시계열 예측 패키지 Prophet 소개
개요
안녕하세요. 하이퍼커넥트의 데이터분석가 장은아입니다. 제가 이번에 소개해드릴 주제는 ‘Prophet 패키지’ 입니다. Prophet은 페이스북에서 공개한 시계열 예측 라이브러리 인데요, 정확도가 높고 빠르며 직관적인 파라미터로 모델 수정이 용이하다는 장점을 갖고 있습니다. 저희 하이퍼커넥트에서는 Prophet로 각종 KPI를 예측하고 변화에 대응하는 전략을 수립하는 데 활용하고 있습니다.
이론
Prophet 모델의 주요 구성요소는 Trend, Seasonality, Holiday 입니다. 이 세가지를 결합하면 아래의 공식으로 나타낼 수 있습니다.
\[y(t) = g(t) + s(t) + h(t) + \epsilon_i\]- \(g(t)\) : piecewise linear or logistic growth curve for modelling non-periodic changes in time series
- \(s(t)\) : periodic changes (e.g. weekly/yearly seasonality)
- \(h(t)\) : effects of holidays (user provided) with irregular schedules
- \(\epsilon_i\): error term accounts for any unusual changes not accommodated by the model
위에서 Trend 를 구성하는 \(g(t)\) 함수는 주기적이지 않은 변화인 트렌드를 나타냅니다. 부분적으로 선형 또는 logistic 곡선으로 이루어져 있습니다. 그리고 Seasonality 인 \(s(t)\) 함수는 weekly, yearly 등 주기적으로 나타나는 패턴들을 포함합니다.
Holiday를 나타내는 \(h(t)\) 함수는 휴일과 같이 불규칙한 이벤트들을 나타냅니다. 만약 특정 기간에 값이 비정상적으로 증가 또는, 감소했다면, holiday로 정의하여 모델에 반영할 수 있습니다. 마지막으로 \(\epsilon_i\) 는 정규분포라고 가정한 오차입니다.
튜토리얼
이제 이론적인 설명을 마치고, prophet 패키지를 사용하여 향후 실적을 예측해봅시다. Prophet 패키지는 R과 Python을 지원하지만, 여기서는 Python을 사용하여 진행하겠습니다.
튜토리얼에 사용될 데이터는 ‘2017-01-01’ 에서 ‘2019-12-27’ 까지의 일자 ‘ds’ 별 실적값 ‘y’ 으로 구성되어 있습니다.
(이 글에서 다루는 데이터는 실제 서비스 실적 데이터가 아닌 임의의 샘플 데이터 임을 밝힙니다.)
데이터 예시
| ds | y |
|---|---|
| 날짜_1 | 수치_1 |
| 날짜_2 | 수치_2 |
| … | … |
먼저 prophet과 필요한 패키지들을 import해줍니다.
import pandas as pd
from fbprophet import Prophet
파라미터를 조정하지 않고 바로 prophet으로 예측을 해봅시다. prophet object를 생성하고, 훈련 데이터를 피팅하여 prophet 모델을 만듭니다.
m = Prophet()
m.fit(df)
그리고 make_future_dataframe() 함수를 이용해 예측값을 넣을 데이터 프레임을 생성합니다. 이때, 인자로 들어가는 periods 값은 향후 몇일 (또는 주,월 등 단위 주기) 을 예측할 것인지를 의미합니다.
아래 코드에서 predict() 함수를 통해 향후 100일의 실적을 예측합니다.
future = m.make_future_dataframe(periods=100)
forecast = m.predict(future)
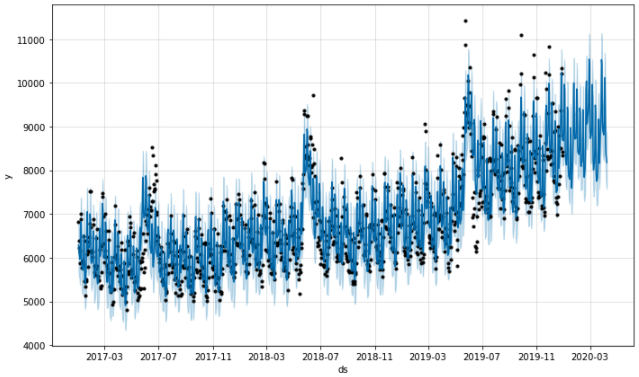
예측한 결과를 시각화해보면 아래와 같습니다.
