Apache Flink 어플리케이션의 End-to-End Latency 병목 찾아내기
어플리케이션을 운영하다 보면, 트래픽 증가나 사용자 경험 개선, 비용 절감 등 다양한 요인으로 인한 성능 개선 요구가 꾸준히 제기됩니다. 저희 팀에서 운영하고 있는 Flink 어플리케이션도 비즈니스 요구사항을 만족시키기 위한 지속적인 성능 튜닝이 필요했습니다. 하이퍼커넥트의 대표 Product인 Azar의 핵심이 되는 1:1 매칭 서비스는 Flink 어플리케이션으로 구현되어 있는데, 특히 스와이프 직후 매칭이 이뤄져야 하는 Azar의 특성상, end-to-end latency는 사용자 만족도와 직결되므로 매우 중요합니다. 이에 따라 성능상 병목 구간을 정확히 찾아내고, 찾아낸 문제를 해결하는 과정이 지속적으로 필요했습니다. 이 글에서는 이러한 Flink 어플리케이션의 end-to-end latency를 낮추기 위해 병목을 진단하고 개선 포인트를 도출해나가는 과정을 소개하고자 합니다.
Flink 어플리케이션의 end-to-end latency 개선 포인트를 찾아내는 과정은 크게 두 단계로 나눌 수 있습니다.
- Application level: 전체 어플리케이션에 걸쳐 Flink operator 단위로 지표를 상세하게 수집하고 관찰하여 비정상적으로 느린 부분을 찾아냅니다.
- Operator level: 찾아낸 Flink operator에 대한 프로파일링을 진행하고, 이후 코드 레벨의 inspection을 수행합니다.
지금부터 각 단계에 대해 상세히 다뤄보겠습니다.
1. Application Level: Operator 단위의 지표 수집 및 관찰
End-to-end latency를 개선하기 위해서는 먼저 Flink의 각 operator 별로 처리에 소요되는 시간을 정확히 파악해야 할 필요가 있습니다. 이렇게 파악만 하더라도 기대와 다르게 느린 지점을 단번에 찾아낼 가능성이 있습니다.
이를 위해서 Flink 어플리케이션의 각 operator에 2종류의 히스토그램 지표를 추가하는 작업이 필요합니다.
- 처리 시간:
map(),processElement()와 같은 어플리케이션 코드가 input을 처리해서 output을 생성하기까지 걸리는 시간 - 처리 외 시간: 처리 시간 밖의 모든 시간. Flink에서 데이터를 de/serialize하거나 네트워크 I/O를 하는 시간 등이 포함됩니다.
지표를 처리 시간과 처리 외 시간의 두 종류로 분리하였는데, 이는 둘 중 어느 곳이 병목이냐에 따라 해결 방식이 완전히 달라지게 되기 때문입니다. 만약 처리 시간이 병목이라면 어플리케이션의 로직을 점검하거나, DB I/O 시간 등을 확인해야 할 수 있습니다. 반대로 처리 외 시간이 병목이라면 네트워크 I/O와 관련된 트러블슈팅을 진행하거나 Flink 내부 코드와 관련된 작업을 해야 할 것입니다.
