PostgreSQL의 슬로우 쿼리에 대처하기
평화롭던 어느 날, 모니터링 시스템에서 데이터베이스의 CPU 사용량이 지속해서 높다는 경고를 보내왔습니다. 처음에는 일시적인 문제이겠거니 했지만, 날이 가면 갈수록 CPU의 사용량은 높아졌고 이제는 90%가 넘어져 더는 그냥 넘어갈 수가 없게 되었습니다.
어떤 쿼리가 문제인지 확인하기
예전에는 DB의 부하를 줄이기 위해 WAS 개발자가 작성한 SQL 쿼리들을 DBA들이 전부 검수했다고 합니다.
요즈음의 애플리케이션은 나날이 복잡해지고 있습니다. 또 그에 맞추어 이제는 SQL을 직접 작성하지 않고도 DB에 접근할 수 있는 ORM 기술이 발전하고 있습니다. 이제는 ORM이 생성하는 쿼리를 DBA와 같은 전문 인력이 사전에 전체 검수하기는 사실상 어려워졌습니다. 클라우드의 시대가 되어 성능 문제가 생기면 돈으로 급한 불을 끌 수 있게 되었습니다. WAS 개발자는 ORM이 생성하는 SQL을 생각하지 않아도 애플리케이션을 개발하는 데 문제가 없는 시대가 되었습니다.
ORM이 생성해 주는 대부분의 쿼리는 프로덕션에서도 문제없이 작동합니다. 하지만 그중 일부 쿼리는 간혹 데이터가 많은 프로덕션 환경에서 성능 이슈를 일으킵니다. 그런 경우, 문제가 되는 쿼리를 찾아서 그 쿼리에 대해서만 대응하면 됩니다. 가성비가 나오지 않기 때문에 ORM이 만드는 모든 SQL 쿼리를 최적화할 필요는 없습니다.
APM에서 문제가 되는 쿼리 찾기
세상에는 좋은 SaaS들이 너무 많습니다. APM과 같은 개발자의 시간을 줄여주는 여러 SaaS들을 적극적으로 사용합시다.
AWS Performance Insight
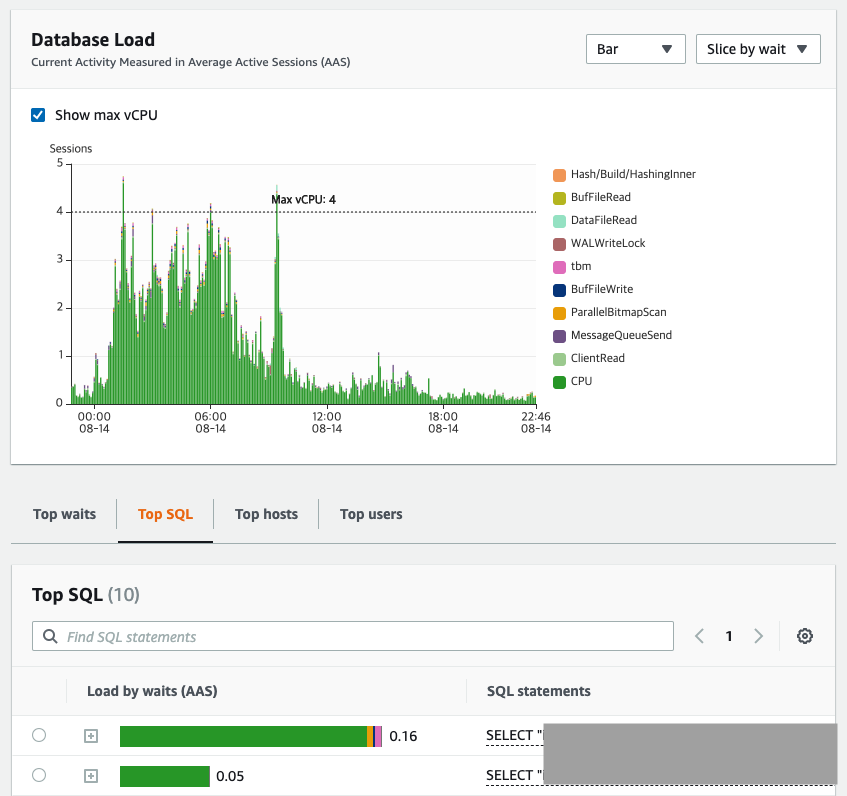
AWS에는 RDS를 모니터링해주는 Performance Insight라는 기능이 있습니다. 여러 가지 기능이 있지만, 슬로우 쿼리를 찾을 때 매우 요긴하게 사용할 수 있습니다. SQL 쿼리가 RDS 인스턴스에 어느 정도의 영향을 미치는지를 보기에 좋습니다.
