bigquery 저장소 최적화 진행기
하이퍼커넥트는 모든 서비스가 클라우드환경에서 작동하고 있으며 그에따라 모든 데이터 파이프 라인 및 레이크도 클라우드 서비스를 이용하고 있습니다.
클라우드 서비스는 기본적으로 사용자가 요청하는 만큼의 자원을 주는 온디멘드 방식입니다. 따라서 자원을 요청하는 범위를 잘 생각하여 사용하여야 합니다.
하지만 데이터 레이크 특성 상 하루에도 몇번씩 데이터가 새로 생기고 조합되며 삭제됩니다.
급급하게 요청되는 데이터 작업을 하다 처리하다 보면 어떤 데이터의 추적이 힘들어지며 또한 데이터 리텐션에 대한 정책을 운영하기 어려워지는 상황에 도래하게 됩니다.
이번 포스트에서 언급할 firebase로그가 이에 해당하는 부분입니다. 이번 글에서는 빅쿼리에서 사용하던 예전 로그들을 비용이 더 저렴한 GCS로 아카이브를 진행했던 내용을 적어보겠습니다.
빅쿼리 저장정책
빅쿼리로 데이터를 로드할 때의 요금은 청구되지 않지만 로드 후 데이터가 저장되는 용량만큼 비용이 청구됩니다.
빅쿼리에 저장되는 데이터도 기본적으로 90일동안 수정이 되지 않았으면 장기 스토리지로 분류되어 저장비용이 저렴해집니다.
파티션을 나눈 테이블에서는 각 파티션마다 별도로 적용되어 특정 파티션 날짜가 위 조건에 해당되면 장기 스토리지으로 간주됩니다.
하지만 활성 스토리지에 비해서 저렴할 뿐이지 일반적으로 아카이브용으로 쓰는 서비스에 비교하면 비용적으로 비싼부분이 있습니다.
아래 공식문서에 나와 있는 것처럼 장기 스토리지로 데이터가 넘어간다고 해도 $0.01 per GB 이며 GCS의 기본 저장 타입인 Nearline Storage와 동일 합니다.
데이터 용량이 적으면 크게 부담은 없지만 하루에 2TB씩 쌓이는 테이블인 경우 첫날은 2TB 둘째날은 4TB… 60TB까지 쌓이기 때문에 한달치 데이터를 저장하는 경우 약 380만원이 사용이 됩니다. 보관 기간이 늘어나거나 이렇게 데이터가 누적되는 테이블이 더 있을 경우 비용은 순식간에 불어날 수 있습니다.
따라서 대용량의 테이블은 보관 기간 정책을 정한 뒤 삭제하거나 필요 시 데이터 저장 비용이 저렴한 스토리지로 아카이브 하는 것이 좋습니다.
빅쿼리 스토리지 요금 정책

데이터 스토리지 요금 정책
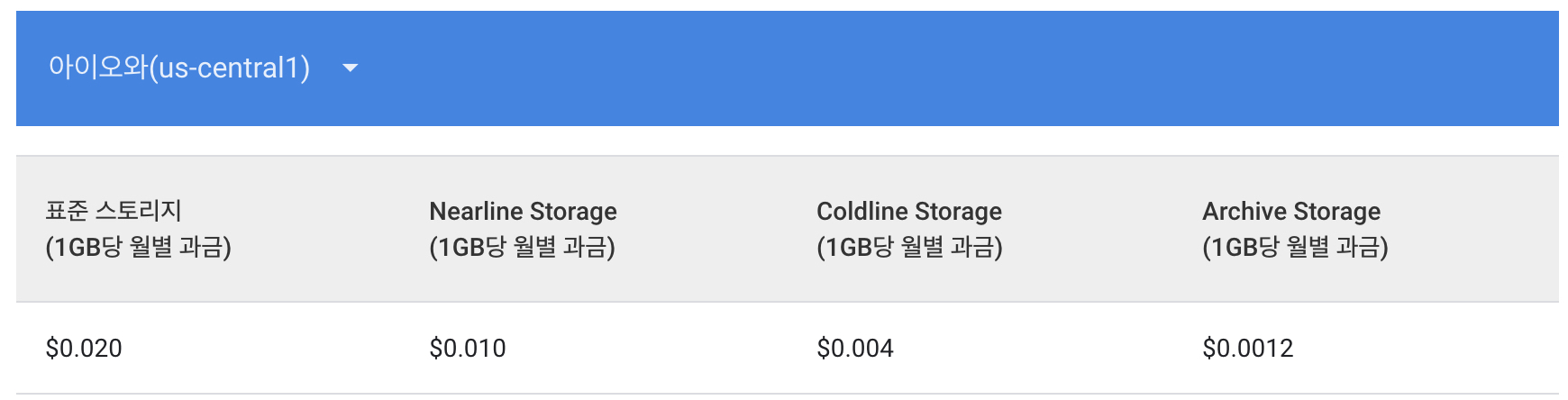
기존 아자르 Firebase 빅쿼리 파이프라인
