Building Resilient, High Performance ScyllaDB Clusters with Super Disk
안녕하세요, SRE - Database Platform Unit(DBP)의 stewart입니다.
Hyperconnect는 전사 NoSQL 데이터베이스로 ScyllaDB를 약 4년 동안 운영하며, ML feature store[2] 등 전사의 매우 다양한 서비스의 고성능 요구사항을 충족해왔습니다. 하지만 최근 장애 모의 훈련에서 cluster rolling update 시 node 복구 시간이 지나치게 길다는 문제를 발견했습니다. 본 글에서는 이 문제를 해결하기 위해 도입한 Super Disk (Write-mostly RAID) 기능이 어떻게 cluster rolling update 시간을 기존 대비 최대 10배 이상 단축시켰으며 , 성능상에는 어떤 차이가 있는지, 이러한 결론을 바탕으로 해당 기능을 Kubernetes 환경에서 더욱 효율적으로 관리하기 위해 도입한 Windmill 기반 자동화 과정까지 단계별로 소개합니다.
1. ScyllaDB 란?
먼저 DBP에서 전사 NoSQL DB로 사용하고 있는 ScyllaDB에 대해 소개하려고 합니다. ScyllaDB는 Cassandra와 호환되는 wide-column Database로, 다음과 같은 특징과 장점을 지닙니다.
-
Cassandra Compatible
기존 Cassandra의 데이터 모델과 쿼리 방식을 그대로 호환하며, 내부적으로 C++와 Seastar 프레임워크를 사용해 자원을 효율적으로 관리합니다. 이를 통해 높은 성능과 낮은 지연시간을 제공합니다.
-
Far less infrastructure
ScyllaDB는 Cassandra 대비 훨씬 효율적으로 동작해 cluster 크기를 크게 축소할 수 있습니다. Comcast나 Discord 같은 기업은 ScyllaDB로 마이그레이션 후 Cassandra cluster를 최대 10분의 1로 줄여 비용 절감과 향상된 ROI를 달성했습니다.[3]
-
Low latency, high throughput
공식 Benchmark 자료에 따르면, 동일한 3-Node cluster에서 ScyllaDB(Open Source 4.4 버전)는 Cassandra(4.0 버전) 대비 2~3배 높은 처리량(throughput)을 보이며, p90, p99 지연시간 또한 10ms 미만으로 유지합니다.[4]
Discord, Zillow 등 여러 글로벌 기업이 ScyllaDB를 활용해 성공 사례를 공유하고 있으며, Hyperconnect 또한 지난 4년 동안 Production 환경에서 안정적으로 운영하고 있습니다.
2. 문제 상황: ScyllaDB node 장애 시 node 롤링 시간이 너무 느리다!
최근 SRE 팀에서 진행한 장애 모의 훈련[5]에서는 ScyllaDB node 장애 상황도 함께 테스트했습니다.
테스트에서는 ScyllaDB가 운영 중인 EC2 인스턴스를 강제로 종료한 후 복구 시간을 측정하였으며, disk 용량에 따라 평균 3~4시간, 데이터 양이 많은 경우에는 최대 12시간 정도 소요되는 것으로 나타났습니다.
이 경우, 일반적인 read/write 성능에는 문제가 없지만, 여러 node가 동시에 장애가 발생하면 cluster 전체 복구에 상당한 지연이 발생합니다. 이는 ScyllaDB가 Local SSD 타입 인스턴스(i4i)를 사용해야 하기 때문입니다.
Cassandra와 달리 ScyllaDB는 Local NVMe SSD 사용을 권장[6]]하는데, 이는 ScyllaDB가 Cassandra와는 전혀 다른 caching 및 disk I/O 전략을 사용하기 때문입니다. 이 전략을 제대로 이해하려면 먼저 ScyllaDB의 caching 방식에 대해 알아볼 필요가 있습니다.
ScyllaDB 의 WhitePaper 7 Reasons Not to Put an External Cache in Front of Your Database를 참고해 보면, ScyllaDB의 Embedded Cache 설계에 대해 상세하게 알 수 있습니다.
-
Cassandra의 Cache 접근 방식
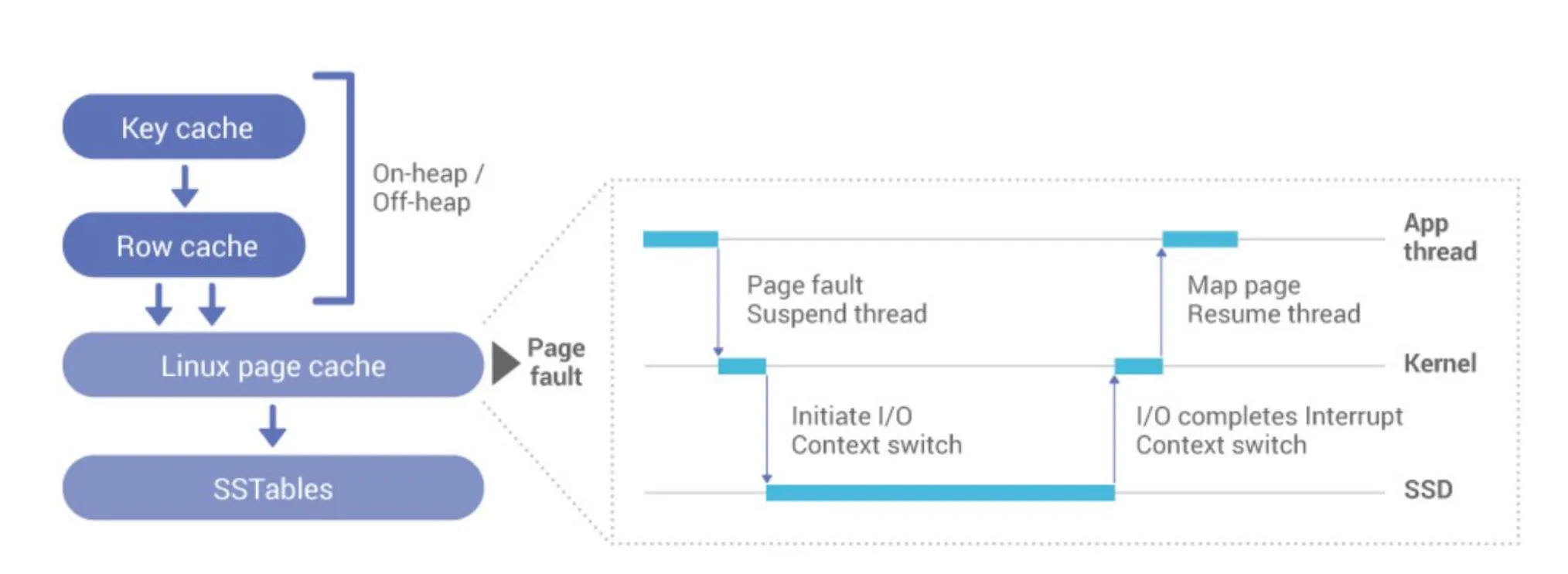
- Cassandra는 OS 차원의 Linux page cache와 자체 key cache, row cache 등을 함께 사용합니다.
