글로벌 서비스에서 지역 통신사 네트워크 이슈 트러블슈팅하기
안녕하세요, SRE 팀의 Ken.K입니다. Hyperconnect의 Azar 서비스는 전 세계에서 서비스를 하고 있기 때문에 국가별로 서버 메트릭이나 클라이언트에서 수집하고 있는 이벤트 데이터를 기반으로 모니터링하고 있습니다. 따라서 대부분의 국가별 이슈를 준 실시간으로 마주하고 대응해나가고 있습니다.
때는 2024년 1월 어느 날, 내부 CS 논의 채널을 통해 수상한 제보가 들어왔습니다.

바로 담당 팀들은 트러블슈팅을 시작했고, 다음과 같은 정보를 얻어냈습니다:
- 하이퍼커넥트 내의 컴포넌트 A 관련 오류인 것
- 몇몇 에러 메세지가 클라이언트쪽에서 상당히 많이 발생하고 있었던 점
하지만 이상했던 점은 문제가 발생한 시기를 전후로 A 컴포넌트의 변경 사항이 없었고, XY 국가의 아주 일부 유저들만 해당 문제를 겪고 있다는 것이었습니다. 당장 심각하게 서비스 지표가 안 좋아진 부분은 발견하지 못했고, 아주 소수의 CS였기 때문에 특별한 단서를 찾지 못한 채 다들 각자의 업무로 돌아갔습니다.
그리고 2024년 중순, CS가 지속적으로 들어오고 있고 그 빈도가 점점 늘어나고 있다는 리포트가 올라옵니다. 관련 CS 건수는 12월 말에 x건에서 3월 셋째 주까지 선형적으로 증가하고 있었습니다.
기존에 우리가 가지고 있는 모니터링 기법으로는 지역 네트워크의 일부만 발생하는 것들에 대해 추적할 수 있는 도구를 가지고 있지 않았고 문제 원인의 실마리를 찾지 못하면 해당 국가에 외부 출장까지 고려해야 하는 심각한 상황이었습니다. SRE 팀은 문제의 원인을 좁히고 이슈를 재현하는 것이 최우선 과제였습니다.
데이터 분석
먼저, 사용자가 느끼는 문제가 어떤 에러와 연결되어 있는지를 파악하는 것이 급선무였습니다. 저는 데이터 분석을 앞서서 두 가지 가설을 세우게 되었습니다.
- 아주 일부의 사용자들만 연결 문제를 겪고 있기 때문에 그들 사이의 공통점이 분명히 있을 것이다.
- CS의 빈도가 12월 말부터 3월까지 점진적인 우상향을 했기 때문에 장기적으로 증가하는 에러의 수에 집중해야 할 것이다.
먼저 CS 정보를 모아둔 시트를 탐색했습니다. 그 시트에는 에러 코드에 대한 리포트에 의하여 확실히 컴포넌트 A 관련 오류라는 힌트가 잘 나타나 있었고, 안드로이드, iOS 차이에 대한 경향성은 크게 보이지 않았습니다. 다만 눈에 띄는 점은 오류를 리포팅한 곳 중 통신사 정보가 나와 있는 사용자는 모두 한 통신사를 가리키고 있었습니다. 이 정도 감각만 잡고 클라이언트 에러 로그를 살펴보았습니다.
하이퍼커넥트는 Databricks와 사내 플랫폼의 조합으로 클라이언트에서 발생하는 에러를 준 실시간으로 분석할 수 있는 인프라가 구축되어 있습니다. 따라서 누구나 간단한 쿼리를 통해 해당 오류를 분석할 수 있었습니다.
하루 동안의 에러 로그의 빈도를 살펴보면 발생하는 수백 개의 에러 타입 중 약 20개 정도의 타입이 1000회가 넘게 찍히는 것을 확인하였습니다. 많은 사용자에게 체감이 되려면 에러 횟수가 많은 에러 타입일수록 연관이 되어 있을 가능성이 많을 것이라고 판단하였고, 일 1000회가 넘는 에러 횟수에 대응되는 타입의 추이를 뽑았습니다. 또한 platform (android/ios)마다 에러 로그를 찍는 패턴이 다르기 때문에 플랫폼별로 살펴보았습니다.
