아자르 Data Lifecycle Policy 개발하기
안녕하세요. Azar API Dev Team의 Ledger 입니다. 아자르는 유럽, 아시아, 중동 등 다양한 지역에서 사랑받고 있는 글로벌 서비스 입니다. 글로벌 서비스를 운영하기 위해서는 고려해야 할 것이 많은데 그 중 유저 데이터의 라이프 사이클에 대해 다뤄보려 합니다. 유저의 프라이버시를 위해 유저가 탈퇴하거나 오랜 시간 접속하지 않는다면 유저의 데이터는 삭제되어야 합니다. 아자르에서는 이를 어떻게 구현하고 있을까요?
요구사항
기능 요구사항은 다음과 같습니다.
- 유저의 데이터는 이용자 안전 보장과 법적 대응을 위해 탈퇴 즉시 삭제하지 않고 일정 기간 보관 후 삭제합니다.
- 데이터는 성격에 따라 보관 기간을 다르게 설정할 수 있어야 하고, 보관 기간은 레코드 단위뿐만 아니라 필드 단위로도 관리할 수 있어야 합니다.
- 탈퇴한 유저와 같은 개인 정보 삭제 대상은 보관 기간이 지난 후 반드시 삭제되어야 합니다.
- 데이터의 삭제는 하나의 팀에서 진행되는 것이 아닌 아자르의 모든 팀에서 다루는 데이터를 기반으로 하며 어플리케이션 데이터뿐 아니라 분석용 데이터 또한 포함됩니다.
- 개인정보 삭제 정책은 언제든지 변경될 수 있기 때문에 특정 날짜를 지정해 삭제를 반복 수행할 수 있어야 하고, 해당 동작은 멱등성을 보장해야 합니다.
비기능 요구사항은 다음과 같습니다.
- 마이크로 서비스 아키텍처로 잘 분리되어 있는 도메인 내에서 담당하고 있는 데이터에 대한 책임을 다합니다.
- 테이블의 추가 및 변경에 유연하게 대응할 수 있어야 합니다.
시스템 구조
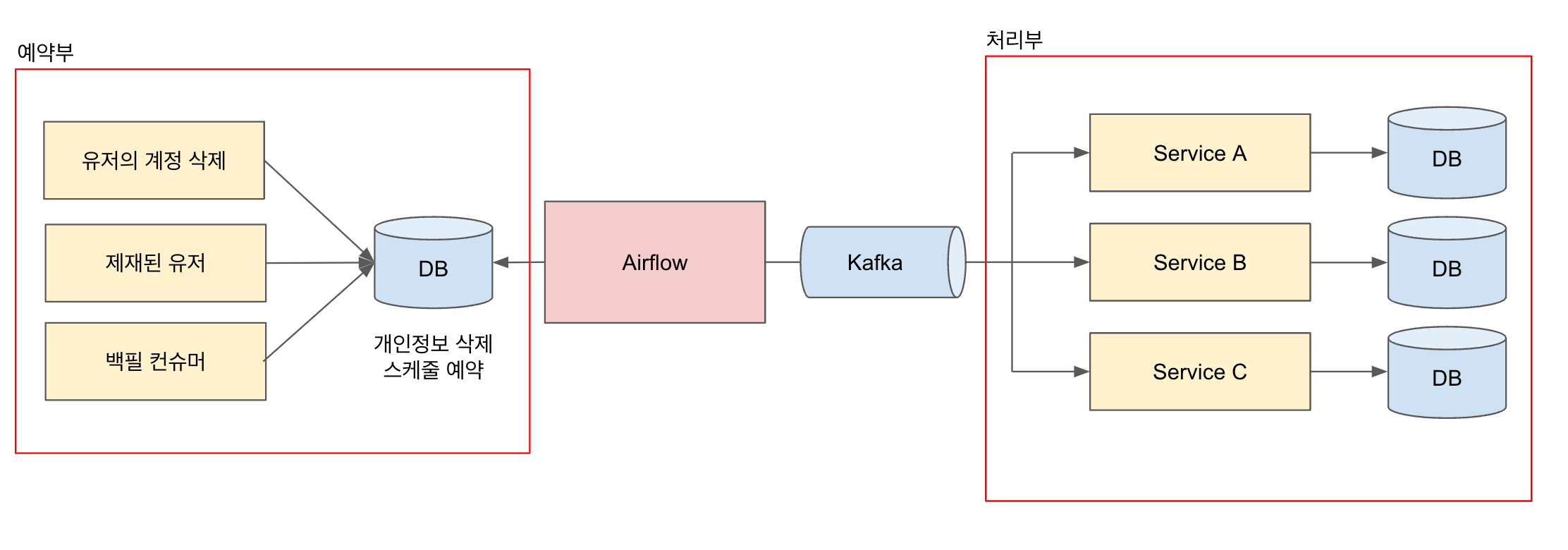
시스템 구조는 이벤트 기반 아키텍처로 설계되어 있으며, 크게 2가지로 나뉩니다. 하나는 유저의 개인정보 삭제를 예약하는 예약부이고, 다른 하나는 유저의 개인정보 삭제 예약이 트리거될 때 처리하는 처리부입니다. 유저의 개인정보 삭제가 필요할 때 스케줄을 예약하고 배치를 통해 예약된 스케줄이 있으면 카프카 이벤트를 발행해 처리부에서 데이터 삭제를 진행합니다.