- Cassandra의 경우, DB Admin이 각 cache 메모리 크기(JVM heap/off-heap 포함)를 세밀히 조정해야 하며 워크로드가 동적으로 변할 때마다 지속적인 튜닝이 필요합니다.
- 또한 page cache를 사용할 경우, Linux page cache가 4KB 단위로 동작하기에, 4KB 미만의 데이터가 많은 NoSQL 워크로드에서는 read amplification(읽기 증폭)이 발생할 수 있습니다.
-
ScyllaDB의 Embedded Cache
- Linux page cache 대신 내부적으로 cache를 일원화해 관리합니다.
- 객체 단위로 caching하고, memtable, compaction, cache controller 등 여러 컨트롤러가 동적으로 cache 크기를 조정합니다.
- cache 미스 시 DMA로 disk에서 데이터를 비동기로 읽어오고, Seastar 프레임워크로 컨텍스트 스위치 오버헤드를 최소화합니다.
- 운영자는 cache 크기를 수동으로 분배할 필요가 없으며, ScyllaDB가 자동 최적화를 수행하므로 관리 부담이 크게 줄어듭니다.
하지만 이렇게 Embedded Cache를 사용하면, Cache miss 시 disk I/O가 병목이 될 수 있습니다.
Cassandra처럼 Linux page cache에 크게 의존하는 구조였다면, Local SSD가 아니라도 page cache가 어느 정도 성능을 방어해 줄 수 있습니다. 그러나 ScyllaDB는 cache를 자체적으로 관리하고, 성능이 disk 속도에 직접적으로 좌우되므로, NVMe SSD의 빠른 접근 성능이 훨씬 중요해집니다.
그렇기에 현재 Hyperconnect에서는 AWS가 제공하는 i4i.4xlarge(Local NVMe disk 내장) instance를 이용해 ScyllaDB를 운영 중입니다. 그러나 클라우드 환경에서 Local NVMe가 붙은 instance를 사용할 경우, instance를 재부팅하면 disk 데이터가 전부 유실된다는 문제가 존재합니다.
물론 ScyllaDB의 다양한 HA 설정(Replication Factor, Cross-DC 설정, Consistency level 등)을 통해 node가 다운되더라도 데이터 유실은 방지할 수 있습니다. 하지만 node를 복구할 때, 다른 node에서 모든 데이터를 가져와야 하므로 복구 시간이 너무 길어지는 단점이 있습니다.
또한 일반적인 EC2 유지보수를 위해 Node를 재부팅하거나 AMI를 변경하는 작업에도 상당한 시간이 소요됩니다. 현재 운영 환경에서는 i4i.4xlarge(3.5TB) node 한 대를 교체하는 데 약 18~24시간이 걸려, 평소 유지보수 작업 시간도 크게 늘어나는 단점이 있습니다.
2.1 새로운 대안: ScyllaDB Super-disk
이러한 문제 해결을 위해 조사하던 중, Discord에서 작성한 How Discord Supercharges Network Disks for Extreme Low Latency을 접하게 되었습니다.
해당 글을 요약하면, Discord는 ScyllaDB를 운영할 때 Persistent Disk 기반 환경에서 Read latency 지연 문제를 겪었다고 합니다. 이후 Local SSD로 옮기려 했으나, 같은 문제(instance 재부팅 시 데이터 유실)를 확인했고, 이를 해결하기 위해 글 작성자들이 Super Disk 구성을 적용했습니다.
해당 구성은 Local SSD와 Persistent Disk를 RAID 할 뿐 아니라, 추가로 Write-mostly라는 RAID 설정을 통해 Persistent Disk로는 쓰기, Local SSD에서만 읽기를 수행하도록 구성해 읽기 지연을 크게 줄였다는 것이 골자입니다.
저희는 이 아이디어에 착안해 영속성과 latency를 둘 다 챙길 수 있는 Super Disk를 적용할 수 있을지 본격적으로 검토를 시작했습니다.
2.2 PoC 시작: ScyllaDB Super-disk
테스트 환경을 위해 같은 스펙(i4i.4xlarge)의 node로 구성된 cluster를 두 개 띄운 뒤, 하나는 Super Disk를 적용하지 않고, 다른 하나에는 Super Disk 설정을 적용해 비교 테스트를 진행했습니다.
사용한 Node spec 및 cluster 설정은 다음과 같습니다.
| Instance | pod CPU | pod memory | scylla embeded memory size | Scylladb version |
|---|---|---|---|---|
| i4i.4xlarge | 14 | 110Gi | 100G |
5.4.9 |
먼저 ScyllaDB를 배포하기 전에 EBS를 provisioning 하고, 해당 EBS를 instance에 attach 한 뒤 RAID를 구성했습니다. EBS 용량은 i4i.4xlarge 의 Nvme Disk와 유사하게 3.4TB 정도를 설정했습니다. (3492GB)
이후, EBS를 mount 한 instance 에서 다음과 같이 RAID를 생성했습니다.
## 새 RAID 생성 (데이터가 없어야 함)
yes | sudo mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/nvme1n1 --write-mostly /dev/nvme2n1 --assume-clean
mkfs -t xfs /dev/md0
mount /dev/md0 /data
## RAID 상태 확인
cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 nvme1n1[2] nvme2n1[0](W)
3661496320 blocks super 1.2 [2/2] [UU]
bitmap: 5/28 pages [20KB], 65536KB chunk
## 마운트 상태
lsblk -b -o NAME,SIZE,TYPE
NAME SIZE TYPE
nvme0n1 162135015424 disk
├─nvme0n1p1 162132901376 part
└─nvme0n1p128 1048576 part
nvme1n1 3750000000000 disk
└─md0 3749372231680 raid1
nvme2n1 3749506449408 disk
└─md0 3749372231680 raid1
이후 ScyllaDB를 배포한 후, 사내에서 Database benchmark을 수행할 때 사용하는 YCSB benchmark tool을 이용해 총 7억 Row (약 node 당 1.5TB)의 데이터를 삽입했습니다. 그런 다음 장애 상황에서 Super Disk가 적용된 cluster가 어떻게 동작하는지 확인했습니다.
2.3 장애 상황 시나리오 테스트
- EBS Detach 시나리오
- EBS 장애 가정: EBS를 AWS 콘솔에서 force detach를 실행합니다.
-
RAID stat 확인: RAID 상태는 degraded 상태로 Local SSD만 남았지만,
_u디바이스 상태로 read/write 정상 수행 가능하였습니다.[stewart-hpcnt ~]$ cat /proc/mdstat Personalities : [raid1] md0 : active raid1 nvme1n1[2] 3659399168 blocks super 1.2 [2/1] [_U] bitmap: 9/28 pages [36KB], 65536KB chunk- ScyllaDB 상태(metric, log 포함)를 확인해도 문제 없이 동작하였습니다.
- i4i instance 자체 장애 시나리오
- i4i instance를 강제로 종료하여 서비스 및 Disk 복구 시나리오를 테스트 하였습니다.
- 우선 console에서 강제로 instance를 종료시켜, node down 상태로 만듭니다.
