Temporal Knowledge Distillation for On-device Audio Classification
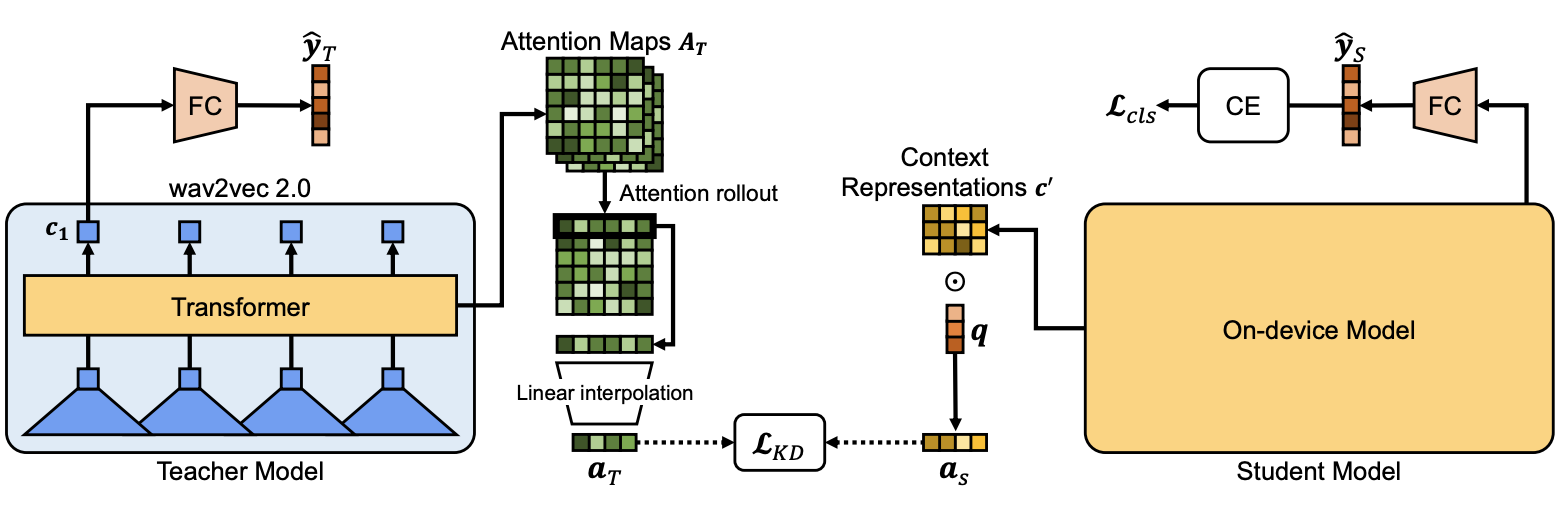 |
|---|
| Fig. 1. Illustration of our proposed model, more details below. |
We are happy to announce that our paper, “Temporal Knowledge Distillation For On-Device Audio Classification” has been accepted to ICASSP 2022!
Attention is not all you need, you also need significant computational resources
Temporal context is absolutely imperative for audio tasks, such as audio classification. Sound is essentially variations in pressure over time after all. So in order for sound to be meaningful, memory of these past changes must be considered when processing. The self-attention mechanism has lead to Transformers being at the forefront of today’s technology for audio understanding due to their ability to highlight the significance of audio features over an entire sequence. This global insight into both time and data comes at a high cost in both memory and computational needs.
The phrase “Bigger is not always better” often comes to my mind when engineering machine learning solutions for real-world applications, especially for on-device usage. Today we see a trend in the deep learning community for larger and more computationally complex deep learning models, like the transformer. Transformers are too heavy to be practical for on-device platforms, which instead commonly use lightweight CNNs and RNNs. It is important and beneficial to run ML models on the edge as they are closest to the data source, which offers high response times and user privacy. In addition, utilizing the smartphone’s computational power can offer a scalable solution for processing user data by off-loading computational and infrastructure costs.
Knowledge Distillation (KD) as model compression
For audio moderation, we use an on-device lightweight client model to isolate abusive content that is sent to a larger server-based Transformer to verify its abusiveness. When developing the client model, we found that Knowledge Distillation from the server model greatly improved performance of the client model. However, among the KD methods available, none attempted to transfer meaningful temporal context from the self-attentions of the transformer to conventional on-device architectures like CNNs and RNNs. This motivated us to develop the temporal knowledge distillation method described in this paper.
