왜 막상 배포하면 효과가 없지? 타겟 지표에 맞는 ML모델 train/eval 설계하기
ML 벤치마크 태스크에서는 타겟 메트릭이 정해져 있고 모델링과 최적화에 집중하는 경우가 많습니다. 하지만 실제 서비스에 ML 모델을 적용할 때는, 무엇을 목표로 삼고 어떤 지표에 초점을 맞춰야 할지부터 정하는 과정이 매우 중요합니다. 비즈니스 목표가 아닌 잘못된 지표를 최적화 하는 경우, 모델 성능을 계속 높여도 서비스에서 아무런 효과가 발생하지 않는 상황을 겪기도 됩니다.
이번 포스트에서는 하이퍼커넥트 AI 조직이 매치그룹 내 데이팅 브랜드와 협업한 프로젝트를 각색한 사례를 소개합니다. 문제 정의에서 시작해 모델 학습 목표 설정과 데이터셋 구축, 오프라인 평가, 온라인 A/B 테스트, 실제 배포까지의 흐름을 따라가며, 비즈니스 문제를 ML 문제로 재구성하고 이를 실제 서비스 성과와 어떻게 연결했는지 살펴봅니다.
문제 상황
특정 서비스에 아이템과 각 아이템을 나타내는 속성(attribute)들이 있는 상황을 살펴봅시다. 만약 광고 추천이라면 아이템은 특정 상품, 속성은 상품별 광고 카피가 될 수 있습니다. 넷플릭스, 유튜브 등의 영상 플랫폼에서는 썸네일이 속성에 해당될 수 있습니다.
일반적으로 유저들이 아이템들을 살펴볼 땐 처음부터 모든 정보들이 노출되지 않습니다. 광고라면 플랫폼에서 노출시키는 아이템별 광고 카피 중 하나를 보게 되고, 영상을 볼 땐 썸네일이 우선적으로 나타나게 됩니다. 처음 노출된 속성은 유저의 아이템에 대한 첫인상을 결정하고, 나아가 유저가 해당 아이템에 대해 구매·소비 등의 전환으로 이어질지에 대해서도 중요한 역할을 하게 됩니다. 즉, 사용자에게 특정 아이템의 여러 속성 중 어떤 것을 처음에 노출시킬지 잘 선택하는 것만으로도, 전환율을 늘릴 수 있습니다. 이후에는 처음에 노출될 속성을 대표 속성(primary attribute)이라고 표현하겠습니다.
그렇다면 유저들에게 전환율을 높일 수 있는 대표 속성을 어떻게 찾을 수 있을까요? 아이템에 포함된 여러개의 속성 중에서, 각 속성을 랜덤하게 대표 속성으로 선택해 유저들에게 노출시켰을 때 전환율을 비교해볼 수 있습니다. 문제를 multi-armed bandit 문제로 바라보는 관점인데요, 문제점이 있습니다. 바로 새로운 아이템이 생기거나 속성이 업데이트 되면 처음부터 다시 exploration을 해야한다는 점입니다. 전환율이 더 높은 속성을 노출시킬 수 있던 기회비용이 드는 것이기 때문에 공짜가 아니고, 최적의 대표 속성을 찾기까지 시간도 걸립니다.
만약 아이템에 포함된 여러 속성 중, 가장 높은 전환율을 보일 대표 속성을 미리 예측해주는 AI 모델이 있다면 어떨까요? 새로 업로드 된 아이템이나 속성이라도 별도의 exploration 단계 없이 아이템의 전환율을 극대화할 수 있을 것입니다. 이후 글에서는 이 문제를 AI 모델이 풀 수 있는 문제로 변환하기 위해 어떤 과정들을 거쳤는지를 소개드리겠습니다.
데이터로 문제 구체화하기
이번 프로젝트의 목표는 한 아이템의 여러 속성 중에서 유저에게 가장 높은 전환율을 보일 속성을 고르는 모델을 학습하는 것 입니다. 이 모델을 학습하기 위해서는, 학습 및 평가를 위한 데이터를 구축하는 것이 첫번째 작업입니다.
유저가 아이템을 보고나면, 전환이 발생할 수도, 발생하지 않을 수도 있습니다. 이 때 대표 속성이 무엇이었는지가 남아있다면, 각 속성에 대한 전환 여부(0/1) 데이터를 구축할 수 있습니다.