-
이후, 새 instance에 EBS를 attach한 후 RAID 재구성을 trigger하고, 얼마나 걸리는지 측정하였습니다.
sudo mdadm --zero-superblock --force /dev/nvme2n1 # 이후 instance 에 volume 을 detach 한 다음에, 다시 attatch # RAID 재구성 진행 sudo mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 --write-mostly /dev/nvme3n2 missing sudo mdadm --add /dev/md0 /dev/nvme1n1 cat /proc/mdstat Personalities : [raid1] md0 : active raid1 nvme1n1[2] nvme3n2[0](W) 3659399168 blocks super 1.2 [2/1] [U_] [>....................] recovery = 0.0% (1602048/3659399168) finish=304.4min speed=200256K/sec bitmap: 0/28 pages [0KB], 65536KB chunk md127 : inactive nvme2n1[0](S) 3659399168 blocks super 1.2 mkfs -t xfs /dev/md0 mount /dev/md0 /data # /data directory 로 들어가보면, scylladb 가 사용하는 /data directory 의 데이터가 있는것을 확인할 수 있다.
-
RAID가 재구성(복구)되는 데 약 1시간이 소요되었으며, 복구가 끝난 뒤 ScyllaDB 서비스를 재시작하면 정상적으로 cluster에 합류되는 것을 확인하였습니다. 이때 다음과 같은 token range change log를 확인할 수 있습니다.
- INFO [shard 0:goss] storage_service - handle_state_normal: Nodes {new-node} and {old-node} have the same token -4597663134675918828. {new-node} is the new owner - INFO [shard 0:goss] storage_service - handle_state_normal: remove endpoint={old-node} token=3541728657769624357 - RAID 복구 중에는 EBS 및 Local SSD disk 자원을 모두 사용하는것을 확인하였습니다. 따라서 RAID 복구가 끝난 뒤 ScyllaDB 서비스를 시작하는 것을 권장합니다.
- 정말 긴급한 상황이라 빠르게 복구해야 할 경우, RAID 복구 전 단계에서 EBS만 Mount 한 뒤, 서비스를 시작해도 무방합니다. 이 경우 Local SSD가 아닌 EBS로만 읽기/쓰기를 하기 때문에 성능 저하가 있을 수 있으나, 빠른 서비스 복구에는 도움이 됩니다.
- i4i instance를 강제로 종료하여 서비스 및 Disk 복구 시나리오를 테스트 하였습니다.
이 실험으로 확인한 것은, EBS가 장애 나거나 i4i instance가 장애를 일으켜도 데이터 유지 및 빠른 복구가 가능하다는 점입니다.
최악의 상황으로, 만약 두 disk 전부 문제가 생긴다고 해도, 기존에 사용했던 방식대로 ScyllaDB의 nodetool replace 명령을 통해 다른 Node의 데이터를 복사해와 해당 Node의 데이터를 복구하는 것도 가능합니다.
하지만 가장 중요한 성능(throughput/latency) 차이는 어떨까요? 다음 항목에서 성능 Benchmark 결과를 살펴봅니다.
2.4 Performance Benchmark
초기 Data Load 시 사용했던 tool 인 YCSB를 이용해 실제 Production과 유사한 read/write/update 비율로 Benchmark를 진행했습니다.
| params | value |
|---|---|
recordcount |
700000000 |
operationcount |
800000000 |
readproportion |
70% |
insertproportion |
20% |
updateproportion |
10% |
threadcount |
50 |
scylla.connection.pool.local.size |
1 |
scylla.connection.max-requests |
1024 |
consistencyLevel |
LOCAL_QUORUM |
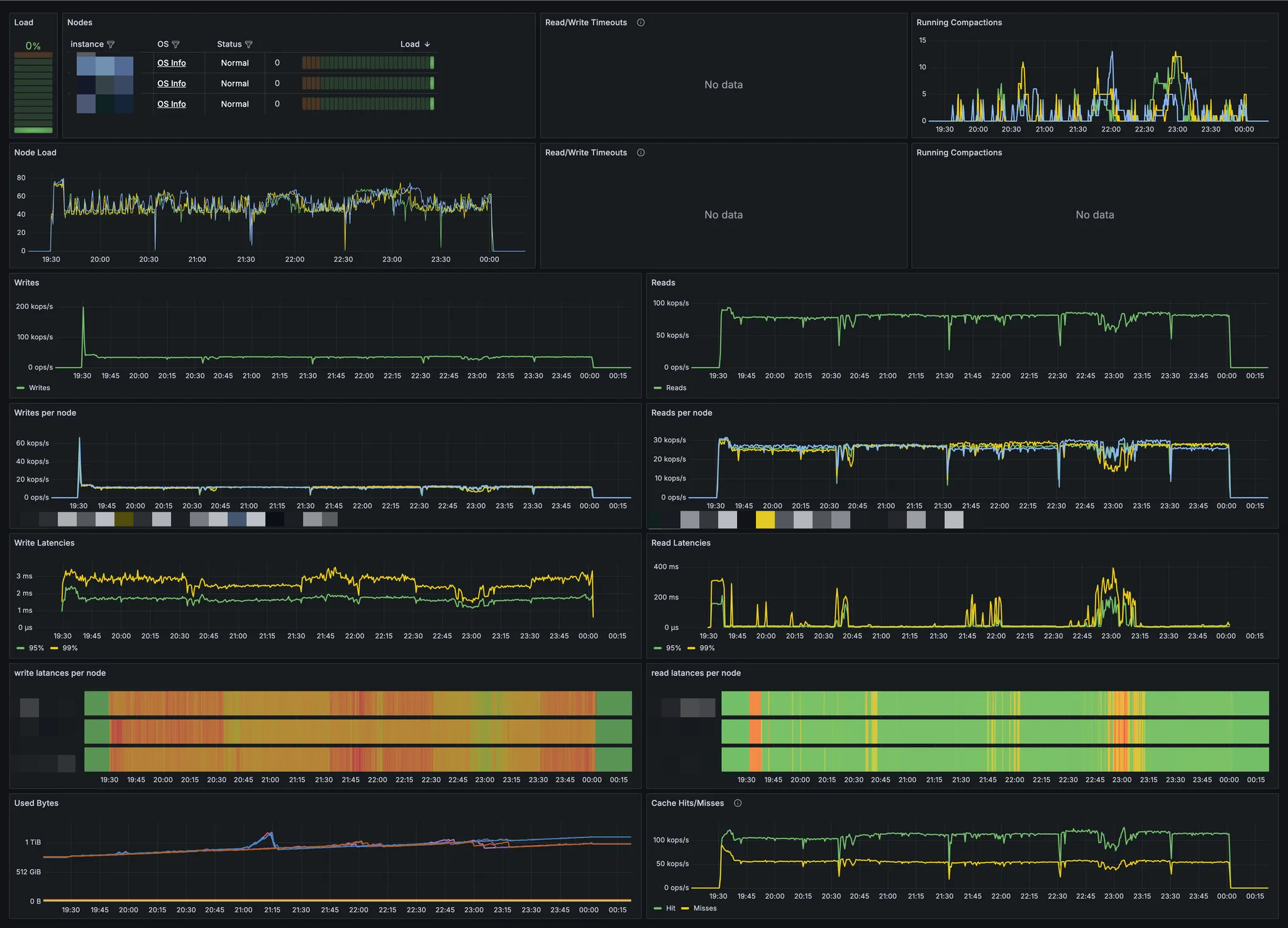
RAID를 적용하지 않은 i4i instance의 성능 벤치마크 결과
RAID를 적용한 i4i instance의 성능 벤치마크 결과
실제로 metric을 확인해 보니, Super Disk를 구성한 cluster와 그렇지 않은 cluster 간 성능 차이가 거의 없었습니다.
compaction 타이밍에 따라 Read latency가 일시적으로 튈 때가 있지만, 전반적인 throughput과 Write latency 모두 크게 차이가 없음을 확인했습니다. 기타 다른 워크로드 시나리오를 돌려 봐도, Super Disk 구성 여부에 따른 성능 차이는 미미했습니다.