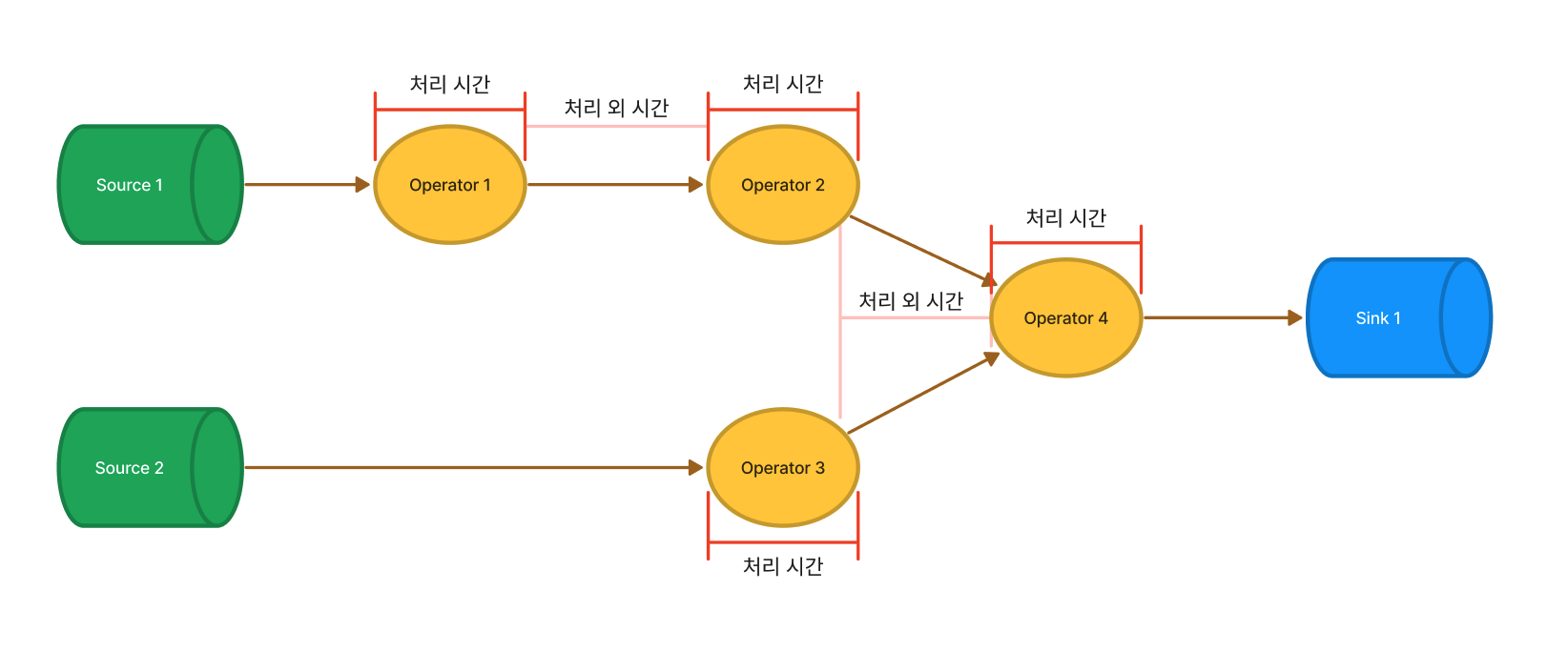
그림 1. 처리 시간과 처리 외 시간 지표가 각각 커버하는 구간의 예시
코드 작업을 통해 지표를 추가하고, 운영 환경에 배포하여 각 operator의 처리 시간과 처리 외 시간을 다음과 같이 수집할 수 있습니다. (이 글 끝에 부록으로 지표 추가 코드의 예시를 실어 놓았습니다)
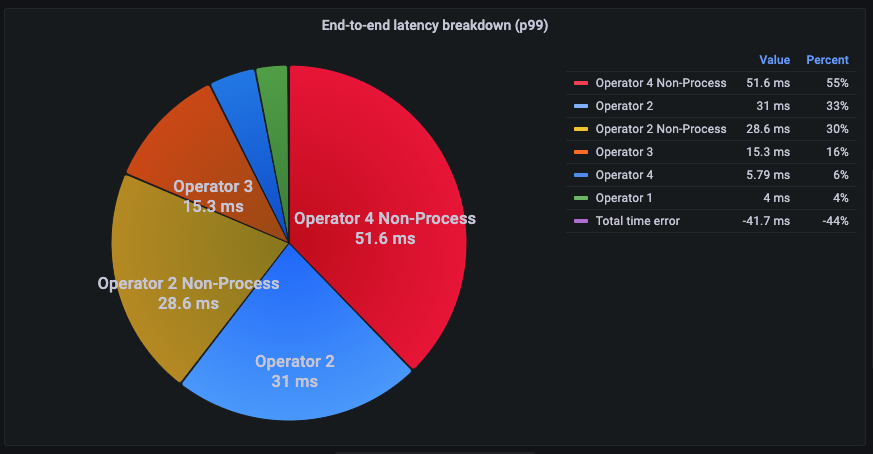
그림 2. 위 예시에서 수집한 지표를 모아 파이 차트로 나타낸 것
처리 시간은 Operator 1, 처리 외 시간은 Operator 1 Non-Process의 형태로 수집하고 있다.