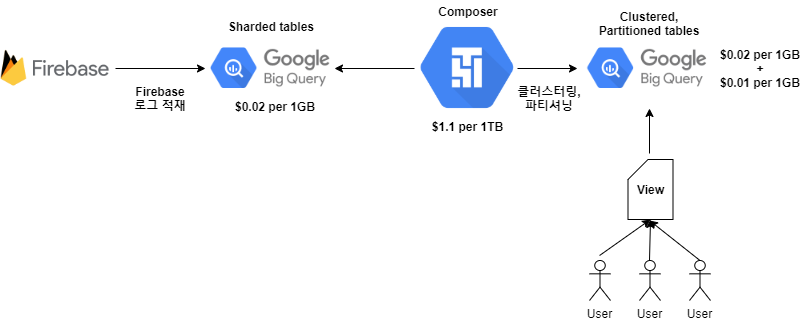
기존의 아자르 Firebase 파이프라인의 모습입니다.
Application의 firebase가 빅쿼리에 저장한 데이터를 주로 분석되는 컬럼들을 위주로 최적화 하기위하여 파티셔닝과 클러스터링 후 다시 빅쿼리에 저장합니다.
firebase가 직접 적재한 빅쿼리는 90일 이내의 데이터만 적재하였기때문에 1GB당 $0.02만큼 비용이 청구 됩니다.
파이프라인은 여기서 끝나지 않고 클러스터링과 파티셔닝을 위해 내부에서 사용중인 Composer의 BigqueryOperator를 이용하여 데이터를 정제하게 됩니다.
여기서 빅쿼리 API비용인 1TB당 $1.1가 소모가 되며 이렇게 정제된 데이터를 저장하기 위해 최근 90일 데이터는 1GB당 $0.02, 그 이후 데이터는 1GB당 $0.01의 비용이 발생합니다.
클러스터링작업을 하여 사용자가 특정 컬럼을 이용할 때 비용이 절감되는 효과가 있지만 동일한 데이터가 중복으로 저장되고 정제하는 과정에서 빅쿼리 비용이 청구되는 등의 문제가 있습니다.
새로 구성한 아자르 Firebase 파이프라인
저장공간
bigquery 테이블의 데이터를 아카이브하는 프로젝트를 진행한 이유는 본질적으로 데이터를 저장하는 비용을 최적화하는 것 이였습니다.
따라서 데이터 활용에 필요한 최소한의 데이터를 제외하고 나머지 데이터들은 아카이브를 진행을 하려고 했습니다.
아카이브를 진행하려고 보니 아카이브를 할 수 있는 다양한 선택지들이 있었습니다. GCP의 GCS와 AWS의 glacier 입니다.
위 2가지의 서비스에 대해서 검토한 결과 GCS를 사용하기로 결정하였는데 이렇게 선택한 이유는 크게 비용적인 부분과 편리성 2가지가 이유였습니다.
비용[1]
스토리지 저장비용
| 업체 | 서비스명 | 가격 |
|---|---|---|
| GCP | GCS Archive Storage | 1기가 당 $0.0012 |
| AWS | AWS Glacier | 1기가 당 $0.004 |
검색 요금
| 업체 | 서비스명 | 가격 | 비고 |
|---|---|---|---|
| GCP | GCS Archive Storage | 1기가 당 $0.05 | |
| AWS | AWS Glacier | 1기가 당 $0.01, 1000개 요청당 $0.05 | 표준 |
위 표를 보시면 알겠지만 기본적으로 저장 비용은 GCP가 훨씬더 저렴한 것을 볼수 있습니다.