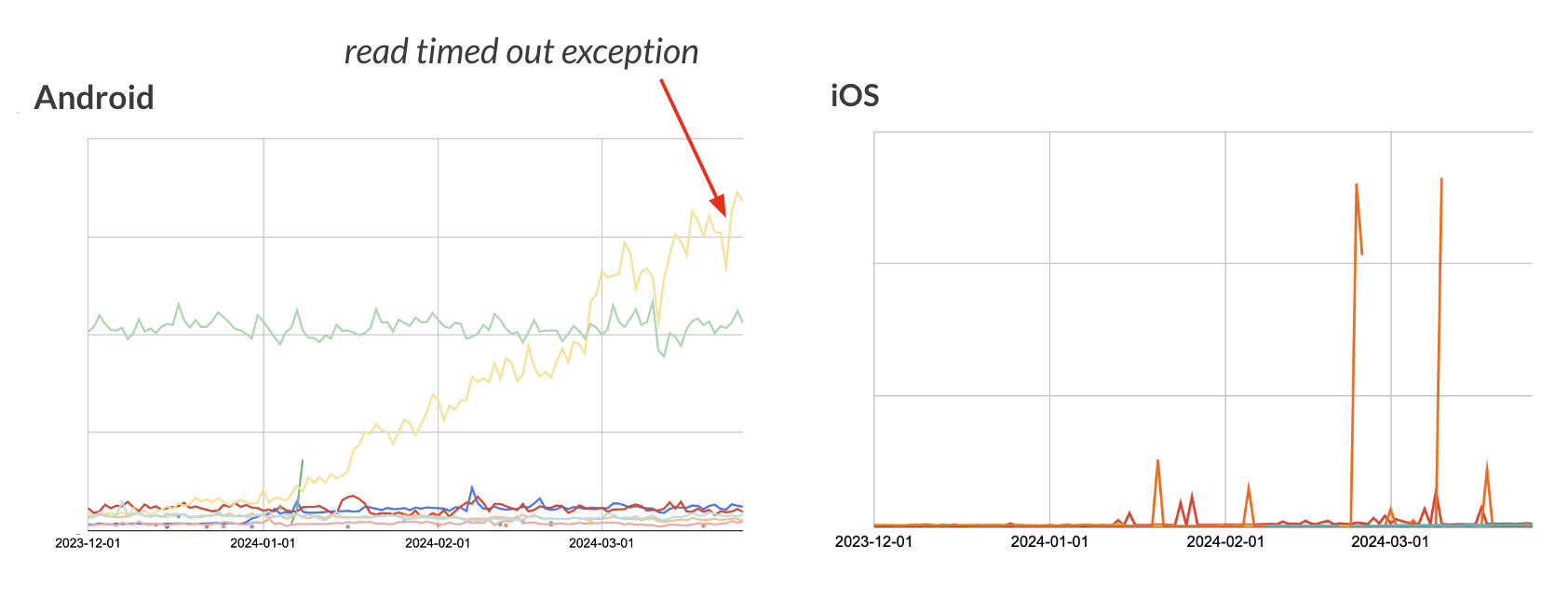
위 그림을 봤을 때, 점진적 우상향 패턴이 iOS에서는 보이지 않았고, Android의 한 사례에만 보이는 것을 확인할 수 있었습니다. 문제의 에러는 read timed out이었는데요. Android 팀과 더블체크를 해보니 컴포넌트 A와의 커넥션이 시간 내에 안 되었을 때 내뱉는 오류라는 답변을 받았습니다. 그렇다면 이 에러가 CS와 연결성을 가지고 있는지 확인하기 위해 통신사 Z에 대해 필터링을 해서 지표를 다시 뽑아봤습니다.
