대규모 Cloud 환경에서 Zabbix 사용 Tip
안녕하세요 Azar Platform팀의 Albert입니다. Hyperconnect의 인프라는 여러 종류의 Global 서비스를 하고 있으며,인프라 모니터링 도구로 Zabbix를 사용하고 있습니다. 이번 글에서는 대규모 AWS Cloud 환경에서 Zabbix 운영 Tip 및 Zabbix의 부족한 부분을 보완하기 위해 Python, ZabbixAPI를 활용한 방법을 소개해 드리고자 합니다.
Zabbix Overview
Zabbix는 최대 수만개의 서버 및 VM으로부터 최대 수백만가지의 metrics를 실시간으로 수집하여 보여줄 수 있는 엔터프라이즈 모니터링 도구입니다.
장점
- All-in-one 모니터링 시스템을 지향하고 있는 Zabbix는 Maintenance, Inventory, Reporting, SLA계산, Web monitoring과 같은 세밀하고 다양한 기능들을 제공합니다.
- Template 사용, 풍부한 Community Template 리소스를 활용 할 수 있습니다.
- Powerful한 Alert 및 Trigger 설정을 간단하게 설정 할 수 있습니다.
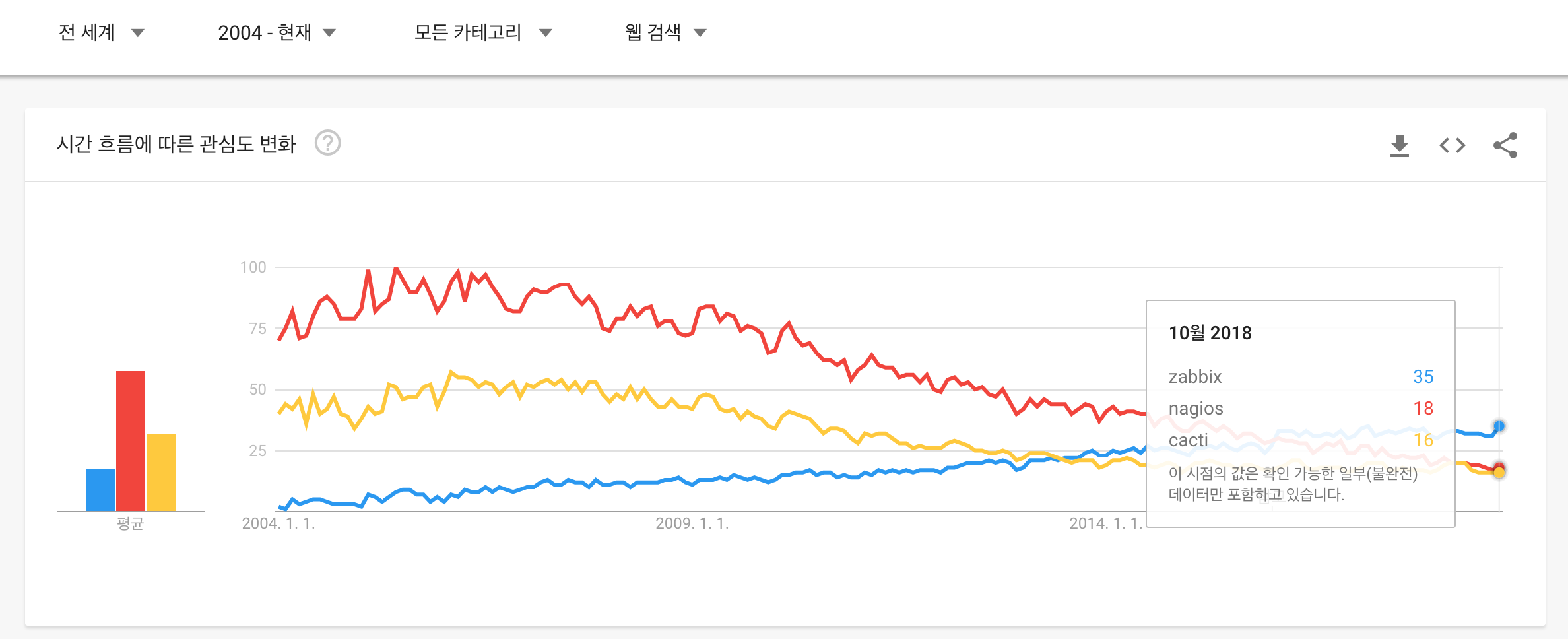
비슷한 경쟁 제품군으로는 Nagios, Cacti가 있습니다. 지속적인 기능 개선과 Dashboard UI가 향상 되면서 오늘 날 Google Trend상으로 추월하고 있는 모습입니다.
