Spring Data Redis Repository 미숙하게 사용해 발생한 장애 극복기
안녕하세요, 하쿠나 백엔드 팀의 하마입니다. 최근 하쿠나 서비스에서 사용하고 있는 Redis에서 latency가 주기적으로 치솟는 문제가 발생했습니다. 문제를 해결하는 과정에서 latency 문제뿐만 아니라 기존의 Redis 메모리 사용량도 크게 낮출 수 있었습니다. 이번 글에서는 저희 팀에서 문제를 어떻게 해결했고, 그 과정에서 얻은 Spring Data Redis Repository를 사용할 때 주의할 점에 대해 공유 드리고자 합니다.
문제 발생
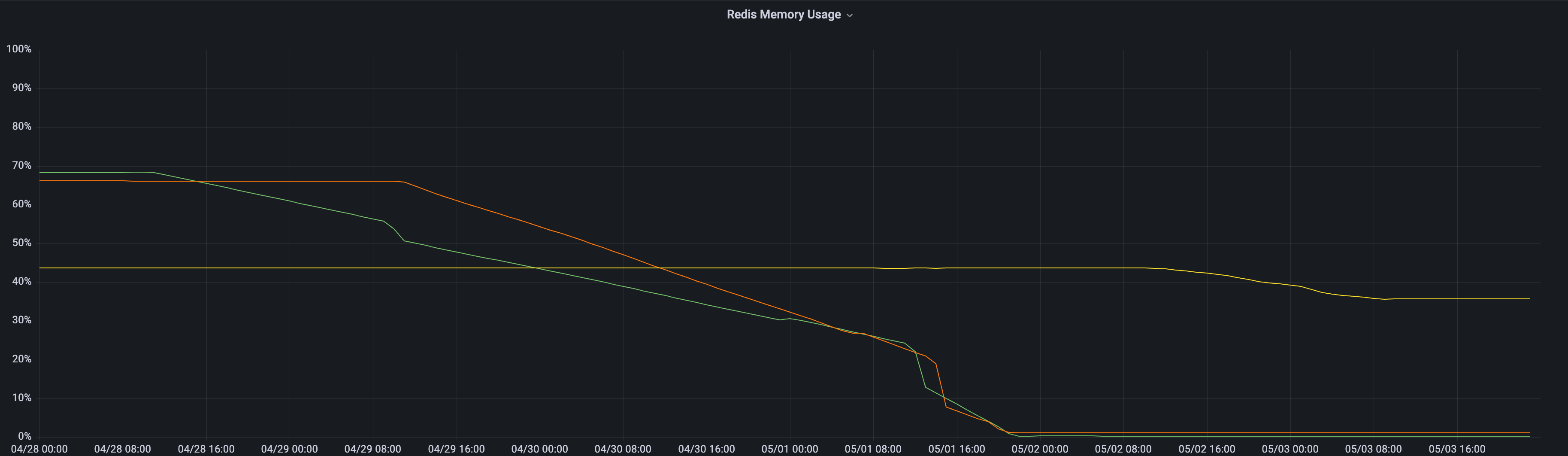
아래 그래프에서 확인할 수 있는 것처럼 특정 시간에 주기적으로 서비스 API latency가 치솟는 문제가 발생했습니다. APM의 Dependency 별 Latency 분석을 통해 Redis에서 발생한 병목 현상이 문제의 원인이란 것을 알 수 있었습니다. 하지만 Redis 사용에 영향을 줄 만한 배포나, 트래픽 패턴에도 변화가 없어 근본적인 원인을 파악하기 어려웠습니다. 그러던 와중에 스파이크가 발생하는 시간과 AWS ElastiCache 백업 시간이 일치한다는 것을 발견했습니다. 하쿠나에서는 데이터를 안전하게 보관하기 위해 이전부터 ElastiCache 백업을 주기적으로 진행했음에도 이제서야 문제가 발생하기 시작한 원인을 파악하기 위해 백업 기능의 자세한 내용을 찾아보았습니다. 확인 결과 ElastiCache는 가용 메모리가 충분하지 않은 상황에서 백업을 진행하면 forkless 기반의 백업 전략[1]을 선택하게 되는데, 이 forkless 기반의 백업은 사용자 요청의 latency와 throughput에 악영향을 준다는 사실을 파악할 수 있었습니다. 추가 모니터링을 통해 Redis 메모리 사용량이 이전부터 꾸준히 증가했고 이에 따라 가용 메모리가 부족하게 된 것을 확인했습니다.