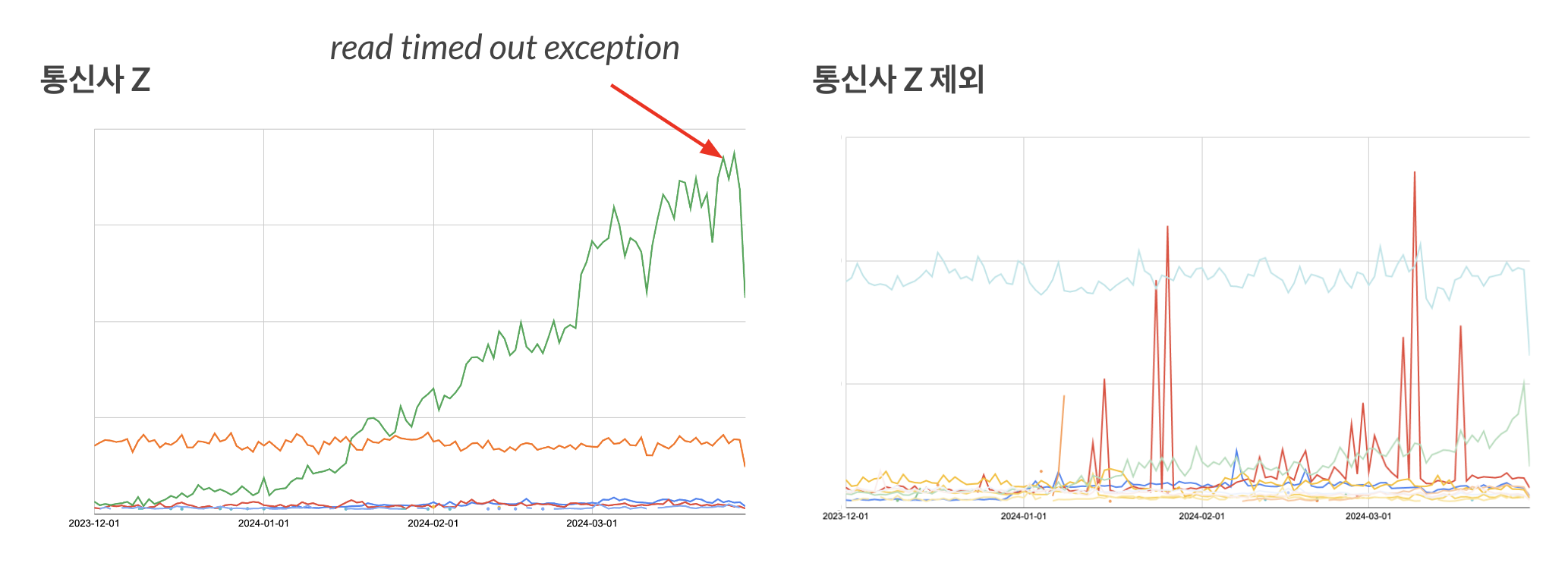
위 두 차트를 보면 통신사 Z에서 우상향하는 추이가 아주 잘 보이고 전체에서의 절대값과 매우 유사함을 확인할 수 있습니다. 이 결과를 바탕으로 timeout 에러가 연결을 경험하지 못하는 것과 연결되어 있다는 강한 추측을 하였고 조금 더 파악하기 위하여 한 명이 얼마나 동일한 문제를 반복해서 겪고 있는지를 알아봤습니다.
2024년 3월 26일 기준 오류 횟수에 따른 유저 수 분포
| 오류 횟수 | 1 | 2 ~ 10 | 10 ~ 100 | 100 초과 |
|---|---|---|---|---|
| 유저 수 | 1322 | 1471 | 798 | 147 |
오류가 딱 1번만 발생한 경우가 절반이 안 되고, 10번이 넘는 에러를 겪은 사용자가 900명이 넘는 것으로 봐서 반복적인 오류로 인해 Azar 앱 사용이 불가한 상태임을 예상할 수 있었습니다.
여기까지 파악하고 본격적으로 왜 timeout이 발생하고 있는지에 대한 탐구를 시작했습니다. 자세한 내용을 다루기 전에 mobile proxy에 대한 이야기를 잠시 하려고 합니다.