전환 데이터 예시:
| user | item | Item feature 1 | Item feature 2 | primary attribute | conversion |
|---|---|---|---|---|---|
| User A | Item X | Category 1 | 2.3 | Attribute 1 | 1 |
| User B | Item X | Category 1 | 2.3 | Attribute 1 | 0 |
| User C | Item X | Category 1 | 2.3 | Attribute 2 | 1 |
| User D | Item Y | Category 2 | 3.5 | Attribute 3 | 0 |
| … | … | … | … | … | … |
학습 방식을 고안하고 그 방식이 망가지는 상황은 없을지 이론적으로 검토하기 위해, 위 데이터의 주요 column을 서로 종속관계가 있는 확률변수로 다루겠습니다. ’유저가 아이템의 속성을 보고 전환 여부가 결정되는 상황’에서 직접 드러나는 종속관계를 확률 그래프 모델(PGM)로 다음과 같이 표현할 수 있습니다:
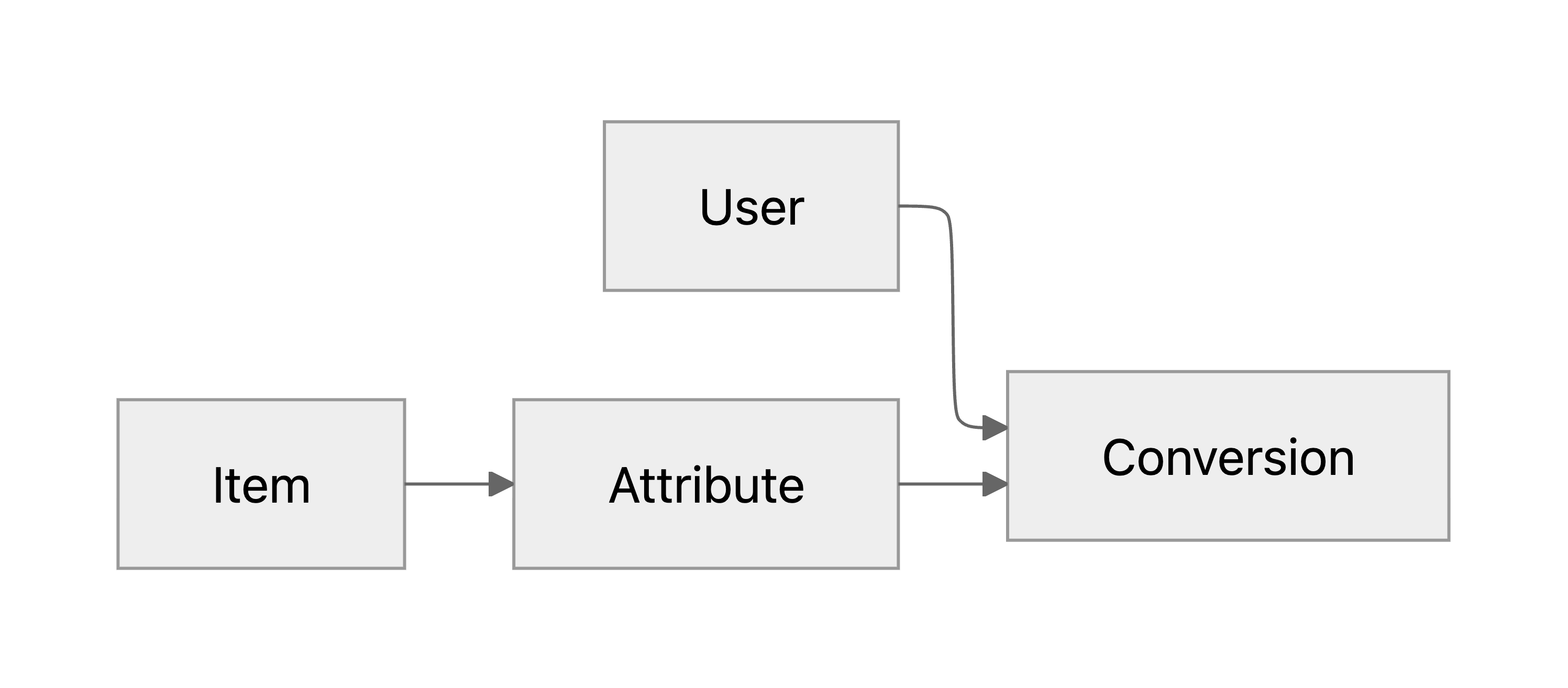
PGM은 변수들 간 조건부 독립 관계를 나타내는 수단이기 때문에, 위 그래프는 우리가 다루는 데이터에 대한 가정을 나타냅니다. 예를 들어 유저와 아이템 둘 다 incoming edge가 없는 것을 통해, 유저와 아이템이 서로 독립이라고 가정했다는 것을 알 수 있습니다.
이 가정들은 물론 현실적이지 않을 수 있지만, 얼마나 현실을 왜곡하는지에는 각 가정마다 차이가 있을 것입니다. 따라서 우선 많은 가정을 필요로 하는 간단한 상황에서 시작해서, 현실을 크게 왜곡하는 가정부터 하나씩 덜어 내면서 학습 방법론을 발전시켜 나가도록 하겠습니다.
안1: 속성 당 전환율을 구해서 supervised learning
주어진 테이블 데이터를 통해 곧바로 구할 수 있는 것이 있습니다. 바로 각 속성의 (대표 속성으로서의) 노출 수 대비 전환 수, 즉 전환율입니다. 아주 많은 수의 (속성, 전환율) 쌍이 확보된 상황이기 때문에, 속성 → 전환율을 예측하는 모델을 supervised learning으로 학습하는 방법을 직관적으로 생각할 수 있습니다.
즉 대표 속성 \(A\)가 주어졌을 때 전환 여부 \(C ∈ {0, 1}\)의 기대값(전환 확률)을 예측하도록 모델 \(f_θ(⋅)\)를 fitting합니다.
\[𝔼[C|A] ≈ f_θ(A)\]이 학습 목표를 달성하기 위해 binary cross entropy 혹은 mean squared error loss를 이용해 모델을 학습할 수 있습니다. 이렇게 학습된 모델을 이용해서 아이템의 각 속성이 전환을 이끌어내기에 얼마나 유리한지 판단하고, 가장 유리한 속성을 대표 속성으로 삼을 수 있습니다.
이제 모델의 예측 정확도를 최대한 끌어올리기만 하면 아이템의 전환율도 극대화할 수 있을까요?