fig1 = m.plot(forecast)
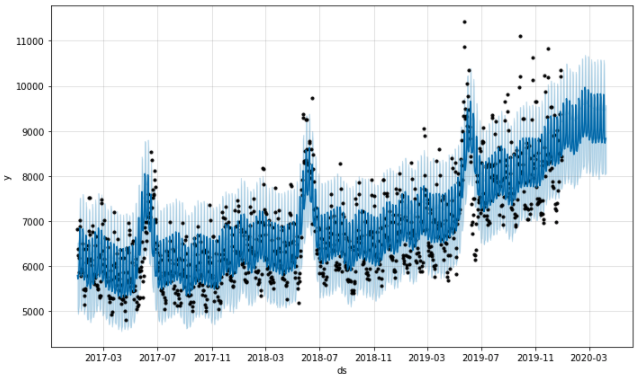
파란색 선이 모델이 예측한 값이고, 검정색 점들이 실제 데이터 입니다. 파라미터를 설정해주지 않은 기본값으로도 패턴을 꽤 잘 잡아내고 있죠? 피팅된 모델의 컴포넌트들을 시각화해보면 아래와 같습니다.
fig2 = m.plot_components(forecast)
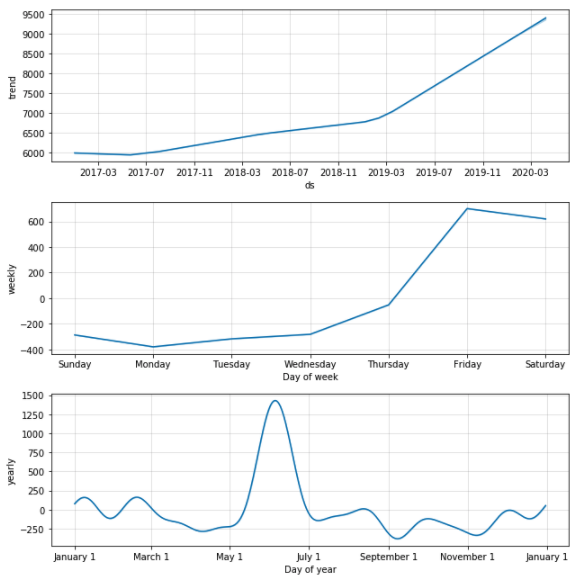
위 결과로 나온 컴포넌트들을 하나하나 해석해봅시다. 먼저, Trend는 점점 증가하는 추세를 보입니다.
만약 모델이 데이터의 Trend를 잘 잡아내지 못하는 것 같다면, changepoint_prior_scale 파라미터값을 높여주어 changepoint를 더 민감하게 감지하도록 할 수 있습니다. 여기서 changepoint란, Trend가 변화하는 지점을 의미합니다.
그 아래 차트는 각각 ‘주 계절성’과 ‘연 계절성’을 의미합니다. 두번째 차트인 weekly 먼저 살펴보면, 금요일과 토요일에 가장 실적이 높게 나타나는 패턴을 보입니다. yearly 패턴으로는 5~6월에 실적이 급격하게 상승하는 모습을 보이네요.
Trend와 마찬가지로 Seasonality또한 seasonality_prior_scale 파라미터로 모델 반영 강도를 조절할 수 있습니다.
Trend
모델의 Trend를 조절할 수 있는 파라미터는 다음과 같습니다.
| Parameter | Description |
|---|---|
| changepoints | 트렌드 변화시점을 명시한 리스트값 |
| changepoint_prior_scale | changepoint(trend) 의 유연성 조절 |
| n_changepoints | changepoint 의 개수 |
| changepoint_range | changepoint 설정 가능 범위. (기본적으로 데이터 중 80% 범위 내에서 changepoint를 설정합니다.) |
다음에서 모델의 changepoint 를 시각화해보고, changepoint_prior_scale 값 변경에 따른 Trend 변화를 살펴보겠습니다.