Mobile Proxy의 활용
저희는 지역 네트워크의 연결성을 모니터링하기 위하여 기존에 사용하던 솔루션이 있었습니다. 그러나 이 솔루션은 데이터센터에서부터 제한된 프로토콜에 대한 통신을 지원하는 솔루션이었고 A 컴포넌트와의 연결은 STOMP 프로토콜을 통한 통신이었기 때문에 모바일 환경에서 해당 통신을 테스트하기는 어려웠습니다. 따라서 저희는 다른 솔루션을 검토할 수밖에 없었고 SOCKS5 프로토콜을 제공하는 mobile proxy 솔루션을 이용하게 되었습니다.
SOCKS?
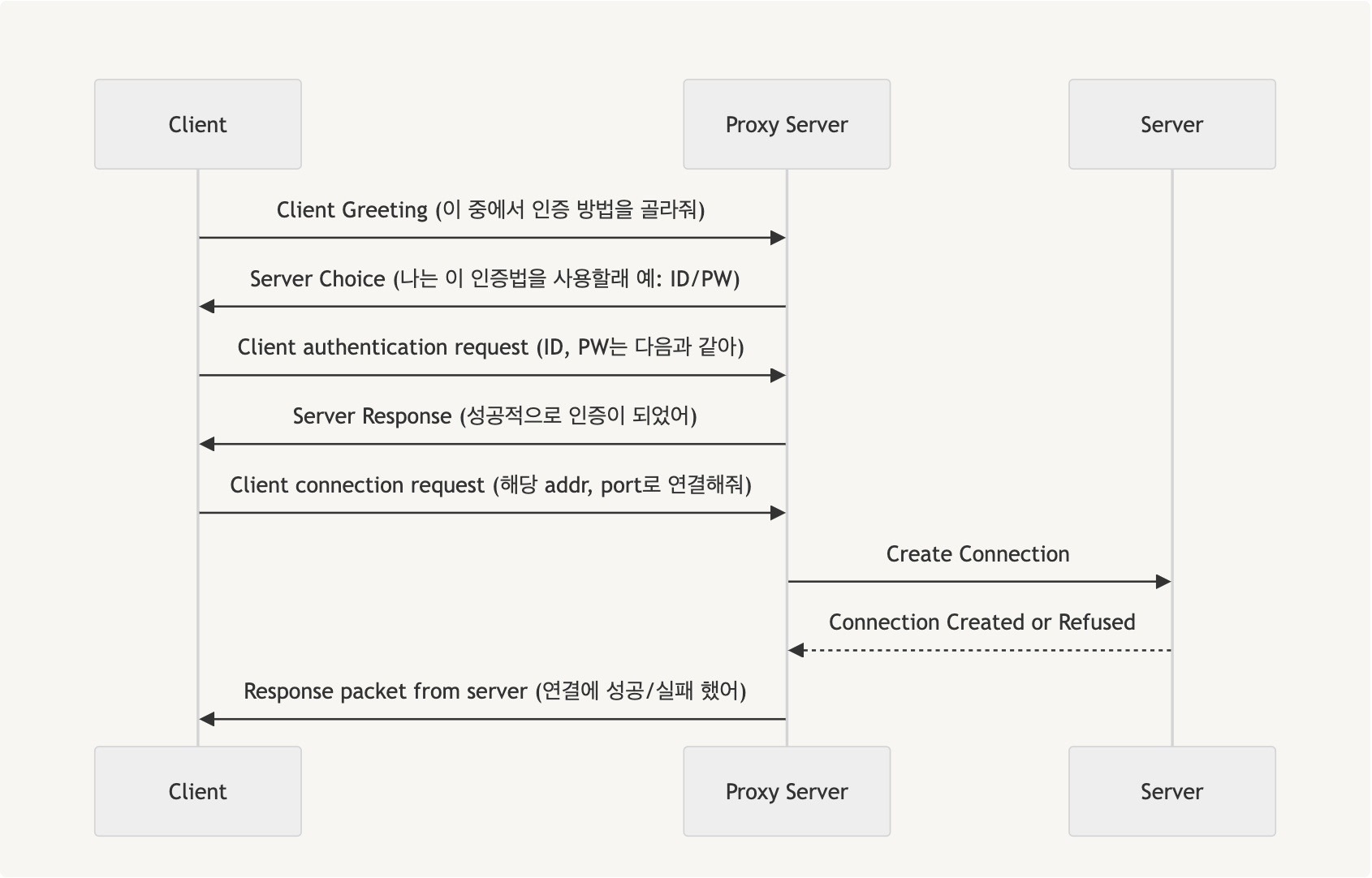
SOCKS는 proxy server를 통해 client와 server 간의 패킷을 교환하는 프로토콜입니다. 그중에서도 SOCKS5 protocol은 SOCKS에 인증이 추가된 방식입니다. SOCKS5의 handshake는 아래의 그림과 같이 요약할 수 있고 handshake가 모두 끝나게 되면 proxy 서버가 데이터를 받아서 relay를 해주게 됩니다.