추가적으로, Benchmark 결과 교차 검증을 위해, ScyllaDB에서 제공하는 ScyllaDB/Cassandra 를 benchmark 를 할 때 사용하는 tool 인 Latte 을 이용해, 다양한 상황에도 local ssd instance 와, raid 된 ScyllaDB 의 latency 가 비슷한지 측정을 진행하였습니다.
ScyllaDB latte 는 Rust 로 작성되었으며, benchmark 설정 테스트를 직접 custom 하게 write 할 수 있어 다양한 Case 에 대해 benchmark test 를 수행할 수 있습니다.
Benchmark 설정은 이번에 ScyllaDB 에서 주최한 ScyllaDB Monster Scale Summit[6] 에 소개된 ScyllaDB is No Longer “Just a Faster Cassandra” session을 참조하여, benchmark workload[7] 를 작성하여 직접 테스트했습니다.
| params | value |
|---|---|
| row_count | 100000000 |
| cache_rows | 10000000 |
| Rate | 200000 |
| standard1_insert | 4% |
| standard1_insert_cache | 16% |
| standard1_select | 16% |
| standard1_select_cache | 64% |
해당 workload 시나리오 후, 동일한 환경에서 Super Disk가 적용되지 않은 cluster와 Super Disk가 적용된 cluster를 각각 Benchmark한 결과, 다음과 같은 결과가 도출되었습니다.
i4i.4xlarge wih no raid - benchmark results
SUMMARY STATS ══════════════════════════════════════════════════════════════════════════════════════════════════════════════
Elapsed time [s] 1800.010
CPU time [s] 17936.141
CPU utilisation [%] 33.2
Cycles [op] 359999850
Errors [op] 0
└─ [%] 0.0
Requests [req] 359999850
└─ [req/op] 1.0
Retries [ret] 0
└─ [ret/req] 0.00000
Rows [row] 104598453
└─ [row/req] 0.3
Concurrency [req] 14 ± 0
└─ [%] 84
Throughput [op/s] 199999 ± 229
├─ [req/s] 199999 ± 229
└─ [row/s] 58110 ± 66
Cycle latency [ms] 6.677 ± 14.502
Request latency [ms] 1.118 ± 0.000
CYCLE LATENCY for standard1_select_cache [ms] ═════════════════════════════════════════════════════════════════════════════
Min 0.662 ± 0.103
25 1.046 ± 0.089
50 1.180 ± 0.093
75 1.372 ± 0.178
90 1.719 ± 0.888
95 2.599 ± 60.779
98 12.829 ± 521.082
99 257.032 ± 679.258
99.9 511.967 ± 668.300
99.99 536.347 ± 668.300
Max 553.648 ± 668.300
CYCLE LATENCY for standard1_insert [ms] ═══════════════════════════════════════════════════════════════════════════════════
Min 0.703 ± 0.081
25 1.048 ± 0.052
50 1.174 ± 0.068
75 1.351 ± 0.100
90 1.628 ± 0.444
95 2.587 ± 2.974
98 12.665 ± 368.587
99 256.770 ± 552.164
99.9 511.705 ± 472.421
99.99 536.084 ± 472.421
Max 553.124 ± 472.421
CYCLE LATENCY for standard1_insert_cache [ms] ═════════════════════════════════════════════════════════════════════════════
Min 0.708 ± 0.108
25 1.048 ± 0.067
50 1.174 ± 0.093
75 1.350 ± 0.148
90 1.628 ± 1.064
95 2.587 ± 59.545
98 12.763 ± 498.869
99 257.294 ± 648.260
99.9 511.705 ± 655.849
99.99 536.347 ± 655.849
Max 554.172 ± 655.849
CYCLE LATENCY for standard1_select [ms] ═══════════════════════════════════════════════════════════════════════════════════
Min 0.672 ± 0.106
25 1.036 ± 0.068
50 1.169 ± 0.090
75 1.362 ± 0.184
90 1.709 ± 1.011
95 2.593 ± 43.601
98 12.747 ± 506.751
99 256.770 ± 629.359
99.9 511.705 ± 559.417
99.99 536.347 ± 559.417
Max 552.600 ± 559.417i4i.4xlarge wih EBS raid - benchmark results
SUMMARY STATS ══════════════════════════════════════════════════════════════════════════════════════════════════════════════
Elapsed time [s] 1800.011
CPU time [s] 18014.552
CPU utilisation [%] 33.4
Cycles [op] 359999836
Errors [op] 0
└─ [%] 0.0
Requests [req] 359999836
└─ [req/op] 1.0
Retries [ret] 0
└─ [ret/req] 0.00000
Rows [row] 104598449
└─ [row/req] 0.3
Concurrency [req] 13 ± 0
└─ [%] 79
Throughput [op/s] 199999 ± 519
├─ [req/s] 199999 ± 519
└─ [row/s] 58110 ± 151
Cycle latency [ms] 11.578 ± 27.880
Request latency [ms] 1.029 ± 0.000
CYCLE LATENCY for standard1_select_cache [ms] ═════════════════════════════════════════════════════════════════════════════
Min 0.568 ± 0.131
25 0.960 ± 0.086
50 1.110 ± 0.124
75 1.326 ± 0.182
90 1.574 ± 0.334
95 1.794 ± 51.754
98 4.440 ± 322.745
99 273.154 ± 974.993
99.9 509.949 ± 984.576
99.99 571.815 ± 984.576
Max 589.641 ± 984.576
CYCLE LATENCY for standard1_select [ms] ═══════════════════════════════════════════════════════════════════════════════════
Min 0.572 ± 0.122
25 0.950 ± 0.069
50 1.099 ± 0.128
75 1.317 ± 0.181
90 1.566 ± 0.312
95 1.784 ± 57.992
98 4.420 ± 346.955
99 272.892 ± 997.156
99.9 509.949 ± 899.543
99.99 571.815 ± 899.543
Max 589.641 ± 899.543
CYCLE LATENCY for standard1_insert [ms] ═══════════════════════════════════════════════════════════════════════════════════
Min 0.614 ± 0.090
25 0.960 ± 0.068
50 1.104 ± 0.093
75 1.316 ± 0.146
90 1.551 ± 0.207
95 1.748 ± 1.830
98 4.420 ± 029.409
99 277.086 ± 521.071
99.9 510.998 ± 801.777
99.99 571.815 ± 801.777
Max 587.544 ± 801.777
CYCLE LATENCY for standard1_insert_cache [ms] ═════════════════════════════════════════════════════════════════════════════
Min 0.610 ± 0.100
25 0.959 ± 0.076
50 1.103 ± 0.104
75 1.315 ± 0.162
90 1.551 ± 0.254
95 1.748 ± 157.607
98 4.403 ± 200.208
99 271.843 ± 933.148
99.9 509.949 ± 954.778
99.99 571.815 ± 954.778
Max 587.544 ± 954.778ScyllaDB Latte를 활용한 벤치마크 결과, 현재 production workload 스펙 기준으로 RAID를 적용한 cluster와 적용하지 않은 cluster 간의 읽기/쓰기 속도 차이는 크지 않았습니다.