이벤트 기반 아키텍처
먼저 이벤트 기반 아키텍처를 채택하게 된 배경부터 살펴보겠습니다.
- 처리해야 할 데이터의 종류가 늘어남에 따라 삭제 수행 트랜잭션이 길어져, 복잡도 및 관리 포인트를 증가시키고 있습니다.
- 도메인이 명확하게 분리되어 있지 않으며 역할과 책임의 분리가 명확하지 않습니다.
- 메소드가 하나의 역할을 수행하지 않고, 많은 역할을 수행하고 있습니다.
- 여러 요구사항으로 인해 단순히 REST API 를 호출하는 것으로는 어려운 상황이 생기고 있습니다.
- 유저 스케일에 해당하는 대량의 데이터를 효과적으로 요청하고 받는 구조가 필요해지고 있습니다.
- REST API 를 호출하는 쪽에서 최종 일관성을 위한 작업을 추가해야만 합니다.
- 단순 레코드 삭제가 아닌 필드 별 삭제를 각각 마이크로 서비스에서 제공해 줘야만 합니다.
이러한 문제를 해결하고자 합니다.
- 이벤트 처리를 통해 역할과 책임을 나누고, 이를 도메인으로 정의하여 분리합니다.
- 각 메소드는 명확하게 하나의 일을 수행하도록 합니다.
- 데이터의 추가 혹은 변경이 발생해도 삭제가 필요한 마이크로 서비스에서만 컨슈머 수정을 진행하면 됩니다.
- 마이크로 서비스 간 통신 패턴으로 카프카를 이용하여 이벤트 기반 아키텍처 형태로 구성합니다.
- 이벤트 발행을 통해 각 마이크로 서비스도 비즈니스 로직을 수행할 수 있습니다.
- 대량의 메시지라도 마이크로 서비스 별로 처리량을 조정할 수 있어 서비스 영향도를 최소화 할 수 있습니다.
- 컨슈머 입장에서 카프카의 오프셋과 메뉴얼 커밋 활용하여 쉽게 이벤트 무손실을 구현할 수 있습니다.
이벤트 예약부
이벤트 예약부가 하는 역할의 핵심은 이벤트 처리부에서 이벤트 보관 기간에 대한 책임이 없게 구현하는 것과 이벤트를 예약하는 시점이 개인정보 유형 별로 다양할 수 있다는 것입니다. 그림 1에서 확인해 보면 유저가 계정을 삭제하거나, 제재를 받는다면 유저의 개인정보 삭제 스케줄을 예약해두고 예약 시점이 지나면 카프카 이벤트를 발행합니다.
이벤트 명세
데이터 보관 기간이 만료되어 발행되는 개인정보 삭제 이벤트 명세는 다음과 같습니다.
/**
* AccountEvent 에 대한 예시입니다.
*
* @property createdMilliseconds 이벤트 생성 timestamp
* @property status 이벤트의 상태. dlp 삭제 리스너의 경우 PERSONAL_INFO_DELETED 를 사용해야 한다. 계정 탈퇴와 개인정보 삭제는 status로 구분한다.
