온디바이스 AI 얼굴 식별 파이프라인 최적화
하이퍼커넥트의 Match Group AI 팀은 다양한 도메인의 머신러닝 모델을 연구하고, 이를 글로벌 서비스에 적용하고 있습니다. 그중 하나로, 사용자의 갤러리에 저장된 수천 장의 사진 중 프로필에 적합한 사진을 추천하는 AI 기술을 연구하고 있습니다. 이번 포스트에서는 안드로이드 온디바이스(on-device) 사진 추천 기술에 사용되는 얼굴 식별(Face Verification) 파이프라인을 최적화하는 과정에서의 주요 경험을 공유하고자 합니다.
Motivation
Tinder에서 진행한 연구에 따르면, 싱글 사용자의 85%는 데이팅 앱에서 프로필 사진이 매우 중요하다고 생각하고 있으며, 52%는 적절한 사진을 고르는 데 어려움을 느끼고 있습니다. 실제로 젊은 세대는 프로필 사진을 고르는 데 평균 33분을 사용한다고 응답했습니다. 저희는 이러한 사용자 경험의 어려움을 해소하기 위해 AI 추천 기술을 도입하여 사용자 경험을 혁신하고자 했습니다.
사용자의 갤러리에 있는 사진 중에서 좋은 이미지를 찾기 위해서는, AI가 갤러리 전체에 접근하여 분석을 수행해야 합니다. 하지만 갤러리는 매우 민감한 개인 정보이기 때문에, 추천 과정에서 생성되는 데이터나 분석 결과가 네트워크를 통해 외부로 전송되어서는 안 됩니다. 이러한 보안과 프라이버시 요구를 충족하기 위해, 모든 데이터 처리는 기기 내에서 시작되고 종료되어야 합니다. 저희는 이러한 기술적 제약과 사용자 보호 원칙을 바탕으로, Match Group의 다른 브랜드들과 함께 온디바이스 ML 기술 기반의 AI 사진 추천 기술을 연구하고 개발해 왔습니다. 기술의 전반적인 동작 방식에 대해 더 알고 싶으시다면, Tinder 기술 블로그를 참고해 보셔도 좋습니다.
AI 사진 추천은 크게 두 단계로 구성됩니다. 첫 번째는 얼굴 인식 파이프라인으로, 전체 사진 중 사용자 본인의 얼굴이 포함된 이미지를 식별합니다. 다음으로 추천 파이프라인은 이들 중에서 품질이 좋은 사진을 선별하고, 프로필로 사용하기에 부적절한 사진을 걸러 최종 결과를 제공합니다. 얼굴 인식 파이프라인은 사용자의 전체 사진을 대상으로 하기 때문에 실행 속도가 매우 중요합니다. 모델을 개선함으로써 속도 향상을 기대할 수도 있지만, 실제 온디바이스 ML 프로젝트를 수행하다 보면 모델 외적인 병목 요소를 많이 마주하게 됩니다.
저희는 모델을 변경하지 않고도 각 연산의 배치 방식과 실행 구조를 개선함으로써, 안드로이드 얼굴 식별 파이프라인에서 응답시간 37% 단축, 처리량 530% 개선이라는 성능 향상을 이끌어낼 수 있었습니다. 이제 저희가 최적화 문제에 어떤 전략으로 접근했는지를 단계별로 설명드리고자 합니다.
Understanding the Face Verification Pipeline
최적화 내용을 소개하기 전에, 우선 얼굴 식별 기술이 무엇인지를 빠르게 살펴보겠습니다. AI 사진 추천에서 얼굴 식별 기술은 두 이미지에 동일 인물이 포함되어 있는지를 확인하는 목적으로 사용되고 있습니다. 얼굴 식별은 얼굴 탐지(Face Detection) 단계와 얼굴 인식(Face Recognition) 단계로 나뉘는데, 각각 도식을 중심으로 간단하게 설명드리겠습니다.
얼굴 탐지(Face Detection) 파이프라인

얼굴 탐지는 사진에서 얼굴을 식별해내 좌표를 뽑아내는 단계입니다. ML 모델을 이용하여 (1) 얼굴이 있는 직사각형 영역(bounding box)을 찾아내고, (2) 눈/코/입술/귀 등 중요한 이목구비 위치(landmark)를 찾아냅니다. 이후, NMS 알고리즘 등 후처리를 적용하여 얼굴을 알맞게 오려내고, 적절한 변환(similarity transform)을 통해 이목구비를 정면으로 정렬합니다. 정렬된 얼굴 이미지는 이후 얼굴 인식 파이프라인에서 활용합니다. 저희는 프로필 사진에서 얼굴을 탐지하는데 특화된 자체 경량 모델을 양자화(quantization)하여 사용하고 있습니다.