changepoint_prior_scale= 0.05 (default)
from fbprophet.plot import add_changepoints_to_plot
fig = m.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), m, forecast)
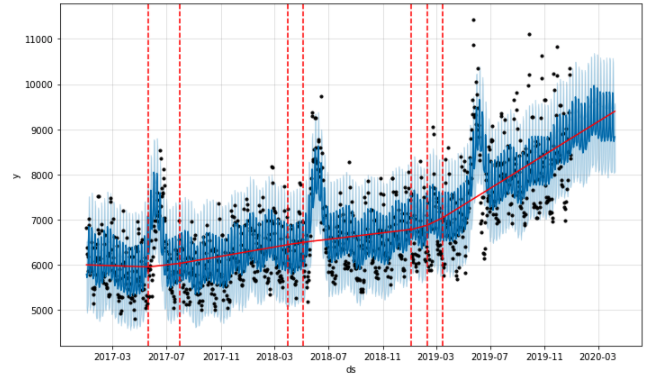
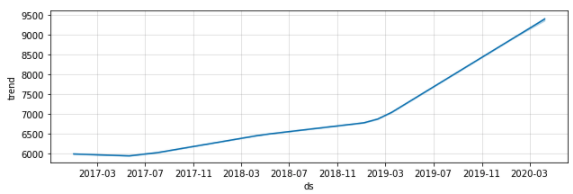
빨간 실선은 트렌드를 의미하며, 빨간 점선은 트렌드가 변화하는 changepoint 를 의미합니다. 빨간 실선인 트렌트만을 따로 그려봤을 때 결과는 아래와 같습니다.
changepoint_prior_scale= 0.3
m = Prophet(changepoint_prior_scale=0.3)
m.fit(df)
fig = m.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), m, forecast)
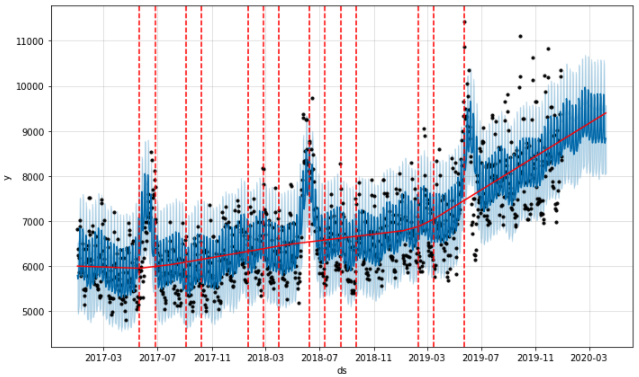
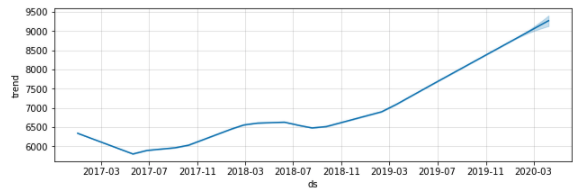
changepoint_prior_scale 값을 0.3으로 높여준 후 트렌드를 더 유연하게 감지하는 것을 확인할 수 있습니다. 이 값을 너무 높여버리면 overfitting의 위험이 있으니 주의해야 합니다.
만약 트렌드가 바뀌는 시점(서비스 확대 배포 또는 프로모션 등으로 인한 변화 시점)을 알고 있다면, changepoints 파라미터를 추가할 수 있고, changepoints 수 또한 n_changepoints 로 지정할 수 있습니다.
물론, 이 두 파라미터를 설정해주지 않아도 모델이 자동으로 감지합니다.
Seasonality
seasonality 관련 파라미터는 다음과 같습니다.
| Parameter | Description |
|---|---|
| yearly_seasonality | 연 계절성 |
| weekly_seasonality | 주 계절성 |
| daily_seasonality | 일 계절성 |
| seasonality_prior_scale | 계절성 반영 강도 |
| seasonality_mode | ‘additive ‘ 인지 ‘multiplicative’ 인지 |
prophet 알고리즘은 푸리에급수(Fourier series)를 이용하여 seasonality 패턴을 추정합니다. 푸리에급수는 주기가 있는 함수를 삼각함수의 급수로 나타낸 것인데요, 이 글에서는 자세히 다루지 않겠습니다.
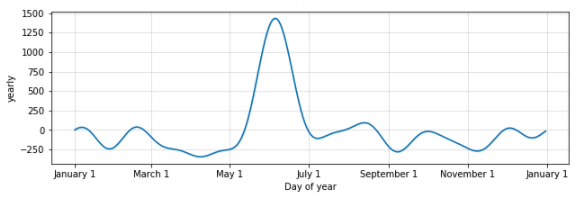
yearly_seasonality, weekly_seasonality 파라미터의 default 값은 ‘10’ 입니다. 만약 이 값을 높이면 어떻게 될까요?