* @property userId userId
* @property personalInfoDeletedInfo status 가 PERSONAL_INFO_DELETED 일 시 정보. 그 외 null
* ...
*/
data class AccountEvent(
val createdMilliseconds: Long,
val status: Status,
val userId: Long,
val personalInfoDeletedInfo: PersonalInfoDeletedInfo?,
// ...
) {
data class PersonalInfoDeletedInfo(
val triggerType: TriggerType,
val privacyType: PrivacyType,
)
}
- 이 이벤트의 컨슈머는 userId 와 privacyType 정보를 사용해 유저의 개인정보를 삭제합니다.
- privacyType 이 무엇인지는 아래 레코드 및 필드 별 데이터 보관과 삭제 섹션에서 자세히 확인해 볼 수 있습니다.
- 이후 생길 수 있는 요구사항인 이벤트 순서 보장을 위해 개인정보 삭제 이벤트로 만드는 것이 아니라 Account 이벤트 내에 상태를 구성합니다.
- 상태는 PERSONAL_INFO_DELETED, DELETED, CREATED 등이 있을 수 있고, 개인정보 삭제 이벤트의 경우에는 PERSONAL_INFO_DELETED 값을 필터링해 사용합니다.
- 예를 들면 유저가 계정을 탈퇴했을 때 유저의 탈퇴 시점에 DELETED 이벤트가 발행되고, 보관 기간이 필요한 데이터는 개인정보 삭제 시점에 PERSONAL_INFO_DELETED 이벤트가 발행됩니다.
- 동일한 내용의 두 이벤트 발행과 하나의 이벤트의 Retry에 의한 중복 컨슘을 구분하기 위해서는, 이벤트의 id를 통해 멱등성 키를 만들어 사용하는 방식으로 이벤트 중복 문제를 해결할 수 있습니다. 다만 컨슈머 구현 자체에서 멱등성 보장을 하게 구현할 것이므로 따로 설명에 넣지 않았습니다.
이벤트 처리부
이벤트 처리부는 위의 이벤트를 컨슘하여 자신에게 맞는 데이터에 대해 삭제를 수행합니다. 처리부의 핵심은 이벤트를 받고 삭제해야 할 데이터를 반드시 삭제하는 것입니다. 넘어온 개인정보 삭제 이벤트는 이미 보관 기간 충족 후에 넘어온 것이므로 유저는 이 데이터가 얼마나 보관되었는지는 고려하지 않아도 됩니다. 만약 탈퇴 시점에 바로 삭제해야 하는 데이터가 있다면 DELETED 이벤트를 컨슘해서 삭제합니다.
여기까지는 두 가지로 나눠진 각 부분에 대해 간단하게 어떤 역할을 수행하는지만 살펴봤습니다. 아래에서 더 자세하게 각 요구사항을 어떻게 해결하였는지 설명해 보겠습니다.
레코드 및 필드 별 데이터 보관과 삭제
하나의 마이크로 서비스에서 관리하는 데이터도 성격에 따라 보관 기간이 모두 다를 수 있습니다. 또한 각 마이크로 서비스에서 관리하는 데이터가 추가 혹은 변경될 때마다 데이터의 보관 기간을 직접 관리하는 것은 부담이 될 수 있습니다. 해당 문제를 해결하고자 아래 구조를 설계하였습니다.
Privacy Type
데이터의 성격에 따라 부여되어야 할 개념인 Privacy Type을 각 데이터에 부여하고 각 타입 별로 보관 기간을 정의합니다. 예를 들어 User 테이블 혹은 User 테이블의 특정 필드의 Privacy Type이 AAA라면 n일 보관하고 삭제되며, 유저의 결제 기록은 다른 Privacy Type인 BBB를 부여하여 m일 동안 보관하고 삭제합니다. 각 데이터가 어느 Privacy Type을 부여받을지는 Privacy 담당자와 확인합니다.
