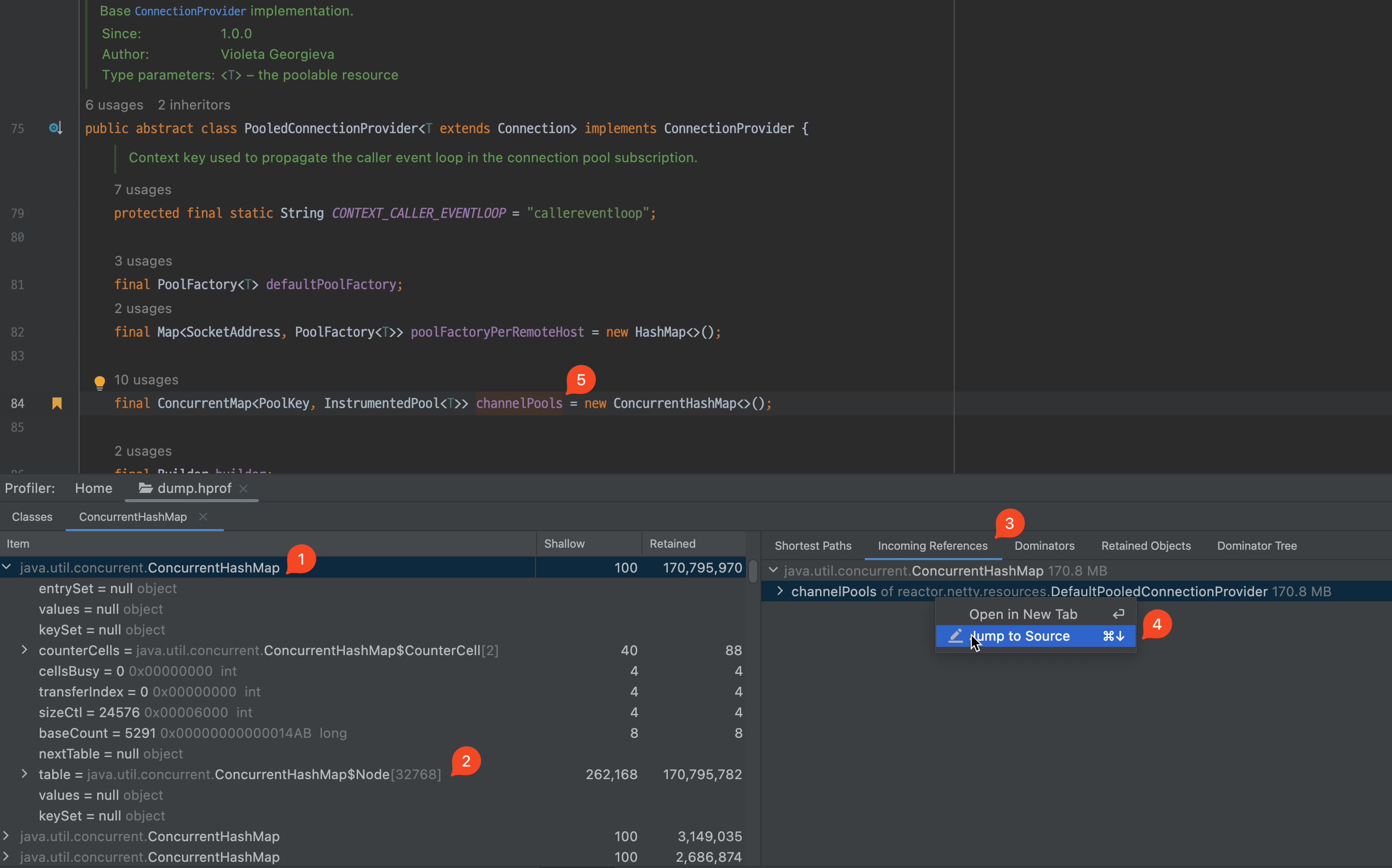
- 처음으로 나온 오브젝트를 펼쳐서 확인해 봅니다.
- 위에서 확인한 대로 해시 맵에서 키 및 값을 저장하는
table멤버 변수의 Retained 값이 큰 것을 확인할 수 있습니다. - 이 오브젝트를 어느 오브젝트가 참조하는지 확인하기 위해, Incoming References 탭을 확인합니다.