Datadog
애플리케이션 레벨에서 가시성을 더 쉽게 파악하기 위해, Datadog이라는 APM 모니터링 솔루션을 함께 사용하고 있습니다. 이를 이용하면 Query 별 TPS와 지연시간 등을 함께 보여줍니다. 이를 이용하면, 어떤 SQL 쿼리가 얼마나 많이 사용되고 있으며, 얼마나 느린지를 파악하는 데 도움이 됩니다.

- 1, 2번째 쿼리는 p99 레이턴시가 가장 높지만, 요청 수가 많지 않고 p50 레이턴시가 높지 않아 최적화 대상이 아니라고 판단할 수 있습니다.
- 3, 4, 5번째 쿼리는 p99 레이턴시가 5~6초이며, p50 레이턴시도 역시 1초 정도입니다. 요청 수도 상당히 많기 때문에 최적화가 필요하다고 판단할 수 있습니다.
쿼리의 실행 계획을 알려주는 Explain
문제가 되는 쿼리를 확인했으니 다음으로 확인해 볼 만한 것은 실행 계획을 확인해 보는 것입니다. 실행 계획은 데이터베이스 옵티마이저가 어떻게 쿼리를 수행할 것인지를 세우는 계획입니다. 이를 확인하려면 Select 앞에 Explain을 붙여 주면 됩니다.
실행 계획을 확인해 본 결과, 수백만 열이 있는 테이블을 대상으로 테이블 전체를 읽는 Seq Scan이 한 쿼리에 두 번이나 사용되고 있었습니다. OLTP 서비스의 쿼리에서 테이블 풀 스캔은 응답 속도를 떨어뜨리고 DB의 CPU, DISK 등의 리소스를 상당히 많이 사용하기 때문에 가급적 피하는 것이 좋습니다. 적절한 인덱스를 생성하여 쿼리 성능을 높이는 것으로 개선의 가닥을 잡았습니다.
PostgreSQL에서 지원하는 Join 알고리즘
PostgreSQL은 다음과 같은 세 가지의 Join 알고리즘을 지원합니다:
- Nested Join: Join 전 Where 조건을 적용한 후의 테이블에서, 두 개의 Join 대상 테이블 중 하나 혹은 두 테이블의 행이 거의 없는 경우 사용합니다. Join 조건이
=이 아닌 경우 이 알고리즘이 사용됩니다. - Hash Join: Join 전 Where 조건을 적용한 후의 테이블에서, Join 조건이
=이며 두 개의 Join 대상 테이블이 모두 크고 해시 테이블의 크기가work_mem에 맞는 경우 사용합니다. - Merge Join: Join 전 Where 조건을 적용한 후의 테이블에서, Join 조건이
=이며 두 개의 Join 대상 테이블이 모두 크지만, Join으로 사용된 식에 인덱스가 있는 등 효율적으로 정렬할 수 있는 경우 사용합니다.
옵티마이저는 대략적인 열 수, 테이블의 통계치 등의 데이터를 활용하여 여러 플랜의 Cost를 계산한 후 가장 적은 Cost가 드는 플랜을 선택하여 사용합니다. OLTP 서비스의 쿼리는 참조하는 열 수가 배치 쿼리에 비해 비교적 적기 때문에, 일반적으로 Nested Join을 사용합니다. 옵티마이저가 열 수를 잘못 예측하는 경우, 올바르지 않은 알고리즘을 선택할 수 있습니다. 예를 들면 예측 열 수는 너무 큰데 실제 열 수는 적은 경우, 실제로는 Nested Join이 가장 빠르지만 옵티마이저는 Hash Join이나 Merge Join을 선택할 수도 있습니다. 반대로 예측 열 수가 작은데 실제 열 수는 엄청 큰 경우, 실제로는 Hash Join이나 Merge Join이 가장 빠르지만 옵티마이저는 Nested Join을 선택할 수도 있습니다. 두 경우 모두 시스템에 부하가 커져 장애로 이어질 수 있습니다.