안1 반박: 추천로직이 있다
앞서 한 아이템-유저의 독립성 가정이 보장된다면 위 방식이 말이 되지만, 실제로는 어떤 유저에게 아이템이 완전히 무작위로 보여지는 것이 아니고 추천 알고리즘 등의 비즈니스 로직에 의해 독립성 가정이 깨지게 됩니다. 아이템에 따라 만나는 유저의 분포가 다르다는 것을 PGM에 반영하면 다음과 같습니다:
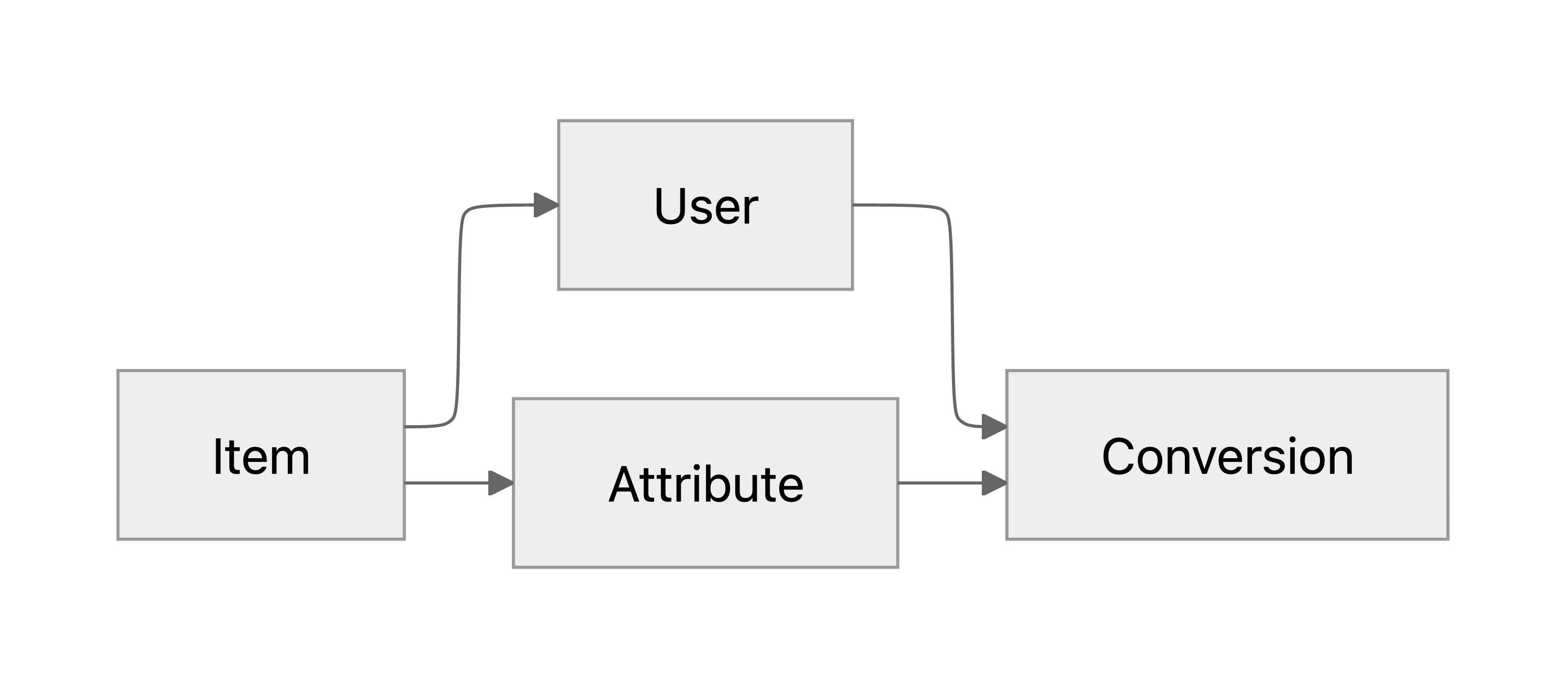
이것이 왜 문제가 될 수 있는지 다소 과장된 예시를 들어 보겠습니다. 특정 속성이 어떤 값이냐에 따라 두 가지 유형 A, B로 나눠진다고 하고, 두 가지 user group X, Y가 있다고 해 봅시다. 여기서 각 속성 유형이 각 유저 group에 노출되는 경우 전환 확률이 다음과 같다고 가정합니다:
| user group X | user group Y | |
|---|---|---|
| attribute type A | 0.4 | 0.2 |
| attribute type B | 0.5 | 0.3 |
모든 경우에 대해서 유형 B가 유형 A보다 유리함을 알 수 있습니다. 하지만 만약 추천로직에 의해 유형 A를 대표 속성으로 두는 아이템은 user group X에게만, 유형 B를 대표 속성으로 두는 아이템은 user group Y에게만 노출된다면, 우리가 얻은 데이터로 계산한 전환율은 속성 A가 더 높습니다. 그렇다면 이 전환율을 타겟으로 학습한 ML모델은 아무리 최적화를 잘 하더라도 속성 A가 속성 B보다 낫다는 잘못된 결론을 내릴 것입니다.
실제로는 위 반례와 같이 아주 뚜렷하게 실패하지는 않을 수 있지만, 데이터셋 상 전환율을 정확히 예측하는것이 유리한 속성을 고르는 측면에서는 최적이 아니라는 것을 알 수 있었습니다. 그렇다면 어떻게 위 반례에서도 망가지지 않는 학습 방식을 설계할 수 있을까요?
안2: user-wise conversion rate(CR) ranking
위 반례에서 전환율 기반의 방식이 실패한 구체적인 이유를 생각해보면, 유저마다 conversion의 기준점이 다르다는 것이 중요하게 작용했음을 알 수 있습니다. 따라서 유저마다 기준점이 다른 것의 효과가 상쇄되도록, 같은 유저의 행동을 상대적으로 비교하는 방식을 떠올려볼 수 있습니다.
구체적으로는 같은 유저(\(U_1 = U_2\))가 전환한 아이템의 속성과 전환하지 않은 아이템의 속성의 쌍이 순서없이 주어졌을 때, 각 속성에 대한 score의 차이로 전환한 속성이 어떤 것인지에 대한 확률을 모델링할 수 있습니다:
\[p(C_1 > C_2 | A_1, A_2, U_1=U_2) \approx \sigma(f_\theta(A_1) - f_\theta(A_2))\]이렇게 되면 유저의 베이스 레벨과 상관없이 상대적인 시그널 만으로 학습되므로, 이전 반례에서도 (최소한의 exploration이 이루어진다면) 유리한 속성을 제대로 고를 수 있게 됩니다. 이제 이 방식에 남아있는 약점은 무엇이 있는지 살펴보겠습니다.