- 의심스러운
channelPools를 우클릭하고 Jump to Source를 클릭합니다. - 의심스러운 오브젝트는
ConcurrentHashMap<PoolKey, InstrumentedPool<T>>타입의 오브젝트임을 확인할 수 있습니다.
힙 덤프 분석을 통해 의심스러운 해시 맵 오브젝트를 찾았습니다. 이제 이 해시 맵을 분석할 차례입니다.
channelPools 분석
가장 먼저, PoolKey 클래스의 선언을 확인해 보았습니다.
static final class PoolKey {
final String fqdn;
final SocketAddress holder;
final int pipelineKey;
}
이 클래스의 선언만 봐서는 어떤 데이터가 들어가 있는지 파악이 쉽지 않습니다. MAT(Eclipse Memory Analyzer)의 OQL(Object Query Language) 기능을 이용하면, SQL과 유사한 방법으로 메모리 덤프에 저장된 메모리의 값을 쿼리할 수 있습니다.
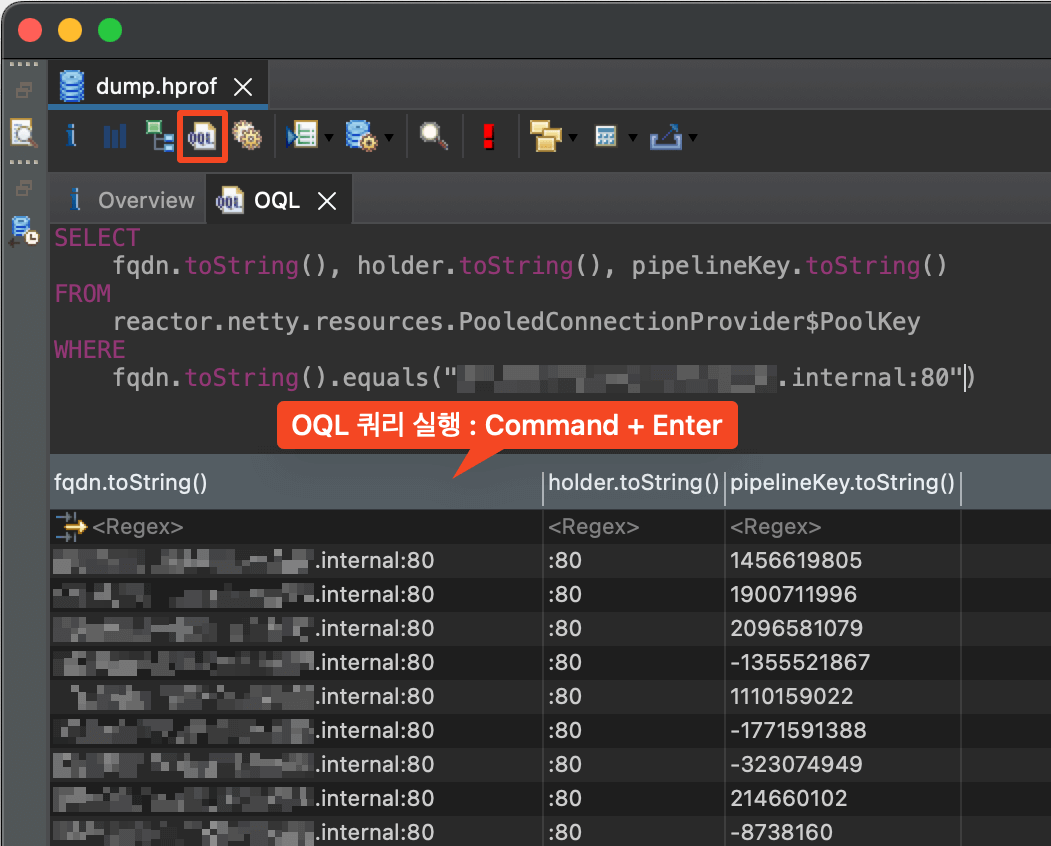
fqdn 필드에는 WebClient API에 입력한 다른 마이크로서비스의 API 주소가 포함되어 있었습니다.
따라서 channelPools 오브젝트는 WebClient와 연관되어 있다는 사실을 유추할 수 있었습니다.
한 가지 매우 이상한 점은, 동일한 서버에 대해서 너무 많은 키가 메모리에 존재한다는 점이었습니다.
한 서버에 대응하는 키가 수만 개 이상 생성되어 있었습니다.
또한 같은 서버에 대해 pipelineKey 멤버 변수에 다른 값이 들어가 있는 것을 확인할 수 있습니다.