Knowledge Distillation is a model compression technique to transfer the “knowledge” from a much larger and more complex model (teacher) to a smaller and simpler model (student). Huge models have a larger set of parameters that can help them converge to a better downstream task performance than the type of lightweight models used on mobile phones. KD helps the smaller student models converge towards the more desirable optimum of the larger teacher model than they would training on the data alone, resulting in better performance without any additional computational and memory requirements at inference time.
Although there are several forms, KD is typically employed as output matching or feature-activation matching in practice. Output matching KD directs the student’s output logits to match the softmax probability outputs (soft labels) of the teacher. Output matching KD only requires both the student and teacher to have the same corresponding outputs. Feature-activation matching KD minimizes the differences between the student’s and teacher’s feature activations (i.e. between certain specific intermediate layers). Feature-activation matching KD allows for more contextual knowledge by sharing high fidelity feature embeddings as opposed to course output logits. However, Feature-activation matching KD has a significant disadvantage in that it requires both the student and teacher to have compatible intermediate features, which may be non-existent in and too computationally expensive for on-device platforms.
Temporal Knowledge Distillation
Our paper is the first to introduce a new method that distills temporal information encoded in the attentions of transformers directly into the conventional features of on-device models that may or may not have attention mechanisms. When processing audio on-device, it is common practice to split the audio into small overlapping time segments (frames) in order to process them quickly and efficiently. Distilling knowledge only from the Transformer’s logits does not convey the temporal significance of the audio frame for the specific task. Our method provides this temporal context during supervision and is shown to improve the performance of a variety of common on-device student models.
May I have your attention please