다음에서 yearly_seasonality 값을 20으로 변경해보겠습니다.
yearly_seasonality= 10 (default)
yearly_seasonality= 20
m = Prophet(
# trend
changepoint_prior_scale=0.3,
# seasonality
weekly_seasonality=10,
yearly_seasonality=20,
daily_seasonality=False
)
m.fit(df)
fig = m.plot_components(forecast)
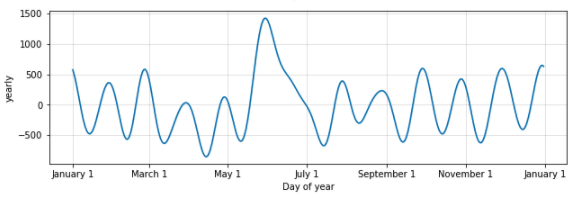
yearly_seasonality 값을 20으로 높여준 결과, 연 주기 패턴을 더 유연하게 잡아주는 것을 확인할 수 있습니다. 하지만 너무 유연하게 fitting 된 모델은 overfitting 위험이 높습니다. 값을 낮춰주는 것이 더 적절해 보이네요.
이 파라미터 역시 overfitting 또는, underfitting 되지 않도록 유의해야 합니다.
기본적으로 daily, weely, yearly seasonality에 대해서는 파라미터로 제공되지만, monthly는 제공되지 않습니다. 만약 필요하다면, 임의로 seasonality를 정의하여 모델에 반영할 수 있습니다. 주기가 30.5일이고, fourier order가 5인 ‘monthly’ 라는 이름의 seasonality를 추가해 보겠습니다.
m.add_seasonality(name='monthly', period=30.5, fourier_order=5)
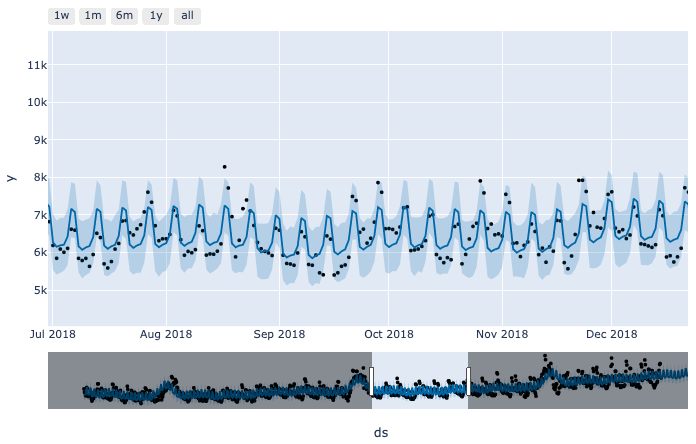
- monthly 추가 전
- monthly 추가 후
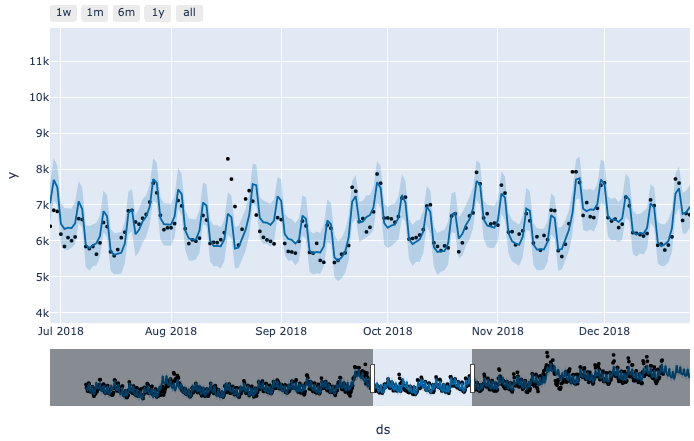
동일 기간 예측값을 비교해 봤을 때, 이전보다 monthly seasonality를 더 잘 잡아주는것을 확인할 수 있습니다. 이렇게 필요한 seasonality에 대해서 직접 커스터마이징하여 모델에 추가하는 것이 가능합니다.
추가로 seasonality_mode 파라미터에 대해 소개해 드리겠습니다. 이 파라미터는 시계열 데이터가 Additive인지 Multiplicative인지 명시합니다.