검색 요금은 얼핏 보면 Glacier가 더 저렴해보이지만 Glacier는 로그를 검색하는 비용 뿐만 아니라 검색이 가능하도록 요청하는 비용을 따로 청구합니다.
또한 Glacier는 검색을 요청하는 타입(신속, 표준, 벌크)에 따라서 비용이 다 다르기때문에 이 부분도 고려되어야 합니다.
저희가 사용하는 용도는 오래된 데이터들을 저장해두고 복구하는 일이 거의 없기 때문에 스토리지 저장 비용을 1순위로 생각하였습니다.
따라서 결과적으로 GCP의 GCS(Archive Storage)를 선택하였습니다.
편리성
GCS
GCS의 경우 Archive Storage타입이라고 할지라도 표준 스토리지에 있는 데이터와 동일한 방식으로 데이터를 조회 및 사용할 수 있습니다.
따라서 사용 편리성에 있어서 크게 불편함이 없습니다.
AWS Glacier
Glacier는 데이터를 조회하기 위해서는 검색 요청을 하여야 합니다.
검색 요청을 한다고 해서 바로 검색이 되는것이 아니라 최소 3시간에서 최대 12시간까지 기다려야하기 때문에 편리성에 있어서 GCS보다 제한되는 점이 많이 있다고 볼 수 있습니다.
위와 같은 이유로 편리성적인 측면도 GCS가 더 낫다고 판단하였습니다.
아카이브 파이프 라인
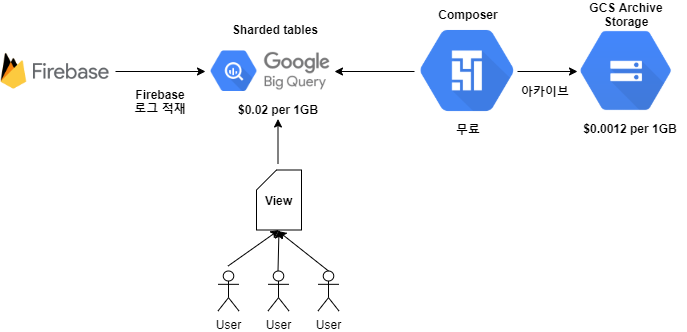
새로 구성한 아자르 Firebase 빅쿼리 파이프라인의 경우 중복으로 저장되는 부분을 제거하기 위해 과감하게 클러스터링을 포기하였습니다.
대신 중복으로 저장되던 빅쿼리 저장공간이 절약되고 클러스터링 작업을 위해 BigqueryOperator에서 사용하던 API이용(1TB당 $1.1)을 아낄수 있었습니다.(빅쿼리 export비용은 무료)
또한 기존에 기간의 제한 없이 저장하던 부분의 기한을 정하기 위해 해당 테이블의 사용 패턴을 분석했고 실제 테이블을 사용하는 분들과 이야기 하였습니다.
그결과 최근 3개월의 데이터가 있으면 괜찮다고 결론이 나와 저장 기한을 3개월로 축소 시키며 3개월이 지난 데이터는 GCS의 ArchiveStorage에 아카이브하도록 파이프라인을 변경하였습니다.
그 결과 저장 비용의 약 70%가 절약되었습니다.
새롭게 파이프라인을 구성하면서 테이블적으로 바뀐것은 크게 2가지 입니다.
- 클러스터링을 사용하지 않은 것
- 데이터 보관용 테이블의 파티션을 Partitioned table로 사용하던 부분을 Sharded table로 변경한 것
위 2가지의 개념에 대해서 간단히 설명 드리겠습니다.
첫번째로 파티션과 클러스터링에 대한 개념 입니다.
파티션과 클러스터링
파티션과 클러스터링은 데이터를 검색하는데 있어서 검색 범위를 좁힐 수 있는 기능들입니다. 빅쿼리에서 검색 범위를 줄이는 것은 매우 중요합니다.