위와 같이 2종류의 지표를 추가하게 되면 end-to-end latency를 잘게 쪼개서 확인할 수 있습니다. 모니터링 체계가 갖춰지면 어느 구간이 예상했던 것보다 시간이 오래 걸리는지 파악할 수 있고, 파악한 병목 operator를 가지고 다음 단계로 넘어갈 수 있습니다.
참고로 Flink 자체적으로도 end-to-end latency를 측정할 수 있는 LatencyMarker라는 기능을 제공합니다. 이 기능을 활성화하면 source로부터 각 operator에서 처리가 끝나기까지 걸리는 시간을 지표로 확인할 수 있습니다. 다만 이 기능은 성능 저하가 상당히 커서 실서버 사용이 어렵고, 처리 시간과 처리 외 시간을 분리해서 볼 수 없으며, timer / aggregation / windowing 등을 사용하는 복잡한 Flink 어플리케이션에서는 latency의 정확도가 떨어진다는 한계를 가지고 있습니다.
2. Operator Level: Flame Graph를 통한 프로파일링
Latency를 개선하고자 하는 operator를 파악했으면, 이제 정확히 어떤 부분이 개선 가능한지를 찾아내야 합니다. 다행히도 Flink에서는 이 과정에 필요한 도구를 제공하고 있는데, 바로 operator flame graph입니다.

그림 3. Flink web UI를 통해 flame graph를 확인할 수 있다. (출처: Flink 공식 documentation)
Flame graph란 시스템 성능 프로파일링 도구의 일종이며, 콜 스택을 여러 번 샘플링한 결과를 그래프로 나타낸 것입니다. 그래프를 통해 함수 호출 스택과 각 함수 호출에 소요되는 시간을 시각화해서 볼 수 있습니다. 가로축이 길수록 해당 함수의 코드를 실행하는 데에 시간이 오래 걸린다는 것을 의미합니다. Flink의 flame graph는 operator 단위로 볼 수 있으며, 색깔을 가지고 유저 코드(주황색)와 Flink 내부 코드(노란색)로 구분할 수 있습니다.
Flame graph에는 처리 시간과 처리 외 시간 둘 다 나타나기 때문에, 이 둘을 구분해서 보아야 합니다. Flame graph에서 처리 시간을 찾는 가장 정확한 방법은 map()이나 processElement()와 같은 콜 스택이 위치한 곳을 찾아서 그 길이를 재는 것입니다. 그 외의 구간은 Flink 내부 코드가 실행되면서 de/serialization, state 처리 등이 일어나는 처리 외 시간이 됩니다. 네트워크 I/O와 같이 Flink operator 밖에서 발생하여 flame graph에서는 확인할 수 없는 처리 외 시간도 존재한다는 점도 참고하시면 좋겠습니다.
Flink의 flame graph는 기본적으로 비활성화되어 있습니다. 활성화하려면 Flink의 config.yaml에 rest.flamegraph.enabled: true를 설정해야 합니다. Flink web UI에서 flame graph를 확인 시 (기본 설정 기준 3분마다) 콜 스택 샘플링을 진행하여 flame graph를 재생성하는데, 이 때마다 해당 operator에서 성능 저하가 발생합니다. 따라서 실서버에서는 활성화하는 것을 권장하지 않으며, 운영과 비슷한 로드가 발생하는 테스트 환경을 구축하여 활용하는 것을 권장드립니다. Flame graph를 관측하기 전까지는 어떠한 성능 저하도 일어나지 않기 때문에, 테스트 환경에서는 flame graph를 항상 켜 놓아도 무방합니다.
이제 이 flame graph를 분석해서 latency 개선 포인트들을 찾을 수 있습니다. 이 글에서는 flame graph의 결과를 유형별로 나누어 살펴보겠습니다.