예약
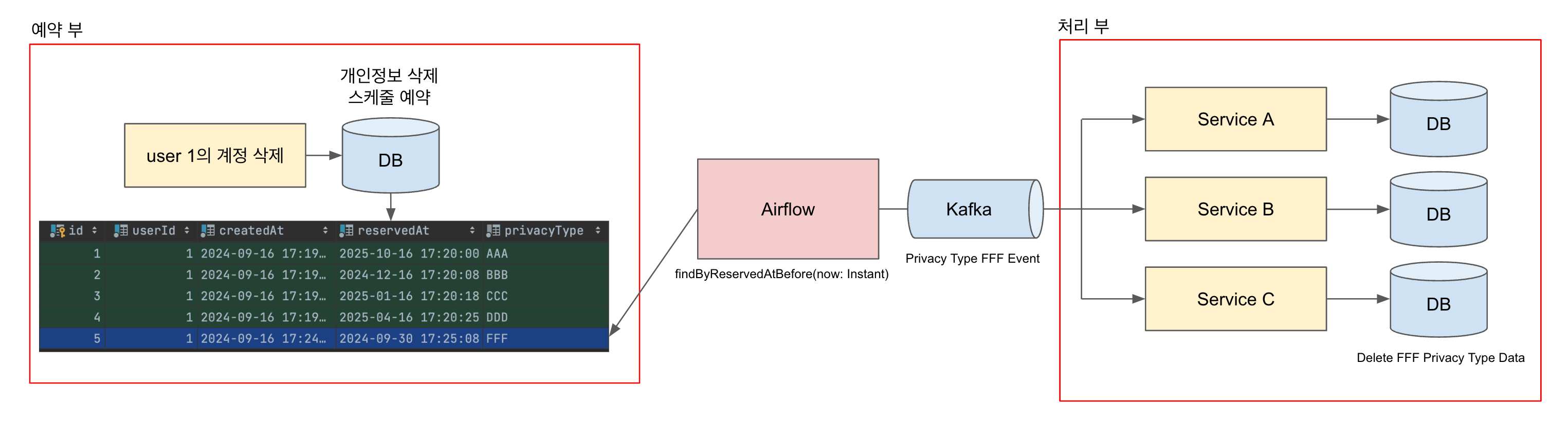
이벤트 발행을 담당하는 쪽에서는 데이터 삭제에 대한 책임이 없어야 하고, 데이터 삭제를 담당하는 컨슈머 쪽에서는 데이터 예약에 대한 책임이 없어야 합니다. 그러므로 삭제 예약을 하는 시점에 모든 Privacy Type에 대해 각각의 타입별 보관 기간에 따라 예약을 진행하고, 각 Privacy Type에 대한 이벤트를 배치에서 발행하도록 합니다.
이후 이벤트 예약부는 새로운 데이터 성격이 필요하여 신규 Privacy Type이 생기지 않는다면 데이터 삭제를 위한 추가 작업을 진행할 일이 없고, 컨슈머 쪽에서는 보관 기간이나 시점 등을 고려할 필요 없이 새로운 데이터가 추가되는 시점에 Privacy Type을 정의하고 삭제 작성을 진행만 하면 됩니다.
정리하면 개인정보 삭제 예약 요청에 대한 Trigger Transaction 이 정상 수행되면 아래 테이블에 각 유저별 예약 데이터가 Privacy Type의 수만큼 저장됩니다.
/**
* 테이블 명세 예시입니다.
* user 별로 Privacy Type의 enum 수만큼 한 번에 저장(예약)합니다.
* Privacy Type에 따라 reservedAt은 각각 다르게 설정됩니다.
*/
class PersonalInfoDeleteSchedule(
val userId: Long,
val createdAt: Instant,
/**
* 개인정보 삭제를 실제 처리할 예약된 시간
*/
val reservedAt: Instant,
/**
* 개인정보 삭제가 되는 이유
*/
val cause: String,
/**
* 개인정보 삭제 예약에 대한 조건
*
* ex. 유저의 탈퇴 요청
*/
val triggerType: TriggerType,
/**
* Privacy Type
* 컨슈머에서는 해당 타입에 따라 데이터를 삭제한다.
*/
val privacyType: PrivacyType,
// ...
)
배치가 돌며 위 데이터를 조회하고 현재 시점이 reservedAt 이후라면 위에서 설명했던 PERSONAL_INFO_DELETED 이벤트를 발행합니다. 컨슈머들은 이벤트를 받으면 Privacy Type에 따라 분류된 유저의 데이터를 삭제합니다.