Oxylabs
Oxylabs는 국가별 임의로 모바일 SOCKS5 proxy를 제공해주는 SaaS 솔루션입니다. 각국에 있는 모바일 기기가 proxy가 되기 때문에 보안적으로 문제가 되지 않는 선에서 connectivity를 체크하기에 아주 적절한 방식입니다. 제공해주는 인터페이스도 아래와 같이 간단합니다.
curl -x socks5h://pr.oxylabs.io:7777 -U "customer-USERNAME-cc-FR:PASSWORD" ip.oxylabs.io/location
저희는 Oxylabs가 제공해주는 mobile proxy 인터페이스를 이용하여 XY국가의 지역 네트워크에서 트러블슈팅을 진행하기로 했습니다.
Troubleshooting
Global Accelerator 적용
사실 앱과 서버 사이의 통신에서 네트워크에 영향을 미칠 수 있는 구간은 꽤 많습니다.
모바일 디바이스 ↔ 지역 기지국 ↔ 지역 ISP ↔ 인터넷 백본 ↔ AWS VPC ↔ 서버 어플리케이션
일단 A 컴포넌트는 모든 국가의 트래픽을 다 받고 있었기 때문에 이 이슈가 애플리케이션 문제가 아닐 것이라고 결론지었습니다. 또한 장기적으로 나타나는 것이기 때문에 AWS 단의 outage는 아닐 것이라고 판단하였습니다. 그렇다면 더욱 구간을 좁히려면 지역 ISP로부터 인터넷 백본을 거쳐서 AWS VPC로 오는 구간을 바꿔볼 수 있습니다. 이를 위해 Global Accelerator를 활용하여 지역 네트워크에서 바로 AWS 회선으로 연결되도록 했습니다. Azar는 국가별로 해당 컴포넌트의 통신 경로를 설정할 수 있도록 되어 있었기 때문에 바로 적용해서 경과를 지켜보았고, 에러 추이에 대한 변동은 발견하지 못했습니다. 따라서 지역 ISP로부터 우리 인프라 구간까지의 이슈는 없으며 지역 네트워크 안에서 발생한 이슈로 좁힐 수 있었습니다.
더 나아가서 해당 유저가 모든 통신에 대하여 timeout 에러가 발생하는 것이 아니라 STOMP 통신에 대해서만 timeout이 발생하고 있었기 때문에 클라이언트의 설정과 지역 네트워크 상황의 조합이 이 문제의 핵심일 것이라고 판단을 했고 최대한 실제 설정과 동일한 환경을 만들어서 이슈를 재현하는 것이 시급한 과제가 되었습니다.
이슈의 재현
Azar 팀은 STOMP 통신을 내부적으로 테스트하기 위해 golang 기반의 스크립트를 운영하고 있었습니다. 기존 스크립트에 SOCKS5 프록시를 연결하도록 코드를 수정하였고, connect 요청 전에 https://ifconfig.co/json 에 HTTP GET 요청을 하여 내가 연결한 모바일 디바이스의 네트워크 정보를 가져왔습니다. Oxylabs에서 제공해주는 mobile proxy는 등록되어 있는 통신사까지 정할 수는 없었기 때문입니다.