1. 처리 시간이 병목인 경우
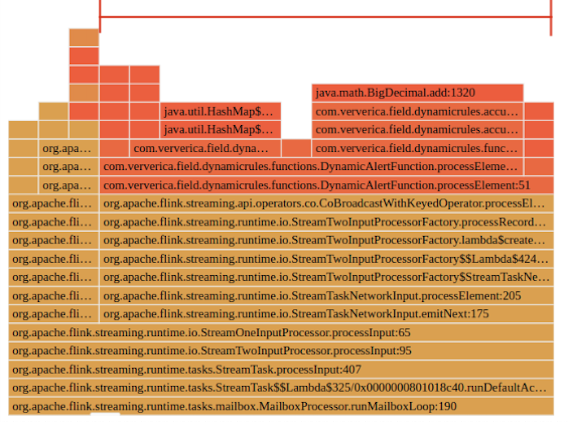
그림 4. 어플리케이션 로직 처리 시간이 오래 걸리는 경우 (원본: Flink 공식 documentation)
특정 operator의 처리 시간 지표가 높고, 위와 같이 어플리케이션 코드 실행에 걸리는 시간이 flame graph의 대부분을 차지하는 경우 어플리케이션 로직이 병목이라고 판단할 수 있습니다. 이 경우에는 콜 스택을 살펴보아 어플리케이션 코드에서 예상보다 오래 걸리는 부분이 있지는 않은지 체크해야 합니다. 만약 의심되는 부분이 있다면 code inspection을 통해 코드 레벨에서 개선을 하면 될 것입니다.
추가로 어플리케이션 로직 외에도 blocking I/O나 Flink state를 사용하는 경우, 이들의 사용 패턴을 개선해야 할 수도 있습니다. Flink state의 경우 state backend의 구현체를 바꿔보거나 관련 설정을 바꿔보는 것이 도움이 될 수 있습니다.
2. 처리 외 시간이 병목인 경우
앞서 처리 외 시간은 map(), processElement()와 같은 어플리케이션 코드가 input을 처리해서 output을 생성하기까지 걸리는 시간이라고 정의했었습니다. 만약 데이터가 전달되는 두 operator가 서로 다른 TaskManager에 존재한다면, 이 과정은 크게 다음과 같은 순서로 진행됩니다.
- 이전(=upstream) operator에서 데이터를 serialize
- 네트워크를 통해 데이터가 upstream operator에서 downstream operator로 전달 (네트워크 I/O)
- 현재(=downstream) operator에서 데이터를 deserialize
아래에서 네트워크 I/O 시간과 Flink 내부 코드 실행 시간으로 나누어서 각각을 살펴보겠습니다.
2-1. 네트워크 I/O가 병목인 경우

그림 5. Flink 내부 코드 실행 시간이 짧은 경우 (원본: Flink 공식 documentation)
만약 처리 외 시간이 지표 상 오래 걸리지만 위와 같이 flame graph에서 Flink 내부 코드 실행에 걸리는 시간이 차지하는 비중이 낮은 경우에는, 네트워크 I/O가 병목일 가능성이 큽니다. 병목 구간이 flame graph의 범위 밖에 있다는 뜻이기 때문입니다. 이런 경우 다음과 같은 접근을 시도해볼 수 있습니다.
- Flink TaskManager의 네트워크 설정 튜닝하기 (
taskmanager.network.*) - 네트워크 인프라 점검하기
이 외에도 Flink 블로그(1편, 2편)에서 Flink 설정을 튜닝하거나 구조를 변경해서 end-to-end latency를 줄이기 위한 방법들에 대해 소개하고 있으니, 읽어보시는 것을 추천드립니다.