속도적인 측면 뿐 아니라 비용과 가장 밀접하게 연관이 있기 때문입니다.
위 파이프라인을 변경하면서 영향이 있었던 클러스터링 부분과 그대로 유지된 파티션은 어떠한 차이가 있을까요?
파티션 테이블
파티션을 나눈 테이블은 파티션이라고 하는 세그먼트로 분할된 특수한 테이블로 보통 일단위로 데이터를 파티셔닝합니다. 파티셔닝된 데이터는 해당 데이터끼리 hard disk내 구분된 공간에 같이 보관이 됩니다. 따라서 일자를 기준으로 데이터를 조회한다면 다른 불필요한 공간을 검색할 필요 없이 데이터를 가져올 수 있습니다.
클러스터링 테이블
일반적으로 파티션 테이블을 만들때는 날짜를 기준으로 하여 생성을 합니다. 그럼 날짜가 아닌 텍스트나 다른 타입을 기준으로 데이터를 정리해두고 싶으면 어떻게 해야할까요? 물론 해당 컬럼으로 파티셔닝을 해도 되지만 보통은 클러스터링을 많이 사용합니다. 클러스터링이란 특정 컬럼을 선택하여 해당 컬럼의 데이터들을 정렬을 해두는 것을 의미합니다. 따라서 클러스터링한 컬럼을 기준으로 데이터를 쿼리할 경우 적은 SCAN으로 데이터를 찾아낼 수 있습니다.
두번째는 Partitioned table로 사용하던 부분을 Sharded table로 변경한 부분에 대해서 설명드리겠습니다. 두 방식은 비용적으로나 성능적으로는 크게 차이가 나지는 않지만 개념적으로는 다릅니다. 빅쿼리에서 파티션 테이블관리법은 총 3가지가 있어 3가지에 대한 개념을 설명 드리겠습니다.
빅쿼리에서의 테이블 관리법[2]
빅쿼리에서 테이블을 파티셔닝할때 크게 3가지 방법이 있습니다.
Partitioned tables
특정한 TIMESTAMP 나 DATE 타입의 컬럼을 기준으로 partition table을 생성할 수 있습니다. 이렇게 지정한 열의 기준에 따라 데이터가 각 파티션에 저장됩니다. 파티션 된 테이블은 최대 4000개의 파티션이 허용 됩니다.
Ingestion-time partitioned tables
_PARTITIONTIME이라는 pseudo 컬럼을 바탕으로 데이터를 검색하는데 사용합니다. 빅쿼리는 데이터 수집 날짜를 기반으로하는 날짜 기반 파티션에 데이터를 자동으로 로드합니다.
Sharded tables
Sharding이란 데이터를 작은 청크로 분할하여 논리적으로 나누는 것을 말합니다. 이 테이블은 테이블 이름을 time-based로 네이밍을 합니다. date-sharded tables 라고 불리며 테이블명_YYYYMMDD처럼 생성합니다. Partitioned tables처럼 제한은 없지만 쿼리에서 테이블을 참조할때 1000개의 테이블만 참조할 수 있습니다.
파티션 테이블 데이터 삭제하기[3]
파티션을 나눈 테이블에서 데이터를 삭제하는 방법은 크게 2가지 방법이 있습니다. 기준 날짜를 바탕으로 데이터를 검색하여 삭제하는 방법과 파티션 만료 기간을 업데이트하는 방법입니다. 특정 날짜의 삭제가 필요하지 않는 이상 가능하면 파티션 만료 기간을 업데이트하여 삭제하는게 좋습니다. 그 이유는 데이터를 삭제하는 방식은 API 비용이 청구되지만 파티션 만료 기간을 업데이트하는 방식은 비용이 청구되지 않기 때문입니다.