수많은 proxy user를 생성해서 연결 테스트를 수행한 결과 통신사 Z의 특정 IP 대역 (IP 대역에 대한 정보를 찾아보니 3G IP pool에 해당)에 접속한 모바일 디바이스에만 응답이 아주 늦게 (40초 ~ 2분) 돌아오는 것을 확인할 수 있었습니다. 그리고 해당 통신에 대한 timeout 설정은 이보다 훨씬 적었기 때문에 모두 timeout이 날 수밖에 없는 구조였습니다. 한 번 안되는 유저에 대해서는 요청을 반복해도 계속 응답이 느린 것을 확인할 수 있었고, 이는 이전에 데이터 분석 단계에서 보였던 한 유저가 같은 오류를 여러 번 겪는 상황도 이해할 수 있었습니다.

문제의 원인
먼저, root cause를 발견할 수 있었던 것은 저 혼자 이 트러블슈팅에 참여한 것이 아니라 모두가 각자의 뷰를 반영하여 문제를 접근했고 다양한 시도를 해봤기 때문에 가능했습니다. 처음 이상함을 발견한 것은 준비한 스크립트로 SOCKS proxy를 날리지 않고 curl 명령어를 이용하여 HTTP proxy로 요청을 하면 문제가 되는 유저에 대해서도 잘못된 연결이라는 응답이 금방 돌아온다는 것이었습니다.
그리고 제가 이슈를 재현하기 전까지 문제가 오히려 재현이 안되서 고생 중이던 코드가 있었습니다. 그래서 자연스럽게 재현이 안되는 코드와 제 코드를 비교하게 되었고 그 차이는 SSL handshake에서 Client Hello 단계에서의 SNI 포함 여부였습니다. STOMP 프로토콜 통신에서 사용하고 있던 라이브러리에서는 TLS 연결을 할 때 SNI를 포함하지 않는 것이 기본 설정이었습니다.
이 설정이 얼마 전까지 문제가 되지 않았지만 저희가 조심스럽게 추정하기로는 통신사 Z가 점진적으로 SNI 여부에 따라서 QoS pool을 조절하는 설정을 rolling update하면서 시간당 오류 수가 점점 커지는 형태라고 봤습니다.
해당 방법에 대해 구글링하여 찾아보니 예를 들어 F5사의 Local Traffic Manager와 같은 소프트웨어에서 소개하는 예시 설정을 조합하면 매우 쉽게 SNI 여부에 따라 QoS를 조절할 수 있음을 발견했습니다.
- SNI가 없는 경우 패킷 드랍: https://my.f5.com/manage/s/article/K60036398
- 특정 path의 request를 보내는 경우 특정 pool로 보내도록 설정: https://my.f5.com/manage/s/article/K15097