얼굴 인식(Face Recognition) 파이프라인
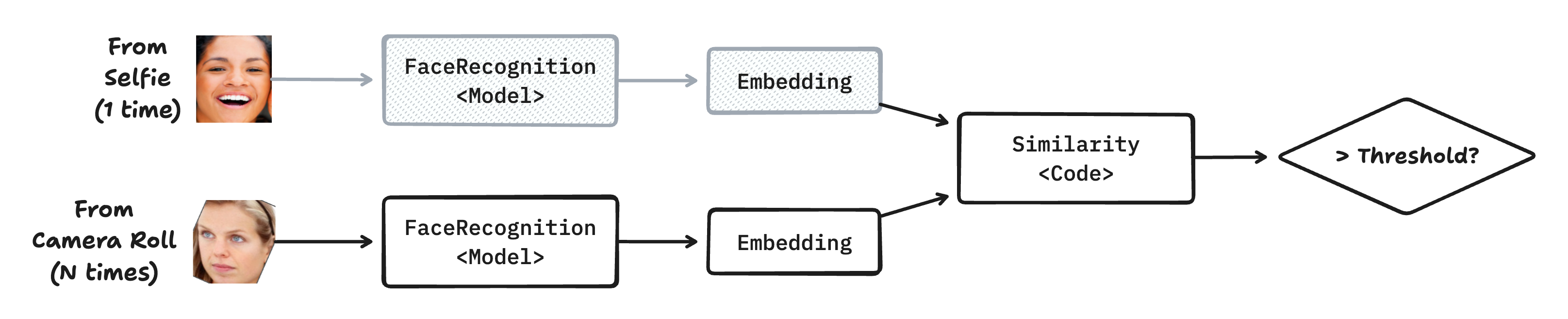
얼굴 인식은 두 얼굴이 동일인인지를 예측하는 단계입니다. ML 모델을 이용하여 (1) 얼굴 이미지에서 고유한 임베딩(Embedding) 벡터를 생성하고, (2) 이를 이미 계산해둔 기준 임베딩과 비교하여 유사도를 구합니다. (3) 유사도가 일정 기준(threshold)을 넘어서면 동일인으로 판정합니다. 이렇게 동일 인물이 포함된 것으로 판정된 사진은 이후 추천 파이프라인에서 활용하게 됩니다. 저희는 써드파티 얼굴 인식 라이브러리를 활용하여 임베딩 추론 및 유사도 계산을 수행하고 있습니다.
얼굴 식별(Face Verification) 파이프라인 요약
이처럼 얼굴 식별 파이프라인은 얼굴 탐지(Detection)와 얼굴 인식(Recognition)의 두 단계로 운영됩니다. 파이프라인으로 각 사진의 사용자 포함 여부를 식별하면, 이를 바탕으로 특정 인물이 포함된 사진만 추천하는 등 제품의 개인화 기능을 구현할 수 있습니다.
지금까지 얼굴 식별 파이프라인의 개요를 설명하였습니다. 지금부터는 저희가 주어진 ML 파이프라인의 최적화에 어떻게 접근하였는지를 하나하나 설명드리도록 하겠습니다.
How to optimize the inference time
실험 설정
성능을 개선하기 앞서, 어떤 환경에서 성능을 측정했는지 설명드리겠습니다. 온디바이스에서 성능 측정은 서버 환경과 달리 기기 환경이 매우 다양하기 때문에, 측정 노이즈로 인해 수치가 쉽게 왜곡될 수 있습니다. 따라서 측정 노이즈를 최소화하기 위해 다음 조건에서 측정했습니다.
- 측정 기기: Galaxy S24 (Android 14)
- 추론 엔진: Tensorflow Lite CPU 가속 적용
- 측정 환경: 완전 충전 후 외부 전원을 공급한 상태에서 측정
- 측정 방식: 특정 벤치마크 시나리오마다 500회 반복하여 측정
- 측정 후에는 5~10분 간격으로 기기 쿨링 진행
AS-IS 구현의 병목 지점 측정
얼굴 식별 파이프라인을 최적화하기에 앞서, 현재 구현에서 병목이 발생하는 지점을 정확히 파악하는 것이 가장 중요합니다. 직감만으로 최적화하는 것은 실제 성능 개선으로 이어지지 않을 뿐 아니라, 시간을 낭비하고 코드 복잡도만 증가시킬 수 있습니다. 따라서 최적화는 반드시 정량적 분석에 기반해 우선순위를 판단하고, 실제 실행 시간과 메모리 사용량이 집중되는 지점을 중심으로 진행해야 합니다.
저희는 성능 병목 지점을 파악하기 위해 두 가지 방법을 활용했습니다.