파티션을 나눈 테이블에서 데이터 삭제
DELETE
project_id.dataset.mycolumntable
WHERE
field1 = 21
AND DATE(ts) = "2017-06-01"
파티션 만료 기간 업데이트
ALTER TABLE mydataset.ytable
SET OPTIONS (
-- Sets partition expiration to 5 days
partition_expiration_days=5
)
빅쿼리 데이터 아카이브 하기[4]
빅쿼리의 데이터를 GCS로 export하는 작업은 간단합니다. 아래와 같이 export할 테이블과 아카이브할 GCS의 위치를 지정해준 뒤 extract_table함수를 수행해주면 됩니다.
from google.cloud import bigquery
client = bigquery.Client()
bucket_name = 'my-bucket'
project = "bigquery-public-data"
dataset_id = "samples"
table_id = "shakespeare"
destination_uri = "gs://{}/{}".format(bucket_name, "shakespeare.csv")
dataset_ref = bigquery.DatasetReference(project, dataet_id)
table_ref = dataset_ref.table(table_id)
extract_job = client.extract_table(
table_ref,
destination_uri,
location="US",
)
extract_job.result()
print(
"Exported {}:{}.{} to {}".format(project, dataset_id, table_id, destination_uri)
)
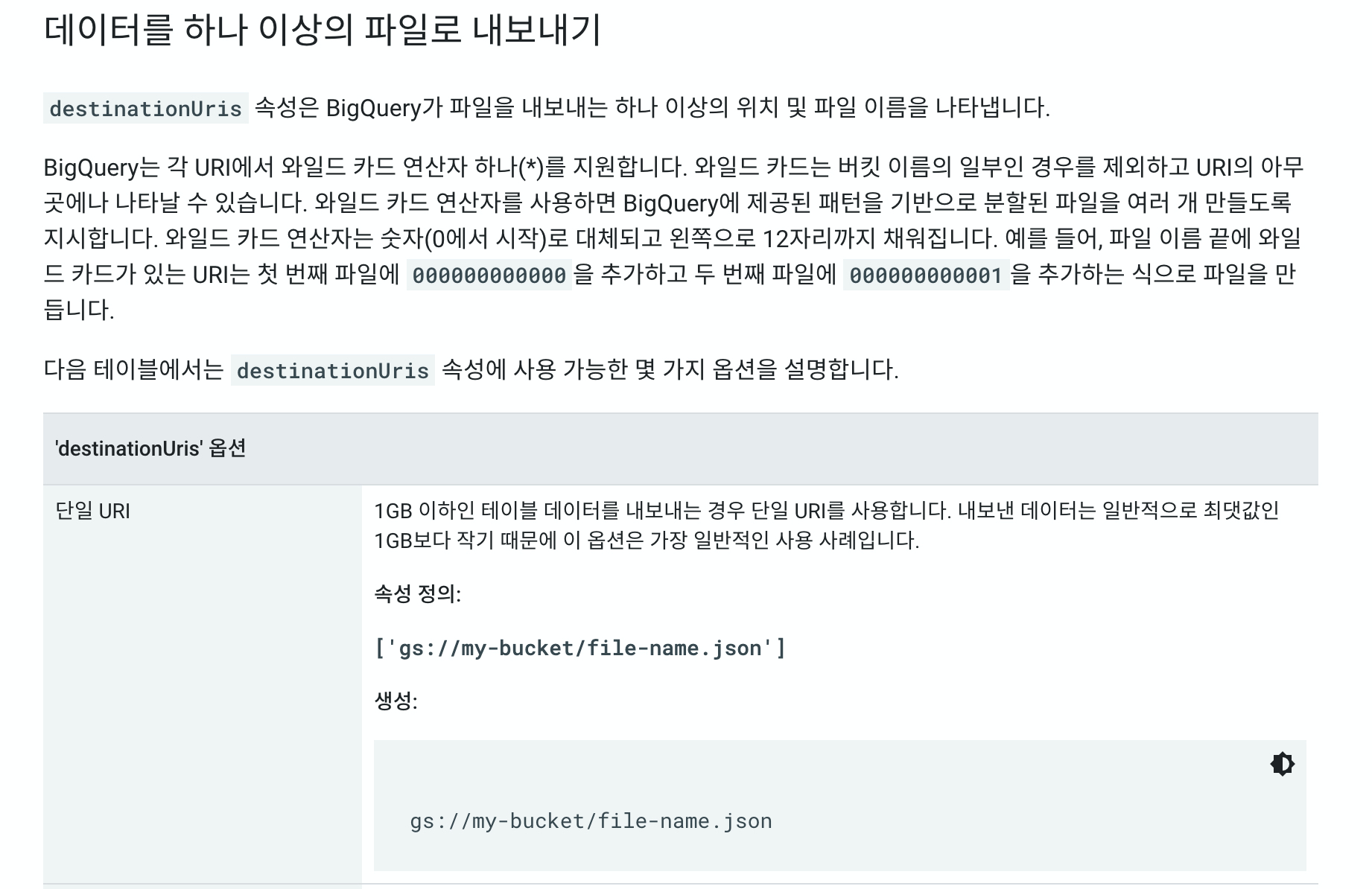
다만 크게 고려해야할 부분이 있다면 크게 2가지가 있습니다. 모든 테이블 데이터를 아카이브 하는 것이 아닌 특정 파티션(날짜)만 아카이브 하는것 이기 때문에 날짜를 지정해 주어야 합니다. 테이블명 뒤에 $의 붙이고 날짜를 지정해주면 됩니다. (shakespeare$20200101) 두번째는 export되는 테이블의 용량을 확인해야합니다. export 되는 데이터의 최댓값은 1GB이고 혹시 1GB가 넘을 시 와일드 카드를 주어 파일의 수를 나누어주어야 합니다. gz등으로 압축을 진행하여 export하는 경우에도 압축전 데이터의 용량이므로 이를 잘 생각하셔야 합니다.
export 데이터 용량이 1GB초과인 경우
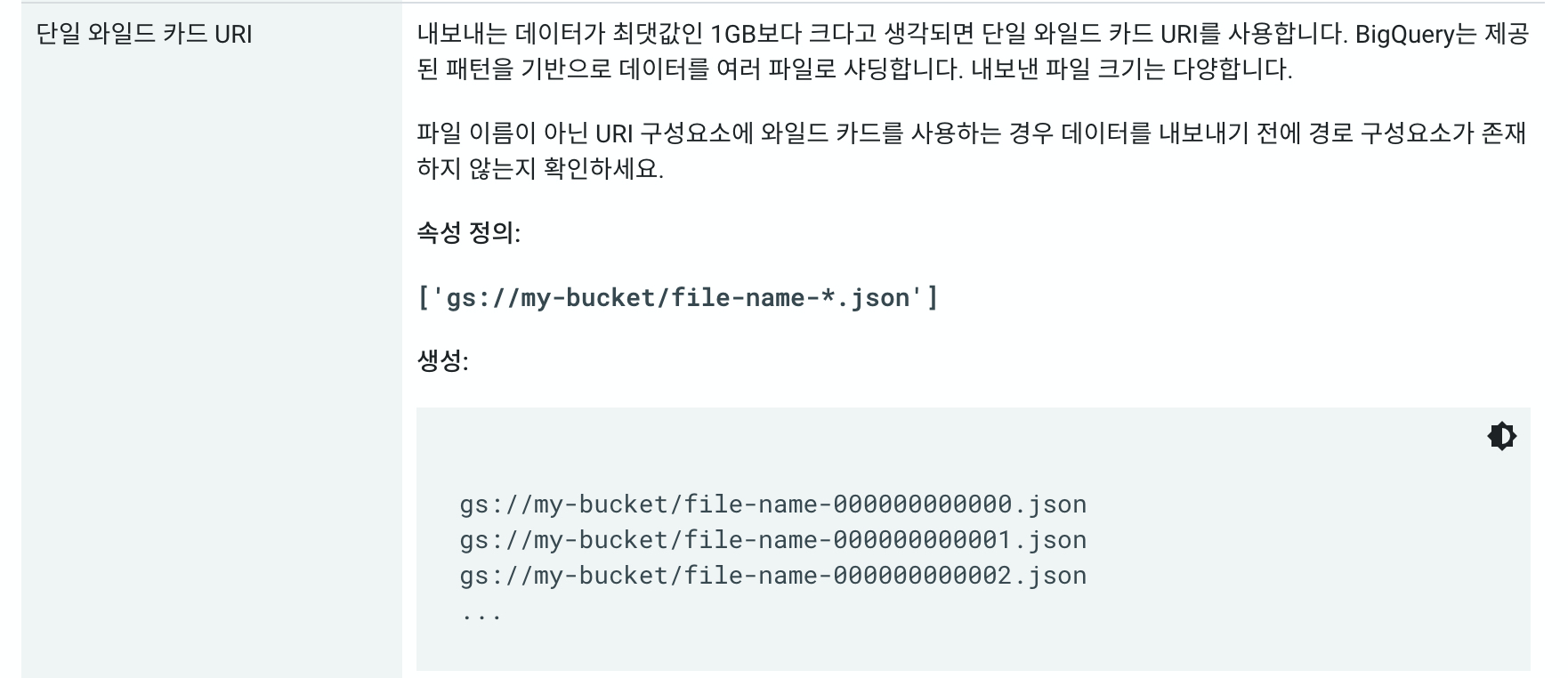
export 데이터 용량이 1GB이하인 경우
아카이브한 데이터 빅쿼리로 로드 하기[5]
데이터 레이크를 운영하다보면 운영 및 CS팀에서 빅쿼리에 없는 예전 데이터를 요구하는 경우가 있습니다.