The idea is to use the student latent encodings with high dimensionally in the temporal domain, we call this the student context representations. For example, we can use the CNN feature map before the global average pooling layer. We introduce an attention mechanism to the student model during training time that acts as a conduit to distill the teacher’s attentions into the student model. The student’s attention mechanism can be discarded during deployment and inference time. To establish temporal correspondence between the student and teacher, a 1-D temporal attention representation is generated. We achieve this by using attention rollout (1) to aggregate the teacher’s multi-layer transformer attentions and use simple linear interpolation to be distilled into the student through the auxiliary attention KD loss. The final objective is a weighted combination of the task loss and the auxiliary attention KD loss. The auxiliary KD loss, Kullback-Leibler (KL) divergence loss, enforces that the attention weights of the student and teacher to be aligned, as shown in Fig. 2.
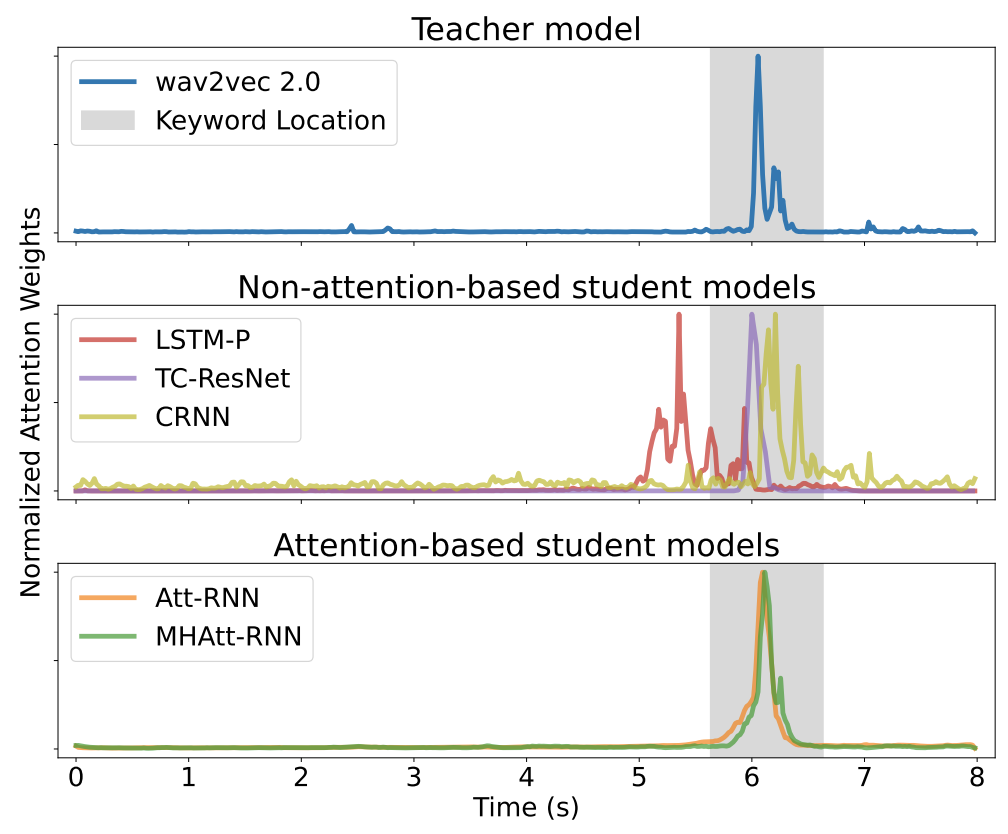 |
|---|
| Fig. 2. Visualization of attention weights extracted from multiple models. We input an arbitrary sample from the Noisy Speech Commands v2 dataset with 8 seconds noise. We plot the location of the one second keyword to all the plots. |
Evaluation Results
To demonstrate the effectiveness of the attention distillation on audio classification, we evaluated on audio event classification and long sequence keyword spotting (KWS). Our teacher transformer is wav2vec 2.0 (4) fine-tuned on the audio classification tasks. We evaluated our method on several common lightweight on-device KWS models, which served as the students. For audio event classification, we trained and evaluated on the FSD50K dataset (3). We found our method improved the on-device model’s mAP scores up to 25.3% compared with no KD applied (Table 1).
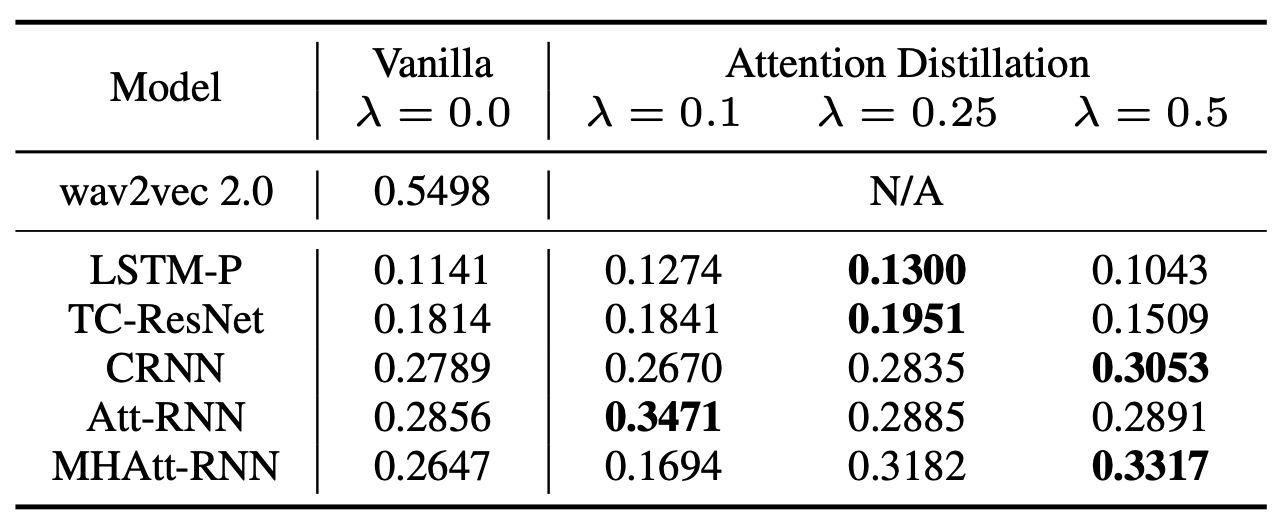 |
|---|
| Table 1. Performance comparison on the FSD50K dataset. Test mAP of the best model found by the validation is reported. |
Interestingly, we found that the KWS dataset, Google’s Speech Commands v2 (2), is trivial even for the lightest models. This is due to the simple 1-second utterances the dataset contains. We introduced a new dataset by mixing the keywords in noise of varying durations to increase the level of difficulty and to illustrate the importance of our temporal distillation method. Our method improved and in some cases outperformed the large teacher transformer in the KWS task (Table 2).