또한, 해당 benchmark 설정 외 다른 워크로드 시나리오를 적용해 본 결과, Super Disk 구성 여부에 따른 성능 차이도 미미한 것으로 나타났습니다.
이러한 실험을 통해, 다음과 같은 결론을 내렸습니다.
- 기존 i4i(Local SSD)만 사용하는 cluster 대비, RAID 기반 Super Disk 구성 시 latency와 throughput이 거의 동일합니다.
- Read 같은 경우, ScyllaDB cache or Local SSD 에서 읽기 때문에, 성능 저하가 일어나지 않습니다.
- write 같은 경우, ScyllaDB 의 Wide-column DB 특성 상 write 시 즉시 disk 에 쓰지 않기 때문에[8], write 성능이 저하되지 않습니다.
- node 장애 발생 시 복구 시간이 크게 단축됩니다.
- 기존에는 node가 장애 날 경우,
nodetool replace를 통해 다른 node에서 데이터를 전부 받아왔기 때문에, 1.8TB 기준 12시간~최대 24시간까지 걸리기도 합니다. - Super Disk 구성 시, RAID 재구성(1시간~ 1시간 반 소요) + hint write 시간이면 충분하므로 node 하나당 복구 시간을 2시간 이내로 단축 가능합니다.
- 만약 긴급한 복구가 필요할 시, RAID 복구를 기다리지 않고 EBS만으로 서비스를 빠르게 재개할 수도 있는 옵션도 확보하여, 장애 대응 전략의 유연성을 높였습니다.
- 기존에는 node가 장애 날 경우,
- Hyperconnect는 ScyllaDB를 Kubernetes 환경에서 운영하고 있어, 해당 방안의 장점이 더욱 컸습니다.
- EKS 버전을 업그레이드할 때 새 버전 AMI로 교체가 필요하고, 모든 node를 신규 AMI instance에 교체해줘야 합니다.
- 따라서 node 교체 때마다 데이터 이동·복구 작업을 하다 보니 총 작업 시간이 길고, Data Transfer 비용도 증가합니다.
- Super Disk 도입 후에는 RAID만 재구성하면 되므로 node 교체 작업을 훨씬 빨리 마무리할 수 있고, Data Transfer 비용 절감 효과도 있습니다.
이러한 결과들을 종합해 보면, RAID 기반 Super Disk 구성이 기존 i4i(Local SSD) 방식과 동일한 성능을 유지하면서도 장애 복구 시간을 단축하고 데이터 전송 비용을 줄일 수 있음이 명확해졌습니다.
이에 따라, 내부 검토를 거쳐 SRE 팀은 ScyllaDB에 Super Disk 기능을 도입하기로 최종 결정하였습니다.
3. Super Disk Migration 시작!
Super Disk 도입을 결정한 뒤 RAID 관련 작업을 자동화해야 했습니다. script 자체는 크게 복잡하지 않았지만, 이를 어디서 어떻게 실행할지가 문제였습니다.
- ScyllaDB를 Kubernetes 위에서 운영하고 있어, Kubernetes API, AWS boto3 API, ssh client, cassandra client 등 다양한 라이브러리를 사용해야 했습니다.
- 민감한 DB 접근 제어도 필요하므로, 이 script를 어느 환경에서 실행할지 고민이 필요했습니다.
저희는 이러한 요구사항을 DevOps 팀과 같이 논의했고, 최근 DevOps team 에서 전사 도입 중인 Windmill 라는 Developer Platform tool 을 이용하여 이 작업을 간소화했습니다.
Windmill은 “Developer platform for APIs, background jobs, workflows and UIs”를 표방하는 도구로,
Airflow, Retool, Scheduler의 장점을 결합한 자동화 지원 툴입니다.
- Python, Rust, Node.js 등 다양한 언어로 작성한 Job을 웹 UI 및 IDE에서 관리하고, 이를 간단히 테스트할 수 있습니다.
- 여러 Job을 Flow로 묶어 실행하고, UI와 결합해 배포까지 용이하게 처리할 수 있습니다.
- On-premise 형태로 사내 인프라에 직접 설치 가능해 보안 이슈에 대한 부담도 적습니다.
이러한 장점을 고려해, ScyllaDB node 교체 작업 자동화에 Windmill을 활용했습니다.
3.1 ScyllaDB Super Disk Workflow
ScyllaDB Super Disk를 적용하기 위해, 총 2가지의 workFlow 를 작성하였습니다.
- 초기 Migration workflow
-
우선 Super Disk를 적용하기 위해서, Super Disk가 적용된 ScyllaDB node 로 데이터를 migration 진행해야 합니다. 이때 새로운 ScyllaDB instance 들을 provisioning 하고, 이를 미리 provisioning 한 EBS 와 RAID 를 수행해야 하는데, 이를 자동화하여 새로운 ScyllaDB instance 에 RAID 를 수행하는 workflow 를 만들었습니다.

-
- EBS RAID 기반 ScyllaDB instance 교체 workflow
- EBS RAID 기반으로 Migration 이 완료되면, 정기적인 AMI 교체나 EKS 버전 업그레이드 시에 기존의 ScyllaDB 교체 방식(data 복사 방식)을 그대로 써서는 안 됩니다.
-
새 방식에 맞춰 node를 drain하고, RAID를 해제하고, EBS를 다른 instance에 attach하는 과정을 자동화해야 합니다. 따라서 이를 자동화 하는 workflow 를 생성하였습니다.