첫 번째는 Inline Timing Snippet입니다. 이는 성능을 확인하고 싶은 코드 블록에 시간 측정 함수를 삽입하여 소요 시간을 측정하는 방식입니다. 이 방법은 간편하지만, 빈번한 함수 호출로 인한 오버헤드가 발생할 수 있습니다.
import kotlin.time.measureTimedValue
inline fun <T> MeasureTime(
tag: String,
block: () -> T
): T {
return measureTimedValue {
block()
}.let { tv ->
println("${tag}: ${tv.duration.inWholeMicroseconds / 1000.0} ms")
tv.value
}
}
두 번째는 Profiler-based Approach로, Android Studio의 CPU/Memory Profiler나 perfetto 같은 프로파일러 도구를 활용해 성능을 분석하는 방식입니다. 이는 CPU/GPU 사용량이나 커널 레벨의 메트릭을 비교적 적은 오버헤드로 측정할 수 있습니다.
저희는 두 방법을 모두 사용하여 얼굴 식별 파이프라인의 세부 단계별 수행 시간을 정량적으로 측정했습니다. 아래 표는 샘플 입력 이미지에 대해 얼굴 식별 파이프라인의 각 작업의 평균 소요 시간을 나타낸 것입니다.
| Task | Avg Latency (ms) | Ratio (%) |
|---|---|---|
| Load Image | 46.4 | 33.6 |
| Face Detection | 30.5 | 22.1 |
| 3rd-party Face Recognition | 61.3 | 44.3 |
| Compare faces | 0.0 | 0.0 |
- Total Avg Latency: 138.2 ms
- Throughput: 7.2 photos/s
측정 결과, Load Image, Face Detection, 3rd-party Face Recognition이 주요 병목 구간으로 나타났습니다. 이를 바탕으로 각 단계별 최적화를 진행했습니다.
1. 필터링 우선 적용 및 연산 융합
먼저 최적화를 고려할 부분은 Face Detection 모델의 전후 처리 과정입니다. Face Detection 작업은 크게 두 부분으로 이루어집니다: 얼굴을 탐지하는 Detect Faces 작업과 얼굴 이미지를 잘라내는 Crop Bitmap 작업입니다. Detect Faces 작업의 세부 단계를 분석해보면, 모델 추론 작업을 제외하면 가장 병목이 되는 부분은 디코딩(decoding) 입니다. 전체 작업의 약 35%가 디코딩에서 소요됩니다.
| Category | Subtask | Avg Latency (ms) | Ratio (%) |
|---|---|---|---|
| Preprocessing | 입력 전처리 및 설정 | 0.70 | 2.9 |
| Inference | 모델 추론 | 14.09 | 58.3 |
| Postprocessing | Decode Bboxes & Landmarks | 8.50 | 35.2 |
| Postprocessing | Confidence 처리 및 필터링 | 0.64 | 2.7 |
| Postprocessing | Apply NMS | 0.18 | 0.7 |
| Postprocessing | 최종 후처리 | 0.02 | 0.1 |
여기서 디코딩이란 무엇일까요? 얼굴 탐지(Detection) 모델은 추론을 통해 다음과 같은 정보를 출력합니다:
- Confidence(신뢰도): 각 후보 영역이 얼굴일 확률 (0~1 사이의 값)
- Location(위치): 얼굴이 있을 것으로 예상되는 영역의 좌표
- Landmark(랜드마크): 눈, 코, 입 등 얼굴 특징점의 위치
디코딩은 이렇게 모델이 출력한 암호화된 형태의 좌표 데이터를 실제로 사용 가능한 픽셀 좌표로 변환하는 작업입니다. 예를 들어, “이 사진의 (100, 200) 위치에 얼굴이 있다”는 식으로 해석하는 과정입니다.