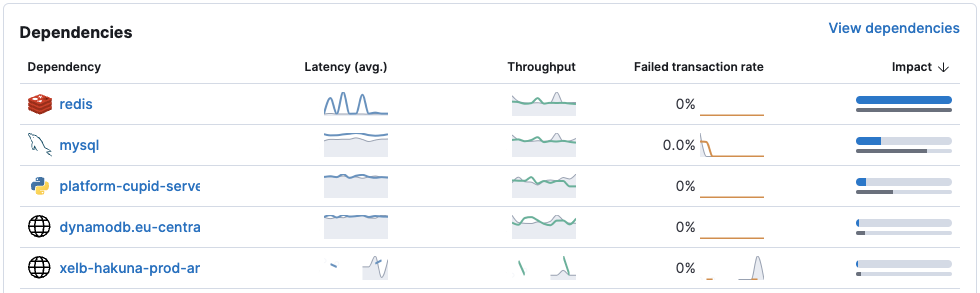
Primary 노드의 부하를 낮추자
하쿠나에서 사용하는 ElastiCache의 경우 가용성을 확보하기 위해 Auto-failover 기능을 사용하고 있습니다. 백업 외에도 서비스 요청을 처리하기에 바쁜 primary 노드와 다르게 secondary 노드의 경우 서비스 요청을 처리하지 않고 primary 노드의 데이터를 복제만 하므로 대부분 idle 했습니다. primary 노드에서 실행되던 백업을 secondary 노드에서 실행되도록 변경하면 primary 노드의 변경 사항이 secondary 노드에 늦게 전파되어 백업 데이터의 비일관성이 발생할 수 있습니다. 하지만 하루에 한 번 실행하는 백업 역시 데이터의 비일관성을 초래할 수 있는 작업이지만 이는 감수할 수 있는 범위라고 판단했습니다. 결론적으로 백업을 secondary 노드에서 실행하도록 변경해 백업으로 발생하는 병목 현상을 해결했습니다.

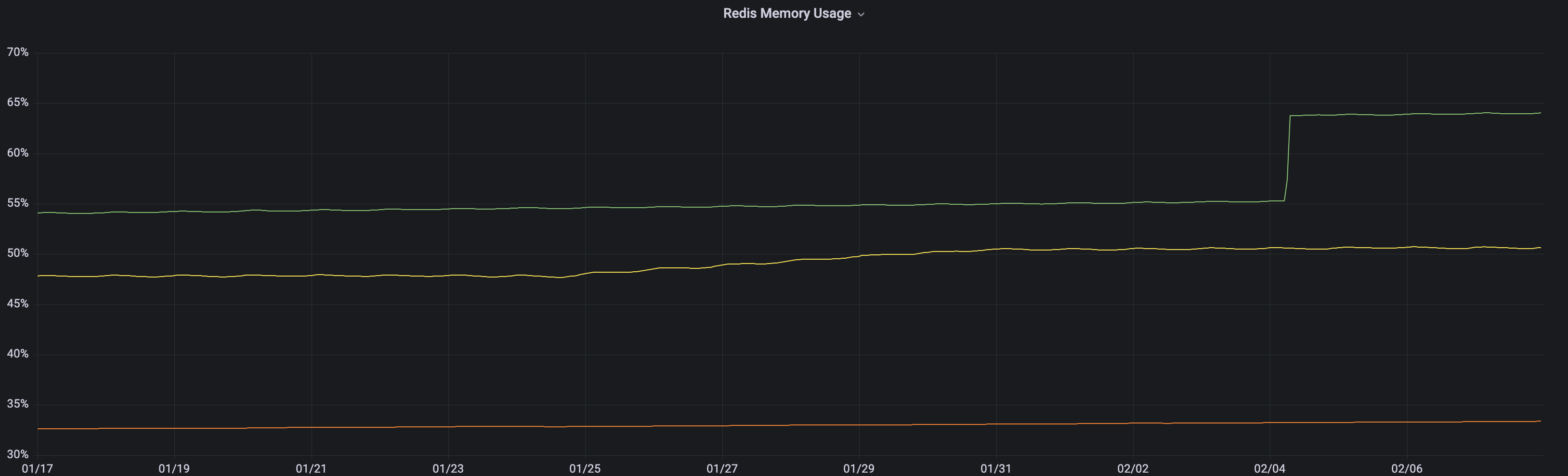
메모리 사용 증가 원인을 찾아보자
메모리 사용량 증가 원인이 TTL(Time to Live) 설정 없이 저장되어 영구적으로 보관되는 데이터에 있다고 생각했습니다. 가설을 검증하기 위해 운영 환경 데이터베이스에 TTL이 명시되지 않은 key가 얼마나 존재하는지 확인해 보았습니다. scan 명령을 기반으로 모든 key를 순회하면서 key, TTL, 데이터 타입, 메모리 사용량의 정보를 파일에 기록하는 스크립트를 작성했습니다. 스크립트 실행 결과로 얻은 key 목록과 하쿠나 서비스 코드를 분석하면서 불필요하게 저장되는 데이터가 있는지 살펴보았습니다. key 목록 분석 중 10GB 이상의 메모리를 사용하고 있는 domain_class key 패턴을 갖는 set과 domain_class:ID:phantom key 패턴을 갖는 set을 발견했습니다. 지나치게 큰 메모리를 사용하고 있는 set 데이터가 존재해 원인을 파악해 보았습니다.
Spring Data Redis Repository
위에서 말씀드린 도메인 데이터에 접근하기 위해 하쿠나 서비스에서는 org.springframework.data.repository.CrudRepository 인터페이스를 사용했습니다. CrudRepository 인터페이스는 spring data commons 모듈에 선언된 인터페이스로 데이터베이스를 다루는 데 필요한 메소드를 모아둔 인터페이스입니다. 도메인 클래스 타입과 ID 타입을 제네릭 인자로 전달하고 CrudRepository 인터페이스를 상속하면 관계형 데이터베이스부터 NoSQL 데이터베이스까지 데이터 조회 기능과 갱신 기능을 편리하게 사용할 수 있습니다. Spring Data Redis Repository 역시 CrudRepository 인터페이스에 선언된 모든 메소드를 오버라이딩 해 Redis Hash 데이터에 쉽게 접근할 수 있습니다.