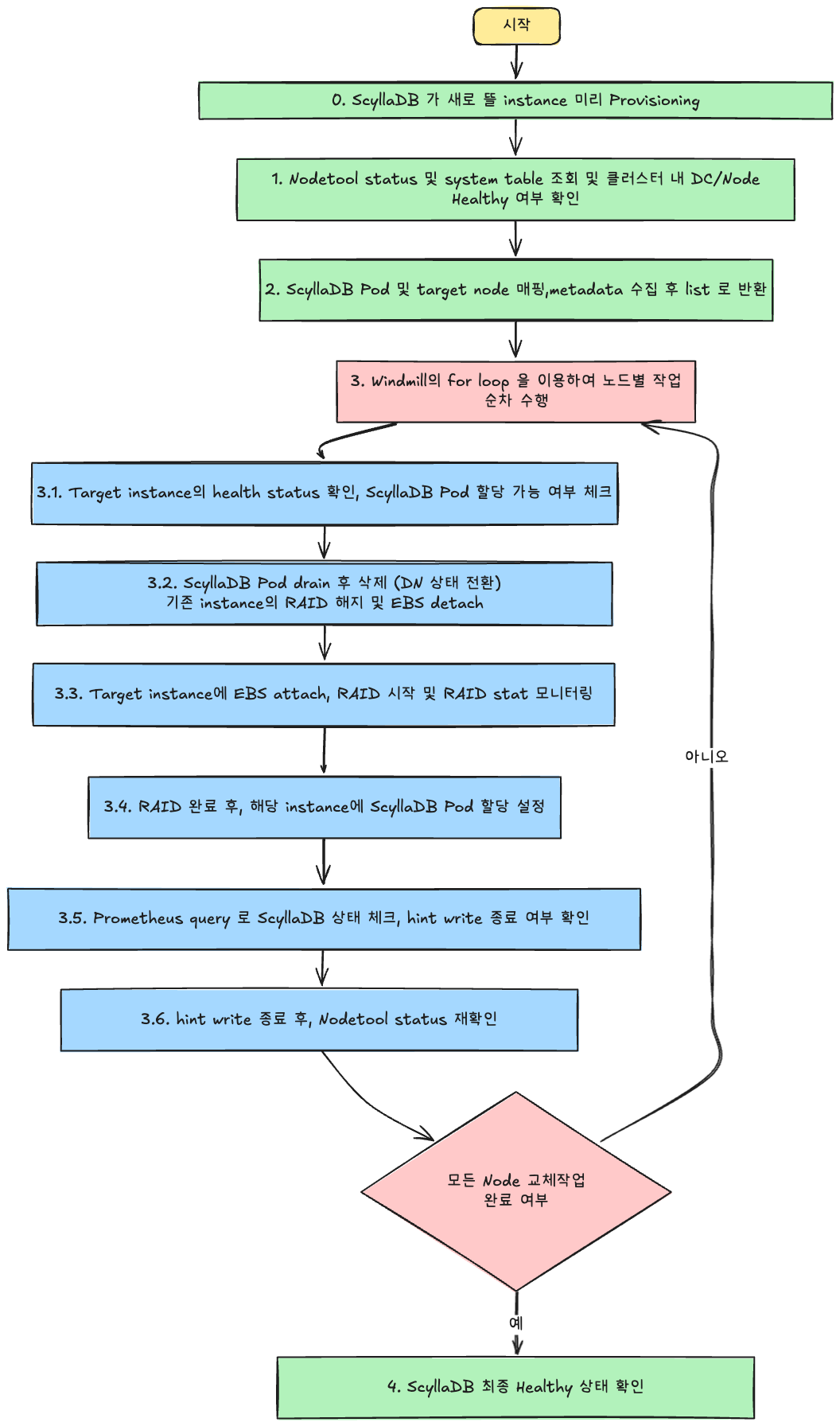
이 과정을 QA/Stage 환경에서 수십 차례 반복 테스트해 발생할 수 있는 예외 상황을 핸들링했고, 오류 발생 시 Flow를 중단 후 재시작 가능하도록 보완했습니다. Windmill은 각 Flow Step 단위로 작업 결과를 UI에 표시하고, 특정 Step만 골라 재실행할 수 있어 디버깅이 매우 편리했습니다.
3.2 Workflow in production
script 안정성을 위해, QA와 Stage 환경에서 정해진 횟수 이상 연속 성공을 목표로 충분히 검증한 뒤, Production에서도 동일하게 Migration을 진행했습니다.
- Super Disk가 적용된 node를 미리 준비(init attach)
- 기존 데이터를 새 node로 옮기는 방식대로 진행
- Prod에서도 node 교체 script가 정상적으로 동작함을 확인
결과적으로 기존 대비 node 교체 시간이 매우 단축되었으며, 실 운영 환경에서 Throughput이나 Latency 등 주요 지표도 정상적으로 유지됨을 확인했습니다.
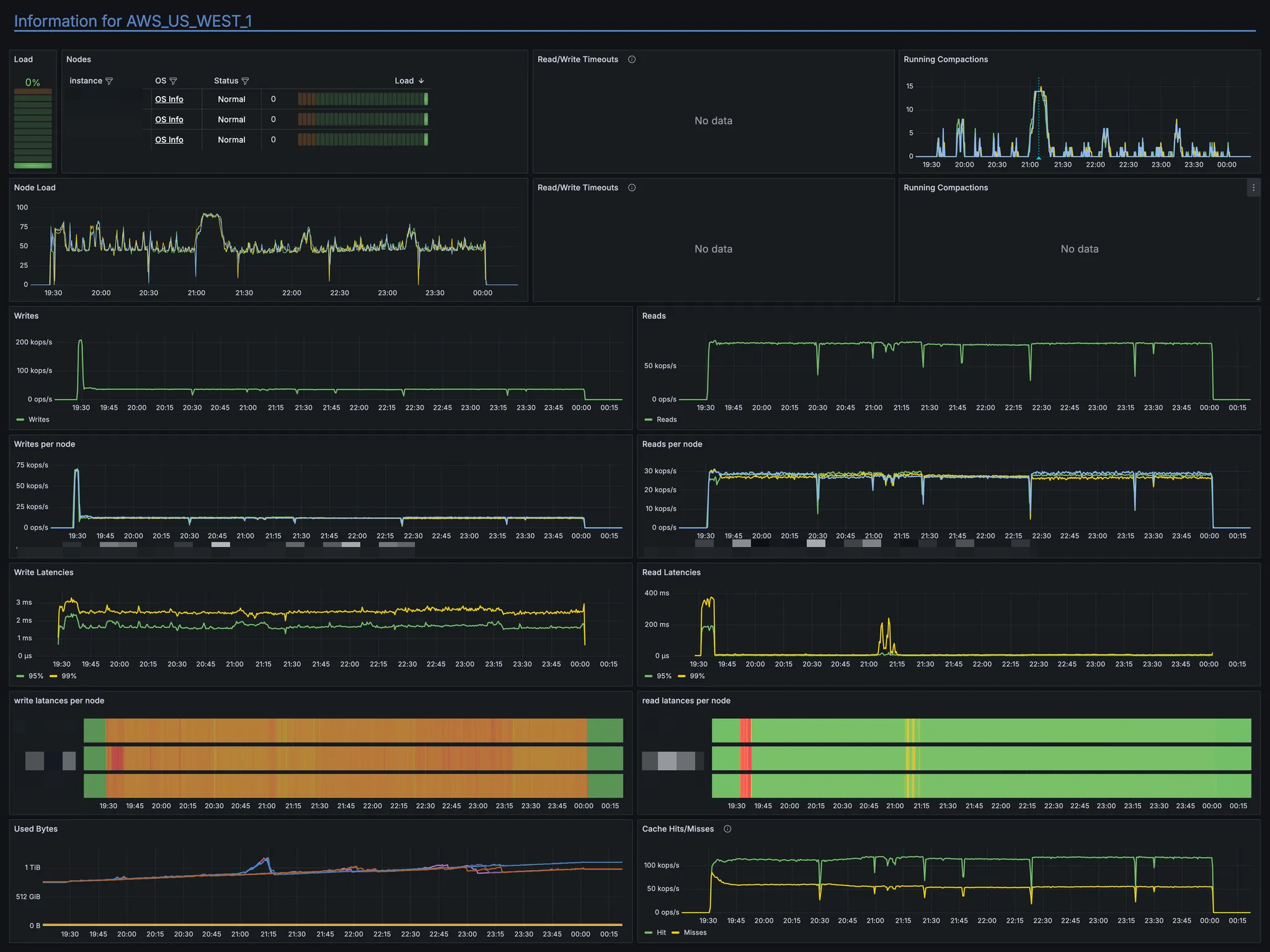
아래는 Production 환경에서 No-Raid와 Raid 성능을 비교한 실제 환경의 metric 입니다.
