Few-shot text-to-speech 를 향한 여정 - Attentron
안녕하세요, 하이퍼커넥트 AI Lab 에서 machine learning engineer 로 근무하는 한승주 입니다. 하이퍼커넥트에서는 글로벌하게 많은 유저들이 사용하는 여러 소셜 디스커버리 서비스을 개발하고 있는데요, 서비스 안에서 유저들이 더 재밌게 사용할 수 있는 기능들을 만들어 주는 것이 AI Lab 의 큰 목표 중 하나였습니다. 이미 트위치와 같은 스트리밍 플랫폼에서도 음성 합성 기능을 활용하여 호스트의 목소리로 도네이션을 할 수 있는 기능이 출시된 적이 있고, 화제가 되었는데요! 올해 초 저희도 새로운 음성 합성 모델을 개발하였고 이를 회사의 라이브 스트리밍 서비스인 하쿠나에서 새로운 음성 합성 시스템을 선보였습니다. 기존의 방법들로는 한시간 이상의 스튜디오에서 녹음된 학습 데이터를 필요로 하는 반면 저희는 훨씬 적은 양의 더 쉬운 녹음 방식으로 얻은 학습 데이터로 음성 합성 기능을 제공할 수 있습니다. 이 연구를 바탕으로, 올해 10월에는 세계 최고의 음성학회인 Interspeech 2020 에서 few-shot text-to-speech 라는 주제로 연구 성과 를 발표하게 되었습니다! (데모 페이지)

이번 포스트에서는 저희가 연구한 few-shot text-to-speech 가 뭔지, 어떤 연구적인 어려움 들이 있었는지를 소개합니다.
Few-shot text-to-speech?
많은 양의 데이터가 있다면 단순한 supervised learning 으로도 학습이 잘 될 것이며, 학계에서는 충분히 갖추어진 데이터를 활용하여 좋은 성능을 내는 모델을 만드는 데 초점이 맞춰있었습니다. 하지만 실제 산업에서는 labeled data 가 굉장히 적고 레이블링 하는데에 드는 비용도 상당히 크기 때문에 아주 적은 양의 데이터만 가지고도 좋은 성능을 가지는 딥러닝 모델을 만드는 것이 매우 중요합니다. 이를 Few-shot 문제라고 부르며 저희는 음성 합성 문제를 few-shot 으로 해결할 수 있어야 서비스에 적용시킬 수 있을 것이라고 생각했습니다.
Text-to-speech, 줄여서 TTS 라고 부르는 기술은 입력된 텍스트를 원하는 특정한 목소리로 읽어주는 음성 합성 시스템 입니다. 최근 TTS 기술이 많이 발전했고 정말 사람 같은 음성을 만드는 데 성공 했지만, 여전히 이를 달성하기 위해서는 원하는 사람의 목소리를 한 시간 정도 녹음한 데이터와 그에 따른 스크립트 정도가 요구되는 상황입니다. 또한 녹음 환경에 영향을 많이 받아서 전문적인 장비가 갖추어진 스튜디오에 가서 녹음을 하는 경우가 많은데 이는 시간적으로나 비용적으로나 소모적인 작업입니다. 저희 팀에서는 특별히 녹음을 해서 데이터를 수집하지 않고 적은 숫자의 녹음된 데이터만 가지고도 학습시킬 수 있는 TTS 를 만들고 싶었기 때문에 학습에 필요한 데이터의 양을 줄이는 것이 아주 중요한 목표였습니다.
연구적 어려움
저희 팀에서 만들고자 하는 모델은 다음과 같은 조건을 충족시켰으면 했습니다.
(1) Few-shot 으로도 학습이 가능한 TTS, (2) 추가적인 학습 (fine-tuning) 단계가 없어야 함
이 주제는 현재 학계에서도 활발하게 연구되고 있는데요, 관련된 연구들 중에서 이 문제를 가장 잘 해결했다고 생각되는 연구를 두 가지 뽑아봤습니다.
- Zero-Shot Multi-Speaker Text-To-Speech with State-of-the-art Neural Speaker Embeddings [paper link]
- ICASSP 2020 에 발표된 논문으로 speaker embedding 을 speaker verification model 을 이용하여 잘 추출한 후, TTS 에 condition으로 이용하면 학습 시점에 보지 못한 화자의 목소리로 TTS 를 만들 수 있다는 연구입니다.
- 이 연구에서는 하나의 speaker embedding 만을 사용하기 때문에 충분한 representation을 담아내기 어렵습니다.