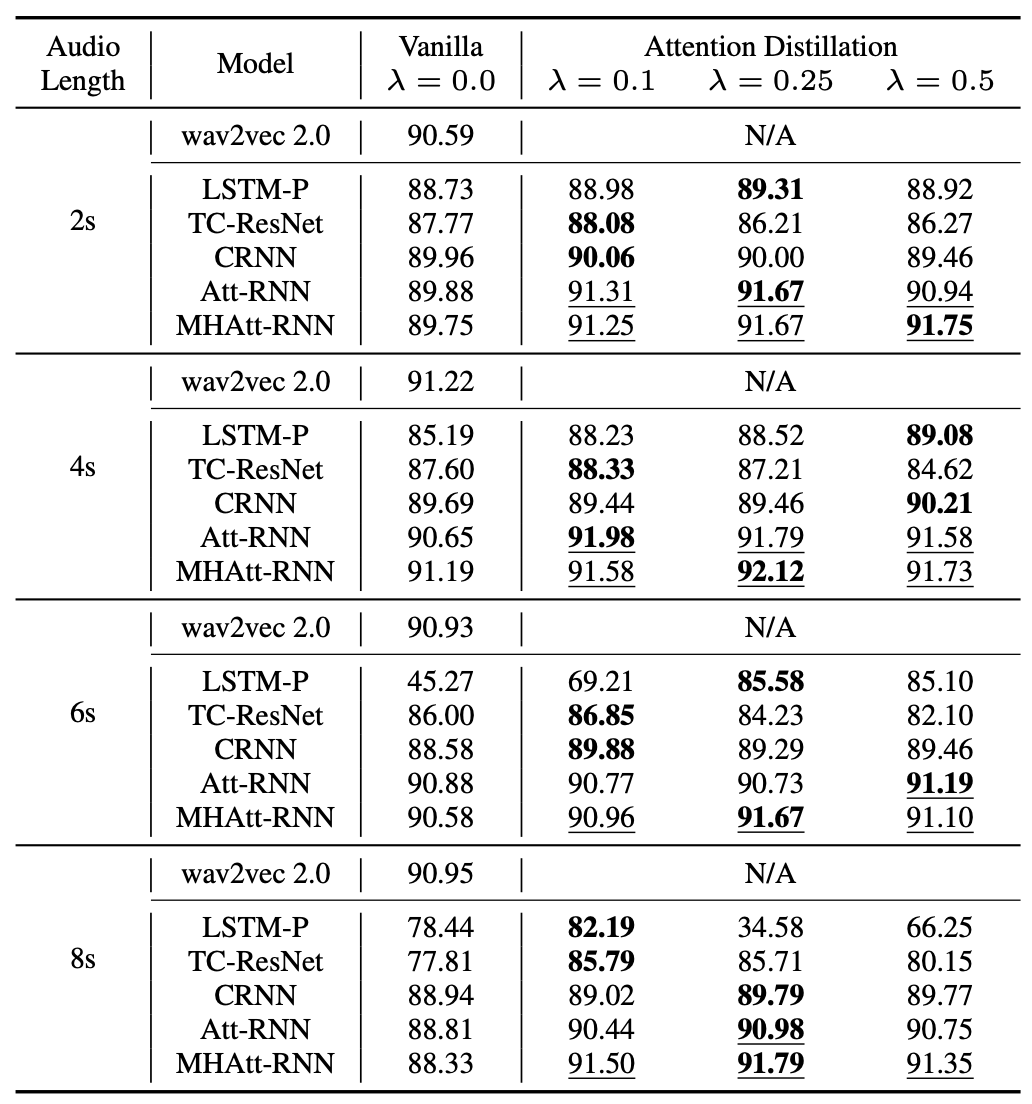 |
|---|
| Table 2. Performance comparison on Noisy Speech Commands v2 dataset. Test accuracy (%) of the best model found by the validation accuracy is reported. Best accuracies are in bold, and the performance of the student models that outperform the teacher model is underlined. |
Summary
We sought to distill the transformer’s valuable learned temporal knowledge to guide lightweight student models of any architecture for audio tasks. To solve the problem, we introduced a novel training time attention mechanism to the student to learn the temporal context in the teacher’s attention weights. Our method shows our method is effective at improving the student’s predictive performance, sometimes even outperforming the teacher model on the same tasks.
References
- Samira Abnar, Willem H. Zuidema, “Quantifying Attention Flow in Transformers.” ACL 2020
- P. Warden, “Speech Commands: A Dataset for Limited Vocabulary Speech Recognition,” ICASSP 2018
- Eduardo Fonseca, Xavier Favory, Jordi Pons, Frederic Font, and Xavier Serra, “FSD50K: an open dataset of human-labeled sound events,” ASLP 2022
- Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, and Michael Auli, “Unsupervised cross-lingual representation learning for speech recognition,” InterSpeech 2021