2-2. Flink 내부 코드 실행이 병목인 경우
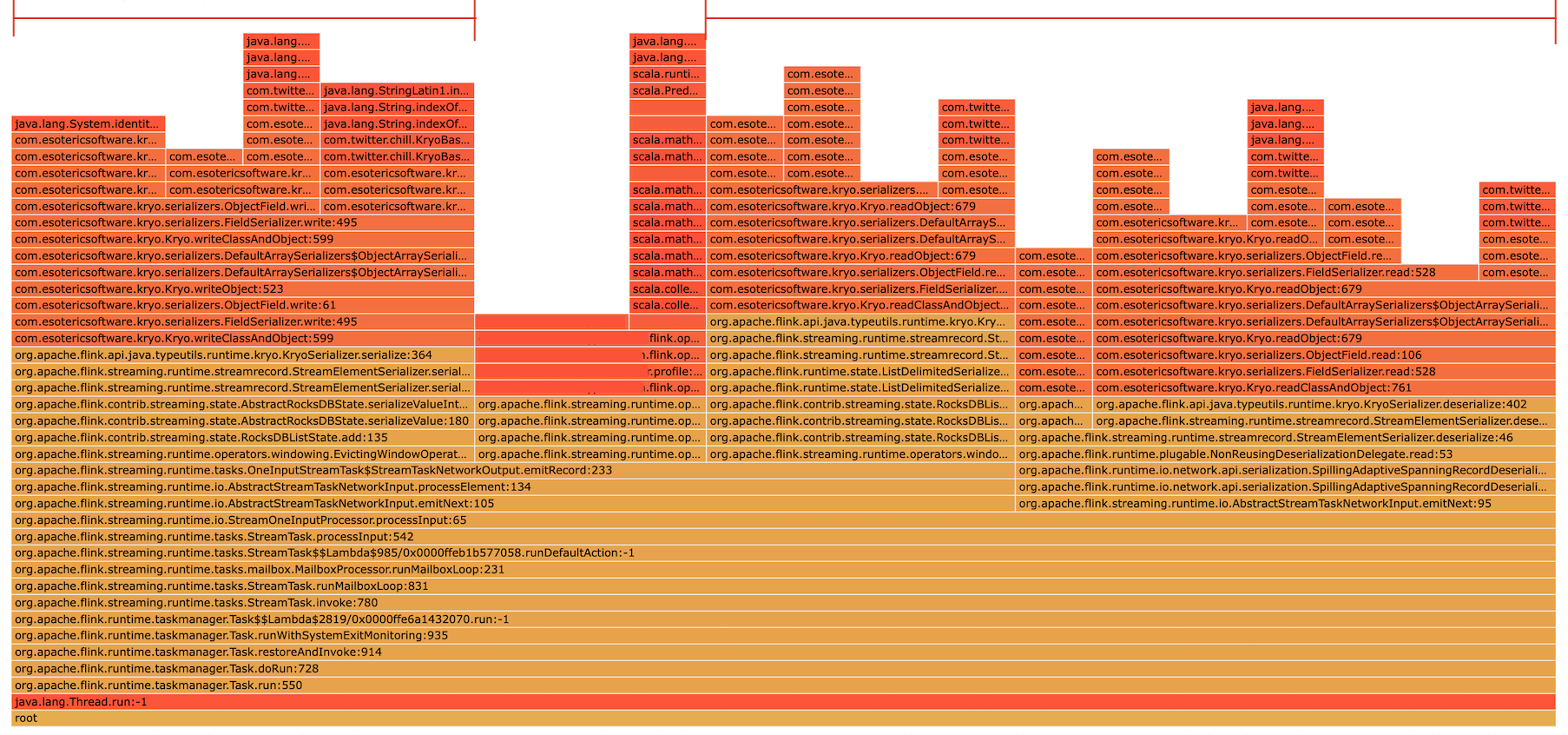
그림 6. Flink 내부 코드 실행에 시간이 오래 걸리는 경우
반대로 처리 외 시간이 지표 상 오래 걸리면서 위와 같이 Flink 내부 실행에 걸리는 시간이 flame graph의 대부분을 차지하는 경우에는 Flink 내부 코드를 들여다볼 필요가 있습니다. 위 예시와 같이 Flink의 내부 코드에서도 유저 코드를 호출하는 경우가 있기 때문에, 콜 스택의 색만 가지고 처리 시간이라고 판단하지 않도록 주의해야 합니다. 예시에서는 operator가 Flink의 fallback serializer인 Kryo serializer 관련 코드를 처리하는 데에 대부분의 시간을 사용하는 것을 확인할 수 있습니다. 이 때 해결 방법으로는 runtime reflection을 사용하는 Kryo serializer 대신 더 빠른 POJO serializer를 사용할 수 있도록 해당 데이터가 정의된 클래스 코드를 수정하는 방법 등을 고려해 볼 수 있습니다.