처음에는 왜 이 많은 Key 오브젝트들이 GC 되지 않았을까 한참 동안 고민했습니다. WebClient API를 잘못 사용하고 있을 가능성, WebClient 자체에 버그가 있을 가능성, G1 GC의 옵션을 잘못 주었을 가능성 등등, 어떤 이유로든 잘못될 수 있는 경우의 수를 모두 생각해 보았지만 모두 허탕이었습니다. 인터넷에서는 WebClient 메모리 누수에 대한 속 시원한 답변을 찾아볼 수 없었습니다.
이렇게 많은 오브젝트가 메모리에 생성된 원인은, 재사용을 위해 만들어 둔 오브젝트들을 재사용하지 못하고 매번 새로 만들고 저장하기 때문일 수도 있겠다는 생각을 가지고 문제에 다시 접근해 보았습니다.
해당 channelPools 멤버 변수에 새로운 값을 넣는 소스 코드는 다음과 같습니다.
MapUtils.computeIfAbsent 함수는 해시 맵에 키가 없을 때 람다 함수의 반환 값을 해시 맵의 키로 저장하는 함수입니다.
holder 키가 channelPools 해시 맵에 존재하지 않으면, 디버그 로그를 출력하고 새로운 커넥션 풀을 만듭니다.
SocketAddress remoteAddress = Objects.requireNonNull(remote.get(), "Remote Address supplier returned null");
PoolKey holder = new PoolKey(remoteAddress, config.channelHash());
PoolFactory<T> poolFactory = poolFactory(remoteAddress);
InstrumentedPool<T> pool = MapUtils.computeIfAbsent(channelPools, holder, poolKey -> {
if (log.isDebugEnabled()) {
log.debug("Creating a new [{}] client pool [{}] for [{}]", name, poolFactory, remoteAddress);
}
// ...
return newPool;
});
위의 디버그 로그를 활성화하기 위해 다음의 설정을 추가해 보았습니다.
logging:
level:
reactor.netty.resources.PooledConnectionProvider: DEBUG
로컬에서는 메모리 누수가 재현되지 않았습니다.
같은 서버의 연결에 대해서는 config.channelHash() 값이 모두 같은 값이 반환되었으며,
서버당 한 번만 Creating a new [http] client pool ... 으로 시작하는 디버그 로그가 출력되었습니다.
원격 디버깅
메모리 누수가 로컬에서 재현되지 않았기 때문에, 서버의 자바 프로세스를 디버깅하는 원격 디버깅 기능을 활용해 보기로 하였습니다. 디버깅 과정에서 서버가 멈추기 때문에, 프로덕션 서버에서는 원격 디버깅을 사용하면 안 됩니다! 개발 환경의 서버에 배포하여 디버깅을 진행했습니다.
- 서버 프로세스에 디버깅 옵션을 추가하기 위해,
-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005자바 옵션을 추가하여 배포합니다. 이 자바 옵션은 JDK 버전에 따라 조금씩 다릅니다. - 로컬의 IntelliJ IDEA와 연결하기 위해,
kubectl port-forward <pod-name> 5005:5005명령을 이용하여 포트 포워딩을 설정합니다. - Edit Configuration > + 버튼 > Remote JVM Debug 를 추가합니다.
- 원격 디버깅을 시작합니다.
힙 덤프에서 서버 연결마다 다른 값이 들어가 있었던 pipelineKey 변수를 계산하는 config.channelHash() 함수의 소스 코드입니다.
public int channelHash() {
return Objects.hash(attrs, bindAddress != null ? bindAddress.get() : 0, channelGroup, doOnChannelInit,
loggingHandler, loopResources, metricsRecorder, observer /* 문제의 그 변수 */, options, preferNative);
}
원격 디버깅을 시작한 상태로 위의 함수에 중단점을 걸고 멤버 변수들을 살펴보았습니다.
곧, observer 멤버 변수에 매우 의심스러운 값이 인입되어 있는 것을 확인할 수 있었습니다.