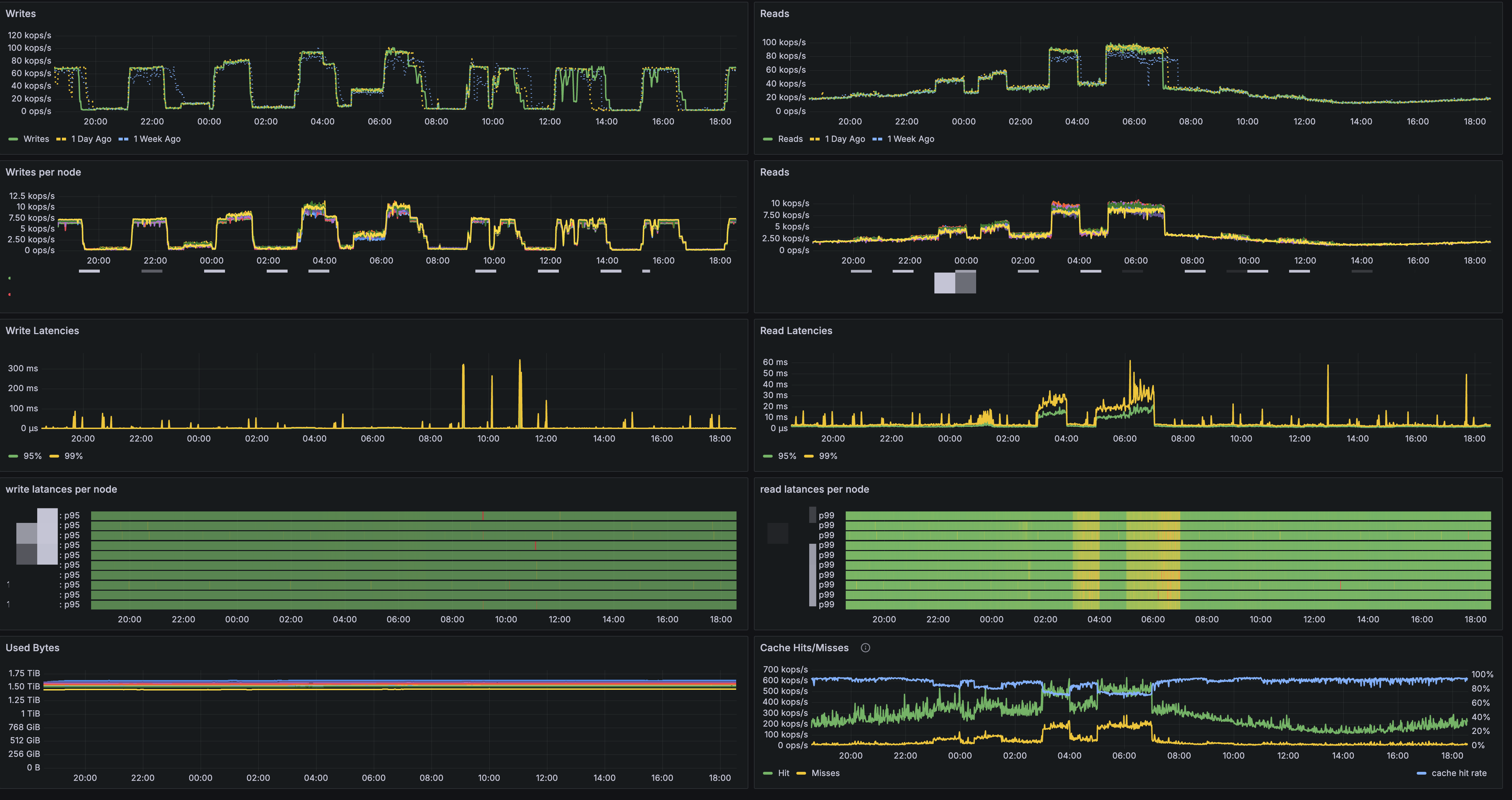
RAID를 적용한 i4i instance의 Production 성능 결과
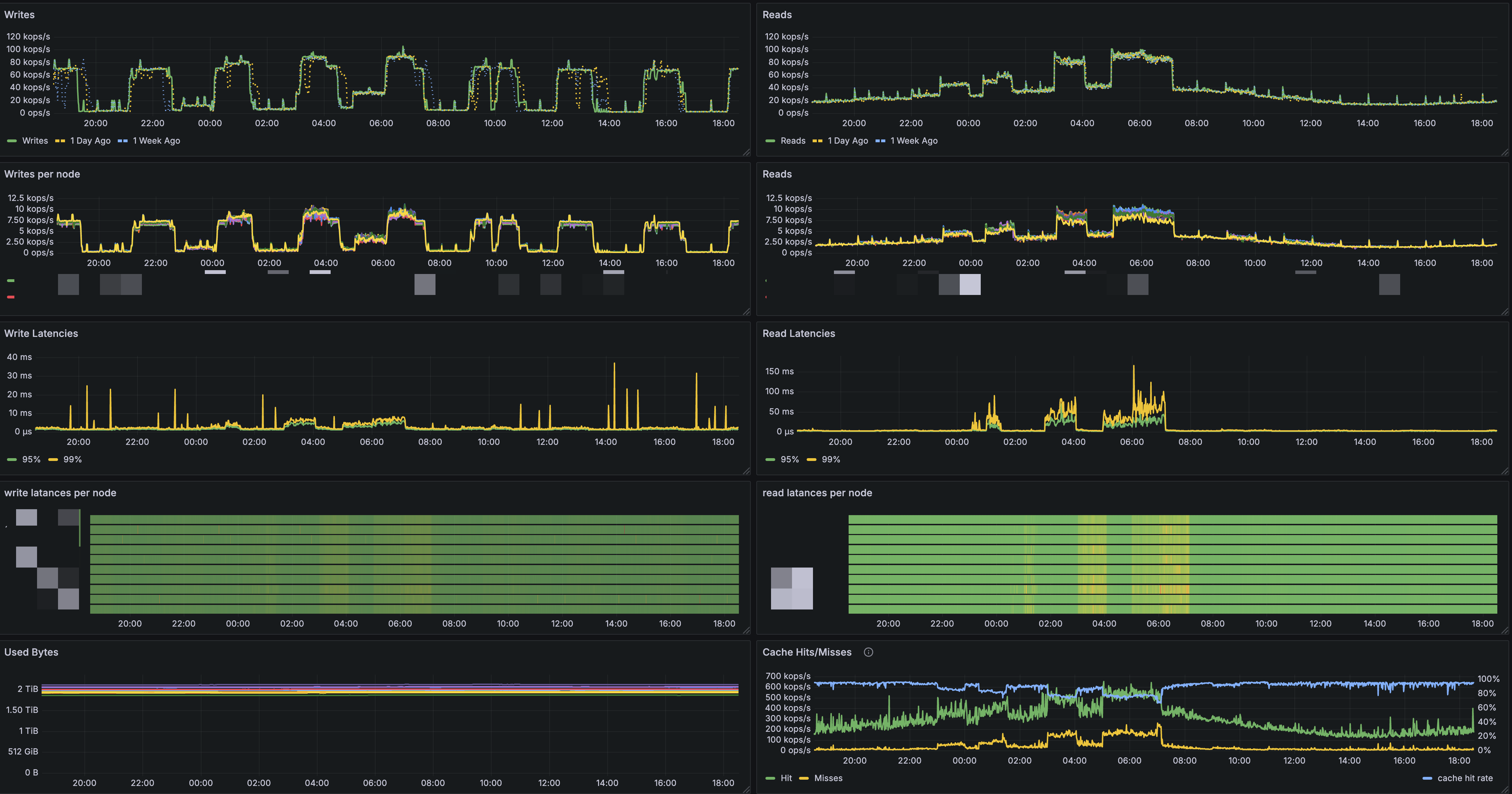
RAID를 적용하지 않은 i4i instance의 Production 성능 결과
실제로 Benchmark와 마찬가지로 Throughput·Latency 차이가 거의 없었습니다.