안2 반박: 유저의 전환 여부는 아이템 전체에도 영향을 받는다:
지금까지의 데이터 모델은 전환이 속성과 유저에 의해 결정되고, 아이템이 직접 전환에 영향을 주지는 않는다고 가정하고 있습니다. 유저가 아이템의 첫인상을 판단할 때 가장 먼저 눈에 들어오는 것은 대표 속성이기 때문에 이는 어느정도 말이 되는 가정이라고도 볼 수 있습니다. 하지만 실제로는 전체적인 속성들과 기타 아이템 정보에도 전환은 작건 크건 영향을 받을 수 밖에 없습니다. 대표 속성 이외의 아이템 프로필이 전환에 영향을 주는 것을 PGM에 반영하면 다음과 같습니다:
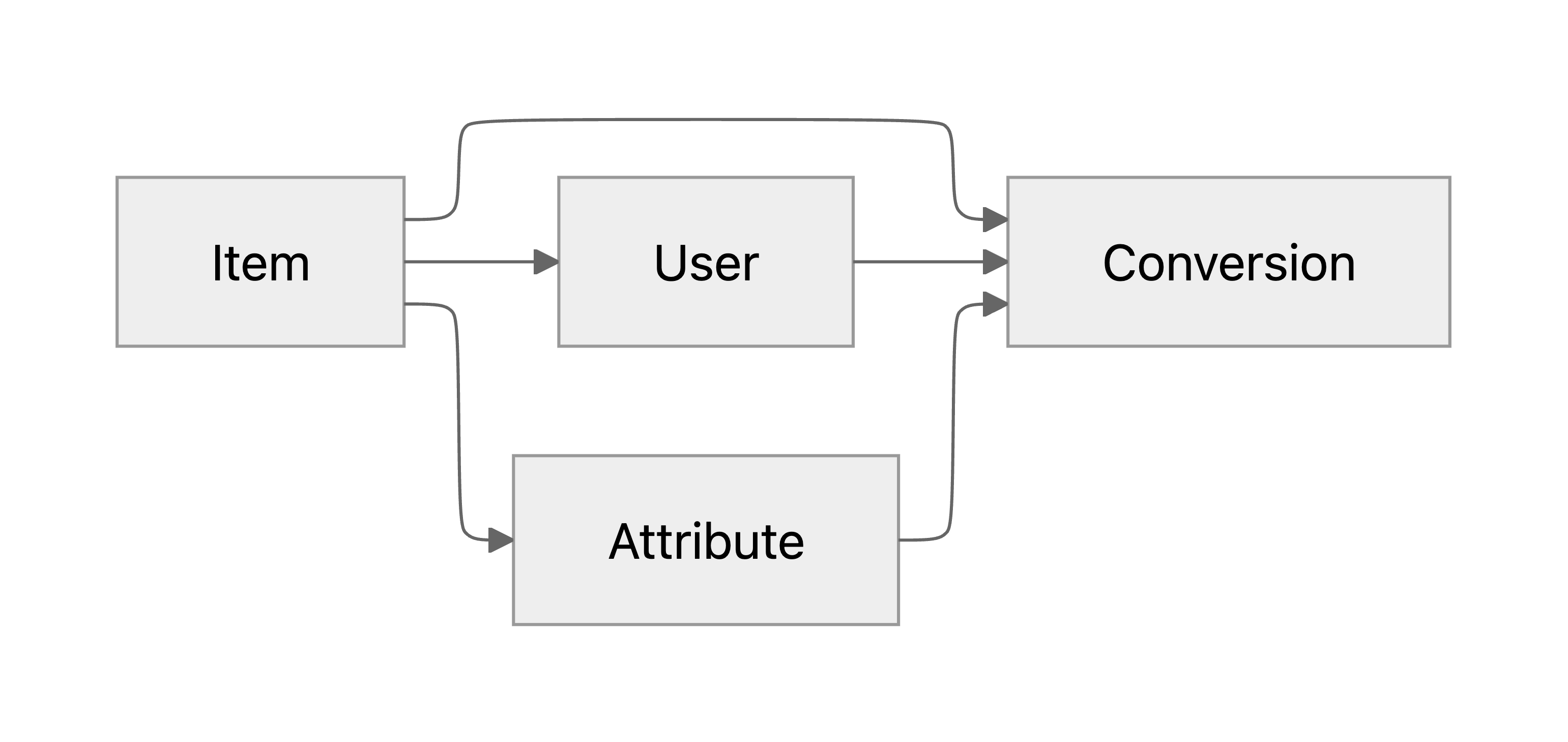
위와 같이 현실적인 요소가 추가되었을 때 유저 기준 상대적인 선호 예측이 실패할 수 있는 케이스를 한가지 떠올려볼 수 있습니다. 아이템 X, Y가 각각 대표 속성으로 속성 유형 A, B를 가지고 있다고 해보겠습니다. 만약 어떤 유저가 아이템 X의 전체적인 설명이 맘에 들어서 전환했고, 아이템 Y의 전체적인 설명이 맘에 들지 않아서 전환하지 않았다고 해보겠습니다. 이 데이터로 학습한 모델은 속성 유형 A가 속성 유형 B보다 유리하다는 판단을 할 것입니다. 하지만 판단에 영향을 준 것은 전체적인 설명이고, 대표 속성의 임팩트는 오히려 반대로 유형 B가 유리했을 수도 있는 것입니다.
즉 다음과 같은 상황으로 정리할 수 있습니다:
- 학습데이터 상 유저의 선호: \((I_x, A_a) > (I_y, A_b)\)
- 모델이 학습하는 순서: \(A_a > A_b\)
- 모든 케이스에 대한 유저의 선호: \((I_x, A_b) > (I_x, A_a) > (I_y, A_b) > (I_y, A_a)\)
- 실제로 유리한 순서: \(A_b > A_a\)
이런 이슈가 실제 환경에서도 발생할 수 있을까요? 아이템을 마케팅할 때는 각 아이템의 강점을 어필하고 약점은 강조되지 않도록 적절히 배치하는 것이 좋은 전략이라고 할 수 있습니다. 모든 아이템이 같은 강점을 가지고 있지 않다는 점을 생각하면, 현실에서도 충분히 발생 가능성이 있다고 짐작할 수 있습니다.
안3: item-wise attribute CR ranking
앞서 소개한 케이스에서는 아이템 자체가 전환에 직접 영향을 주면서, 각 아이템의 입장에서 유리한 속성을 잘못 판단했었습니다. 그렇다면 아이템이 달라서 생기는 효과를 상쇄하기 위해 같은 아이템의 두 속성을 비교하는 방식으로 학습하는 것을 대안으로 고려할 수 있습니다.