Spring Data Redis Repository 내부 동작
일반적으로 Key-Value 데이터베이스는 Primary Key를 통한 데이터베이스 접근만 지원하므로 다른 데이터베이스에 비해 구조가 간단하며 성능이 뛰어납니다. 하지만 데이터의 통계 정보 조회 또는 Value 부분에 있는 특정 필드 값을 이용한 검색 기능은 Redis를 포함한 대부분의 Key-Value 데이터베이스에서 대부분 지원하지 않기 때문에 해당 기능이 필요하다면 애플리케이션 레벨에서 기능을 별도로 직접 구현해야 합니다.
CrudRepository 인터페이스는 count(통계 정보 조회) 연산과 query derivation(Value의 특정 필드 값을 기반한 조회) 연산을 추상화했기 때문에 앞서 말한 두 가지 기능을 프레임워크 레벨에서 구현했습니다. Redis의 모든 keyspace를 순회해 저장된 도메인 데이터의 수를 확인하거나 Value의 특정 필드 값으로 데이터를 검색할 수 있지만 매우 무거운 작업이 될 것입니다. Spring Data Redis Repository에서는 앞서 말씀드린 연산을 빠르게 수행하기 위해 key 값만 저장하는 set과 secondary index[2]를 추가로 이용해 primary key access만 제공하는 Key-Value 데이터베이스의 한계를 극복했습니다.
Spring Data Redis Repository를 통해 새로운 데이터를 저장하면 데이터의 key가 별도의 set에 저장되고 데이터를 삭제하면 대응되는 key가 set에서 삭제됩니다. key 값만 보관하는 set에 크기를 조회함으로써 저장된 데이터의 총수를 빠르게 알 수 있습니다. 또한 특정 필드 검색 기능을 사용하기 위해 @Indexed 어노테이션을 원하는 특정 필드에 선언함으로써 별도의 index를 생성할 수 있습니다. @Indexed 어노테이션이 선언된 도메인 데이터를 저장하면 domain_class:field_name:value 형태의 키를 갖는 index(sorted set)에 id 값을 저장합니다. 이후 필드 값으로 데이터를 조회하면 이전에 생성한 index에서 ID 목록을 반환받아 실제 데이터를 조회할 수 있습니다. 아래는 도메인 클래스의 정의와 특정 필드 값으로 데이터를 검색하는 테스트 코드를 볼 수 있습니다. redis-cli monitor를 이용해 실제 테스트 코드 실행했을 때 Redis server로 들어온 명령어 목록 또한 확인할 수 있습니다.