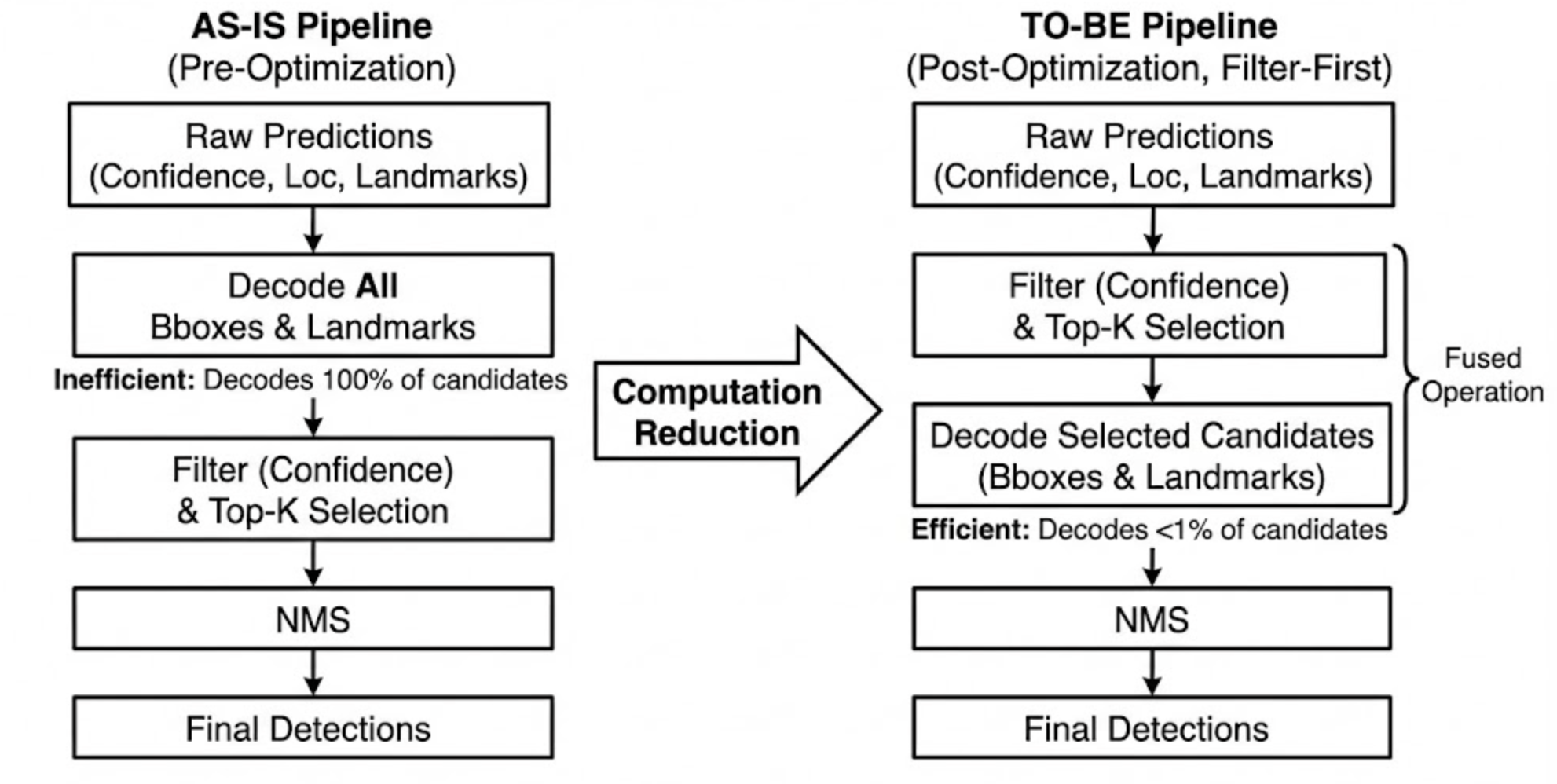
기존 구현에서는 모델이 출력한 모든 후보 영역에 대해 디코딩을 수행한 후, 그 다음 단계에서 confidence 값이 낮은 것들을 필터링하고 있었습니다. 하지만 여기서 중요한 질문이 떠올랐습니다: “모델의 출력에 존재하는 모든 bounding box 후보를 다 디코딩해야 하나?” 실제로 모델은 수천 개의 후보 영역을 출력하지만, 그중 대부분은 confidence가 매우 낮아서 결국 필터링되어 버립니다. 예를 들어, 모델이 10,000개의 후보를 출력했지만, 실제로 사용되는 것은 상위 100개뿐이라면 나머지 9,900개에 대한 디코딩 작업은 불필요한 낭비입니다.
이 개념은 데이터베이스 쿼리 최적화에서 널리 알려진 PPD(Predicate Pushdown) 기법과 유사합니다. PPD는 조건을 가능한 한 초기에 적용함으로써, 처리해야 할 데이터의 양을 줄여서 불필요한 연산을 조기에 배제하는 전략입니다.
우리의 경우도 마찬가지입니다. 디코딩 작업을 수행하기 전에 먼저 각 bounding box 후보의 confidence 값을 확인하여, 일정 기준 이상인 후보들만 선별한 다음, 그 선별된 후보들에 대해서만 디코딩을 수행하면 됩니다. 이렇게 하면 디코딩해야 할 데이터 양이 크게 줄어들고(예: 10,000개 → 100개), 불필요한 연산을 아예 수행하지 않게 되며, 전체 파이프라인이 훨씬 가볍고 빠르게 실행됩니다.
NMS(Non-Maximum Suppression): 여러 개의 겹치는 탐지 결과 중 가장 확실한 것만 남기는 알고리즘
또한, 필터링과 정렬(sorting), 상위 K개 선택(Top-K) 같은 작업들을 하나의 Fused Operation으로 묶어서 최적화할 수 있습니다. 이렇게 하면 독립적인 연산은 병렬로 처리할 수 있고(예: bounding box 디코딩과 landmark 디코딩은 서로 독립적이므로 동시에 수행 가능), 불필요한 중간 단계를 제거할 수 있습니다.