단점
- Auto Scaling, Immutable 인프라 환경 등으로 인한 IP, Resource 변경이 동적으로 발생하면 Host 관리에 불편함이 있습니다.
- Backend DB로 RDBMS를 사용하기 때문에 많은 양의 Log형 Data를 적재하고 Query하여 사용하는 방식은 DB에 무리를 줄 수 있기 때문에 사용하기 어렵습니다.
- Zabbix Data의 Retention 주기를 관리하는 Housekeeper라는 Process가 있습니다. 인프라 규모에 따라 설정값을 적절하게 Tuning 하지 못하면 DB에 큰 부담을 줄 수 있습니다.
4.0 LTS 버전 이전에는 Backend Database로 RDBMS(MySQL, PostgreSQL)를 사용해야 합니다. 하지만 4.0 LTS 버전 이후, Backend DB로 ElasticSearch를 지원하고 있습니다.
4.0 LTS Release note
- Zabbix Data의 Retention 주기를 관리하는 Housekeeper라는 Process가 있습니다. 인프라 규모에 따라 설정값을 적절하게 Tuning 하지 못하면 DB에 큰 부담을 줄 수 있습니다.
구성요소
Zabbix Server
Zabbix Server는 아래 요소로 구성되어 있습니다.
- Web
- Apache, Nginx 등 Web Front용 Web Server와 PHP
- Zabbix Server
- Alerting, HouseKeeper, Poller, Trapper등 Data 수집, 관리, 저장 기능 수행
- Database
- Data 저장에 필요한 Backend Database
Zabbix Sender
Active(Push)방식으로 Server의 Trapper로 Data 전송이 필요할 때 Zabbix Sender라는 CLI Tool을 사용하게 됩니다. 사용법은 아래와 같습니다.
$ zabbix_sender -z "ZabbixServer주소" -s "Zabbix에 등록된 HostName" -k "Host에 등록된 ItemKeyName" -o "Data값"
Zabbix Agent
Prometheus의 Exporter와 같이 Metric Data 송수신에 필요한 Agent 입니다. TCP 통신방식이며, Default Port로 10050을 사용하고 있습니다. Item Type에 따라 Active(Push), Passive(Pull) 방식을 지원합니다. Agent를 설치하게 되면 기본적으로 Agent에서 제공하는 Native Item Key들이 있습니다. 그 밖에, Agent에서 수집하는 Custom Item Metric이 필요한 경우 다음 2가지 방법을 이용해야 합니다.
- UserParameter
zabbix_agentd.conf파일에 연동할 Script, Command 설정만 해주면 되기 때문에 설정이 간편합니다.
- Module
- Item Metric Key를 Native하게 확장하여 사용하기 위한 방법으로서, C언어로 Module 개발이 필요합니다.
- Performance Co-Pilot Zabbix Module과 같은 검증된 Module을 사용해도 좋습니다.
- Performance Co-Pilot은 Redhat, Netflix등에서도 사용되고 있는 System Performance 수집 Toolkit
Zabbix Proxy
Zabbix Proxy는 일반적으로 아래와 같은 상황에서 사용됩니다.