데이터 삭제
데이터는 Privacy Type 별로 다른 보관 기간을 가지게 되며, 각 마이크로 서비스에서는 해당 서비스가 가지고 있는 데이터의 Privacy Type에 맞는 데이터 삭제를 구현합니다. 예를 들어 특정 마이크로 서비스에서는 레코드 전체가 같은 보관 기간이 아닌 각 필드별로 다른 보관 기간이 필요하고, 특정 필드가 NOT NULL 등의 요구사항으로 하드 딜리트가 아닌 소프트 딜리트가 필요하더라도 각 마이크로 서비스에서 상황에 맞게 구현이 가능합니다. 이것으로 DLP 요구사항을 충족할 수 있습니다.
fun deletePersonalInfo(
privacyType: PrivacyType,
userId: Long,
) {
val rateLimiter = RateLimiter.create(THROUGHPUT) // 처리량 조절
if (privacyType == PrivacyType.AAA) {
findBy(userId).forEach {
rateLimiter.acquire()
delete(it)
}
// ...
} else if (privacyType == PrivacyType.BBB) {
// ...
}
}
무손실
이벤트 발행 보장
계정 삭제나 제재 요청 등이 정상적으로 수행된 후에 개인정보 삭제 예약 스케줄을 MySQL 테이블에 저장합니다. 이 테이블을 기반으로 트랜잭셔널 아웃박스 패턴을 구현하고, 또한 Kafka Producer의 ack level을 all로 설정하여 어플리케이션으로부터 Kafka Broker까지의 이벤트가 손실되지 않도록 합니다.
이벤트 처리의 무손실 보장
컨슈머에서는 이벤트를 받아 올바르게 모든 데이터가 삭제되었을 경우에만 커밋을 하고(Manual Commit) 데이터를 올바르게 삭제하지 못한 경우 계속 재시도 하거나 DLQ(Dead Letter Queue) 등을 사용하는 전략을 사용합니다.
아래 예시는 Spring Kafka 기반에서 높은 처리량을 위해 Batch Listener를 사용하고, 모든 데이터에 대한 삭제 보장을 위해 데이터들을 순차 처리합니다. 재시도하여 처리 가능한 이벤트와 처리 불가능한 이벤트를 구분하고 재시도하여 처리 가능한 이벤트는 nack을 사용하여 다음 배치 리스너에 들어오는 이벤트의 offset이 nack 한 시점부터 다시 처리할 수 있도록 구성했습니다.
/**
* 스프링 카프카 배치 리스너에서 무손실을 구현한 코드입니다.
* 무손실을 구현 전략으로 처리 가능한 이벤트는 성공할 때까지 재시도 하고 처리 불가능한 이벤트는 의도하에 버려지도록 구현했습니다.
*/
@Component
class DeleteAccountEventHandler @Autowired constructor(
private val dataLifeCyclePolicyService: DataLifeCyclePolicyService
) {
@KafkaListener(
topics = ["topic"],
groupId = "group-id",
containerFactory = "avroBatchKafkaListenerContainerFactory"
)
fun handle(
records: List<ConsumerRecord<AccountEventKey, AccountEventValue>>,
acknowledgment: Acknowledgment
) {
// nack 을 사용하기 위해 이벤트별 index를 구합니다.
val validEventMessages = records
.mapIndexed { index, consumerRecord -> index to consumerRecord.value() }
.filter { it.second != null }
.filter { it.second.status == AccountEvent.Status.PERSONAL_INFO_DELETED.name }
if (validEventMessages.isNotEmpty()) {
validEventMessages.forEach { (index, it) ->
try {
dataLifeCyclePolicyService.deletePersonalInfo(
it?.personalInfoDeletedInfo?.privacyType,
it.userId,
)
} catch (ex: IllegalArgumentException) {
// 재시도 시 처리 불가능한 이벤트는 exception을 받아 넘어가 다음 이벤트 처리를 유도합니다.
log.error("deletePersonalInfo failed by IllegalArgumentException. event: $it, ex: $ex")
} catch (ex: Exception) {
// 재시도 시 처리 가능한 이벤트는 그전까지 성공한 이벤트들을 모두 commit 하고 다시 재시도를 시키는 nack 을 사용하여 실패 시점부터 재시도 하도록 합니다.