구체적으로는 같은 아이템(\(I_1 = I_2\))의 두 속성이 주어졌을 때, 전환율이 높은 속성이 어떤 것인지에 대한 확률을 score 차이로 모델링합니다:
\[p(\bar C_1 > \bar C_2 | A_1, A_2, I_1=I_2) \approx \sigma(f_\theta(A_1) - f_\theta(A_2))\]이렇게 되면 다시 서로 다른 유저들의 전환 데이터끼리 비교하게 되지만, 같은 아이템이 노출되는 유저들이므로 분포 관점에서는 동질성을 지닌 유저 그룹들일 것이라고 할 수 있습니다. 이제 꽤 robust한 방법이 된 것 같지만, 혹시 이 방법으로도 해결되지 않는 부분이 남아있을까요?
안3 반박: 아이템이 주어졌을 때 유저와 아이템이 독립이라는 가정이 남아있다
같은 아이템을 보는 유저들이더라도, 그 각 속성에 반응하는 유저들이 분포 레벨에서 달라질 여지가 남아 있습니다. 예를 들어 ’시간’이 일종의 hidden variable로 작용할 수 있습니다. 아이템을 등록한 사람들이 시간에 따라 대표 속성을 바꿀 수 있고, 전체적인 유저 풀이 변화하거나 추천 로직에 업데이트가 생길 수도 있습니다. 그러면 같은 아이템이 전제된 상황에서도 유저와 속성의 독립성이 깨지게 되고, 안1(단순 supervised learning)의 반례에서 봤던 아이템-유저 간 종속성 문제와 유사한 문제가 한 계층 아래에서 발생하게 됩니다.
추천 로직에 속성을 직접 활용하지 않는 이상 속성과 유저가 서로 인과적으로 영향을 주는 것은 아니기 때문에, 위의 ’시간’과 같이 속성과 유저에 동시에 영향을 주는 hidden variable을 추가하여 유저와 속성간 종속성을 PGM에 반영하겠습니다:

인과 추론 분야에서는 위와 같은 원리로 문제를 일으키는 hidden variable을 confounder라고 부릅니다. Confounder 역할을 하는 요인들을 알고있다면 고려할 수 있는 분석 방법론들이 있지만, 미처 고려하지 못한 confounder들의 영향까지 한번에 해결할 수 있는 가장 확실한 방법이 있습니다. 효과를 알아내고자 하는 변수값을 직접 랜덤하게 할당하여 결과를 관찰하는 randomized controlled trial(RCT)입니다. 유저 트래픽을 랜덤하게 분산시켜서 결과를 관찰하는 A/B 테스트가 RCT의 가장 대표적인 형태입니다.
최종안: randomized 데이터를 활용한 item-wise attribute CR ranking
우리 상황에서 RCT의 원리를 적용하려면, 어떤 아이템을 유저에게 보여줄 때 그 아이템의 속성 후보들 중에서 대표 속성을 랜덤하게 골라서 보여주면 됩니다. 이렇게 되면 속성은 오로지 아이템에만 의존하게 되고, hidden variable이 confounder로 속성에 영향을 주는 관계를 강제로 끊어낼 수 있습니다. 이 효과를 PGM으로 나타내면 다음과 같습니다:
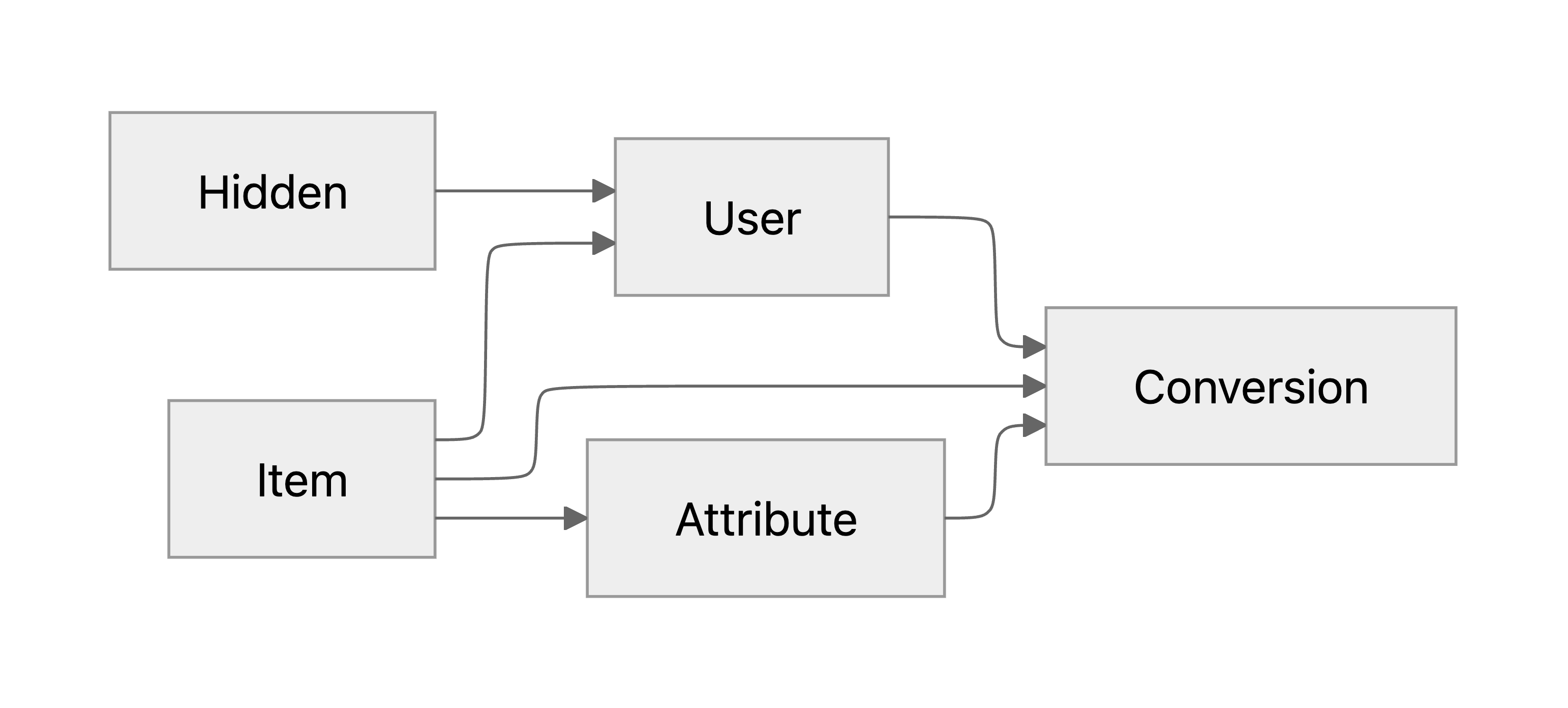
운이 좋게도, 이미 위와 같은 방식으로 수집해 둔 ‘attribute shuffle’ 데이터가 소량이지만 존재한다는 것을 알게 되었습니다. 이 데이터는 원래 학습이 아니라 평가에 사용할 예정이었지만, 앞서 살펴본 이유로 인해 이 데이터에서만 얻을 수 있는 시그널이 있기 때문에 데이터셋을 split해서 학습에 활용했습니다. 그리고 실제로 모델을 학습시켰을 때, 이 데이터를 활용해야 앞서 언급된 다른 대안들보다 우리의 오프라인 평가 지표상 가장 좋은 성능을 얻을 수 있다는 것이 확연히 드러났습니다.