- 다른 Network로부터 Data 수집을 위한 Gateway로 사용 (Firewall 사용 시 Security 관리 편의성)
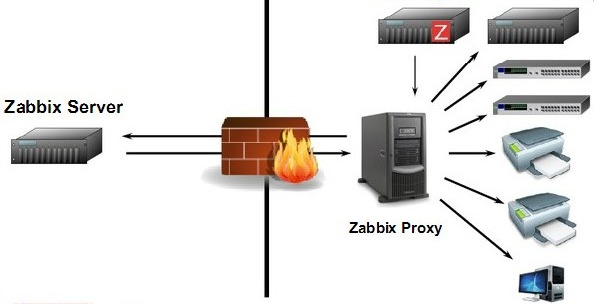
- Zabbix Server의 부하를 줄이기 위한 용도 (Distributed Monitoring)
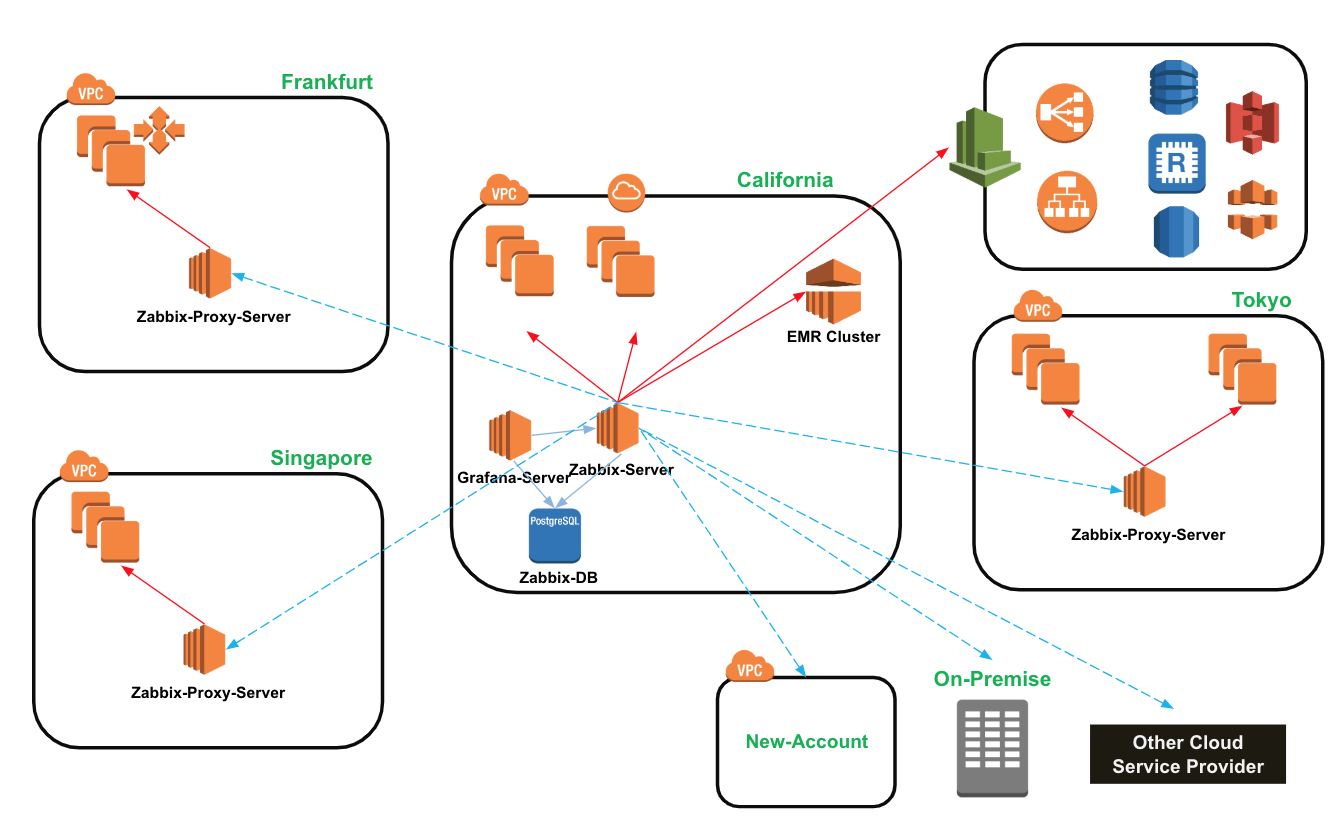 “Zabbix Proxy 활용 Architecture 구성”
“Zabbix Proxy 활용 Architecture 구성” - Global Region 간 Network 통신 문제 시, Data 유실 보호
- Server <-> Proxy 간 Network 문제로 인해 Data수집에 문제가 발생하여도 Proxy Server Database에 Data가 보관되어짐
Zabbix JavaGateway
JMX Data 수집을 위한 Gateway (Polling)
- Proxy Server처럼 JMX Data 수집을 위한 Gateway로 사용
- JMX Remote 설정
간단히 Zabbix에 대해 소개해 드렸습니다. 아래에서는 하이퍼커넥트가 이런 Zabbix를 수백개 이상의 서버를 관리하는데 사용하면서 얻은 운영 Tip을 소개합니다.