- 저희가 실제로 직접 재현해본 결과 뭔가 학습 과정에서 모델이 봤던 (즉 학습 데이터에 있었던 누군가) 의 목소리로 mapping 해준 다는 느낌이 들었습니다.
- Hierarchical Generative Modeling for Controllable Speech Synthesis [paper link]
- 이 논문은 구글에서 2018년에 ICLR 에 발표한 논문입니다. Gaussian Mixture Model 을 활용한 Variational AutoEncoder 를 이용하여 latent space 위에서 화자에 대한 정보를 모델링 할 수 있었다는 내용을 담고 있습니다.
- few-shot 문제를 푸는 것이 직접적인 목표가 아니었던 만큼 저희가 해결하고 싶어하는 문제를 잘 해결하고 있지 못합니다.
위에 소개한 기존 연구들은 상기한 단점들을 가지고 있었으며 이로 인해 이들을 재구현하는 것 만으로는 서비스에 넣기 힘들거라고 판단하여, 저희는 더 나은 few-shot TTS 를 만들어서 서비스에 활용하고자 하였고 연구를 진행하였습니다.
저희 모델은 TTS 연구에서 가장 활발하게 사용되고 있는 Tacotron 2 모델을 베이스로 출발하여, 화자의 음성에 관련된 정보를 잘 가져올 수 있는 두 개의 인코더를 활용합니다. 저희는 만들어진 모델을 Attentron 이라고 부르며 Attentron 모델은 attention 을 활용하여 따라하고자 하는 화자의 특징에 대한 정보를 스펙트로그램으로부터 직접 가져올 수 있습니다.
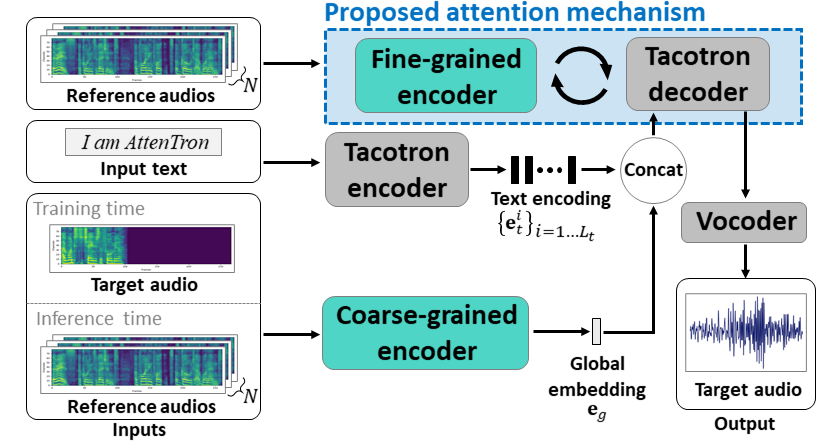
위 그림에서 Coarse-grained Encoder 는 모방하려고 하는 화자의 음성에 대한 전반적인 정보를 가져오기를 기대하며, Fine-grained Encoder 에서는 화자의 발화 특징을 따라하기 위한 세부적인 정보를 추출하는 것을 목표로 합니다. 이 중 저희 모델의 메인 contribution 은 Fine-grained Encoder 입니다.
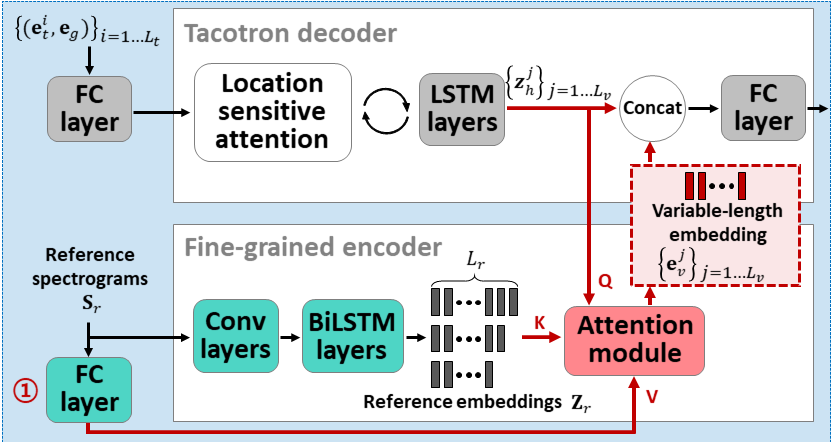
모방하고자 하는 화자의 음성 샘플들 (그림에서 Reference spectrograms)을 CNN 과 BiLSTM 에 태우면 time step 의 길이에 비례하는 숫자의 embedding 들이 생성됩니다. Tacotron decoder 에서는 매 스텝마다 attention 을 이용하여 위에서 생성된 embedding 들 중에서 특별히 유의미한 embedding 들에 강한 weight을 줘서 골라내고, 이를 condition으로 활용하여 스펙트로그램을 합성합니다. 이는 기존의 연구들에서 볼 수 없었던 방법론이었으며 이 모듈은 가변변적인 길이의 임베딩 (Variable-length embedding) 을 활용할 수 있다는 장점 덕분에 더 많은 representation을 담아낼 수 있었습니다.