최종적으로, 주어진 비즈니스 문제를 같은 아이템 내에서 전환율이 더 높은 속성이 무엇인지를 score 차이로 모델링하는 ML 문제로 치환할 수 있었습니다.
\[p(\bar C_1 > \bar C_2 | A_1, A_2, I_1=I_2) \approx \sigma(f_\theta(A_1) - f_\theta(A_2))\]또한 주어진 데이터를 활용하여 모델을 다음과 같이 학습할 수 있습니다.
- Pairwise 데이터셋 구성
- 한 아이템 당 N개의 속성이 있을 때, \(\binom{N}{2}\)개의 속성 pair를 생성합니다.
- 각 쌍에서 실제 관찰된 전환율이 더 높은 속성을 first attribute로, 낮은 속성을 second attribute로 라벨링합니다.
- Score 차이 계산
- 모델은 각 속성 \(A_k\)와 item feature를 입력으로 받아 \(score\ s_k =f_\theta(A_k)\)를 예측합니다.
- 두 속성의 score 차이 \(s_i - s_j\) (first - second)를 구해, 위의 확률 모델 \(\sigma(s_i - s_j)\)를 계산합니다.
- 쌍을 정의할 때 항상 first attribute의 전환율이 더 높도록 하였기 때문에 log를 취해 부호를 변환하면 negative log likelihood이 되고, 이를 loss function으로 삼아 모델을 학습합니다.
위처럼 pairwise로 구성된 데이터셋 위에서 Ranking Loss를 최소화하도록 모델을 학습시킴으로써, “어떤 속성이 다른 속성보다 더 높은 전환율을 보일 수 있을지”를 예측하는 모델을 확보할 수 있습니다.
오프라인 평가방법 구체화
Naive한 평가 metric들과 이슈들
평가용으로 attribute shuffle 데이터의 held-out set (unseen 아이템)을 두고, 각 속성에 대한 전환율을 계산할 수 있습니다. 이 때 우리의 모델은 같은 아이템의 속성들 중 전환율이 높은 속성을 더 상위에 배치할 수 있어야합니다. 이를 평가하기 위해 초기에 구상한 메트릭은 다음과 같습니다:
- Mean Spearman’s rank correlation coefficient (이하 mean SRCC): 아이템의 속성이 n개 있을 때, 각 속성의 관찰된 전환율 순위와 모델이 랭킹한 순위의 Spearman’s rank correlation coefficient로 일치율을 구할 수 있습니다. 이는 순위 값으로 계산한 Pearson correlation coefficient와 같습니다. 아이템마다 구한 값을 모든 아이템에 대해서 평균 낸 값을 평가지표로 활용할 수 있습니다.
- Top-1 accuracy: 아이템의 속성 중 가장 높은 전환율을 가지는 속성을 예측하는 태스크로 보면, 각 아이템마다 정답/오답 여부를 따질 수 있습니다. 이를 통해 계산한 accuracy를 평가지표로 활용할 수 있습니다.
위 메트릭들은 언뜻 보기에는 문제가 없어보이지만, 비즈니스 임팩트를 가늠하거나 기준치를 설정하기가 어렵다는 이슈가 있습니다. 만약 완전히 랜덤하게 score를 할당하는 모델이 있다면, mean SRCC = 0.0, top-1 acc = 1/n이 나올 것입니다. 따라서 최소한 이 값을 넘기는 것을 일종의 sanity check으로 삼을 수 있습니다. 그렇다면 optimal한 모델이 있다고 하면 mean SRCC = 1.0, top-1 acc = 1.0이 나올까요? 후술할 이유로 인해서 그렇지 않습니다.
이슈: observed CR에 내재된 noise
만약 어떤 속성이 랜덤한 유저에게 노출되었을 때 전환율의 참값(이론적 확률값)이 \(p\)라고 해보겠습니다. 만약 attribute shuffle 데이터상으로 \(n\)개의 관찰을 통해 전환율을 계산했다면, 그 값은 \(p\)가 아니라 \(p\)에 대한 noisy estimate입니다. 여기서 특히 주의해야할 점은, \(n\) = 100 이라고해서 \(p\)를 1%p 단위로 알 수 있는 것이 아니고 불확실성이 훨씬 크다는 것입니다.