또한 disk 메트릭을 확인해 보면, --write-mostly 옵션이 정상 작동해 Local SSD에서만 Read가 발생함을 확인했습니다.
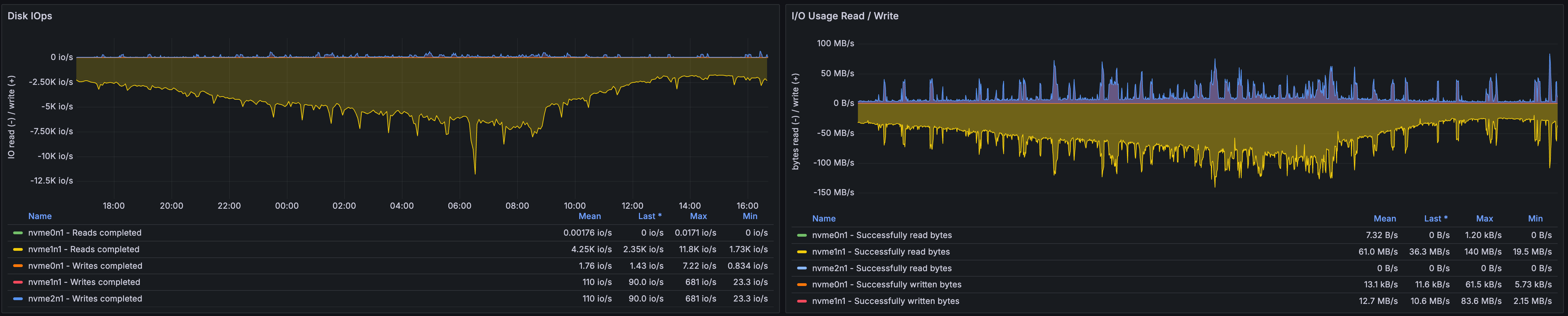
4.글을 마치며
이번 글에서 공유드린 내용을 요약하자면 아래와 같습니다.
- Super Disk 적용으로 빠른 Latency와 안정성을 동시에 확보
- 기존 i4i(Local SSD) 운영 방식과 비슷한 성능을 내면서, 데이터 유실 시에도 빠르게 EBS 복구가 가능해 RPO가 크게 개선되었습니다.
- 기존에는 node 하나를 복구하는데, 18시간~24시간 정도 소요되었으나 현재 RAID 방식으로 수행할 경우 1시간 안에 node 를 복구 가능하여, 약 20배 빠른 복구 속도를 가질수 있게 되었습니다.
- 또한 장애 모의 훈련 시, 로컬 SSD 장애 및 유실에 대한 우려가 있었는데, RAID EBS 가 Backup 역할을 수행할 수 있어 EBS 에 문제가 없다면 RAID 재구성을 통해 비교적 단시간에 node를 복구할 수 있게 되었습니다.
- 기존 i4i(Local SSD) 운영 방식과 비슷한 성능을 내면서, 데이터 유실 시에도 빠르게 EBS 복구가 가능해 RPO가 크게 개선되었습니다.
- node 교체 작업 시간 단축
- 전에는 node를 교체하면 모든 데이터를 복제해 왔어야 했기 때문에 node 하나당 하루 이상 소요되어 운영 부담이 매우 컸습니다.
- 이제는 RAID 복구만 거치면 되므로 교체 작업에 걸리는 시간이 약 95% 단축되어, 더 자주 정기 유지보수를 할 수 있게 되었습니다.
- 다른 node에서 데이터를 가져와 복구할 때 발생하던 AWS Data Transfer 비용이 절감되어, Node 교체 시 드는 비용 절감 효과를 얻었습니다.
- 긴급 상황 시 RAID 복구를 기다리지 않고 EBS만으로 서비스를 빠르게 재개할 수도 있는 옵션도 확보하여, 장애 대응 전략의 유연성을 높였습니다.
- Windmill을 통한 자동화
- AWS, Kubernetes, ScyllaDB 관련 각종 CLI와 API를 하나의 통합된 Flow로 구성하여 복잡한 multi-step 작업을 일관되게 처리할 수 있게 되었습니다.
- 자동화된 예외 처리와 재시도 메커니즘을 통해 작업 실패율을 98% 이상 감소시켰고, 휴먼 에러로 인한 교체 작업 실패 가능성을 크게 줄였습니다.
앞으로도 Hyperconnect SRE 팀은 team 내부에서 운영하는 모든 Database 및 messaging platform 의 안정성과 성능 향상, 운영 자동화를 위해 지속적인 테스트, 자동화 도구 도입, 그리고 내부 공유를 통한 개선 노력을 이어갈 예정입니다.
긴 글 읽어주셔서 감사합니다!
References
[1] ML Feature Store @ Hyperconnect (DEVIEW 2023)
[2] ScyllaDB vs. Cassandra
[3] Cassandra 4.0 vs. Scylla Open Source 4.4 Benchmark
[4] SRE 팀은 장애에 어떻게 대응할까? Hyperconnect 장애 모의 훈련
[5] ScyllaDB Disk Requirements
[6] 7 Reasons Not to Put an External Cache in Front of Your Database
[7] How Discord Supercharges Network Disks for Extreme Low Latency
[8] YCSB - Yahoo! Cloud Serving Benchmark
[9] Latte - ScyllaDB Benchmark Tool
[10] ScyllaDB Monster Scale Summit
[11] ScyllaDB is No Longer “Just a Faster Cassandra” (ScyllaDB Monster Scale Summit Tech Talk)
[12] Benchmark Workload example for ScyllaDB Latte
[13] Log-Structured Merge-Tree (LSM Tree)
[14] Hinted Handoff (ScyllaDB Documentation)