이렇게 만들어진 모델을 평가하기 위한 두 가지 요소는 naturalness(음성이 얼마나 자연스러운지) 와 speaker similarity(얼마나 모방하려고 하는 목소리와 비슷한지) 가 있었는데요. Attentron은 이 두 가지 측면에서 기존의 state-of-the-art 들보다 모두 우수한 모습을 보여주었습니다. 이에 관련하여 연구를 진행한 내용을 논문 과 데모 페이지 에 좀 더 상세하게 다뤘으니, 관심이 있는 분들은 확인해보시기 바랍니다.
Attentron 의 장점
저희 Attentron 이 기존 방법론들에 비해 우수한 점들은 다음과 같습니다.
- 기존에는 few-shot TTS 문제를 해결하기 위해 speaker embedding 을 추출하기 위한 speaker verification 모델을 사전에 학습하여 활용하는 방법이 많았습니다. 이런 방법은 학습에 필요한 단계를 많이 가져가면서 생기는 불편함이 있었으며, speaker verification 모델을 학습시키기 위한 추가적인 리소스와 데이터셋을 요구합니다.
- Attentron은 이런 과정이 필요없이 한번에 end-to-end 로 모델을 학습합니다.
- 단일의 speaker embedding 을 활용하는 모델들은 화자에 대한 정보를 단 하나의 벡터에 담아줘야 했기 때문에 충분한 정보를 담지 못합니다.
- 저희는 기존의 이런 임베딩들을 fixed-length embedding 이라고 부르는데, 이런 방법들은 representation learning 에 한계가 있고 실제 음성을 합성해보면 speaker similarity 가 낮았습니다.
- Attentron은 이 단점을 attention 을 활용한 variable-length embedding 을 활용하여 개선하였고 덕분에 더 높은 speaker similarity를 얻을 수 있었습니다.
- 기존 연구들은 아무리 음성 샘플이 많아도 이 음성 샘플 들에서 얻은 임베딩에 그냥 평균을 취해서 하나의 임베딩으로만 만들어버리니 그 정보를 효율적으로 쓰고 있지 못합니다. 음성이 5초가 있는 경우와 1분이 있는 경우에도 같은 양의 정보만을 활용하게 되는 것이죠.
- Attentron은 mean embedding 을 사용하는 대신 attention 을 활용하여 더 많은 숫자의 음성 샘플을 효과적으로 활용하여 embedding 을 만들고, 그 덕분에 더 높은 speaker similarity를 보입니다.
마치며
이 글에서는 저희가 Few-shot TTS 를 왜 개발하고자 했으며 기존 연구들이 어떤 아쉬운 점이 있었는지, 그리고 이를 어떻게 해결하였는지에 대한 얘기를 소개했습니다. 저희는 제시한 Attentron 을 활용하여 회사의 라이브 스트리밍 서비스인 하쿠나 라이브에서 다섯명의 호스트를 대상으로 보이스 기프트 기능을 베타 서비스를 제공하였습니다. 해당 기능 출시 직후 15일간의 데이터를 관찰해보니 다섯 명의 호스트에 대하여 보이스 기프트의 사용 횟수가 기존과 비교하여 전체적으로는 19%, 특정 호스트는 최대 140% 증가하는 경향을 보여줬고, 시청자당 평균 선물한 보이스 기프트 숫자가 63% 만큼 증가 하는 등, 연구와 서비스 두 마리 토끼를 모두 잡는 결과를 보여주었습니다. AI Lab 에서는 추후에도 음성 합성 뿐만 아니라 다양한 머신러닝 기술을 활용하여 서비스에서 사용할 수 있는 재밌는 피쳐를 만들어 볼 계획이며, 함께 할 실력있는 팀원들을 항상 채용하고 있습니다!