구조를 바꾼 이후에, 디코딩 시간은 기존 대비 약 79% 감소했습니다(8.9ms → 1.9ms). 전체 파이프라인 입장에서는, 단일 사진 처리 시간(latency)은 76ms → 70ms로 개선되었으며, 처리량(throughput)은 13장/초 → 14장/초로 개선되었습니다.
2. top-K 선택 알고리즘 최적화
디코딩 구조를 개선한 후 프로파일러를 통해 병목을 분석해보면, 앞 단계에서 설명했던 top-K개의 후보군을 뽑는 과정인 takePromisingTopKIndices를 처리하는데 CPU를 주로 사용하고 있으며 주된 병목임을 확인할 수 있습니다. 실제로 저희는 아래 코드와 같이 iteration을 진행하고 있었습니다.
private fun takePromisingTopKIndices(
conf: FloatArray,
topKBeforeNMS: Int,
confidenceThreshold: Float
): List<Int> {
return (0 until numPriors)
.filter { conf[confShape[0, it, 1]] > confidenceThreshold }
.sortedByDescending { conf[confShape[0, it, 1]] }
.take(topKBeforeNMS)
}
이 함수는 모델이 출력한 수천 개의 bounding box 후보 중에서, confidence가 threshold를 넘는 후보들을 필터링하고, confidence가 높은 순서로 정렬한 후, 상위 K개만 선택하는 역할을 합니다. 예를 들어, 모델이 10,000개의 후보를 출력했고 threshold를 넘는 후보가 500개라면, 이 중에서 confidence가 가장 높은 상위 100개를 선택하는 식입니다.
하지만 이 구현 방식은 다음과 같은 문제가 있습니다:
- 불필요한 전체 정렬: threshold를 통과한 모든 후보(예: 500개)를 정렬하지만, 실제로 필요한 것은 상위 K개(예: 100개)뿐입니다. 500개를 모두 정렬하는 것은 O(n log n) 시간 복잡도를 가지며, 최종적으로 사용하지 않을 400개의 원소까지 정렬하는 불필요한 작업이 발생합니다.
- 중간 컬렉션 생성 오버헤드:
filter,sortedByDescending,take각 단계마다 새로운 List를 생성하므로 메모리 할당 및 복사 비용이 발생합니다.
힙 기반 알고리즘으로 최적화
이 문제를 해결하기 위해, 전체를 정렬하는 대신 Min Heap(최소 힙) 자료구조를 활용하여 상위 K개만 유지하는 알고리즘으로 개선했습니다.
private fun takePromisingTopKIndices(
conf: FloatArray,
topKBeforeNMS: Int,
confidenceThreshold: Float
): List<Int> {
// Min Heap: confidence가 작은 것이 우선순위가 높음
val pq = PriorityQueue(compareBy<Int> { conf[confShape[0, it, 1]] })
for (i in 0 until numPriors) {
val confidence = conf[confShape[0, i, 1]]
if (confidence > confidenceThreshold) {
pq.add(i) // 필터를 통과한 인덱스를 힙에 추가
if (pq.size > topKBeforeNMS) {
pq.poll() // 힙 크기가 K를 초과하면 가장 작은 값(루트) 제거
}
}
}
// 힙에 남은 K개의 인덱스를 confidence 내림차순으로 정렬하여 반환
return pq.sortedByDescending { conf[confShape[0, it, 1]] }
}
힙 기반 알고리즘으로 전환한 결과, Pre NMS Filter & TopK 단계에서 78%의 응답 시간 개선을 확인할 수 있었습니다.
3. TensorBuffer 사용 시 getFloatValue 대신 floatArray 사용
응답 시간 벤치마크는 측정 대상 범위에 한정된 응답 시간 정보만 제공하기 때문에, 측정되지 않은 개별 함수마다 발생하는 오버헤드는 정확히 파악하기 어렵습니다. 추가적인 연산 오버헤드를 파악하기 위해 Android Studio Profiler의 Flame Chart를 활용해 분석한 결과, landmark 디코딩 과정에서 상당한 시간이 소요되고 있음을 확인했습니다. 특히 TensorBuffer 내부 값에 접근할 때 사용하는 getFloatValue에서 많은 시간이 소비되고 있었습니다.

이는 TensorFlow Lite의 TensorBuffer에서 필요한 값을 가져오기 위해 getFloatValue 메소드를 반복적으로 호출하는 것이 매우 비효율적이기 때문입니다. getFloatValue 메소드 내부에서 사용되는 ByteBuffer의 getFloat 메소드는 JNI(Java Native Interface)로 구현되어 있어 JNI 함수를 호출하는 오버헤드가 발생합니다.