@RedisHash("Animal")
public class Animal {
@Id
private String id;
@Indexed
private String name;
// @TimeToLive
private long lifeSpan
public Animal(String name, lifeSpan) {
this.name = name;
this.lifeSpan = lifeSpan;
}
public String getName() {
return name;
}
}
class AnimalRepositoryTest {
@Test
void findByDerivedQuery() {
// given
String name = "hama";
Animal hama = new Animal(name, 1);
animalRepository.save(hama);
// when
Animal foundHama = animalRepository.findByName(name);
// then
assertNotNull(foundHama);
assertEquals(getName(), foundgetName());
}
}
$ redis-cli monitor
# save operation
1666705854.204093 "SISMEMBER" "Animal" "ID"
1666705854.210611 "DEL" "Animal:ID"
1666705854.213870 "HMSET" "Animal:ID" "_class" "Animal" "id" "ID" "name" "hama" "ttl" "1"
1666705854.216122 "SADD" "Animal" "ID" # add key to set
1666705854.218855 "SADD" "Animal:name:hama" "ID" # sorted set for index
1666705854.220389 "SADD" "Animal:ID:idx" "Animal:name:hama"
# query by name field
1666705854.234460 "SINTER" "Animal:name:hama"
1666705854.242417 "HGETALL" "Animal:ID"
Time To Live
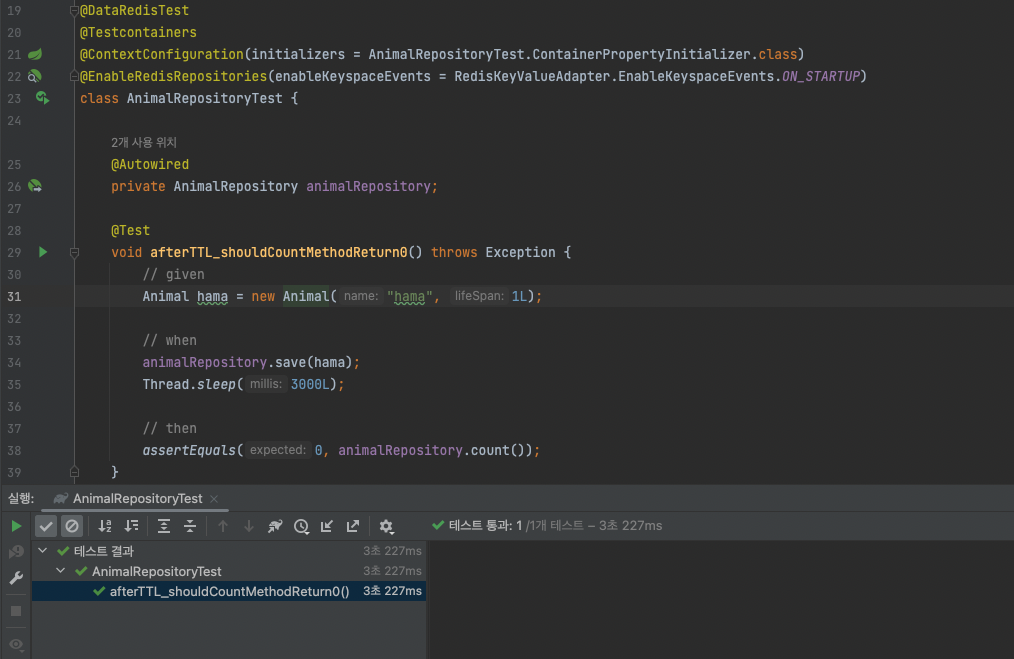
CrudRepository 인터페이스만을 이용해 데이터를 조작한다면 CrudRepository는 의도대로 잘 동작합니다. 하지만 @TimeToLive 또는 @RedisHash(timeToLive = 1) 어노테이션을 통해 데이터의 TTL을 설정한다면 오류가 발생하기 시작합니다. TTL 시간이 지나면 저장된 데이터는 제거되지만, key 목록을 관리하는 set의 element는 제거되지 않기 때문에 데이터의 정합성이 깨지게 됩니다. 아래는 count 메소드를 검증하는 테스트입니다. TTL 1초인 데이터를 저장한 뒤 3초가 지난 후에 count 메소드를 호출하면 0을 반환하기를 기대했으나 기대와는 다르게 1이 반환되어 테스트는 실패했습니다.