Naming Convention Rule
대규모 환경의 인프라를 효율적으로 관리하기 위해서는 인프라를 분류하는 Naming Convention Rule이 꼭 필요합니다.
Cloud 환경이던, On-Premise 환경이던 인프라의 형상, 서비스, 지역을 명명하는 Naming Convention Rule이 회사마다 있을 것입니다.
Hyperconnect에서는 아래 기준에 맞추어 인프라를 분류하고 있으며, AWS Tag정보에 포함됩니다.
Resource Type- Resource의 종류를 나타냅니다. (e.g EC2, RDS, ELB, ElastiCache)
Product- Service의 종류를 말합니다. (e.g: Azar)
Id- Resource의 고유한 ID (e.g InstanceID, S/N 등)
Stack- 형상의 종류를 나타냅니다. (e.g: Production, Dev, QA, Stage)
Duty- Ownership이 있는 Team을 나타냅니다. (e.g: Backend Team, Data Team)
Role- Service 안에서 역할 분류 (e.g: worker, web, was)
Region- 인프라가 서비스되는 지역
예시와 같은 Naming Convention Rule을 기반으로 Zabbix 상의 Hostgroup, Host, Template의 이름을 설계하는 것을 권장합니다.
Zabbix Linked Template 활용
Zabbix는 Template이라는 편리한 기능을 통해, Template에 Item과 Trigger를 정의 해놓고 모니터링 Host에 이를 Link하여 사용하게 되며, 아래 그림과 같은 구조를 갖습니다.
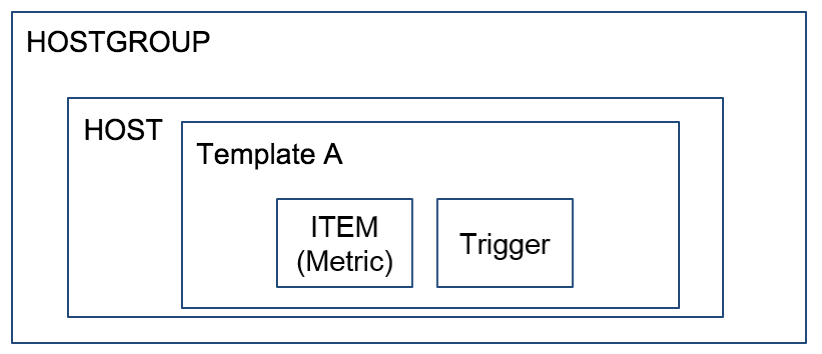
Programming의 추상화 개념처럼 필요한 집합에 공통된 Item과 Trigger를 Template화 하고 이를 상속받아 Child Template에서 사용할 수 있습니다. (Linked Template)
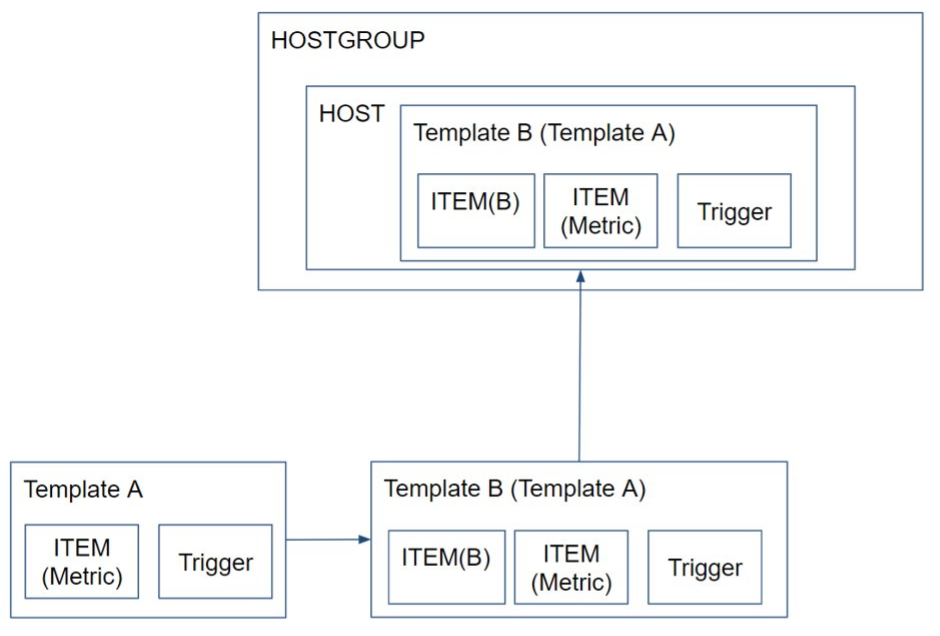
Naming Rule과 Linked Template 기능을 활용해 그림과 같이 Template을 계층화 해서 사용 하고 있습니다.