JNI 함수 호출 시 발생하는 오버헤드는 다음과 같습니다:
- Marshaling Data: 자바와 네이티브 사이에서 객체를 변환하는 비용
- Function Call Overhead: 네이티브 함수를 호출하기 위한 환경 설정 비용과 컨텍스트 스위칭 비용
- Lack of JVM Optimization: 네이티브 코드는 JVM의 JIT 컴파일 최적화 대상이 되지 않음
- Context Switching: JVM과 네이티브 코드 간의 컨텍스트 스위칭 지연
따라서, TensorFlow Lite 모델의 출력 버퍼를 읽을 때 TensorBuffer로부터 반복적으로 getFloatValue를 호출하는 것보다, TensorBuffer의 floatArray 프로퍼티를 사용하면 FloatArray로의 복사 연산만 수행하기 때문에 JNI 호출은 최소화할 수 있고, JVM에서 관리되는 메모리 영역을 사용하기 때문에 JIT 컴파일에 의한 최적화 효과를 얻을 수 있습니다. TensorBuffer.floatArray의 구현을 보면, floatBuffer.get(arr)을 통해 FloatBuffer가 가지고 있는 native 메모리를 JVM heap에 위치한 FloatArray로 복사하는 연산이 memcpy를 이용해 1회만 발생하기 때문에 효율적으로 값을 복사할 수 있습니다. 이후 개별 원소에 접근하는 연산은 FloatArray의 get 연산이며 이는 JVM heap에서 관리되는 객체이므로 GC나 JIT 컴파일러의 최적화 대상이 됩니다.
위 최적화를 통해 getFloatValue를 사용한 함수들 (Pre NMS Filter & TopK, Decode Bboxes, Decode Landmarks, Apply NMS)의 응답 시간이 각각 10-20% 정도 개선되었습니다. 전체 파이프라인 입장에서는, 단일 사진 처리 시간(latency)은 70.2ms → 69ms로 개선되었습니다.
4. TensorFlow Lite 스레드 풀 크기 최적화
지금까지 살펴본 최적화는 모두 모델 외부의 로직을 대상으로 한 것이었습니다. 즉, 모델의 구조나 가중치를 변경하지 않고도 코드의 실행 순서를 조정하거나 알고리즘을 개선함으로써 응답 속도를 높일 수 있었습니다. 하지만, 실제 병목이 되는 부분은 모델 추론이고, 모델의 구조를 직접 수정하지 않는 한 응답 시간을 개선하기는 어렵습니다. 따라서, 저희는 모델 추론을 병렬로 처리하여 응답 시간이 아닌 처리량 개선을 시도했습니다.
TensorFlow Lite의 인터프리터는 intra operation 처리를 위한 thread pool을 가지고 있습니다. TensorFlow Lite는 이 스레드 풀을 이용해 단일한 연산을 처리할 때 여러 스레드로 작업을 쪼개 병렬적인 처리가 가능합니다.
저희 팀에서는 이 스레드 풀 크기의 기본 값으로 경험적으로 결정된 4를 사용하고 있었기 때문에 이것이 가장 최적인지에 대한 의문이 있었습니다. 하지만, 벤치마크를 돌려본 결과는 예상과 달랐습니다.
| Thread Pool Size | 1개 | 2개 | [AS-IS] 4개 | 8개 |
|---|---|---|---|---|
| P50 Inference 응답 시간(ms) | 6.2 | 18.6 | 13.8 | 83.5 |
P50은 중간값(median)으로, 전체 측정값 중 50%가 이 값보다 빠른 응답 시간을 보였음을 의미합니다.
내부 스레드 풀 사이즈가 1일 때가 가장 빨랐고, 스레드 풀 사이즈가 커질수록 더 지연되는 경향을 관찰했습니다. 이를 해석하면, TFLite 모델 내부의 병렬 연산이 실제로 병렬적으로 수행되기에 적합하지 않은 형태일 수 있음을 유추할 수 있습니다. 암달의 법칙(Amdahl’s Law)에 따르면, 병렬화를 통한 성능 향상은 병렬화 가능한 부분의 비율에 의해 제한됩니다. 즉, 어떤 연산을 병렬로 처리했을 때 성능 향상이 있으려면, 작업이 병렬적으로 분할 가능해야 하고 병렬적으로 처리된 작업의 결과를 하나로 합치고 동기화하는 비용이 작업을 쪼개지 않고 수행했을 때보다 작아야 합니다.