둘의 차이점에 대해서 간단하게 설명드리면, Additive는 데이터의 진폭이 일정함을 의미하고, Multiplicative는 데이터의 진폭이 점점 증가하거나 감소하는 것을 뜻합니다.
만약, 시계열 데이터 분석시 데이터가 Additive인지 Multiplicative인지 잘못 구분한다면 오차항을 제대로 분리하지 못하게 됩니다.
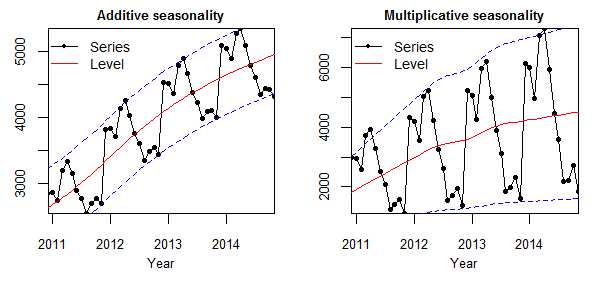
- Additive Seasonality : Time series = Trend + Seasonality + Error
- Multiplicative Seasonality : Time series = Trend * Seasonality * Error
이제 seasonality_mode = 'multiplicative' 파라미터를 모델에 추가해봅시다.
- seasonality_mode = ‘additive’ (default)
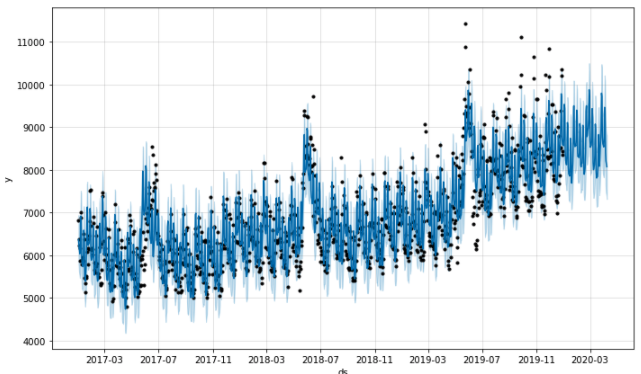
- seasonality_mode = ‘multiplicative’
m = Prophet(
# trend
changepoint_prior_scale=0.3,
# seasonality
weekly_seasonality=10,
yearly_seasonality=10,
daily_seasonality=False,
seasonality_mode='multiplicative'
)
# Specifying Custom Seasonalities
m.add_seasonality(name='monthly', period=30.5, fourier_order=5)
m.fit(df)
forecast = m.predict(future)
fig1 = m.plot(forecast)
위 데이터에서는 ‘Multiplicative’한 특성이 강하지 않아 추가하기 전과 비교해봤을 때, 큰 차이를 보이지 않습니다.
Holiday
마지막으로 Holiday관련 파라미터입니다.
| Parameter | Description |
|---|---|
| holidays | 휴일 또는 이벤트 기간을 명시한 데이터프레임 |
| holiday_prior_scale | holiday 반영 강도 |
데이터에 영향을 미치는 휴일이나 프로모션같은 이벤트를 알고 있다면, 모델에 반영하여 정확도를 높일 수 있습니다. 우리가 다루고 있는 데이터에서도 수치가 급격하게 상승하는 부분이 있습니다. 휴일이나 명절의 영향으로 수치가 달라질 수 있는데요, 이 특성을 모델에 반영해 보겠습니다.
먼저 holiday 정보 (기간,이름) 을 담은 데이터 프레임을 생성합니다.
m.add_country_holidays(country_name=’국가코드’)로 간단하게 국가 공휴일을 불러올 수도 있습니다. 하지만 모든 국가의 공휴일이 있는건 아닙니다.
holiday = pd.DataFrame({
'holiday': 'holiday',
'ds': pd.concat([
pd.Series(pd.date_range('2017-05-05', '2017-06-03', freq='D')),
pd.Series(pd.date_range('2018-05-05', '2018-06-03', freq='D')),
pd.Series(pd.date_range('2019-05-05', '2019-06-03', freq='D')),
pd.Series(pd.date_range('2020-05-05', '2020-06-03', freq='D'))
])
# lower_window = 0,
# upper_window = 1
})
만약 휴일이 휴일 전,후에도 영향을 미친다면 해당일만큼 파라미터로 설정해 줄 수 있습니다. 예를 들어, 공휴일 영향이 그 다음날에도 영향을 미친다면 lower_window=0, upper_window=1 을 추가하면 됩니다.