인덱스는 최소 개수로 유지
테이블 풀 스캔을 하는 쿼리를 최적화할 때, 일반적인 해결책은 인덱스를 거는 것입니다. 그렇다고 모든 컬럼에 인덱스를 거는 건 좋지 않고, 전략적으로 거는 것이 좋습니다.
인덱스를 걸면 Select를 제외한 Insert, Update, Delete를 진행할 때마다 인덱스도 함께 갱신해야 합니다. 불필요하게 인덱스가 많으면 해당 쿼리의 지연 시간이 늘어나며, 옵티마이저가 잘못된 인덱스를 선택해서 성능이 떨어지기도 합니다. 그래서 인덱스의 개수는 최소한으로 유지하는 것이 좋습니다.
카디널리티가 높은 컬럼에 인덱스 추가
중복도가 낮으면 카디널리티가 높고, 중복도가 높으면 카디널리티가 낮다고 합니다. 예를 들면 성별 데이터는 유니크한 개수가 얼마 되지 않아 카디널리티가 낮고, 주민번호 데이터는 유니크한 개수가 많아 카디널리티가 높다고 할 수 있습니다. 인덱스를 통한 Select 성능 향상은 조회 대상 데이터의 양을 줄이는 것이 목적이므로, 일반적으로 카디널리티가 높은 컬럼에 인덱스를 걸기를 권장하고 있습니다.
사례: 카디널리티가 낮은 쿼리 최적화하기
아래는 문제가 되는 SQL입니다. 전형적인 Top-N 쿼리에 Join을 얹은 모양을 하고 있습니다. 모든 테이블 이름과 필드 이름은 수정되었습니다.
select *
from sub_task
inner join main_task on sub_task.main_task_id = main_task.id
where main_task.main_task_type = ?
and sub_task.sub_task_type = ?
and sub_task.current_progress < sub_task.total_progress
order by
sub_task.first_order_by desc,
sub_task.second_order_by
limit ?
카디널리티가 낮지만, 적당히 비대칭적인 컬럼
바로 위에서 카디널리티가 높은 것을 인덱스로 삼아야 한다고 했습니다. 그런데 위의 Where 절에 나온 컬럼들은 모두 중복되는 데이터가 아주 많은 컬럼들이었습니다. 하지만 인덱스를 사용할 만한 가치는 있었는데요, 데이터들이 적당히 비대칭적으로 분포하고 있고 그중 많은 쪽과 적은 쪽을 둘 다 쿼리하는 경우가 있었기 때문입니다.
예를 들어, 컬럼의 90%가 TYPE_A이고 10%만이 TYPE_B인 테이블이 있습니다.
인덱스를 걸지 않으면 TYPE_A를 검색하나 TYPE_B를 검색하나 모두 Full Table Scan을 할 것입니다.
인덱스를 걸어주면, TYPE_B를 검색할 때 인덱스를 타면 10%만 검색하면 되기 때문에 인덱스를 탑니다.
반면 대다수를 차지하는 TYPE_A를 검색할 때에는, 인덱스를 타는 것보다는 Full Table Scan이 효율적이기 때문에 인덱스를 타지 않습니다.
TYPE_A와 TYPE_B를 모두 검색하는 일이 잦다면 이 컬럼에도 인덱스를 거는 것이 좋습니다.
sub_task_type 컬럼은 카디널리티가 낮지만, 적당히 비대칭적인 데이터 분포를 가지고 있었습니다.