이를 직접 확인해보기 위해 실제 TensorFlow Lite 공식 문서에서 제안하는 프로파일링 도구를 이용해 모델 추론 시 어떤 연산이 느려지는지 관찰했습니다. 프로파일링 도구를 통해 각 연산별로 스레드 풀 크기에 따른 성능 변화를 측정한 결과, 특정 연산의 비용이 스레드 풀 크기가 커졌을 때 무려 7.8배나 느려진 것을 확인하였습니다.
| 연산 | Thread Pool Size = 1일 때 평균 응답 시간 (ms) | Thread Pool Size = 2일 때 평균 응답 시간 (ms) | 비고 |
|---|---|---|---|
| Binary Elementwise (ND):0 | 0.2 | 1.4 | 7.7배 지연 |
| Binary Elementwise (ND):1 | 0.2 | 1.4 | 7.8배 지연 |
해당 연산은 이미지 입력을 처리하기 위해 RGB 채널의 0~255 사이의 값을 모델이 선호하는 input range로 rescale 해주는 연산인데, 이 연산은 스레드 풀을 사용시 더 느려지는 것을 확인했습니다. 이처럼 프로파일링 도구를 활용하면 모델 내부의 각 연산이 스레드 풀 크기에 어떻게 반응하는지 구체적으로 파악할 수 있어, 최적의 스레드 풀 설정을 결정하는 데 큰 도움이 됩니다.
결과적으로, 스레드 풀의 크기가 4일 때 69ms인 응답 시간이 풀 크기를 1로 고정하자 60ms로 약 12.5% 응답 시간이 개선되었습니다. 다만, 이러한 최적화 옵션은 디바이스 사양에 따라 상이한 결과를 보일 수 있으므로, 실제 프로덕션 환경에 적용하기 위해서는 다양한 기기에서의 벤치마크가 필수적입니다. 스레드 풀 설정은 단순히 “많이 쓰면 빠르다”는 가정이 항상 성립하지 않으며, 연산의 성격과 디바이스 환경에 따라 세심하게 조율해야 합니다.
5. 모델 인스턴스 병렬화를 통한 처리량 최적화
앞서 살펴본 스레드 풀 크기 최적화는 단일 연산을 여러 스레드로 쪼개서 처리하는 방식으로, 하나의 이미지를 처리하는 응답 시간(latency)을 개선하는 것이 목표였습니다. 반면, 이번에 다룰 모델 인스턴스 병렬화는 여러 개의 모델 인스턴스를 만들어 서로 다른 입력 이미지들을 동시에 처리함으로써 단위 시간당 처리할 수 있는 이미지 수인 처리량(throughput)을 높이는 방법입니다. 개별 이미지의 처리 시간은 증가할 수 있지만(병렬 처리로 인한 동시성 제어 오버헤드 발생), 전체 시스템 관점에서 더 많은 이미지를 동시에 처리할 수 있게 됩니다.
얼굴 탐지(Detection) 모델 인터프리터 수 최적화
TensorFlow Lite에서 모델 추론을 위해 사용되는 인터프리터 객체는 기본적으로 thread-safe하지 않습니다. 하지만, 이는 단일한 Interpreter에 대한 thread-safety를 지원하지 않는 것이지 여러 개의 Interpreter를 만들어서 병렬로 처리하는 것은 지원 가능합니다. 병렬 모델 추론을 위해, Interpreter 수를 1개, 2개, 4개로 늘렸을 때 얼굴 탐지 모델 추론 응답 시간의 변화를 알아보기 위해 벤치마크를 진행했습니다.
| 인터프리터 수 | 1 | 2 | 4 |
|---|---|---|---|
| 얼굴 탐지(Detection) 평균 응답 시간 (ms) | 6.2 | 9.9 | 6.9 |
| 전체 파이프라인 응답 시간 (ms) | 60.3 | 107.3 | 105.3 |
| 처리량 (장/초) | 16.6 | 18.6 | 37.9 |
측정 결과 인터프리터 수를 1개, 2개, 4개로 늘렸을 때 추론 응답 시간은 소폭 늘지만 처리량은 16.6장/초 → 37.9장/초로 2.28배 향상되는 것을 확인할 수 있었습니다. 그런데, 전체 파이프라인에 걸리는 응답 시간은 급격하게 커지는 것을 관찰할 수 있습니다. 원인은 TFLite 얼굴 탐지 모델의 경우 인터프리터 수를 늘려 병렬적으로 동작할 수 있지만, 저희가 사용하고 있는 써드파티 라이브러리 얼굴 인식(Recognition) 모델이 탐지 모델의 결과에 의존하고 있어, 인식 모델이 병렬적으로 동작하지 않아 전체 파이프라인에 병목이 되기 때문입니다.
얼굴 인식(Recognition) 모델 수 최적화
따라서, 써드파티 라이브러리로 제공되는 얼굴 인식 모델이 병목이 되지 않도록 인식 모델 추론을 위한 스레드 풀을 만들어 시도했습니다.