마치며
이 글에서는 Flink 어플리케이션의 end-to-end latency를 개선하기 위해 병목을 찾아내는 방법에 대해서 다루었습니다. 이 글을 마치기 전에 강조하고 싶은 것은, 위에서 상술한 작업을 본격적으로 시작하기에 앞서 이미 정의되어 수집되고 있는 지표들이 자신이 알고 있는 정의와 정확히 일치하는지 더블 체크를 해야 한다는 점입니다. 제가 작업했을 당시를 돌이켜보면, 제가 병목을 찾아내고자 하는 Flink 어플리케이션은 이미 latency 관련 지표들을 다양하게 수집하고 있는 상태였습니다. 그러나 이 지표들은 처리 시간 지표들뿐이었고, 처리 외 시간 지표가 존재하지 않는 상태였습니다. 이로 인해 처리 외 시간의 병목(Kryo serializer)을 찾아낼 수 없었고, 잘못된 판단으로 많은 시간을 허비하게 되었습니다. 또 이미 수집하고 있던 처리 시간 지표들도 제가 생각했던 것과 의미가 달라서 큰 시행착오를 겪기도 했습니다. 따라서, 이런 종류의 작업을 수행하기 전에는 지표가 어떤 값을 나타내고 있는지 정확하게 파악하고, 만약 어플리케이션에서 커스텀으로 수집하고 있는 지표의 경우 코드 레벨에서 확실하게 크로스체크하는 습관이 생긴다면 좋을 것 같습니다. 감사합니다.
Appendix I. Operator 단위의 Metric 구현 예시 코드
import com.codahale.metrics.Reservoir;
import com.codahale.metrics.SlidingWindowReservoir;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.dropwizard.metrics.DropwizardHistogramWrapper;
import org.apache.flink.metrics.Histogram;
import org.apache.flink.metrics.MetricGroup;
public class MyInput {
private long createdAt;
/* ... */
}
public class MyOutput {
private long createdAt;
/* ... */
}
public class MyOperator extends RichMapFunction<MyInput, MyOutput> {
private static final int HISTOGRAM_RESERVOIR_SIZE = 120;
private Histogram createHistogram(String key) {
MetricGroup metricGroup = getRuntimeContext().getMetricGroup();
Reservoir reservoir = new SlidingWindowReservoir(HISTOGRAM_RESERVOIR_SIZE);
Histogram histogram = new DropwizardHistogramWrapper(new com.codahale.metrics.Histogram(reservoir));
return metricGroup.histogram(key, histogram);
}
private Histogram inputNonProcessTimeMetric; // 처리 외 시간
private Histogram inputProcessTimeMetric; // 처리 시간
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
inputNonProcessTimeMetric = createHistogram("my_operator_input_non_process_time");
inputProcessTimeMetric = createHistogram("my_operator_input_process_time");
}
@Override
public MyOutput map(MyInput input) throws Exception {
long startTime = System.currentTimeMillis();
inputNonProcessTimeMetric.update(startTime - input.getCreatedAt());
/*
* Input을 처리하는 코드...
*/
MyOutput output = new MyOutput();
long endTime = System.currentTimeMillis();
output.setCreatedAt(endTime);
inputProcessTimeMetric.update(endTime - startTime);
return output;
}
}
References
Read more
-
Jackson과 Scala 기반 Flink를 사용한 코드 리팩토링 과정에서 발생한 Serialization 관련 이슈 해결하기
Jackson과 Scala 기반 Flink를 사용한 코드를 리팩토링하는 과정에서 발생한 Serialization 관련 이슈들을 살펴보고 이를 해결한 방법들을 공유합니다.