log.error("DeleteAccountEventHandler: $ex")
acknowledgment.nack(index, NACK_SLEEP_MS)
return
}
}
}
/** 모두 성공한 경우 최종 커밋 합니다. **/
acknowledgment.acknowledge()
}
companion object {
private const val NACK_SLEEP_MS = 50L
}
}
At Least Once
여기까지의 구현으로는 Exactly Once를 보장할 수 없지만, 요구사항으로 특정 유저 군에 대해 개인정보 삭제 예약 이벤트들이 다시 발행될 수 있다고 하였으니 Exactly Once 구현은 불필요합니다. 중복해서 이벤트가 들어왔을 때 문제없도록 각 컨슈머에서 적절히 구현합니다.
백필 (Backfill)
하이퍼커넥트에서는 Data Lakehouse로 Databricks를 사용하고 있습니다. 데이터들은 메달리온 아키텍처를 기반으로 구성되고 있으며, 브론즈 레이어에서는 소스 시스템(S3, DB, Kafka 등)에서 Databricks로 sync 됩니다. (이번 글에서는 메달리온 아키텍처나 Databricks에 대한 내용을 자세히 다루지는 않습니다.)
DLP에서는 브론즈 레이어에서 RDBMS 기반의 User 테이블과 동일하게 sync 하고 있는 테이블과, 분석용 데이터 및 카프카 이벤트를 사용하여 구성된 테이블을 사용합니다.
특정 이유로 DLP를 다시 재수행 해야 한다면 해당 테이블들을 조인하여 원하는 유저 군을 서비스 영향 없이 대규모로 쿼리 할 수 있으며, 추출된 내용을 이벤트로 발행할 수 있습니다. 이벤트 발행은 Databricks의 notebook을 사용하여 파이썬 코드를 실행시키는 것으로 수행합니다.
1. Databricks에서 원하는 유저 군을 쿼리 합니다. (ex. 2024년 9월 이후에 해당하는 DLP 적용 대상에 대한 유저군 가져오기)
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, lit
# 1. 대상 유저 id 추출
query = """
select userId from x, y where deletedAt > '2024-09-01' and deleted = true and ...
"""
df = spark.sql(query)
2. 유저 식별자를 추출하여 이벤트 DTO를 만듭니다.
from pyspark.sql.functions import to_json, struct
json_df = df.withColumn("value", to_json(struct(*[col for col in df.columns]).alias("id"))) \
.selectExpr("CAST(id AS STRING) as key", "CAST(value AS STRING) as value")
json_df.display()
json_df.count()
추출한 유저 식별자를 출력하여 확인할 수 있게 구성되어 있습니다.
3. 만들어진 이벤트 DTO를 카프카 이벤트로 발행합니다.
from pyspark.sql.functions import col, expr
kafka_topic = "topic-name"
kafka_servers = "url"
json_df.write \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("topic", kafka_topic) \
.save()
4. 이벤트를 받은 백필 컨슈머에서는 넘어온 유저들에 대해 개인정보 삭제를 예약합니다.
마찬가지로 빠르게 수행되어야 하기보단 손실이 없어야 하며, 받는 컨슈머 쪽에서 부하가 없는 것이 중요하기 때문에 처리하는 쪽에서는 Rate Limiter를 달아 처리 속도를 조절합니다. 다만 모든 컨슈머가 Rate Limiter를 달았는지 지속 추적이 불가능하기 때문에, 발행부에서도 안전장치로 Rate Limiter를 달아 발행량을 조절합니다.
모니터링
메트릭 모니터링
/**
* 남기는 시점: 개인정보 삭제 예약을 완료한 직후
*
* @property userId 삭제 예약된 userId
* @property reservedAt 삭제 예약 날짜
* @property triggerType 삭제 타입
* @property privacyType privacy type
* ...
*/
class PersonalInfoDeleteScheduleLog(
val userId: Long,
val reservedAt: Instant,
val triggerType: TriggerType,
val privacyType: PrivacyType,
// ...