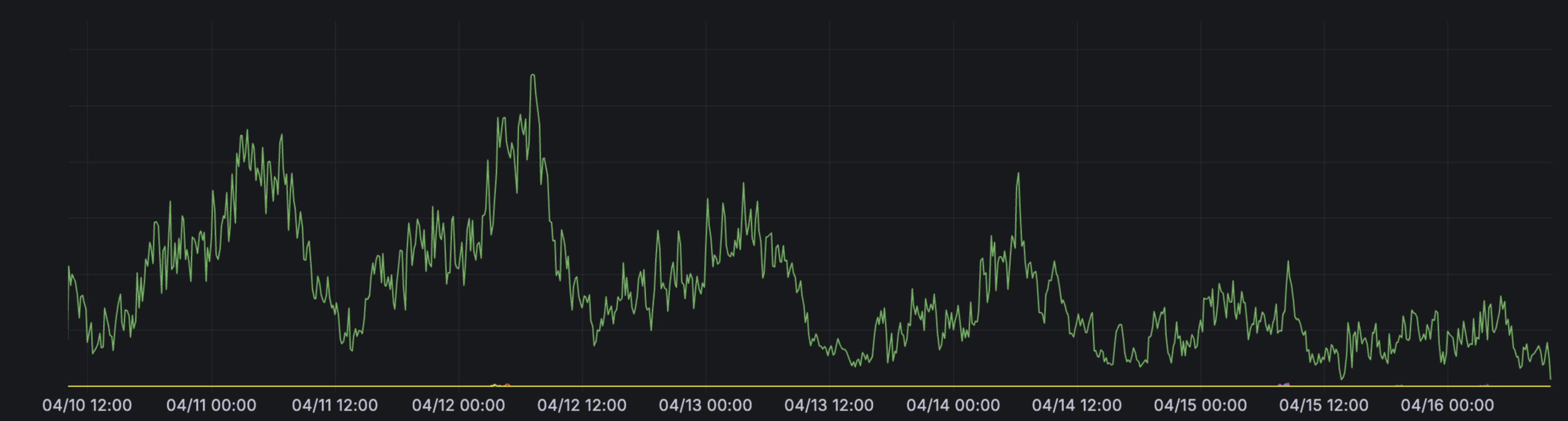
Android & iOS 둘 다 이 부분에 대한 핫픽스를 빠르게 도와주셨고 실제 SNI가 적용된 버전과 적용되지 않은 버전에 대하여 Android는 tun2socks라는 앱으로, iOS는 ShadowRocket이라는 앱으로 SOCKS 프록시를 연결해서 원하는 대로 동작의 차이가 있는지 확인한 후 배포했습니다. iOS에서 오류 패턴이 안 보였던 이유는 timeout error에 대한 리포팅을 하는 로직에 버그가 있었고 핫픽스에 이 문제가 같이 수정되었습니다. 배포 후에 adoption rate가 올라감에 따라 아래와 같이 오류 수가 점진적으로 줄어드는 모습을 확인할 수 있었고 관련 CS는 그 후로 들어오지 않아서 이 케이스를 마무리하게 되었습니다.
정리하며
위의 지역 네트워크 이슈에 저희는 다음과 같은 과정으로 문제를 해결했습니다:
- 데이터 분석을 통하여 어떤 부분을 봐야할 지 파악
- 문제의 구간을 좁히고 Mobile Proxy를 통한 문제 상황 재현
- Root Cause 파악, 테스트, 그리고 핫픽스 배포
- TTD 개선을 위한 회고
SRE 팀은 CS가 쌓임에 따라 첫 문제 발생 후 최소 3개월이 지나서야 문제를 보기 시작했다는 점에서 문제가 있다는 것을 회고 때 이야기하였고 Oxylabs와 같은 mobile proxy 솔루션을 더 적극적으로 활용하여 자동으로 글로벌 네트워크 환경에서 core component에 대한 연결성을 테스트하고 메트릭을 수집하여 장애가 났을 때 보다 빠르게 대처할 수 있도록 개선하는 것을 action item으로 잡았습니다.
글로벌 서비스를 운영하다 보면 예상치 못한 지역 네트워크의 변화로 인해 사용자가 우리 회사 인프라와의 네트워크 연결에 문제를 겪고 서비스를 제대로 이용하지 못하는 사례가 일어날 수 있습니다. 이번 이슈는 자칫하면 Azar의 주요 국가 중 하나인 XY의 유저 경험을 상당 부분 악화시킬 가능성이 있는 문제였습니다. 하이퍼커넥트의 Azar Studio와 SRE 팀은 one team으로서 뭉쳐 데이터 기반의 원인 분석과 검증으로 빠르게 대처할 수 있었습니다.
이 글 마지막도 역시나 채용공고입니다. 이렇게 가슴 뛰는 트러블슈팅을 같이할 SRE 팀의 많은 지원 부탁드립니다.
Read more
-
장애 모의 훈련 그리고 배운 점
하이퍼커넥트 내의 장애 대응 능력을 올리기 위한 첫 모의훈련, 어떻게 준비했고 무엇을 배웠는지 소개합니다.