위에서 만든 holiday 데이터 프레임을 모델에 holidays 파라미터 값으로 넣어줍니다.
m = Prophet(
# trend
changepoint_prior_scale=0.3,
# seasonality
weekly_seasonality=10,
yearly_seasonality=10,
daily_seasonality=False,
seasonality_mode='multiplicative',
# holiday
holidays=holiday,
holidays_prior_scale=15
)
# Specifying Custom Seasonalities
m.add_seasonality(name='monthly', period=30.5, fourier_order=5)
m.fit(df)
forecast = m.predict(future)
fig = plot_plotly(m, forecast)
py.iplot(fig)
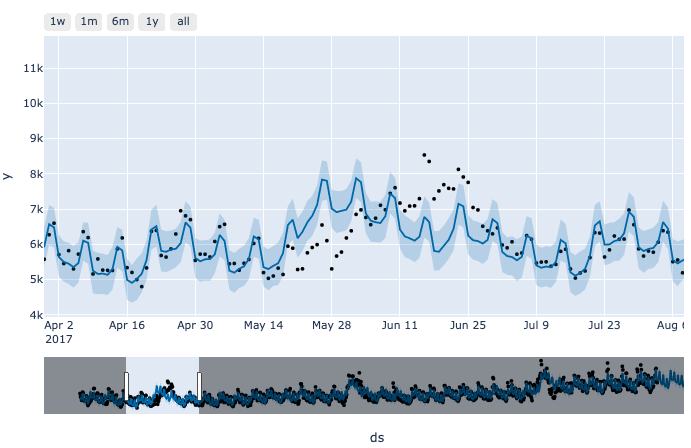
- holiday 설정 전
- holiday 설정 후
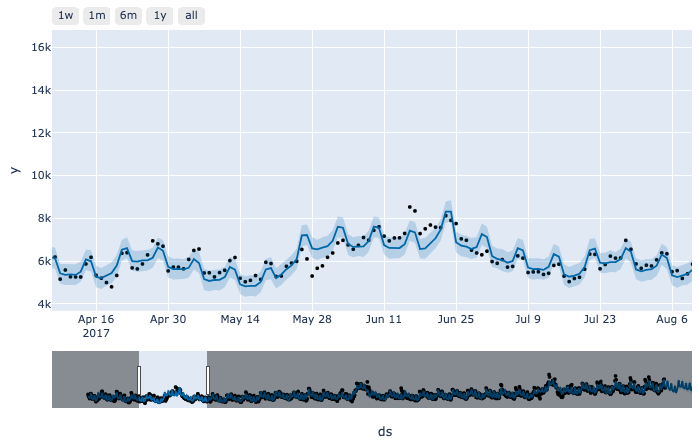
holiday설정 후, 설정해준 기간에 수치가 변화하는 패턴을 더 잘 맞추는 것을 볼 수 있습니다.
이상 Prophet 패키지를 활용한 시계열 데이터 예측이었습니다. 미처 소개시켜드리지 못한 prophet 함수와 기능들이 많지만 글이 길어질 것 같아 여기서 마치겠습니다. 더 자세한 사항은 아래 References로 추가한 페이지들을 참고해주세요.
마치며
앞서 소개해드린 것처럼 prophet 알고리즘의 파라미터는 매우 직관적이기 때문에 시계열 데이터에 대한 지식이 부족하더라도 쉽게 사용할 수 있습니다. 또한, 파라미터를 수정하고 시각화하는 과정을 반복하면서 빠르게 모델의 정확성을 높일 수 있다는 장점이 있습니다. 시계열 데이터를 분석, 예측하고자 하는 분들이라면 prophet을 사용해 보세요!
References
[1] https://facebook.github.io/prophet/
[2] https://peerj.com/preprints/3190/
[3] https://kourentzes.com/forecasting/2014/11/09/additive-and-multiplicative-seasonality/
[4] https://zzsza.github.io/data/2019/02/06/prophet/
[5] https://gorakgarak.tistory.com/1255
[6] https://www.analyticsvidhya.com/blog/2018/05/generate-accurate-forecasts-facebook-prophet-python-r/