이때 TYPE_B를 쿼리하는 경우가 자주 있어서, 인덱스를 추가해 주었습니다.
create index sub_task_type_idx
on sub_task (sub_task_type);
테이블의 일부만 주로 검색하는 경우, 부분 인덱스를 활용
테이블이 아주 크고, 대부분의 쿼리가 일부분의 열만 조회한다면 인덱스를 일부분만 만들어 주는 것이 좋습니다.
sub_task.current_progress < sub_task.total_progress 표현식은 True 혹은 False로 나오지만, 99% 이상은 False이고 단 1% 미만이 True입니다.
WAS에서 해당 조건식이 True인 경우에만 주로 쿼리하고 있어서, False인 부분에는 굳이 인덱스를 만들어 줄 필요가 없었습니다.
PostgreSQL에는 특정 조건을 만족하는 경우에만 인덱스를 걸어 주는, 부분 인덱스라는 기능이 있습니다.
문제의 쿼리를 살펴보면 ORDER BY first_order_by DESC, second_order_by LIMIT 100 인, 전형적인 Top-N 쿼리입니다.
Order By로 정렬을 하기 위해서는 전체 Row를 계산하는 작업이 필요합니다.
그런데, Order By 조건대로 인덱스를 걸어 두면 정렬할 필요가 없어집니다.
만든 인덱스를 이용해서 데이터를 가져올 때는 이미 정렬이 되어 있기 때문입니다.
또한 전체 데이터를 가져올 필요가 없고 최초로 발견된 것 N개만 찾아 반환하면 되기 때문에 빠르게 결과를 낼 수 있습니다.
실제 실험 결과, LIMIT이 있는 것과 없는 것의 실행 계획이 달랐고, LIMIT이 있는 것이 없는 것보다 성능이 월등하게 빨랐습니다.
프로덕션 데이터베이스를 복제해 인덱스를 거는 순서에 따라 최적의 시간이 나오는지 테스트를 진행해 보았습니다. 그 결과, 인덱스를 어떻게 걸어주느냐에 따라 큰 차이를 보였습니다.
- 인덱스를 걸지 않았을 때, 447ms
- Where 절의 컬럼들로만 부분 복합 인덱스를 걸었을 때, 233ms (1.9배 성능 향상)
- Order By 절의 컬럼들로만 쿼리와 다른 정렬 조건으로 (
first_order_by **ASC**, second_order_by ASC) 부분 복합 인덱스를 걸었을 때, 251ms (1.7배 성능 향상) → Order By 조건은 컬럼 순서뿐만 아니라 ASC, DESC 여부에도 영향을 끼침 - Order By 절의 컬럼들로만 쿼리와 동일한 정렬 조건으로 (
first_order_by **DESC**, second_order_by ASC) 부분 복합 인덱스를 걸었을 때, 22.9ms (19배 성능 향상) - Order By 절의 컬럼과 Where 절의 컬럼 모두 부분 복합 인덱스를 걸었을 때, 6.91ms (64배 성능 향상!!)
반면, 테이블의 일부에만 인덱스를 걸어 주었기 때문에 많은 컬럼을 복합 인덱스로 추가해도, 인덱스의 크기는 1.7 MB로 디스크 용량을 많이 차지하지 않았습니다.
다음과 같이 인덱스를 추가해 주었습니다.
create index progress_partial_idx
on sub_task (first_order_by desc, second_order_by, sub_task_type)
where current_progress < total_progress;
Join + Where 조건을 인덱스만을 이용하여 조회
Join을 이용하는 부분도 최적화를 진행할 수 있습니다. 다음은 위의 쿼리 중 Join 절과 Where 절 일부입니다.
inner join main_task on sub_task.main_task_id = **main_task.id**
where **main_task.main_task_type** = ?
여기서 Join 대상 테이블인 main_task 테이블을 id와 main_task_type으로 조회하는 것을 볼 수 있습니다.
(main_task.id, main_task.main_task_type)으로 복합 인덱스를 걸면 직관적으로 성능이 향상될 것처럼 보입니다.