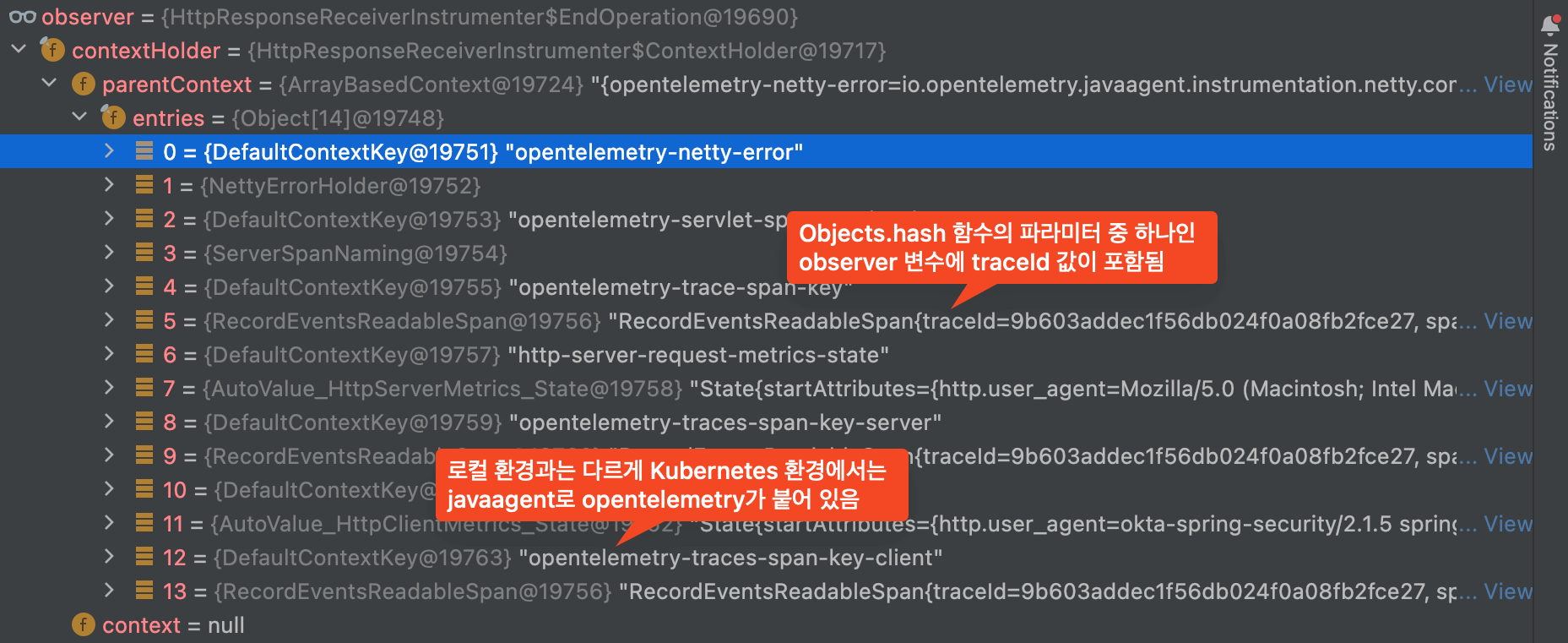
로컬 환경에서는 observer 멤버 변수에 항상 일정한 값이 들어가 있었지만,
원격 환경에서는 매 요청마다 값이 달라지는 opentelemetry-trace-span-key 가 포함되어 있었습니다.
이 때문에 Objects.hash(..., observer, ...)의 반환 값이 매 요청마다 달라졌습니다.
이로 인해 pipelineKey 값이 달라져서 기존에 생성된 클라이언트 풀을 재사용하지 못하고 매번 새로운 클라이언트를 생성하던 것이 메모리 누수의 원인이었습니다.
하이퍼커넥트의 마이크로서비스들은 Docker Hub의 adoptopenjdk/openjdk11 등의 이미지를 바로 사용하지 않습니다.
대신, DevOps 팀에서 제공해 주는 언어 별 베이스 이미지를 사용하고 있습니다.
이 베이스 이미지에는 여러 에이전트의 jar 파일이 포함되어 있는데,
저희 팀의 애플리케이션은 APM 추적을 위한 OpenTelemetry라는 에이전트를 사용하고 있다는 사실을 떠올렸습니다.
(OpenTelemetry 에이전트는 지표와 분산 트레이스, 로그를 수집하는 CNCF 프로젝트입니다. New Relic이나 DataDog의 에이전트와 유사한 역할을 한다고 보시면 됩니다.)
이 때문에 Docker를 이용하지 않는 로컬 개발 환경에서는 재현이 되지 않았던 것이었습니다!
문제 해결
곧바로 opentelemetry webclient memory leak 키워드로 검색했고, 관련된 이슈 (Issue #4862)를 확인할 수 있었습니다.