Observed CR을 \(C̄\)라고 하면, 다음 분포를 따르게 됩니다:
\[n \bar C \sim \textrm{Binomial}(n,p)\]여기서 \(p\)에 대한 noisy estimate으로서의 \(\bar C\)는 다음과 같은 오차 스케일을 가집니다.
\[\bar C = p+\epsilon\] \[\sigma_\epsilon = \sqrt{p(1-p)/n}\]전환율의 참값이 0.1인 속성에 대해 랜덤한 100개의 관찰을 통해 계산한 observed CR의 분포를 구하면 다음과 같습니다:
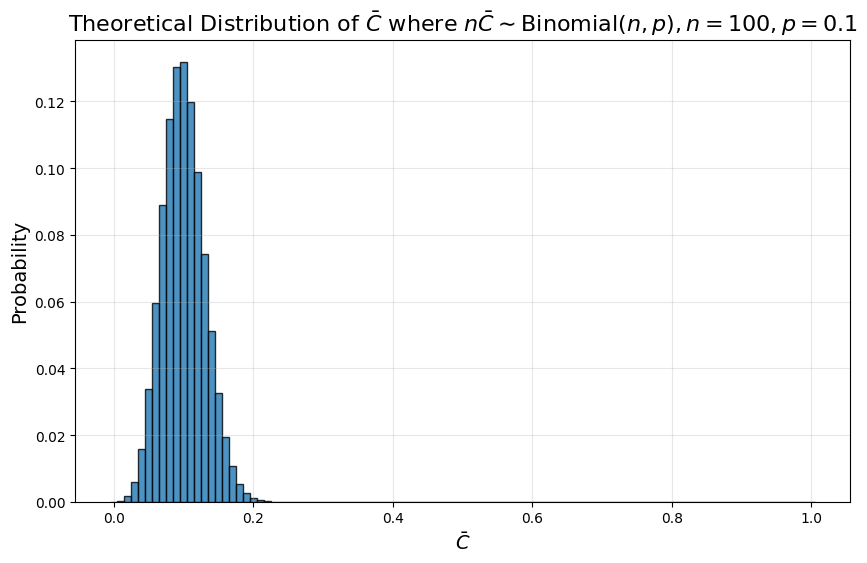
보시다시피 실제값인 0.1을 중심으로 나타나는 오차 스케일이 0.01보다 훨씬 크다는 것을 확인할 수 있습니다.
이슈: 전환율 차이의 스케일이 반영되지 않는다
한편, observed 전환율이 noisy estimate이라는 것 이외에도 위 메트릭들이 비즈니스 임팩트를 가늠하기 어려운 이유가 또 있습니다. 만약 아이템 A에 대한 속성들의 전환율이 0.1%p 스케일로 갈리고, 아이템 B가 1%p 스케일로 갈리는 상황이라면, A보다는 B의 랭킹 성능에 집중하는 것이 비즈니스 임팩트 측면에서 더 이득입니다. 하지만 mean SRCC와 top-1 acc 지표는 A와 B를 동등하게 취급하기 때문에, 전환율 차이가 거의 없는 속성들을 랭킹하는 성능에 불필요하게 많은 가중치를 실어주게 됩니다.
Mean SRCC와 top-1 acc 지표는 모델 간의 상대적 비교 용도로는 써볼 수 있지만, 위 이슈들로 인해 ‘이 모델을 적용하는것이 AS-IS 대비 이득인지’ 가늠하기는 매우 어렵습니다. 그렇다면 비즈니스 임팩트를 가늠할 수 있는 지표를 어떻게 설계할 수 있는지 살펴보겠습니다.
새 평가 메트릭 구축: relative mean conversion-rate lift
모델에 대해 정말 알고싶은 것이 무엇인지 원점으로 돌아가서 생각해보면, 기존에 사람이 설정한 대표 속성 대비 모델로 대표 속성을 선택해줬을 때 전환율이 오를지, 오른다면 얼마나 오를지입니다. 만약 온라인 A/B 테스팅을 진행한다면 다음과 같이 설계할 수 있습니다:
- 아이템들을 랜덤하게 대조군/실험군으로 나눠서 할당합니다.
- 아이템의 속성들을 유저에게 노출시킬 때, 대조군은 사람이 설정한 대표속성으로, 실험군은 모델이 고른 대표속성으로 노출시킵니다
- 시간이 지난 후 대조군/실험군 아이템들의 전환율을 비교하여 전환율에 대한 lift를 계산합니다.
아이템들 간 간접적인 interaction을 무시할 수 있다고 보면, 온라인 A/B 테스팅은 비즈니스 임팩트를 평가하기위한 가장 확실한 방법입니다.
한편, 온라인 실험에도 다음과 같은 문제들이 남아있습니다:
- 온라인 실험은 실제 유저 경험에 영향을 주는 것이기 때문에 유저 경험을 해칠 가능성이 있는 기능을 함부로 실험군으로 할당할 수 없습니다.
- 유의미한 비교가 이루어지려면 실험 기간이 확보되어야하기 때문에, 모델을 평가하고 개선하는 iteration이 느립니다.
- 또한 모델을 서빙하고 기능을 배포하기 위한 시스템을 구축하는 공수가 들기 때문에, 모델이 도움이 된다는 근거가 없는 상황에서 인력을 투입하는 것도 곤란합니다.
위 이유들로 인해 온라인 실험 전에 사용할 수 있는 오프라인 평가 메트릭이 필요합니다.
운이 좋게도 attribute shuffle 데이터가 있기 때문에, 위에서 언급한 온라인 A/B 테스트의 결과를 오프라인에서 시뮬레이션 할 수 있습니다. 학습에 사용되지 않은 unseen 아이템들로 구성된 held-out attribute shuffle 데이터를 이용해서, 유저가 고른 속성들의 전환율과 모델이 고른 속성들의 전환율을 계산해서 비교하는 방법입니다. 유저 선택 대비 모델 선택의 상대값을 구하면 relative mean CR lift를 구할 수 있습니다.
만약 relative CR lift가 +5%라면, 모델을 배포했을 때 전환율이 +5% 상승할 것으로 예상된다는 의미이므로 비즈니스 지표상의 임팩트를 직접 가늠할 수 있다는 장점이 있습니다. Relative CR lift가 양수 값으로 나온다는 것은 모델을 배포하는 것이 이득이라는 의미이고, 이는 앞서 언급했던 random baseline보다 더 강력한 기준점입니다. 유저 선택이 random 선택보다 나을 가능성이 높기 때문에, random baseline의 relative CR lift는 음수 값으로 나오기 때문입니다. 이는 attribute shuffle을 적용했을 때의 exploration cost라고도 해석할 수 있습니다.