Host Auto Discovery: ZabbixAPI & AWS Tag 활용
규모가 큰 인프라 환경에서 Host를 일일히 등록하는 것은 너무 비효율적인 일입니다. Zabbix는 친절하게도 Auto Registration이라는 기능을 제공하고 있습니다.
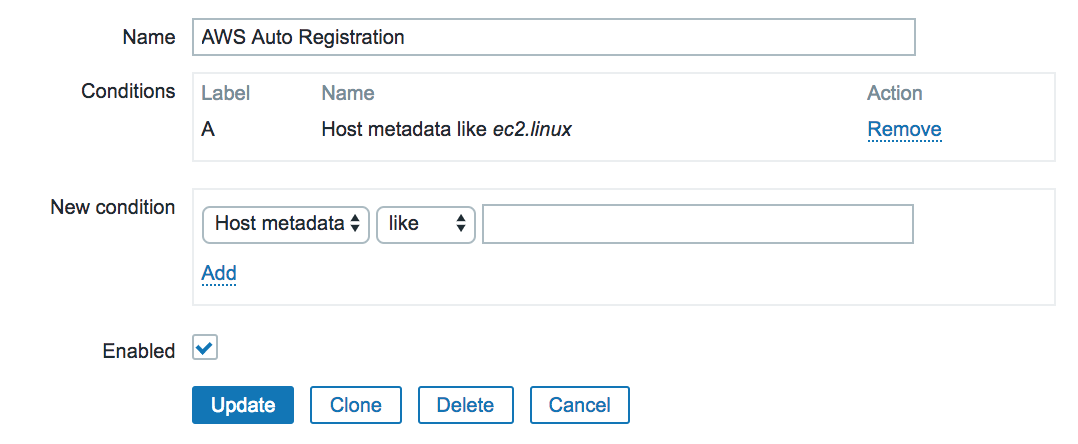
복잡하지 않은 인프라 구성의 경우 위 그림과 같이 Host Metadata와 Operation에서 Host를 등록하고 Template Link, HostGroup 할당하는 것 만으로도 충분할 수 있습니다.
Auto Registration: Remote Command 활용
Host 자동 등록 시, Host macro 추가와 유연한 Template 연결이 필요했었습니다. 그래서 저희는 Auto Registration Operation에 Remote Command로 Python Script를 Trigger 하여 Auto Registration 기능을 활용하고 있습니다. Naming Convention이 잘 정립되어 있다면 규칙에 맞추어 Host Auto Discovery하는 것이 수월합니다.
#!/bin/bash
# Zabbix RemoteCommand for Auto-Registration
auto-registration.py "{HOST.HOST}"
{HOST.HOST}는 Zabbix에 내장되어 사용할 수 있는 내장 Macro 중 하나입니다. Case 별로 사용할 수 있는 Macro가 있으니 해당 Table을 확인 하시기 바랍니다.
#!/usr/bin/python3
import boto3
import json
import os
import yaml
from datetime import datetime
from pyzabbix import ZabbixAPI
..
...
# Boto3로 Describe하여 가져온 정보를 macro format으로 변경
macro_lt = [
{'macro': '{$PRODUCT}', 'value': i['Product']},
{'macro': '{$STACK}', 'value': i['Stack']},
{'macro': '{$DUTY}', 'value': i['Duty']},
{'macro': '{$ROLE}', 'value': i['Role']},
{'macro': '{$REGION}', 'value': i['Region']},
{'macro': '{$INSTANCEID}', 'value': i['InstanceId']},
{'macro': '{$NAME_TAG}', 'value': i['Name']},
{'macro': '{$PRIVATE_IP}', 'value': i['PRIVATE_IP']},
{'macro': '{$PUBLIC_IP}', 'value': i['PUBLIC_IP']}
]
#ZabbixAPI를 통한 Host 등록
res = self._zapi.host.create(
host=self._input_host,
name=f"{i['Name']}::{i['InstanceId']}::{i['Region']}",
interfaces=interfaces,
status='0',
groups=groups_lt,
macros=macro_lt,
templates=templates,
inventory_mode='0',
inventory=inventory_dt,
description=f"{self._now}: EC2 Auto-Registrated"
)
...