)
예약부에서 스케줄을 정상적으로 예약하면 위의 명세로 카프카 이벤트를 발행하고 Databricks에 Sync 합니다. Sync 된 데이터를 대시보드에 그려 실시간으로 처리량을 모니터링할 수 있습니다.
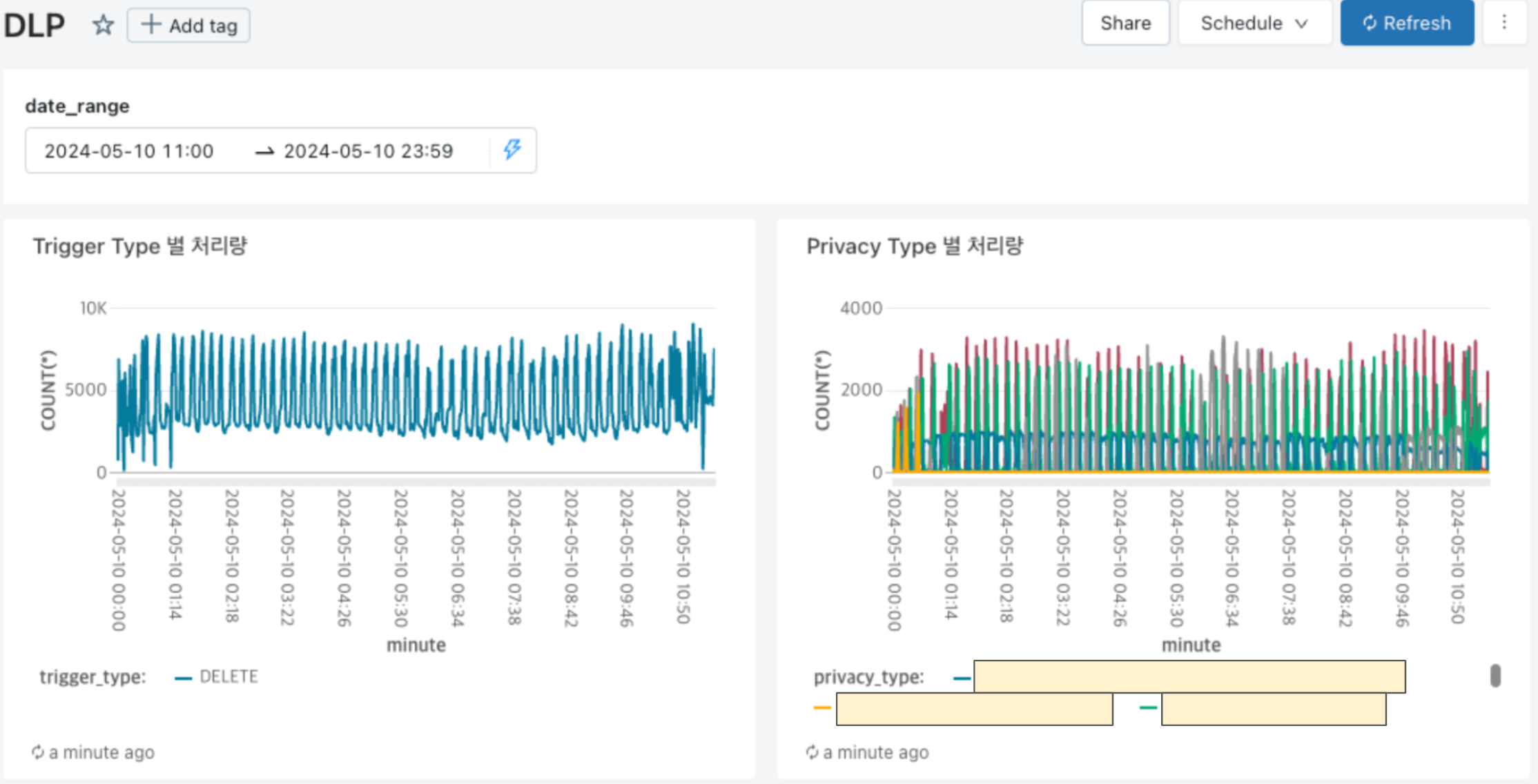
삭제 검증
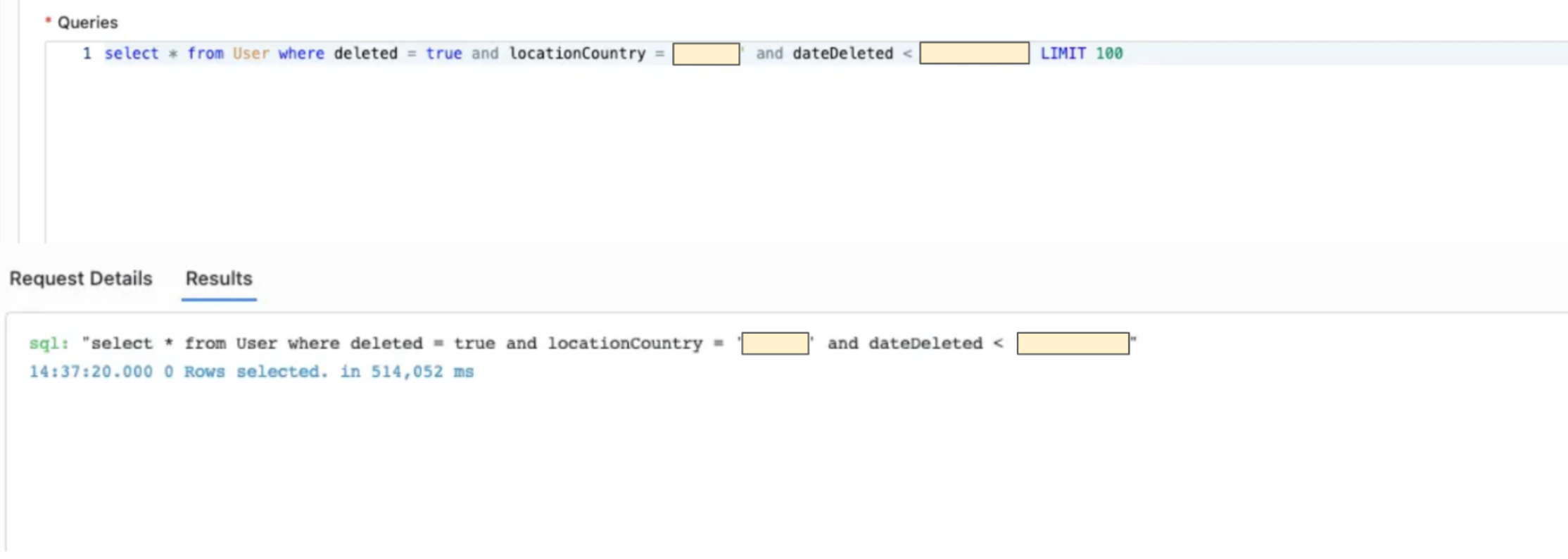
각 마이크로 서비스에서의 검증은 계정 삭제 날짜인 dateDeleted를 이용해 이미 삭제되었어야 할 유저 군을 추출하고 해당 데이터가 남아있는지 검증이 필요한 테이블에서 쿼리하여 체크하거나, 제거되었을 것으로 예상되는 쿼리를 수행하여 정말로 데이터가 안 나오는지 체크합니다.
아래는 특정 날짜 이후 삭제되어야 할 데이터가 정말로 삭제되었는지 Replica Production Database에서 Full Scan을 수행했던 쿼리 예시입니다.
정리하며
이렇게 각 기능 / 비기능 요구사항을 모두 만족하는 구성으로 DLP를 구현했습니다.
실제로는 API 팀에서 다루는 30개가 넘는 마이크로 서비스에서 삭제를 실수 없이 구현해야 하고, 억 단위의 배치를 몇 번이나 유저에게 영향 없이 효율적으로 처리해야 했기 때문에 많은 고민이 있었습니다.
그럼에도 대용량 데이터나, 특수한 트래픽 문제를 해결하는 일은 언제나 즐거운 일입니다. 다음 글에서는 백필 파트의 효율적인 대규모 배치 처리와 분석용 데이터에 대한 DLP 적용을 남기면서 글을 마치겠습니다. 읽어주셔서 감사합니다.
Read more
-
Spring Transactional Rollback Deep Dive
Spring Transactional Rollback 이 되는 케이스를 심층적으로 살펴보고 예시로 확인해봅니다.