한가지 주의해야할 포인트는 각 아이템별 개별 CR lift가 아니라 많은 아이템에 대한 평균 CR lift를 계산해야 비로소 의미가 있다는 것입니다. 각 아이템의 개별 CR lift는 앞서 언급한 내재된 noise가 고스란히 포함되어있기 때문에, 실제로는 전환율을 변화시키지 않는 선택을 하더라도 CR lift가 양수와 음수값으로 랜덤하게 나타나게 됩니다. 많은 아이템에 대해서 평균냈을 때 비로소 이 랜덤한 노이즈들도 같이 평균되면서 오차의 스케일이 실제 전환율 변화보다 작아져서 유의미한 지표가 됩니다.
물론 이 오프라인 지표가 온라인 실험을 완전히 대체할 수 있는 것은 결코 아닙니다. 노이즈를 억제하기 위해 충분히 많은 아이템을 사용해야 한다는 전제 조건도 있지만, 학습과 평가 데이터셋이 같은 기간에 수집된 데이터셋에서 왔기 때문에 미래에 하는 실험에서 얼마나 잘 작동할지는 장담할 수 없습니다. 또한 실제로는 유저가 아이템을 보고 전환 행동을 하는 과정이 완전히 i.i.d가 아니고, 전체적인 전환 수에 대한 캐퍼시티를 두거나 전후 경험에 영향을 받는 등의 상관관계가 있을 수 있습니다. 따라서 우리의 CR lift 추정치는 실제 프로덕션 배포 시에 관찰하게 될 CR lift와 얼마든지 다를 수 있고, 온라인 실험 전에 확인할 수 있는 차선의 추정치라고 봐야 합니다.
Optimal 성능 가늠하기
이제 평가지표는 정의했지만, 이 지표가 어느정도 나와야 모델이 잘 학습된 건지에 대한 기준치가 있어야 학습이 제대로 돌고 있는지에 대한 감을 잡을 수 있습니다. 우선 최소한 CR lift가 0보다는 크게 나와야 적용하는 의미가 있으므로 0을 기준점으로 삼을 수 있습니다. 그렇다면 만약 최적의 속성을 골랐을 때 어느정도의 CR lift가 있을지 상방을 어떻게 추정할 수 있을까요?
각 아이템 별로 observed CR이 가장 큰 속성으로 전환율을 계산하는 것을 자연스럽게 떠올릴 수 있지만, 이렇게하면 observed 전환율에 내재된 노이즈가 ‘+’ 방향으로 큰 경우만 살아남기 때문에 평균을 내는 과정에서 노이즈가 상쇄되지 못하는 maximization bias가 아주 크게 발생하게 됩니다.
우리는 maximization bias를 억제하기 위해 다음과 같은 방법을 사용하였습니다:
- 각 속성별 conversion을 랜덤하게 두 그룹으로 쪼갭니다
- 한 그룹의 관찰치로 계산한 전환율로 각 아이템별 ’최선의 속성’을 뽑습니다
- ’최선의 속성’에 대응되는 전환율을 다른 쪽 그룹의 관찰치로 계산해서 모든 아이템에 대해 평균냅니다
이는 RL 분야에서 maximization bias를 해결하기 위해 사용하는 Double DQN과 같은 아이디어를 적용했다고 볼 수 있습니다.
한편, observed CR으로 최선의 속성을 뽑을 때 이미 노이즈가 있기 때문에 뽑은 속성은 optimal 속성이 아닐 수 있습니다. 따라서 위 과정을 통해 계산한 mean CR lift는 엄밀히 말해 ’optimal 성능’이 아니라 ’optimal 성능의 lowerbound’라고 봐야합니다. 그래도 성능을 더 올릴 여지가 있는지 판단하기 위한 기준치로서는 충분히 사용할 수 있었습니다.
Offline 실험 결과 & 온라인 배포 결과
실제 해당 사례에서는 지금까지 설명한 과정을 모두 거쳐 모델을 학습했고, 오프라인 평가 메트릭인 mean CR lift에서 기존의 여러 비교 방법론과 비교해 가장 좋은 성과를 얻을 수 있었습니다. 이 결과는 위에서 가늠한 optimal 성능의 lower bound와 유사한 수준이었습니다. 오프라인 평가 이후에는 실제 유저를 대상으로 대규모 온라인 A/B 테스트를 진행했고, 이를 통해 프로덕션 환경에서도 의미 있는 mean CR lift가 나타나는 것을 확인할 수 있었습니다. 또한, 해당 기능에서 달성하고자 했던 핵심 지표 역시 유의미하게 개선되는 것을 확인하며, 전체 배포도 성공적으로 완료할 수 있었습니다.
마치며
이번 포스트에서는 하이퍼커넥트에서 문제가 주어졌을 때 실제 ML 문제로 정의하기 위한 과정을 소개하였습니다.
모델의 배포가 실제 비즈니스 임팩트로 이어지도록 하기위해, 데이터가 수집된 환경의 통계적인 특성을 고려하여 item-wise ranking이라는 학습 objective를 설계하였습니다. 이 과정에서 confounder의 영향을 최대한 배제하여 인과관계를 학습하기 위해 랜덤하게 수집된 데이터를 활용했습니다. 또한 기능을 처음 개발하는 단계라 베이스라인이 없는 상황에서도 모델의 성능수준을 가늠하기 위해, 비즈니스 임팩트와 직접 연결된 mean CR lift라는 평가 지표를 도입해 모델 성능을 가늠할 수 있었습니다. 마지막으로 오프라인 평가를 거쳐 실제 서비스 환경에서도 유의미한 전환율 상승을 달성했습니다.
하이퍼커넥트 AI는 비즈니스 임팩트를 최적화하는 문제 정의부터, 학습 및 평가 지표까지 꼼꼼히 설계하며 실질적인 임팩트를 창출하는 솔루션을 만들어가고 있습니다. 실제 임팩트를 내기 위한 솔루션을 같이 만들어나가실 분들의 많은 지원을 기다립니다.