..
해당 Code는 전달 받은 {HOST.HOST} (Agent에 등록된 Hostname)에서 InstanceID를 Parsing하여 Instance Tag, EC2 Metadata등을 가져와서 boto3, pyzabbix로 Host Macro정보와 함께 Convention에 맞는 적절한 Template과 Hostgroup, Hostname으로 자동 등록을 실행하게 됩니다.
Metadata 활용을 위한 Host Macro 등록
Managed 인프라와 Instance Status의 변화 Discovery
Cloud 환경에서는 Agent의 Auto Registration 기능으로 등록 할 수 없는 ELB, RDS, ElastiCache 등 AWS Managed Resource들이 있습니다.
또한, Instance Status (Stop, Termination, Replace 등)의 변화가 생길 수 있습니다.
이러한 인프라 변화에도 대응하기 위해 ZabbixAPI와 Boto3를 통해 자동화된 Zabbix 설정을 구현하여 사용 중 입니다.
결과적으로, AWS상에서 생성, 삭제, 교체되는 모든 인프라 자원들은 Zabbix에 자동으로 Update 됩니다.
Item Metric Auto Discovery: Zabbix Custom LLD 활용
Host 뿐만 아니라 Host내부의 Item metric들도 가변적인 요소들이 있습니다. 이러한 경우에 가변적인 Item metric을 Discovery하여 자동으로 Host Item에 등록하게 해주는 기능이 LLD(Low Level Discovery) 입니다. 현재 저희가 LLD을 사용하여 등록하는 Metric은 아래와 같습니다.
- Partition
vfs.fs.discoveryDefault로 내장된 Key를 제공하고 있음
- Network Interface
net.if.discoveryDefault로 내장된 Key를 제공하고 있음- Docker등 이 설치되어 있는 경우, 불필요한 Interface를 Filter해야 할 수 있습니다.
- Disk, Process, AWS ALB Targetgroup
- Custom LLD Key 필요
Custorm LLD 스크립트 예시
예시로, Disk를 Discovery하는 LLD Script를 만들어 보겠습니다.
#!/bin/bash
DISK=( $(lsblk | grep disk | awk '{print $1}') )
LEN=${#DISK[@]}
printf "{\"data\":["
for disk in "${DISK[@]}";
do
if [ $LEN -gt 1 ] ;
then
LEN=$(($LEN-1))
printf "{\"{#DISK}\":\"$disk\"},"
else
printf "{\"{#DISK}\":\"$disk\"}"
fi
done
printf "]}"
출력 결과는 다음과 같습니다.
{"data":[{"{#DISK}":"nvme0n1"},{"{#DISK}":"nvme0n2"}]}
결과 Format은 항상 {"data":[{"{#대문자}":"값"},{"{#대문자}":"값"},....]}위와 같은 형식을 맞추어 주어야 정상적으로 Zabbix가 인식합니다.
예시로 Bash Script를 소개했지만, 결과 출력 Format만 맞추어 준다면 편하게 사용할 수 있는 다른 언어를 사용하셔도 됩니다.
이제 해당 LLD Script를 UserParameter등을 통해 Item Key로 등록하고 Zabbix가 Discovery할 수 있게 하면 됩니다.
Cloudwatch + Lambda + ZabbixAPI의 사용
단순 Auto Discovery 기능을 넘어, 좀 더 복잡한 상황에서 AWS에서 발생하는 Event와 Zabbix 연동 간 Event Driven 방식 처리가 필요한 경우도 있습니다. 이럴 때는 Cloudwatch Event -> Lambda -> ZabbixAPI 연동 Pipeline을 구성하여 복잡한 모니터링 설정 변경 대응이 가능합니다.
마치며
소개해드린 것 처럼 Zabbix는 script, API 등을 통한 customize 를 통해 여러 use case 에 대응할 수 있는 모니터링 도구입니다. 정립된 convention을 통해 위 기능들을 적절하게 활용한다면 유기적으로 변화하는 대규모 Cloud환경에서도 Zabbix로 모니터링을 성공적으로 할 수 있을 것 입니다.