실제로 PostgreSQL은 인덱스만으로 모든 데이터를 조회하는 Index-only Scan을 지원하며 Join 시에도 사용할 수 있습니다. 단, 옵티마이저가 Nested Join 알고리즘을 선택해야 합니다. (Hash Join과 Merge Join을 사용하면 인덱스로 성능 향상이 안 됩니다)
복합키를 걸 때에는 카디널리티가 높은 것에서 낮은 순서대로 거는 것이 좋으므로 id를 먼저 걸고 main_task_type을 다음에 걸어 주었습니다.
create index composite_idx
on main_task (id, main_task_type)
Django 호환성
Django에서는 2.2 버전 기준으로, 위에서 언급했던 단일 인덱스, 복합 인덱스, 부분 인덱스, 부분 복합 인덱스를 모두 지원합니다.
성능 향상
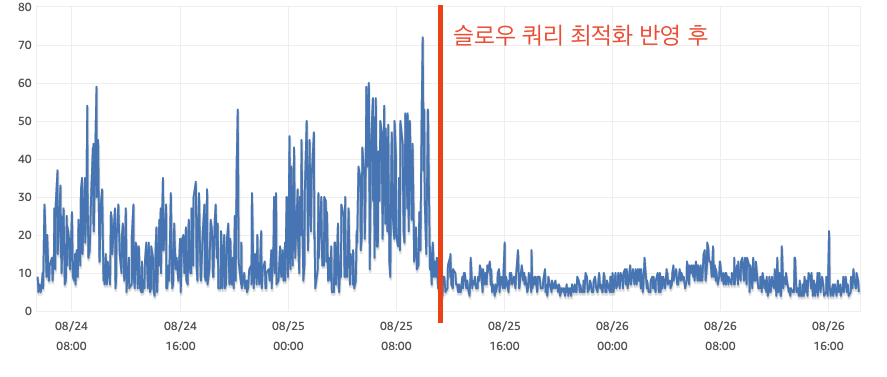
RDS CPU 지표입니다. 안정화 반영 전 최대 70%를 넘어가던 CPU는, 안정화 이후 10%에서 20% 정도를 유지하는 안정적인 모습을 보여주고 있습니다.
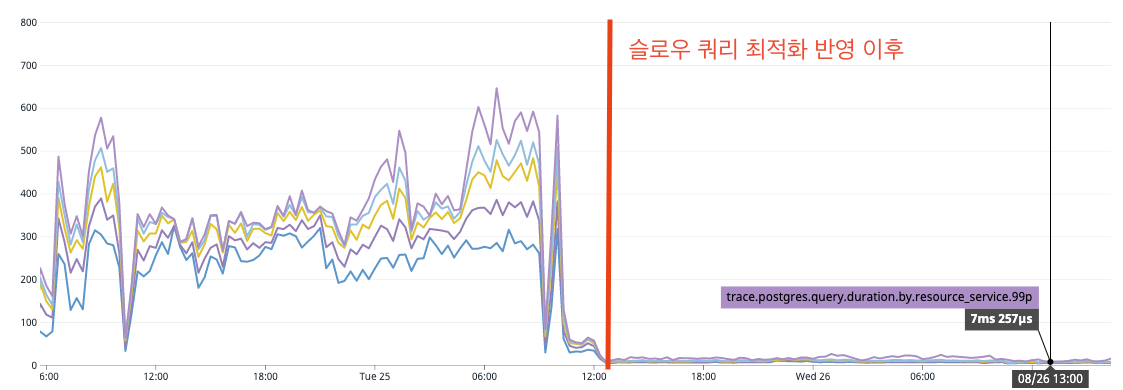
다음으로는 SQL 처리 시간입니다. 처리까지 최대 700ms 가까이 걸리던 쿼리가 안정화 이후 10ms를 벗어나지 않는 것을 확인할 수 있었습니다.
Lessons Learned
- 데이터베이스의 인덱스를 실험할 때는 프로덕션 데이터베이스를 복제해서 실험하는 것이 가장 좋습니다. Local, Dev, QA, Stage 환경과 Production 환경은 데이터 양과 분포도가 다르기 때문에 쿼리 실행 계획이 같게 나오지 않습니다.
- PostgreSQL에서는 테이블의 일부에만 인덱스를 거는 부분 인덱스 기능이 있습니다. 큰 테이블에서 일부 데이터만 주로 쿼리하는 경우 이를 잘 이용하면 데이터베이스 쿼리 성능을 크게 높일 수 있습니다.