이런 경우에는 GCS에 아카이브한 데이터를 다시 빅쿼리로 로드해주는 작업이 필요합니다. 따라서 미리 GCS에서 데이터를 로드하는 작업을 테스트할 필요가 있습니다.
데이터를 export하는 것 만큼 로드하는 작업도 간단합니다.
GCS는 데이터를 Archive Storage에 저장한다고 해서 AWS의 glacier처럼 데이터를 읽기 위해 별도의 작업을 하지 않해도 됩니다. 따라서 기존 GCS에서 작업하던 방식대로 작업하면 됩니다.
샘플 코드는 아래와 같습니다.
from google.cloud import bigquery
client = bigquery.Client()
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField("name", "STRING"),
bigquery.SchemaField("post_abbr", "STRING"),
],
source_format = biquery.SourceFormat.NEWLINE_DELIMITED_JSON,
)
uri = "gs://cloud-samples-data/bigquery/us-states/us-states.json"
load_job = client.load_table_from_uri(
uri,
table_id,
location="US",
job_config = job_config,
)
load_job.result()
destination_table = client.get_table(table_id)
print("Loaded {} rows.".format(destination_table.num_rows))
결과
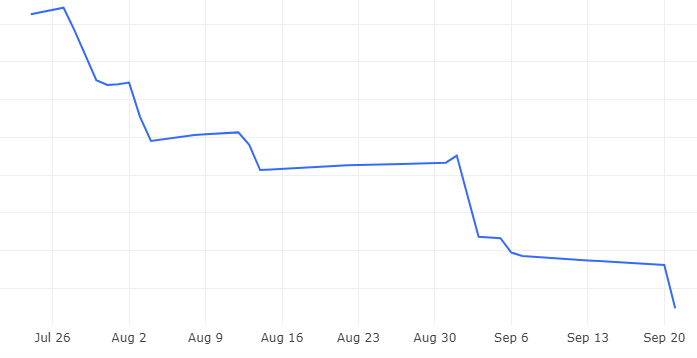
결과적으로 상당한 비용을 아낄 수 있었습니다.
firebase로그의 아카이브 경우 7월 말부터 8월초까지 진행을 하였는데 빅쿼리의 저장 용량의 70%이상을 절감할 수 있었습니다.
또한 데이터 정제를 위한 API비용까지 절감된 것을 고려하면 절감 비용은 그 이상으로 생각할 수 있습니다.
이 프로젝트를 진행하면서 데이터를 잘 저장 시키는 것도 중요하지만 그 만큼 저장된 데이터를 잘 모니터링 하면서 회사 시스템에 맞추어 최적화 하는 부분도 신경써야겠다고 느낀 프로젝트였습니다.
빅쿼리 저장 비용 추이
Reference
[1] 빅쿼리 가격 책정
[2] 파티션을 나눈 테이블 관리
[3] BigQuery ETL : 11 Best Practices For High Performance
[4] 테이블 데이터 내보내기
[5] GCS에서 데이터 로드