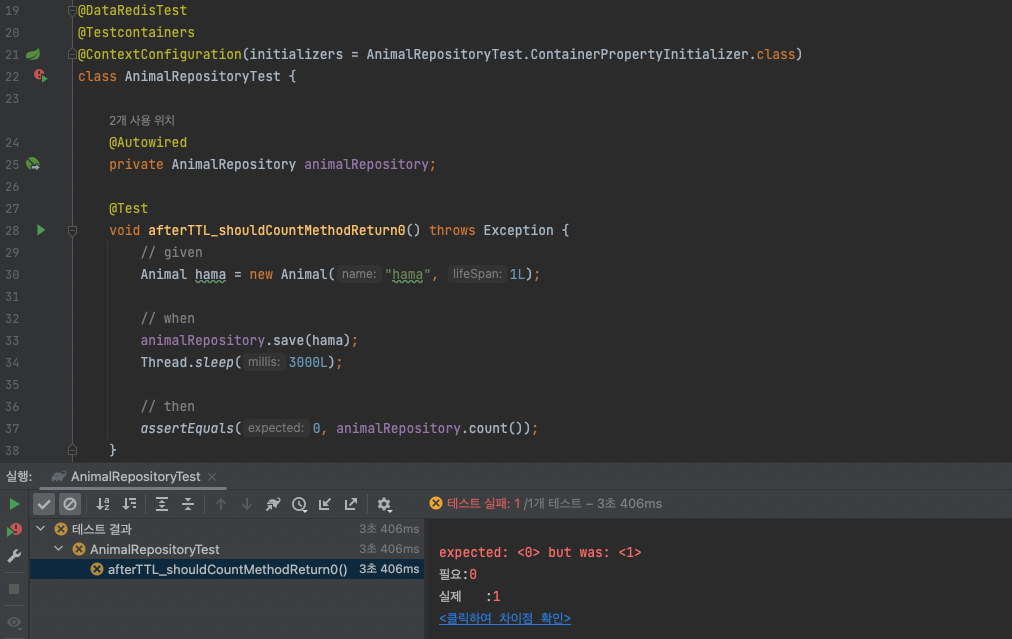
TTL을 설정한다면 Redis keyspace notification[3]을 구독해 데이터의 expire 이벤트를 수신하는 방법으로 문제가 된 set 데이터의 정합성을 유지할 수 있습니다. @EnableRedisRepositories(enableKeyspaceEvents = ON_STARTUP) 선언을 추가하는 것으로 Redis로부터 expired 이벤트를 수신할 수 있습니다. 더불어 TTL이 설정된 데이터를 저장할 때는 원본과 사본(domain class:ID:phantom) 데이터를 함께 저장합니다. 덕분에 Redis로부터 expire notification을 받았을 때 사본 데이터를 이용해 RedisKeyExpiredEvent[4]에 복원된 원본 데이터를 담아 필요한 이벤트를 발행할 수 있습니다.