- PostgreSQL에서는 표현식에도 인덱스를 걸 수 있습니다. 부분 인덱스를 적용하기에 앞서 표현식 인덱스를 거는 것을 적용했었습니다. 옵티마이저가 예상 열을 실제보다 5,000배 이상 많이 잡는 등 데이터의 갈피를 잡지 못하고 혼란스러워하는 것을 볼 수 있었습니다. 심지어는 실시간으로 쿼리 플랜이 불안정하게 바뀌기도 하였습니다. (조금만 트래픽이 더 많았어도 바로 장애로 이어질 수 있던 순간이었습니다) 따라서 표현식 인덱스를 추가하고 며칠간 모니터링 후 롤백하고, 부분 복합 인덱스를 추가했습니다. 프로덕션 반영 후 지속해서 모니터링 중인데, 부분 복합 인덱스가 성능도 더 낫고 쿼리 플랜도 안정적으로 나오고 있습니다.
- Order By 조건에 인덱스를 태우려면, 복합 인덱스를 걸 때 Order By 절의 정렬 조건을 맨 앞에 붙이고, Where 절의 컬럼들은 그 뒤에 붙여야 옵티마이저가 인덱스를 사용합니다. 이 때, 복합 인덱스의 순서도 맞아야 하고 ASC, DESC 여부도 맞아야 합니다. 하나라도 틀리면 인덱스를 타지 않습니다.
- 인덱스를 추가해도 옵티마이저가 인덱스를 사용하지 않는 게 더 빠르다고 판단하면, 인덱스를 타지 않고 Full Table Scan을 진행합니다. 데이터의 분포도에 따라 인덱스의 사용 여부가 결정되기 때문에, 프로덕션 DB를 복제해서 테스트를 진행하는 것이 좋습니다.
- PostgreSQL에는 기본적으로는 쿼리 힌트가 없고,
pg_hint_plan라는 확장을 이용하면 오라클처럼 쿼리 힌트를 사용할 수는 있지만, 권고하고 있지는 않습니다. (AWS RDS에서도 해당 확장을 지원하기는 합니다) 쿼리 힌트를 사용하기 전, 쿼리가 왜 느린지를 파악하고 대안을 찾아보는 것이 우선입니다. 쿼리 힌트를 사용하면 당장은 잘 돌아가겠지만, 데이터가 많아지거나 분포도가 달라지면 문제가 생길 수 있으며, 추후 PostgreSQL 업그레이드 시 더 효율적인 실행 계획을 사용하지 못하거나 느려지는 등, 기술 부채로 남을 수 있습니다. set enable_nestloop/enable_hashjoin/enable_mergejoin = on/off;등의 설정을 이용하여 Join 알고리즘을 변경해 테스트해볼 수 있습니다.- PostgreSQL의 Explain은 마치 고대 상형 문자처럼 매우 해독하기 어렵습니다. 이를 시각화해주는 Postgres Explain Visualizer 2 라이브러리를 알게 되어 유용하게 잘 사용했습니다. 서비스 주소: https://explain.dalibo.com/
Reference
- Do covering indexes in PostgreSQL help JOIN columns?
- Nested Join vs Merge Join vs Hash Join in PostgreSQL
- PostgreSQL Documentation : CREATE INDEX
- PostgreSQL Documentation : Partial Indexes
- PostgreSQL Wiki : Index-only scans
- Django Docs : Model index reference # condition
- Speeding Up PostgreSQL With Partial Indexes
- Amazon RDS의 PostgreSQL
- PGCon 2016 - A Challenge of Huge Billing System Migration
Read more
-
Spring WebClient에서 새어나가는 메모리 잡기
WebClient를 사용한 애플리케이션에서 메모리 누수로 인하여 서비스 장애가 발생했습니다. 메모리 누수의 원인을 찾아 해결하는 여정을 공유합니다. -
Pull Requests를 Merge 하면 자동으로 배포하기
Pull Requests를 Merge하면 자동으로 배포가 되도록 시스템을 구성하기까지의 고민을 공유합니다.