(얼굴 탐지 모델 설정: 인터프리터 수 = 4, 스레드 풀 크기 = 1)
| 인식 모델 수 | 1 | 2 | 4 |
|---|---|---|---|
| 얼굴 인식(Recognition) 평균 응답 시간 (ms) | 44.0 | 36.5 | 37.6 |
| 전체 파이프라인 응답 시간 (ms) | 105.3 | 98.7 | 86.8 |
| 처리량 (장/초) | 37.9 | 40.4 | 45.9 |
얼굴 인식 모델 수를 늘린 결과, 전체 파이프라인 응답 시간을 줄일 수 있음은 물론, 전체 파이프라인의 처리량이 37.9장/초에서 45.9장/초로 추가로 향상되었습니다. 얼굴 탐지와 얼굴 인식 모델 모두를 병렬화함으로써 파이프라인 전체의 병목을 해소할 수 있었습니다.
최적화 작업 요약
이번 온디바이스 얼굴 식별 파이프라인 최적화 작업은 성능을 정량적 지표에 기반해 분석하고, 체계적으로 개선해 나간 과정을 소개했습니다. 그 결과, 응답 시간(latency per image)은 평균 138ms → 87ms로 약 37% 감소, 처리량(images/s)은 7.2장/초 → 45.9장/초로 약 530% 개선해, 훨씬 더 많은 이미지를 더 빠르게 처리할 수 있게 되었습니다.
단계별 최적화 내용 및 개선 수치:
| 단계 | 최적화 내용 | Latency (ms) | 단계별 개선율 | Throughput (photos/s) | 단계별 개선율 |
|---|---|---|---|---|---|
| Baseline | 초기 상태 | 138.2 | - | 7.2 | - |
| Step 1 | 필터링 우선 적용 및 연산 융합 | 70.2 | +49.2% | 14.3 | +98.6% |
| Step 2-3 | Top-K 최적화 + TensorBuffer 개선 | 69.8 | +0.6% | 14.3 | 0% |
| Step 4 | TFLite 스레드 풀 최적화 | 60.3 | +13.6% | 16.6 | +16.1% |
| Step 5 | 모델 인스턴스 병렬화 | 86.8 | -44.0% | 45.9 | +176.5% |
| 최종 | 전체 개선 (Baseline 대비) | 86.8 | +37.2% | 45.9 | +530% |
Step 5의 Latency 증가는 병렬 처리를 위한 동시성 제어 오버헤드에 의한 것이며, 실제 사용자 경험에서는 Throughput이 더 중요한 지표입니다.
Conclusion
성능 최적화 과정에서 가장 중요한 출발점은 직관이 아닌 정량적인 분석이라는 점입니다. 프로파일러와 벤치마크 도구와 같은 정량적인 분석 방법을 적극 활용해 실제로 어디서 시간이 소모되고 있는지를 수치로 확인한 것이 핵심이었습니다.
저희는 복잡한 기술을 사용하지 않고도 연산의 흐름을 재설계함으로써, 단순히 연산 속도를 빠르게 만드는 것뿐만 아니라, 필요 없는 연산을 아예 하지 않도록 만들어 훨씬 더 근본적인 성능 개선을 이끌어낼 수 있었습니다. 또한, 반복 호출되는 간단한 연산이 전체적인 성능에 나타나는 효과를 간과하면 안 된다는 사실도 확인할 수 있었습니다. 예를 들어, TensorBuffer.getFloatValue()는 단일 호출로는 성능에 거의 영향을 주지 않는 연산이지만, 수백만 번 반복 호출되면서 JNI 호출 오버헤드가 누적되어 전체 응답 시간에 병목이 되었습니다.
멀티 스레드는 만능이 아닙니다. TFLite 인터프리터의 스레드 풀 사이즈를 증가시켰을 때 일부 연산의 응답 시간이 7~8배 커지는 역효과가 발생했습니다. 이는 해당 연산이 실제로는 compute-intensive하지 않은 연산이라 병렬화로 인한 이득보다 병렬화된 작업을 합치는 비용인 communication overhead가 더 컸기 때문입니다. 따라서 병렬화의 효과를 사전에 예측하고 벤치마크를 통해 성능 향상폭을 검증하는 과정이 반드시 필요합니다. 한편, 병렬화는 처리량 향상에 효과적이었습니다. 얼굴 탐지(Detection)나 얼굴 인식(Recognition) 모델에 대해 인터프리터 혹은 인스턴스를 병렬로 구성한 결과, 단일 응답 시간은 동시성 제어를 위한 lock contention으로 인해 오히려 느려지는 경우도 있었지만, 전체 시스템의 처리량은 약 6.4배까지 향상되었습니다.
결국, 시스템 최적화는 전반적인 구조에 대한 이해와 실제 측정을 바탕으로 이뤄져야 하며, 성능 병목은 직관이 아닌 데이터를 통해 확인하고, 변경의 영향도 구체적인 수치를 통해 검증하는 것이 핵심입니다.