$ redis-cli monitor
1666708623.152376 "PSUBSCRIBE" "__keyevent@*__:expired"
1666708623.433392 "SISMEMBER" "Animal" "ID"
# save operation
1666708623.441755 "DEL" "Animal:ID"
1666708623.447413 "HMSET" "Animal:ID" "_class" "Animal" "id" "ID" "name" "hama" "ttl" "1"
1666708623.450531 "SADD" "Animal" "ID"
1666708623.452873 "EXPIRE" "Animal:ID" "1"
1666708623.455347 "DEL" "Animal:ID:phantom"
1666708623.457286 "HMSET" "Animal:ID:phantom" "_class" "Animal" "id" "ID" "name" "hama" "ttl" "1"
1666708623.459087 "EXPIRE" "Animal:ID:phantom" "301"
1666708623.461080 "SADD" "Animal:name:hama" "ID"
1666708623.462480 "SADD" "Animal:ID:idx" "Animal:name:hama"
# when get expired event
1666708624.496305 "HGETALL" "Animal:ID:phantom"
1666708624.508926 "DEL" "Animal:ID:phantom"
1666708624.521223 "SREM" "Animal" "ID"
1666708624.523267 "SMEMBERS" "Animal:ID:idx"
1666708624.525812 "TYPE" "Animal:name:hama"
1666708624.527917 "SREM" "Animal:name:hama" "ID"
1666708624.530535 "DEL" "Animal:ID:idx"
# count operation
1666708626.477647 "SCARD" "Animal"
1666708626.518987 "PUNSUBSCRIBE"
이러한 방법으로 set의 크기를 적당하게 유지할 수 있었지만, 팀에서는 두 가지 이유로 CrudRepository 인터페이스를 이용하는 것보다 단순히 RedisTemplate을 통해 데이터에 접근하는 방법이 더 낫다고 생각했습니다. 첫 번째 이유는 Spring Data Redis Repository 인터페이스를 이용하는 비즈니스에서 CrudRepository 인터페이스에 선언된 대부분 기능을 사용하지 않고 있었습니다. 사용되지 않는 메소드를 위해 시스템 복잡도를 높일 필요는 없습니다. 두 번째 이유는 메소드의 성능 문제입니다. 위에서 본 것처럼 save 연산을 위해 의도하지 않은 불필요한 오버헤드 동작이 내부적으로 존재하고 있습니다.
가용 메모리 확보
우선 메모리 사용량 증가를 막기 위해 TTL 없이 저장되고 있던 데이터를 TTL과 함께 저장되도록 선행해서 코드를 수정했습니다. 그리고 Redis Hash CrudRepository를 사용하던 곳은 RedisTemplate을 이용해 다시 CustomRepository를 구현했습니다. 뒤이어 기존에 쌓인 필요 없는 데이터를 삭제하는 스크립트를 실행했습니다. 그 결과 3대의 데이터베이스에서 총 58GB의 가용 메모리를 확보할 수 있었고, 더 이상 메모리 사용량이 증가하지 않았습니다.
결론
지금까지 하쿠나에서 발생한 장애와 그 해결 과정과 Spring Data Redis Repository 동작 방식에 관해 설명해드렸습니다. secondary index를 프레임워크 레벨에서 관리해 주는 Spring Data Redis Repository는 TTL이 필요 없으며 쿼리 성능이 크게 요구되는 비즈니스에서 매력적인 선택지가 될 수 있을 것 같습니다. 문제를 해결하면서 Redis에 대해 많이 공부할 수 있었던 부분은 좋았지만, 한편으로 팀에서 지금까지 Redis 운영과 모니터링에 있어 미흡했던 부분들이 있어 아쉬움도 컸습니다. 흔히 알려진 내용이지만 저희가 겪은 이런 종류의 실수를 하지 않기 위해 Redis 데이터베이스를 운영하면서 주의할 점들에 대해 강조하면서 마무리하도록 하겠습니다. 읽어주셔서 감사합니다.
- 데이터 간의 관계가 있거나 데이터의 값으로 검색이 필요하다면 관계형 데이터베이스 사용하는 것을 추천해 드립니다.
- 영속성 보장이 필요한 데이터는 되도록 Redis가 아닌 on-disk 기반의 저장소에 기록하는 것을 추천해 드립니다.
- ElastiCache Snapshot을 생성해야 한다면 가용 메모리를 50% 이상으로 유지하는 것이 좋습니다.
- DEL collection과 같은 O(n) 시간복잡도의 명령으로 운영 환경 Redis가 멈추지 않도록 조심해야 합니다.
- 어플리케이션과 데이터베이스 사이에 불필요한 I/O가 없는지 주기적으로 확인해야 합니다
References
[1] https://docs.aws.amazon.com/AmazonElastiCache/latest/red-ug/backups.html
[2] https://redis.io/docs/reference/patterns/indexes/
[3] https://redis.io/docs/manual/keyspace-notifications/
[5] https://docs.spring.io/spring-data/redis/docs/current/reference/html/#redis.repositories
[6] https://engineering.salesforce.com/lessons-learned-using-spring-data-redis-f3121f89bff9/