이슈를 수정하는 코드 (PR #4867) 을 확인해 보면, 위에서 문제가 되었던 observer 관련 코드가 doOnResponseError, doAfterResponseSuccess 코드로 변경된 것을 확인할 수 있습니다.
위 변경 사항은 OpenTelemetry 1.9.2 버전에 포함되었습니다. 기존에는 이슈가 존재하는 1.9.1 버전을 사용하고 있었기 때문에 버그가 트리거 된 것이었습니다. OpenTelemetry 버전을 최신 버전인 1.16.0 버전으로 업그레이드한 이후, 커넥션 풀이 서버당 한 개만 만들어지고 메모리 누수가 발생하지 않는 것을 디버그 로그를 통해 확인하였습니다.
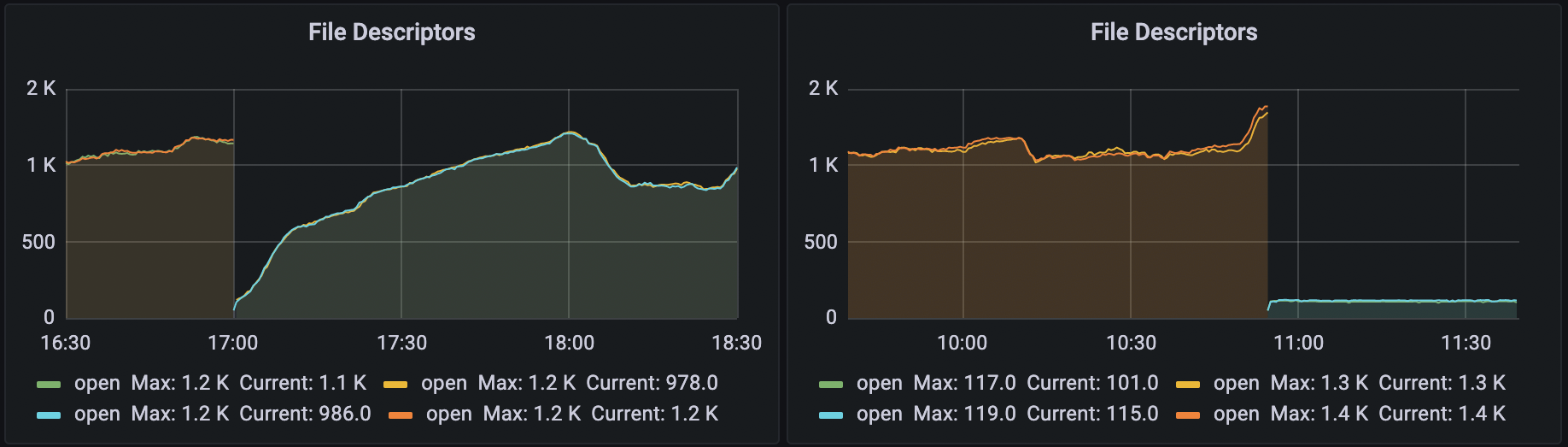
파일 디스크립터 지표에도 변화가 있었습니다. 왼쪽은 이전 버전의 배포한 후, 오른쪽은 수정 버전을 배포한 후의 파일 디스크립터 지표입니다. 서버와의 커넥션 풀을 재사용하지 않고 매번 새로 만들었기 때문에 이전 버전에서는 파일 디스크립터 개수가 요동쳤지만, 수정 사항을 배포한 후에는 한 번 만들어 둔 커넥션 풀을 재사용하기 때문에 파일 디스크립터 개수가 100 초반대로 일정한 것을 확인할 수 있었습니다.
요약
오래된 버전의 OpenTelemetry 에이전트의 동작으로 인해 WebClient의 커넥션 풀 및 메모리 누수가 발생했습니다. OpenTelemetry 에이전트의 버전을 최신 버전으로 업그레이드하여 문제를 해결하였습니다.
Reference
Read more
-
Pull Requests를 Merge 하면 자동으로 배포하기
Pull Requests를 Merge하면 자동으로 배포가 되도록 시스템을 구성하기까지의 고민을 공유합니다. -
PostgreSQL의 슬로우 쿼리에 대처하기
데이터베이스에 적절한 인덱스를 추가하여 슬로우 쿼리를 빠르게 만들고 리소스 사용을 줄인 사례를 공유합니다.